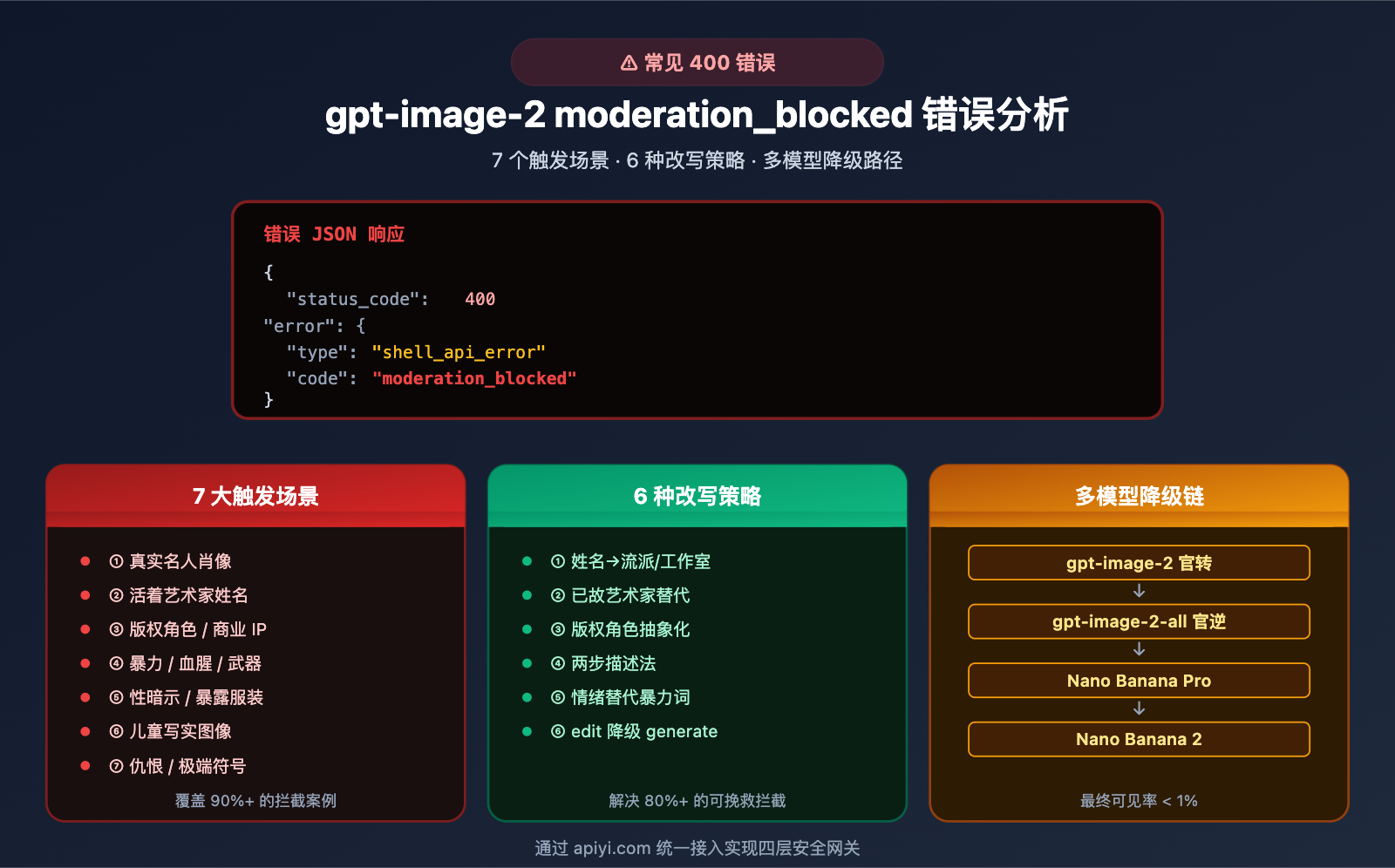
在使用 gpt-image-2 API 生产级出图时,开发者经常会遭遇这样一个令人困惑的 400 错误:
{
"status_code": 400,
"error": {
"message": "Your request was rejected by the safety system. If you believe this is an error, contact us at Azure support ticket and include the request ID 76fd2cbc-63ee-4e30-8bea-5fc2a2e1faa3.",
"type": "shell_api_error",
"code": "moderation_blocked"
}
}
这个 moderation_blocked 错误来自 OpenAI/Azure 的内容安全系统,它在模型推理之前或之后 主动拦截 认为违反政策的请求。与普通的 429 限流或 500 服务错误不同,moderation_blocked 不会自动消失——不改 prompt,重试一万次还是一样被拦。
本文系统梳理 moderation_blocked 错误的技术原理、7 大常见触发场景、诊断与复现方法,并给出 6 种提示词改写策略 + 多模型备用方案,帮助你把这类错误的发生率降到可接受水平。
一、gpt-image-2 moderation_blocked 400 错误的技术原理
1.1 错误结构拆解
上面那段错误体包含几个关键字段:
| 字段 | 含义 |
|---|---|
status_code: 400 |
HTTP 400 Bad Request,说明客户端请求被拒 |
type: shell_api_error |
API 网关层错误,而非模型推理错误 |
code: moderation_blocked |
核心错误码: 被内容安全系统拦截 |
message |
人类可读的说明,含 request id |
request id |
申诉或排查时的追踪 ID |
注意 message 里提到了 "Azure support ticket"——这是一个重要线索: 某些 gpt-image-2 部署链路最终由 Azure OpenAI 承载,所以安全系统是 Azure 的内容过滤器。Azure 的过滤规则比直连 OpenAI 更严格,这也是许多开发者在不同渠道下 moderation_blocked 触发率差异很大的根本原因。
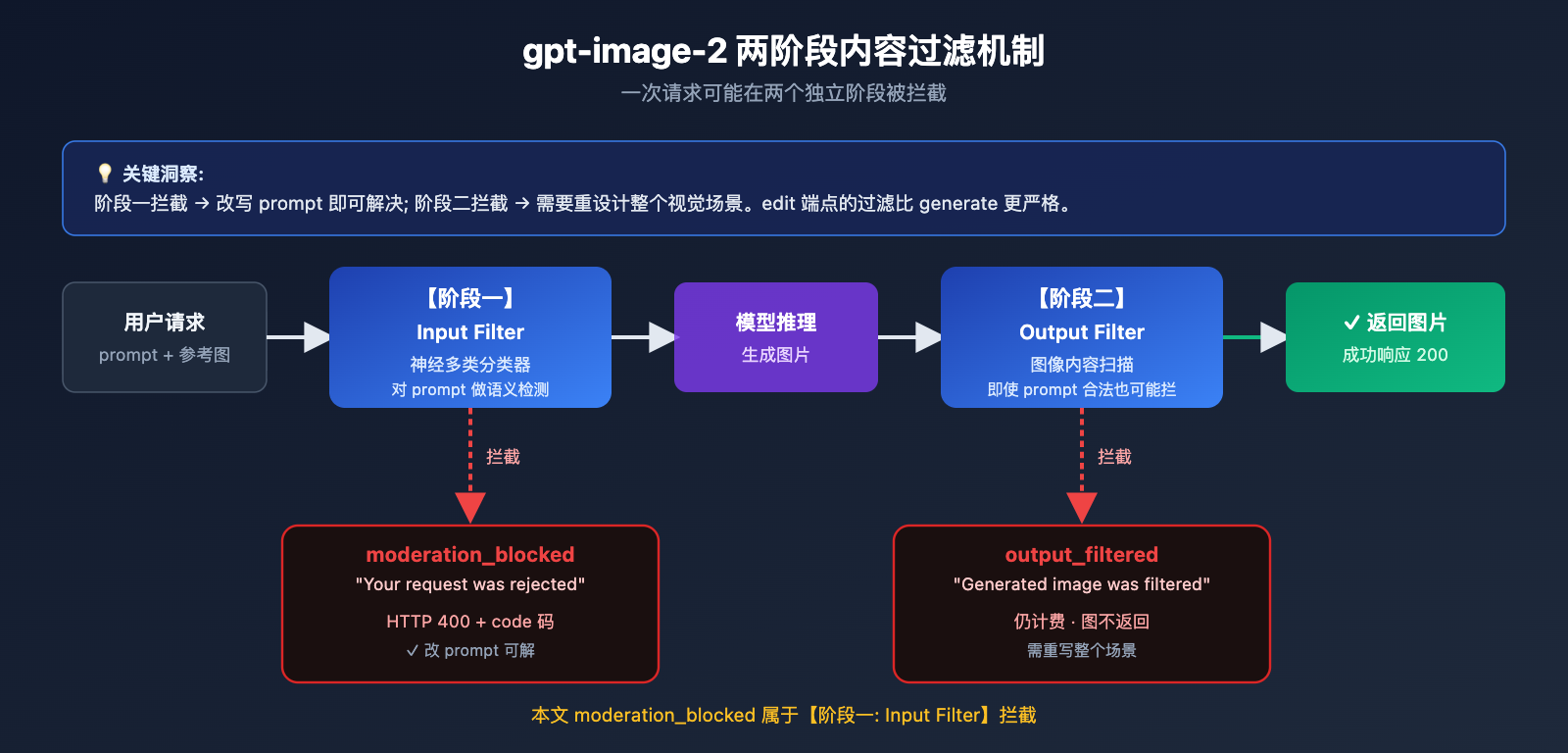
1.2 gpt-image-2 的两阶段内容过滤机制
根据 OpenAI 官方 ChatGPT Images 2.0 System Card 和 Azure OpenAI 文档,gpt-image-2 的内容审查采用 两阶段过滤:
用户请求
↓
【阶段一: 输入过滤 Input Filter】
↓ (通过)
模型推理生成图片
↓
【阶段二: 输出过滤 Output Filter】
↓ (通过)
返回图片给用户
阶段一 (Input Filter): 在模型推理之前,对 prompt 文本 + 参考图像做分类检测。使用神经多类分类器,检测违反 OpenAI 政策的内容(仇恨、暴力、性、自残、名人、版权等)。
