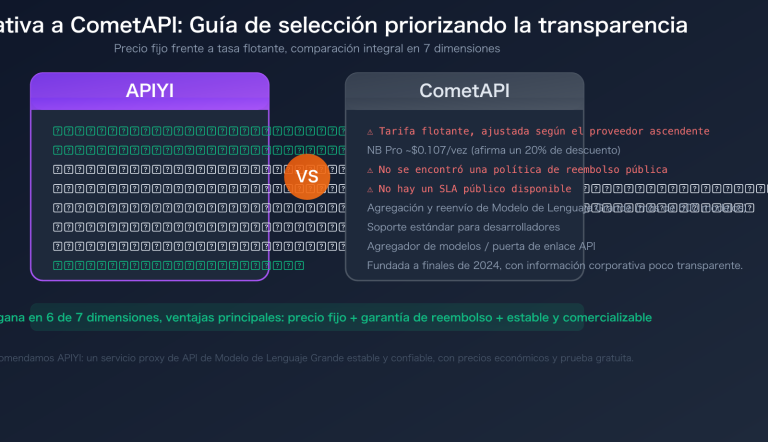
Nota del autor: El modelo gpt-5.4-nano de OpenAI, el más económico con un costo de solo $0.20/$1.25, iguala al modelo mini con un 92.5% en τ2-Bench. Este artículo detalla los 7 escenarios de aplicación ideales para nano, cuándo sustituirlo por mini y cómo optimizar costos con un descuento del 90% mediante caché.
Si tu aplicación realiza más de 10,000 invocaciones diarias, o si estás seleccionando modelos para tareas de alto rendimiento como atención al cliente, clasificación o enrutamiento RAG, habrás notado que OpenAI ha llevado el "precio base" de la serie GPT-5.4 a un nuevo mínimo: gpt-5.4-nano, $0.20 entrada / $1.25 salida por 1M de tokens, siendo la entrada 3.75 veces más barata que el 5.4-mini.
Esto no es simplemente un "modelo barato recortado". Los benchmarks publicados por OpenAI muestran que nano alcanza un 92.5% en invocación de herramientas (τ2-Bench), casi igualando el 93.4% de mini; y obtiene un 82.8% en preguntas de conocimiento general (GPQA Diamond), solo 5.2 puntos porcentuales por debajo de mini. Esto significa que, para una gran cantidad de escenarios de "alto rendimiento + baja complejidad", nano es la verdadera solución óptima.
Valor central: Este artículo analiza 7 escenarios de aplicación específicos, detallando en qué tareas nano es "suficiente y más barato", en cuáles es "obligatorio usar mini", y proporciona fragmentos de código y estimaciones de costos para cada caso.

Puntos clave de los escenarios de aplicación de GPT-5.4 nano
| Punto | Descripción | Valor |
|---|---|---|
| Precio ultra bajo | $0.20 / $1.25 por 1M de tokens | 3.75x más barato que 5.4-mini |
| Caché -90% | Entrada en caché solo $0.02 / 1M | Casi gratis para contextos frecuentes |
| Invocación de herramientas | τ2-Bench 92.5% vs mini 93.4% | Suficiente para la mayoría de casos |
| QA de conocimiento | GPQA Diamond 82.8% | Capaz en FAQ y recuperación |
| Ventana de contexto 400K | Entrada 400K + Salida 128K | Procesamiento masivo de documentos |
| Velocidad líder | ~200 t/s, 10% más rápido que mini | Ideal para alta concurrencia |
Cómo determinar el "umbral de suficiencia" de GPT-5.4 nano
Para determinar si nano es suficiente, puedes usar una "clasificación de tres zonas":
Zona verde (usa nano con confianza): Invocación de herramientas, extracción estructurada, clasificación y etiquetado, preguntas y respuestas, enrutamiento de contenido, traducción/resumen por lotes. En estas tareas, la diferencia de rendimiento entre nano y mini es < 10 puntos porcentuales, y la ventaja de precio supera con creces la brecha de capacidad.
Zona amarilla (evalúa con precaución): Razonamiento complejo de varios pasos, orquestación de agentes de cadena larga, generación de código. Aunque SWE-Bench Pro con 52.4% sigue siendo capaz, se recomienda realizar una prueba A/B con nano antes de decidir.
