“Unterstützt gemini-3.1-flash-lite-image den Inferenzmodus überhaupt?” ist in den API-Call-Gruppen aktuell eine der meistgestellten Fragen. Die Antwort lautet: Ja – und das ist keine Vermutung. Wir haben anhand der offiziellen Google-Dokumentation und über das Gateway von APIYI drei Vergleichsreihen getestet und dabei reale Token-Verbräuche sowie Latenzwerte gemessen. In diesem Artikel erklären wir thinkingLevel aus drei Blickwinkeln: Parameterstruktur, Messdaten und Abrechnungsregeln.
Kernnutzen: Nach dem Lesen wissen Sie genau, wie Sie den Inferenzmodus von gemini-3.1-flash-lite-image aktivieren, wie viele zusätzliche Tokens das kostet und in welchen Szenarien sich diese zusätzliche Latenz lohnt.

Zentrale Schlussfolgerung zum Inferenzmodus von gemini-3.1-flash-lite-image
Zuerst das Fazit, dann die Details. In der offiziellen Google-Dokumentation steht klar, dass Entwickler bei gemini-3.1-flash-image und gemini-3.1-flash-lite-image die Denkmenge des Modells steuern können. Das bedeutet: Auch die Flash-Lite-Stufe hat eingebauten Inferenzsupport – nicht nur die Spitzenmodelle. Allerdings unterstützen nicht alle Bildmodelle diesen Parameter. Die folgende Tabelle zeigt den Vergleich bei drei gängigen Gemini-Bildmodellen.
| Modell | Unterstützt thinkingLevel? |
Einstellbare Stufen | Standardstufe | Hinweis |
|---|---|---|---|---|
gemini-3.1-flash-image |
✅ Unterstützt | minimal / high | minimal | In der offiziellen Dokumentation ausdrücklich aufgeführt |
gemini-3.1-flash-lite-image |
✅ Unterstützt | minimal / high | minimal | Nutzt dieselbe thinkingConfig wie flash-image |
gemini-3-pro-image |
⚠️ Parameter wirkungslos | Fest, nicht verstellbar | intern fix | high kann übergeben werden, ändert in Tests aber nichts |
Wichtig ist: thinkingLevel hat nur zwei Stufen, nicht wie bei Textmodellen ein kontinuierlich einstellbares Denkbudget. In der offiziellen Beschreibung heißt es, dass „minimal thinking“ nicht bedeutet, dass das Modell gar nicht nachdenkt. Selbst in der Standardstufe führt das Modell also eine gewisse Grundform der Inferenz aus – nur eben nicht mit mehreren Runden zur Kompositionsprüfung wie bei high.
Das ist auch ein interessantes Signal für die Branche. Bei früheren Bildgenerierungsmodellen – ob nano banana oder die erste Version von flash-image – gab es in der offiziellen API keinen Parameter für Denkstufen. Entweder wurde mit einer festen Strategie generiert, oder man musste Mängel in der Bildkomposition vollständig über die Eingabeaufforderung ausgleichen. In der 3.1-Generation hat Google den Inferenzmechanismus „erst planen, dann generieren“ für die Flash-Serie geöffnet. Im Kern wurde damit ein Denkparadigma, das zuvor nur bei Textmodellen validiert war, auf die Bilderzeugung übertragen. Wer diesen Hintergrund versteht, kann besser einschätzen, ob andere Anbieter mit ihren Bildmodellen einen ähnlichen Weg gehen werden.
🎯 Technischer Hinweis: Wenn Sie Gemini-Bildmodelle über APIYI apiyi.com aufrufen, sollten Sie zunächst mit der Standardstufe
minimalden Workflow stabil zum Laufen bringen und erst danach anhand der tatsächlichen Bildqualität entscheiden, ob Sie aufhighwechseln. Die Plattform bietet eine einheitliche Schnittstelle, sodassgemini-3.1-flash-image,flash-lite-imageundpro-imagemit demselben Code umgeschaltet werden können – ideal für A/B-Tests.
thinkingLevel 参数详解与调用方式
thinkingLevel ist kein eigenständiger Parameter, sondern steckt als Objekt thinkingConfig unter generationConfig und wird zusammen mit includeThoughts verwendet. includeThoughts legt fest, ob die Denkzusammenfassung des Modells an den Aufrufer zurückgegeben wird; thinkingLevel steuert die „Intensität“ des Nachdenkens. Beides sind entkoppelte Schalter – nicht verwechseln.
