Nota del autor: Sin necesidad de cambiar a canales de modelos económicos, detallo cómo OpenClaw ahorra costes controlando la longitud de los tokens de entrada: aislamiento de tareas en nuevas conversaciones, recuperación precisa de bloques de código en lugar de volcar todo el contenido, poda de contexto, búsqueda local QMD y otras 6 estrategias clave.
OpenClaw es famoso por su alto consumo de tokens; hay usuarios que han llegado a quemar 21,5 millones de tokens en un día, con facturas mensuales superiores a los $600. La reacción inmediata de muchos es cambiar a canales de modelos más baratos, pero esto suele sacrificar la calidad. La verdadera forma de ahorrar tokens es controlar la entrada: la cantidad de contexto que le das al modelo es el factor determinante del coste. Este artículo se centra en una cuestión fundamental: ¿cómo pasar de "volcar todo el contenido" a "alimentar con precisión" sin cambiar de modelo ni reducir la calidad?
Valor central: Al terminar de leer este artículo, dominarás 6 estrategias prácticas para controlar los tokens de entrada, con una previsión de ahorro de costes de entre el 50% y el 90%.

Puntos clave para ahorrar tokens en OpenClaw
Primero, establezcamos una premisa: este artículo trata sobre métodos para ahorrar tokens sin cambiar de modelo y sin reducir la calidad. Estás usando Claude Opus 4.6 o GPT-5 a precio completo; el modelo sigue siendo el mismo, lo que ahorras es en el lado de la entrada.
| Estrategia | Tasa de ahorro | Dificultad | Idea central |
|---|---|---|---|
| Nuevas conversaciones por tarea | 60-80% | Baja | Abrir un chat nuevo para cada tarea independiente para evitar la acumulación de historial |
| Recuperación precisa de bloques de código | 40-95% | Media | Enviar solo fragmentos de código relevantes, no el archivo completo |
| Poda de contexto | 30-50% | Baja | Limpiar manualmente o automáticamente el historial de chat innecesario |
| Búsqueda local QMD | 80-90% | Media | Búsqueda vectorial local, enviando solo los fragmentos relevantes |
| Prompt Caching | 80-90% (costo de entrada) | Baja | Usar caché para evitar enviar repetidamente las indicaciones del sistema |
| Desactivar modo Thinking | 10-50x | Baja | Desactivar el modo de pensamiento para tareas que no sean de razonamiento |
Mecanismos subyacentes del consumo de tokens en OpenClaw
Entender cómo ahorrar tokens requiere comprender por qué OpenClaw consume tantos.
Cada vez que envías un mensaje en OpenClaw, no solo se envía esa línea; se vuelve a enviar todo el historial de la conversación al modelo. Cuanto más larga es la conversación, mayor es el número de tokens de entrada en cada solicitud.
Específicamente, la entrada de una solicitud contiene:
- Indicación del sistema (System Prompt): Las instrucciones principales de OpenClaw, generalmente de 2000 a 5000 tokens.
- AGENTS.md / SOUL.md: Archivos de configuración del espacio de trabajo.
- Skills cargadas: Cada Skill habilitada ocupa tokens.
- Historial completo de la conversación: Todos los mensajes desde el inicio de la sesión hasta ahora.
- Resultados de invocación del modelo: La salida de cada lectura de archivo o ejecución de comando.
- Resultados de recuperación de memoria: Contenido relevante recuperado de la base de memoria.
En una sesión de OpenClaw que dura 30 minutos, la entrada de tokens del último mensaje puede haber alcanzado los 100,000 o incluso 1,000,000, mientras que la mayor parte del contenido de los primeros 29 minutos ya no es útil para la tarea actual.
Estrategia 1: Abrir nuevas conversaciones para diferentes tareas en OpenClaw
Esta es la estrategia más sencilla y efectiva.
Por qué las nuevas conversaciones ahorran tokens
Supongamos que haces 3 cosas en la misma sesión: corregir el error A → escribir la función B → refactorizar el módulo C. Para la tercera tarea, la entrada del modelo contiene todo el historial de chat y los resultados de lectura de archivos de las dos primeras tareas, pero esto es totalmente inútil para refactorizar el módulo C.
