Biaya terbesar dalam menjalankan aplikasi Model Bahasa Besar (LLM) sebenarnya bukan pada token output, melainkan pada system prompt dan dokumen panjang yang dikirim berulang kali. OpenAI dan Anthropic telah memberikan solusinya—prompt caching (penyimpanan petunjuk)—namun filosofi penagihan keduanya sangat berbeda: OpenAI mengambil jalur "tanpa konfigurasi, diskon moderat", sementara Claude mengambil jalur "deklarasi eksplisit, diskon ekstrem".
Artikel ini disusun berdasarkan dokumentasi resmi terbaru per Mei 2026 dan data pengujian pengembang. Kami membandingkan aturan penagihan caching antara OpenAI dan Claude dari enam dimensi: panjang minimum petunjuk, persyaratan struktur petunjuk, biaya tambahan penulisan, diskon pembacaan, kontrol TTL, dan granularitas cache. Kami juga menghitung berapa banyak uang yang bisa dihemat dengan skenario nyata sebesar 100 ribu token.
Nilai Inti: Setelah membaca artikel ini, Anda akan langsung tahu solusi caching mana yang harus digunakan untuk bisnis Anda, berapa banyak yang bisa dihemat, dan modifikasi teknis apa yang perlu dilakukan.

5 Perbedaan Utama Penagihan Caching OpenAI dan Claude
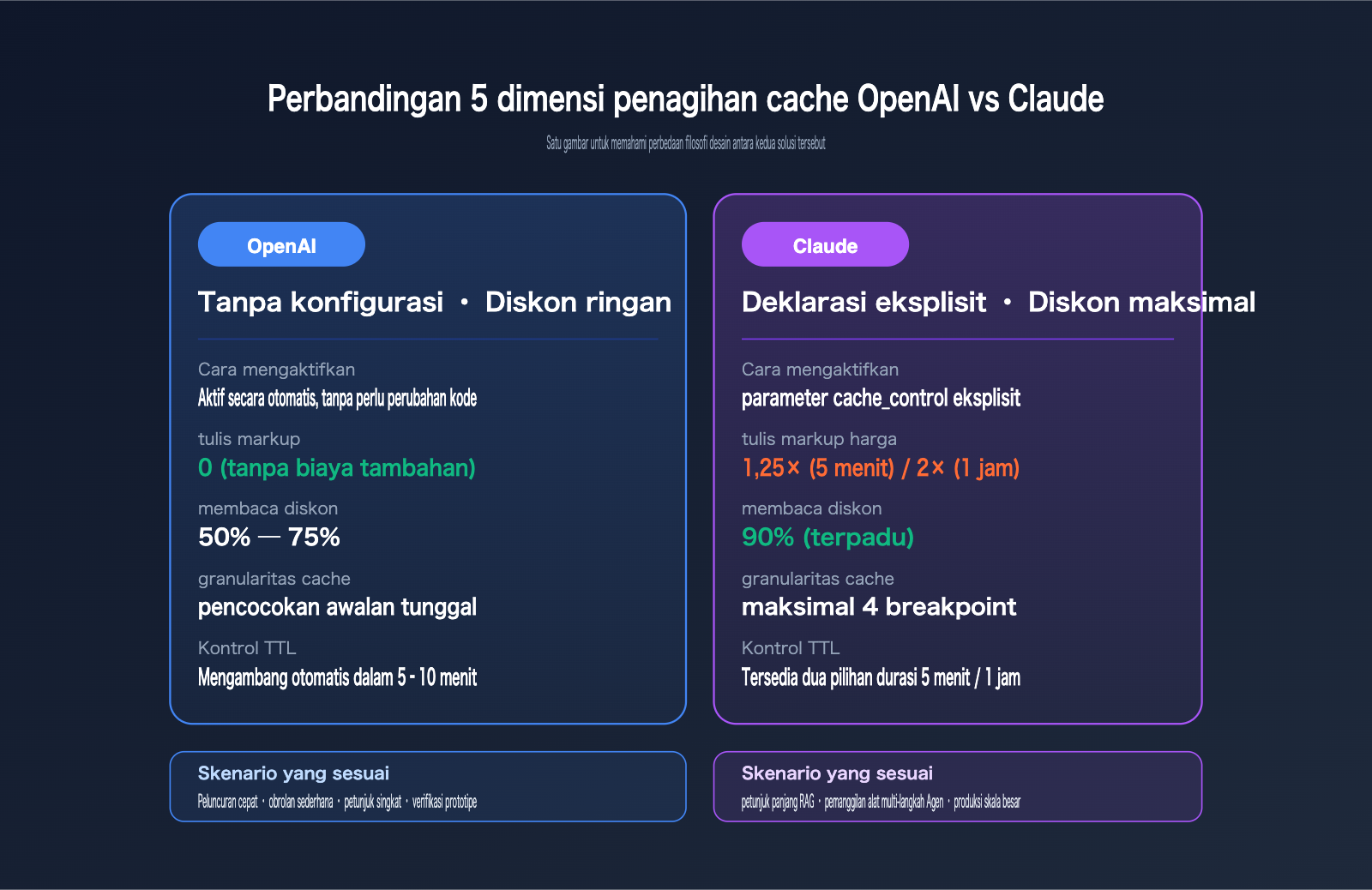
Sekilas, solusi caching kedua perusahaan ini tampak sama-sama menawarkan "diskon pembacaan cache", namun filosofi desain di balik setiap aturan menentukan efisiensi ekonomi nyata dalam skenario bisnis yang berbeda. Tabel di bawah ini merangkum 5 perbedaan utama berdasarkan dokumentasi harga resmi.
| Dimensi Perbedaan | Cache OpenAI | Cache Claude |
|---|---|---|
| Cara Mengaktifkan | Sepenuhnya otomatis, tanpa konfigurasi | Parameter cache_control eksplisit |
| Panjang Petunjuk Min. | 1024 token (seragam) | 1024 / 4096 token (tergantung model) |
| Biaya Tambahan Penulisan | 0 (tanpa biaya tambahan) | 1,25× (5 menit) atau 2× (1 jam) dari harga input dasar |