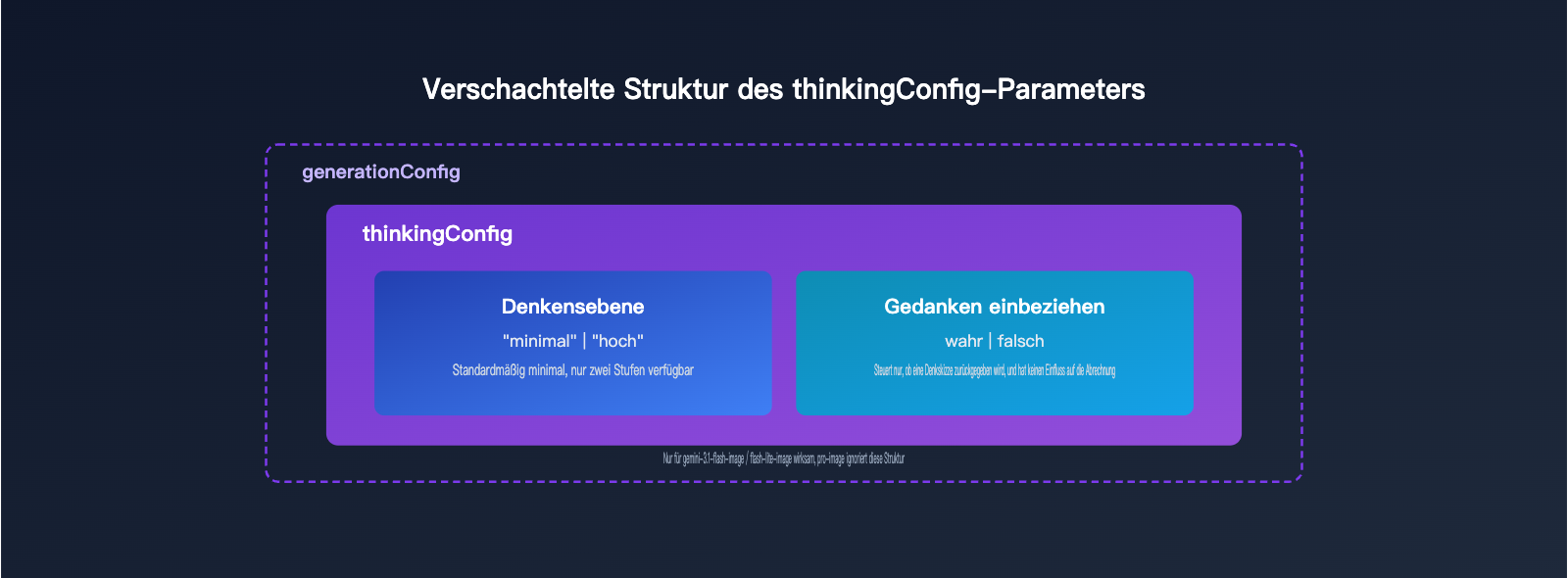
Die folgende Tabelle fasst Typ und Wertebereich der beiden wichtigen Felder im Objekt thinkingConfig zusammen.
| Feld | Typ | Mögliche Werte | Standardwert | Wirkung |
|---|---|---|---|---|
| thinkingLevel | Enum-String | minimal / high |
minimal |
Steuert die Schlussfolgerungsintensität des Modells, wirkt nur bei Flash-Bildmodellen |
| includeThoughts | Boolescher Wert | true / false |
false |
Ob der Denkprozess im Response zurückgegeben wird, hat keinen Einfluss auf die Abrechnung |
Bei der tatsächlichen Nutzung ist die Struktur in den drei gängigen Sprachen identisch: Man legt einfach ein thinkingConfig-Objekt in config ab. Beispiel in Python:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Über den APIYI-Gateway aufrufen
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-image",
messages=[{"role": "user", "content": "Zeichne eine Katze, die unter einem Schneeberg Kaffee trinkt"}],
extra_body={
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": True
}
}
)
print(response.choices[0].message.content)
Vollständiges Beispiel für den nativen REST-Aufruf anzeigen
{
"contents": [{"parts": [{"text": "Zeichne eine Katze, die unter einem Schneeberg Kaffee trinkt"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
Die JavaScript-SDK-Schreibweise hat die gleiche Struktur, nur dass die REST-Snake-Notation in ein camelCase-thinkingConfig-Objekt übertragen wird; die übrigen Feldnamen bleiben unverändert. An der eigentlichen Aufruflogik ändert sich in den drei Sprachen nichts. Merken Sie sich einfach die Regel: thinkingConfig hängt nur unter generationConfig.