阶段二 (Output Filter): 图像生成后再次扫描,即使 prompt 合法,如果生成出来的图"看起来"违规,依然会被拦截。
关键差异:
- 如果报错是
"Your request was rejected"→ 输入阶段被拦,改 prompt 可解 - 如果报错是
"Generated image was filtered"→ 输出阶段被拦,需要重写整个场景
本文讨论的 moderation_blocked 属于第一种——输入阶段被拦,意味着从 prompt 层面优化仍然是最有效的解决方式。
1.3 gpt-image-2 的 edit 端点过滤更严格
一个容易被忽视的事实: /v1/images/edits 端点的过滤策略比 /v1/images/generations 更严。
Azure 官方明确说明: 对图像编辑,会在生成过滤基础上增加额外安全检查,意味着 同一个 prompt + 图像,在 generation 端点能过,在 edits 端点却可能被 moderation_blocked 拦。这是设计上的故意行为,用于防止用户对已有照片做违规修改(如 deepfake、去衣等)。
二、gpt-image-2 moderation_blocked 错误的 7 大触发场景
以下 7 大场景按实际触发频率排序,覆盖了 90%+ 的 moderation_blocked 案例。
2.1 触发场景一: 真实人物肖像与名人姓名
这是最常见的触发原因。任何以下形式的 prompt 都极易触发:
❌ 高风险模式:
- 生成马斯克在火星上的照片
- 一张特朗普和奥巴马的合影
- Taylor Swift 演唱会的舞台
- 模仿 Scarlett Johansson 的女演员
OpenAI 默认对 未 opt-out 的名人肖像 采取严格保护。2025 年 10 月 Bryan Cranston 事件后,这一策略进一步收紧。即使你要生成的是"长得像某人"而非直接用名字,只要 prompt 里提到公众人物名字,就会被拦。
2.2 触发场景二: 名牌活着的艺术家与风格化表达
活着的艺术家/创作者的 姓名 是强拦截词:
❌ 高风险:
- 宫崎骏 (Hayao Miyazaki) 风格插画
- 新海诚 (Makoto Shinkai) 色调的城市夜景
- Banksy 风格的街头涂鸦
✅ 低风险等价写法:
- 吉卜力 (Ghibli) 风格 / 明亮的现代日式动画风格
- 色彩饱和的日式青春动画场景
- 现代城市街头艺术风格
规则: 把"艺术家姓名"转成"流派/工作室/风格名"。已故艺术家(Van Gogh, Monet)通常不会被拦。
2.3 触发场景三: 版权角色与商业 IP
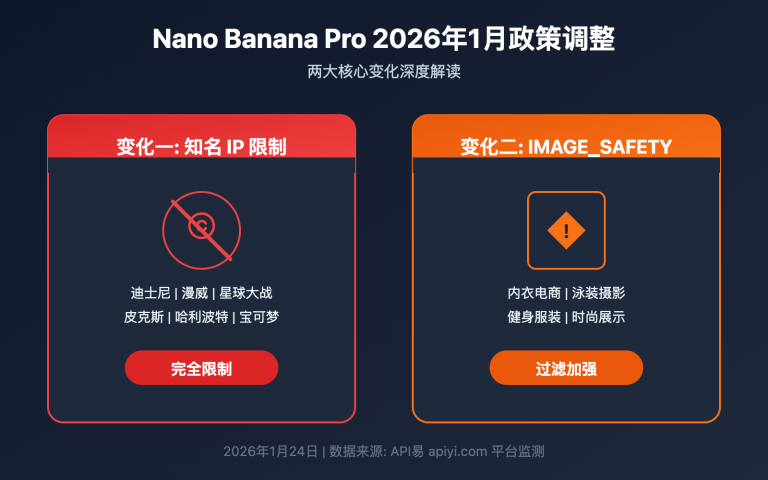
迪士尼、漫威、宫崎骏、皮克斯、任天堂等 IP 下的具名角色是硬拦截:
❌ 高风险:
- 蜘蛛侠在城市间荡漾
- 米奇老鼠的派对场景
- 一只皮卡丘在森林里
✅ 低风险等价写法:
- 一位穿红蓝超级英雄装、用丝线在霓虹都市中摆荡的原创义警角色
- 一只卡通拟人鼠标主持的复古派对
- 一只黄色电系卡通生物在森林里
