Anmerkung des Autors: Die neueste Mini-Serie von OpenAI, gpt-5.4-mini, ist jetzt über die API verfügbar. Mit 54,4 % in SWE-Bench Pro übertrifft sie das GPT-5 mini (45,7 %). Dieser Artikel bietet eine vollständige Analyse des Leistungssprungs, des 90%-Rabatts für Cache-Eingaben sowie der Abwägungen beim Upgrade von 4o-mini/5-mini.
Falls Sie noch gpt-4o-mini oder gpt-5-mini verwenden, haben Sie vielleicht bemerkt, dass OpenAI am 17.03.2026 das "bisher stärkste Mini-Modell" veröffentlicht hat: gpt-5.4-mini. Es erreicht 54,4 % in SWE-Bench Pro (GPT-5 mini lag bei 45,7 %), 60,0 % in Terminal-Bench 2.0 und 72,1 % bei OSWorld-Verified für Computer-Use-Aufgaben – und das bei einer doppelt so schnellen Antwortzeit wie das Vorgängermodell GPT-5 mini.
Das sieht nach einem kleinen Update aus, doch die Designabsicht geht weit darüber hinaus. OpenAI positioniert gpt-5.4-mini explizit als ein Modell, das "für Programmierung, Computer Use und Subagents optimiert" wurde – zum ersten Mal werden agentische Fähigkeiten in das Einsteiger-Preissegment gebracht. Dieser Artikel analysiert, was GPT-5.4 mini wirklich ist, wo die Upgrades gegenüber 4o-mini/5-mini liegen und was das für Ihre tägliche Arbeit bedeutet.
Kernwert: Eine umfassende Analyse der Integrationslösung für GPT-5.4 mini unter Berücksichtigung von Leistungssteigerung, Preisstruktur, Cache-Optimierung und den Auswahlkriterien gegenüber der alten Mini-Serie.

Kernpunkte der GPT-5.4 mini API
| Punkt | Beschreibung | Wert |
|---|---|---|
| Leistungssprung | SWE-Bench Pro 54,4 % vs. GPT-5 mini 45,7 % | 19 % höhere Genauigkeit bei Programmieraufgaben |
| 400K Kontextfenster | 400.000 Token Input + 128.000 Output | Verarbeitung ganzer Code-Repositories/langer Dokumente |
| 90 % Cache-Rabatt | Cache-Input nur $0,075/1M | Massive Kostensenkung bei häufigen Kontext-Szenarien |
| Computer Use | OSWorld-Verified 72,1 % | Erste vollständige Unterstützung für Desktop-Automatisierung in der Mini-Serie |
| Standard-Zugriff | Direkt verfügbar über APIYI | Sofort einsatzbereit für neue Nutzer, keine Beantragung nötig |
Hauptunterschiede zwischen GPT-5.4 mini und der vorherigen Mini-Generation
GPT-5.4 mini ist nicht einfach eine "preisreduzierte Version". OpenAI hat in drei Dimensionen substantielle Leistungsverbesserungen vorgenommen:
Erstens: Subagent-Orchestrierung erstmals im Mini-Preissegment. In der Vergangenheit war es für Mini-Modelle nahezu unmöglich, mehrere Teilaufgaben zuverlässig zu koordinieren oder Tool-Aufrufketten zu verwalten – sie verloren nach 3-4 Schritten oft den Kontext oder ignorierten Anweisungen. Durch einen verbesserten Reasoning-Token-Mechanismus und Training zur Befolgung von Anweisungen erreicht GPT-5.4 mini in Szenarien mit Multi-Agenten-Zusammenarbeit eine Zuverlässigkeit von etwa 90 % im Vergleich zur GPT-5.4-Standardversion, bei nur 1/6 der Kosten.
Zweitens: Volle Unterstützung für Computer Use. GPT-5.4 mini ist das erste Modell der OpenAI-Mini-Serie, das OSWorld-Verified auf über 70 % bringt. Das bedeutet, dass Sie einen vollständigen Desktop-Automatisierungs-Agenten zum Mini-Preis einsetzen können, um Aufgaben wie Klicken, Formularausfüllen oder Dateimanipulationen durchzuführen.
Drittens: 2-fache Steigerung der Antwortgeschwindigkeit. Bei gleichzeitiger Leistungssteigerung ist GPT-5.4 mini doppelt so schnell wie GPT-5 mini. Für Szenarien mit hohem Durchsatz (Kundenservice, Batch-Verarbeitung) bedeutet dies eine direkte Kostenersparnis.

