El mayor agujero negro de costes al ejecutar aplicaciones de Modelos de Lenguaje Grande nunca ha sido la salida de tokens, sino la repetición constante de la indicación del sistema y los documentos extensos. Tanto OpenAI como Anthropic han dado una respuesta: la caché de indicaciones (prompt caching), pero la filosofía de facturación de ambas empresas es, de hecho, completamente diferente: OpenAI sigue la ruta de "configuración cero y descuentos moderados", mientras que Claude apuesta por la "declaración explícita y descuentos extremos".
Este artículo, basado en la documentación oficial más reciente de mayo de 2026 y datos de pruebas de desarrolladores, compara sistemáticamente las reglas de facturación de caché de OpenAI y Claude a través de seis dimensiones: longitud mínima de la indicación, requisitos de estructura, recargo por escritura, descuento por lectura, control de TTL y granularidad de caché. Además, calculamos cuánto dinero pueden ahorrar realmente ambas soluciones en un escenario real de 100.000 tokens.
Valor central: Al terminar de leer este artículo, podrás determinar de inmediato qué solución de caché necesita tu negocio, cuánto dinero puedes ahorrar y qué cambios de ingeniería debes realizar.

5 diferencias clave en la facturación de caché entre OpenAI y Claude
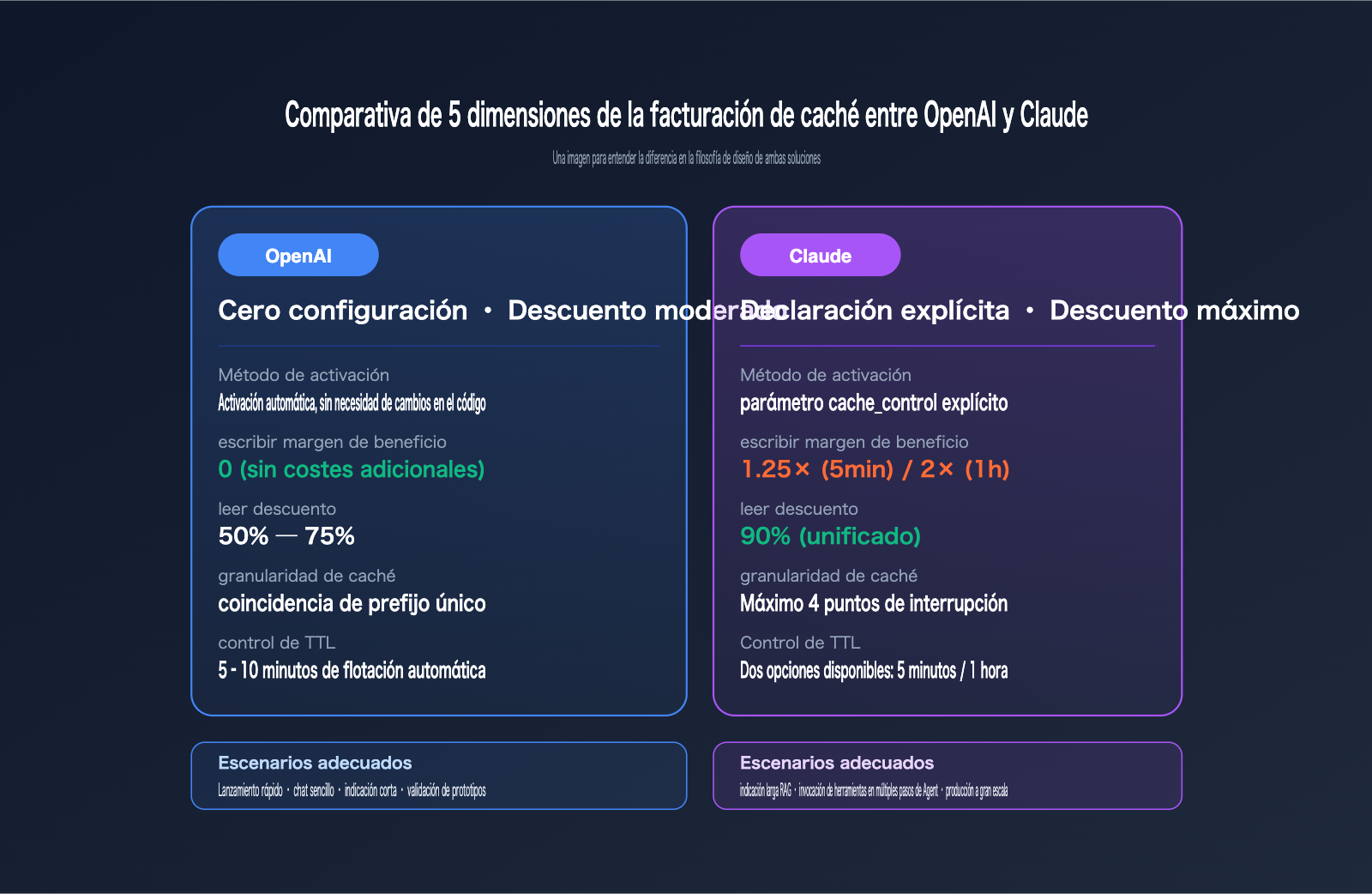
Aunque a primera vista ambas soluciones parecen basarse en el mismo concepto de "descuento por lectura de caché", la filosofía de diseño detrás de cada regla determina su rentabilidad real en diferentes escenarios de negocio. La siguiente tabla resume las 5 diferencias principales que hemos recopilado de la documentación oficial de precios.
