Nota del autor: Te enseño paso a paso cómo conectar gpt-image-2 en Chatbox mediante un endpoint personalizado y analizo a fondo por qué Chatbox no permite modificar imágenes mediante conversaciones continuas al estilo de la versión web de ChatGPT. La razón radica en las diferencias de arquitectura entre los tres endpoints: images/generations, chat/completions y Responses API.
Muchos usuarios configuran su clave API de OpenAI en Chatbox e intentan generar imágenes introduciendo gpt-image-2, solo para recibir errores o texto cifrado. Este artículo te dará dos respuestas: primero, la forma correcta de conectar Chatbox a gpt-image-2 (configurando el endpoint personalizado en https://api.apiyi.com/v1/images/generations); y segundo, lo más importante: por qué Chatbox no puede "generar una imagen y luego editarla mediante diálogo" como lo hace la interfaz web de ChatGPT.
Esto no es un error de Chatbox, sino que OpenAI asigna la generación de imágenes, la finalización de chat y la edición multironda a tres endpoints de API completamente diferentes. La ruta que utiliza Chatbox por defecto simplemente no admite la generación y edición continua.
Valor clave: Tras leer este artículo, comprenderás perfectamente los límites y diferencias de capacidad de los tres endpoints principales de OpenAI, sabrás cuándo es suficiente con Chatbox, cuándo debes cambiar a la API de Responses y cómo utilizar el servicio proxy de API de APIYI para realizar invocaciones estables a cualquier endpoint desde China.
Cuál es la forma correcta de conectar Chatbox a gpt-image-2
Empecemos por lo más práctico: si quieres que Chatbox funcione con gpt-image-2 de inmediato, sigue estos pasos y lo tendrás listo en 5 minutos.
Configuración clave para conectar Chatbox a gpt-image-2
Por defecto, Chatbox llama a la API como una "finalización de chat" (usando el endpoint /v1/chat/completions), pero gpt-image-2 no es un modelo de chat, es un modelo de generación de imágenes puro, cuyo endpoint es /v1/images/generations. Por lo tanto, debes usar la función de "endpoint personalizado" de Chatbox para sobrescribir la dirección predeterminada.
Pasos de configuración completos:
| Paso | Operación | Parámetro clave |
|---|---|---|
| 1 | Abrir Ajustes de Chatbox → Proveedor de modelos → Añadir proveedor personalizado | Seleccionar modo compatible con OpenAI API |
| 2 | Host de API | https://api.apiyi.com |
| 3 | Ruta de API (modificación clave) | /v1/images/generations |
| 4 | Clave API | Token de Bearer obtenido en el panel de control de APIYI |
| 5 | Campo Modelo | gpt-image-2 |
| 6 | Tiempo de espera | Configurar ≥ 360 segundos |
Ejemplo mínimo de invocación para conectar Chatbox a gpt-image-2
A continuación, se muestra un ejemplo de llamada curl recomendado oficialmente; puedes usarlo primero para verificar si tu clave API es válida:
curl --request POST \
--url https://api.apiyi.com/v1/images/generations \
--header 'Authorization: Bearer sk-your-apiyi-key' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-image-2",
"prompt": "Formato de película 16:9, viejo faro junto al mar al atardecer"
}'
Una vez que este curl funcione, vuelve a Chatbox y cambia el endpoint a /v1/images/generations para poder usarlo.
🎯 Consejo de configuración: Al configurar el endpoint personalizado de Chatbox por primera vez, se recomienda usar primero curl para verificar que la clave API y la ruta del endpoint sean correctas. Recomendamos obtener crédito de prueba a través de la plataforma APIYI (apiyi.com); el saldo gratuito es suficiente para completar toda la configuración y verificación.
