Lors de la génération d'images par IA avec Nano Banana Pro (Imagen 3), vous avez peut-être déjà été confronté à cette confusion :
Pourquoi, avec la même invite, l'image 4K générée par Vertex AI pèse-t-elle 18 Mo, alors qu'elle n'en fait que quelques-uns sur AI Studio ?
Pourquoi Vertex AI semble-t-il parfois plus lent, alors qu'AI Studio génère des images à toute vitesse ?
D'où vient l'erreur Please use a valid role: user, model lors d'un appel à Vertex AI ?
La racine de ces problèmes réside dans un fait simple : bien que Vertex AI et AI Studio permettent tous deux d'appeler Nano Banana Pro, leurs architectures sous-jacentes, leurs paramètres de qualité et leurs formats d'API sont totalement différents.
Cet article s'appuie sur des tests réels pour analyser en profondeur les 5 différences clés entre ces deux plateformes, afin de vous aider à faire le meilleur choix.
Aperçu des deux plateformes Nano Banana Pro
Qu'est-ce que Nano Banana Pro ?
Nano Banana Pro est le nom de code interne de Google Gemini 3 Pro Image, qui est aussi la version commerciale d'Imagen 3, le grand modèle de langage spécialisé dans l'image le plus avancé de Google. Il offre les capacités suivantes :
- Sortie ultra-haute résolution 4K : supportant jusqu'à 4096×4096 pixels.
- Rendu de texte exceptionnel : les textes intégrés aux images sont clairs et lisibles.
- Photoréalisme saisissant : surpasse les générations précédentes en termes de détails, de gestion de la lumière et de fidélité des couleurs.
- Filigrane SynthID : protection des droits d'auteur via un filigrane invisible au niveau des pixels.
Différences de positionnement
| Dimension de comparaison | AI Studio (Google AI) | Vertex AI (Google Cloud) |
|---|---|---|
| Positionnement | Prototypage développeur | Déploiement production entreprise |
| Utilisateurs cibles | Développeurs solos, tests rapides | Équipes en entreprise, applications commerciales |
| Authentification | Clé API | Compte de service (SA) / OAuth |
| Limites de débit | Limites de base | Quotas élevés de niveau production |
