Note de l'auteur : Une comparaison objective de Claude Opus 4.6 et GPT-5.4 sur 12 tests de référence, leurs tarifs, leur fenêtre de contexte, leurs capacités d'agent et leurs cas d'utilisation, pour aider les développeurs à faire le bon choix.
En février et mars 2026, le domaine de l'IA a accueilli deux modèles phares majeurs : Claude Opus 4.6 d'Anthropic (5 février) et GPT-5.4 d'OpenAI (5 mars). Tous deux sont les modèles généraux les plus puissants jamais créés par leurs entreprises respectives, mais leurs philosophies de conception et leurs domaines d'excellence diffèrent radicalement.
Les tests de référence montrent que : GPT-5.4 remporte 5 catégories, Claude Opus 4.6 en remporte 3 — mais la supériorité de Claude dans les dimensions essentielles comme la programmation, le raisonnement et la qualité du code a une valeur pratique plus significative.
Valeur clé : Après avoir lu cet article, vous saurez précisément quel modèle choisir pour différents scénarios : programmation, raisonnement, automatisation, vision, etc.

Comparaison des données clés entre Claude Opus 4.6 et GPT-5.4
| Dimension de comparaison | Claude Opus 4.6 | GPT-5.4 | Explication |
|---|---|---|---|
| Date de sortie | 2026-02-05 | 2026-03-05 | Écart d'1 mois |
| ID du modèle | claude-opus-4-6 | gpt-5.4 | — |
| Fenêtre de contexte | 200K (1M Beta) | 1 000K | GPT supporte officiellement 1M |
| Sortie maximale | 128K | 128K | Identique |
| Prix d'entrée | 5,00 $/M | 2,50 $/M | GPT 50% moins cher |
| Prix de sortie | 25,00 $/M | 15,00 $/M | GPT 40% moins cher |
| Cache d'entrée | 0,50 $/M | 0,25 $/M | GPT 50% moins cher |
| Mode de raisonnement | Pensée adaptative (Adaptive) | Raisonnement à 5 niveaux (none→xhigh) | Chacun a ses spécificités |
| Contrôle d'ordinateur | ✅ (72,7%) | ✅ (75,0%) | GPT dépasse l'humain |
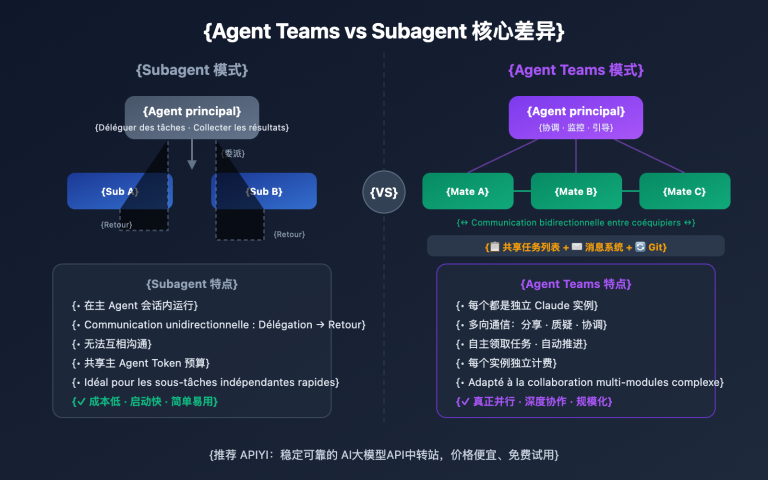
| Équipes d'agents | ✅ Agent Teams | ❌ | Exclusif à Claude |
| Recherche d'outils | ❌ | ✅ Token réduit de 47% | Exclusif à GPT |
| Plugins financiers | ❌ | ✅ Excel/Sheets | Exclusif à GPT |
Différences de philosophie de conception entre Claude Opus 4.6 et GPT-5.4
Les philosophies de conception des deux modèles sont radicalement différentes :
Claude Opus 4.6 suit la voie de "l'intelligence profonde". La pensée adaptative (Adaptive Thinking) permet au modèle de déterminer automatiquement la profondeur de raisonnement en fonction de la complexité du problème, sans avoir à définir manuellement un budget. La fonction Agent Teams permet à une instance principale de Claude de dériver plusieurs sous-agents indépendants travaillant en parallèle, coordonnés via un système de liste de tâches et de messages partagés. Cette architecture est plus adaptée aux tâches de programmation complexes nécessitant une compréhension approfondie et un raisonnement en chaîne longue.