Zona roja (usa mini directamente): Computer Use (nano en OSWorld solo 39%), tareas largas de terminal (46.3% es débil), escenarios personalizados que requieren ajuste fino (Fine-tuning). En estos casos, el rendimiento de nano es claramente insuficiente; elige mini o la versión estándar.

Escenario de aplicación 1 de GPT-5.4 nano: Clasificación en tiempo real
Descripción del escenario
La clasificación en tiempo real es la aplicación más clásica de nano, incluyendo análisis de sentimiento, reconocimiento de intención, etiquetado de temas, marcado de moderación de contenido, etc. Estas tareas suelen requerir solo unos pocos cientos de tokens de entrada y unas pocas decenas de tokens de salida por cada invocación del modelo, siendo extremadamente sensibles a la latencia y al costo.
Ejemplo de código minimalista
import openai
import json
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def classify_intent(user_query: str) -> dict:
"""Clasifica la intención de la consulta del usuario"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": "Eres un clasificador de intenciones. Devuelve en formato JSON: {intent, confidence, sub_category}"},
{"role": "user", "content": user_query}
],
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
# Uso
result = classify_intent("Quiero cancelar mi pedido de la semana pasada")
# {"intent": "refund_request", "confidence": 0.95, "sub_category": "subscription_cancel"}
Estimación de costos
| Escala del escenario | Costo por vez | Costo diario (100,000 veces) |
|---|---|---|
| Atención al cliente básica(50 entrada + 20 salida) | $0.000035 | $3.5 |
| SaaS mediano(200 entrada + 30 salida) | $0.000078 | $7.8 |
| Nivel empresarial(500 entrada + 50 salida) | $0.000163 | $16.3 |
💡 Sugerencia de optimización: Coloca las etiquetas de clasificación y los ejemplos en la indicación del sistema (system prompt). Al habilitar el caché, el costo de entrada puede reducirse hasta en un 90%. Al realizar la invocación del modelo a través de APIYI (apiyi.com), los descuentos por caché están totalmente sincronizados.
Escenario de aplicación 2 de GPT-5.4 nano: Extracción de datos
Descripción del escenario
Extraer campos estructurados de texto no estructurado (currículums, contratos, noticias, correos electrónicos). Este es el punto fuerte de nano; al combinarlo con Structured Outputs (restricciones estrictas de JSON Schema), se puede lograr una tasa de precisión de formato superior al 99%.
Código práctico
from pydantic import BaseModel
from typing import Optional
class ContactInfo(BaseModel):
name: str
email: Optional[str]
phone: Optional[str]
company: Optional[str]
role: Optional[str]
def extract_contact(text: str) -> ContactInfo:
response = client.beta.chat.completions.parse(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": "Extrae la información de contacto, devuelve null para los campos faltantes"},
{"role": "user", "content": text}
],
response_format=ContactInfo
)
return response.choices[0].message.parsed
Lista de tareas de extracción adecuadas para nano
- Extracción de campos clave de currículums/CV
- Reconocimiento numérico de facturas/recibos
- Análisis de bloques de firma en correos electrónicos
- Reconocimiento de entidades en noticias (nombres de personas, lugares, organizaciones)
- Normalización de datos de formularios
- Clasificación de eventos de registro (logs)
Caso de uso 3 de GPT-5.4 nano: Clasificación de contenido
Descripción del escenario
Se utiliza para reordenar resultados de búsqueda, listas de recomendaciones y colas de mensajes. El bajo costo de la versión nano hace que utilizar un Modelo de Lenguaje Grande como reranker sea económicamente viable en entornos de producción.
Ejemplo de código para reordenamiento
def rerank_documents(query: str, candidates: list[str], top_k: int = 5) -> list:
"""Reordena los documentos candidatos según su relevancia con la consulta"""
docs_text = "\n".join([f"[{i}] {doc[:300]}" for i, doc in enumerate(candidates)])
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[{
"role": "user",
"content": f"""Ordena los siguientes documentos según su relevancia para la consulta "{query}".