| Diskon Pembacaan | 50% – 75% off | 90% off (seragam) |
| Granularitas Cache | Pencocokan awalan tunggal | Hingga 4 lapisan breakpoint |
| Kontrol TTL | Mengambang otomatis 5–10 menit | Dua pilihan: 5 menit dan 1 jam |
Memahami tabel di atas akan membawa kita pada kesimpulan: OpenAI memungkinkan Anda untuk masuk dengan cara "gratisan", sementara Claude mengharuskan Anda untuk masuk dengan cara "investasi". OpenAI cocok untuk skenario peluncuran cepat dengan anggaran dan tenaga terbatas, sedangkan Claude cocok untuk beban kerja produksi berskala besar, terkontrol, dan berjangka panjang.
🎯 Saran Perbandingan Cepat: Jika ingin melakukan stress test pada efek penagihan caching OpenAI dan Claude dalam satu proyek yang sama, disarankan untuk menggunakan APIYI (apiyi.com). Platform ini menyediakan protokol yang kompatibel dengan OpenAI untuk kedua vendor, sehingga Anda bisa menggunakan satu kode yang sama, beralih berdasarkan bidang
model, dan langsung membandingkancached_tokenssertacache_read_input_tokensdari keduanya secara berdampingan.
Detail Aturan Penagihan Cache API OpenAI
Desain penagihan cache OpenAI sangat ringkas. Inti aturannya adalah: Selama awalan petunjuk (prompt) Anda ≥ 1024 token dan sama persis dengan permintaan sebelumnya, sistem akan otomatis memberikan diskon tanpa perlu perubahan kode atau header apa pun.
Persyaratan Panjang dan Struktur Petunjuk untuk Penagihan Cache OpenAI
Kondisi hit cache OpenAI dapat dibagi menjadi dua batasan ketat: panjang petunjuk harus mencapai 1024 token, dan cache hanya mencocokkan bagian awalan (prefix) dari permintaan. Konten dinamis apa pun harus diletakkan di bagian akhir petunjuk. Aturan spesifiknya adalah sebagai berikut:
- Panjang Minimum: Total panjang petunjuk ≥ 1024 token. Jika kurang, sistem tidak akan menggunakan cache dan tidak akan ada pesan kesalahan.