Schnelleinstieg in die GPT-5.4 mini API
Minimalistisches Python-Beispiel (Ersatz für alte mini-Modelle)
Wenn Sie bisher gpt-4o-mini oder gpt-5-mini verwendet haben, müssen Sie lediglich den Parameter model anpassen, um auf gpt-5.4-mini umzusteigen. Der restliche Code bleibt unverändert:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-mini", # Nur diese Zeile ändert sich
messages=[
{"role": "user", "content": "Implementiere einen LRU-Cache mit Nebenläufigkeitsunterstützung in Python"}
]
)
print(response.choices[0].message.content)
Minimalistisches cURL-Beispiel
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "gpt-5.4-mini",
"messages": [
{"role": "user", "content": "Fasse die Kernpunkte dieses langen Dokuments zusammen"}
]
}'
Aufruf-Paradigma für Computer Use (erstmals in der mini-Serie unterstützt)
# Computer Use Tools aktivieren
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{
"role": "user",
"content": "Öffne den Browser, suche nach 'OpenAI API Dokumentation' und klicke auf das erste Ergebnis"
}],
tools=[{
"type": "computer_use",
"config": {
"screen_width": 1920,
"screen_height": 1080
}
}]
)
# Das Modell gibt strukturierte Befehle zurück (click/type/scroll etc.)
for action in response.choices[0].message.tool_calls:
print(f"Aktion: {action.function.name}, Parameter: {action.function.arguments}")
Vollständigen Produktionscode anzeigen (inkl. Tracking von Cache-Treffern und Kosten)
import openai
from typing import List, Dict
# GPT-5.4 mini Preise (pro 1M Token)
PRICE_INPUT = 0.75
PRICE_INPUT_CACHED = 0.075 # Preis bei Cache-Treffer (90% Rabatt)
PRICE_OUTPUT = 4.50
def call_gpt54_mini(
messages: List[Dict],
api_key: str,
max_tokens: int = 4096
) -> Dict:
"""
Produktionsreifer GPT-5.4 mini Aufruf mit Tracking der Cache-Trefferquote
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
try:
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=messages,
max_tokens=max_tokens
)
usage = response.usage
input_tokens = usage.prompt_tokens
output_tokens = usage.completion_tokens
# Cache-Treffer-Token (abhängig von der SDK-Version)
cached_tokens = getattr(usage, 'prompt_tokens_details', {}).get('cached_tokens', 0)
regular_input = input_tokens - cached_tokens
# Gestaffelte Abrechnung
input_cost = (
regular_input / 1_000_000 * PRICE_INPUT +
cached_tokens / 1_000_000 * PRICE_INPUT_CACHED
)
output_cost = output_tokens / 1_000_000 * PRICE_OUTPUT
total_cost = input_cost + output_cost
cache_rate = cached_tokens / max(input_tokens, 1) * 100
print(f"📊 Input: {input_tokens:,} | Cache-Treffer: {cached_tokens:,} ({cache_rate:.1f}%)")
print(f"📊 Output: {output_tokens:,} Token")
print(f"💰 Kosten dieses Aufrufs: ${total_cost:.4f}")
print(f"💰 Cache-Einsparung: ${(cached_tokens / 1_000_000 * (PRICE_INPUT - PRICE_INPUT_CACHED)):.4f}")
return {
"content": response.choices[0].message.content,
"tokens": {
"input": input_tokens,
"cached": cached_tokens,
"output": output_tokens
},
"cost_usd": total_cost,
"cache_hit_rate": cache_rate
}
except openai.RateLimitError:
return {"error": "Ratenbegrenzung, bitte später erneut versuchen"}
except openai.APIError as e:
return {"error": f"API-Fehler: {str(e)}"}
# Anwendungsbeispiel
result = call_gpt54_mini(
messages=[
{"role": "system", "content": "Du bist ein erfahrener Python-Entwickler"},
{"role": "user", "content": "Überprüfe diesen Code auf Probleme bei der Nebenläufigkeit..."}
],
api_key="YOUR_API_KEY"
)
print(result["content"])
🎯 Tipp für den Start: GPT-5.4 mini ist bei APIYI bereits für die Standard-Gruppe freigeschaltet. Neue Nutzer können das Modell ohne vorherige Beantragung direkt aufrufen. Wir empfehlen die Anbindung über die Plattform APIYI (apiyi.com): Bei Aufladungen von 100 USD erhalten Sie 10 % Bonus, was effektiv einem Rabatt von ca. 15 % gegenüber der offiziellen Website entspricht. Zudem ist eine direkte Verbindung aus dem Inland ohne VPN möglich und das System ist vollständig mit dem OpenAI SDK kompatibel.
