Un usuario recibió el siguiente error al invocar gpt-image-2, el cual se ha convertido en uno de los errores más frecuentes en la comunidad de desarrolladores desde el lanzamiento de gpt-image-2 en abril de 2026:
{
"status_code": 400,
"error": {
"message": "Your request was rejected by the safety system. ... safety_violations=[violence].",
"type": "shell_api_error",
"code": "moderation_blocked"
}
}
La primera reacción de muchos es pensar: "Solo añadiré un reintento y listo". Pero esta es una reacción incorrecta: el mismo prompt fallará 100 veces si lo reintentas 100 veces. La esencia del error moderation_blocked en gpt-image-2 es que la solicitud ni siquiera llega al modelo; es rechazada activamente por el clasificador de seguridad previo. Reintentar es simplemente una pérdida de tiempo.
Este artículo parte de este caso de error real para desglosar sistemáticamente el mecanismo de revisión de seguridad de gpt-image-2 (incluida la arquitectura de filtrado de dos etapas), el panorama de los 7 escenarios de activación, 5 estrategias de optimización de la indicación y las mejores prácticas de ingeniería para reducir la tasa de error en producción. Tras leerlo, podrás realizar una auditoría de cumplimiento de tus plantillas de indicación y reducir la tasa de infracciones en más de un 80%.
<rect x="20" y="72" width="280" height="32" rx="6" fill="#1e293b" stroke="#10b981"/>
<text x="35" y="92" fill="#a7f3d0" font-size="11" font-family="'Hiragino Sans GB', 'STHeiti', sans-serif">① Reescritura de desensibilización</text>
<rect x="20" y="110" width="280" height="32" rx="6" fill="#1e293b" stroke="#10b981"/>
<text x="35" y="130" fill="#a7f3d0" font-size="11" font-family="'Hiragino Sans GB', 'STHeiti', sans-serif">② Reemplazo de sujeto real</text>
<rect x="20" y="148" width="280" height="32" rx="6" fill="#1e293b" stroke="#10b981"/>
<text x="35" y="168" fill="#a7f3d0" font-size="11" font-family="'Hiragino Sans GB', 'STHeiti', sans-serif">③ Declaración del marco de escenarios</text>
<rect x="20" y="186" width="280" height="32" rx="6" fill="#1e293b" stroke="#10b981"/>
<text x="35" y="206" fill="#a7f3d0" font-size="11" font-family="'Hiragino Sans GB', 'STHeiti', sans-serif">④ moderación: baja + descomposición en múltiples pasos</text>
Interpretación de la esencia del error moderation_blocked en gpt-image-2
Para resolver este error, primero debemos entender qué es exactamente. Muchos desarrolladores lo consideran un "modelo que se niega a responder", pero en realidad no es así.
Hechos clave sobre el error moderation_blocked en gpt-image-2
| Hecho | Explicación | Implicación técnica |
|---|---|---|
| HTTP 400 (lado del cliente) | Error a nivel de solicitud, no fallo del servidor | Reintentar no sirve, debes cambiar el prompt |
| La solicitud no llega al modelo | Interceptada por el clasificador previo | No se cobra, no consume tokens |
code=moderation_blocked |
Código de error estandarizado, identificable por programa | Ideal para construir tuberías de reescritura automática |
safety_violations=[…] |
Matriz que lista las categorías de infracción activadas | Localiza con precisión la parte que necesita modificación |
| Reproducción 100% con el mismo prompt | El resultado es determinista, no un evento probabilístico | Debes reescribir el prompt para recuperar el servicio |
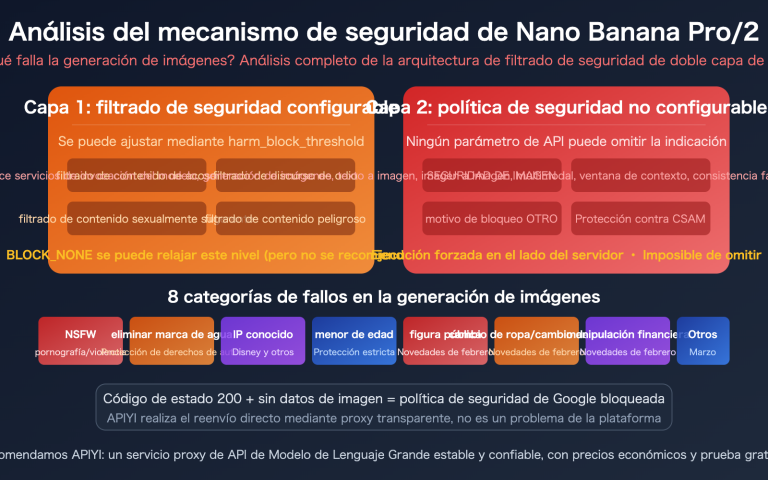
Mecanismo de revisión de seguridad de dos etapas de gpt-image-2
Para entender el error de gpt-image-2, primero debemos observar la arquitectura de filtrado de seguridad de dos etapas de OpenAI.