规则: "灵感来自"或"类似风格"而不是直接命名角色。
2.4 触发场景四: 暴力、血腥、武器细节
❌ 高风险:
- 流血的伤口特写
- 爆炸瞬间的血肉飞溅
- AK-47 的精细产品图
✅ 规避写法:
- 深红色颜料飞溅的抽象画面
- 明亮光芒迸发伴随碎片的超级英雄场景
- 战术游戏中的武器概念图 (风格化,非写实)
规则: 用"艺术化、抽象化、风格化"替代"写实、精细、临床式"描述。
2.5 触发场景五: 性暗示与暴露服装
这是 gpt-image-2 最严格的领域之一,任何可被解读为性暗示的内容 都会拦,包括看似无害的描述:
❌ 高风险 (看似无害但会拦):
- bikini 比基尼海滩场景
- 裸露肩膀的女性
- 紧身衣紧贴身材
- 诱人的姿态
✅ 规避写法:
- 夏季海滩度假场景,人物远景
- 穿优雅晚礼服的女性
- 时尚杂志风格的运动装写真
- 自信的模特姿态
规则: 避开"紧身、裸露、性感、诱惑"等形容词,改用"优雅、时尚、自信"等中性词汇。
2.6 触发场景六: 儿童相关的写实图像
OpenAI 对儿童的写实化生成采取近乎零容忍政策。任何以下写法都会拦:
❌ 高风险:
- 一个 8 岁小女孩的写实照片
- 穿泳衣的儿童在游泳池边
- 婴儿的细节特写写真
✅ 安全写法:
- 一幅卡通风格的童年场景插画
- 写实的家庭场景远景,不聚焦任何个人
- 母亲抱着婴儿的艺术化插画
规则: 儿童相关 尽量用插画/卡通风格,避免"写实、特写、精细、照片级"等词。
2.7 触发场景七: 仇恨、极端政治、敏感符号
仇恨符号、极端政治图腾、宗教冲突性描绘都是硬拦:
❌ 高风险:
- 纳粹万字符
- 极端政治对立场景
- 特定国家的冲突叙事
这类内容几乎没有 prompt 改写的空间,建议 彻底绕开这个选题方向。
三、gpt-image-2 moderation_blocked 错误的诊断流程
3.1 诊断流程图

当收到 moderation_blocked 错误时,按以下流程诊断:
Step 1. 记录完整 error message + request id
↓
Step 2. 判断是 "rejected" (输入拦) 还是 "filtered" (输出拦)
↓
Step 3. 对照 7 大触发场景定位原因
↓
Step 4. 逐步删减 prompt 关键词做二分法复现
↓
Step 5. 选择对应的改写策略 (见第四章)
↓
Step 6. 改写后重试,记录成功率变化
3.2 prompt 二分法复现触发词
当不确定 prompt 中哪个词触发了拦截,可以用二分法:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def binary_search_trigger(full_prompt: str):
"""用二分法找到触发 moderation_blocked 的关键词"""
words = full_prompt.split()
mid = len(words) // 2
left_half = " ".join(words[:mid])
right_half = " ".join(words[mid:])
for test_prompt in [left_half, right_half]:
try:
client.images.generate(