Documentos:
{docs_text}
Devuelve un JSON: {{"ranking": [lista de índices de documentos, del más relevante al menos relevante]}}"""
}],
response_format={"type": "json_object"}
)
ranking = json.loads(response.choices[0].message.content)["ranking"]
return [candidates[i] for i in ranking[:top_k]]
🎯 Sugerencia de escenario: El reordenamiento con nano ofrece una mayor precisión que los rerankers tradicionales basados en BM25 + búsqueda vectorial, pero con un costo que es solo el 27% del de GPT-5.4-mini. Puedes acceder directamente a través de APIYI (apiyi.com); el grupo predeterminado no requiere ninguna solicitud previa.
Caso de uso 4 de GPT-5.4 nano: Capa de ejecución de Sub-agentes
Descripción del escenario
En arquitecturas multi-agente, el Agente principal (normalmente una versión mini o estándar) se encarga de la planificación, mientras que los Sub-agentes (trabajadores de ejecución) se ocupan de la invocación de herramientas, consultas de datos y actualizaciones de estado. La puntuación del 92.5% de nano en τ2-Bench lo hace perfectamente capaz de desempeñar el rol de trabajador.
Ejemplo de colaboración multi-agente
def execute_subtask(task: dict, available_tools: list) -> dict:
"""nano actúa como Sub-agente para ejecutar una subtarea individual"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": f"Eres un trabajador de ejecución. Herramientas disponibles: {available_tools}"},
{"role": "user", "content": f"Ejecuta la tarea: {task['description']}"}
],
tools=task.get("tools", []),
tool_choice="auto"
)
return {
"task_id": task["id"],
"result": response.choices[0].message.content,
"tool_calls": response.choices[0].message.tool_calls
}
# El Agente principal usa mini, los Sub-agentes usan nano: ahorro de costos superior al 60%
Escenario de aplicación 5 de GPT-5.4 nano: Capa de enrutamiento RAG
Descripción del escenario
En los sistemas RAG, el modelo nano actúa como una "capa de enrutamiento" para determinar el tipo de consulta (problemas técnicos / consultas de preventa / comentarios sobre productos / charla casual) y distribuirla a los procesadores correspondientes. Este diseño permite que los modelos mini o estándar, que son más costosos, solo se utilicen cuando realmente sea necesario.
Ejemplo de enrutamiento RAG
def route_query(query: str) -> str:
"""nano determina a qué procesador RAG enviar la consulta"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": """Devuelve la etiqueta de enrutamiento según el tipo de consulta:
- "technical_docs": consulta de documentación técnica
- "product_faq": FAQ de productos
- "code_help": ayuda con código
- "small_talk": charla casual (no requiere RAG)
- "complex_reasoning": razonamiento complejo (transferir a mini/estándar)"""},
{"role": "user", "content": query}
],
max_tokens=20
)
return response.choices[0].message.content.strip()
route = route_query(user_input)
if route == "complex_reasoning":
final_model = "gpt-5.4-mini" # Escalar a mini
else:
final_model = "gpt-5.4-nano" # Continuar con nano
💰 Optimización de costos: Esta arquitectura de "enrutamiento con nano + procesamiento con mini/estándar" suele reducir los costos operativos totales entre un 60% y un 80%. Puedes cambiar flexiblemente entre ambos modelos usando la misma clave API a través de APIYI (apiyi.com), simplemente modificando el parámetro
model.
Escenario de aplicación 6 de GPT-5.4 nano: Resumen y traducción de alto rendimiento
Descripción del escenario
Tareas de procesamiento por lotes como resúmenes de noticias, traducción de documentos y reescritura de comentarios. Gracias a su ventana de contexto de 400K, nano puede procesar artículos largos de una sola vez, con un costo por unidad prácticamente despreciable.
Ejemplo de Batch API
# Preparar tareas por lotes
batch_requests = []
for doc_id, content in documents.items():
batch_requests.append({
"custom_id": f"summary-{doc_id}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-5.4-nano",
"messages": [
{"role": "system", "content": "Resume el siguiente contenido en 100 palabras"},
{"role": "user", "content": content}
],
"max_tokens": 200
}
})
# Enviar Batch API (mismo precio, no consume cuota en línea)
batch = client.batches.create(
input_file_id=file_id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
GPT-5.4 nano Escenario de aplicación 7: Uso de herramientas (Tool Use)
Descripción del escenario
En el benchmark τ2-Bench, el modelo nano alcanzó un 92.5%, casi igualando el 93.4% del modelo mini. Para escenarios estandarizados de function calling como "consultar el clima, verificar pedidos o buscar en documentos", el modelo nano es perfectamente capaz de realizar el trabajo.