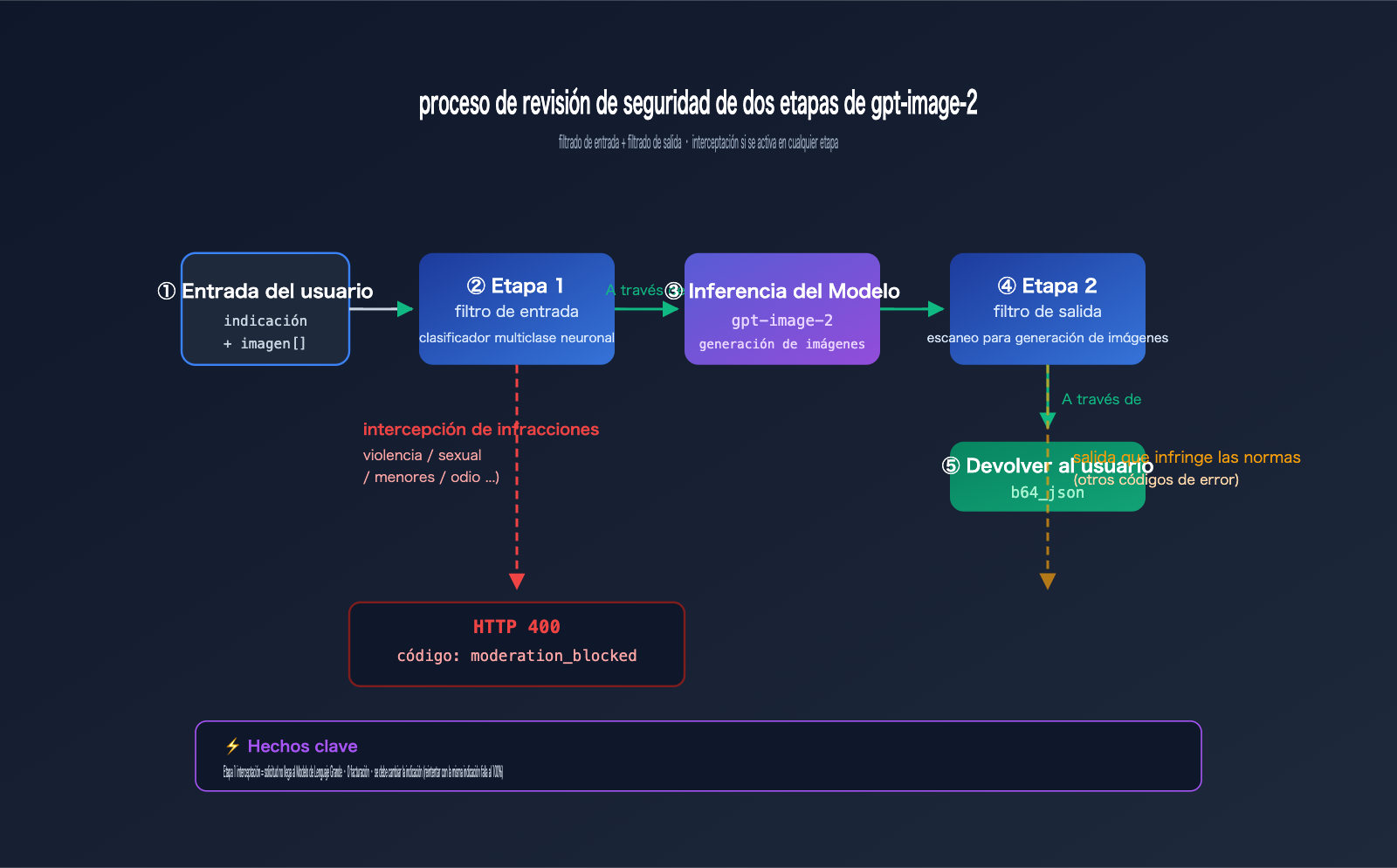
Toda la cadena de seguridad cuenta en realidad con dos niveles:
Etapa 1 · Filtro de entrada (Input Filter):
- Escanea tu texto de indicación.
- Escanea todas las imágenes de referencia cargadas (si se invoca
/v1/images/edits). - Utiliza un clasificador neuronal multiclase (multi-class neural classifier).
- Aquí es donde se activa
moderation_blocked.
Etapa 2 · Filtro de salida (Output Filter):
- Escanea las imágenes que el modelo ya ha generado.