Errores comunes de configuración al conectar Chatbox a gpt-image-2
He recopilado los 5 problemas más frecuentes que encuentran los usuarios:
| Síntoma de error | Causa raíz | Solución |
|---|---|---|
Devuelve model not found |
Se usó el endpoint /v1/chat/completions |
Cambiar a /v1/images/generations |
Devuelve invalid prompt format |
Se usó el formato messages del chat |
Cambiar al campo prompt (cadena de texto) |
| Tiempo de espera excedido tras 60s | El tiempo de espera es demasiado corto | Ajustar a ≥ 360 segundos (necesario para alta resolución) |
| La imagen no aparece | Chatbox no analiza el formato b64_json |
Hacer que la respuesta devuelva el formato url |
| Error en prompt en chino | Problema de codificación | Confirmar Content-Type: application/json; charset=utf-8 |
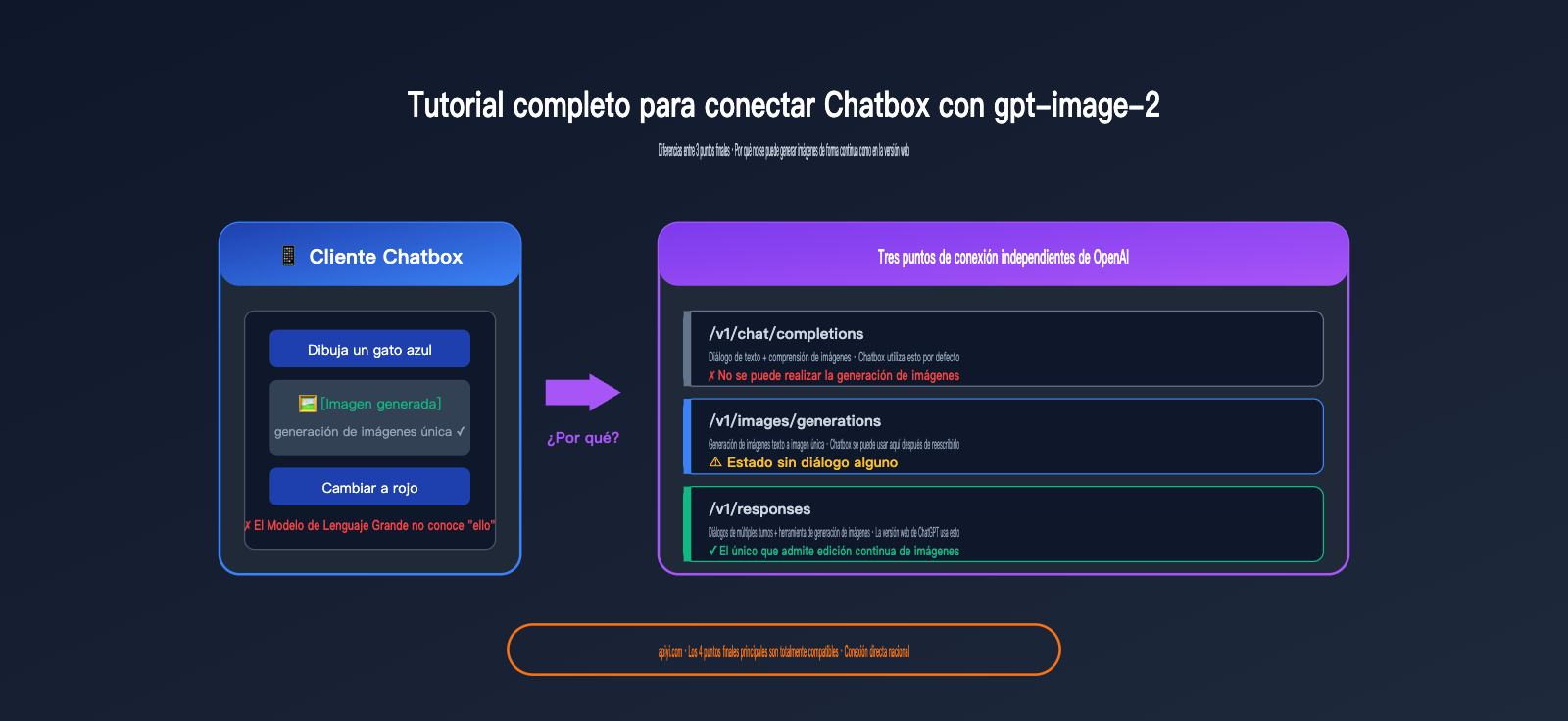
¿Por qué no puedo modificar imágenes continuamente en Chatbox tras conectar gpt-image-2?
Este es el punto técnico más importante del artículo. Muchos usuarios, tras configurar todo, preguntan: "¿Por qué genero una imagen en Chatbox, luego le pido 'cambia el cielo a azul' y el modelo no entiende nada? ¿Por qué la versión web de ChatGPT sí permite modificaciones continuas e ilimitadas?".
