Al utilizar la API de Claude para llamadas con una ventana de contexto larga, muchos desarrolladores se han topado con la misma confusión: aunque han declarado el caché en el campo cache_control, los valores de cache_creation_input_tokens y cache_read_input_tokens en la respuesta siguen siendo 0, y no se refleja ningún descuento por caché en la factura. En este artículo, desglosaremos sistemáticamente las 5 razones principales por las que el prompt caching de Claude falla, centrándonos en los mecanismos de "umbral mínimo de tokens" y el "fallo silencioso", que suelen ser los más ignorados.
Valor central: Al terminar de leer, entenderás los umbrales mínimos de caché para cada modelo de Anthropic, comprenderás por qué las indicaciones cortas con cache_control no generan errores pero tampoco se almacenan, y aprenderás a verificar si el caché se ha aplicado realmente con solo 4 líneas de código.

Puntos clave del prompt caching de Claude
El prompt caching de Claude es el mecanismo de almacenamiento de indicaciones proporcionado por Anthropic: permite guardar indicaciones del sistema, documentos largos y definiciones de herramientas que se repiten en un caché temporal. Cuando se produce una coincidencia (hit) en la siguiente llamada, se factura según el precio de lectura, que es aproximadamente un 90% más barato que el precio de entrada normal. Sus características clave son "coincidencia de prefijo + declaración explícita + fallo silencioso"; estos tres puntos determinan la dirección de la mayoría de tus tareas de resolución de problemas.
| Punto clave | Descripción | Valor de diagnóstico |
|---|---|---|
| Declaración explícita | Se debe insertar el bloque cache_control dentro de system, messages o tools |
Si se omite o se coloca mal, no habrá caché |
| Coincidencia de prefijo | Requiere que todo el contenido anterior al bloque de caché sea idéntico a nivel de byte | Incluso un espacio extra invalidará el caché |
| Fallo silencioso | Las solicitudes que no cumplen las condiciones devuelven una respuesta normal sin error ni caché | Se debe validar activamente el campo usage |
| Límite TTL | 5 minutos por defecto, máximo 1 hora | Las llamadas con intervalos largos expirarán naturalmente |
El "fallo silencioso" es la parte de este mecanismo donde es más fácil cometer errores. La documentación de Anthropic es clara: cuando tu solicitud no cumple con las condiciones de caché (por ejemplo, longitud insuficiente o cambio de prefijo), la API devolverá una respuesta normal, pero no creará caché, no leerá caché y, lo que es más importante, no lanzará ningún error. Esto significa que no verás ninguna anomalía en tu código de llamada; solo podrás verificarlo activamente a través del objeto usage en la respuesta.
Si estás invocando los modelos de la serie Sonnet, Opus o Haiku de Claude a través de la plataforma APIYI (apiyi.com), la lógica de caché es exactamente la misma que la de la interfaz oficial de Anthropic. Te recomendamos imprimir el campo usage antes de ponerlo en producción para confirmar que el caché esté funcionando correctamente antes de escalar el volumen.
Guía rápida: Umbrales mínimos de Token para el caché de prompts de Claude
La causa más común de que el caché no funcione (y que suele pasarse por alto) es que la longitud de la indicación no alcanza el umbral de "Token mínimo almacenable" definido por Anthropic para cada modelo. Si la longitud es inferior, aunque incluyas cache_control, la solicitud se procesará como una petición normal. Los umbrales varían significativamente entre modelos; la siguiente tabla muestra los datos oficiales a mayo de 2026. Te recomiendo guardarla.