| Licence commerciale | Non commerciale | Supportée |
| Plateformes disponibles | APIYI (apiyi.com) | APIYI (apiyi.com), GCP |
🎯 Conseil technique : Si vous avez besoin de tester les résultats sur les deux plateformes simultanément, nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com). Elle propose une interface API unifiée permettant de basculer en un clic entre les backends Vertex AI et AI Studio, ce qui facilite grandement les comparaisons rapides.
Différence clé n°1 : Qualité d'image et taille de fichier
Comparaison des données réelles
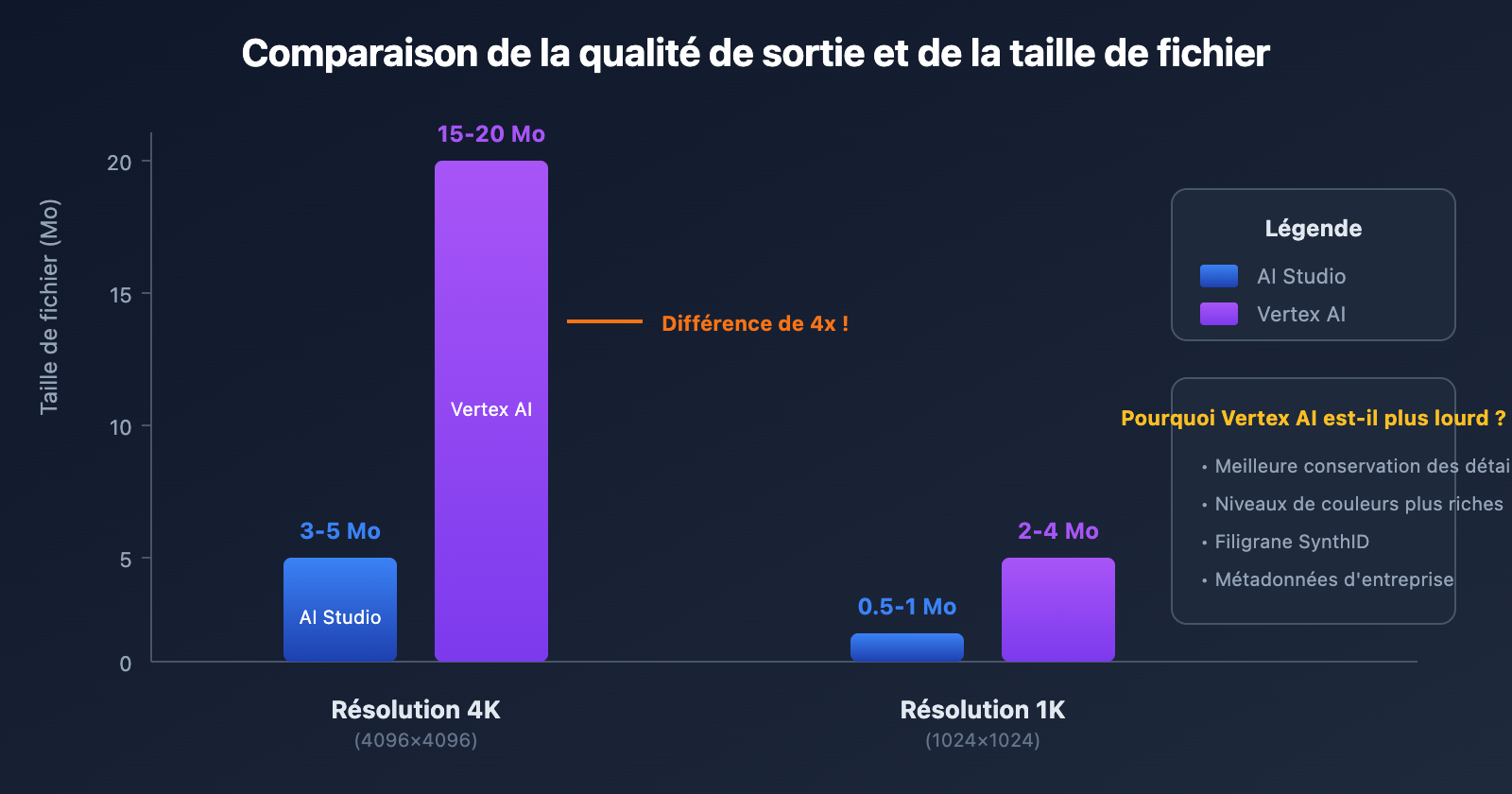
Nous avons utilisé la même invite pour générer des images en résolution 4K sur les deux plateformes. Voici les données obtenues :
| Élément de test | AI Studio | Vertex AI | Analyse de la différence |
|---|---|---|---|
| Taille de fichier image 4K | 3-5 Mo | 15-20 Mo | Vertex AI est environ 4x plus lourd |
| Taille de fichier image 1K | 0.5-1 Mo | 2-4 Mo | Vertex AI est environ 3x plus lourd |
| Format de sortie par défaut | PNG | PNG | Identique |
| Qualité de compression (JPEG) | 75 | 75 | Valeur par défaut identique |
| Profondeur de couleur | Standard | Améliorée | Plus riche sur Vertex AI |
Pourquoi les fichiers Vertex AI sont-ils plus volumineux ?
Les fichiers d'image générés par Vertex AI sont nettement plus lourds pour plusieurs raisons clés :
1. Meilleure conservation des détails
En tant que plateforme de niveau entreprise, Vertex AI conserve par défaut plus de détails dans l'image et réduit la compression avec perte. Cela signifie :
- Des dégradés de couleurs plus riches
- Des contours plus nets
- Moins d'artefacts de compression
2. Métadonnées enrichies intégrées
Les images générées par Vertex AI contiennent des métadonnées plus complètes :
- Informations de filigrane SynthID
- Enregistrement des paramètres de génération
- Marquages de conformité et de sécurité
3. Standards de qualité professionnelle
Vertex AI est optimisé pour un usage commercial, produisant par défaut des images de haute qualité adaptées à l'impression ou à l'affichage sur grand écran.
