Nota del autor: Análisis profundo de la capacidad de estructuración de texto del Modelo de Lenguaje Grande GLM-4.7. Aprende técnicas prácticas para extraer información clave en formato JSON de documentos complejos como contratos e informes.
Extraer rápidamente información clave de grandes volúmenes de texto no estructurado es un desafío central en el procesamiento de datos empresariales. El Modelo de Lenguaje Grande GLM-4.7, lanzado por Zhipu AI en diciembre de 2025, ofrece una solución innovadora gracias a su soporte nativo para JSON Schema y su ventana de contexto ultra larga de 200K.
Valor principal: Al terminar de leer este artículo, habrás aprendido a usar GLM-4.7 para extraer datos estructurados de documentos complejos como contratos e informes, logrando un aumento exponencial en la eficiencia del procesamiento de documentos.

Puntos clave de la estructuración de texto con GLM-4.7
| Punto clave | Descripción | Valor |
|---|---|---|
| JSON Schema nativo | Soporte incorporado para salida estructurada, sin necesidad de una ingeniería de indicaciones compleja. | Mejora de la precisión de extracción en más del 40%. |
| Ventana de contexto de 200K | Permite la entrada de documentos largos completos sin necesidad de segmentarlos. | Procesa contratos o informes íntegros de una sola vez. |
| Capacidad de salida de 128K | Puede generar resultados estructurados extremadamente largos. | Ideal para la extracción de información masiva. |
| Soporte para llamada a funciones | Capacidad nativa de Tool Calling. | Integración fluida con sistemas de negocio. |
| Ventaja en costos | $0.10/M de tokens, entre 4 y 7 veces más económico que modelos de su categoría. | Costos de implementación a gran escala totalmente controlados. |
Detalles clave de la estructuración de texto en GLM-4.7
GLM-4.7 es el Modelo de Lenguaje Grande insignia de nueva generación lanzado por Zhipu AI el 22 de diciembre de 2025. Este modelo emplea una arquitectura Mixture-of-Experts (MoE) con un total aproximado de 358B de parámetros, logrando una inferencia eficiente mediante un mecanismo de activación dispersa. En lo que respecta al procesamiento de estructuración de texto, GLM-4.7 representa un salto cualitativo frente a la versión GLM-4.6, con una mejora del 38% en el benchmark HLE, alcanzando un 42.8%, lo que lo sitúa al nivel de GPT-5.1 High.
La capacidad de salida estructurada de GLM-4.7 se fundamenta en tres dimensiones. En primer lugar, el Pensamiento Intercalado (Interleaved Thinking): el modelo planifica automáticamente la ruta de razonamiento antes de cada salida, asegurando la coherencia en la lógica de extracción. En segundo lugar, el Pensamiento Preservado (Preserved Thinking), que mantiene el razonamiento del contexto a través de diálogos de múltiples turnos, lo que resulta ideal para tareas de extracción de información iterativas y complejas. Por último, el Control a Nivel de Turno (Turn-level Control) permite ajustar dinámicamente la profundidad del razonamiento en cada solicitud, logrando un equilibrio flexible entre velocidad y precisión.