Detaillierte Preisübersicht der GPT-5.4 mini API
Offizielle Preisstruktur
Die Preisgestaltung von GPT-5.4 mini liegt etwas über der alten mini-Serie, kann jedoch durch den Cache-Mechanismus die tatsächlichen Kosten erheblich senken:
| Abrechnungsart | Preis (pro 1M Token) | Hinweis |
|---|---|---|
| Input | $0,75 | Standardpreis |
| Gecachter Input | $0,075 | 90 % Rabatt, massive Kostenersparnis |
| Output | $4,50 | Inklusive Reasoning-Token |
| Batch API Input | $0,75 | Identisch mit Standardpreis |
| Region-Data-Residency-Endpunkt | +10 % | Für Szenarien mit Datenresidenz-Anforderungen |
Preisvergleich der drei mini-Generationen
| Modell | Input-Preis | Gecachter Input | Output-Preis | Kontext | Max. Output |
|---|---|---|---|---|---|
| GPT-4o mini | $0,15 | Nicht unterstützt | $0,60 | 128K | 16K |
| GPT-5 mini | $0,25 | $0,025 | $2,00 | 400K | 128K |
| GPT-5.4 mini | $0,75 | $0,075 | $4,50 | 400K | 128K |
⚠️ Wichtige Beobachtung: Der Standardpreis von GPT-5.4 mini ist 5-mal so hoch wie bei GPT-4o mini und 3-mal so hoch wie bei GPT-5 mini. Beachten Sie jedoch zwei entscheidende Fakten: 1) Bei aktivierter Cache-Nutzung können die Kosten pro Aufruf auf $0,0075/1M sinken (in bestimmten Hochfrequenz-Szenarien), und 2) die gesteigerte Leistungsfähigkeit führt oft dazu, dass weniger Debugging-Schleifen nötig sind, was die Gesamtzahl der Aufrufe reduziert.
Kostenkalkulation bei Cache-Treffern
Der 90-prozentige Cache-Rabatt von GPT-5.4 mini ist das am meisten unterschätzte Feature dieses Upgrades:
| Szenario | Input-Token | Cache-Trefferquote | Tatsächliche Kosten pro Aufruf |
|---|---|---|---|
| Hochfrequenz-Support (System-Prompt-Wiederverwendung) | 5K | 80 % | $0,0046 |
| Code-Assistent (Kontext-Wiederverwendung) | 50K | 70 % | $0,034 |
| Fragen zu langen Dokumenten (Dokument-Wiederverwendung) | 200K | 90 % | $0,030 |
| Subagent-Orchestrierung (Geteilte Anweisungen) | 30K | 85 % | $0,0162 |
💰 Optimierungstipp für den Cache: Der Cache-Mechanismus von GPT-5.4 mini ist bei Szenarien mit langen System-Prompts und wiederkehrendem Kontext am effektivsten. Für Anwendungsfälle wie Kundensupport, Code-Assistenten oder Dokumenten-Q&A können die tatsächlichen Kosten sogar unter denen von GPT-5 mini liegen. Nutzen Sie zusätzlich den 10 % Bonus bei Aufladungen auf APIYI (apiyi.com), um Ihre Rechnung weiter zu optimieren.
GPT-5.4 mini API-Leistungssprung
Benchmark-Vergleich
| Bewertungsdimension | GPT-4o mini | GPT-5 mini | GPT-5.4 mini | Steigerung |
|---|---|---|---|---|
| SWE-Bench Pro (Programmierung) | ~23% | 45,7% | 54,4% | +8,7pp |
| Terminal-Bench 2.0 | ~30% | ~50% | 60,0% | +10pp |
| OSWorld-Verified (Computer Use) | Nicht unterstützt | ~58% | 72,1% | +14pp |
| Reaktionsgeschwindigkeit | Basis | Basis | 2x schneller | Verdoppelt |
Analyse der Leistungssteigerung
SWE-Bench Pro 54,4%: Dies ist der bemerkenswerteste Wert des GPT-5.4 mini. Mit 54,4% nähert er sich dem Standardmodell GPT-5.4 (57,7%) an, kostet jedoch nur ein Sechstel. Für Aufgaben wie die Korrektur echter GitHub-Issues oder Refactoring von Codebasen ist das mini-Modell nun eine zuverlässige Wahl.
Terminal-Bench 60,0%: Dies bedeutet, dass das mini-Modell über 60% der Aufgaben bei der Ausführung von Terminalbefehlen, beim Debugging und in automatisierten Workflows stabil bewältigt. In Kombination mit Subagent-Orchestrierung lassen sich damit zuverlässige CI/CD-Automatisierungen oder Bots für Code-Reviews erstellen.
OSWorld 72,1%: Ein historischer Durchbruch für die mini-Serie bei Computer-Use-Aufgaben. Es ermöglicht den Einsatz von Desktop-Automatisierungs-Agenten zum Preis eines mini-Modells, um Formulare auszufüllen, Klicks auszuführen oder Dateivorgänge zu verarbeiten.