Comment contrôler la taille du fichier
Si vous avez besoin de fichiers plus légers, vous pouvez ajuster les paramètres suivants :
import requests
# Exemple d'appel Vertex AI - Contrôle de la qualité de sortie
payload = {
"instances": [
{
"prompt": "A beautiful sunset over mountains, 4K quality"
}
],
"parameters": {
"sampleCount": 1,
"aspectRatio": "1:1",
"outputOptions": {
"mimeType": "image/jpeg", # Utiliser le JPEG pour réduire la taille
"compressionQuality": 85 # Ajuster la qualité de compression (0-100)
}
}
}
💡 Optimisation des coûts : Pour des scénarios d'affichage Web, vous pouvez régler la qualité de compression entre 80 et 85. Cela permet de réduire le volume du fichier d'environ 40 % tout en préservant l'effet visuel. Ces paramètres sont également valables via la plateforme APIYI (apiyi.com).
Différence clé n°2 : Vitesse de génération et stabilité
Comparaison de la vitesse réelle
C'est la question que se posent de nombreux développeurs : Pourquoi Vertex AI semble-t-il parfois "bloqué" ?
| Indicateur de performance | AI Studio | Vertex AI | Explication |
|---|---|---|---|
| Génération d'image 1K | 2-4 sec | 5-10 sec | AI Studio est plus de 2x plus rapide |
| Génération d'image 4K | 8-15 sec | 20-40 sec | AI Studio est 2 à 3 fois plus rapide |
| Latence de première réponse | Basse | Haute | Démarrage à froid (cold start) lent sur Vertex AI |
| Taux d'expiration (Timeout) | < 1% | 3-8% | Vertex AI est moins stable |
| Performance en pic d'utilisation | Stable | Fortes fluctuations | AI Studio est plus fiable |
Pourquoi Vertex AI est-il plus lent ?
1. Contrôles de sécurité de niveau entreprise
Vertex AI effectue des audits de sécurité plus stricts pour chaque requête :
- Filtrage de sécurité du contenu
- Détection des risques liés au droit d'auteur
- Vérification de la conformité
Ces vérifications supplémentaires augmentent le temps de traitement.
2. Processus de génération de qualité supérieure
Vertex AI utilise davantage d'étapes d'inférence et un pipeline de rendu plus raffiné pour garantir une qualité de sortie professionnelle.
3. Frais de gestion des ressources
En tant que service de Google Cloud, Vertex AI nécessite une planification des ressources et un équilibrage de charge plus complexes.

Conseils d'optimisation de la vitesse
Si la vitesse est votre priorité, vous pouvez adopter les stratégies suivantes :
Utiliser le mode Imagen 3 Fast :
# Utiliser le mode Fast pour réduire la latence de 40%
payload = {
"instances": [{"prompt": "votre invite ici"}],
"parameters": {
"model": "imagen-3.0-fast-generate-001", # Version Fast
"sampleCount": 1
}
}
Réduire la résolution :
# La résolution 1K est 3 à 4 fois plus rapide que la 4K
"parameters": {
"aspectRatio": "1:1", # Par défaut 1024x1024
# Ne pas spécifier de paramètre d'upscale
}
Différence majeure n°3 : Format de l'API et paramètre role
Différence clé : Exigences du champ role
Lors de l'appel à Vertex AI, vous avez peut-être déjà rencontré cette erreur :
[&{Please use a valid role: user, model. (request id: xxx) 400 }]
Cela s'explique par le fait que Vertex AI impose le champ role, alors qu'AI Studio permet de l'omettre.