La respuesta no es un error (bug) de Chatbox, sino que el endpoint en sí mismo no lo admite.
Limitaciones de la arquitectura del endpoint de Chatbox al conectar gpt-image-2
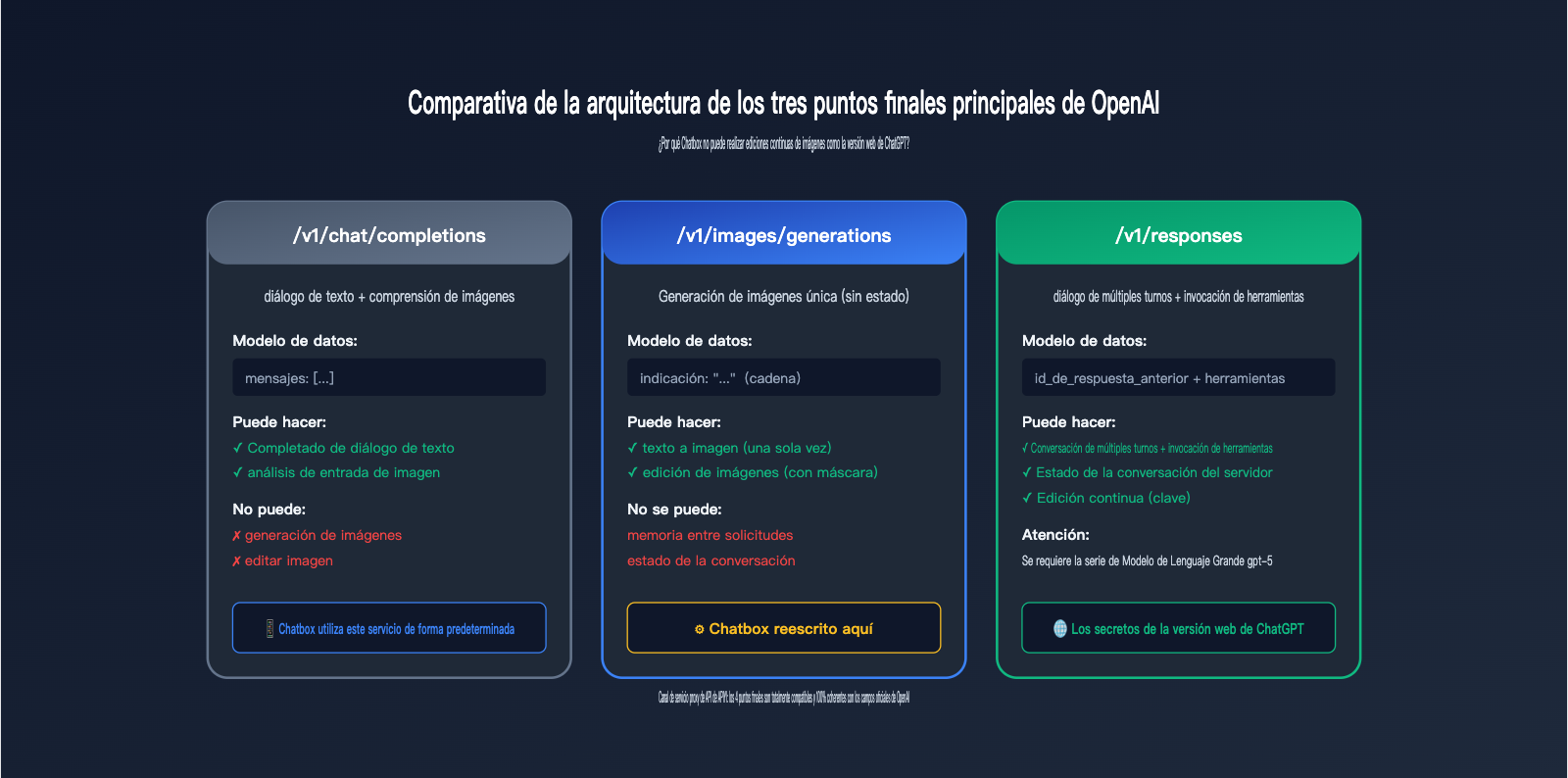
Para entender esto a fondo, debemos comprender los tres endpoints independientes que ofrece OpenAI actualmente:
| Endpoint | Ruta | Propósito | ¿Soporta generación? | ¿Tiene estado de chat? |
|---|---|---|---|---|
| Chat Completions | /v1/chat/completions |
Completado de texto | ❌ Solo entrada de imagen | ❌ Gestionado por cliente |
| Image Generations | /v1/images/generations |
Texto a imagen único | ✅ Solo generación | ❌ Sin estado |
| Image Edits | /v1/images/edits |
Imagen a imagen/edición | ✅ Edición | ❌ Sin estado |
| Responses API | /v1/responses |
Chat multironda + herramientas | ✅ Invocación de herramientas | ✅ Gestionado por servidor |
La cruda realidad:
- Chatbox usa por defecto
/v1/chat/completions: este endpoint no soporta la generación de imágenes. - Si cambias la ruta a
/v1/images/generationspodrás generar imágenes, pero este endpoint es completamente apátrida (sin estado): cada solicitud es aislada. - La versión web de ChatGPT utiliza por detrás
/v1/responses: tiene integrada la invocación de la herramientaimage_generationjunto con el estado de la conversación en el servidor.