GPT-5.4 suit la voie du "couteau suisse polyvalent". Il fusionne pour la première fois la programmation (héritée de GPT-5.3 Codex), le contrôle d'ordinateur, la vision en pleine résolution et la recherche d'outils dans un modèle générique unique. Le mécanisme de recherche d'outils permet au modèle de rechercher les définitions d'outils à la demande, réduisant l'utilisation de tokens de 47%. Les plugins financiers (Moody's, MSCI, etc.) et ChatGPT for Excel ciblent quant à eux les travaux professionnels de niveau entreprise.
🎯 Conseil de sélection : Leurs domaines de force sont presque complémentaires. Grâce à APIYI apiyi.com, vous pouvez utiliser une seule clé API pour invoquer à la fois Claude Opus 4.6 et GPT-5.4, et basculer de manière flexible en fonction du scénario.
Analyse détaillée des tests de référence Claude Opus 4.6 vs GPT-5.4
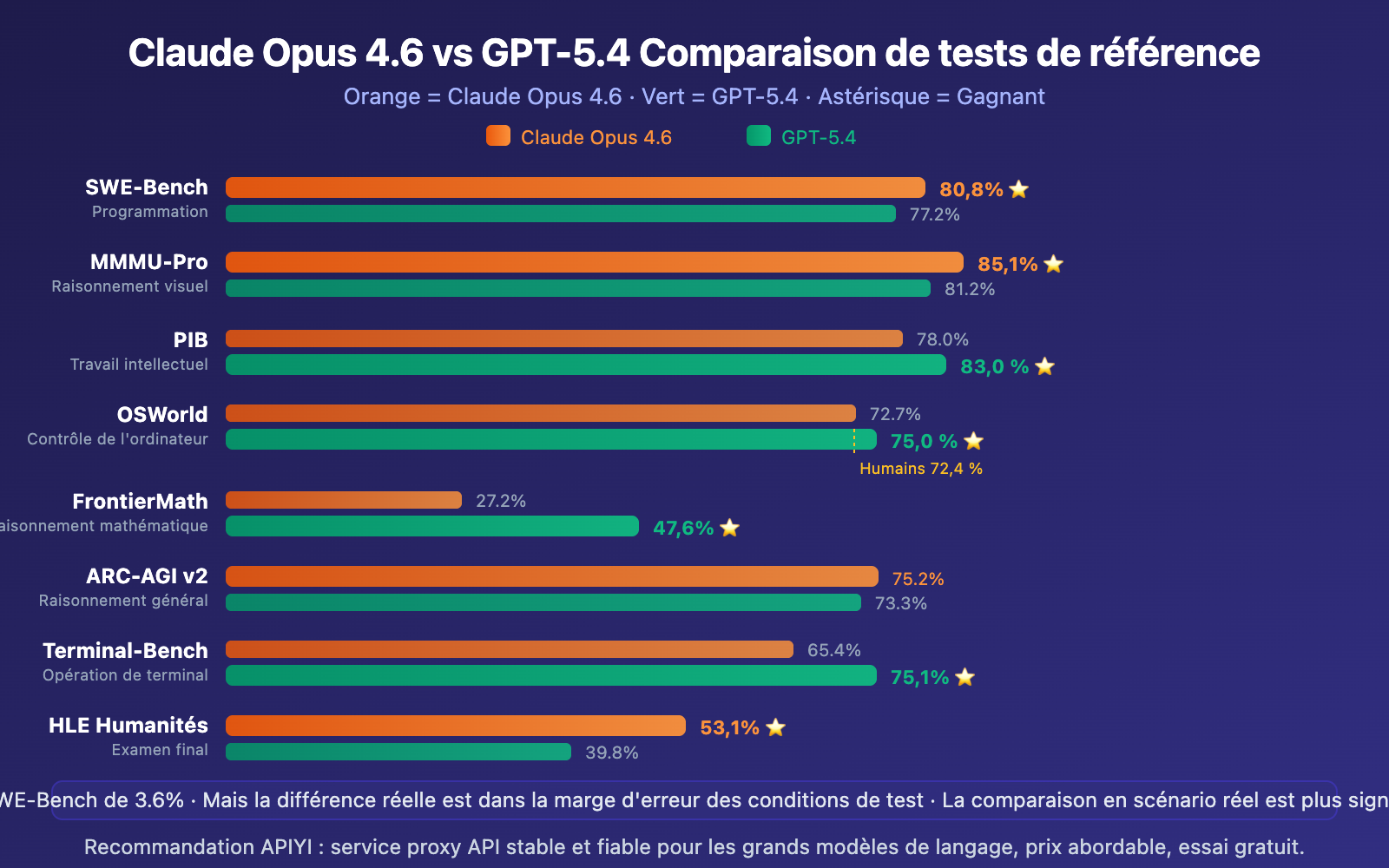
Tableau complet des tests de référence Claude Opus 4.6 vs GPT-5.4
| Test de référence | Claude Opus 4.6 | GPT-5.4 | Écart | Gagnant |
|---|---|---|---|---|
| SWE-Bench Verified | 80,8% | 77,2% | +3,6% | Claude |
| SWE-Bench Pro (haute difficulté) | ~45,9% | 57,7% | +11,8% | GPT |
| MMMU-Pro Raisonnement visuel | 85,1% | 81,2% | +3,9% | Claude |
| GDPval Travail intellectuel | 78,0% | 83,0% | +5,0% | GPT |
| OSWorld Contrôle d'ordinateur | 72,7% | 75,0% | +2,3% | GPT |
| FrontierMath Mathématiques | 27,2% | 47,6% | +20,4% | GPT |
| ARC-AGI v2 Raisonnement général | 75,2% | 73,3% | +1,9% | Claude |
| Terminal-Bench Terminal | 65,4% | 75,1% | +9,7% | GPT |
| Humanity's Last Exam | 53,1% | 39,8% | +13,3% | Claude |
| Tau2 Telecom | 99,3% | 98,9% | +0,4% | Claude |