| Exigences du format API | AI Studio | Vertex AI |
|---|---|---|
| Champ role | Facultatif | Obligatoire |
| Valeurs role valides | user, model | user, model |
| Rôle system | Non supporté | Non supporté |
| Comportement si role absent | Complété automatiquement | Renvoie une erreur 400 |
Syntaxe correcte pour Vertex AI
❌ Mauvaise syntaxe (provoque une erreur 400) :
{
"contents": [
{
"parts": [{"text": "Generate an image of a cat"}]
}
]
}
✅ Syntaxe correcte :
{
"contents": [
{
"role": "user",
"parts": [{"text": "Generate an image of a cat"}]
}
]
}
Solution d'appel unifiée
Si votre code doit supporter les deux plateformes, je vous recommande d'utiliser le format compatible OpenAI :
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
# Format unifié, s'adapte automatiquement aux deux plateformes
response = client.images.generate(
model="nano-banana-pro",
prompt="A futuristic city at night, cyberpunk style",
size="1024x1024",
quality="hd"
)
print(response.data[0].url)
🚀 Démarrage rapide : Je vous conseille d'utiliser la plateforme APIYI (apiyi.com) pour monter rapidement vos prototypes. Elle gère automatiquement les différences de format entre Vertex AI et AI Studio, vous permettant de basculer d'un backend à l'autre sans modifier votre code.
Différence majeure n°4 : Authentification et quotas
Comparaison des systèmes d'authentification
| Élément d'authentification | AI Studio | Vertex AI |
|---|---|---|
| Méthode d'authentification | Clé API | Compte de service / OAuth 2.0 |
| Difficulté d'obtention | Simple, en quelques secondes | Complexe, nécessite un projet GCP |
| Gestion des clés | Clé unique | Fichier de clé JSON requis |
| Granularité des permissions | Aucune | Contrôle IAM précis |
| Journaux d'audit | Aucun | Traçabilité complète des audits |
Comparaison des limites de quotas
| Élément de quota | AI Studio | Vertex AI |
|---|---|---|
| Requêtes par minute | 60 RPM | 300+ RPM |
| Requêtes par jour | 1 500 | 10 000+ |
| Requêtes simultanées | 5 | 20+ |
| Taille max d'une image | 4K | 4K |
| Génération par lot | Jusqu'à 4 images | Jusqu'à 8 images |
Configuration de l'authentification Vertex AI
from google.oauth2 import service_account
from google import genai
# Authentification via compte de service
credentials = service_account.Credentials.from_service_account_file(
'your-service-account.json',
scopes=['https://www.googleapis.com/auth/cloud-platform']
)
client = genai.Client(
vertexai=True,
project="your-project-id",
location="us-central1",
credentials=credentials