Ein Detail ist leicht als Stolperfalle zu übersehen: Die Werte von thinkingLevel sind groß-/kleinschreibungs-sensitive String-Enums. In den offiziellen Beispielen tauchen sowohl "High" als auch "high" auf. In Tests wurden beide Schreibweisen vom Gateway korrekt erkannt und wirksam umgesetzt. Um aber nicht von nicht dokumentiertem Kompatibilitätsverhalten abhängig zu sein, sollten Sie im Code einheitlich die Kleinbuchstaben-Variante "high" und "minimal" verwenden. So gibt es später keine Überraschung, falls die Groß-/Kleinschreibung serverseitig enger validiert wird.
Empfehlung: Holen Sie sich über APIYI auf apiyi.com ein kostenloses Testkontingent und prüfen Sie direkt im Gateway, ob die
thinkingConfig-Parameter korrekt durchgereicht werden. Das ist deutlich bequemer, als erst einen offiziellen Key zu beantragen und dann zu debuggen.
APIYI Praxistest: Echte Auswirkungen von thinkingLevel auf Token und Latenz
So klar eine Doku auch geschrieben ist – echte Messwerte sind oft anschaulicher. Wir haben mit derselben Eingabeaufforderung für 1K-Auflösung im Text-zu-Bild-Modus über den APIYI-Gateway drei Fälle getestet: minimal bei gemini-3.1-flash-image, high bei gemini-3.1-flash-image sowie das Erzwingen von high bei gemini-3-pro-image.
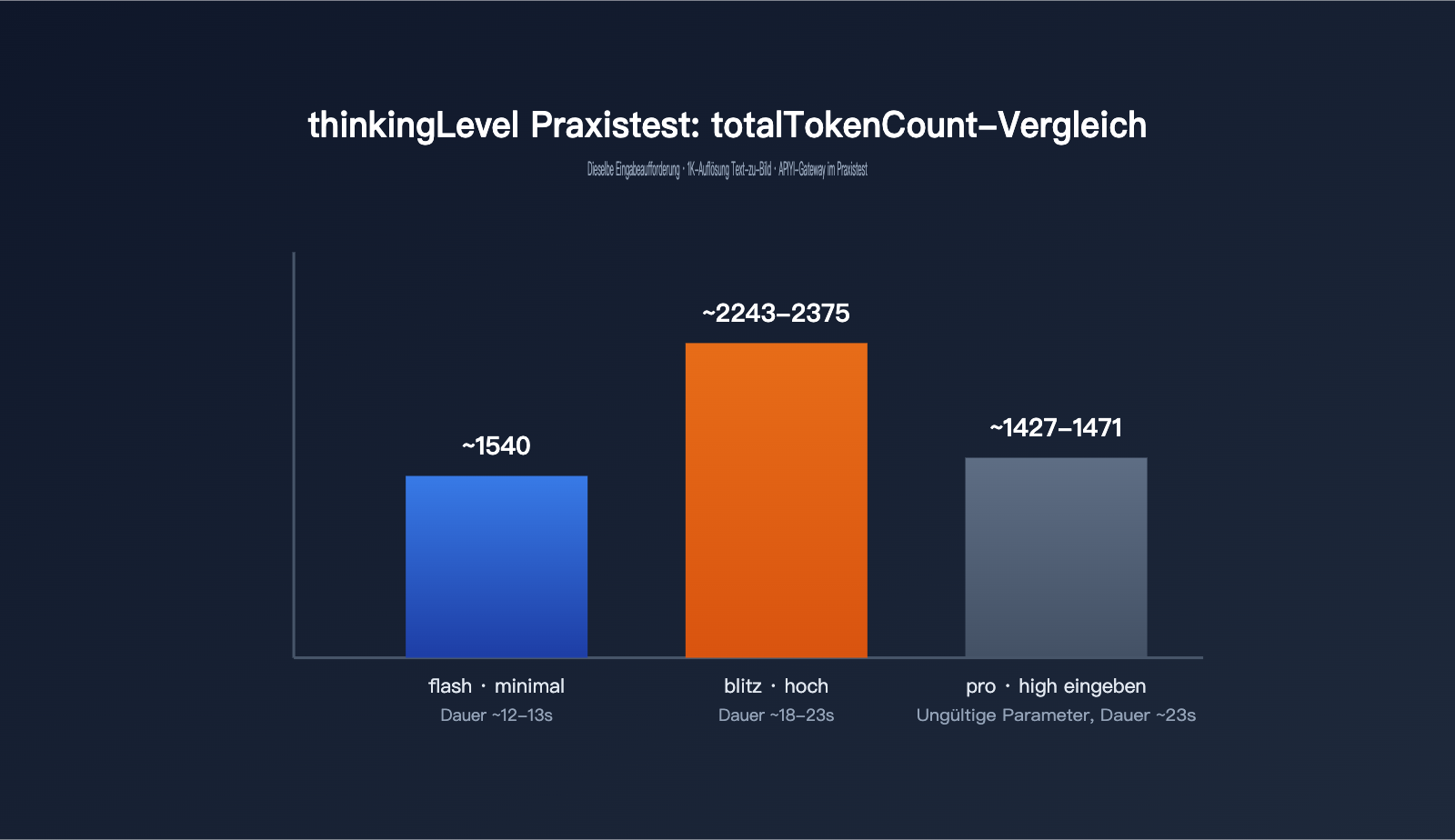
| Modell / Einstellung | thoughtsTokenCount | Bild-Tokens | totalTokenCount | Dauer |
|---|---|---|---|---|