| Dimensión de diferencia | Caché de OpenAI | Caché de Claude |
|---|---|---|
| Método de activación | Totalmente automático, configuración cero | Parámetro cache_control explícito |
| Longitud mínima de indicación | 1024 tokens (unificado) | 1024 / 4096 tokens (según el modelo) |
| Coste adicional de escritura | 0 (sin recargo) | 1.25× (5 min) o 2× (1 h) del precio base de entrada |
| Descuento por lectura | 50% – 75% de descuento | 90% de descuento (unificado) |
| Granularidad de caché | Coincidencia de prefijo único | Hasta 4 niveles de puntos de interrupción (breakpoints) |
| Control de TTL | Flotante automático de 5 a 10 minutos | Dos opciones: 5 min y 1 h |
Al entender esta tabla, se puede resumir en una frase: OpenAI te permite una integración "sin esfuerzo", mientras que Claude te propone una integración "como inversión". OpenAI es ideal para escenarios de lanzamiento rápido con presupuestos y recursos limitados, mientras que Claude es adecuado para cargas de trabajo de producción a gran escala, controlables y de largo plazo.
🎯 Consejo de comparación rápida: Si deseas realizar pruebas de carga del efecto de facturación de caché de OpenAI y Claude en el mismo proyecto, te recomendamos utilizar APIYI (apiyi.com). Esta plataforma ofrece protocolos compatibles con OpenAI para ambos proveedores, lo que te permite usar el mismo código, cambiar según el campo
modely comparar directamente los valores decached_tokensycache_read_input_tokensde ambos.
Detalles de las reglas de facturación de caché de la API de OpenAI
El diseño de facturación de caché de OpenAI es extremadamente sencillo. La regla fundamental es: siempre que el prefijo de tu indicación sea ≥ 1024 tokens y sea idéntico a la solicitud anterior, el sistema te aplicará un descuento automáticamente, sin necesidad de cambios en el código o en los encabezados.
Requisitos de longitud y estructura de la indicación para la caché de OpenAI
Las condiciones para que se produzca un acierto de caché en OpenAI se pueden dividir en dos restricciones estrictas: la longitud de la indicación debe alcanzar los 1024 tokens y la caché solo coincide con la parte del prefijo de la solicitud; cualquier contenido dinámico debe colocarse al final de la indicación. Las reglas específicas se resumen a continuación:
- Longitud mínima: La longitud total de la indicación debe ser ≥ 1024 tokens; si es menor, no entrará en la caché y no se generará ningún error.
- Coincidencia de prefijo: El sistema compara token por token desde el inicio de la indicación. Si algún elemento cambia en el medio, todo lo que sigue a esa posición se facturará sin caché.
- Incrementos de 128 tokens: La coincidencia de caché se realiza en incrementos de 128 tokens. Después de superar los 1024, cada 128 tokens idénticos adicionales seguirán contando como acierto.
- Identidad total: Incluye el mensaje del sistema, definiciones de herramientas, mensajes históricos e imágenes. Cualquier diferencia en los caracteres romperá la caché.
- Mantenimiento automático: No se requiere ID de caché ni invalidación manual. Se limpia automáticamente tras 5-10 minutos de inactividad, pudiendo extenderse a 1 hora en periodos de baja demanda.