- Si el contenido generado infringe las normas, aún puede ser interceptado.
- Normalmente devuelve un código de error diferente (no
moderation_blocked).
El caso proporcionado por el usuario activa el filtro de entrada de la Etapa 1, por lo que ni siquiera entra en la fase de inferencia del modelo. Esto también explica por qué la respuesta de error es tan rápida (normalmente < 1 segundo): no hay cola de espera ni consumo de GPU.
Diferencias de backend en el error de gpt-image-2
Un hecho que se pasa por alto fácilmente: la rigurosidad de la revisión varía según el canal de backend. Existe una diferencia significativa en la tasa de activación entre la conexión directa de OpenAI y Azure OpenAI con el mismo prompt; Azure es generalmente más estricto. Por eso, la información de error en el caso del usuario menciona "contact us at Azure support ticket": esta solicitud fue enrutada al filtro de backend de Azure.
🎯 Sugerencia de selección de canal: Si estás probando el mismo prompt en diferentes canales, es normal encontrar que algunos canales lo bloquean y otros lo permiten. Recomendamos verificar a través del canal de proxy oficial de OpenAI de APIYI (apiyi.com), el cual sigue la estrategia de filtrado oficial de OpenAI, manteniendo una tasa de activación consistente con la conexión directa de OpenAI, lo que facilita establecer una línea base de comparación.
Panorama de los 7 escenarios que disparan errores en gpt-image-2
OpenAI ha detallado explícitamente 7 categorías de escenarios de alta frecuencia en su System Card de ChatGPT Images 2.0. Comprender estos 7 escenarios es la base fundamental para redactar una indicación que cumpla con las normas de seguridad.
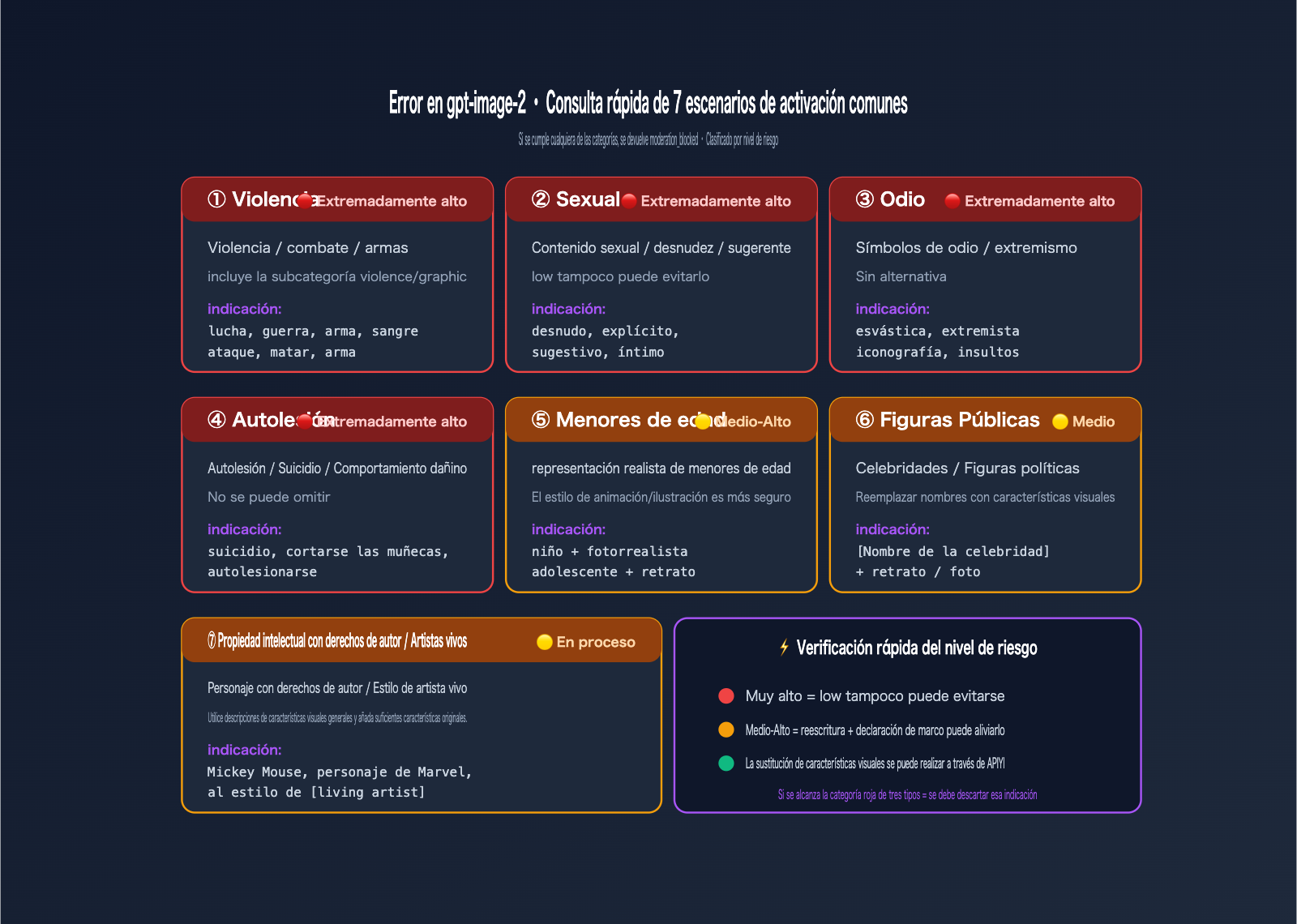
Tabla comparativa de escenarios de error en gpt-image-2
| Categoría | Ejemplos de palabras de activación de alto riesgo | Nivel de riesgo |
|---|---|---|
| Violencia | fight, war, weapon, blood, shoot, punch, kill | 🔴 Alto |
| Violencia/Gráfica | gore, gruesome, mutilation, severed | 🔴 Extremadamente alto |
| Sexual | nude, explicit, suggestive, intimate poses | 🔴 Extremadamente alto |
| Símbolos de odio | swastika, iconografía extremista específica | 🔴 Extremadamente alto |
| Autolesión | suicide, cut wrists, harming oneself | 🔴 Extremadamente alto |
| Menores | Combinación de child + fotorrealista | 🟡 Medio-Alto |
| Figuras públicas | Figuras políticas, nombres de celebridades | 🟡 Medio |
| IP con derechos de autor | Personajes de Disney, Marvel, nombres de IP conocidos | 🟡 Medio |
| Artistas vivos | "in the style of [nombre del artista vivo]" | 🟡 Medio |
Desglose de la subcategoría de violencia en gpt-image-2
safety_violations=[violence] en realidad corresponde a dos subcategorías que mucha gente en la industria suele confundir:
violence → Descripción general de violencia (presencia de acciones, conflictos, armas)
violence/graphic → Detalles de violencia gráfica y sangrienta
Siempre que la indicación active cualquiera de estas dos subcategorías, se devolverá safety_violations=[violence]. Esto significa que, incluso si escribes una descripción relativamente neutral como "un soldado con un rifle", es posible que el clasificador marque toda la indicación como violencia debido al contexto general.
Análisis profundo de casos de usuario: la causa raíz del error "violence"
Volviendo al error real que mencionamos al principio: el campo safety_violations=[violence] nos indica que se ha activado un bloqueo por contenido violento, pero ¿qué palabra específica lo provocó? A continuación, te presento un enfoque de diagnóstico sistemático.
Lista de palabras que activan el error "violence" en gpt-image-2
Según los comentarios de la comunidad y nuestras pruebas, los siguientes términos aumentan significativamente la tasa de bloqueo por violencia (aunque no se limitan solo a estos):
| Tipo de palabra clave | Términos de alta frecuencia | Alternativas seguras |
|---|---|---|
| Sustantivos de armas | gun, rifle, sword, knife, weapon | ceremonial prop, movie prop, decorative blade |
| Acciones violentas | fight, attack, shoot, stab, punch | dynamic cinematic action, dramatic standoff |
| Contexto bélico | war, battle, soldier, combat | heroic struggle, historical reenactment |
| Sangre/Daño | blood, wound, scar, gore | red splatter, dramatic shadow, weathered |
| Explosión/Destrucción | explosion, destruction, debris | dramatic light burst, swirling particles |
Proceso de diagnóstico para errores en gpt-image-2
Si tu indicación (prompt) activa un bloqueo por violencia, sigue este orden para investigar:
- Revisa palabras violentas explícitas: Escanea la indicación en busca de los términos mencionados arriba.
- Revisa la intensidad de los verbos: Intenta reemplazar verbos de acción como "fight" o "attack" por descripciones de estado.
- Revisa la imagen de referencia (si es un escenario de edición): Verifica si la imagen subida contiene elementos violentos.
- Revisa el contexto general: Incluso sin palabras de alto riesgo, una descripción que forme una escena violenta en su conjunto puede activar el bloqueo.
- Intenta añadir una declaración de marco: Añade "movie still" o "theatrical scene" al principio de la indicación.
Uso del ID de solicitud en errores de gpt-image-2
El request id: 2026042723155331083492939703753 que aparece en el mensaje de error no es un adorno; es la credencial única para localizar los registros (logs). Si utilizas un canal de acceso oficial, puedes contactar al soporte técnico de la plataforma con este ID para verificar la causa exacta del bloqueo.