¿Por qué la versión web de ChatGPT puede modificar imágenes continuamente?
El flujo de trabajo detrás de la versión web de ChatGPT es el siguiente:
- Escribes "dibuja un gato azul".
- ChatGPT llama al endpoint
/v1/responses, el modelo decide invocar la herramientaimage_generation. - La herramienta devuelve un ID de imagen (por ejemplo,
ig_abc123) y lo registra en el estado del servidor de la sesión actual. - Luego dices "cámbialo a rojo".
- ChatGPT llama de nuevo a
/v1/responses, pasando elprevious_response_id. - El modelo, basándose en el contexto, identifica que "cámbialo" se refiere a la imagen anterior e invoca la acción
editde la herramientaimage_generation. - La herramienta edita la imagen anterior y devuelve una nueva.
La clave de todo el proceso es el previous_response_id + el estado de la conversación en el servidor + la herramienta integrada image_generation; capacidades que el endpoint /v1/images/generations no posee.
Limitaciones de la arquitectura actual de Chatbox
Chatbox es un cliente de estilo Chat Completions: su modelo de datos central es una "matriz de mensajes" (mensajes de sistema / usuario / asistente en múltiples rondas). Su mecanismo de trabajo es:
- Añadir cada mensaje del usuario a la matriz de mensajes.
- Llamar a un endpoint de estilo chat (por defecto
/v1/chat/completions). - Añadir la respuesta a la matriz de mensajes.
- Repetir.
Cuando cambias la ruta del endpoint a /v1/images/generations, Chatbox simplemente cambia la ruta de la solicitud, pero la matriz de mensajes se sigue enviando en formato chat, y el endpoint solo acepta una indicación única, por lo que el estado de la conversación no se puede transmitir.
💡 Interpretación técnica: El diseño central de Chatbox asume que "el endpoint es de estilo chat", mientras que OpenAI diseñó la generación y edición de imágenes como endpoints de recursos RESTful independientes; esto es una incompatibilidad a nivel de arquitectura. Recomendamos probar primero
/v1/images/generationspara una generación única a través de la plataforma APIYI (apiyi.com). Una vez verificado el resultado, planifica si necesitas cambiar a la Responses API.
Límites de capacidad y alternativas para la integración de gpt-image-2 en Chatbox
Una vez conocidos los límites, podemos establecer una lista clara de lo que es posible y lo que no.