Esto significa que si en tu aplicación el mensaje del sistema va seguido de un prefijo dinámico con marcas de tiempo o ID de usuario, toda la caché se invalidará. Mover el contenido dinámico hacia el final y colocar el contenido estático al principio es la clave para que la caché de OpenAI sea efectiva.
Rangos de descuento reales en la facturación de caché de OpenAI
El descuento por lectura de OpenAI no es una cifra única, sino que varía según el modelo. Algunos modelos nuevos, como GPT-5.5, ofrecen un descuento más agresivo del 75%. La siguiente tabla muestra los precios de caché de los principales modelos de OpenAI en mayo de 2026.
| Modelo | Entrada estándar ($/M) | Lectura de caché ($/M) | Tasa de descuento |
|---|---|---|---|
| GPT-5.5 | 5.00 | 1.25 | 75% |
| GPT-5.5 mini | 0.25 | 0.0625 | 75% |
| GPT-4o | 2.50 | 1.25 | 50% |
| GPT-4o mini | 0.15 | 0.075 | 50% |
| o1-preview | 15.00 | 7.50 | 50% |
OpenAI devuelve el número real de tokens que acertaron en la caché en el campo usage.prompt_tokens_details.cached_tokens de la respuesta. Puedes usar este campo directamente para calcular el ahorro. Automatización total + descuento moderado es el núcleo de la propuesta de valor de la caché de OpenAI.
Detalles de las reglas de facturación de caché de la API de Claude
La facturación de caché de Claude se basa en una filosofía de "compromiso explícito": debes decirle explícitamente al modelo "quiero guardar este segmento en caché", y a cambio, el modelo te ofrece un descuento extremo del 90%, aunque la escritura conlleva un sobrecoste.
Requisitos mínimos de tokens para la caché de Claude (varían según el modelo)
Mientras que OpenAI tiene un estándar de 1024 tokens, Claude diferencia por niveles de modelo, marcando una clara distinción. Hemos recopilado los umbrales mínimos de tokens para la caché de los modelos actuales de Claude:
| Modelo | Tokens mínimos para caché | Entrada estándar ($/M) | Escritura 5min ($/M) | Lectura de caché ($/M) |
|---|---|---|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 | 5.00 | 6.25 | 0.50 |
| Claude Sonnet 4.6 / 4.5 | 1024 | 3.00 | 3.75 | 0.30 |
| Claude Opus 4.1 | 1024 | 15.00 | 18.75 | 1.50 |
| Claude Haiku 4.5 | 4096 | 1.00 | 1.25 | 0.10 |
Esto significa que si utilizas la última generación de Opus o Haiku, un mensaje del sistema de 3000 tokens no se guardará en caché, por lo que necesitarás añadir contenido (como definiciones completas de herramientas o ejemplos de diálogo) para alcanzar los 4096 tokens. En la serie Sonnet, este paso no es necesario, ya que 1024 tokens son suficientes.
Reglas de TTL de doble nivel y retorno de inversión de Claude
Otra característica clave de Claude es la opción de TTL de doble nivel: 5 minutos por defecto, con opción de ampliar a 1 hora, con diferencias de precio significativas. A continuación, presentamos un análisis de retorno de inversión para la toma de decisiones:
- TTL de 5 minutos: La escritura tiene un sobrecoste del 25%. Basta con una lectura posterior para recuperar la inversión. Ideal para preguntas frecuentes y chatbots.
- TTL de 1 hora: La escritura tiene un sobrecoste del 100% (el doble). Requiere ≥ 2 lecturas para recuperar la inversión. Ideal para procesamiento por lotes (batch), tareas de agentes de múltiples pasos e informes programados.
- TTL mixto: El TTL largo debe colocarse antes que el corto, permitiendo disfrutar de estrategias de caché con diferentes tiempos de vida simultáneamente.
Es importante destacar que el TTL de 5 minutos se renueva automáticamente tras cada lectura exitosa, por lo que una caché "activa" puede prolongarse indefinidamente. Siempre que la frecuencia de solicitud sea inferior a 5 minutos, solo pagarás la tarifa de escritura una vez.