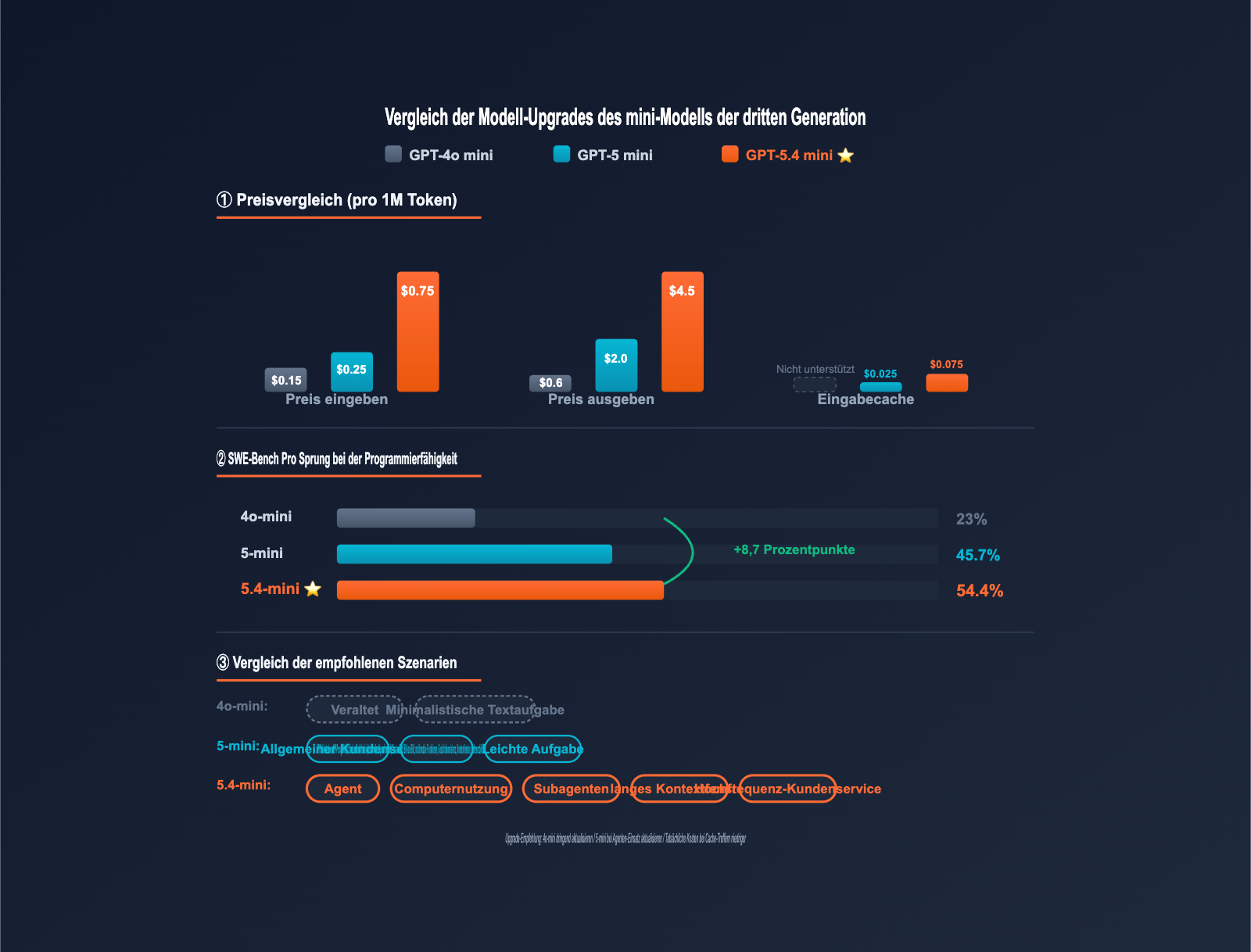
Vergleich: GPT-5.4 mini vs. vergleichbare Modelle
| Modell | Input / Output | Kontext | Programmierfähigkeit | Computer Use | Empfohlene Szenarien |
|---|---|---|---|---|---|
| GPT-4o mini | $0,15 / $0,60 | 128K | schwach | nicht unterstützt | veraltet, einfache Aufgaben |
| GPT-5 mini | $0,25 / $2,00 | 400K | mittel | teilweise unterstützt | allgemeiner Kundenservice, leichte Aufgaben |
| GPT-5.4 mini | $0,75 / $4,50 | 400K | stark | voll unterstützt | Agent / Computer Use / langer Kontext |
| GPT-5.4 Standard | $5,00 / $30,00 | 1M | top | top | komplexe Schlussfolgerungen, kritische Entscheidungen |
| Claude Haiku 4.5 | $0,80 / $4,00 | 200K | stark | nicht unterstützt | starker Schreibstil / Textproduktion |
Empfehlungen für die Upgrade-Entscheidung
4o-mini → 5.4-mini: GPT-4o mini bietet bei einfachen Textaufgaben weiterhin einen Preisvorteil. Die Leistungsfähigkeit ist jedoch deutlich zurückgefallen. Sobald Ihre Anwendung Schlussfolgerungen, Programmierung oder einen langen Kontext erfordert, lohnt sich das Upgrade auf 5.4-mini. Selbst bei einem 5-fach höheren Einzelpreis ist das Verhältnis von Aufrufhäufigkeit zu Qualitätssteigerung meist wirtschaftlicher.