Lo que puedes hacer con Chatbox + gpt-image-2
| Escenario | ¿Soportado? | Notas |
|---|---|---|
| Generar una imagen con una sola indicación | ✅ | Uso estándar |
| Indicaciones en chino e inglés | ✅ | Soporte nativo de gpt-image-2 |
| Especificar dimensiones/proporción | ✅ | Mediante el parámetro size |
| Especificar calidad (standard/high) | ✅ | Mediante el parámetro quality |
| Obtener URL o base64 | ✅ | Mediante el parámetro response_format |
Lo que no puedes hacer con Chatbox + gpt-image-2
| Escenario | ¿Soportado? | Alternativa |
|---|---|---|
| Modificar una imagen tras generarla (ej. "cámbiala a rojo") | ❌ | Cambiar a Responses API |
| Iteraciones múltiples para ajustar detalles | ❌ | Cambiar a Responses API |
| Subir imagen + indicación para edición local | ❌ Chatbox no lo soporta | Cambiar a /v1/images/edits o Responses API |
| Fusionar varias imágenes de referencia | ❌ Chatbox no lo soporta | Cambiar a Responses API |
| Historial de chat guardado en servidor | ❌ | Cambiar a Responses API |
Código mínimo para implementar generación continua de imágenes con Responses API
Si necesitas "modificar imágenes mediante chat", debes dejar de usar el cliente Chatbox y escribir tu propio código para invocar el endpoint /v1/responses:
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
timeout=600.0
)
# Primera ronda: generar imagen inicial
resp1 = client.responses.create(
model="gpt-5", # Responses API requiere la serie gpt-5
input="Dibuja un gato azul paseando bajo la luz de la luna, estilo realista",
tools=[{"type": "image_generation"}]
)
response_id_1 = resp1.id
print("Primera imagen: ", resp1.output[-1])
# Segunda ronda: modificar basándose en la anterior (la clave es previous_response_id)
resp2 = client.responses.create(
model="gpt-5",
previous_response_id=response_id_1, # Conecta el estado del chat
input="Cambia su color a naranja y el fondo a un amanecer",
tools=[{"type": "image_generation"}]
)
print("Tras la modificación: ", resp2.output[-1])
Ten en cuenta estos puntos clave:
- Debes usar
gpt-5o un modelo más reciente (gpt-image-2 no puede invocarse directamente como modelo de chat). - Debes pasar
tools=[{"type": "image_generation"}]para habilitar la herramienta. - Debes usar
previous_response_idpara conectar el historial del chat; de lo contrario, el modelo no sabrá a qué se refiere con "su" o "la".
🚀 Consejo de integración: Al usar Responses API para generación continua, configura la
base_urlcomohttps://api.apiyi.com/v1. Es totalmente compatible con los campos oficiales de OpenAI, por lo que solo necesitas cambiar una línea de código en tu SDK de OpenAI existente. Recomendamos realizar la integración a través de APIYI (apiyi.com) para una conexión estable y directa.
Guía práctica para configurar Chatbox con gpt-image-2
Tras haber cubierto toda la teoría, aquí tienes una guía completa "paso a paso" para ponerlo todo en marcha.
Paso 1: Obtener la clave API de la plataforma APIYI
- Accede al panel de control de APIYI en
api.apiyi.com. - Tras iniciar sesión, dirígete a la página de "Tokens de API".
- Crea un nuevo Token (se recomienda usar uno independiente para cada proyecto).
- Copia el Bearer Token completo (que comienza por
sk-).
Paso 2: Configurar el proveedor personalizado en Chatbox
Realiza los siguientes pasos en Chatbox:
- Abre "Ajustes" → "Proveedor de modelos".
- Haz clic en "Añadir" → selecciona "Proveedor compatible con OpenAI personalizado".
- Rellena los siguientes campos:
Nombre: APIYI - Generación de imágenes
API Host: https://api.apiyi.com
API Path: /v1/images/generations # ¡Clave! Debes sobrescribirlo
API Key: sk-tu-clave-apiyi
Modelo predeterminado: gpt-image-2
- Ajustes avanzados:
- Tiempo de espera de solicitud: 600 segundos
- Reintentos: 2
- Codificación de caracteres: UTF-8
Paso 3: Enviar una indicación de prueba
En el cuadro de diálogo de Chatbox, introduce:
Formato de cine 16:9, viejo faro junto al mar al atardecer,
tonos cálidos y suaves, niebla sobre el mar, resolución 2K
Si la configuración es correcta, deberías recibir la imagen generada en un plazo de 1 a 3 minutos.