- Pencocokan Awalan: Sistem membandingkan token demi token dari awal petunjuk. Jika ada perubahan di tengah, bagian setelah perubahan tersebut akan dikenakan biaya non-cache.
- Langkah 128 Token: Hit cache dihitung dalam kelipatan 128 token. Setelah melewati 1024, setiap penambahan 128 token yang sama akan tetap mendapatkan hit cache.
- Sama Persis: Termasuk pesan sistem (system message), definisi alat (tool), pesan historis, dan gambar. Perbedaan karakter sekecil apa pun akan merusak cache.
- Pemeliharaan Otomatis: Tidak perlu ID cache atau pembatalan manual. Cache akan dibersihkan otomatis setelah 5–10 menit tidak aktif, dan bisa diperpanjang hingga 1 jam di luar jam sibuk.
Artinya, jika dalam bisnis Anda terdapat awalan dinamis seperti stempel waktu atau ID pengguna setelah petunjuk sistem, seluruh cache akan batal. Memindahkan konten dinamis ke belakang dan menempatkan konten statis di depan adalah kunci agar cache OpenAI berfungsi.
Rentang Diskon Penagihan Cache OpenAI
Diskon baca OpenAI tidak seragam, melainkan dibagi berdasarkan model. Beberapa model baru seperti GPT-5.5 memberikan diskon yang lebih agresif sebesar 75%. Tabel berikut menunjukkan perbandingan harga cache untuk model utama OpenAI per Mei 2026.
| Model | Input Standar ($/Juta) | Baca Cache ($/Juta) | Tingkat Diskon |
|---|---|---|---|
| GPT-5.5 | 5.00 | 1.25 | 75% |
| GPT-5.5 mini | 0.25 | 0.0625 | 75% |
| GPT-4o | 2.50 | 1.25 | 50% |
| GPT-4o mini | 0.15 | 0.075 | 50% |
| o1-preview | 15.00 | 7.50 | 50% |
OpenAI mengembalikan jumlah token yang berhasil di-cache melalui kolom usage.prompt_tokens_details.cached_tokens dalam respons. Anda bisa menggunakan kolom ini untuk menghitung penghematan biaya. Otomatisasi penuh + diskon menengah adalah posisi inti dari penagihan cache OpenAI.
Detail Aturan Penagihan Cache API Claude
Filosofi penagihan cache Claude lebih condong ke "komitmen eksplisit": Anda harus memberi tahu model secara jelas "bagian ini ingin saya cache", lalu model memberikan diskon ekstrem 90%, tetapi ada biaya tambahan untuk penulisan.
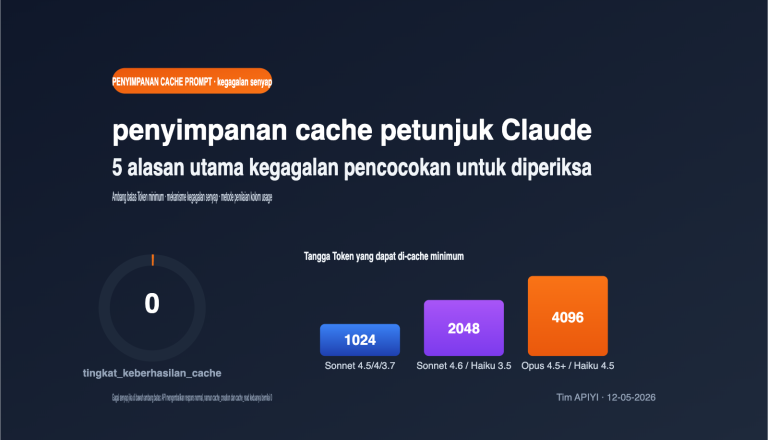
Persyaratan Token Minimum Cache Claude (Bervariasi per Model)
Jika OpenAI menggunakan standar 1024 token untuk semua, Claude membedakan ambang batas berdasarkan model. Berikut adalah ambang batas token minimum untuk cache model Claude saat ini:
| Model | Token Minimum Cache | Input Standar ($/Juta) | Penulisan 5 menit ($/Juta) | Baca Cache ($/Juta) |
|---|---|---|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 | 5.00 | 6.25 | 0.50 |
| Claude Sonnet 4.6 / 4.5 | 1024 | 3.00 | 3.75 | 0.30 |
| Claude Opus 4.1 | 1024 | 15.00 | 18.75 | 1.50 |
| Claude Haiku 4.5 | 4096 | 1.00 | 1.25 | 0.10 |
Artinya, jika Anda menggunakan Opus atau Haiku generasi terbaru, petunjuk sistem sepanjang 3000 token tidak akan di-cache. Anda perlu menambahkan konten (seperti definisi alat lengkap atau contoh percakapan) hingga mencapai 4096 token. Pada seri Sonnet, langkah ini tidak diperlukan karena 1024 token sudah cukup.