| GPQA Raisonnement niveau master | 91,3% | 92,8% | +1,5% | GPT |
| BrowseComp Navigation web | 84,0% | 82,7% | +1,3% | Claude |
Il est important de souligner que : Les différences de SWE-Bench entre 80,0%, 80,6% et 80,8% se situent en réalité dans la marge d'erreur des conditions de test. En d'autres termes, sur les références de programmation standardisées, les deux modèles convergent. Les véritables différences se manifestent dans la qualité du code, la compréhension de l'architecture et l'expérience réelle de développement.
🎯 Conseil pratique : Les tests de référence ne sont qu'un point de départ. Nous vous recommandons d'obtenir un crédit gratuit via APIYI apiyi.com pour comparer les performances réelles des deux modèles dans vos propres projets. Cela aura bien plus de valeur que n'importe quel test de référence.
Comparaison des capacités exclusives : Claude Opus 4.6 vs GPT-5.4
Avantages exclusifs de Claude Opus 4.6
1. Agent Teams (Équipes d'agents)
La fonctionnalité Agent Teams introduite par Claude Opus 4.6 est unique dans le domaine actuel de l'IA. Une instance principale de Claude (Lead) peut générer plusieurs sous-agents indépendants (Teammates), chacun disposant d'une fenêtre de contexte complète et indépendante, collaborant en parallèle via un système partagé de listes de tâches et de messages.
Dans les tâches de recherche approfondie, cette technologie multi-agents améliore les performances d'environ 15 points de pourcentage. Cette architecture est particulièrement adaptée à la refactorisation parallèle de grandes bases de code – l'agent principal se charge de la planification, tandis que les sous-agents traitent différents modules.