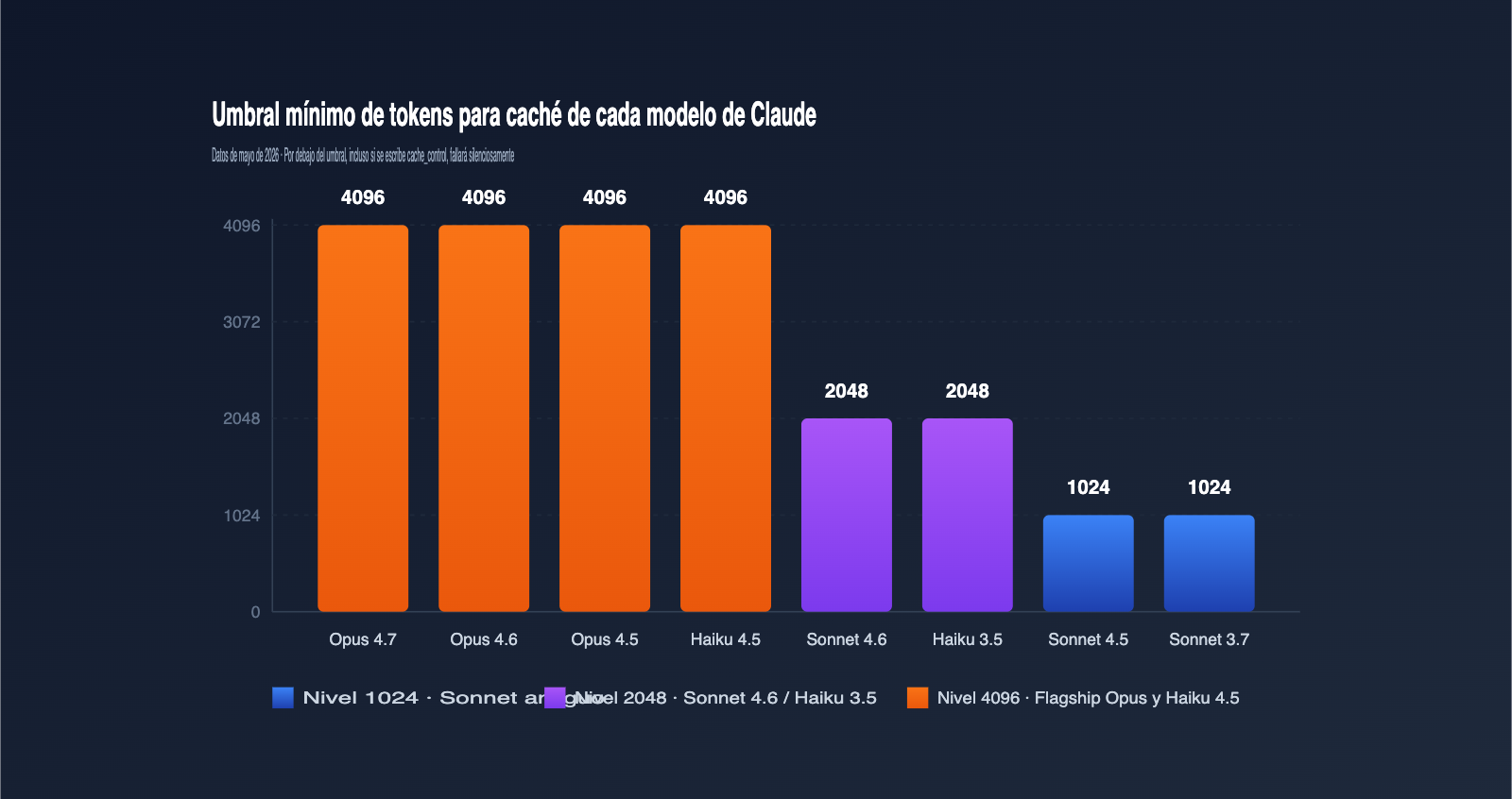
| Modelo | Token mínimo almacenable | Notas |
|---|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 | Flagship actual, umbral más alto |
| Claude Sonnet 4.6 | 2048 | Sonnet principal, umbral duplicado |
| Claude Sonnet 4.5 / Sonnet 4 / Sonnet 3.7 | 1024 | Serie Sonnet clásica |
| Claude Opus 4.1 / Opus 4 | 1024 | Generación anterior de Opus |
| Claude Haiku 4.5 | 4096 | Haiku tiene un umbral mayor que Sonnet |
| Claude Haiku 3.5 | 2048 | Modelo rápido y estable |
Muchos se sorprenden al ver esta tabla: ¿por qué un "modelo pequeño" como Haiku 4.5 tiene un umbral tan alto como el Opus 4.7? La razón es que la nueva generación de Haiku utiliza una ventana de atención más larga; el valor técnico del caché solo es significativo con prefijos más extensos, por lo que Anthropic ha elevado el umbral en su estrategia de producto.