5-mini → 5.4-mini: GPT-5 mini ist für allgemeinen Kundenservice oder Übersetzungen weiterhin gut geeignet. Wenn Sie jedoch Computer Use, Subagent-Orchestrierung oder komplexe Agent-Workflows benötigen, ist 5.4-mini die erste Wahl. Zudem ist der Cache-Rabatt zwar bei 90 % geblieben, aber durch die höheren Absolutwerte langfristig kosteneffizienter.
5.4-mini → 5.4 Standard: GPT-5.4 mini bietet bei 80 % der Standardaufgaben eine ähnliche Leistung bei nur einem Sechstel der Kosten. Nur wenn Aufgaben tatsächlich höchste Schlussfolgerungsfähigkeiten erfordern (mathematische Beweise, komplexe 20-Stunden-Agent-Prozesse), sollten Sie auf die Standardversion wechseln.
📊 Upgrade-Pfad: Über APIYI (apiyi.com) können Sie unter demselben API-Schlüssel die tatsächliche Leistung von 4o-mini, 5-mini, 5.4-mini und 5.4 Standard nahtlos vergleichen, indem Sie einfach den
model-Parameter anpassen. Dieser einheitliche Zugang eignet sich besonders für Teams, die schrittweise migrieren oder A/B-Tests durchführen möchten.
Anwendungsbereiche für GPT-5.4 mini API
Die Kombination aus "hoher Leistungsfähigkeit + Cache-Optimierung + Computer Use + Subagents" macht GPT-5.4 mini ideal für folgende Szenarien:
- Hochvolumiger Dialog-Kundenservice: Hohe Cache-Trefferquote, schnelle Antwortzeiten und ausreichende logische Tiefe für komplexe Anfragen.
- Großflächige Content-Generierung: Batch-Zusammenfassungen, Übersetzungen und Umschreibungen; das 400K-Kontextfenster verarbeitet ganze Dokumente in einem Durchgang.
- Subagent-Kollaboration: Erstmalig zuverlässige Orchestrierung von Teilaufgaben im "mini"-Preissegment.
- Desktop-Automatisierungs-Agenten: Mit 72,1 % in OSWorld werden Browser-, Formular- und Dateioperationen möglich.
- Leichte Code-Vervollständigung und -Überprüfung: Mit 54,4 % in SWE-Bench Pro nahe an der Standardversion, ideal für die IDE-Integration.
- Batch-Dokumentenverarbeitung: In Kombination mit der Batch-API und Caching extrem kosteneffizient bei der Verarbeitung zehntausender Dokumente.
- Bildungs- und Tutoring-Tools: Verbesserte logische Token sorgen für zuverlässigere Problemlösungen und Erklärungen.
🎯 Entscheidungshilfe: Wenn Ihre Anwendung täglich mehr als 10.000 Aufrufe generiert, die Cache-Trefferquote über 50 % liegt und Sie logische Schlussfolgerungen oder Tool-Fähigkeiten benötigen, ist GPT-5.4 mini das Modell, auf das Sie 2026 umsteigen sollten. Direkt über APIYI (apiyi.com) verfügbar, in der Default-Gruppe ohne vorherige Beantragung nutzbar.
Integrationsanleitung für GPT-5.4 mini bei APIYI
Strategie für die Freischaltung von Default-Gruppen
Die Plattform APIYI wendet für GPT-5.4 mini eine Strategie an, die der von Grok 4.3 entspricht, sich jedoch von der für GPT-5.5 Pro unterscheidet:
- ✅ Default-Gruppe: Vollständig geöffnet, für neue Benutzer direkt nach der Registrierung verfügbar.
- ✅ SVIP-Gruppe: Vollständig geöffnet, ohne jegliche Einschränkungen.
- ✅ Cache-Rabatt synchronisiert: Der Cache-Preis von $0,075/1M ist vollständig anwendbar.
Warum ist GPT-5.4 mini für alle Gruppen geöffnet, während GPT-5.5 Pro nur für SVIP verfügbar ist? Der Kern liegt in der Risikobewertung pro Modellaufruf:
- GPT-5.4 mini: Ein einzelner Aufruf kostet in der Regel nur wenige Cent, daher ist die Freischaltung für alle Gruppen risikofrei.
- GPT-5.5 Pro: Ein einzelner Aufruf kann mehrere Dollar kosten; hier ist der Schutz durch die SVIP-Gruppe erforderlich, um eine versehentliche Fehlbenutzung durch Anfänger zu vermeiden.