| gemini-3.1-flash-image · minimal (Standard) | kein solches Feld | 1120 | ca. 1540 | ca. 12–13 s |
| gemini-3.1-flash-image · high | 700–792 | 1120 | ca. 2243–2375 | ca. 18–23 s |
| gemini-3-pro-image · high übergeben | 181–214 (wie Standard) | 1120 | ca. 1427–1471 | ca. 23 s |
Diese Daten zeigen drei wichtige Punkte. Erstens: Sobald thinkingLevel auf high gesetzt wird, steigt thoughtsTokenCount von standardmäßig 0 – im Response erscheint das Feld dann nicht einmal – auf etwa 700 bis 800. Der gesamte Tokenverbrauch steigt damit um fast 50 %, und auch die Antwortzeit verlängert sich von 12–13 Sekunden auf 18–23 Sekunden. Denken kostet also tatsächlich Geld und Zeit. Zweitens: Unabhängig davon, ob minimal oder high verwendet wird, bleibt die Ausgabe der Bild-Tokens immer bei 1120. Das zeigt, dass thinkingLevel nur beeinflusst, wie das Modell „denkt“, nicht aber die Auflösung des Bildes oder die Bildabrechnung. Drittens: Wenn high an gemini-3-pro-image übergeben wird, gibt es zwar keinen Fehler, aber mit 181–214 Denk-Tokens ist praktisch kein Unterschied zum Standard zu sehen. Das bestätigt die Aussage der offiziellen Doku, dass das Denkverhalten bei pro-image konstant ist und sich nicht extern steuern lässt.
Mit anderen Worten: Wenn Ihre Geschäftslogik einen einheitlichen thinkingConfig-Parameter an Flash, Flash-Lite und Pro verteilt, ignoriert pro-image diesen Parameter stillschweigend. Es bricht also nicht ab, passt aber auch die Denkintensität nicht wie gewünscht an.