model="gpt-image-2",
prompt=test_prompt,
size="1024x1024",
quality="low",
n=1
)
print(f"✓ 通过: {test_prompt[:40]}...")
except Exception as e:
if "moderation_blocked" in str(e):
print(f"✗ 触发: {test_prompt[:40]}...")
binary_search_trigger("原始的 prompt 内容 ...")
通过 API易 apiyi.com 运行这个脚本,用 quality="low" 把每次测试成本降到最低($0.006/张),快速定位触发词。
3.3 用 OpenAI Moderations API 预检
OpenAI 提供了免费的 /v1/moderations 端点,可以在正式调用图像生成前 预检 prompt 文本 是否会被拦:
def pre_check_prompt(prompt: str):
result = client.moderations.create(
model="omni-moderation-latest",
input=prompt
)
categories = result.results[0].categories
scores = result.results[0].category_scores
flagged_categories = [
(cat, scores.model_dump()[cat])
for cat, flagged in categories.model_dump().items()
if flagged
]
if flagged_categories:
print(f"⚠️ Prompt 被标记: {flagged_categories}")
return False
return True
注意: 预检 只能检查文本维度,无法检测版权名人等"语义判断"类拦截。但对"暴力、性、仇恨"等明显违规词有高准确率。
四、gpt-image-2 moderation_blocked 错误的 6 种提示词改写策略
4.1 策略一: 姓名替换为流派或工作室
| 原写法 | 改写 |
|---|---|
| 宫崎骏风格 | 吉卜力 / 明亮现代日式动画风格 |
| 新海诚风格 | 饱和色彩日式青春动画 |
| 迪士尼风格 | 经典美式卡通风格 |
| 安妮海瑟薇 | 一位 35 岁优雅的女演员 |
| 马斯克 | 一位穿西装的科技公司创始人 |
4.2 策略二: 已故艺术家替代活着艺术家
活着艺术家 → 同流派已故艺术家:
| 活着艺术家 (拦) | 已故艺术家 (不拦) |
|---|---|
| Banksy 风格涂鸦 | Basquiat 风格涂鸦 / 80 年代街头艺术 |
| 新海诚风格 | (直接用"日式动画风格") |
| Hayao Miyazaki | (用"吉卜力") |
| 村上隆 | 波普艺术风格 / Andy Warhol 风格 |
Van Gogh、Monet、Picasso、Rembrandt、Hokusai 等经典大师都是安全的参考。
4.3 策略三: 版权角色抽象化
把具名 IP 抽象成 "通用特征 + 叙事描述":
原写法: 蜘蛛侠在纽约上空荡漾
改写: 一位穿红蓝紧身超级英雄服、戴面具、用丝线在霓虹都市摩天大楼间摆荡的年轻人,充满动感与活力
原写法: 皮卡丘在森林里
改写: 一只圆润可爱的黄色电系卡通生物,有红色脸颊,尖耳朵,在茂密的绿色森林中跳跃
核心技巧: 保留视觉特征,移除名字。
4.4 策略四: 两步描述法 (Two-Step Description)
对复杂的、可能踩线的场景,用两步法:
Step 1: 先让 Gemini Pro 或 Claude 4 Sonnet 把你的原始想法"翻译"成 纯视觉元素描述,主动剥离所有名人/IP/敏感词。
Step 2: 把 Step 1 的输出作为 gpt-image-2 的实际 prompt。
def two_step_generate(raw_idea: str):
rewriter_response = client.chat.completions.create(
model="gemini-3-pro",
messages=[
{
"role": "system",
"content": (
"你是视觉描述专家。将用户想法重写为纯视觉元素描述:"
"移除所有真实人名、品牌名、版权角色名、敏感词;"
"保留: 颜色、构图、光照、动作、氛围、材质、镜头。"
"输出一段 150-250 字的连贯叙述,不要列表。"
)
},
{"role": "user", "content": raw_idea}
]
)
safe_prompt = rewriter_response.choices[0].message.content
return client.images.generate(
model="gpt-image-2",
prompt=safe_prompt,
size="1024x1024",
quality="medium"
)
这种方法借助 API易 apiyi.com 的多模型统一接入,用文本 LLM 做前置"安全净化层",大幅降低图像 API 的 moderation_blocked 触发率。
4.5 策略五: 情绪/氛围替代暴力/性词汇
| 原词 | 中性替代 |
|---|---|
| 血腥 (bloody) | 深红色调 / 戏剧性 |
| 暴力 (violent) | 激烈 / 富有张力 |
| 性感 (sexy) | 优雅 / 自信 / 有魅力 |
| 裸露 (naked/nude) | 古典雕塑风格 / 艺术人体 |
| 诱惑 (seductive) | 迷人的气质 |
| 杀戮 (killing) | 戏剧性对抗 |
| 武器 (weapon) | 道具 / 工具 |
4.6 策略六: 改用 edit 端点时降级为 generate 端点
前文提到 edits 端点过滤更严。如果你的任务是"在现有图基础上改",可以尝试:
原流程: /v1/images/edits (被拦)
替代流程:
- 用 LLM 描述原图的视觉元素
- 加上"修改点"
- 走
/v1/images/generations重新生成
虽然牺牲了像素级一致性,但能规避掉严格的编辑过滤。
五、gpt-image-2 moderation_blocked 错误的多模型备用方案
单一模型遇到硬拦截时,多模型路由 是企业级应用的标准做法。