Dieses Design der risikobasierten Verwaltung hält die Hürde für die mini-Serie für alle Entwickler niedrig, während bei hochpreisigen Modellen ein Gruppenschutz greift.
Kostenvergleich: APIYI vs. offizielle Webseite
| Projekt | OpenAI Webseite | APIYI apiyi.com |
|---|---|---|
| Basispreis | $0,75 / $4,50 pro 1M | $0,75 / $4,50 pro 1M (gleicher Preis) |
| Cache-Rabatt | $0,075 / 1M (90%) | $0,075 / 1M (vollständig synchron) |
| Aufladebonus | Keiner | $100 aufladen, $10 geschenkt (10%) |
| Tatsächliche Kosten | 100% Standardpreis | ca. 90% Standardpreis (ca. 15% Rabatt) |
| Zugriff aus China | VPN erforderlich | Direktzugriff, kein VPN nötig |
| Zahlungsmethoden | Internationale Kreditkarte | RMB, Alipay, WeChat Pay unterstützt |
| SDK-Kompatibilität | OpenAI nativ | Vollständig kompatibel mit OpenAI SDK |
| Gruppenbeschränkung | Keine | Default + SVIP vollständig offen |
💰 Kostenoptimierung: Durch die Anbindung von GPT-5.4 mini über APIYI apiyi.com erhalten Sie bei einer Aufladung von 100 USD zusätzlich 10% Bonus, was effektiv einem Rabatt von 15% gegenüber dem offiziellen Preis entspricht, bei vollständig synchronem Cache-Rabatt. Für Anwendungen mit hohem Aufrufvolumen und hoher Cache-Trefferquote können die Gesamtkosten um über 20% niedriger sein als bei OpenAI direkt.
Häufig gestellte Fragen (FAQ)
Q1: Was ist GPT-5.4 mini? Was sind die Hauptunterschiede zu GPT-5 mini und GPT-4o mini?
GPT-5.4 mini ist das am 17.03.2026 von OpenAI veröffentlichte mini-Modell der neuen Generation und wird als "unser bisher stärkstes mini-Modell" positioniert. Die Hauptunterschiede: 1) SWE-Bench Pro liegt mit 54,4% deutlich vor GPT-5 mini (45,7%) und 4o-mini (23%); 2) Erstmalige vollständige Unterstützung für Computer Use (OSWorld 72,1%); 3) Subagent-Orchestrierung auf mini-Preisniveau; 4) Reaktionsgeschwindigkeit 2x schneller als bei 5 mini. Der Preis ist jedoch auf $0,75/$4,50 gestiegen, was durch Caching teilweise kompensiert werden kann.
Q2: Ich nutze derzeit gpt-4o-mini / gpt-5-mini, lohnt sich ein Upgrade auf 5.4-mini?
Nutzern von 4o-mini wird ein Upgrade dringend empfohlen: Der Leistungsunterschied ist mittlerweile zu groß. Selbst bei einem 5-mal höheren Einzelpreis sind die Gesamtqualität und die Reduzierung von Debugging-Schleifen meist wirtschaftlicher.
Nutzern von 5-mini wird das Upgrade je nach Szenario empfohlen:
- ✅ Upgrade empfohlen: Bei Anwendungen mit Computer Use, Subagents, komplexen Tool-Ketten oder langem Kontext (>200K).
- ⏸️ Weiterhin nutzbar: Einfache FAQ-Bots, leichte Übersetzungen oder reine Textgenerierung, bei denen 5-mini ausreicht.
Best Practice: Führen Sie einen A/B-Test mit demselben API-Schlüssel auf APIYI apiyi.com durch, um zu sehen, was sich mehr lohnt.
Q3: Wie wird der Cache-Rabatt von $0,075/1M für GPT-5.4 mini aktiviert?
Der Cache-Mechanismus von OpenAI wird automatisch ausgelöst, es sind keine zusätzlichen Parameter erforderlich. Wenn das Präfix Ihrer Eingabeaufforderung (in der Regel System-Prompt + geteilter Kontext) mit Anfragen der letzten 5-10 Minuten übereinstimmt, wird der Cache automatisch genutzt und Sie erhalten 90% Rabatt ($0,075/1M).
Optimierungstipps:
- Platzieren Sie den System-Prompt ganz am Anfang des messages-Arrays.
- Geteilten Kontext (z. B. Wissensdatenbanken, Dokumentzusammenfassungen) nach dem System-Prompt einfügen.
- Die eigentliche Benutzeranfrage ganz ans Ende stellen.
- Häufige Aufrufe beibehalten (>5 Minuten Inaktivität führen zum Ablauf des Caches).
Bei Aufrufen über die Plattform APIYI apiyi.com ist der Cache-Rabatt vollständig mit der offiziellen Webseite synchronisiert, eine zusätzliche Konfiguration ist nicht erforderlich.