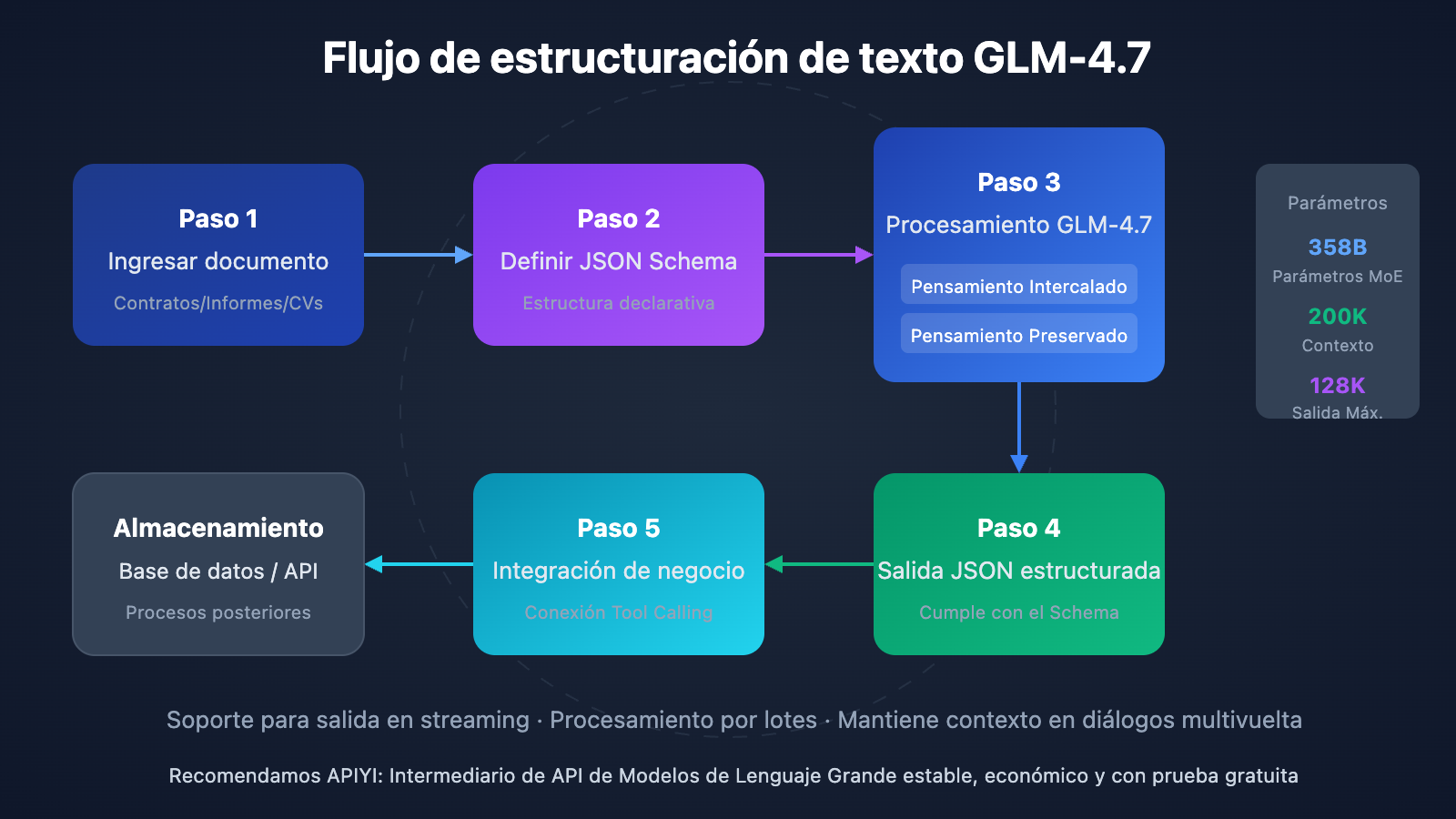
Guía rápida de estructuración de texto con GLM-4.7
Ejemplo minimalista
Aquí tienes la forma más sencilla de usarlo: con solo 10 líneas de código puedes completar la extracción estructurada de texto:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "从以下合同中提取:甲方、乙方、金额、日期。合同内容:甲方:北京科技有限公司,乙方:上海创新科技,合同金额:人民币伍拾万元整,签订日期:2025年12月15日"}],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
Ver código de implementación completo (incluye restricciones de JSON Schema)
import openai
from typing import Optional, Dict, Any
def extract_contract_info(
contract_text: str,
api_key: str = "YOUR_API_KEY",
base_url: str = "https://vip.apiyi.com/v1"
) -> Dict[str, Any]:
"""
使用 GLM-4.7 从合同文本中提取结构化信息
Args:
contract_text: 合同原文内容
api_key: API密钥
base_url: API基础地址
Returns:
包含提取信息的字典
"""
client = openai.OpenAI(api_key=api_key, base_url=base_url)
# 定义 JSON Schema 约束输出格式
json_schema = {
"name": "contract_extraction",
"schema": {
"type": "object",
"properties": {
"party_a": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "甲方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"party_b": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "乙方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"contract_amount": {
"type": "object",
"properties": {
"value": {"type": "number", "description": "金额数值"},
"currency": {"type": "string", "description": "货币单位"},
"text": {"type": "string", "description": "金额大写"}
},
"required": ["value", "currency"]
},
"dates": {
"type": "object",
"properties": {
"sign_date": {"type": "string", "description": "签订日期"},
"effective_date": {"type": "string", "description": "生效日期"},
"expiry_date": {"type": "string", "description": "到期日期"}
}
},
"key_terms": {
"type": "array",
"items": {"type": "string"},
"description": "关键条款摘要"
}
},
"required": ["party_a", "party_b", "contract_amount"]
}
}
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{
"role": "system",
"content": "你是专业的合同分析专家,请从合同文本中准确提取关键信息。"
},
{
"role": "user",
"content": f"请从以下合同中提取关键信息:\n\n{contract_text}"
}
],
response_format={
"type": "json_schema",
"json_schema": json_schema
},
max_tokens=4000
)
import json
return json.loads(response.choices[0].message.content)
# 使用示例
contract = """
采购合同
甲方:北京智谱科技有限公司
法定代表人:张三
地址:北京市海淀区中关村大街1号
乙方:上海创新科技集团
法定代表人:李四
地址:上海市浦东新区张江路100号
合同金额:人民币伍拾万元整(¥500,000.00)
签订日期:2025年12月15日
合同有效期:2025年12月15日至2026年12月14日
主要条款:
1. 乙方向甲方提供AI模型API服务
2. 付款方式为季度预付
3. 服务可用性保证99.9%
"""
result = extract_contract_info(contract)
print(result)