Ejemplo de Function Calling
tools = [{
"type": "function",
"function": {
"name": "get_order_status",
"description": "Consultar el estado del pedido",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string"}
},
"required": ["order_id"]
}
}
}]
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[{"role": "user", "content": "¿Cómo va mi pedido #12345?"}],
tools=tools,
tool_choice="auto"
)
# nano identifica con precisión que debe llamar a get_order_status y extrae order_id="12345"
Detalles de precios de GPT-5.4 nano
Estructura oficial de precios
| Tipo de facturación | Precio (por 1M de tokens) | Descripción |
|---|---|---|
| Entrada | $0.20 | Precio estándar |
| Entrada en caché | $0.02 | 90% de descuento |
| Salida | $1.25 | Incluye tokens de razonamiento |
| Batch API | $0.20 / $1.25 | Mismo precio, no ocupa cuota en línea |
| Residencia de datos regional | +10% | Escenarios de cumplimiento de datos |
Comparativa de precios: nano vs mini
| Dimensión | gpt-5.4-nano | gpt-5.4-mini | Factor |
|---|---|---|---|
| Entrada | $0.20 | $0.75 | nano es 3.75x más barato |
| Entrada en caché | $0.02 | $0.075 | nano es 3.75x más barato |
| Salida | $1.25 | $4.50 | nano es 3.6x más barato |
| Velocidad de respuesta | ~200 t/s | ~180 t/s | nano es ~10% más rápido |
| Contexto | 400K | 400K | Igualado |
| Salida máxima | 128K | 128K | Igualado |
💰 Optimización de costes: Para escenarios de alto rendimiento con millones de solicitudes al día, la diferencia de precio entre nano y mini puede acumularse hasta miles de dólares al mes. Al acceder a través de APIYI (apiyi.com), puedes disfrutar de un 10% adicional al recargar 100 dólares, lo que equivale a un 15% de descuento sobre el precio oficial, logrando un ahorro total de hasta un 25% respecto a la web oficial.
Comparativa integral: GPT-5.4 nano vs. mini

| Dimensión de evaluación | gpt-5.4-nano | gpt-5.4-mini | Diferencia | ¿Es suficiente nano? |
|---|---|---|---|---|
| SWE-Bench Pro | 52.4% | 54.4% | -2.0pp | ✅ Casi igual |
| Terminal-Bench 2.0 | 46.3% | 60.0% | -13.7pp | ⚠️ Usa mini para tareas largas |
| Toolathlon | 35.5% | 42.9% | -7.4pp | ✅ Suficiente para tareas generales |
| GPQA Diamond | 82.8% | 88.0% | -5.2pp | ✅ Capaz en preguntas de conocimiento |
| OSWorld-Verified | 39.0% | 72.1% | -33.1pp | ❌ Usa mini para Computer Use |
| τ2-Bench(Tool Use) | 92.5% | 93.4% | -0.9pp | ✅ Casi igualado |
| MCP Atlas | 56.1% | 57.7% | -1.6pp | ✅ Casi igual |
| Velocidad de respuesta | ~200 t/s | ~180 t/s | +10% | ✅ nano es más rápido |
Recomendaciones de selección
Cuándo priorizar nano:
- Tareas en la "zona verde" (clasificación, extracción, ordenamiento, enrutamiento, uso de herramientas, procesamiento por lotes).
- Volumen de llamadas > 10,000 al día, con sensibilidad al costo.
- Necesidad de latencia baja (< 1 segundo).
- Capas de ejecución de sub-agentes (mini para el agente principal, nano para los trabajadores).
Cuándo actualizar a mini:
- Tareas que involucran Computer Use (diferencia decisiva en OSWorld).
- Tareas largas en terminal (> 10 pasos de operación).
- Necesidad de razonamiento complejo de varios pasos o depuración profunda de código.
- Cuando la calidad de la tarea es más importante que el costo.