Q4: Wann sollte ich GPT-5.4 mini und wann die GPT-5.4 Standardversion verwenden?
Szenarien mit Priorität für mini:
- Hoher Durchsatz (>10K Aufrufe/Tag)
- Cache-Trefferquote > 50%
- Aufgaben vom Typ SWE-Bench / Terminal-Bench
- Computer Use Automatisierung
- Kostensensible Produktionsumgebungen
Szenarien mit Priorität für die Standardversion:
- Mathematische Beweise auf FrontierMath-Niveau
- Komplexe Agenten mit 20-stündigen Laufzeiten
- Hochrisikoaufgaben wie juristische Vertragsprüfung oder medizinische Diagnosen
- Kritische Entscheidungen mit einem Wert pro Aufruf > $0,10
Einfaches Prinzip: 80% der Aufgaben lassen sich mit mini erledigen, nur bei sehr komplexen Schlussfolgerungen sollte auf die Standardversion gewechselt werden.
Q5: Wie rufe ich GPT-5.4 mini über APIYI auf? Welche Code-Änderungen sind nötig?
APIYI ist vollständig kompatibel mit dem OpenAI SDK. Es sind nur drei Schritte erforderlich:
- Registrieren Sie sich auf APIYI apiyi.com (keine Bewerbung nötig, Default-Gruppe ist direkt verfügbar).
- API-Schlüssel abrufen.
- Ändern Sie die
base_urlim Code aufhttps://vip.apiyi.com/v1und setzen Sie dasmodelaufgpt-5.4-mini.
client = openai.OpenAI(
api_key="YOUR_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[...]
)
Bei einer Aufladung von 100 USD erhalten Sie 10% Bonus, was effektiv ca. 15% Rabatt entspricht; der Cache-Rabatt ist vollständig synchron.
Q6: Unterstützt GPT-5.4 mini Fine-tuning?
Nein, wird nicht unterstützt. Dies ist eine der Haupteinschränkungen von GPT-5.4 mini. Wenn Ihre Anwendung zwingend Fine-tuning erfordert, müssen Sie wählen zwischen:
- GPT-5 mini (unterstützt Fine-tuning, etwas schwächere Leistung)
- GPT-4o mini (unterstützt Fine-tuning, noch schwächere Leistung)
- GPT-5.4 Standardversion (unterstützt Fine-tuning, 6-facher Preis)
Alternative: Die Kombination aus Reasoning Token, Function Calling und Cache-Mechanismus von GPT-5.4 mini erzielt oft auch ohne Fine-tuning hervorragende Ergebnisse.
Q7: Wie wird Computer Use bei GPT-5.4 mini aufgerufen?
Dies wird über den Parameter tools aktiviert:
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{"role": "user", "content": "Hilf mir, die Webseite zu öffnen und zu suchen..."}],
tools=[{
"type": "computer_use",
"config": {"screen_width": 1920, "screen_height": 1080}
}]
)
Das Modell gibt strukturierte Befehle zurück (click/type/scroll/screenshot). Sie müssen diese Aktionen auf Client-Seite implementieren und die Ergebnisse an das Modell zurückgeben, damit es die Schlussfolgerung fortsetzen kann. Ein OSWorld-Verified-Score von 72,1% bedeutet, dass die meisten Desktop-Aufgaben bewältigt werden können.
Q8: Welche bekannten Einschränkungen hat GPT-5.4 mini?
Zu den Haupteinschränkungen gehören:
- Kein Fine-tuning: Keine Anpassung mit eigenen Datensätzen möglich.
- Keine Bildausgabe: Nur Textausgabe, keine Bilderzeugung möglich.
- Höherer Preis als ältere mini-Modelle: Der Standardpreis ist 5-mal höher als bei 4o-mini, erfordert Optimierung durch Caching.
- Reasoning Token werden bei der Ausgabe berechnet: Bei komplexen Aufgaben können die Ausgabekosten höher ausfallen als erwartet.
- Regionale Datenhaltung +10%: Bei Compliance-Anforderungen fallen zusätzliche Gebühren an.
Für Szenarien, die extrem zeitkritisch sind (<1 Sekunde Antwortzeit), empfehlen wir vor einem Wechsel entsprechende Tests.
GPT-5.4 mini API: Die wichtigsten Punkte
- Leistungssprung: Mit 54,4 % bei SWE-Bench Pro übertrifft es das GPT-5 mini (45,7 %) um ganze 8,7 Prozentpunkte.
- Cache-Rabatt: 90 % Rabatt auf den Eingabe-Cache bei $0,075/1M, was die Kosten in Szenarien mit hoher Frequenz drastisch senkt.
- Computer Use: 72,1 % bei OSWorld; die mini-Serie unterstützt erstmals vollständig die Desktop-Automatisierung.