Niveles de caché y control de puntos de interrupción (breakpoint) de Claude
La mayor ventaja de Claude son sus hasta 4 puntos de interrupción (cache breakpoints), que permiten dividir la indicación en múltiples niveles gestionados de forma independiente. Esto es crucial para aplicaciones complejas. Los niveles de caché siguen estrictamente el orden descendente herramientas → sistema → mensajes: el nivel de herramientas contiene definiciones y esquemas de funciones, el nivel de sistema alberga la indicación del sistema y la configuración de roles, y el nivel de mensajes contiene el historial de diálogo y documentos de contexto.
Lo más crítico es que la invalidación de un nivel superior invalida todos los niveles inferiores. Si cambias una línea en la definición de una herramienta, la caché del sistema y de los mensajes se invalidará simultáneamente. Por el contrario, si solo cambias la última frase del usuario, la caché de los niveles anteriores seguirá siendo válida. A nivel de ingeniería, debes intentar mover el contenido que cambia con menos frecuencia hacia arriba; esta regla determina directamente la tasa de aciertos de la caché.
Además, ten en cuenta que cada punto de interrupción tiene una ventana de retroceso de unos 20 bloques: el sistema buscará hacia atrás 20 bloques de contenido desde la posición del punto de interrupción. Si encuentra una indicación histórica idéntica dentro de esa ventana, se producirá un acierto de caché. Después de 20 rondas de diálogo, se recomienda añadir otro punto de interrupción en el medio para evitar que la caché histórica quede "fuera de alcance".
💡 Recomendación de arquitectura: Para aplicaciones complejas que integran múltiples modelos, recomendamos realizar pruebas reales a través de la plataforma APIYI apiyi.com para tomar la decisión que mejor se adapte a tus necesidades. Esta plataforma admite llamadas a interfaces unificadas tanto para OpenAI como para la serie Claude, permitiéndote comparar la factura real de la misma carga de trabajo bajo los mecanismos de caché de ambos proveedores sin necesidad de reescribir el código.
Cálculo del coste real de la facturación por caché en OpenAI y Claude
El análisis teórico está muy bien, pero las diferencias reales se ven en los números de un escenario de negocio. Vamos a simular un caso de uso muy común:
- System prompt estático: 100.000 tokens (documentación técnica + ejemplos few-shot)
- Por cada solicitud del usuario: 100 tokens de entrada (pregunta real) + 1000 tokens de salida
- Frecuencia de llamadas: 1000 veces al día, distribuidas uniformemente durante el horario laboral
- Modelos comparados: GPT-5.5 vs Claude Sonnet 4.6 (ambos son los "caballos de batalla" de sus respectivas plataformas)

Tabla comparativa de costes diarios por caché entre OpenAI y Claude
La siguiente tabla desglosa los costes clave del escenario anterior. Ten en cuenta que todas las cifras corresponden únicamente al coste de los tokens de entrada, excluyendo los de salida (cuyos precios son similares en ambos casos y pueden considerarse por separado).
| Proyecto | GPT-5.5 sin caché | Caché OpenAI activada | Sonnet 4.6 sin caché | Caché Claude 5min activada |
|---|---|---|---|---|
| Coste de escritura inicial | — | $0.50 | — | $0.375 |
| Lectura posterior (999 veces) | $499.50 | $124.875 | $299.70 | $29.97 |
| Coste diario de entrada | $500.00 | $125.38 | $300.00 | $30.35 |
| Tasa de ahorro | 0% | 75% | 0% | 90% |
| Coste mensual (30 días) | $15,000 | $3,761 | $9,000 | $910 |
La conclusión es clara: con la misma carga de trabajo, el coste mensual de Claude Sonnet 4.6 con caché activada es aproximadamente el 24% del coste de GPT-5.5 con caché. Si tu negocio se basa en el modelo de "system prompt largo + preguntas cortas", la ventaja de costes de Claude crecerá linealmente con el volumen de llamadas.
Sin embargo, hay dos premisas implícitas que debes tener en cuenta:
- La caché debe ser efectiva: Si el system prompt cambia constantemente, el ahorro en ambas soluciones se reducirá drásticamente.
- No se considera la diferencia de capacidades: La calidad de salida entre GPT-5.5 y Sonnet 4.6 puede variar según la tarea, por lo que debes evaluar el rendimiento según tus indicadores de negocio.