💡 Consejo de diagnóstico: Guarda todos los IDs de solicitud y las indicaciones originales que resulten en errores
moderation_blockedpara crear una "biblioteca de muestras de infracción" interna, útil para entrenar reglas de reescritura automática. Recomendamos exportar los registros de solicitud a través de la consola de APIYI (apiyi.com) para realizar auditorías de cumplimiento mensuales e identificar los patrones de bloqueo más frecuentes de tu equipo.
5 estrategias de optimización de indicaciones para errores en gpt-image-2
A continuación, presentamos 5 estrategias probadas en el campo para reducir la tasa de error de gpt-image-2. El orden es de mayor a menor prioridad, por lo que recomendamos aplicarlas secuencialmente.
Estrategia 1: Reescritura para desensibilización (Desensitization)
Esta es la estrategia más común y efectiva: reemplazar palabras de alto riesgo por descripciones neutras que tengan un equivalente visual. El principio fundamental es mantener el efecto visual eliminando la referencia violenta.
# ✗ Activa el bloqueo por violencia
- "Two warriors fighting with swords, blood splatter on the ground, war scene"
# ✓ Pasa tras la reescritura de desensibilización
+ "Two armored figures in dramatic standoff with ceremonial blades, red light reflections on the stone floor, cinematic composition, theatrical scene"
Cambios realizados:
fighting→dramatic standoffswords→ceremonial bladesblood splatter→red light reflectionswar scene→theatrical scene
Estrategia 2: Sustitución del sujeto real
Evita hacer referencia directa a figuras públicas, celebridades o personajes con derechos de autor; utiliza en su lugar descripciones de características visuales.
# ✗ Activa el bloqueo por public_figures o copyrighted_ip
- "A portrait of [Nombre de celebridad] in business suit"
- "Mickey Mouse riding a bicycle in Paris"
# ✓ Descripción segura
+ "A portrait of a charismatic 30-year-old Asian businesswoman with shoulder-length black hair, wearing a tailored navy suit"
+ "A friendly anthropomorphic mouse character with round black ears and red shorts, riding a bicycle near the Eiffel Tower"
Nota: Las "descripciones de estilo" completas aún pueden activar bloqueos en escenarios de personajes con derechos de autor, ya que el moderador juzga basándose en la similitud visual, no solo en la coincidencia de texto. Se recomienda añadir suficientes características "originales".
Estrategia 3: Declaración de marco de escena
Añade un marco artístico o creativo explícito al principio de la indicación para indicar al clasificador que se trata de una creación y no de la realidad.
- "Soldiers running across a battlefield"
+ "Movie still from a 1940s war drama: soldiers running across a foggy field, sepia tones, film grain texture"
- "Action scene with gunfire"
+ "Video game cutscene illustration: heroic action sequence with stylized energy effects, comic book style"
Palabras de marco comunes:
movie still/film stilltheatrical scene/stage performancevideo game cutscene/game illustrationcomic book panel/manga stylehistorical reenactment/museum dioramaoil painting/watercolor sketch
Estrategia 4: Descomposición en múltiples pasos
Los escenarios complejos y de alto riesgo pueden dividirse en varios pasos:
# Paso 1: Generar una "imagen de referencia de estilo" (sin elementos sensibles)
step1_prompt = "Cinematic storyboard sketch, dramatic composition, sepia tones, no text"
style_ref = client.images.generate(model="gpt-image-2", prompt=step1_prompt)
# Paso 2: Generar la imagen final usando la descripción de estilo + contenido neutro
step2_prompt = "Two figures in dramatic standoff, sepia tones, cinematic storyboard style, dust particles in the air"
final_image = client.images.generate(model="gpt-image-2", prompt=step2_prompt)
Este flujo de trabajo de "estilo primero, contenido después" puede reducir significativamente la sensibilidad de una sola indicación.
Estrategia 5: Ajuste del parámetro de moderación
La API proporciona el parámetro moderation para controlar la sensibilidad (solo aplicable a modelos de imagen de la familia OpenAI):
response = client.images.generate(
model="gpt-image-2",
prompt="A dramatic action scene from a noir film",
moderation="low", # El valor predeterminado es auto, se puede bajar a low
size="1024x1024",
quality="medium"
)
Recordatorio importante:
moderation: "low"no desactiva la revisión, solo relaja el umbral.- El contenido extremadamente peligroso (sexo, autolesiones, realismo con menores, símbolos de odio) será bloqueado incluso en "low".