Paso 4: Solución rápida de problemas comunes
| Problema | Qué comprobar |
|---|---|
| No devuelve nada | Comprueba si la clave API está completa y si tienes permisos de generación de imágenes |
| Error 401 | Clave API incorrecta o caducada, vuelve a obtenerla |
| Error 404 | Error en la ruta API, confirma /v1/images/generations |
| Error 429 | Se alcanzó el límite de velocidad, espera unos minutos y vuelve a intentar |
| Tiempo de espera (timeout) | El tiempo de espera es muy corto, ajústalo a 600 segundos |
💡 Consejo avanzado: Si necesitas integrar gpt-image-2 en tu propia aplicación en lugar de usar un cliente de escritorio, te recomiendo usar directamente el SDK oficial de OpenAI para llamar a
/v1/images/generations; es mucho más flexible que Chatbox. Sugerimos realizar la conexión a través de APIYI (apiyi.com), simplemente reemplazando elbase_urlporhttps://api.apiyi.com/v1.
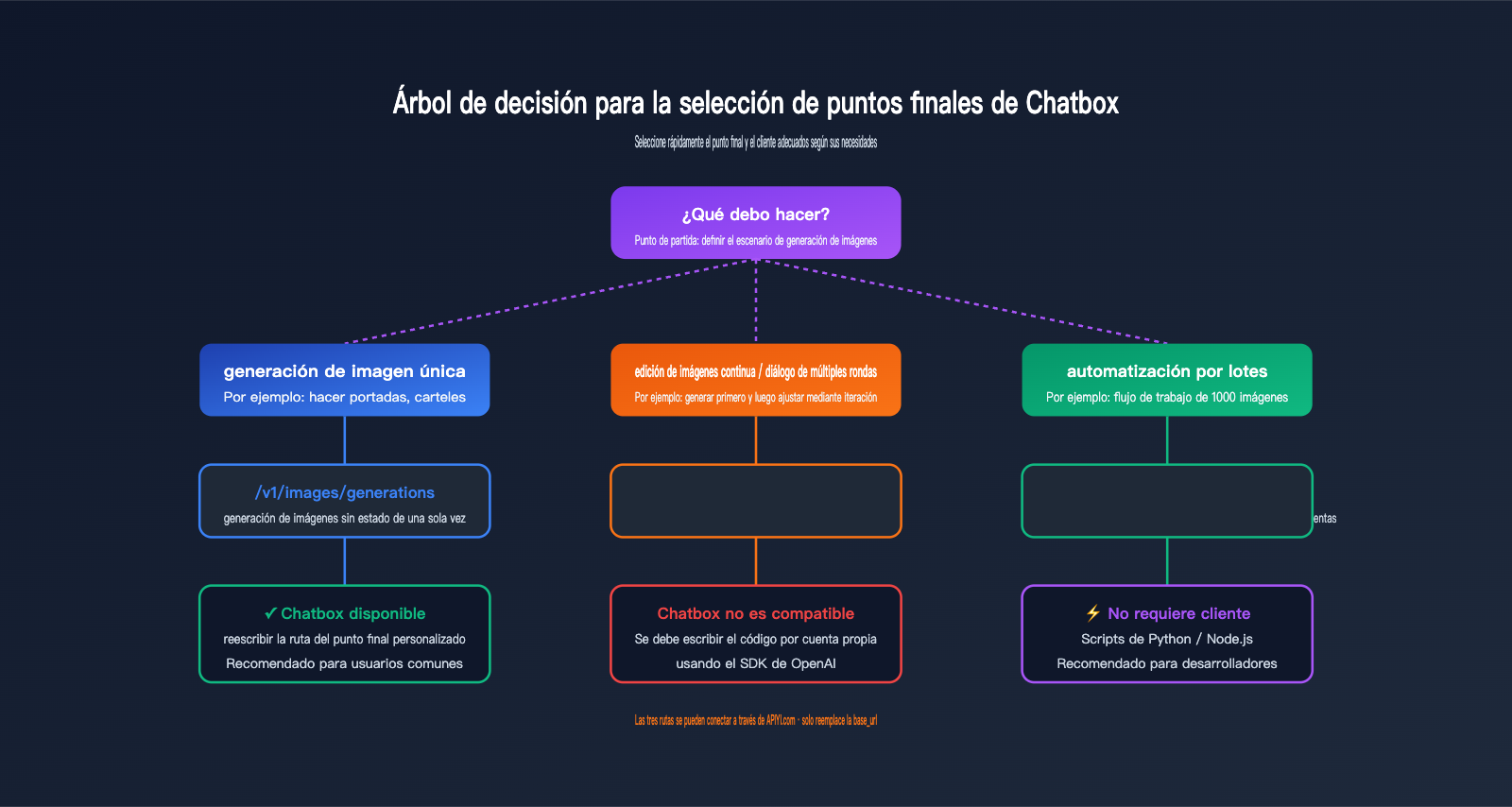
Guía de decisión para la selección de endpoints
La siguiente tabla te ayudará a decidir rápidamente qué endpoint utilizar según el escenario:
| Tu necesidad | Endpoint recomendado | Cliente aplicable |
|---|---|---|
| Texto a imagen único (ej. portada) | /v1/images/generations |
Chatbox / curl / SDK |
| Edición de imagen única (con máscara) | /v1/images/edits |
curl / SDK (Chatbox no es compatible) |
| Modificación de imagen en diálogo continuo | /v1/responses |
Código propio (Chatbox no es compatible) |
| Solo diálogo de texto | /v1/chat/completions |
Chatbox / cualquier cliente de chat |
| Diálogo de texto + comprensión de imagen | /v1/chat/completions |
Compatible con Chatbox |

Preguntas frecuentes (FAQ) sobre la integración de gpt-image-2 en Chatbox
Pregunta 1: ¿Por qué Chatbox no admite directamente la generación continua de imágenes con gpt-image-2?
Esto no es un fallo de diseño de Chatbox, sino una limitación inherente a los clientes de chat. El modelo de datos de Chatbox es una matriz de messages (estilo chat), mientras que el modelo de datos de la API de Responses utiliza previous_response_id junto con un estado de conversación en el servidor; son dos paradigmas fundamentalmente incompatibles. Para que Chatbox admita esta capacidad, tendría que reescribir todo su motor de diálogo.