Misma sesión:
Historial de chat de la tarea A (20K tokens)
+ Contenido de archivos de la tarea A (30K tokens)
+ Historial de chat de la tarea B (25K tokens)
+ Contenido de archivos de la tarea B (40K tokens)
+ Mensaje actual de la tarea C (5K tokens)
= 120K tokens de entrada (de los cuales 115K son carga histórica innecesaria)
Nueva sesión:
Mensaje actual de la tarea C (5K tokens)
+ Indicación del sistema (3K tokens)
= 8K tokens de entrada (ahorro del 93%)
Mejores prácticas en escenarios de conversación
| Escenario | ¿Abrir nueva sesión? | Razón |
|---|---|---|
| Cambiar a una tarea totalmente distinta | Sí | El contexto de la tarea anterior es totalmente inútil |
| Ajustes iterativos de la misma función | Continuar | Se necesita el contexto de la discusión previa |
| Corregir errores diferentes en archivos distintos | Sí | Cada error es independiente, no requiere contexto cruzado |
| Modificaciones continuas del mismo módulo | Continuar | El modelo necesita entender la intención de las modificaciones previas |
| Conversación de más de 20 turnos | Sí o compactar | La acumulación histórica ya es muy grande |
🎯 Consejo práctico: Un criterio simple: si necesitas decir "olvida lo anterior, ahora haz otra cosa", simplemente abre una nueva conversación.
Este principio no solo se aplica a OpenClaw, sino también a Claude Code y otras herramientas de codificación con IA. Cada solicitud de API independiente realizada a través de APIYI (apiyi.com) es naturalmente una "nueva sesión", por lo que no hay problemas de acumulación de contexto.
Estrategia 2: Recuperación precisa de bloques de código con OpenClaw, sin cargar todo el archivo
Este es el punto central de este artículo: ¿Cómo hacer que el modelo vea solo los bloques de código que necesita modificar, en lugar de enviarle el archivo completo o incluso todo el proyecto?
La esencia del problema: ¿Por qué "cargar todo" es un desperdicio?
Los datos de investigación muestran que los agentes de codificación de IA desperdician el 80% de sus tokens en "buscar cosas". Un escenario típico: le pides a OpenClaw que modifique una función, y este lee 25 archivos solo para encontrar las 3 funciones realmente relevantes. El costo en tokens de leer esos 25 archivos corre por tu cuenta.
Un archivo de 1000 líneas tiene aproximadamente entre 15,000 y 25,000 tokens. Si solo necesitas modificar 20 líneas (unos 300-500 tokens), pero se le entrega el archivo completo al modelo, el 96-98% de los tokens de entrada se desperdician.
4 métodos para la recuperación precisa de bloques de código en OpenClaw
Método 1: Especificar claramente el archivo y el número de línea
No digas "modifica la función de inicio de sesión", di "modifica la función handleLogin en las líneas 45-78 de src/auth/login.ts". Cuanto más precisa sea la instrucción, menos archivos tendrá que leer OpenClaw.
❌ "Arregla el error de inicio de sesión"
→ OpenClaw lee más de 10 archivos, consume más de 200K tokens
✅ "Arregla la comprobación de puntero nulo en la línea 52 de src/auth/login.ts"
→ OpenClaw solo lee la parte relevante de 1 archivo, consume ~20K tokens
Método 2: Utilizar la búsqueda semántica local QMD
QMD (Quick Memory Database) de OpenClaw puede crear un índice vectorial local, recuperando fragmentos de código relevantes para enviar solo el contenido más importante al modelo.
Cómo activarlo: habilita QMD en la configuración de OpenClaw; este indexará automáticamente los archivos de tu proyecto y el historial de conversaciones. En consultas posteriores, QMD encontrará primero los bloques de código relevantes localmente y enviará solo los fragmentos que coincidan con precisión al modelo.
Método 3: Usar la sintaxis @file para referencias directas
En OpenClaw puedes usar la sintaxis @file para referenciar archivos con precisión, evitando que el modelo realice búsquedas por su cuenta:
Modifica la función handleLogin en @src/auth/login.ts,
añadiendo la lógica de manejo para cuando el refreshToken expire.
Consulta el método isTokenExpired en @src/auth/token.ts.
De esta forma, OpenClaw solo cargará los 2 archivos que especificaste, en lugar de escanear todo el directorio src/auth/.