Sugerencia: Obtén cuotas de prueba gratuitas a través de APIYI (apiyi.com) para verificar rápidamente la efectividad de la estructuración de texto de GLM-4.7. La plataforma admite llamadas mediante una interfaz unificada para múltiples modelos principales, lo que facilita comparar la precisión de extracción de GLM-4.7 con otros modelos.
Escenarios de aplicación para la estructuración de texto con GLM-4.7
La capacidad de estructuración de texto de GLM-4.7 es aplicable a diversos escenarios empresariales:
| Escenario | Datos de entrada | Formato de salida | Mejora de eficiencia típica |
|---|---|---|---|
| Extracción de contratos | Contratos en PDF/Word | Datos estructurados JSON | De varias horas → minutos |
| Análisis de informes financieros | Reportes anuales/trimestrales | Tablas de indicadores financieros | Precisión 95%+ |
| Filtrado de currículums | Texto de currículums | Perfil del candidato en JSON | Eficiencia de filtrado 10x |
| Monitoreo de opinión pública | Noticias/Contenido social | Grafos de relaciones de entidades | Capacidad de procesamiento en tiempo real |
| Interpretación de informes | Informes de investigación industrial | Extracción de puntos clave | Aumento de cobertura 5x |
Ventajas técnicas de la estructuración de texto con GLM-4.7
1. Soporte nativo para JSON Schema
Al igual que los modelos de la serie GPT, GLM-4.7 permite especificar directamente un JSON Schema en el campo response_format. El modelo seguirá estrictamente la estructura definida para generar los resultados. Esto significa que no necesitas redactar indicaciones complejas para "convencer" al modelo de que use un formato específico; simplemente defines la estructura deseada de forma declarativa.
2. Procesamiento de contexto ultralargo
Con una ventana de contexto de 200K tokens, GLM-4.7 puede procesar de una sola vez documentos de aproximadamente 150,000 caracteres chinos, lo que equivale a un contrato completo o a un manual de especificaciones técnicas. Esto evita la complejidad de fragmentar documentos largos y luego fusionar los resultados, reduciendo el riesgo de pérdida de información y rupturas de contexto.
3. Pensamiento entrelazado para mayor precisión
Al manejar tareas de extracción complejas, el modo de pensamiento entrelazado de GLM-4.7 realiza automáticamente múltiples pasos de razonamiento antes de generar la salida. Por ejemplo, al extraer el monto de un contrato, el modelo primero identifica los párrafos relacionados con dinero, luego realiza una validación cruzada entre las cifras numéricas y el texto escrito, y finalmente entrega el resultado con mayor nivel de confianza.