📊 Consejo: En el 80% de los escenarios de "alto rendimiento + baja complejidad", la relación costo-beneficio de nano supera a la de mini. Puedes comparar el rendimiento de ambos modelos directamente en tus tareas específicas a través de APIYI (apiyi.com) simplemente modificando el parámetro
model.
Instrucciones de integración de GPT-5.4 nano en APIYI
Disponible directamente en el grupo Default
La plataforma APIYI aplica la misma estrategia de apertura para GPT-5.4 nano y 5.4-mini:
- ✅ Grupo Default (Predeterminado): Acceso total, disponible para invocación inmediatamente después del registro.
- ✅ Grupo SVIP (Premium): Acceso total, sin restricciones.
- ✅ Sincronización de descuento por caché: El precio de caché de $0.02/1M es totalmente aplicable.
- ✅ Sincronización de Batch API: Las tareas por lotes disfrutan del mismo precio.
Comparativa de costes: APIYI vs. Sitio oficial
| Proyecto | Sitio oficial de OpenAI | APIYI apiyi.com |
|---|---|---|
| Precio base | $0.20 / $1.25 por 1M | $0.20 / $1.25 por 1M (mismo precio) |
| Descuento por caché | $0.02 / 1M (90%) | $0.02 / 1M (totalmente sincronizado) |
| Bonificación por recarga | Ninguna | Recarga $100 y recibe $10 (10%) |
| Coste real | 100% precio estándar | Aprox. 90% precio estándar (aprox. 15% de ahorro) |
| Acceso desde China | Requiere VPN | Conexión directa, sin VPN |
| Métodos de pago | Tarjeta de crédito internacional | Soporta RMB, Alipay, WeChat |
| Compatibilidad SDK | Nativo de OpenAI | Totalmente compatible con SDK de OpenAI |
| Recarga mínima | $5 | Desde $1 |
💰 Optimización de costes: Para aplicaciones con un volumen de llamadas superior al millón mensual, al integrar nano a través de APIYI apiyi.com, puedes combinar el ahorro del 15% con la optimización de caché, logrando un coste total entre un 25% y un 35% menor que llamando directamente a OpenAI.
Preguntas frecuentes (FAQ)
Q1: ¿Qué es gpt-5.4-nano? ¿En qué se diferencia principalmente de gpt-5.4-mini?
GPT-5.4-nano es el modelo ligero más económico y rápido de la serie OpenAI GPT-5.4 ($0.20/$1.25 por 1M de tokens), con una velocidad de respuesta de unos 200 t/s. Diferencias clave con 5.4-mini: 1) Es entre 3.6 y 3.75 veces más barato; 2) Su capacidad de Computer Use (39% vs 72.1% en OSWorld) y tareas largas en Terminal (46.3% vs 60%) es significativamente menor; 3) En otros escenarios (clasificación, extracción, uso de herramientas, preguntas y respuestas), la diferencia suele ser inferior a 10 puntos porcentuales.
Q2: ¿Para qué aplicaciones es más adecuado nano? ¿En cuáles es obligatorio usar mini?
Ideal para nano (Zona verde):
- Clasificación en tiempo real (sentimiento, intención, tema)
- Extracción de datos estructurados
- Clasificación y reordenamiento de contenido
- Capa de ejecución de sub-agentes
- Capa de enrutamiento RAG
- Resumen/traducción de alto rendimiento
- Uso de herramientas estandarizadas (92.5% en τ2-Bench)
Escenarios donde es obligatorio usar mini (Zona roja):
- Automatización de escritorio con Computer Use (diferencia de 33pp en OSWorld)
- Tareas largas en Terminal (>10 pasos)
- Razonamiento complejo de múltiples pasos
- Escenarios personalizados que requieren Fine-tuning
Q3: ¿Por qué no se recomienda nano para Computer Use?
En la evaluación OSWorld-Verified, nano obtuvo solo un 39.0%, muy por debajo del 72.1% de mini. Esto significa que la tasa de error de nano en operaciones de escritorio de varios pasos (abrir navegador → buscar → hacer clic → rellenar formulario) es demasiado alta para completar la cadena de tareas de forma estable. Si tu escenario requiere Computer Use, elige directamente mini o la versión estándar de 5.4.