)
Configuration de l'authentification AI Studio
import google.generativeai as genai
# Authentification simple par clé API
genai.configure(api_key="YOUR_API_KEY")
model = genai.ImageGenerationModel("imagen-3.0-generate-001")
response = model.generate_images(prompt="Votre invite ici")
Différence clé n°5 : Cas d'usage et coûts
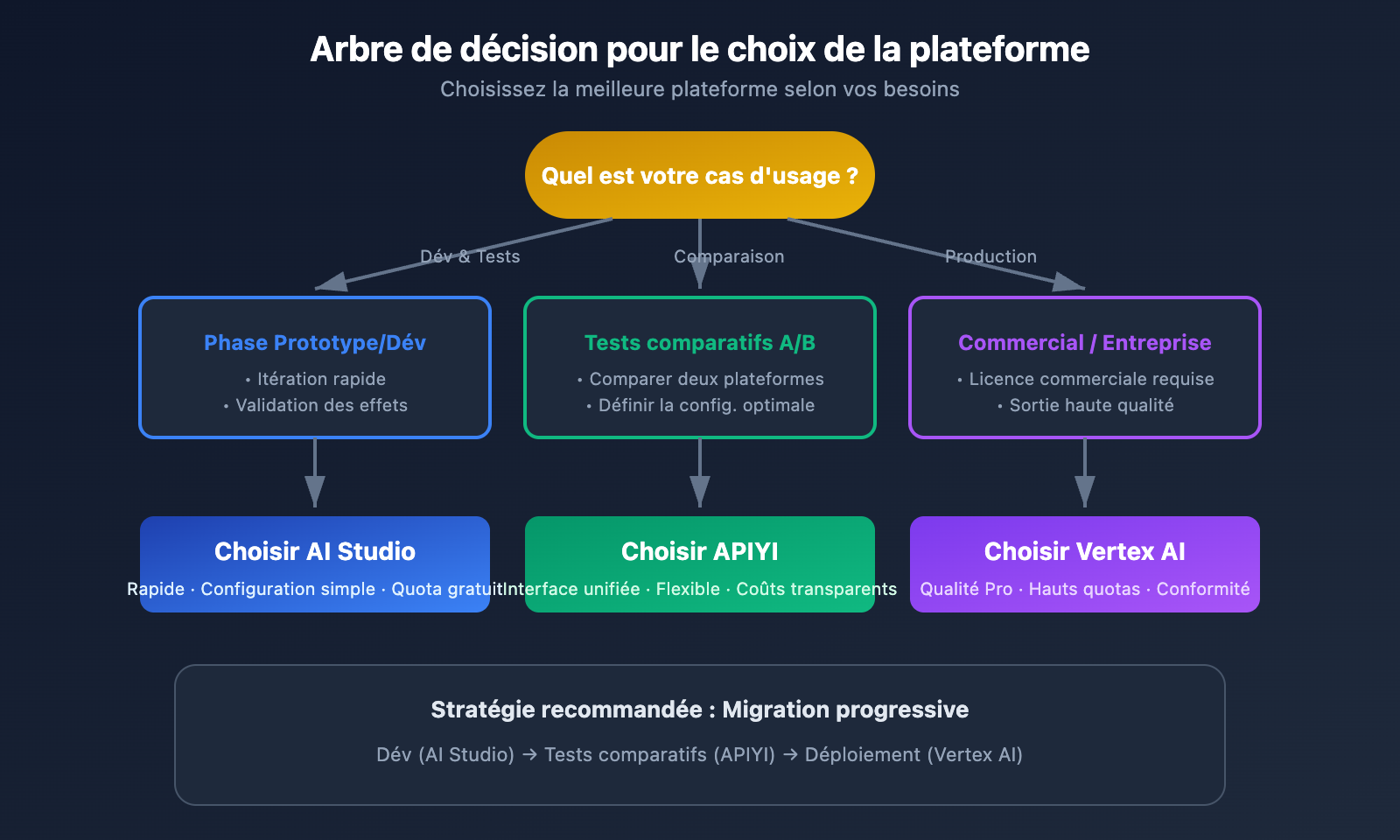
Matrice de recommandation des scénarios
| Cas d'usage | Plateforme recommandée | Raison |
|---|---|---|
| Validation rapide de prototype | AI Studio | Rapidité, configuration simple |
| Tests de projets personnels | AI Studio | Quotas gratuits généreux |
| Lancement de produit commercial | Vertex AI | Licence commerciale, quotas élevés |
| Photos de produits e-commerce | Vertex AI | Haute qualité, fichiers volumineux |
| Images pour réseaux sociaux | AI Studio | Vitesse prioritaire, qualité moyenne |
| Supports d'impression | Vertex AI | 4K HD, détails riches |
| Génération d'images par lots | Vertex AI | Haute concurrence, quotas stables |
| Comparaison et tests A/B | APIYI (apiyi.com) | Interface unifiée, basculement flexible |
Comparaison des coûts
| Élément de coût | AI Studio | Vertex AI |
|---|---|---|
| Prix unitaire image 1K | 0 $ (quota gratuit) | 0,02 $ – 0,04 $ |
| Prix unitaire image 4K | 0 $ (quota gratuit) | 0,04 $ – 0,08 $ |
| Quota gratuit mensuel | Limité | Offert aux nouveaux utilisateurs |
| Remise entreprise | Aucune | Négociable |
| Paiement à l'usage | Post-paiement après dépassement | Tarification standard |
Stratégies d'optimisation des coûts
1. Utiliser AI Studio pendant la phase de développement :
- Profiter du quota gratuit pour le débogage
- Faire itérer rapidement vos invites
- Valider la faisabilité technique
2. Utiliser Vertex AI pour l'environnement de production :
- Obtenir la licence commerciale nécessaire
- Garantir la stabilité avec des quotas élevés
- Assurer la sécurité et la conformité de niveau entreprise
3. Utiliser APIYI pour une solution flexible :
- Réduire les coûts de développement grâce à une API unique
- Basculer entre les backends selon vos besoins
- Garder des coûts transparents et maîtrisés
💰 Optimisation des coûts : Pour les projets sensibles au budget, vous pouvez envisager d'appeler les API via la plateforme APIYI (apiyi.com). Elle propose des modes de facturation flexibles et permet de basculer entre les backends AI Studio et Vertex AI selon les besoins, ce qui est idéal pour les petites et moyennes équipes ainsi que pour les développeurs indépendants.