Aturan TTL Dua Tingkat dan Titik Impas Claude
Fitur kunci lain dari Claude adalah pilihan TTL dua tingkat: default 5 menit, dengan opsi peningkatan ke 1 jam, yang memiliki perbedaan harga signifikan. Berikut adalah perhitungan titik impas untuk referensi:
- TTL 5 Menit: Biaya penulisan naik 25%. Hanya perlu dibaca 1 kali untuk mencapai titik impas. Cocok untuk tanya jawab frekuensi tinggi dan chatbot.
- TTL 1 Jam: Biaya penulisan naik 100% (2x lipat). Perlu dibaca ≥ 2 kali untuk mencapai titik impas. Cocok untuk batch, tugas agen multi-langkah, dan laporan terjadwal.
- TTL Campuran: TTL panjang harus ditempatkan sebelum TTL pendek agar bisa menikmati strategi cache dengan durasi berbeda secara bersamaan.
Perlu dicatat bahwa TTL 5 menit akan diperpanjang otomatis setiap kali pembacaan berhasil. Jadi, cache yang "hidup" bisa bertahan tanpa batas selama frekuensi permintaan tetap dalam rentang 5 menit, sehingga Anda hanya membayar biaya penulisan sekali.
Kontrol Hierarki dan Breakpoint Cache Claude
Senjata utama Claude adalah maksimal 4 breakpoint cache, yang memungkinkan Anda membagi petunjuk menjadi beberapa lapisan untuk dikelola secara independen. Hierarki cache mengikuti urutan dari atas ke bawah: tools → system → messages. Lapisan tools berisi definisi alat dan skema fungsi, lapisan system berisi petunjuk sistem dan pengaturan peran, dan lapisan messages berisi percakapan historis serta dokumen konteks.
Hal yang krusial adalah kegagalan lapisan atas akan menyebabkan seluruh lapisan di bawahnya ikut gagal. Jika Anda mengubah satu baris definisi alat, cache system dan messages akan ikut terhapus. Namun sebaliknya, jika hanya mengubah kalimat terakhir pengguna, cache di lapisan sebelumnya tetap valid. Secara teknis, tempatkan konten yang paling jarang berubah di bagian atas untuk meningkatkan rasio hit cache.
Perlu diperhatikan juga bahwa setiap breakpoint memiliki jendela penelusuran sekitar 20 blok: sistem akan mencari 20 blok konten ke belakang dari posisi breakpoint. Jika ditemukan petunjuk historis yang sama persis dalam jendela tersebut, cache akan terkena (hit). Setelah percakapan melebihi 20 putaran, disarankan untuk menambahkan breakpoint di tengah agar cache historis tidak "terlewat".
💡 Saran Arsitektur: Untuk aplikasi kompleks yang menggunakan banyak model sekaligus, kami menyarankan pengujian langsung melalui platform APIYI (apiyi.com). Platform ini mendukung antarmuka terpadu untuk OpenAI dan Claude, memungkinkan Anda membandingkan tagihan nyata dari beban kerja yang sama pada kedua mekanisme cache tanpa perlu menulis ulang kode.
Perhitungan Biaya Aktual Penagihan Cache OpenAI dan Claude
Analisis teoretis hanyalah teori, perbedaan biaya yang sebenarnya harus dihitung berdasarkan skenario nyata. Mari kita buat skenario bisnis yang sangat umum:
- System prompt statis: 100.000 token (dokumentasi teknis + contoh few-shot)
- Setiap permintaan pengguna: Input 100 token (pertanyaan aktual) + Output 1.000 token
- Frekuensi pemanggilan: 1.000 kali per hari, terdistribusi merata selama jam kerja
- Model perbandingan: GPT-5.5 vs Claude Sonnet 4.6 (keduanya merupakan "kuda beban" utama dari masing-masing penyedia)

Tabel Perbandingan Biaya Harian Cache OpenAI dan Claude
Tabel di bawah ini merinci tagihan utama untuk skenario di atas. Harap dicatat bahwa semua angka adalah biaya untuk bagian input token, tidak termasuk output token (harga output kedua penyedia serupa, sehingga bisa dipertimbangkan secara terpisah).
| Item | GPT-5.5 Tanpa Cache | Cache OpenAI Aktif | Sonnet 4.6 Tanpa Cache | Cache Claude 5mnt Aktif |
|---|---|---|---|---|
| Biaya Penulisan Awal | — | $0,50 | — | $0,375 |
| Pembacaan Lanjutan (999 kali) | $499,50 | $124,875 | $299,70 | $29,97 |
| Biaya Input Harian | $500,00 | $125,38 | $300,00 | $30,35 |
| Rasio Penghematan | 0% | 75% | 0% | 90% |
| Biaya Bulanan (30 hari) | $15.000 | $3.761 | $9.000 | $910 |
Kesimpulan perbandingannya sangat jelas: Untuk beban kerja yang sama, biaya bulanan Claude Sonnet 4.6 setelah mengaktifkan cache hanya sekitar 24% dari biaya bulanan GPT-5.5 dengan cache aktif. Jika bisnis Anda adalah tipe "system prompt panjang + tanya jawab singkat", keunggulan biaya Claude akan meningkat secara linear seiring dengan skala pemanggilan.
Namun, ada dua prasyarat implisit yang perlu diwaspadai:
- Cache harus benar-benar hit: Jika system prompt sering berubah, penghematan dari kedua solusi akan menyusut drastis.
- Tidak mempertimbangkan perbedaan kemampuan model: Kualitas output antara GPT-5.5 dan Sonnet 4.6 mungkin tidak setara untuk tugas yang berbeda, sehingga perlu dinilai secara komprehensif berdasarkan metrik bisnis.
💰 Tips Optimasi Biaya: Untuk proyek yang sensitif terhadap anggaran, pertimbangkan untuk memanggil API melalui platform APIYI (apiyi.com). Platform ini menawarkan metode penagihan yang fleksibel dan harga yang lebih kompetitif, cocok bagi tim kecil maupun pengembang individu untuk memvalidasi ROI nyata dari skema cache dengan cepat, tanpa perlu mengelola dua sistem penagihan sendiri.
Rekomendasi Skenario Penagihan Cache OpenAI dan Claude
Harga hanyalah salah satu variabel. Anda juga perlu mempertimbangkan apakah perombakan teknis untuk cache sepadan, apakah stabilitas hit cache dapat terjamin, dan apakah arsitektur multi-model kompatibel. Berikut adalah rekomendasi solusi berdasarkan skenario bisnis.
Skenario Khas untuk Memilih Cache OpenAI
Daya tarik utama cache OpenAI terletak pada "integrasi tanpa hambatan", yang cocok untuk tim yang tidak memiliki tenaga teknis khusus untuk optimasi petunjuk (prompt engineering), atau untuk tahap awal bisnis yang kompleksitasnya belum stabil.
- Chatbot sederhana, jawaban FAQ layanan pelanggan, di mana system prompt tidak terlalu panjang namun volume pemanggilan tinggi.
- Tahap verifikasi prototipe yang cepat, memprioritaskan pengurangan hambatan pengembangan, melihat hasil terlebih dahulu sebelum membahas optimasi.
- Bisnis yang sudah menggunakan ekosistem OpenAI secara luas (function calling, structured outputs, dll.) dan tidak ingin menambahkan SDK baru.
- Lingkungan kolaborasi multi-tim di mana sulit untuk memastikan semua orang menggunakan parameter
cache_controldengan benar.
Skenario Khas untuk Memilih Cache Claude
Keunggulan cache Claude akan terasa maksimal pada tiga skenario: petunjuk panjang, pembacaan frekuensi tinggi, dan beban produksi yang dapat dikontrol.
- RAG dengan system prompt panjang + dokumen panjang: Misalnya, memasukkan seluruh buku panduan produk ke dalam system, diskon 90% sangat menarik.
- Pemanggilan alat multi-putaran Agent: Definisi alat + system dapat di-cache secara terpisah, cocok untuk inferensi rantai panjang.
- Batch / Tugas offline: TTL 1 jam dikombinasikan dengan pembacaan frekuensi rendah beberapa kali per menit, pas untuk memanfaatkan biaya tambahan penulisan 2×.
- Aplikasi dengan petunjuk berlapis: Memasukkan template, basis pengetahuan, dan konteks pengguna ke dalam 4 breakpoint secara terpisah untuk kontrol kedaluwarsa yang presisi.
Tabel Perbandingan Komprehensif Penagihan Cache OpenAI vs Claude
Tabel di bawah ini membandingkan dimensi keputusan utama dari kedua solusi tersebut agar Anda dapat menyesuaikannya langsung dengan situasi proyek Anda.
| Dimensi Keputusan | Cache OpenAI | Cache Claude | Rekomendasi |
|---|---|---|---|
| Biaya perombakan teknis | Hampir nol | Perlu perombakan cache_control |
OpenAI |
| Tingkat penghematan | 50%–75% | 90% | Claude |
| Kompatibilitas petunjuk panjang | Sedang | Sangat baik | Claude |
| Adaptasi petunjuk pendek | 1024 cukup | Opus/Haiku butuh 4096 | OpenAI |
| Penggunaan Agent / Tool | Definisi alat memakan petunjuk | Alat di-cache terpisah | Claude |
| Kematangan standar petunjuk tim rendah | Tidak mudah salah | Mudah bermasalah | OpenAI |
| Kontrol multi-TTL | Tidak didukung | Tersedia 5 menit / 1 jam | Claude |
Praktik Kode Penagihan Cache OpenAI dan Claude
Setelah membahas teorinya, yang kita butuhkan sekarang adalah puluhan baris kode yang siap dijalankan. Berikut adalah cara implementasi minimal yang bisa langsung Anda salin dan tempel ke dalam proyek Anda.
Contoh Kode Penagihan Cache OpenAI
OpenAI tidak memerlukan parameter khusus terkait cache. Kuncinya adalah menempatkan konten statis di depan dan konten dinamis di belakang, lalu memverifikasi hit cache melalui usage.prompt_tokens_details.cached_tokens.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
LONG_SYSTEM = "(System prompt panjang Anda yang mencapai 100 ribu token, harus diletakkan di depan dan selalu konsisten setiap saat)"
response = client.chat.completions.create(
model="gpt-5.5",
messages=[
{"role": "system", "content": LONG_SYSTEM},
{"role": "user", "content": "Bagaimana cuaca hari ini?"} # Konten dinamis diletakkan di akhir
],
)
# Verifikasi hit cache
print(response.usage.prompt_tokens_details.cached_tokens)
Contoh Kode Penagihan Cache Claude
Claude memerlukan cache_control eksplisit yang harus ditandai pada blok konten system atau messages. Berikut adalah penggunaan tipikal "system + 1 breakpoint".
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": "(System prompt panjang 4096+ token, harus diletakkan paling depan)",
"cache_control": {"type": "ephemeral"} # Default 5 menit, bisa diubah ke ttl="1h"
}
],
messages=[{"role": "user", "content": "Bagaimana cuaca hari ini?"}],
)
# Verifikasi hit cache
print(response.usage.cache_read_input_tokens,
response.usage.cache_creation_input_tokens)
Lihat kode lengkap dengan 4 breakpoint dan cache berlapis
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
tools=[
{
"name": "search_db",
"description": "...",
"input_schema": {...},
"cache_control": {"type": "ephemeral", "ttl": "1h"} # TTL terlama diletakkan paling atas
}
],
system=[
{
"type": "text",
"text": "Ringkasan basis pengetahuan perusahaan (tidak berubah dalam jangka panjang)",
"cache_control": {"type": "ephemeral", "ttl": "1h"}
},
{
"type": "text",
"text": "Instruksi dinamis hari ini (diperbarui sekali sehari)",
"cache_control": {"type": "ephemeral"} # Default 5 menit
}
],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Data kunci laporan keuangan minggu lalu..."},
{
"type": "text",
"text": "Tolong bantu saya merangkumnya",
"cache_control": {"type": "ephemeral"}
}
]
}
]
)
Perbedaan inti dari kedua kode ini adalah OpenAI tidak menyadari keberadaan cache, sementara Claude memaksa pengembang untuk memikirkan batas cache secara aktif. Pada lapisan integrasi terpadu, Anda hanya perlu mengganti kolom model agar kode bisnis yang sama dapat beralih antar model tanpa kendala.
Saran Keputusan Penagihan Cache: OpenAI vs Claude
Jika hanya boleh memberikan satu saran: Semakin kompleks bisnis Anda, semakin panjang prompt-nya, dan semakin sering pemanggilan dilakukan, maka nilai diskon 90% dari Claude akan semakin terasa. Sebaliknya, jika bisnis Anda sederhana, prompt pendek, dan waktu peluncuran sangat mendesak, konfigurasi nol dari OpenAI lebih layak dipilih.
Saat implementasi, disarankan untuk mengikuti tiga langkah berikut:
- Langkah pertama: Ukur beban kerja nyata, hitung rata-rata jumlah token pada system prompt Anda dan volume pemanggilan harian. Kedua angka ini menentukan seberapa besar penghematan biaya dari cache.
- Langkah kedua: Tentukan model utama, selama kemampuan model memenuhi kebutuhan bisnis, prioritaskan solusi dengan diskon cache yang lebih besar.
- Langkah ketiga: Lakukan rekayasa prompt, letakkan semua "konten yang selalu berulang" di depan, dan letakkan "konten yang berubah setiap saat" di belakang atau gunakan breakpoint terpisah.
🚀 Saran Memulai Cepat: Direkomendasikan menggunakan platform APIYI (apiyi.com) untuk membangun prototipe dengan cepat. Anda dapat menyatukan pemanggilan antarmuka OpenAI dan Claude tanpa perlu mengintegrasikan SDK keduanya secara terpisah. Kode yang sama dapat beralih model hanya dengan mengubah kolom model, dan kolom penagihan cache juga dikembalikan melalui protokol yang kompatibel dengan OpenAI, sehingga memudahkan evaluasi perbandingan.
Pertanyaan Umum Seputar Penagihan Cache OpenAI dan Claude
Q1: Mengapa cache OpenAI saya “tidak berfungsi”?
Ada tiga alasan paling umum: Pertama, total panjang petunjuk kurang dari 1024 token; kedua, konten dinamis (seperti stempel waktu atau ID pengguna) diletakkan di bagian depan petunjuk, yang menyebabkan awalan tidak konsisten setiap saat; ketiga, interval antara dua permintaan berturut-turut melebihi 5–10 menit, sehingga cache telah dibersihkan secara otomatis. Disarankan untuk mengirimkan petunjuk yang sama dua kali berturut-turut dan amati apakah cached_tokens bernilai bukan nol untuk mengesampingkan masalah lingkungan dengan cepat.
Q2: Bisakah ambang batas minimum 4096 token Claude dilewati?
Tidak bisa. Opus 4.7/4.6/4.5 dan Haiku 4.5 harus mencapai 4096 token agar dapat dimasukkan ke dalam cache. Jika petunjuk sistem (system prompt) Anda hanya berjumlah 2000-an token, ada dua cara yang disarankan: Pertama, beralihlah ke Sonnet 4.6 (mulai cache dari 1024 token), atau kedua, tambahkan definisi alat, contoh percakapan, panduan gaya, dan konten lainnya ke dalam sistem hingga mencapai ambang batas 4096+.
Q3: Apakah kenaikan harga 25% untuk penulisan cache sepadan?
Dalam sebagian besar kasus, sangat sepadan. Penulisan cache 5 menit Claude hanya 25% lebih mahal daripada input dasar, sementara setiap pembacaan 90% lebih murah. Artinya, untuk konten yang sama, cukup dibaca 1 kali saja, biaya tambahan penulisan cache sudah tertutup. Cache 1 jam membutuhkan 2 kali pembacaan untuk balik modal. Jika Anda khawatir tingkat keberhasilan (hit rate) kurang, tarik statistik cache_read_input_tokens selama 24 jam di lingkungan produksi; data akan menunjukkan penghematan yang sebenarnya.
Q4: Bisakah OpenAI dan Claude mengaktifkan cache secara bersamaan?
Bisa, dan sangat disarankan. Mekanisme cache keduanya tidak saling memengaruhi. Anda dapat memilih model yang berbeda untuk modul bisnis yang berbeda dalam satu proyek: misalnya, OpenAI untuk pengenalan niat (petunjuk pendek, frekuensi tinggi), dan Claude untuk ringkasan dokumen panjang (petunjuk panjang, penalaran mendalam). Melalui lapisan akses terpadu untuk berbagi sistem templat petunjuk, Anda dapat menghindari pemeliharaan dua strategi cache yang tumpang tindih.
Q5: Bagaimana pengembang di Indonesia dapat menguji efek cache OpenAI dan Claude dengan cepat?
Jalur paling langsung adalah menggunakan platform akses terpadu yang dapat diakses di Indonesia. Kami merekomendasikan APIYI (apiyi.com), yang menyediakan antarmuka protokol yang kompatibel dengan OpenAI untuk OpenAI dan Claude, sekaligus meneruskan bidang penagihan cache dari keduanya (cached_tokens dan cache_read_input_tokens). Anda dapat menjalankan kedua model dalam satu skrip dan membandingkan penghematan biaya secara langsung tanpa perlu mendaftar dan mengelola akun di kedua penyedia secara terpisah.
Kesimpulan: Cara Memilih Penagihan Cache OpenAI dan Claude
Kembali ke konflik inti di awal: hemat uang vs. hemat tenaga adalah perbedaan mendasar antara OpenAI dan Claude dalam hal penagihan cache. OpenAI mencakup 80% skenario umum dengan konfigurasi nol dan diskon menengah, sementara Claude memenangkan beban kerja produksi berskala besar dengan petunjuk panjang dan pemanggilan frekuensi tinggi melalui deklarasi eksplisit dan diskon ekstrem.
Prinsip pengambilan keputusan dalam tiga poin:
- Petunjuk < 4096 token dan bisnis sederhana → Pilih cache OpenAI, nikmati diskon langsung 50–75%.
- Petunjuk > 4096 token dan ada banyak pembacaan berulang per menit → Pilih cache 5 menit Claude, nikmati diskon langsung 90%.
- Agen / batch / pemanggilan lintas jam → Pilih cache 1 jam Claude, balik modal hanya dengan 2 kali pembacaan.
Saran teknis spesifiknya adalah: lakukan restrukturisasi petunjuk terlebih dahulu, baru bahas diskon cache. Letakkan konten statis di depan dan konten dinamis di belakang, lalu lakukan uji beban (stress test) paralel pada kedua solusi, dan buat pilihan akhir berdasarkan tagihan yang sebenarnya.
Direkomendasikan untuk memverifikasi efeknya dengan cepat melalui APIYI (apiyi.com) guna mendapatkan solusi cache yang paling sesuai untuk bisnis Anda tanpa terikat pada satu vendor saja.
Penulis: Tim Teknis APIYI — Fokus pada praktik rekayasa API Model Bahasa Besar AI. Jika Anda ingin mengetahui lebih lanjut tentang data biaya dan kinerja seri model OpenAI, Claude, dan Gemini dalam skenario bisnis nyata, kunjungi APIYI (apiyi.com) untuk mendapatkan laporan evaluasi terbaru dan kuota uji coba gratis.