- Si después de ajustar a "low" sigue apareciendo
moderation_blocked, significa que realmente se ha cruzado la línea y debes modificar la indicación. - Ten precaución al usar "low" en productos orientados al usuario final (riesgos de cumplimiento).
🚀 Consejo de inicio rápido: Intenta primero las estrategias 1-3 (reescritura + sustitución + declaración de marco), ya que pueden resolver más del 80% de los errores
moderation_blocked. Recomendamos utilizar la interfaz unificada de APIYI (apiyi.com) para verificar primero si la indicación es realmente conforme conmoderation: autoantes de decidir si es necesario bajar a "low".
Comparativa práctica: optimización de errores en gpt-image-2
A continuación, presento 4 escenarios reales que demuestran el efecto concreto de la optimización de indicaciones.

Caso 1 de optimización de error en gpt-image-2: Póster de película de acción
# ✗ Antes de la optimización (dispara violencia)
- "An action movie poster featuring a male hero firing a gun at enemies, blood splatter background"
# ✓ Después de la optimización
+ "Cinematic action movie poster: a male protagonist in dramatic pose, holding a stylized prop, dynamic motion lines, red gradient background, theatrical lighting, film grain"
Caso 2 de optimización de error en gpt-image-2: Ilustración de personaje de juego
# ✗ Antes de la optimización (dispara violencia)
- "Fantasy warrior with bloody sword, severed enemy head at his feet, gore details"
# ✓ Después de la optimización
+ "Fantasy warrior video game character art: armored figure with ornate ceremonial blade, defeated stylized monster silhouette at his feet, JRPG illustration style, painterly textures"
Caso 3 de optimización de error en gpt-image-2: Ilustración educativa histórica
# ✗ Antes de la optimización (dispara violencia)
- "World War II soldiers fighting in trenches with rifles and explosions"
# ✓ Después de la optimización
+ "Historical educational illustration depicting a 1940s European trench scene: figures in period uniforms, weathered terrain with dramatic atmospheric effects, sepia documentary style, museum diorama aesthetic"
Caso 4 de optimización de error en gpt-image-2: Imagen conceptual de publicidad comercial
# ✗ Antes de la optimización (dispara figuras públicas)
- "[Nombre de celebridad] holding our coffee product in his usual style"
# ✓ Después de la optimización
+ "Charismatic 35-year-old male model with confident smile, casual blazer, warmly holding a takeaway coffee cup, modern minimalist café background, professional commercial photography"
Mejores prácticas de ingeniería para reducir la tasa de errores de gpt-image-2
Si tu proyecto realiza miles de llamadas diarias a gpt-image-2, revisar manualmente cada indicación no es viable. Aquí tienes varias estrategias de ingeniería para reducir la tasa de errores de gpt-image-2.
Flujo de pre-validación para errores de gpt-image-2
Antes de invocar la API de imágenes, realiza una pre-validación utilizando la Moderations API:
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1"
)
def safe_generate(prompt: str, max_rewrites: int = 3):
# Paso 1: Pre-validación
mod = client.moderations.create(input=prompt)
flagged = mod.results[0].flagged
categories = mod.results[0].categories
if flagged:
offending = [k for k, v in categories.model_dump().items() if v]
raise ValueError(f"La indicación activó la pre-validación: {offending}")
# Paso 2: Invocación real
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="medium"
)
La pre-validación puede bloquear entre el 60 y el 70% de las solicitudes de alto riesgo, evitando llamadas innecesarias.
Pipeline de reescritura automática para errores de gpt-image-2
Para las plantillas de indicaciones en producción, puedes construir un reescritor ligero:
SENSITIVE_REPLACEMENTS = {
r"\bgun\b": "ceremonial prop",
r"\bsword\b": "ornate ceremonial blade",
r"\bblood\b": "red splatter",
r"\bfight\b": "dramatic standoff",
r"\bwar\b": "heroic struggle",
r"\battack\b": "dynamic motion",
r"\bweapon\b": "stylized prop",
r"\bkill\b": "defeat",
r"\bshoot\b": "aim",
}
import re
def desensitize(prompt: str) -> str:
out = prompt
for pattern, replacement in SENSITIVE_REPLACEMENTS.items():
out = re.sub(pattern, replacement, out, flags=re.IGNORECASE)
if not out.lower().startswith(("movie still", "video game", "theatrical")):
out = "Cinematic movie still: " + out
return out
Encapsulamiento de reintento inteligente para errores de gpt-image-2
Para una estrategia de reintento específica ante moderation_blocked, recuerda: no reintentes exactamente lo mismo, debes reescribir la indicación primero:
from openai import BadRequestError
def generate_with_rewrite(prompt: str, max_attempts: int = 3):
current = prompt
for attempt in range(max_attempts):
try:
return client.images.generate(
model="gpt-image-2",
prompt=current,
size="1024x1024"
)
except BadRequestError as e:
if "moderation_blocked" not in str(e):
raise # Otros errores 400 no deben reintentarse
print(f"[{attempt+1}/{max_attempts}] Se activó la moderación, aplicando reescritura de desensibilización...")