Solutions aux problèmes courants
Problème 1 : Erreur role 400 sur Vertex AI
Message d'erreur :
Please use a valid role: user, model. (request id: xxx) 400
Solution :
Ajoutez "role": "user" à chaque objet du tableau contents :
{
"contents": [
{
+ "role": "user",
"parts": [{"text": "Generate an image..."}]
}
]
}
Problème 2 : Délai d'attente dépassé (timeout) sur Vertex AI
Symptômes : La requête ne répond pas pendant une longue période et finit par expirer.
Solution :
- Utiliser le mode Fast : Passez au modèle
imagen-3.0-fast-generate-001. - Réduire la résolution : Générez d'abord en 1K, puis utilisez l'API d'upscale pour agrandir l'image.
- Ajouter une logique de retry :
import time
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
def generate_image_with_retry(prompt):
return client.images.generate(
model="nano-banana-pro",
prompt=prompt,
timeout=60
)
Problème 3 : Quota insuffisant sur AI Studio
Message d'erreur : RESOURCE_EXHAUSTED: Quota exceeded
Solution :
- Attendre la réinitialisation du quota : Généralement, le quota est réinitialisé par minute ou par jour.
- Utiliser plusieurs clés API : Répartissez la charge des requêtes.
- Passer à Vertex AI : Pour obtenir des quotas plus élevés.
- Utiliser la plateforme APIYI : Obtenez des quotas stables via apiyi.com.
Problème 4 : Fichier image trop volumineux
Contexte : Les images 4K générées par Vertex AI peuvent atteindre 18 Mo, ce qui rend leur téléchargement difficile.
Solution :
from PIL import Image
import io
# Compression en post-traitement
def compress_image(image_bytes, target_quality=85):
img = Image.open(io.BytesIO(image_bytes))
output = io.BytesIO()
img.save(output, format='JPEG', quality=target_quality, optimize=True)
return output.getvalue()
# Ou spécifier directement lors de la requête API
"outputOptions": {
"mimeType": "image/jpeg",
"compressionQuality": 80
}
Meilleures pratiques : Stratégie d'utilisation hybride
Flux de développement recommandé
┌─────────────────────────────────────────────────────────┐
│ Phase de développement │
│ Utiliser AI Studio │
│ - Itération rapide sur les invites │
│ - Validation du rendu et du style │
│ - Tests à coût nul │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ Phase de pré-lancement │
│ Utiliser la plateforme APIYI │
│ - Tests d'interface unifiée │
│ - Comparaison A/B entre les deux plateformes │
│ - Détermination de la configuration finale │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ Phase de production │
│ Utiliser Vertex AI │
│ - Garantie de licence commerciale │
│ - Fonctionnement stable avec des quotas élevés │
│ - Sécurité et conformité de niveau entreprise │
└─────────────────────────────────────────────────────────┘
Exemple de code : Sélection automatique du meilleur backend
import openai
class NanoBananaProClient:
def __init__(self, api_key, prefer_quality=False):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
self.prefer_quality = prefer_quality
def generate(self, prompt, size="1024x1024"):
# Sélection automatique du backend selon les besoins
if self.prefer_quality:
model = "nano-banana-pro-vertex" # Backend Vertex AI
quality = "hd"
else:
model = "nano-banana-pro" # Backend AI Studio
quality = "standard"
return self.client.images.generate(
model=model,
prompt=prompt,
size=size,
quality=quality
)
# Exemple d'utilisation
client = NanoBananaProClient(
api_key="VOTRE_CLÉ_APIYI",
prefer_quality=True # Choix de Vertex AI pour une haute qualité
)
response = client.generate("Une photo professionnelle d'une montre de luxe")
FAQ (Foire Aux Questions)
Q1 : Dois-je choisir Vertex AI ou AI Studio ?