Sugerencia práctica: Recomendamos realizar pruebas reales a través de la plataforma APIYI (apiyi.com) para evaluar el desempeño de GLM-4.7 en tus casos de uso específicos. La plataforma ofrece cuotas gratuitas y registros de llamadas detallados para facilitar la depuración y optimización.

Comparativa de soluciones: Estructuración de texto con GLM-4.7
| Solución | Características clave | Escenarios de aplicación | Rendimiento |
|---|---|---|---|
| GLM-4.7 | JSON Schema nativo, contexto de 200K, bajo costo | Extracción de documentos largos, procesamiento a gran escala, sensibilidad al costo | HLE 42.8%, SWE-bench 73.8% |
| GPT-5.1 | Salida estable, ecosistema maduro, rápida velocidad de respuesta | Requisitos de alta fiabilidad, escenarios de entrega rápida | HLE 42.7%, tiempo de respuesta óptimo |
| Claude Sonnet 4.5 | Fuerte razonamiento lógico, comprensión profunda del contexto | Tareas de análisis complejo, razonamiento de múltiples pasos | HLE 32.0%, excelente profundidad de razonamiento |
| DeepSeek-V3 | Código abierto y desplegable, alta relación calidad-precio | Despliegue privado, necesidades personalizadas | Excelente desempeño en benchmarks |
Diferencias clave entre GLM-4.7 y la competencia
| Dimensión de comparación | GLM-4.7 | GPT-5.1 | Claude Sonnet 4.5 |
|---|---|---|---|
| Estado de código abierto | Código abierto (Apache 2.0) | Código cerrado | Código cerrado |
| Precio (/M tokens) | $0.10 | ~$0.50 | ~$0.40 |
| Ventana de contexto | 200K | 128K | 200K |
| Salida máxima | 128K | 16K | 8K |
| Optimización para chino | Fuerte | Normal | Normal |
| Despliegue local | Compatible | No compatible | No compatible |
Sugerencias de elección:
- Si necesitas procesar una gran cantidad de documentos en chino y eres sensible a los costos, GLM-4.7 es la mejor opción.
- Si buscas estabilidad en los resultados y facilidad de integración con el ecosistema, GPT-5.1 es más maduro.
- Si la tarea implica un razonamiento complejo de varios pasos, la capacidad lógica de Claude Sonnet 4.5 es superior.
Nota sobre la comparativa: Los datos anteriores provienen de benchmarks públicos como HLE y SWE-bench, y pueden verificarse mediante pruebas reales en la plataforma APIYI (apiyi.com). La plataforma permite realizar llamadas a todos los modelos mencionados a través de una interfaz unificada.
Técnicas avanzadas de estructuración de texto con GLM-4.7
Procesamiento de documentos por lotes
Para tareas de estructuración de grandes volúmenes de documentos, puedes aprovechar la salida en streaming y las capacidades de concurrencia de GLM-4.7:
import asyncio
import aiohttp
async def batch_extract(documents: list, api_key: str):
"""Extracción asíncrona de información de documentos por lotes"""
async with aiohttp.ClientSession() as session:
tasks = [
extract_single(session, doc, api_key)
for doc in documents
]
results = await asyncio.gather(*tasks)
return results
Integración con Function Calling
La capacidad de Tool Calling de GLM-4.7 permite conectar los resultados de la extracción directamente con tus sistemas de negocio:
tools = [
{
"type": "function",
"function": {
"name": "save_contract_to_database",
"description": "Guarda la información extraída del contrato en la base de datos",
"parameters": {
"type": "object",
"properties": {
"contract_id": {"type": "string"},
"party_a": {"type": "string"},
"party_b": {"type": "string"},
"amount": {"type": "number"}
},
"required": ["contract_id", "party_a", "party_b", "amount"]
}
}
}
]
Preguntas frecuentes
Q1: ¿Qué tan precisa es la extracción estructurada de texto con GLM-4.7?