Pregunta 2: Tras configurar un endpoint personalizado en Chatbox, ¿puedo subir imágenes para que gpt-image-2 las edite?
Teóricamente sí, pero en la práctica es muy complicado. El endpoint /v1/images/edits requiere una carga de archivos de imagen en formato multipart/form-data, mientras que el cuadro de diálogo de Chatbox solo admite entrada de texto. Si intentas forzarlo, obtendrás un error 415. Alternativa recomendada: utiliza curl, Postman o un script propio para invocar /v1/images/edits.
Pregunta 3: ¿El servicio proxy de API de APIYI admite la API de Responses?
Totalmente. APIYI es un canal de transferencia oficial, por lo que los campos de solicitud/respuesta están 100% sincronizados con los de OpenAI, incluyendo los 4 endpoints principales: /v1/responses, /v1/images/generations, /v1/images/edits y /v1/chat/completions. Recomendamos realizar la invocación del modelo de la API de Responses a través de APIYI (apiyi.com) para lograr una generación continua de imágenes con una conexión estable desde China, sin necesidad de proxies.
Pregunta 4: Al usar Chatbox para invocar gpt-image-2, ¿cuál es la longitud máxima del campo de indicación?
OpenAI limita oficialmente el campo de indicación a 32,000 caracteres, pero en la práctica recomendamos mantenerlo por debajo de los 1,000 caracteres. Una indicación demasiado larga puede dispersar la atención del modelo, lo que paradójicamente reduce la calidad de la generación.
Pregunta 5: ¿Se puede configurar un Modelo de Lenguaje Grande de chat y un modelo de generación de imágenes simultáneamente en Chatbox?
Sí, Chatbox permite configurar múltiples "proveedores personalizados". Te sugerimos crear dos:
APIYI - Chat→ Endpoint/v1/chat/completions→ Modelogpt-5/claude-sonnet-4-6, etc.APIYI - Generación de imágenes→ Endpoint/v1/images/generations→ Modelogpt-image-2
Al cambiar de proveedor, podrás alternar entre ambos modos.
Pregunta 6: Cuando la invocación de gpt-image-2 falla en Chatbox, ¿cómo determinar si el problema es de Chatbox o de la API?
La forma más rápida es invocar la API directamente usando curl. Si el comando curl funciona, el problema está en la configuración de Chatbox; si el curl también falla, el problema reside en la clave API o en la red. Puedes copiar y usar directamente los ejemplos de curl que aparecen al principio de este artículo.