current = desensitize(current)
if attempt == max_attempts - 1:
# En el último intento, añadir moderation: low
return client.images.generate(
model="gpt-image-2",
prompt=current,
moderation="low",
size="1024x1024"
)
raise RuntimeError("Todas las estrategias de reescritura fallaron")
Panel de monitoreo de cumplimiento para errores de gpt-image-2
El entorno de producción debe registrar métricas clave de cada infracción:
| Métrica | Propósito |
|---|---|
| Tasa de infracción (bloqueos/solicitudes totales) | Salud general |
Distribución por categorías de safety_violations |
Identificar tipos de infracción frecuentes |
| Top 10 de indicaciones que activan infracciones | Optimizar plantillas problemáticas |
| Tasa de éxito tras reescritura | Evaluar la efectividad del reescritor |
🎯 Consejo de despliegue en producción: Sugerimos utilizar la tasa de infracción como una métrica SLO central. Una línea de producción saludable suele tener una tasa de infracción < 2%; si supera el 5%, indica problemas sistémicos en las plantillas de indicaciones. Recomendamos realizar análisis diarios mediante el panel de control de APIYI (apiyi.com) para localizar plantillas de alta incidencia y reescribirlas de forma centralizada.
Preguntas frecuentes sobre errores de gpt-image-2
P1: ¿Se cobra si gpt-image-2 arroja un error de moderation_blocked?
No. El clasificador de seguridad intercepta la solicitud antes de que llegue al modelo, por lo que no se consume ningún token ni tiempo de GPU. Tanto OpenAI como APIYI siguen esta regla. Si ves cargos en tu factura, contacta a la plataforma para verificar. Recomendamos verificar los registros de cargos por cada request_id en el panel de control de APIYI (apiyi.com) para asegurar que las solicitudes bloqueadas tengan un costo de 0.
P2: ¿Por qué no funciona reintentar con la misma indicación si gpt-image-2 falla?
Porque el clasificador de seguridad es determinista: el resultado de la clasificación para una misma entrada es estable, a diferencia de los modelos generativos que tienen aleatoriedad. Reintentar 100 veces dará 100 bloqueos idénticos. La única solución es modificar la indicación.
P3: ¿Puede moderation: low desactivar completamente la revisión?
No. low solo reduce el umbral de sensibilidad, siendo más permisivo con contenido moderadamente sensible, pero el contenido extremadamente peligroso (sexual, autolesiones, realismo con menores, símbolos de odio, líderes políticos, etc.) será bloqueado incluso con low. Es un error considerar esto como un "interruptor de apagado".
P4: ¿Por qué mi indicación parece inofensiva y aun así fue bloqueada?
Existen tres posibilidades:
- Contexto general: Las palabras individuales son inofensivas, pero la combinación forma un escenario prohibido.
- Palabras polisémicas: Por ejemplo, "shoot a photo" puede ser malinterpretado como un término violento.
- Diferencias en el backend: El backend de Azure es más estricto que la conexión directa a OpenAI.
Para el segundo caso, añadir un marco de contexto ("professional photography session") ayuda mucho. Recomendamos utilizar APIYI (apiyi.com) para guardar estos casos de "falsos positivos" en una base de conocimiento interna como material para iterar tus plantillas.
P5: ¿Puedo saber qué palabra específica activó el error de gpt-image-2?
La API no devuelve la palabra desencadenante específica, solo la categoría (ej. [violence]). Es una decisión de diseño de OpenAI para evitar que se utilice como una "guía para evadir". Para localizar la palabra, realiza una búsqueda binaria: divide la indicación en dos y pruébalas por separado.
P6: ¿Qué hacer si hay una infracción en la imagen de referencia (escenarios de edición)?
La Etapa 1 del endpoint /v1/images/edits escanea simultáneamente el texto de la indicación y todas las imágenes de referencia cargadas. Si la imagen de referencia es la que infringe:
- Verifica si contiene violencia, sugerencias sexuales o personajes con derechos de autor.
- Preprocesa la imagen localmente (recortar o desenfocar áreas sensibles).
- Si es una foto de una persona real, confirma que no viola las políticas de figuras públicas.
P7: ¿Las categorías de infracción de gpt-image-2 coinciden con las de la Moderations API de OpenAI?