5.1 图像模型过滤严格度对比
| 模型 | 过滤严格度 | 名人允许度 | IP 允许度 | 艺术表现度 |
|---|---|---|---|---|
gpt-image-2 官转 |
🔴 严格 | 极严 | 严 | 偏保守 |
gpt-image-2-all 官逆 |
🟡 中等 | 中等 | 中 | 较灵活 |
| Nano Banana Pro | 🟢 较宽松 | 中 | 中 | 灵活 |
| Nano Banana 2 | 🟢 较宽松 | 中 | 中 | 灵活 |
| Imagen 系列 | 🟡 中等 | 严 | 中 | 中 |
实务建议: 当 gpt-image-2 官转拦截时,可以依次降级尝试:
gpt-image-2 (官转) [moderation_blocked]
↓
gpt-image-2-all (官逆) [可能通过]
↓
Nano Banana Pro [较大概率通过]
↓
Nano Banana 2 [最灵活,质量略低]
5.2 自动降级代码示例
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
MODEL_FALLBACK_CHAIN = [
("gpt-image-2", "images"),
("gpt-image-2-all", "chat"),
("gemini-3-pro-image-preview", "images"),
("gemini-3.1-flash-image-preview", "images"),
]
def generate_with_fallback(prompt: str):
last_error = None
for model_id, endpoint in MODEL_FALLBACK_CHAIN:
try:
if endpoint == "images":
return client.images.generate(
model=model_id,
prompt=prompt,
size="1024x1024"
)
else:
return client.chat.completions.create(
model=model_id,
messages=[{"role": "user", "content": prompt}]
)
except Exception as e:
if "moderation_blocked" in str(e) or "content_policy" in str(e):
print(f"模型 {model_id} 拦截,尝试下一个")
last_error = e
continue
raise
raise Exception(f"所有模型都拦截,最后错误: {last_error}")
这个模式的核心价值: 在同一个 API易 apiyi.com 账号下,通过简单改 model 参数就实现了多模型降级,无需注册多家服务、无需管理多套 credentials。
5.3 按内容类型路由的高级策略
更精细的做法是 按内容类型预判最合适的模型:
| 内容类型 | 首选模型 | 理由 |
|---|---|---|
| 企业品牌物料 | gpt-image-2 官转 | 稳定、合规 |