Q4: ¿Cómo se activa el descuento por caché de $0.02/1M en nano?
El mecanismo de caché de OpenAI se activa automáticamente, sin necesidad de parámetros adicionales. Se aplica cuando el prefijo del prompt (normalmente el system prompt + contexto compartido) coincide con las solicitudes de los últimos 5-10 minutos, obteniendo un descuento del 90%.
Consejos de optimización:
- Coloca el system prompt al principio del array de mensajes.
- El contexto compartido (etiquetas de clasificación, definición de esquema) debe ir justo después.
- La consulta real del usuario debe ir al final.
- Mantén la frecuencia de llamadas (caduca después de >5 minutos).
Al invocar a través de APIYI apiyi.com, el descuento por caché está totalmente sincronizado con el sitio oficial.
Q5: ¿Cuáles son las mejores prácticas para manejar tareas por lotes con nano?
Tres estrategias clave:
- Usar Batch API: Envía tareas por lotes a través de la interfaz
/v1/batches. Se completan en 24 horas, mantienen el precio y no consumen la cuota de RPM en línea. - Compartir el system prompt: Usa las mismas instrucciones para todas las tareas para activar la coincidencia de caché.
- Configurar un max_tokens razonable: La salida de nano es barata, pero se acumula; establece un límite superior razonable de 50-500 según la tarea.
Al enviar tareas Batch a través de APIYI apiyi.com, disfrutas de un coste real de aproximadamente el 85% del precio oficial tras aplicar el 10% de bonificación por recarga.
Q6: ¿Cómo invocar GPT-5.4 nano a través de APIYI?
APIYI es totalmente compatible con el SDK de OpenAI. Solo necesitas tres pasos:
- Visita APIYI apiyi.com y regístrate (no requiere solicitud, el grupo Default está disponible directamente).
- Obtén tu clave API.
- Cambia el
base_urlen tu código ahttps://vip.apiyi.com/v1y establece el modelo comogpt-5.4-nano.
client = openai.OpenAI(
api_key="TU_CLAVE",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[...]
)
Recargar 100 dólares otorga un 10% extra, lo que equivale a un ahorro del 15% respecto al oficial, con descuentos de caché sincronizados.
Q7: ¿Cuándo es nano más rentable que mini? ¿Cómo se calcula?
Fórmula de decisión:
Condición de rentabilidad de nano = (Tolerancia a la degradación de calidad) × (Volumen de llamadas) × (Diferencia de precio)
> (Beneficio de mejora de calidad al pasar a mini)
Escenarios reales:
- Volumen > 10K/día: Ahorro > $30/día ($1000/mes)
- Volumen > 100K/día: Ahorro > $300/día ($9000/mes)
- Volumen > 1M/día: Ahorro > $3000/día ($90000/mes)
Para tareas de zona verde (clasificación, extracción, uso de herramientas), la pérdida de calidad de nano suele ser < 5%, pero el ahorro de costes es del 73% (cálculo puro de 3.6x). El ROI general casi siempre favorece a nano.
Q8: ¿Qué limitaciones conocidas tiene GPT-5.4 nano?
Limitaciones principales:
- Sin soporte para Computer Use: El 39% en OSWorld es demasiado bajo para automatización de escritorio estable.
- Sin soporte para Fine-tuning: No se puede ajustar con conjuntos de datos personalizados.
- Sin entrada de audio/vídeo: Solo admite entrada de texto e imagen.
- Debilidad en tareas largas de Terminal: 46.3% en Terminal-Bench; las operaciones de más de 10 pasos suelen fallar.
- Capacidad de razonamiento complejo limitada: 82.8% en GPQA, cercano a mini, pero el rendimiento cae significativamente en tareas extremadamente difíciles como FrontierMath.
Alternativa: Si encuentras estas limitaciones, cambia directamente a gpt-5.4-mini o a la versión estándar de 5.4.
Puntos clave de los escenarios de aplicación de GPT-5.4 nano
- Precio base: $0.20/$1.25 por cada 1M de tokens, entre 3.6 y 3.75 veces más barato que el 5.4-mini.
- 90% de descuento en caché: Entrada desde $0.02/1M, ideal para escenarios de contexto de alta frecuencia casi gratuitos.