Método 4: Guía mediante archivo de estructura del proyecto
Escribe una descripción general de la estructura del proyecto en AGENTS.md o SOUL.md para que OpenClaw sepa "qué función está en qué archivo", reduciendo el escaneo exploratorio de archivos.
## Estructura del proyecto
- Autenticación: src/auth/ (login.ts, token.ts, session.ts)
- Gestión de usuarios: src/user/ (profile.ts, settings.ts)
- Rutas API: src/routes/ (auth.route.ts, user.route.ts)
Esta descripción general solo ocupa unos cientos de tokens, pero puede ayudar a OpenClaw a ahorrar decenas de miles de tokens en escaneos de archivos innecesarios.

Estrategias tres a seis: Trucos avanzados de OpenClaw para ahorrar tokens
Estrategia tres: Poda de contexto (Context Pruning)
OpenClaw admite la poda de contexto tanto manual como automática. Cuando una conversación se vuelve demasiado larga, puedes limpiar los mensajes históricos que ya no son necesarios.
OpenClaw 2026.3.7 introdujo los Context Engine Plugins, que permiten a plugins de terceros ofrecer estrategias alternativas de gestión de contexto (anteriormente, esta parte estaba codificada de forma rígida en el núcleo). El plugin lossless-claw puede comprimir el historial de la conversación sin perder información crítica.
Recomendaciones prácticas:
- Después de completar cada subtarea, limpia manualmente las salidas de llamadas a herramientas que no sean relevantes.
- Establece
contextTokens: 50000para limitar el tamaño de la ventana de contexto. - Utiliza la función
compactpara comprimir el historial de la conversación.
Estrategia cuatro: Búsqueda semántica local QMD
QMD (Quick Memory Database) es la función de búsqueda vectorial local de OpenClaw. Crea una base de datos vectorial en el dispositivo local para indexar el historial de conversaciones y documentos. Al realizar una consulta, primero busca el contenido relevante de forma local y solo envía los fragmentos más importantes al modelo.
Resultado: Reduce el costo de tokens de entrada en un 80-90%.
Estrategia cinco: Aprovechar el almacenamiento en caché de indicaciones (Prompt Caching)
Tanto Claude como la familia de modelos GPT admiten Prompt Caching: cuando las instrucciones del sistema o el contexto de uso frecuente no cambian, la API utiliza automáticamente la versión en caché, reduciendo el costo de tokens de entrada en un 80-90%.
Pero hay una limitación clave: La llamada a Claude a través del formato compatible con OpenAI (/v1/chat/completions) no admite Prompt Caching; debes usar el formato nativo de Anthropic (/v1/messages). Si realizas la llamada a través de APIYI (apiyi.com), la plataforma admite el Prompt Caching en formato nativo.
Estrategia seis: Desactivar el modo "Thinking" en tareas que no requieren razonamiento
El modo Thinking/Reasoning hace que el consumo de tokens se dispare entre 10 y 50 veces. Si la tarea actual no requiere un razonamiento profundo (como un formato simple, mover archivos o reemplazar texto), desactivar el modo Thinking puede ahorrar una cantidad significativa.
| Tipo de tarea | ¿Requiere Thinking? | Diferencia de tokens |
|---|---|---|
| Análisis complejo de errores | Sí | Consumo normal |
| Diseño de arquitectura | Sí | Consumo normal |
| Formateo simple | No | Ahorro de 10-50x al desactivar |
| Mover/renombrar archivos | No | Ahorro de 10-50x al desactivar |
| Generar código base | Depende | Se puede desactivar en plantillas simples |
Nota: La compactación de contexto de Claude Code y la poda de contexto de OpenClaw resuelven el mismo problema: controlar la acumulación de tokens de entrada. Si utilizas ambas herramientas, puedes gestionar de forma unificada tus cuotas de llamadas a la API a través de APIYI (apiyi.com).
Comparativa de ahorro de tokens: OpenClaw vs. Claude Code
Ambas herramientas enfrentan el mismo problema, pero sus soluciones difieren.