En escenarios como contratos estándar, currículums e informes financieros, la precisión de la extracción de GLM-4.7, cuando se utiliza con restricciones JSON Schema, puede superar el 95%. Para documentos complejos, se recomienda integrar un mecanismo de revisión humana. El modo de pensamiento entrelazado del modelo realiza automáticamente una verificación de varios pasos, lo que mejora aún más la exactitud.
Q2: ¿Qué limitaciones tiene GLM-4.7 al procesar documentos largos?
GLM-4.7 soporta una ventana de contexto de 200K tokens, lo que equivale aproximadamente a 150,000 caracteres chinos. Para documentos extremadamente largos, sugerimos dividir el contenido por capítulos lógicos o utilizar las herramientas de segmentación de documentos largos que ofrece la plataforma APIYI. La salida máxima por petición es de 128K tokens, suficiente para cubrir la gran mayoría de las necesidades de extracción estructurada.
Q3: ¿Cómo puedo empezar a probar rápidamente las capacidades de estructuración de texto de GLM-4.7?
Te recomendamos utilizar una plataforma de agregación de APIs que soporte múltiples modelos para tus pruebas:
- Visita APIYI (apiyi.com) y registra una cuenta.
- Obtén tu API Key y el saldo gratuito.
- Utiliza los ejemplos de código de este artículo para realizar una validación rápida.
- Compara el rendimiento de diferentes modelos en tus escenarios de negocio específicos.
Resumen
Puntos clave de la estructuración de texto con GLM-4.7:
- Soporte estructurado nativo: Salida restringida mediante JSON Schema, sin necesidad de una ingeniería de indicaciones compleja.
- Capacidad de contexto ultra largo: Ventana de 200K tokens para procesar documentos largos completos en un solo paso.
- Excelente relación costo-beneficio: El precio es solo entre 1/4 y 1/7 del de otros modelos de su misma categoría, ideal para despliegues a gran escala.
- Optimización para escenarios en chino: Al ser un modelo de origen chino, comprende con mayor precisión contratos, informes y otros documentos en este idioma.
Como el modelo insignia de Zhipu AI, GLM-4.7 ha demostrado capacidades a la par de GPT-5.1 en el ámbito de la estructuración de texto, ofreciendo además las ventajas únicas de ser código abierto, tener bajo costo y estar optimizado para el chino. Para empresas con grandes volúmenes de procesamiento de documentos, GLM-4.7 es una opción que merece una evaluación seria.
Te recomendamos verificar los resultados rápidamente a través de APIYI (apiyi.com). La plataforma ofrece cuotas gratuitas y una interfaz unificada para múltiples modelos, lo que facilita las pruebas en escenarios reales.
Recursos de referencia
⚠️ Nota sobre el formato de los enlaces: Todos los enlaces externos utilizan el formato
Nombre del recurso: dominio.com. Esto facilita su copia pero evita que sean clicables, previniendo así la pérdida de autoridad SEO.
-
Documentación oficial de GLM-4.7: Documentación para desarrolladores de Zhipu AI
- Enlace:
docs.z.ai/guides/llm/glm-4.7 - Descripción: Incluye la explicación completa de los parámetros de la API y las mejores prácticas.
- Enlace:
-
Análisis técnico de GLM-4.7: Análisis profundo de la arquitectura y capacidades del modelo
- Enlace:
medium.com/@leucopsis/a-technical-analysis-of-glm-4-7-db7fcc54210a - Descripción: Evaluación técnica de terceros que incluye una comparativa de datos de referencia (benchmarks).
- Enlace:
-
Página del modelo en Hugging Face: Descarga de pesos de código abierto
- Enlace:
huggingface.co/zai-org/GLM-4.7 - Descripción: Proporciona los archivos del modelo necesarios para el despliegue local y guías de implementación.
- Enlace:
-
OpenRouter GLM-4.7: Acceso a la API a través de múltiples canales
- Enlace:
openrouter.ai/z-ai/glm-4.7 - Descripción: Ofrece opciones de acceso de varios proveedores y comparativas de precios.
- Enlace:
Autor: Equipo técnico
Intercambio técnico: Te invitamos a compartir tus experiencias sobre el uso de GLM-4.7 para la estructuración de texto en la sección de comentarios. Para más materiales, puedes visitar la comunidad técnica de APIYI en apiyi.com.