2. Pensée adaptative (Adaptive Thinking)
Contrairement aux 5 niveaux de raisonnement manuels de GPT-5.4, la pensée adaptative de Claude permet au modèle d'évaluer automatiquement la complexité d'un problème et d'allouer dynamiquement la profondeur de raisonnement. Au niveau high par défaut, Claude active presque toujours une chaîne de raisonnement ; pour les problèmes simples, elle saute automatiquement cette étape, économisant ainsi des tokens et réduisant la latence.
La pensée adaptative prend également en charge la pensée entrelacée (Interleaved Thinking) – intercalant des réflexions entre les appels d'outils, ce qui est particulièrement efficace pour les flux de travail de type agent.
Avantages exclusifs de GPT-5.4
1. Contrôle natif de l'ordinateur
GPT-5.4 est le premier modèle généraliste d'OpenAI doté de capacités natives de contrôle informatique intégrées. Son score OSWorld de 75,0 % dépasse directement la ligne de base humaine de 72,4 %. Il peut interagir avec les navigateurs et les applications de bureau via du code Playwright ou des instructions directes clavier/souris.
2. Recherche d'outils (Tool Search)
Dans les systèmes possédant un grand nombre d'outils, l'approche traditionnelle nécessite d'envoyer toutes les définitions d'outils au modèle en une seule fois. La recherche d'outils de GPT-5.4 permet au modèle de rechercher les définitions d'outils à la demande, réduisant l'utilisation de tokens de 47 % tout en maintenant la même précision.
3. Intégration approfondie dans le secteur financier
L'intégration de ChatGPT pour Excel/Google Sheets avec les données de Moody's/MSCI/FactSet confère à GPT-5.4 un avantage écologique que Claude ne peut actuellement égaler dans le domaine de l'analyse financière. Les benchmarks internes des banques d'investissement sont passés de 43,7 % à 87,3 %.
🎯 Accès API : Claude Opus 4.6 et GPT-5.4 peuvent tous deux être appelés via l'interface unifiée d'APIYI apiyi.com. Les tarifs de GPT-5.4 sont alignés sur le site officiel (2,50 $/15,00 $), avec une offre de 10 % offerte à partir d'un dépôt de 100 $.
Guide de sélection par scénario : Claude Opus 4.6 vs GPT-5.4

Exemple d'accès API pour Claude Opus 4.6 vs GPT-5.4
import openai
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://vip.apiyi.com/v1"
)
# Refactorisation de code complexe → Claude Opus 4.6
refactor = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "Refactorisez l'injection de dépendances de ce module"}]
)
# Analyse globale d'un projet très volumineux → GPT-5.4
analysis = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "Analysez les vulnérabilités de sécurité de l'ensemble du projet"}]
)
Recommandation : Inscrivez-vous sur APIYI apiyi.com pour accéder simultanément aux deux modèles phares. Les tarifs de GPT-5.4 sont alignés sur le site officiel, avec une offre de 10 % offerte à partir d'un dépôt de 100 $. Pour changer de modèle, il suffit de modifier un paramètre.
Questions fréquentes
Q1 : Claude Opus 4.6 et GPT-5.4, lequel est le plus fort en programmation ?
Cela dépend de la dimension. Sur le benchmark standard SWE-Bench, Claude mène avec 80,8 % contre 77,2 % pour GPT, et offre également une meilleure qualité de code et une capacité de refactoring multi-fichiers supérieure. Cependant, GPT-5.4 reprend l'avantage sur le SWE-Bench Pro plus difficile avec 57,7 % contre ~45,9 %, et domine largement dans les tâches de manipulation de terminal (75,1 % contre 65,4 %). Pour la plupart des développeurs, les capacités de programmation des deux modèles convergent désormais.
Q2 : L’écart de prix est-il important ? Comment choisir ?