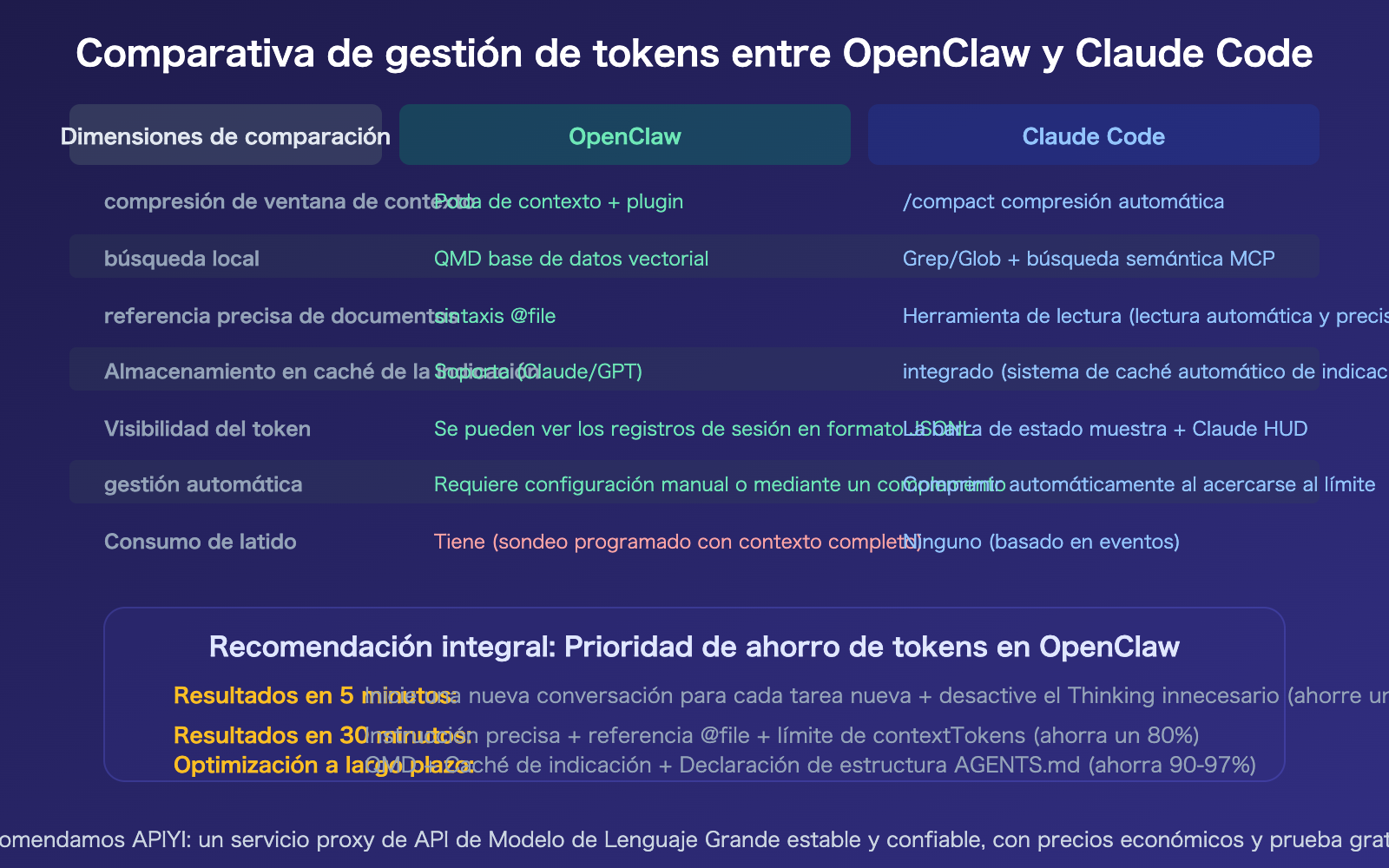
Preguntas frecuentes
Q1: ¿Qué hago si el modelo no conoce el contexto del proyecto al iniciar una nueva conversación?
Utiliza el sistema de memoria de OpenClaw y el archivo AGENTS.md. La memoria recuperará automáticamente la información relevante del contexto del proyecto en las nuevas sesiones (enviando solo los fragmentos más pertinentes, en lugar de todo el historial). Define la estructura del proyecto y los acuerdos clave en AGENTS.md para que se carguen automáticamente en cada sesión nueva; esto es mucho más eficiente que arrastrar 20 rondas de historial de conversación.