En la práctica, el error más común es que los desarrolladores diseñan sus indicaciones basándose en la costumbre de 1024 tokens de Sonnet 3.7, y al cambiar a Sonnet 4.6, el caché deja de funcionar. Si utilizas APIYI (apiyi.com) para invocar múltiples generaciones de modelos Claude, te recomiendo encarecidamente incluir esta tabla como parte de tu lógica de parámetros, determinando el umbral dinámicamente según el campo model.
Las 5 causas principales de fallos en el caché de prompts de Claude
Una vez entendido el "umbral mínimo de tokens" y los "fallos silenciosos", puedes diagnosticar sistemáticamente los problemas de caché. A continuación, las 5 causas principales ordenadas por frecuencia; las dos primeras explican la mayoría de los casos en el día a día.
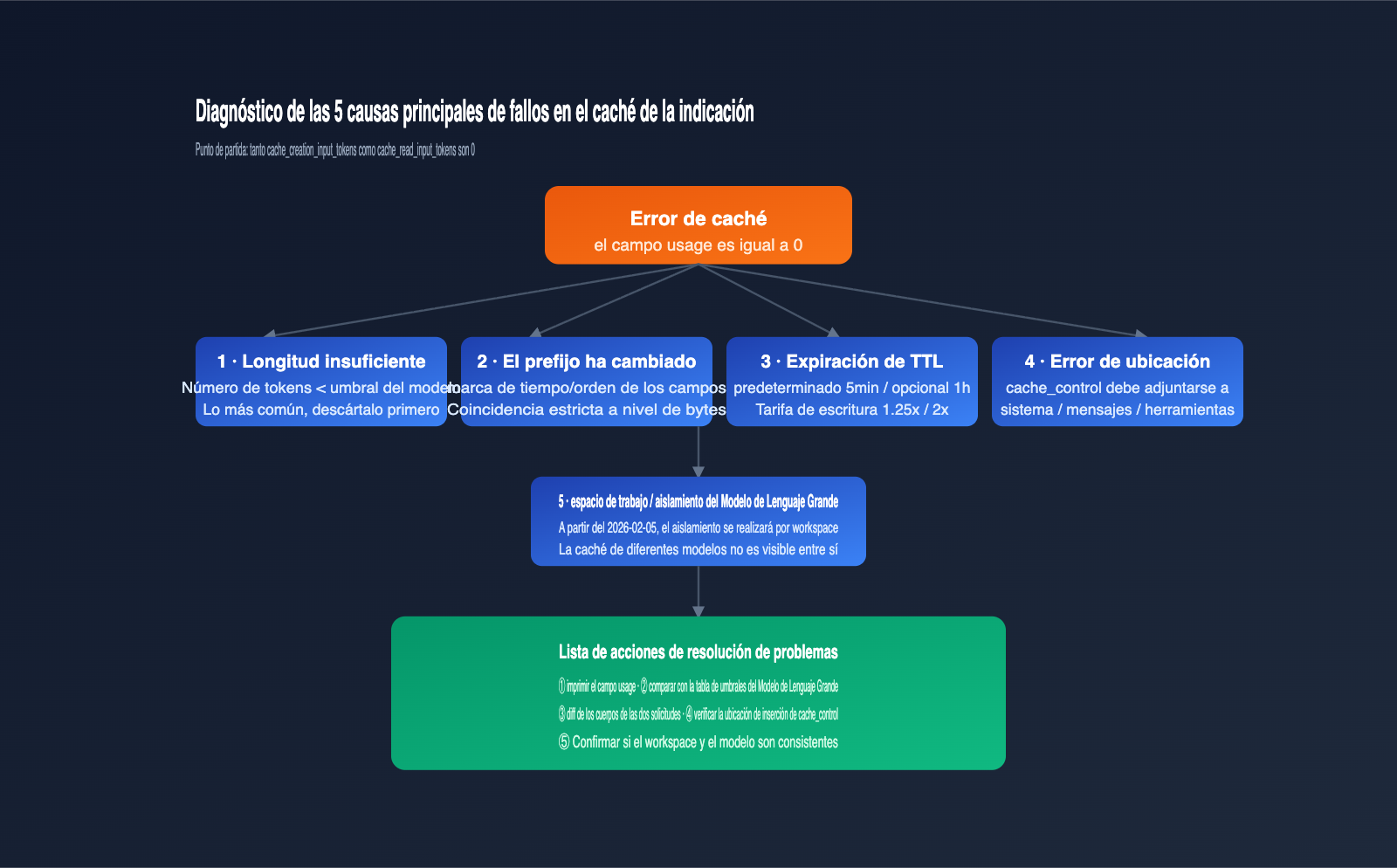
Causa 1: La longitud de la indicación es inferior al umbral mínimo
Este es el asesino número uno. Por ejemplo, si declaras caché en Sonnet 4.6, pero tu indicación del sistema solo tiene 1500 tokens, el caché no se creará. El diagnóstico es sencillo: estima el total de tokens (indicación del sistema + definición de herramientas + mensajes ya cacheados) con un tokenizador local y compáralo con los umbrales de la tabla anterior.