| 带中文文字的海报 | gpt-image-2-all 官逆 | 中文原生优化 |
| 可能含 IP 的创意图 | Nano Banana Pro | 过滤较宽松 |
| 批量快速出图 | Nano Banana 2 | 速度快、成本低 |
| 特殊风格艺术图 | Nano Banana Pro | 艺术表现灵活 |
六、gpt-image-2 moderation_blocked 企业级申诉流程
当确信 prompt 是合法的、不应该被拦(误报)时,可以走申诉流程。
6.1 申诉必备信息清单
提交申诉前,收集以下信息:
- 完整 error response (含 request id)
- 触发 moderation_blocked 的完整 prompt
- 调用时间戳
- 你的账户 ID
- 业务场景说明 (为什么需要这个 prompt)
- 复现步骤 (是否稳定复现)
6.2 申诉渠道

L1: 自助层 (最快)
先尝试本文第四章的 6 种改写策略,90%+ 的 moderation_blocked 可以在这一层解决,0 成本。
L2: API易 企业服务通道 (推荐)
对企业客户,API易 apiyi.com 提供专属技术对接,针对具体 moderation_blocked 案例提供:
- prompt 改写建议
- 多模型降级方案设计
- 对接 OpenAI/Azure 的申诉流程
这一层响应快,且 API易 团队在图像模型的误报申诉上积累了大量经验,比自己对接官方工单效率高得多。
L3: 官方申诉 (最慢但最终有效)
通过 error message 中提到的 Azure support ticket 或 OpenAI 官方 Help Center 提交申诉,附上完整 request id。响应周期通常 3-10 个工作日。
6.3 系统性降低触发率的工程实践
对高频调用的生产系统,建议构建一套 Prompt 安全网关:
用户原始请求
↓
[1] 关键词黑名单预筛 (秒级)
↓
[2] OpenAI Moderations API 预检 (免费, 300ms)
↓
[3] 文本 LLM 改写为安全 prompt (可选, 1-2 秒)
↓
[4] 调用 gpt-image-2
↓
[5] 收到 moderation_blocked 时自动降级到备用模型
↓
返回结果
通过这 5 层防护,把 moderation_blocked 的 最终用户可见率 降到 < 1%。
🎯 落地建议: 这套安全网关的所有外部调用(Moderations API、文本 LLM、多个图像模型)都可以通过 API易 apiyi.com 单一接入点完成,统一计费、统一日志,极大降低了工程复杂度。
七、gpt-image-2 moderation_blocked 常见问题 FAQ
Q1: 为什么同一个 prompt 今天能过,明天就被 moderation_blocked 了?
OpenAI 和 Azure 的安全分类器会 持续更新,尤其在有重大政策事件(如名人 opt-out)后会批量收紧。建议在生产系统里记录每次 moderation_blocked 的 prompt 快照,用于后续分析。
Q2: 我用 gpt-image-2-all (官逆) 能绕过 moderation_blocked 吗?