💰 Consejo de optimización de costes: Para proyectos sensibles al presupuesto, considera utilizar la plataforma APIYI (apiyi.com) para realizar la invocación del modelo. Esta plataforma ofrece métodos de facturación flexibles y precios más competitivos, ideales para que equipos pequeños y desarrolladores independientes validen el ROI real de sus estrategias de caché sin necesidad de gestionar dos sistemas de facturación distintos.
Recomendaciones de escenarios para la facturación con caché en OpenAI y Claude
El precio es solo una variable más. Hay que considerar si realmente vale la pena realizar cambios de ingeniería para implementar el caché, si se puede garantizar una tasa de acierto estable y si la solución es compatible con una arquitectura de múltiples modelos. A continuación, presento recomendaciones claras basadas en escenarios de negocio.
Escenarios típicos para elegir el caché de OpenAI
El mayor atractivo del caché de OpenAI es su "integración transparente", ideal para equipos que no cuentan con recursos de ingeniería dedicados a la optimización de indicaciones (prompt engineering) o para etapas tempranas donde la complejidad del negocio aún no es estable.
- Chatbots sencillos y respuestas de atención al cliente (FAQ), donde la indicación del sistema no es muy larga pero el volumen de llamadas es alto.
- Etapas de validación rápida de prototipos, donde se prioriza reducir la fricción de desarrollo para ver resultados antes de optimizar.
- Proyectos que ya utilizan intensivamente el ecosistema de OpenAI (llamadas a funciones, salidas estructuradas, etc.) y no desean añadir nuevos SDKs.
- Entornos de colaboración entre múltiples equipos donde no se puede garantizar que todos utilicen correctamente el parámetro
cache_control.
Escenarios típicos para elegir el caché de Claude
Las ventajas del caché de Claude se potencian al máximo en tres escenarios: indicaciones largas, lectura de alta frecuencia y cargas de producción controlables.
- Indicaciones de sistema largas + RAG de documentos extensos: Por ejemplo, incluir todo un manual de producto en la indicación del sistema, donde un descuento del 90% resulta extremadamente atractivo.
- Invocación de herramientas en múltiples pasos por parte de agentes: Tanto la definición de herramientas como la indicación del sistema pueden almacenarse en caché de forma independiente, ideal para razonamientos de cadena larga.
- Tareas por lotes (Batch) / fuera de línea: Un TTL (tiempo de vida) de 1 hora combinado con lecturas de baja frecuencia (pocas veces por minuto) permite aprovechar al máximo el recargo por escritura de 2x.
- Aplicaciones con indicaciones estratificadas: Dividir plantillas, bases de conocimiento y contexto del usuario en 4 puntos de ruptura (breakpoints) para un control preciso de la expiración.
Tabla comparativa de selección: Caché de OpenAI vs. Claude
La siguiente tabla compara las dimensiones clave de decisión de ambas soluciones para que puedas contrastarlas directamente con las necesidades de tu proyecto.
| Dimensión de decisión | Caché de OpenAI | Caché de Claude | Recomendación |
|---|---|---|---|
| Coste de ingeniería | Casi nulo | Requiere cache_control |
OpenAI |
| Nivel de ahorro | 50%–75% | 90% | Claude |
| Compatibilidad con indicaciones largas | Media | Excelente | Claude |
| Adaptación a indicaciones cortas | 1024 es suficiente | Opus/Haiku requieren 4096 | OpenAI |
| Uso de Agentes / Herramientas | La definición ocupa espacio | Caché independiente | Claude |
| Madurez de normas de equipo | Difícil de fallar | Propenso a errores | OpenAI |
| Control de múltiples TTL | No soportado | Opciones de 5min / 1h | Claude |
Implementación práctica de facturación con caché en OpenAI y Claude
Después de tanta teoría, lo que realmente necesitas para poner esto en marcha son unas pocas líneas de código funcional. A continuación, te presento la forma más sencilla de habilitar esta función en ambos servicios, lista para copiar y pegar en tu proyecto.