Noch ein Hinweis: Die Werte oben stammen nicht aus einer Einzelmessung, sondern aus mehreren identischen Requests pro Einstellung. Deshalb schwankt thoughtsTokenCount bei high zwischen 700 und 792 und ist kein fester Wert. Denkaufgaben sind naturgemäß etwas zufällig; der interne Pfad der Schlussfolgerung ist nicht jedes Mal exakt gleich, also schwankt auch der Tokenverbrauch leicht. Das grobe Niveau und der Trend bei der Latenz sind aber stabil reproduzierbar. Es kommt also nicht vor, dass high plötzlich schneller als minimal ist oder die Denk-Tokens unerwartet in die Tausende schießen.
Denken-Token und Abrechnungsregeln für Bildmodelle
Viele Entwickler vergleichen das Feld thoughtsTokenCount beim ersten Blick unwillkürlich mit den Denk-Kosten von Textmodellen. Bei Bildmodellen ist der Denkprozess aber tatsächlich in zwei Teile der Abrechnung aufgeteilt. Das zu verstehen ist wichtig für die Kostenkontrolle.
| Dimension | Denken bei Textmodellen | Denken bei Bildmodellen |
|---|---|---|
| Form des Denk-Ergebnisses | Reine textuelle Schlusskette | Textzusammenfassung + bis zu zwei temporäre Konstruktionsskizzen |
| Größenordnung der Denk-Token | Bis zu mehreren Tausend | Im Pro-Tarif nicht über 400, im Flash-high-Tarif etwa 700–800 |
| Hauptfeld für die Kosten | thoughtsTokenCount | Skizzen werden in candidatesTokenCount eingerechnet und als normales Bild-Part abgerechnet |
| Abrechnung pro Skizze | Nicht anwendbar | Bei 1K-Auflösung etwa 1120 Tokens, also ca. 0,0336 US-Dollar pro Bild |
Einfluss von includeThoughts auf die Abrechnung |
Kein Einfluss, feste Abrechnung | Kein Einfluss, feste Abrechnung |
Die offizielle Dokumentation betont ausdrücklich: Egal ob includeThoughts auf true oder false gesetzt ist, die beim Denken entstehenden Tokens werden ganz normal berechnet. Das haben wir auch im Test bestätigt — nachdem includeThoughts aktiviert wurde, änderten sich Rückgabeformat und Gesamtabrechnung gar nicht. Es kam nur ein zusätzlicher Abschnitt mit einer Denk-Zusammenfassung für Debugging-Zwecke dazu. Anders gesagt: includeThoughts ist nur ein Schalter für „anzeigen oder nicht“, nicht für „bezahlen oder nicht“. Dieses Detail wird leicht missverstanden.
Noch wichtiger: Der größere Kostenblock bei Bildmodellen steckt nicht im Feld thoughtsTokenCount, sondern in den temporären Konstruktionsbildern, die während der Inferenz erzeugt werden. Laut offizieller Dokumentation kann das Modell in der Denkphase bis zu zwei temporäre Bilder erzeugen, um Komposition und logische Plausibilität zu prüfen. Diese Skizzen werden als normale Bild-Parts zurückgegeben und in candidatesTokenCount eingerechnet, also zum Standardpreis für Ausgabe-Bilder abgerechnet. Das heißt: Ein einmaliger High-Tarif-Aufruf für die generative Bilderzeugung kann praktisch unbemerkt ein bis zwei „unsichtbare“ Skizzenkosten zusätzlich verursachen. Das wird bei der Kostenplanung leicht übersehen.
Eine konkrete Rechnung macht das greifbarer. Nehmen wir an, ein 1K-Bilderzeugungsauftrag läuft im High-Tarif, der Denktext verbraucht etwa 750 Tokens, und das Modell erzeugt während der Inferenz tatsächlich zwei temporäre Skizzen. Zusammen mit dem finalen Bild entstehen theoretisch drei Bild-Parts. Bei 1120 Tokens und rund 0,0336 US-Dollar pro Bild liegen die reinen Ausgabe-Kosten für diese drei Bilder schon nahe an 0,1 US-Dollar. Mit den Kosten für den Denktext zusammen kann der Gesamtaufwand also 2–3 Mal so hoch sein wie im minimalen Tarif. Ob tatsächlich zwei Skizzen ausgelöst werden, hängt davon ab, wie das Modell die aktuelle Eingabeaufforderung bewertet. Es ist also nicht so, dass bei jedem High-Tarif-Aufruf automatisch zwei Skizzen erzeugt werden. Genau deshalb liegt der gemessene Gesamt-Tokenverbrauch oft in einem Bereich wie 2243–2375 und nicht exakt bei einer Verdopplung.