Pregunta 7: ¿Qué diferencia hay entre invocar a través de APIYI y hacerlo directamente con OpenAI?
Los campos son exactamente iguales, ya que APIYI es un canal de transferencia oficial. Las diferencias principales radican en tres aspectos: conexión directa desde China sin necesidad de proxy, soporte técnico especializado en chino y facturación transparente y visible. Recomendamos a los desarrolladores locales acceder a gpt-image-2 a través de APIYI (apiyi.com) para evitar problemas de estabilidad de red.
Pregunta 8: ¿Cuándo debería dejar de usar Chatbox y pasar a escribir mi propio código con la API de Responses?
Hay tres señales claras:
- Necesitas "edición de imágenes conversacional": generar una vez y realizar múltiples ajustes finos.
- Necesitas una salida mixta de imagen y texto (explicar un fragmento, generar una imagen, y luego seguir explicando).
- Estás desarrollando un producto y no es solo para uso personal, por lo que necesitas gestionar el estado de la conversación en el servidor.
Si cumples cualquiera de estas condiciones, deberías cambiar a la API de Responses.
Puntos clave sobre la integración de gpt-image-2 en Chatbox
- Chatbox utiliza por defecto
/v1/chat/completions: este endpoint no admite la generación de imágenes, por lo que debe cambiarse a/v1/images/generations. /v1/images/generationses un endpoint sin estado: cada solicitud es independiente, por lo que no es posible realizar "modificaciones continuas".- La capacidad de generación continua de imágenes en la web de ChatGPT proviene de la API de Responses: utiliza la herramienta
image_generationintegrada + el estado de conversaciónprevious_response_id. - Que Chatbox no pueda realizar generación continua no es un error (bug): es una diferencia fundamental entre el paradigma de los clientes de chat y la API de Responses.
- Solución alternativa: cuando necesites generación continua, usa el SDK de OpenAI para invocar
/v1/responsesmediante código, utilizando obligatoriamente modelos de la serie gpt-5. - Recomendación de acceso local: utiliza APIYI (apiyi.com), que admite los 4 endpoints principales; solo necesitas reemplazar la
base_url. - Solución de problemas rápida: si la configuración falla, verifica primero con curl; si el curl funciona, el problema está en el cliente y no en la API.
Resumen
El problema de "configuración" al conectar Chatbox con gpt-image-2 es solo la punta del iceberg. Lo que realmente vale la pena que los desarrolladores comprendan es la arquitectura de tres endpoints independientes de OpenAI; cada uno está diseñado para escenarios de uso distintos y sus capacidades son totalmente diferentes:
- Chat Completions: Es el endpoint para "conversación de texto + comprensión de imágenes", no puede generar imágenes.
- Images Generations / Edits: Es el endpoint sin estado para "generación/edición única de imágenes"; es simple y directo, pero no permite iteraciones multironda.
- Responses API: Es el endpoint para "conversación multironda + invocación de herramientas", la única vía para lograr la "edición de imágenes conversacional".
Dado que Chatbox es un cliente de estilo chat, solo puede adaptarse perfectamente a uno de los dos primeros modos (mediante la reescritura del endpoint personalizado para admitir la generación única de imágenes). Sin embargo, para lograr esa "edición conversacional infinita" que ofrece la versión web de ChatGPT, debes abandonar las herramientas de cliente y escribir tu propio código para invocar la Responses API.
Una vez que entiendas esto, tu elección de flujo de trabajo será clara:
- Pequeña escala, generación única, uso personal: Chatbox +
/v1/images/generations - Necesidad de edición continua, integración a nivel de producto: Responses API + código propio
- Generación por lotes, flujos de trabajo automatizados: SDK directo invocando
/v1/images/generations
✨ Consejo final: Para los desarrolladores en China, independientemente del camino que elijan, recomendamos acceder a través de la plataforma APIYI (apiyi.com). Es compatible con los 4 endpoints principales, mantiene una consistencia del 100% con los campos oficiales de OpenAI, ofrece conexión directa estable desde el país y una facturación transparente por token. Los nuevos usuarios cuentan con una cuota de prueba gratuita, suficiente para completar la configuración de Chatbox y la verificación de ambas rutas de la Responses API.
Autor: Equipo de APIYI
Última actualización: 02-05-2026