Ejemplo de código para la facturación con caché en OpenAI
OpenAI no requiere parámetros específicos para la caché; la clave está en colocar el contenido estático al principio y el dinámico al final, verificando el acierto de caché mediante usage.prompt_tokens_details.cached_tokens.
from openai import OpenAI
client = OpenAI(
api_key="TU_CLAVE_API",
base_url="https://api.apiyi.com/v1"
)
LONG_SYSTEM = "(Tu system prompt largo de 100k tokens, debe ir al principio y ser idéntico siempre)"
response = client.chat.completions.create(
model="gpt-5.5",
messages=[
{"role": "system", "content": LONG_SYSTEM},
{"role": "user", "content": "¿Cómo está el clima hoy?"} # Contenido dinámico al final
],
)
# Verificar el acierto de caché
print(response.usage.prompt_tokens_details.cached_tokens)
Ejemplo de código para la facturación con caché en Claude
Claude requiere un cache_control explícito, el cual debe marcarse en los bloques de contenido de system o messages. A continuación, el uso típico de "system + 1 punto de interrupción (breakpoint)".
import anthropic
client = anthropic.Anthropic(
api_key="TU_CLAVE_API",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": "(System prompt largo de más de 4096 tokens, debe ir al principio)",
"cache_control": {"type": "ephemeral"} # 5 minutos por defecto, se puede cambiar a ttl="1h"
}
],
messages=[{"role": "user", "content": "¿Cómo está el clima hoy?"}],
)
# Verificar el acierto de caché
print(response.usage.cache_read_input_tokens,
response.usage.cache_creation_input_tokens)
Ver código completo con 4 puntos de interrupción (breakpoints) y caché multinivel
import anthropic
client = anthropic.Anthropic(
api_key="TU_CLAVE_API",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
tools=[
{
"name": "search_db",
"description": "...",
"input_schema": {...},
"cache_control": {"type": "ephemeral", "ttl": "1h"} # El TTL más largo arriba
}
],
system=[
{
"type": "text",
"text": "Resumen de la base de conocimientos de la empresa (no cambia)",
"cache_control": {"type": "ephemeral", "ttl": "1h"}
},
{
"type": "text",
"text": "Instrucciones dinámicas del día (se actualizan diariamente)",
"cache_control": {"type": "ephemeral"} # 5 minutos por defecto
}
],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Datos clave del informe financiero de la semana pasada..."},
{
"type": "text",
"text": "Por favor, ayúdame a resumir",
"cache_control": {"type": "ephemeral"}
}
]
}
]
)
La diferencia fundamental entre ambos es que OpenAI es totalmente transparente respecto a la caché, mientras que Claude obliga al desarrollador a definir activamente los límites de la misma. En una capa de integración unificada, basta con cambiar el campo model para alternar entre ambos modelos sin necesidad de modificar la lógica de negocio.
Recomendaciones para decidir sobre la facturación con caché: OpenAI vs Claude
Si tuviera que resumirlo en una frase: Cuanto más complejo sea tu negocio, más largos sean tus prompts y más frecuentes tus llamadas, mayor será el valor del descuento del 90% de Claude; por el contrario, si tu negocio es sencillo, los prompts cortos y necesitas rapidez, la configuración automática de OpenAI es la mejor opción.
Para la implementación, te sugiero seguir estos tres pasos:
- Paso 1: Mide la carga real, calcula el promedio de tokens de tu system prompt y el volumen diario de llamadas; estas cifras determinarán cuánto dinero puedes ahorrar con la caché.
- Paso 2: Elige el modelo principal, priorizando la opción con mayores descuentos en caché siempre que cumpla con los requisitos de tu negocio.
- Paso 3: Optimiza la ingeniería de prompts, colocando todo el "contenido repetitivo" al principio y dejando el "contenido variable" al final o tras un punto de interrupción (breakpoint).
🚀 Consejo para empezar rápido: Te recomiendo usar la plataforma APIYI (apiyi.com) para crear prototipos rápidamente. Permite unificar las llamadas a OpenAI y Claude sin tener que integrar ambos SDK por separado. Con el mismo código, solo cambias el campo
modely los campos de facturación de caché se devuelven bajo el protocolo compatible de OpenAI, facilitando la evaluación comparativa.
Preguntas frecuentes sobre la facturación de caché en OpenAI y Claude
P1: ¿Por qué mi caché de OpenAI «no funciona»?
Las razones más comunes son tres: primero, la longitud total de la indicación es inferior a 1024 tokens; segundo, el contenido dinámico (como marcas de tiempo o ID de usuario) se colocó al principio de la indicación, lo que provoca que el prefijo sea diferente en cada llamada; tercero, el intervalo entre dos solicitudes consecutivas superó los 5-10 minutos, por lo que la caché se limpió automáticamente. Te recomiendo enviar la misma indicación dos veces seguidas y observar si cached_tokens es distinto de cero; esto te ayudará a descartar rápidamente problemas de entorno.