- Subagent-freundlich: Erstmals wird die Zusammenarbeit mehrerer Agenten in das mini-Preissegment integriert.
- 400K Kontextfenster: Ganze Fachbücher oder vollständige Code-Bibliotheken können in einem Durchgang verarbeitet werden.
- 2x Reaktionsgeschwindigkeit: Verdoppelte Geschwindigkeit bei gleichzeitiger Leistungssteigerung.
- Default-Zugang: Über APIYI direkt in der Standardgruppe verfügbar, ohne dass eine gesonderte Beantragung erforderlich ist.
Zusammenfassung
Die Kernpunkte der GPT-5.4 mini API:
- Upgrade-Motivation: Umfassende Verbesserungen in den drei Dimensionen SWE-Bench Pro, Terminal-Bench und OSWorld; Computer Use und Subagents sind erstmals im mini-Preissegment verfügbar.
- Preisgestaltung: $0,75 / $4,50 pro 1M Token, 90 % Rabatt auf den Eingabe-Cache ($0,075), wodurch die tatsächlichen Kosten in Szenarien mit hoher Frequenz sogar unter denen des alten mini liegen können.
- Zugang: Direkter Modellaufruf über die Standardgruppe von APIYI (apiyi.com); bei einer Aufladung von 100 gibt es 10 dazu, direkte Verbindung aus dem Inland ohne VPN.
GPT-5.4 mini ist nicht einfach nur eine "teurere Version des GPT-5 mini", sondern ein entscheidender Schritt von OpenAI, agentische Fähigkeiten in den Einstiegsbereich zu bringen. Für Anwendungen, die täglich mehr als 10.000 Aufrufe tätigen, eine Cache-Trefferquote von über 50 % aufweisen oder Agent- bzw. Computer-Use-Fähigkeiten benötigen, ist dieses Upgrade nahezu unverzichtbar. Für rein einfache Textaufgaben können GPT-4o mini oder GPT-5 mini weiterhin problemlos genutzt werden.
Wir empfehlen den schnellen Zugriff auf GPT-5.4 mini über die Plattform APIYI (apiyi.com): Die Standardgruppe erfordert keine Beantragung, Cache-Rabatte werden vollständig synchronisiert, Aufladungen werden mit 10 % Bonus belohnt und die Verbindung aus dem Inland ist stabil.
Weiterführende Artikel
Wenn Sie sich für die GPT-5.4 mini API interessieren, empfehlen wir Ihnen folgende weiterführende Lektüre:
- 📘 GPT-5.5 Pro API-Integrationsleitfaden – Erfahren Sie mehr über das Top-Inferenz-Flaggschiff von OpenAI, das eine ideale Ergänzung zum mini-Modell für verschiedene Szenarien darstellt.
- 📊 Deep Dive in die OpenAI-Caching-Mechanismen: Best Practices für 90 % Rabatt – Meistern Sie technische Kniffe zur Optimierung durch Caching.
- 🚀 Praxisleitfaden: Aufbau eines Computer-Use-Automatisierungs-Agents auf Basis von GPT-5.4 mini – Entdecken Sie produktionsreife Anwendungen für die Desktop-Automatisierung.
📚 Referenzen
-
Offizielle Dokumentation zum OpenAI GPT-5.4 mini Modell: Modellspezifikationen, Preisgestaltung, Aufrufbeispiele
- Link:
developers.openai.com/api/docs/models/gpt-5.4-mini - Hinweis: Hier erhalten Sie die aktuellsten und verbindlichsten technischen Parameter.
- Link:
-
DataCamp GPT-5.4 mini Testbericht: Detaillierte Benchmark-Aufschlüsselung und generationsübergreifender Vergleich
- Link:
datacamp.com/blog/gpt-5-4-mini-nano - Hinweis: Unabhängige Bewertung durch Dritte, ideal für den horizontalen Vergleich ähnlicher Modelle.
- Link:
-
APIYI GPT-5.4 mini Integrationsdokumentation: Lösungen für den inländischen Aufruf, Gruppierungsinformationen und Aufladerabatte
- Link:
docs.apiyi.com - Hinweis: Ein praktischer Leitfaden für Entwickler in China zur Implementierung.
- Link:
-
OpenAI Preisübersicht: Vollständige Preisliste und Erläuterung der Caching-Mechanismen
- Link:
developers.openai.com/api/docs/pricing - Hinweis: Aktuelle Abrechnungsstandards für alle Modelle.
- Link:
Autor: APIYI Technik-Team
Technischer Austausch: Wir freuen uns auf Ihre Erfahrungen mit dem Upgrade auf GPT-5.4 mini in den Kommentaren. Weitere Informationen zur Modellintegration finden Sie im APIYI-Dokumentationszentrum unter docs.apiyi.com.