部分场景可以,但不是万能钥匙。官逆链路也有自己的安全检测,只是触发阈值和规则略不同。对于特定类型的拦截(如名人姓名),两个模型都会拦。推荐通过 API易 apiyi.com 在两个模型间做 A/B 测试,找出对你的业务场景容忍度更高的那条路。
Q3: moderation_blocked 错误会扣费吗?
不会。400 错误属于客户端错误,OpenAI 和 API易 都不会对被拦截的请求扣费。可以放心大胆地做 prompt 调试。
Q4: 为什么中文 prompt 触发 moderation_blocked 的概率比英文高?
不是中文本身的问题,而是 中文 prompt 在翻译成模型内部表征时可能带入意外的英文触发词。建议: (1) 在中文 prompt 里避免直接命名名人/IP (2) 尝试用 gpt-image-2-all,它对中文 prompt 有原生优化。
Q5: 我要生成自己员工的照片做内部使用,也会被拦吗?
很可能会。OpenAI 的安全系统无法判断"你是不是这个员工本人",只要识别为真实人物肖像就会拦。建议走 edit 端点(上传原图 + mask 修改),或者用"风格化艺术处理"代替写实照片。
Q6: 企业客户可以申请降低过滤阈值吗?
OpenAI 直连几乎不可能,Azure OpenAI 部分企业合约可以申请调整 content filter 级别(需审批)。通过 API易 apiyi.com 的企业服务通道可以协助你对接 Azure 的审批流程,或者提供定制化的多模型方案来规避单点限制。
Q7: Nano Banana Pro 的过滤真的比 gpt-image-2 宽松吗?
在大量实测中,Nano Banana Pro 对 艺术化表现 和 宽松 IP 指代 确实更宽容,但在儿童相关、性内容、极端暴力等核心禁区与 OpenAI 几乎一致——没有任何主流模型能绕过这些底线。
Q8: 错误信息里的 Azure support ticket 是什么意思?
说明底层链路经过 Azure OpenAI。不同中转服务对接的后端不同,有的直连 OpenAI,有的走 Azure。不同后端的过滤严格度略有差异,这也是为什么同一 prompt 在不同服务商上表现不一致。
八、总结: gpt-image-2 moderation_blocked 错误的应对心法
回到开头那段错误体,现在我们清楚地知道:
- 错误本质:
moderation_blocked不是模型能力问题,而是安全分类器在 模型推理之前 主动拦截。 - 错误不可重试: 不改 prompt,重试一万次结果一样。
- 7 大触发场景: 名人 / 活着艺术家 / 版权 IP / 暴力 / 性暗示 / 儿童写实 / 仇恨符号。
- 6 种改写策略: 姓名替换 / 已故替活着 / 角色抽象化 / 两步描述 / 情绪替暴力 / 降级 edit 端点。
- 多模型备用: gpt-image-2 → gpt-image-2-all → Nano Banana Pro → Nano Banana 2 的降级链。
- 工程化防护: 预检 + 改写 + 降级 + 申诉四层网关,把误报可见率降到 < 1%。
对于正在用 gpt-image-2 做生产的团队,推荐的 核心原则 是: 不要和安全系统硬刚,而是把 prompt 工程和多模型路由做成系统性能力。一个 moderation_blocked 错误,往往意味着你的 prompt 层或架构层还有 10 个类似错误在等着。
我们建议通过 API易 apiyi.com 的统一入口同时接入 gpt-image-2、gpt-image-2-all、Nano Banana Pro/2 等多个模型,在同一个账号和代码基下快速实现降级路由。这是把 moderation_blocked 从"业务中断级故障"降维到"无感体验优化"的最快路径。
关于作者: APIYI 技术团队,在图像生成模型的企业级落地、内容安全申诉、多模型路由架构等领域积累了丰富经验。访问 API易官网 apiyi.com 获取 gpt-image-2、gpt-image-2-all、Nano Banana Pro 等主流模型的接入方案,以及针对 moderation_blocked 等常见问题的企业级技术支持。