P2: ¿Se puede evitar el umbral mínimo de 4096 tokens de Claude?
No. Los modelos Opus 4.7/4.6/4.5 y Haiku 4.5 deben alcanzar los 4096 tokens para ser incluidos en la caché. Si tu indicación del sistema tiene realmente poco más de 2000 tokens, te sugiero dos caminos: primero, cambiar a Sonnet 4.6 (que comienza a cachear desde los 1024 tokens), o bien, añadir definiciones de herramientas, ejemplos de diálogo o guías de estilo a tu indicación del sistema para alcanzar el umbral de 4096+.
P3: ¿Vale la pena el recargo del 25% por escritura en caché?
En la gran mayoría de los casos, sí. La escritura en caché de 5 minutos de Claude solo cuesta un 25% más que la entrada básica, pero cada lectura es un 90% más barata, lo que significa que con una sola lectura del mismo contenido, el recargo por escritura ya se ha amortizado. La caché de 1 hora requiere 2 lecturas para amortizarse. Si te preocupa la tasa de aciertos, primero obtén una estadística de cache_read_input_tokens de 24 horas en tu entorno de producción; los datos te mostrarán el ahorro real.
P4: ¿Puedo habilitar la caché en OpenAI y Claude al mismo tiempo?
Sí, y de hecho es lo más recomendable. Los mecanismos de caché de ambos no interfieren entre sí, por lo que puedes elegir diferentes modelos para distintos módulos de negocio en un mismo proyecto: por ejemplo, usar OpenAI para reconocimiento de intenciones (indicaciones cortas, alta frecuencia) y Claude para resúmenes de documentos largos (indicaciones largas, razonamiento profundo). Al utilizar una capa de acceso unificada para compartir el sistema de plantillas de indicación, evitarás tener que mantener dos estrategias de caché por separado.
P5: ¿Cómo pueden los desarrolladores locales probar rápidamente el efecto de la caché de OpenAI y Claude?
La ruta más directa es utilizar una plataforma de acceso unificado accesible desde el país. Recomendamos usar APIYI (apiyi.com), que ofrece interfaces con protocolo compatible con OpenAI tanto para OpenAI como para Claude, transmitiendo al mismo tiempo los campos de facturación de caché de ambos (cached_tokens y cache_read_input_tokens). Puedes ejecutar ambos modelos en un mismo script y comparar directamente el ahorro real, sin necesidad de solicitar y mantener cuentas por separado.
Resumen: Cómo elegir la facturación de caché entre OpenAI y Claude
Volviendo al conflicto central mencionado al principio: ahorrar dinero frente a ahorrar esfuerzo es la diferencia fundamental en la facturación de caché entre OpenAI y Claude. OpenAI cubre el 80% de los escenarios comunes con una configuración cero y descuentos moderados, mientras que Claude gana en cargas de trabajo de producción a gran escala, con indicaciones largas y llamadas de alta frecuencia gracias a su declaración explícita y descuentos extremos.
Principio de decisión en tres puntos:
- Indicación < 4096 tokens y negocio sencillo → Elige la caché de OpenAI, disfruta directamente de un descuento del 50-75%.
- Indicación > 4096 tokens y múltiples lecturas repetidas por minuto → Elige la caché de 5 minutos de Claude, disfruta directamente de un descuento del 90%.
- Agentes / procesamiento por lotes / llamadas que cruzan la hora → Elige la caché de 1 hora de Claude, se amortiza con 2 lecturas.
La recomendación técnica es: primero optimiza la estructura de tu indicación y luego habla de descuentos de caché. Coloca el contenido estático al principio y el dinámico al final, realiza pruebas de carga paralelas con ambas soluciones y toma la decisión final basándote en la factura real.
Te recomendamos verificar los resultados rápidamente a través de APIYI (apiyi.com) para obtener la solución de caché que mejor se adapte a tu negocio sin depender de un único proveedor.
Autor: Equipo técnico de APIYI — Especialistas en prácticas de ingeniería de API para Modelos de Lenguaje Grande. Si deseas conocer más sobre los datos de costos y rendimiento de la serie de modelos OpenAI, Claude y Gemini en escenarios de negocio reales, visita APIYI (apiyi.com) para obtener los últimos informes de evaluación y cuotas de prueba gratuitas.