Q2: ¿Cómo puedo saber cuántos tokens he consumido en la sesión actual?
Los registros de chat de OpenClaw se guardan en archivos JSONL dentro del directorio .openclaw/agents.main/sessions/, donde puedes consultar directamente la cantidad de tokens de cada solicitud. Una opción más cómoda es utilizar el panel de uso de tu proveedor de API: al realizar la invocación del modelo a través de APIYI (apiyi.com), puedes ver en el panel el consumo exacto de tokens y el coste de cada solicitud.
Q3: ¿Qué diferencia hay entre QMD y buscar directamente con grep?
grep realiza una coincidencia exacta; si buscas "handleLogin", solo encontrarás los lugares que contengan esa cadena de texto. QMD es una búsqueda semántica: si buscas "manejo de errores en el inicio de sesión del usuario", encontrará todos los bloques de código relacionados semánticamente, incluso si el código no contiene las palabras "inicio de sesión" o "manejo de errores". La precisión de la búsqueda semántica es mayor, lo que reduce el contenido irrelevante enviado al modelo y, por tanto, ahorra más tokens.
Q4: ¿Por qué Heartbeat consume tantos tokens?
El mecanismo de Heartbeat (latido) de OpenClaw verifica periódicamente el estado de las tareas. Si el intervalo configurado es muy corto (por ejemplo, cada 5 minutos), cada latido enviará el contexto completo de la sesión al modelo. Algunos usuarios han reportado que la función de verificación automática de correo electrónico puede consumir hasta $50 al día. La solución: aumenta el intervalo de latido o pausa el Heartbeat cuando no necesites supervisión automática.
Resumen
Puntos clave para ahorrar tokens en OpenClaw (sin cambiar de modelo ni reducir la calidad):
- Los tokens de entrada son el mayor gasto (70-85%): Reenviar todo el historial de la conversación en cada solicitud hace que el chat sea más caro a medida que crece. La forma más sencilla de ahorrar es iniciar conversaciones nuevas para tareas diferentes.
- La recuperación precisa de bloques de código es la mayor palanca: Pasar de "meter todo el texto" (120K tokens) a "alimentar con precisión" (4K tokens) permite ahorrar un 96% en la misma modificación. Métodos: especificar números de línea de archivo, usar referencias
@file, búsqueda semántica QMD y declaración de estructura enAGENTS.md. - Ruta de optimización en tres etapas: Resultados en 5 minutos (nueva conversación + desactivar Thinking, ahorra un 50%) → Resultados en 30 minutos (instrucciones precisas + limitar contexto, ahorra un 80%) → A largo plazo (QMD + Caching, ahorra un 97%).
Recomendamos gestionar las llamadas a la API de OpenClaw a través de APIYI (apiyi.com), ya que la plataforma ofrece estadísticas precisas de uso de tokens y supervisión de costes, ayudándote a cuantificar el efecto real de cada optimización.
📚 Referencias
-
Guía de uso de tokens y control de costes de OpenClaw: Documentación oficial sobre la gestión de tokens.
- Enlace:
docs.openclaw.ai/reference/token-use - Descripción: Incluye la configuración de
contextTokensy la optimización de Heartbeat.
- Enlace:
-
Optimización práctica de tokens en OpenClaw: de $600 a $20: Marco de optimización completo en tres etapas.
- Enlace:
blog.laozhang.ai/en/posts/openclaw-save-money-practical-guide - Descripción: Incluye parámetros de configuración específicos y los porcentajes de ahorro esperados.
- Enlace:
-
El 80% de los tokens en agentes de codificación IA se desperdician buscando información: Estudio sobre la precisión del contexto.
- Enlace:
medium.com/@jakenesler/context-compression-to-reduce-llm-costs - Descripción: Explica por qué la recuperación precisa es más efectiva que simplemente ampliar la ventana de contexto.
- Enlace:
-
Centro de documentación de APIYI: Estadísticas de uso de tokens y monitorización de costes.
- Enlace:
docs.apiyi.com - Descripción: Soporta la gestión de la invocación del modelo para OpenClaw y Claude Code.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a participar en la sección de comentarios. Para más información, visita el centro de documentación de APIYI en docs.apiyi.com.