- 7 escenarios de zona verde: Clasificación, extracción, clasificación (ranking), sub-agentes, enrutamiento, procesamiento por lotes y uso de herramientas (Tool Use).
- τ2-Bench 92.5%: La invocación de herramientas casi iguala al mini; suficiente para más del 90% de los escenarios de Function Calling.
- GPQA 82.8%: Gran capacidad de respuesta a preguntas de conocimiento general, ideal para FAQ y moderación de contenido.
- Velocidad de 200 t/s: 10% más rápido que el mini, la opción preferida para flujos de alta capacidad.
- Advertencia de zona roja: Para tareas largas de Computer Use o Terminal, es obligatorio cambiar al modelo mini.
Resumen
Puntos clave sobre los escenarios de aplicación de GPT-5.4 nano:
- Posicionamiento del escenario: El modelo nano es la mejor opción para tareas de alta capacidad y baja complejidad. Su terreno principal incluye la clasificación en tiempo real, extracción de datos, trabajadores sub-agentes, enrutamiento RAG y procesamiento por lotes.
- Límites de capacidad: En pruebas como τ2-Bench, GPQA y SWE-Bench Pro, casi iguala al modelo mini, pero su rendimiento en tareas largas de Computer Use o Terminal es notablemente inferior.
- Cómo acceder: Accede directamente a través del grupo predeterminado en APIYI (apiyi.com). Los descuentos por caché están sincronizados y obtienes un 10% extra en recargas de 100.
GPT-5.4 nano no es un producto barato que "hace de todo pero nada bien", sino un arma ligera optimizada por OpenAI específicamente para escenarios de alta capacidad y baja complejidad. Si tu aplicación encaja en los 7 escenarios de zona verde mencionados, nano casi siempre será más rentable que mini. Sin embargo, si el proyecto involucra Computer Use o tareas largas en Terminal, cambiar a mini es la decisión correcta.
Te recomendamos acceder rápidamente a GPT-5.4 nano a través de la plataforma APIYI (apiyi.com). No necesitas solicitar acceso para el grupo predeterminado, los descuentos de caché están totalmente sincronizados, recibes un 10% de regalo en tus recargas y disfrutas de una conexión estable desde cualquier lugar.
Lecturas recomendadas
Si te interesa la API de GPT-5.4 nano, te recomiendo seguir explorando estos temas:
- 📘 Guía de actualización de la API de GPT-5.4 mini – Conoce las capacidades y casos de uso del modelo mini de la generación anterior.
- 📊 Análisis profundo del mecanismo de caché de OpenAI: mejores prácticas para obtener un 90% de descuento – Domina las técnicas de ingeniería para optimizar el caché.
- 🚀 Implementación práctica de una capa de enrutamiento RAG basada en GPT-5.4 nano – Explora la arquitectura híbrida de "enrutamiento con nano + procesamiento con mini".
📚 Referencias
-
Documentación oficial de OpenAI sobre GPT-5.4 nano: especificaciones del modelo, precios y ejemplos de invocación.
- Enlace:
developers.openai.com/api/docs/models/gpt-5.4-nano - Nota: Obtén los parámetros técnicos oficiales más recientes y fiables.
- Enlace:
-
Análisis de referencia de AI Cost Check: evaluación multidimensional de nano frente a mini.
- Enlace:
aicostcheck.com/blog/gpt-5-4-mini-nano-pricing-benchmarks - Nota: Evaluación de terceros, ideal para comparar las diferencias de capacidad de forma transversal.
- Enlace:
-
Documentación de integración de GPT-5.4 nano en APIYI: soluciones de invocación, explicaciones de grupos y promociones de recarga.
- Enlace:
docs.apiyi.com - Nota: Guía práctica de integración ideal para desarrolladores.
- Enlace:
-
Página de precios de OpenAI: tabla completa de precios y explicación del mecanismo de caché.
- Enlace:
developers.openai.com/api/docs/pricing - Nota: Estándares de facturación más recientes para todos los modelos.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a discutir tus experiencias con GPT-5.4 nano en la sección de comentarios. Para más información sobre la integración de modelos, visita el centro de documentación de APIYI en docs.apiyi.com.