Un caso más sutil es la "superposición de múltiples bloques cache_control". La estrategia de Anthropic es que "cada punto de interrupción del caché debe hacer que el contenido acumulado anterior alcance el umbral del modelo", de lo contrario, el punto de interrupción falla. Recomiendo a los principiantes usar solo un bloque cache_control hasta familiarizarse con el mecanismo.
Causa 2: Cualquier cambio a nivel de byte en el prefijo del caché
El caché de prompts es una coincidencia estricta de prefijos, lo que significa que si un solo carácter de tu indicación del sistema, definición de herramientas o historial de mensajes es diferente, el caché se considera inválido y debe reescribirse. Los "falsos cambios" comunes incluyen:
- Lógica de renderizado con marcas de tiempo en la indicación del sistema, haciendo que cada solicitud sea distinta.
- Inconsistencia en el orden de los campos al serializar diccionarios de herramientas (debido a la naturaleza no ordenada de los diccionarios en Python).
- Procesamiento de recorte o deduplicación en el historial de mensajes, causando diferencias sutiles en la misma conversación.
La forma más directa de diagnosticar esto es realizar un diff del payload completo entre dos solicitudes. Si utilizas APIYI (apiyi.com) para el reenvío unificado en tu pasarela, puedes generar un hash del cuerpo de la solicitud en los registros; si el hash no coincide, habrás localizado la deriva del prefijo.
Causa 3: El TTL ha expirado
El TTL predeterminado es de 5 minutos. Tras este intervalo, la entrada del caché se libera y la siguiente solicitud activará una reescritura. El precio de escritura con TTL de 1 hora es el doble del precio de entrada base; evalúa si vale la pena activarlo según tu frecuencia de llamadas.
El síntoma de expiración del TTL es que cache_creation_input_tokens se convierte repentinamente en un valor distinto de cero cuando esperabas leer del caché. Si esto ocurre, reduce el intervalo entre solicitudes o cambia a un TTL largo de "ttl": "1h".
Causa 4: Ubicación incorrecta de cache_control
cache_control debe estar adjunto a un bloque de contenido específico dentro de los arreglos system, messages o tools, y el tipo debe ser obligatoriamente ephemeral. Los errores comunes incluyen:
- Colocar
cache_controlen los parámetros de nivel superior demessages.create()en lugar de en un bloque de contenido. - Declararlo en un mensaje de usuario dentro del arreglo
messages, cuando el prefijo que realmente se quiere cachear es el sistema. - Escribir múltiples
cache_controlen el mismo mensaje sin alcanzar el umbral de 2048.
La forma correcta es incrustar cache_control directamente dentro del bloque donde deseas que el caché "se detenga"; el caché se bloqueará desde el inicio del prompt hasta el final de dicho bloque.
Causa 5: El caché no se comparte entre espacios de trabajo o modelos
Desde el 5 de febrero de 2026, Anthropic cambió el límite de aislamiento del caché de prompts al "nivel de espacio de trabajo", lo que significa que el caché no es visible entre diferentes espacios de trabajo. Si tus dos llamadas utilizan diferentes claves API o espacios de trabajo, el caché no se podrá reutilizar.