Cela dépend de vos besoins spécifiques :
- Choisir AI Studio : Projets personnels, prototypage rapide, budget limité, besoin de rapidité.
- Choisir Vertex AI : Usage commercial, besoin d'une sortie de haute qualité, exigences de sécurité de niveau entreprise.
Grâce à la plateforme APIYI (apiyi.com), vous pouvez basculer de manière flexible entre les deux backends, ce qui facilite les tests comparatifs avant de prendre une décision.
Q2 : Pourquoi les fichiers images de Vertex AI sont-ils si volumineux ?
Vertex AI génère par défaut des images de qualité professionnelle ("Enterprise-grade"), préservant davantage de détails et d'informations colorimétriques. Vous pouvez réduire la taille des fichiers en configurant mimeType: "image/jpeg" et en abaissant la valeur de compressionQuality.
Q3 : AI Studio peut-il être utilisé pour des projets commerciaux ?
Ce n'est pas recommandé. AI Studio est principalement positionné pour le développement et les tests. Ses conditions d'utilisation ne garantissent pas la stabilité ni la conformité nécessaires à un usage commercial. Pour vos projets professionnels, il est préférable d'utiliser Vertex AI ou de passer par APIYI (apiyi.com) pour obtenir des interfaces avec licence commerciale.
Q4 : Comment résoudre les problèmes de latence sur Vertex AI ?
- Utilisez la version rapide
imagen-3.0-fast-generate-001. - Générez d'abord une image en basse résolution, puis utilisez l'API d'upscale (mise à l'échelle).
- Mettez en place une file d'attente de requêtes et un traitement asynchrone.
- Envisagez un déploiement multi-régions pour répartir la charge.
Q5 : La différence de qualité d'image est-elle flagrante entre les deux plateformes ?
À paramètres identiques, la différence de qualité se manifeste principalement sur :
- Vertex AI : Des détails plus riches, une meilleure gestion des dégradés de couleurs et moins d'artéfacts de compression.
- AI Studio : Une bonne qualité globale, mais les détails sont légèrement en retrait lorsqu'on zoome sur l'image.
Pour un affichage Web, la différence est peu perceptible ; pour l'impression, Vertex AI est vivement recommandé.
Résumé
Les différences de Nano Banana Pro entre les plateformes Vertex AI et AI Studio peuvent se résumer ainsi :
| Dimension de différence | AI Studio | Vertex AI |
|---|---|---|
| Vitesse | ⚡ 2 à 3 fois plus rapide | 🐢 Plus lent mais stable |
| Qualité | Bonne | ⭐ Haute qualité (Entreprise) |
| Taille de fichier | Petite (3-5 Mo) | Grande (15-20 Mo) |
| Format API | Souple | Strict (role obligatoire) |
| Scénario idéal | Développement et tests | Production commerciale |
Conseils clés :
- Phase de développement : Utilisez AI Studio pour itérer rapidement.
- Tests comparatifs : Passez par l'interface unifiée d'APIYI (apiyi.com) pour comparer facilement les deux plateformes.
- Déploiement en production : Basculez sur Vertex AI pour garantir la conformité commerciale.
- Attention au champ
role: Les appels API vers Vertex AI doivent impérativement inclure"role": "user".
Nous vous recommandons d'utiliser APIYI (apiyi.com) pour valider rapidement vos résultats. La plateforme propose une interface d'appel unifiée et une gestion flexible du backend, vous permettant de vous concentrer sur le développement de votre logique métier.
Lectures complémentaires :
- Documentation officielle Imagen 3 : cloud.google.com/vertex-ai/generative-ai/docs/image/overview
- Guide de développement Vertex AI : cloud.google.com/blog/products/ai-machine-learning/a-developers-guide-to-imagen-3-on-vertex-ai
- API d'upscaling d'image : cloud.google.com/vertex-ai/generative-ai/docs/image/upscale-image
📝 Auteur : Équipe technique APIYI | Spécialistes de l'intégration et de l'optimisation des API de génération d'images par IA.
🔗 Échanges techniques : Visitez APIYI (apiyi.com) pour obtenir des crédits de test Nano Banana Pro et un support technique.