GPT-5.4 est globalement moins cher : entrée à 2,50 $ contre 5,00 $ par million de tokens (50 % de moins), sortie à 15,00 $ contre 25,00 $ par million (40 % de moins). Si le coût est le critère principal, GPT-5.4 est plus adapté. Si votre projet exige une qualité de code et une compréhension de l'architecture extrêmement élevées, la prime de Claude en vaut la peine. Nous recommandons d'utiliser les deux modèles de manière mixte selon les scénarios via APIYI (apiyi.com) pour optimiser les coûts.
Q3 : Comment utiliser les deux modèles depuis une seule plateforme ?
Inscrivez-vous sur APIYI (apiyi.com) :
- Obtenez une clé API unifiée
- Définissez le
base_urlsurhttps://vip.apiyi.com/v1 - Pour le refactoring :
model="claude-opus-4-6" - Pour l'analyse de gros projets :
model="gpt-5.4" - Pour les tâches quotidiennes :
model="gpt-5.3-chat-latest"(le plus économique)
Un rechargement de 100 USD minimum offre un bonus de 10 %. Un seul compte permet d'appeler tous les principaux modèles.
Conclusion
Voici les conclusions essentielles de la comparaison Claude Opus 4.6 vs GPT-5.4 :
- Pour la programmation et le raisonnement visuel, choisissez Claude : 80,8 % sur SWE-Bench, 85,1 % sur MMMU-Pro (le plus haut du secteur), un code plus propre, et la collaboration multi-agents (Agent Teams) est un avantage unique.
- Pour le travail de connaissance et l'automatisation, choisissez GPT : 83,0 % sur GDPval, 75,0 % sur OSWorld (dépasse les humains), un contexte de 1M de tokens désormais disponible, et une API 40 à 50 % moins chère.
- La stratégie la plus intelligente est de les combiner : Leurs domaines de force sont presque complémentaires – utilisez Claude pour le refactoring, GPT pour l'analyse de gros projets et l'automatisation, et GPT-5.3 Instant pour les tâches quotidiennes afin de réaliser des économies.
L'écart de 80,8 % contre 77,2 % sur SWE-Bench peut sembler faible, mais dans le développement réel, l'avantage de Claude en compréhension de l'architecture et en propreté du code reste significatif. GPT-5.4, quant à lui, a établi sa supériorité sur un autre plan grâce à son contexte de 1M de tokens, sa capacité à contrôler un ordinateur et son tarif plus bas.
Nous recommandons d'accéder aux deux modèles phares de manière unifiée via APIYI (apiyi.com) : une seule clé API pour tout appeler, avec un bonus de 10 % à partir de 100 USD de recharge.
📚 Références
-
GPT-5.4 vs Claude Opus 4.6 – Comparaison en programmation : Analyse du SWE-Bench, de la qualité du code et des capacités d'Agent du point de vue du développeur
- Lien :
blog.getbind.co/gpt-5-4-vs-claude-opus-4-6-which-one-is-better-for-coding/ - Description : La comparaison la plus détaillée sur les dimensions de la programmation, incluant les données du SWE-Bench Pro et du Terminal-Bench.
- Lien :
-
GPT-5.4 vs Opus 4.6 vs Gemini 3.1 Pro – Comparaison des trois géants : Analyse complète sur 12 tests de référence
- Lien :
digitalapplied.com/blog/gpt-5-4-vs-opus-4-6-vs-gemini-3-1-pro-best-frontier-model - Description : Couverture complète des prix, du contexte, des tests de référence, des avantages et des inconvénients.
- Lien :
-
Annonce officielle de Claude Opus 4.6 : Détails sur les nouvelles fonctionnalités comme les Agent Teams et la pensée adaptative
- Lien :
anthropic.com/news/claude-opus-4-6 - Description : Source de première main pour comprendre les fonctionnalités uniques de Claude.
- Lien :
-
Documentation de l'API de pensée adaptative de Claude Opus 4.6 : Guide d'intégration pour les développeurs
- Lien :
platform.claude.com/docs/en/build-with-claude/adaptive-thinking - Description : Comprendre les méthodes d'utilisation spécifiques et les paramètres de la pensée adaptative.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : Bienvenue dans les commentaires pour discuter. Plus de ressources sont disponibles dans le centre de documentation APIYI docs.apiyi.com.