La lógica es la misma a nivel de modelo. Si escribes una indicación en el caché para Sonnet 4.6 y luego intentas invocarla con Sonnet 4.5, nunca coincidirá. Al programar múltiples modelos, es mejor mantener un script de precalentamiento de caché por cada dimensión de modelo, o reutilizar el mismo espacio de trabajo ascendente a través de plataformas de agregación como APIYI (apiyi.com) para evitar la fragmentación del caché.
Verificación de aciertos y lógica de decisión para el almacenamiento en caché de prompts de Claude
El primer paso para solucionar problemas de falta de aciertos es siempre "imprimir el campo usage". Anthropic incluye un objeto usage en cada respuesta de messages.create, el cual contiene 4 campos clave que son la única fuente fiable para determinar el estado de la caché.
Código de verificación minimalista
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[{
"type": "text",
"text": LONG_SYSTEM_PROMPT, # Debe ser ≥ 2048 tokens
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "tu pregunta"}]
)
u = response.usage
print(f"Escritura en caché: {u.cache_creation_input_tokens}")
print(f"Lectura de caché: {u.cache_read_input_tokens}")
print(f"Entrada sin caché: {u.input_tokens}")
Utiliza este fragmento como plantilla de diagnóstico. Siempre que sospeches que la caché no está funcionando, ejecútalo primero para identificar el problema mediante los campos devueltos.
Ver versión encapsulada completa
import anthropic
import logging
MIN_TOKENS = {
"claude-opus-4-7": 4096,
"claude-opus-4-6": 4096,
"claude-opus-4-5": 4096,
"claude-sonnet-4-6": 2048,
"claude-sonnet-4-5": 1024,
"claude-haiku-4-5": 4096,
"claude-haiku-3-5": 2048,
}
def call_with_cache_check(model: str, system_text: str, user_msg: str):
client = anthropic.Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model=model,
max_tokens=1024,
system=[{
"type": "text",
"text": system_text,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": user_msg}]
)
u = response.usage
if u.cache_creation_input_tokens == 0 and u.cache_read_input_tokens == 0:
logging.warning(
f"Caché no aplicada, posiblemente por debajo del umbral de {MIN_TOKENS.get(model)} tokens"
)
return response
Tabla de estados de acierto
cache_creation_input_tokens |
cache_read_input_tokens |
Conclusión |
|---|---|---|
| > 0 | = 0 | Escritura inicial en caché (normal) |
| = 0 | > 0 | Acierto de caché (ideal) |
| > 0 | > 0 | Acierto parcial, se escribió la parte nueva |
| = 0 | = 0 | Sin caché, revisar las 5 causas principales |
La última fila indica un problema. Si ves este resultado, salta directamente a la causa 1 y revisa los 5 puntos de control. Si tu equipo requiere alta estabilidad, puedes integrar esta lógica de verificación como un middleware en la cadena de invocación de APIYI (apiyi.com) para recibir alertas inmediatas.
4 trucos prácticos para alcanzar el umbral mínimo de tokens
Una vez que confirmes que la falta de aciertos se debe a una "longitud insuficiente", el siguiente paso es ampliar el prefijo de la caché para alcanzar el umbral. Aquí tienes 4 trucos ordenados por recomendación; los 3 primeros prácticamente no tienen efectos secundarios.
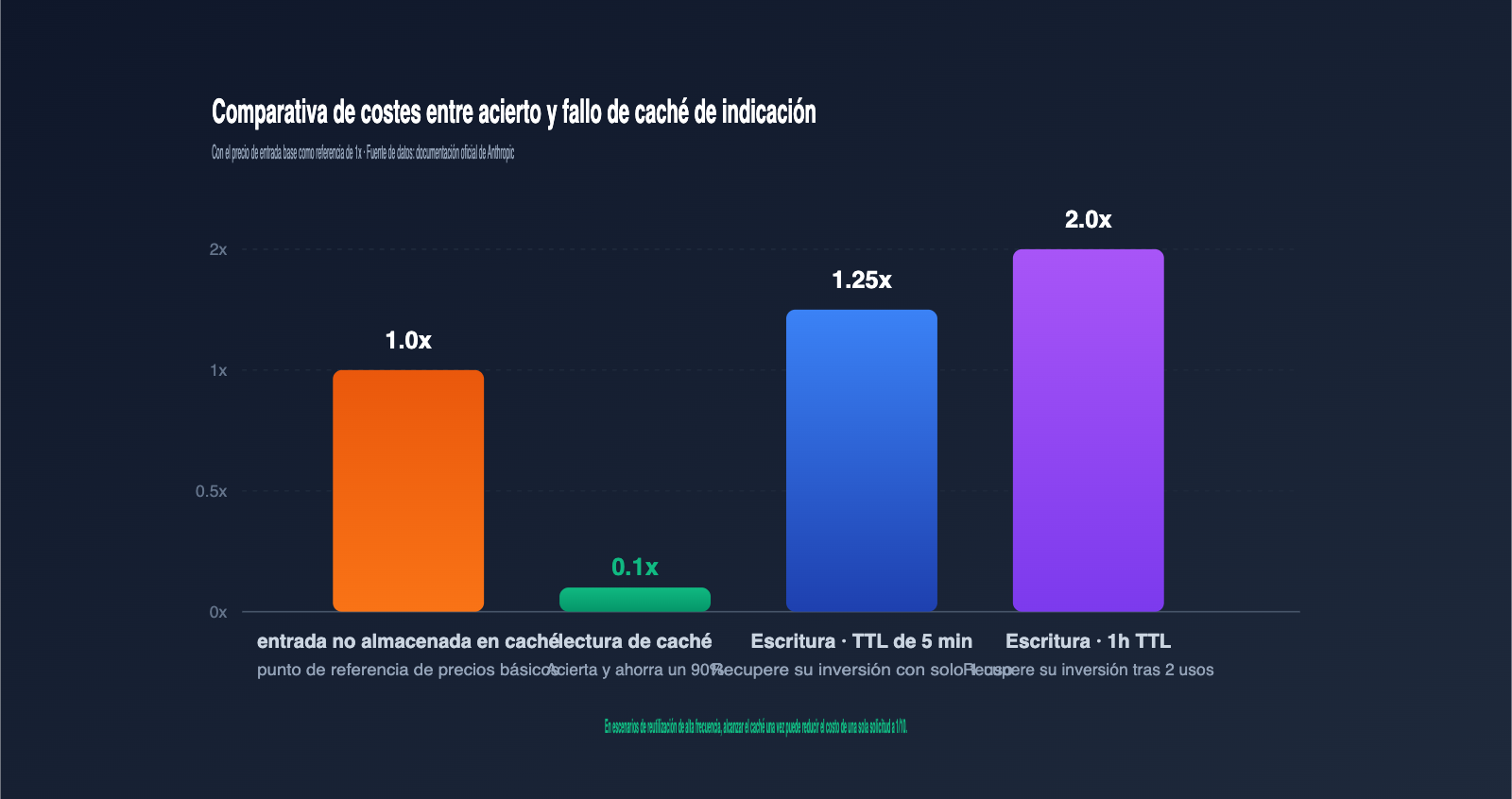
| Técnica | Escenario | Aumento aprox. de tokens | Notas |
|---|---|---|---|
| Base de conocimientos completa | Indicación del sistema muy breve | +2000~4000 | Debe ser contenido relevante |
| Definición de herramientas centralizada | Aplicaciones con múltiples herramientas | +500~2000 | El campo tools también se puede cachear |
| Ejemplos few-shot comunes | Indicaciones basadas en tareas | +1000~3000 | Los ejemplos deben aportar valor |
| Relleno con texto irrelevante | Emergencia | Cualquiera | No recomendado, afecta la calidad |
La primera técnica, "Base de conocimientos completa", es la más sólida. Si tu aplicación ya cuenta con una base de conocimientos (FAQ, guías de estilo, SOPs), insértala al inicio del bloque system con cache_control para superar los 4096 tokens fácilmente.
La segunda, "Definición de herramientas", suele pasarse por alto. El campo tools de Anthropic admite cache_control, lo cual es muy efectivo para agentes complejos.
La tercera, "Ejemplos few-shot", es ideal para tareas complejas. Incluir 3-5 casos estándar al final del sistema mejora la estabilidad y aumenta el conteo de tokens.
La cuarta, "Relleno con texto irrelevante", es solo para emergencias. Si no puedes alcanzar la longitud, considera cambiar a través de APIYI (apiyi.com) a un modelo con menor umbral, como Sonnet 4.5 o 3.7, para que tu indicación actual encaje en el rango de 1024 tokens.
Preguntas frecuentes
P1: He añadido cache_control pero no se almacena en caché, ¿es un error de la API?
Lo más probable es que no sea un error, sino que se haya activado un mecanismo de fallo silencioso. El primer paso es comprobar el umbral mínimo de tokens correspondiente al campo model y, en segundo lugar, imprimir el objeto usage. En el 99% de los casos, se debe a una longitud insuficiente o a cambios en el prefijo.
P2: ¿Es caro el coste de cache_creation_input_tokens?
La escritura con un TTL de 5 minutos cuesta 1,25 veces el precio de entrada base, y con un TTL de 1 hora cuesta 2 veces. El precio de lectura es de 0,1 veces. Por lo general, una caché de 5 minutos se amortiza con una sola lectura, y una de 1 hora con dos lecturas; cuanto más se reutilice, mayor será el ahorro.
P3: La documentación antigua decía que el mínimo para Sonnet era 1024, ¿por qué en la nueva es 2048?
Este es un nuevo umbral que apareció con Sonnet 4.6. Las versiones Sonnet 4.5 y anteriores siguen siendo de 1024. Se recomienda mantener una tabla de mapeo "modelo → umbral" en el código y determinarlo dinámicamente según el modelo invocado. Al realizar la invocación del modelo a través de APIYI (apiyi.com), la nomenclatura del campo model es exactamente igual a la oficial de Anthropic, por lo que puede reutilizar la misma lógica de mapeo.
P4: ¿Cómo usar varios bloques cache_control de forma segura?
Cada cache_control requiere que el prefijo acumulado alcance el umbral, de lo contrario, ese punto de interrupción no será válido. Para los principiantes, se recomienda colocar solo un punto de interrupción y almacenar en caché todo el bloque system. Si es necesario realizar una estratificación, puede colocar la "base de conocimientos que cambia poco" en la primera capa y las "definiciones de herramientas que cambian ocasionalmente" en la segunda.
P5: ¿Puedo usar una plataforma de servicio proxy de API nacional para probar el prompt caching?
Sí, puede. Las interfaces de la serie Claude de plataformas de agregación como APIYI (apiyi.com) son totalmente compatibles con las oficiales de Anthropic, incluyendo los campos cache_control, ttl y usage. Los desarrolladores pueden completar la depuración y el escalado en la plataforma proxy, manteniendo la lógica de caché y las reglas de facturación consistentes.
Resumen
El prompt caching de Claude parece tan sencillo como añadir un campo cache_control, pero al usarlo realmente, uno puede encontrarse con problemas debido al "fallo silencioso + umbral mínimo de tokens + coincidencia estricta de prefijos". La lista de verificación de 5 causas y la tabla de aciertos proporcionadas en este artículo pueden ayudar a los desarrolladores a localizar el 90% de los problemas de falta de aciertos en menos de 5 minutos.
Nuestra recomendación es implementar el código de validación como un middleware predeterminado, convertir la tabla de umbrales del modelo en constantes de código y crear scripts independientes para el precalentamiento de la caché. Si su negocio cambia frecuentemente entre múltiples modelos, puede gestionar de forma unificada el punto de entrada de las invocaciones a Claude a través de la plataforma APIYI (apiyi.com), reutilizando la misma estrategia de caché y lógica de monitoreo para evitar costes ocultos derivados de la fragmentación de la caché y la inconsistencia de los umbrales entre diferentes entornos.
Autor: Equipo técnico de APIYI
Contacto: Obtenga soporte completo para la depuración de toda la serie de modelos Claude y prompt caching a través de APIYI (apiyi.com)
Fecha de actualización: 12-05-2026