Son mayormente consistentes, pero con diferencias. Las categorías de la Moderations API son más detalladas (11), mientras que las de generación de imágenes son más generales (7-9). Se recomienda usar la Moderations API como herramienta de pre-validación, pero no asumas que los resultados son idénticos; a veces, una indicación aprobada por Moderations puede ser bloqueada por el modelo de imágenes.
P8: ¿Se pueden apelar los errores de gpt-image-2?
Sí, pero con resultados limitados. El request_id del mensaje de error puede usarse para contactar al soporte técnico. Experiencia práctica: si es un falso positivo (ej. contenido neutral para fines médicos o educativos), la plataforma podría incluirlo en una lista blanca; si realmente infringe las normas, la apelación no servirá. Recomendamos enviar la apelación a través del sistema de tickets de APIYI (apiyi.com) incluyendo el request_id completo y una explicación del caso de uso para mejorar la eficiencia del proceso.
Resumen: De los errores en gpt-image-2 a una indicación eficiente y conforme a las normas
Tras completar los 7 capítulos de este artículo, ya deberías dominar el sistema completo de gestión de errores de gpt-image-2:
- ✅ Comprender la esencia ——
moderation_blockedes un error 400 a nivel de solicitud; no genera cargos y no debe reintentarse. - ✅ Dominar la arquitectura —— Revisión de seguridad en dos etapas (Etapa 1: filtrado de entrada + Etapa 2: filtrado de salida).
- ✅ Conocer los escenarios de activación —— 7 categorías principales de infracción y detalles de la subcategoría de violencia.
- ✅ Diagnosticar infracciones —— Localización precisa mediante el campo
safety_violations. - ✅ 5 estrategias de optimización —— Reescribir para reducir la sensibilidad, sustitución de sujetos, declaración de marcos, descomposición en varios pasos y parámetros de moderación.
- ✅ Soluciones de ingeniería —— Pre-validación, reescritura automática, reintento inteligente y monitoreo de cumplimiento.
La lección más importante: El error moderation_blocked en gpt-image-2 no es un error técnico (bug), sino el límite de cumplimiento del producto. En lugar de quejarse de la rigurosidad, es mejor considerar la "ingeniería de indicaciones conforme a normas" como una capacidad de producción, lo cual es, precisamente, una de las competencias centrales para el despliegue de productos de IA en el mercado de consumo (C-end).
Si tu equipo se enfrenta a errores frecuentes de moderation_blocked, necesita establecer un proceso de auditoría de cumplimiento de indicaciones para la línea de producción o desea utilizar soluciones de ingeniería para reducir la tasa de infracciones, te recomendamos solicitar una clave de prueba directamente a través de APIYI en apiyi.com y ejecutar la plantilla de código de pre-validación + reescritura automática de este artículo. Todos los ejemplos se basan en el SDK oficial + el canal de servicio proxy de API de APIYI (los campos son 100% consistentes con OpenAI), lo que garantiza una alta compatibilidad para reutilizarlos directamente en tus propios proyectos.
Referencias
-
Tarjeta del sistema de OpenAI ChatGPT Images 2.0: Explicación oficial de la política de seguridad y los mecanismos de bloqueo.
- Enlace:
deploymentsafety.openai.com/chatgpt-images-2-0/live-blocking - Descripción: Incluye la arquitectura de filtrado de dos etapas y la lista completa de categorías de infracción.
- Enlace:
-
Documentación de la API de Moderación de OpenAI: Guía oficial para el uso de herramientas de pre-validación.
- Enlace:
developers.openai.com/api/docs/guides/moderation - Descripción: 11 categorías de infracción y métodos de invocación de la API.
- Enlace:
-
Políticas de uso de OpenAI: Explicación oficial sobre las políticas de uso.
- Enlace:
openai.com/policies/usage-policies/ - Descripción: Usos prohibidos, asunción de responsabilidades y requisitos de cumplimiento.
- Enlace:
-
Guía de indicaciones para modelos de generación de imágenes GPT de OpenAI: Mejores prácticas oficiales para las indicaciones.
- Enlace:
developers.openai.com/cookbook/examples/multimodal/image-gen-models-prompting-guide - Descripción: Incluye ejemplos y cómo redactar indicaciones que cumplan con las normas.
- Enlace:
-
Documentación de integración de gpt-image-2 de APIYI: Guía completa de integración en español.
- Enlace:
docs.apiyi.com/api-capabilities/gpt-image-2/overview - Descripción: Incluye detalles sobre los parámetros de moderación y el manejo de códigos de error.
- Enlace:
Autor: Equipo técnico de APIYI
Fecha de publicación: 27 de abril de 2026
Palabras clave: error gpt-image-2, moderation_blocked, safety_violations, moderación de contenido, optimización de indicaciones, APIYI, cumplimiento de OpenAI