💰 Kostenoptimierung: Für Teams mit hoher Token-Kosten-Sensibilität empfiehlt es sich, zuerst über die Aufruf-Logs der APIYI apiyi.com-Plattform den tatsächlichen
totalTokenCountzu prüfen und erst dann zu entscheiden, ob der High-Tarif dauerhaft aktiviert bleiben soll. So vermeidet man Budgetüberschreitungen durch übersehene Skizzen-Abrechnung.
Für welche Szenarien High sinnvoll ist und wann Minimal ausreicht
Auf Basis der Tests lässt sich eine einfache Entscheidungshilfe geben.

| Geschäftsszenario | Empfohlene Stufe | Begründung |
|---|---|---|
| Massenhafte Erstellung von Marketing-Bildern, bei denen keine hohe Präzision der Komposition nötig ist | minimal (Standard) | Geringere Latenz, kontrollierbare Token-Kosten, reicht für die tägliche Bilderzeugung |
| Komplexe Kompositionen mit mehreren Motiven, bei denen Textlayout oder räumliche Beziehungen exakt eingehalten werden müssen | high | Zusätzliche Denkzeit bringt höhere Genauigkeit bei der Komposition und lohnt sich für die Qualität |
| E-Commerce-Detailseiten, Poster und ähnliche Szenarien mit geringer Fehlertoleranz | high | Weniger Nachbearbeitung und Neugenerierung, dadurch kann die Gesamtkostenrechnung sogar günstiger sein |
| Echtzeit-Interaktionen mit sehr hohen Anforderungen an die Antwortgeschwindigkeit | minimal | Im High-Tarif verlängert sich die Latenz um 5–10 Sekunden, das passt nicht zu starken Interaktionsanforderungen |
Aufruf von gemini-3-pro-image |
Keine Einstellung nötig | Das Denkverhalten dieses Modells ist fest, ein gesetzter Parameter hat keine Wirkung |
Kurz gesagt: High eignet sich vor allem für Szenarien, in denen „beim ersten Mal sitzen“ wichtiger ist als „schnell ein Bild bekommen“. Wenn eure Anwendung häufig neu ansetzen und die Eingabeaufforderung mehrfach anpassen muss, um eine passende Komposition zu erreichen, dann ist High oft die bessere Wahl. Ihr zahlt zwar pro Aufruf etwas mehr, bekommt aber eine höhere Erfolgsquote beim ersten Versuch. Insgesamt kann das sogar günstiger sein.
In der praktischen Umsetzung ist es am sinnvollsten, thinkingLevel als konfigurierbare Option zu behandeln und nicht fest im Code zu verdrahten. Beispiel: Je nach vom Aufrufer übergebenem Geschäftstyp wird automatisch geroutet — Batch-Jobs standardmäßig auf minimal, Anfragen mit präzisem Layout oder mehreren Objekten im Raum automatisch auf high. So bleibt der Durchschnittspreis unter Kontrolle, ohne in kritischen Szenarien auf Qualität zu verzichten. Wenn das Team gleichzeitig die Aufruflogik für flash, flash-lite und pro pflegt, sollte die Parametrisierung in einer gemeinsamen Schicht erfolgen. Dort wird thinkingLevel nur an Modelle weitergegeben, die es tatsächlich unterstützen. So vermeidet man, dass ungültige Parameter an pro-image durchgereicht werden und die Fehlersuche erschweren.
🚀 Schnellstart: Für schnelle Prototypen empfiehlt sich die APIYI apiyi.com-Plattform. Mit derselben
base_urllassen sich minimal und high direkt vergleichen, ohne separate Authentifizierungsdaten für unterschiedliche Stufen konfigurieren zu müssen.
Häufige Fragen
Q1: Haben gemini-3.1-flash-lite-image und gemini-3.1-flash-image die gleiche Inferenzleistung?
Beide teilen sich dieselbe thinkingConfig-Parameterstruktur, und die unterstützten Stufen sind ebenfalls minimal und high. Allerdings ist flash-lite als Leichtgewichts-Version positioniert; die tatsächliche Denktiefe und die Detailtiefe des finalen Bildes sind meist schwächer als bei flash-image. Das zeigt sich auch im Namensschema: Die flash-lite-Reihe ist bei Textmodellen traditionell auf „schneller, günstiger, leicht reduzierte Genauigkeit“ ausgelegt, und die Bildmodelle folgen derselben Logik. Mit der high-Stufe lässt sich die Schwäche des Leichtgewichtsmodells bei komplexen Kompositionen bis zu einem gewissen Grad ausgleichen, aber die Leistung von flash-image wird sich kaum vollständig erreichen lassen. Für einen quantitativen Vergleich kannst du über die APIYI-Plattform apiyi.com beide Modelle parallel mit derselben Eingabeaufforderung aufrufen und thoughtsTokenCount sowie das Bildergebnis direkt vergleichen.
Q2: Führt das Übergeben des thinkingLevel-Parameters an gemini-3-pro-image zu einem Fehler?
Nein. Unsere Tests zeigen: Wenn der high-Parameter übergeben wird, kommt die Anfrage normal zurück, aber thoughtsTokenCount bleibt im Bereich von 181–214 und ist nahezu identisch mit dem Fall ohne Parameter. Das zeigt, dass das Modell intern ein festes Denkverhalten hat und keine externe Steuerung akzeptiert. Bei Batch-Aufrufen mehrerer Modelle solltest du in der Business-Logik den Modellnamen separat prüfen, damit nicht fälschlicherweise angenommen wird, der Parameter hätte بالفعل gewirkt.
Q3: Müssen nach dem Einschalten der high-Stufe auch Bildauflösung oder Qualitätsparameter angepasst werden?
Nein. Die Messdaten zeigen, dass die Bild-Token in den Stufen minimal und high stabil bei 1120 liegen. Das bedeutet, dass thinkingLevel nur auf den internen Inferenzprozess des Modells wirkt und die Auflösung des Ausgabebildes nicht verändert. Die Auflösung wird weiterhin separat über die Größenparameter in imageConfig gesteuert und hat nichts mit der Denkstufe zu tun. Anders gesagt: thinkingLevel und Auflösungsparameter sind zwei unabhängige Stellschrauben – die eine regelt, wie gründlich „nachgedacht“ wird, die andere, wie groß und detailliert das Bild wird. Beides lässt sich frei kombinieren; es gibt weder eine Ausschließung noch eine gekoppelte Wirkung.
Zusammenfassung
gemini-3.1-flash-lite-image unterstützt tatsächlich den Inferenzmodus, was sowohl durch die offizielle Dokumentation als auch durch die Messdaten von APIYI bestätigt wurde. Für thinkingLevel gibt es nur die beiden Stufen minimal und high. high erhöht die Denk-Token auf über 700 und verlängert die Gesamtlaufzeit um etwa 5–10 Sekunden, verändert aber den Token-Verbrauch des endgültigen Bildes nicht. gemini-3-pro-image akzeptiert diesen Parameter zwar ohne Fehler, setzt ihn in der Praxis jedoch nicht um. Zu verstehen, dass „gedachte Texte“ über thoughtsTokenCount und „Kompositionsskizzen“ über candidatesTokenCount abgerechnet werden, ist ein wichtiger Hebel zur Kostenkontrolle bei der Bilderzeugung. Wenn du zwischen mehreren Gemini-Bildmodellen schnell hin- und herschalten und sie testen möchtest, empfiehlt sich die einheitliche Gateway-Nutzung über APIYI apiyi.com, damit du nicht für jedes Modell separat API-Schlüssel beantragen und den Aufrufcode pflegen musst.
Die Daten in diesem Artikel stammen aus Praxistests des APIYI-Technikteams. Wenn du dich über weitere Details zu den Gemini-Bildmodellen austauschen möchtest, kontaktiere gern den technischen Support über APIYI apiyi.com.
Referenzmaterial
- Gemini API Offizielle Dokumentation – Bilderzeugung: Beschreibung des Parameters für die Denkstufe (thinking levels)
- Link:
ai.google.dev/gemini-api/docs/generate-content/image-generation
- Link: