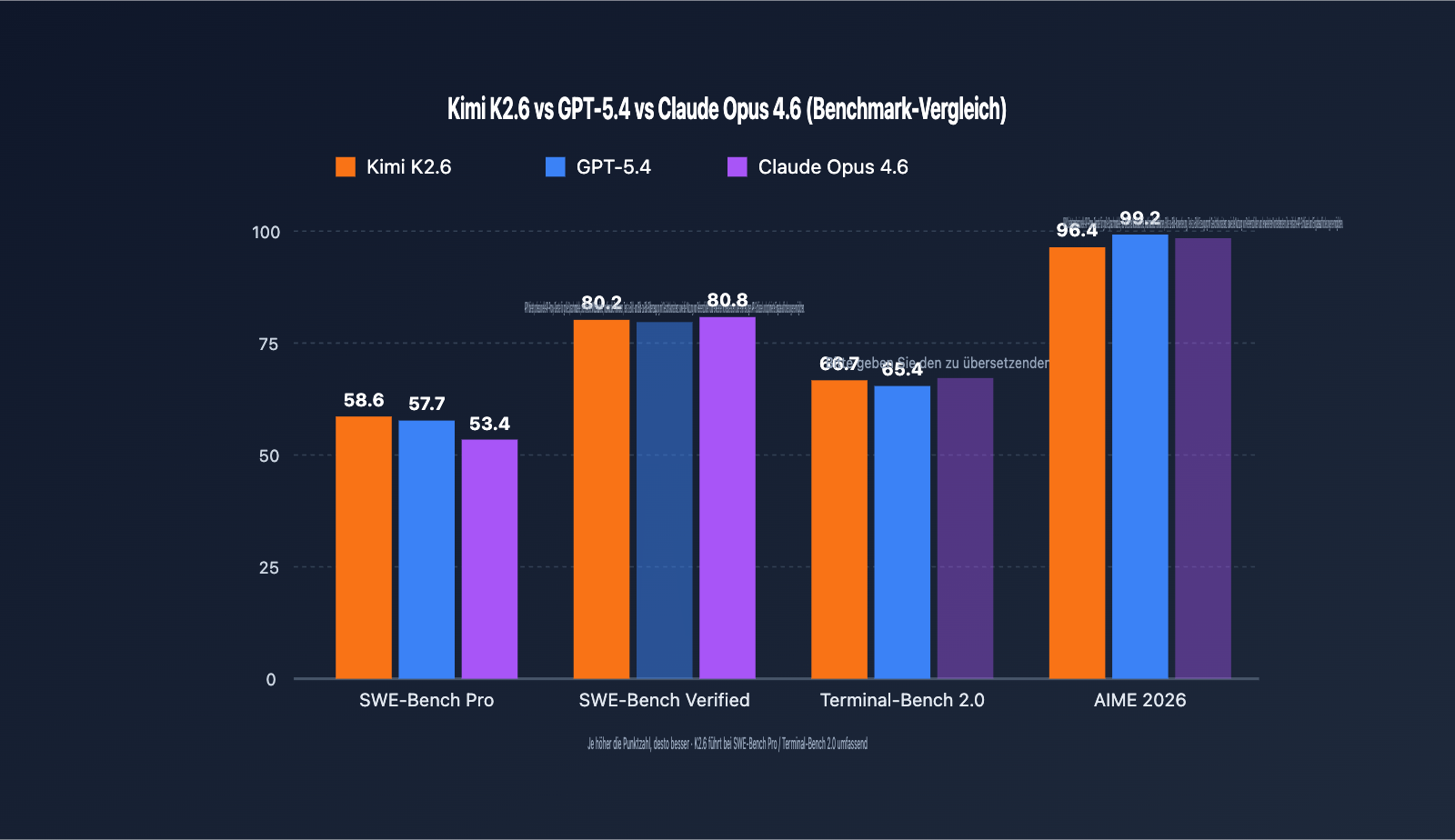
Chinesische Open-Source-Großmodelle erreichten 2026 einen Meilenstein: Das Flaggschiffmodell Kimi K2.6 von Moonshot AI wurde offiziell als Open Source veröffentlicht. Mit einem Score von 58,6 Punkten im SWE-Bench Pro Benchmark übertraf es GPT-5.4 (57,7) und Claude Opus 4.6 (53,4) und ist damit das derzeit leistungsfähigste aufrufbare Modell für die Lösung echter GitHub-Issues.
Dieser Artikel behandelt den Integrationsprozess der Kimi K2.6 API, analysiert deren 1T-MoE-Architektur, das 256K-Kontextfenster sowie die Fähigkeiten zur Funktionsaufrufe (Function Call) und zum Präfix-Schreiben (Prefix Completion). Anhand vollständiger Code-Beispiele helfen wir Ihnen, die API in nur 5 Minuten zu integrieren. Zudem sparen Sie dank des API-Proxy-Dienstes von APIYI (apiyi.com) über den offiziellen Huawei Cloud-Kanal: Mit $0,60 für Input und $2,40 für Output pro 1M Token zahlen Sie nur etwa 60 % der offiziellen Preise von ¥6,5 / ¥27.
Kernnutzen: Nach dem Lesen dieses Artikels beherrschen Sie die vollständige Implementierung der Kimi K2.6 API, die Orchestrierung von Function-Call-Tools, Optimierungstechniken für Präfix-Caching und wissen, wann der Einsatz von K2.6 die kosteneffizienteste Lösung darstellt.

Kernaspekte der Kimi K2.6 API
Kimi K2.6 ist das im April 2026 veröffentlichte Open-Source-Flaggschiffmodell von Moonshot AI. Es basiert auf der MoE-Architektur der Kimi K2-Serie und bietet signifikante Upgrades in den Bereichen Programmierung, Langkontext-Verarbeitung und Tool-Nutzung. Die folgende Tabelle fasst die wichtigsten Spezifikationen für Entwickler zusammen:
| Punkt | Detaillierte Spezifikation | Echter Mehrwert |
|---|---|---|
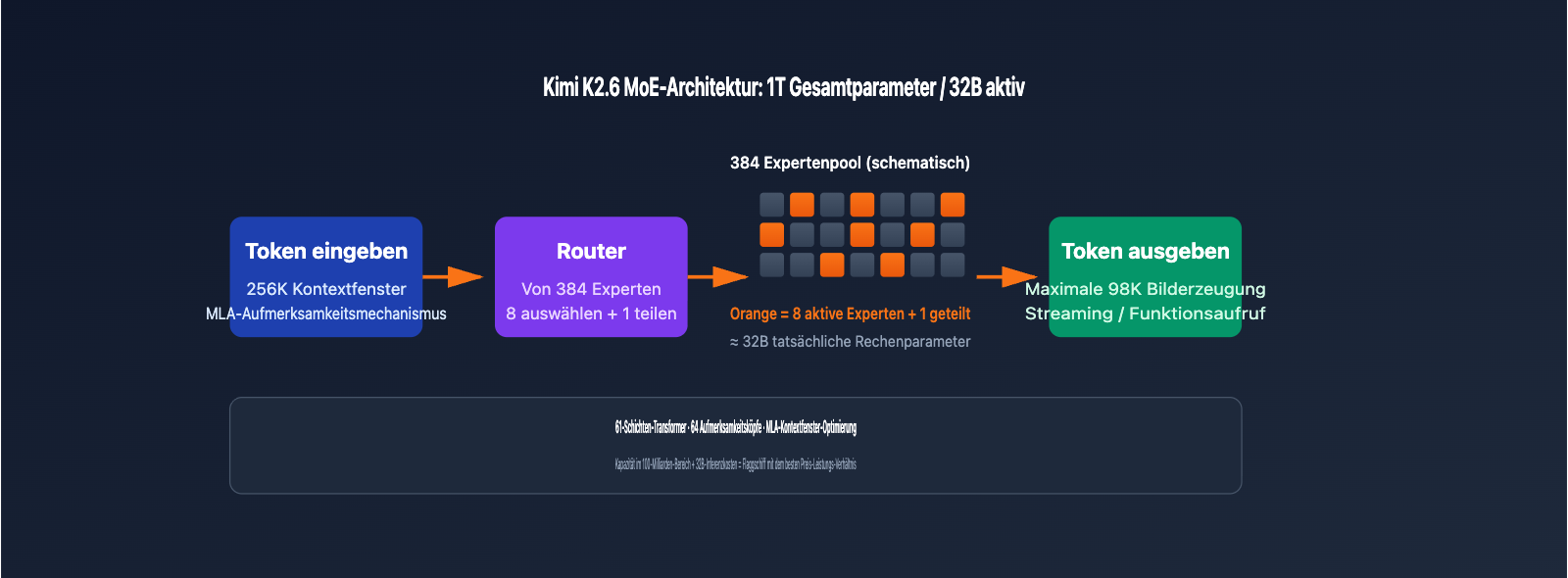
| MoE-Architektur | 1T Gesamtparameter / 32B aktiv / 384 Experten (8 gewählt + 1 geteilt) | Fähigkeiten auf 1T-Niveau bei 推理-Kosten eines 32B-Modells |
| Kontextfenster | 256K Token (exakt 262.144) | Verarbeitung umfangreicher Code-Repositories oder Rechtsdokumente in einem Durchgang |
| Maximale Ausgabe | Bis zu 98.304 Token pro Durchgang | Erfüllt Anforderungen für langwierige Code-Refactorings und Dokumentengenerierung |
| Multimodale Kapazität | Integrierter 400M MoonViT Vision-Encoder | Natives Verständnis von Bild- und Video-Inputs |
| Agent-Orchestrierung | Agent Swarm unterstützt 300 Sub-Agenten / 4.000 Koordinationsschritte | Bewältigung komplexer, mehrstufiger Entwicklungsabläufe |
| Open-Source-Lizenz | Modified MIT License | Kommerzielle Nutzung problemlos möglich, keine nennenswerten Einschränkungen |
Detaillierte Analyse der Kimi K2.6 API-Funktionen
Im Vergleich zur Vorgängergeneration K2.5 bietet K2.6 Verbesserungen in drei Dimensionen: Erstens der Durchbruch auf 58,6 Punkte im SWE-Bench Pro, womit es erstmals GPT-5.4 und Claude Opus 4.6 bei Aufgaben zur Lösung echter Open-Source-Issues übertrifft; zweitens die Erhöhung der Sub-Agenten in Agent Swarm von 100 auf 300 sowie der Koordinationsschritte von 1500 auf 4000, was komplexere Entwicklungsprozesse ermöglicht; drittens wurde das 256K-Kontextfenster für die gesamte Serie freigeschaltet, wobei durch Multi-head Latent Attention (MLA) der Bedarf an Grafikspeicher und die Latenz bei der Langkontext-Inferenz signifikant reduziert wurden.
🎯 Technischer Rat: Wir empfehlen, Kimi K2.6 direkt über die Plattform APIYI (apiyi.com) anzubinden. Die Plattform greift über den offiziellen Huawei Cloud-Kanal auf die Modelle zu, ist vollständig OpenAI-SDK-kompatibel und ermöglicht den Modellwechsel ohne Änderungen an Ihrem bestehenden Code.
Detaillierte technische Architektur der Kimi K2.6 API
Das Verständnis der zugrunde liegenden Architektur von Kimi K2.6 hilft Ihnen dabei, fundierte Entscheidungen für verschiedene Geschäftsszenarien zu treffen. Das Architekturdesign schafft ein ausgewogenes Verhältnis zwischen einer "Parameterkapazität im Hunderte-Milliarden-Bereich" und "Inferenzkosten im zweistelligen Milliardenbereich".
MoE-Mechanismus zur spärlichen Aktivierung
Kimi K2.6 nutzt eine Mixture-of-Experts (MoE)-Architektur mit 1 Billion Parametern, die 384 Expertennetzwerke umfasst. Bei der Inferenz eines Tokens werden jeweils nur 8 dieser Experten (plus 1 gemeinsam genutzter Experte) aktiviert, was bedeutet, dass 32 Mrd. Parameter an der Berechnung beteiligt sind. Dieses Design verleiht dem Modell die Wissensbreite eines Modells mit hunderten Milliarden Parametern, während gleichzeitig die Inferenzgeschwindigkeit auf dem Niveau von 32 Mrd. Parametern beibehalten wird. Dies macht es zu einem der Flaggschiff-Modelle mit dem aktuell besten Preis-Leistungs-Verhältnis für Modellaufrufe.
Optimierung für lange Kontexte
| Technische Komponente | Funktion | K2.6 Konfiguration |
|---|---|---|
| Multi-head Latent Attention (MLA) | Reduziert das Volumen des KV-Cache bei der Inferenz langer Kontexte | 64 Attention-Heads |
| Netzwerkschichten | Bestimmt die Inferenz-Tiefe des Modells | 61 Transformer-Schichten |
| Kontextfenster | Maximale Anzahl an Tokens pro Eingabe | 262.144 Tokens (256K) |
| Positionskodierung | Schlüsseltechnologie zur Unterstützung extrem langer Sequenzen | Speziell für lange Kontexte trainiert |
| Präfix-Caching | Wiederholte Eingabeaufforderungen nutzen den Cache, was Kosten senkt | Eingabekosten nach Treffer um ca. 75 % reduziert |
💡 Architektur-Einblick: Bei Konversationen mit mehreren Runden oder festen system prompts kann das Präfix-Caching die Eingabekosten erheblich senken. Es wird empfohlen, den system prompt in Produktionsumgebungen stabil zu halten, um die Cache-Trefferquote zu maximieren.
Benchmark-Vergleich der Kimi K2.6 API-Leistung
Die Beurteilung, ob sich die Einbindung eines Modells lohnt, basiert am besten auf Benchmarks. Im Folgenden vergleichen wir die Leistung von Kimi K2.6, GPT-5.4 und Claude Opus 4.6 anhand von fünf maßgeblichen Benchmarks.
Fähigkeiten in Programmierung und Softwareentwicklung
| Benchmark | Kimi K2.6 | GPT-5.4 | Claude Opus 4.6 | Bestes Modell |
|---|---|---|---|---|
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | Kimi K2.6 |
| SWE-Bench Verified | 80.2 | – | 80.8 | Claude Opus 4.6 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | – | Kimi K2.6 |
| HLE (mit Tools) | 54.0 | – | 53.0 | Kimi K2.6 |
| AIME 2026 | 96.4 | 99.2 | – | GPT-5.4 |
| GPQA-Diamond | 90.5 | – | – | – |
Wichtige Erkenntnisse:
- SWE-Bench Pro misst die End-to-End-Lösungsfähigkeit bei realen GitHub Issues. K2.6 erzielte 58,6 Punkte und ist damit das erste Open-Weights-Modell, das bei diesem Benchmark die proprietären Flaggschiff-Modelle übertrifft. Dies bedeutet, dass bei Aufgaben wie der Codewartung und Fehlerbehebung K2.6 bevorzugt werden sollte.
- SWE-Bench Verified ist eine vereinfachte Version, bei der Claude Opus 4.6 leicht die Nase vorn hat (80,8 vs. 80,2). Der Abstand ist gering, zeigt aber, dass Claude bei standardisierten Code-Aufgaben weiterhin Vorteile bietet.
- Terminal-Bench 2.0 testet die Fähigkeit zur Orchestrierung von Terminalbefehlen. K2.6 führt mit 66,7 Punkten und eignet sich daher gut für DevOps- und automatisierte Betriebsszenarien.
- AIME / HMMT und andere reine mathematische Schlussfolgerungen sind weiterhin die Stärke von GPT-5.4. Für rein mathematische Szenarien empfehlen wir daher, GPT-5.4 als Option beizubehalten.
🎯 Szenario-Empfehlung: Wir empfehlen A/B-Tests über verschiedene Modelle hinweg für unterschiedliche Aufgaben – bei der Codewartung hat K2.6 Vorrang, bei mathematischen Schlussfolgerungen GPT-5.4 und für langes kreatives Schreiben können Sie die Claude-Option beibehalten.
Kimi K2.6 API – Schnelleinstieg
Im Folgenden zeigen wir Ihnen anhand von vollständigem Code, wie Sie das Kimi K2.6-Modell aufrufen. Die Kimi-API-Serie ist vollständig kompatibel mit dem OpenAI-SDK-Protokoll. Wenn Sie bereits Code für OpenAI-Aufrufe haben, müssen Sie lediglich base_url und model anpassen.
Minimalistisches Beispiel (Python)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Du bist ein erfahrener Python-Entwickler."},
{"role": "user", "content": "Implementiere einen parallelen Request-Pool mit asyncio, der die maximale Parallelität auf 10 begrenzt."}
],
temperature=0.3,
max_tokens=2048
)
print(response.choices[0].message.content)
Vollständiges Beispiel für asynchronen Streaming-Aufruf (inkl. Fehlerbehandlung)
import asyncio
from openai import AsyncOpenAI
from openai import APIError, RateLimitError
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
max_retries=3,
timeout=120.0
)
async def call_kimi_k26_stream(prompt: str, system: str = "") -> str:
"""Kimi K2.6 per Streaming aufrufen und Tokens in Echtzeit ausgeben"""
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": prompt})
full_response = ""
try:
stream = await client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
stream=True,
temperature=0.3,
max_tokens=8192
)
async for chunk in stream:
if chunk.choices[0].delta.content:
token = chunk.choices[0].delta.content
print(token, end="", flush=True)
full_response += token
except RateLimitError:
print("\n[Rate-Limit erreicht, bitte Wiederholungsversuche konfigurieren oder Tarif upgraden]")
raise
except APIError as e:
print(f"\n[API-Fehler: {e}]")
raise
return full_response
async def main():
result = await call_kimi_k26_stream(
prompt="Erkläre, wie die MoE-Architektur die Inferenzkosten senkt",
system="Du bist ein Experte für KI-Architektur, antworte prägnant und professionell"
)
print(f"\n\n[Gesamtanzahl der Tokens: {len(result)}]")
if __name__ == "__main__":
asyncio.run(main())
🚀 Schnellstart: Nachdem Sie Ihren API-Schlüssel über die APIYI-Plattform (apiyi.com) erhalten haben, setzen Sie einfach die
base_urlaufhttps://api.apiyi.com/v1. Alle SDKs des OpenAI-Ökosystems (Python/Node.js/Go) können direkt verwendet werden – die Integration dauert nur 5 Minuten.
Aufruf mit Node.js / TypeScript
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "kimi-k2.6",
messages: [
{ role: "user", content: "Schreibe eine Debounce-Funktion in TypeScript mit Generics-Unterstützung" }
],
temperature: 0.2,
});
console.log(completion.choices[0].message.content);
Direkter cURL-Aufruf
curl https://api.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_APIYI_KEY" \
-d '{
"model": "kimi-k2.6",
"messages": [
{"role": "user", "content": "Hallo, Kimi K2.6"}
],
"max_tokens": 1024
}'
Praxisbeispiel: Function Call (Werkzeugaufruf)
Die Function-Call-Fähigkeit von K2.6 ist ein deutliches Upgrade gegenüber der K2-Serie und erzielt hervorragende Ergebnisse im Berkeley Function-Calling Leaderboard. Das folgende Beispiel zeigt den Workflow zur Werkzeug-Orchestrierung anhand einer Wetterabfrage.
Werkzeugdefinition und -aufruf
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Aktuelles Wetter für eine angegebene Stadt abfragen",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "Name der Stadt"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
}
]
def get_weather(city: str, unit: str = "celsius") -> dict:
"""Simulierte Wetter-API"""
return {"city": city, "temperature": 22, "unit": unit, "condition": "sonnig"}
messages = [{"role": "user", "content": "Bitte prüfe das Wetter in Peking und Shanghai"}]
response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
tools=tools,
tool_choice="auto"
)
assistant_msg = response.choices[0].message
messages.append(assistant_msg)
if assistant_msg.tool_calls:
for tool_call in assistant_msg.tool_calls:
args = json.loads(tool_call.function.arguments)
result = get_weather(**args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result, ensure_ascii=False)
})
final_response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages
)
print(final_response.choices[0].message.content)
Präfix-Fortsetzung (Partial Mode)
K2.6 unterstützt die OpenAI-Stil "Präfix-Fortsetzung", bei der der Anfang einer Assistant-Nachricht vorgegeben wird und das Modell ab dieser Position weiter generiert. Dies wird häufig verwendet, um JSON-Ausgaben oder spezifische Formatvorgaben zu erzwingen:
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "user", "content": "Gib die BIP-Daten von Peking (2023) im JSON-Format zurück"},
{"role": "assistant", "content": '{"city": "Peking", "year": 2023, "gdp":'}
],
max_tokens=200
)
print(response.choices[0].message.content)
💰 Kostenoptimierung: Bei langen System-Prompts (z. B. RAG, Agenten) sinken die Eingabekosten nach einem Treffer im Präfix-Cache um ca. 25 %. Dies eignet sich ideal für Multi-Turn-Dialoge und Anwendungen mit häufigen festen Vorlagen. Es wird empfohlen, die kontobasierte Cache-Überwachung auf apiyi.com zu aktivieren, um die Trefferquote in Echtzeit zu verfolgen.
Kimi K2.6 API – Fortgeschrittene Fähigkeiten
Neben Function Calls bietet K2.6 drei weitere fortgeschrittene Funktionen: Agent Swarm für Multi-Agenten-Orchestrierung, ein 256K-Kontextfenster und native multimodale Fähigkeiten. Diese bilden die Kernkompetenz für Szenarien wie Programmierung, F&E-Automatisierung und Dokumentenanalyse.
Agent Swarm Multi-Agenten-Orchestrierung
Eine der differenzierendsten Fähigkeiten von K2.6 ist Agent Swarm – eine einzelne Aufgabe kann bis zu 300 parallele Unteragenten koordinieren und 4.000 Koordinationsschritte ausführen. Dies macht K2.6 besonders stark bei der Umstrukturierung großer Codebasen, der Analyse referenzübergreifender Dokumente und komplexen F&E-Pipelines.
Scheduling-Modi für Unteragenten
K2.6 Agent Swarm unterstützt drei typische Orchestrierungsmuster:
| Orchestrierungsmuster | Anwendungsfall | Anzahl Unteragenten | Koordinationsschritte |
|---|---|---|---|
| Single-Layer Parallel | Batch-Zusammenfassung, Code-Review | 10-50 | < 200 |
| Hierarchisches Scheduling | Modulübergreifende Code-Refactorings | 50-150 | 500-1500 |
| Tiefe Kollaboration | Repository-übergreifende Agenten-Pipelines | 150-300 | 1500-4000 |
Beispiel für einfache Agenten-Orchestrierung
Hier zeigen wir, wie K2.6 fünf parallele Unteragenten koordiniert, um eine Code-Review durchzuführen:
from openai import OpenAI
import asyncio
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
async def review_module(module_name: str, code: str) -> dict:
"""Unteragent für die Überprüfung eines einzelnen Moduls"""
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Du bist ein Experte für Code-Reviews, achte besonders auf Sicherheit und Performance."},
{"role": "user", "content": f"Überprüfe Modul {module_name}:\n{code}"}
],
temperature=0.2
)
return {
"module": module_name,
"review": response.choices[0].message.content
}
async def parallel_review(modules: dict) -> list:
"""Parallele Orchestrierung mehrerer Unteragenten"""
tasks = [review_module(name, code) for name, code in modules.items()]
return await asyncio.gather(*tasks)
# Hauptprozess: Koordination von 5 Unteragenten zur Überprüfung von 5 Modulen
modules = {
"auth.py": "...",
"database.py": "...",
"api_routes.py": "...",
"cache.py": "...",
"logger.py": "..."
}
results = asyncio.run(parallel_review(modules))
for r in results:
print(f"[{r['module']}] {r['review'][:100]}...")
Best Practices für Agent Swarm
- Aufgabengranularität: Ein einzelner Unteragent sollte 5K-20K Tokens verarbeiten; zu große Aufgaben führen zu hohem Koordinationsaufwand.
- Fehlerisolierung: Jeder Unteragent sollte in einem try/except-Block laufen, um kaskadierende Ausfälle zu vermeiden.
- Ergebnisaggregation: Ein "Hauptagent" sollte die Ergebnisse der Unteragenten sammeln und kreuzvalidieren.
- Timeout-Management: Einzelne Unteragenten sollten auf 60-120 Sekunden begrenzt sein, der Hauptagent auf 10-30 Minuten.
- Ratenkontrolle: Verwenden Sie Semaphoren, um die maximale Parallelität zu begrenzen und API-Rate-Limits zu vermeiden.
256K Kontextfenster in der Praxis
Das 256K-Kontextfenster (262.144 Tokens) ist ein Kernverkaufsargument von K2.6. Dies entspricht etwa 400.000 bis 500.000 chinesischen Schriftzeichen und kann große Code-Repositories oder ganze Fachbücher auf einmal aufnehmen.
Typische Nutzung des langen Kontextfensters
import os
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def load_repo_files(repo_path: str, extensions=(".py", ".ts", ".md")) -> str:
"""Lädt alle Dateien mit den angegebenen Endungen aus dem Repository"""
contents = []
for root, _, files in os.walk(repo_path):
for f in files:
if f.endswith(extensions):
full_path = os.path.join(root, f)
with open(full_path, "r", encoding="utf-8") as fp:
contents.append(f"## {full_path}\n```\n{fp.read()}\n```")
return "\n\n".join(contents)
repo_text = load_repo_files("./my_project")
print(f"Geschätzte Repository-Tokens: {len(repo_text) // 2}")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Du bist ein erfahrener Architekt, spezialisiert auf die Analyse großer Codebasen."},
{"role": "user", "content": f"Analysiere die Architektur des folgenden Projekts und gib Refactoring-Vorschläge:\n{repo_text}"}
],
temperature=0.3,
max_tokens=8192
)
print(response.choices[0].message.content)
Abwägung von Kosten und Leistung bei langem Kontext
| Eingabegröße | Geschätzte Kosten/Aufruf | Latenz (erstes Token) | Anwendungsfall |
|---|---|---|---|
| 8K | $0.005 | 1-2 Sek. | Einzelfail-Analyse |
| 32K | $0.019 | 3-5 Sek. | Modul-Review |
| 100K | $0.06 | 8-15 Sek. | Analyse mittlerer Repos |
| 200K | $0.12 | 18-30 Sek. | Große Repos / Ganzes Buch |
| 256K (Voll) | $0.154 | 25-40 Sek. | Extrem lange Dokumente |
🎯 Optimierungstipps für lange Dokumente: Teilen Sie den System-Prompt in "feste Anweisungen + dynamische Dokumente" auf. Wenn der feste Teil durch das Präfix-Caching getroffen wird, werden nachfolgende Aufrufe nur für den geänderten Teil berechnet. In RAG-Szenarien können die Gesamtkosten für 100 Aufrufe so um 40 % bis 60 % gesenkt werden.
Multimodale visuelle Aufrufe
K2.6 verfügt über einen integrierten MoonViT-Vision-Encoder mit 400 Millionen Parametern und unterstützt nativ Bild- und Videoeingaben. Die multimodale Schnittstelle ist ebenfalls mit dem OpenAI-Protokoll kompatibel:
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
image_b64 = encode_image("./architecture_diagram.png")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Analysiere dieses Architekturdiagramm und identifiziere potenzielle Single Points of Failure"},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_b64}"}
}
]
}
],
max_tokens=2048
)
print(response.choices[0].message.content)
Multimodale Anwendungsfälle:
- Analyse von Architektur- und Flussdiagrammen mit Änderungsvorschlägen
- Überprüfung von UI-Design-Entwürfen und Codegenerierung
- Verständnis von Screenshots technischer Dokumentationen
- Datenextraktion aus Diagrammen und Tabellen
- Visuelle Identifizierung in der industriellen Qualitätskontrolle
Kimi K2.6 API-Migration und Leistungsoptimierung
Falls Ihr Projekt derzeit OpenAI, K2.5 oder Modelle anderer Anbieter verwendet, erfordert die Migration zu K2.6 in der Regel nur 3-5 Codezeilen. Gleichzeitig können durchdachte Strategien für Nebenläufigkeit (Concurrency) und Caching die Kostenvorteile von K2.6 weiter maximieren.
Migration von OpenAI GPT-Serien
# Ursprünglicher Code (OpenAI)
client = OpenAI(api_key="OPENAI_KEY")
response = client.chat.completions.create(
model="gpt-5.4",
messages=[...]
)
# Migration zu K2.6 (nur base_url und model anpassen)
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[...]
)
Migration von Kimi K2 / K2.5
Die Modell-IDs der K2-Serie unterscheiden sich, aber das API-Protokoll ist vollständig identisch:
| Alte Modell-ID | Neue Modell-ID | Geplantes Ende des Supports |
|---|---|---|
kimi-k2 |
kimi-k2.6 |
25.05.2026 |
kimi-k2.5 |
kimi-k2.6 |
Support läuft weiter, Upgrade empfohlen |
moonshot-v1-128k |
kimi-k2.6 |
Innerhalb von 2026 |
Kompatibilitätsprüfung vor der Migration
Vor der Migration sollten folgende Punkte geprüft werden:
- max_tokens Limit: K2.6 ermöglicht eine Ausgabe von bis zu 98K. Wenn Ihr Code hartkodierte 8K-Limits setzt, können diese gelockert werden.
- temperature Bereich: Für K2.6 werden 0.1-0.7 empfohlen; zu hohe Werte beeinträchtigen die Codequalität.
- stop sequences: K2.6 unterstützt benutzerdefinierte Stopp-Sequenzen, genau wie OpenAI.
- tool_choice Verhalten: Der
auto-Modus von K2.6 neigt stärker zum Aufruf von Werkzeugen; falls konservativeres Verhalten gewünscht ist, nutzen Sienoneoder eine explizite Angabe. - Streaming-Protokoll: Das SSE-Format ist vollständig kompatibel, Frontend-Code muss nicht angepasst werden.
Best Practices zur Leistungsoptimierung
Optimierung der Aufrufgeschwindigkeit
| Optimierung | Implementierung | Erwartete Steigerung |
|---|---|---|
| Nebenläufige Anfragen | Nutzung von AsyncOpenAI + asyncio.gather | 3-10x Durchsatz |
| Streaming-Ausgabe | Aktivierung von stream=True | 70% geringere Latenz beim ersten Token |
| Präfix-Caching | Fester System-Prompt | 75% geringere Eingabekosten |
| Optimale max_tokens | Limit basierend auf Aufgabe setzen | 30% geringere Einzellatenz |
| Temperaturkontrolle | temp=0.2 für Programmieraufgaben | Stabilere Ausgabe |
Empfehlungen zur Fehlerbehandlung
from openai import OpenAI, APIError, RateLimitError, APITimeoutError
import time
def call_with_retry(prompt: str, max_retries: int = 3):
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
timeout=120.0
)
for attempt in range(max_retries):
try:
return client.chat.completions.create(
model="kimi-k2.6",
messages=[{"role": "user", "content": prompt}]
)
except RateLimitError:
wait = 2 ** attempt
print(f"Rate-Limit erreicht, warte {wait}s vor Wiederholung")
time.sleep(wait)
except APITimeoutError:
print(f"Zeitüberschreitung, {attempt+1}. Wiederholungsversuch")
except APIError as e:
print(f"API-Fehler: {e}")
if attempt == max_retries - 1:
raise
raise Exception("Maximale Anzahl an Wiederholungsversuchen erreicht")
Preisvorteile und Modellauswahl für Kimi K2.6 API
Der Preis ist ein entscheidender Faktor bei der Modellwahl. Die folgende Tabelle vergleicht die Listenpreise für Kimi K2.6 über verschiedene Kanäle (Einheit: pro 1M Token):
| Kanal | Eingabepreis | Ausgabepreis | Hinweis |
|---|---|---|---|
| Kimi Offizielle Plattform | ¥6.5 (~$0.95) | ¥27 (~$4.00) | Offizielle Inlandsabrechnung |
| APIYI (Huawei Cloud Proxy) | $0.60 | $2.40 | Ca. 40% günstiger als offiziell |
| OpenRouter (Parasail) | $0.60 | $2.40+ | Inoffizieller Kanal |
| GPT-5.4 (Referenz) | $2.50 | $15.00 | 4-6x teurer als K2.6 |
| Claude Opus 4.6 (Referenz) | $15.00 | $75.00 | Über 25x teurer als K2.6 |
Tatsächliche Kostenschätzung
Am Beispiel eines täglichen Code-Assistenten (Annahme pro Sitzung: 5K Token Eingabe / 2K Token Ausgabe, 100.000 Aufrufe monatlich):
| Modell | Monatliche Eingabekosten | Monatliche Ausgabekosten | Monatliche Gesamtkosten |
|---|---|---|---|
| Kimi K2.6 (APIYI) | $300 | $480 | $780 |
| GPT-5.4 | $1.250 | $3.000 | $4.250 |
| Claude Opus 4.6 | $7.500 | $15.000 | $22.500 |
Fazit: In den Bereichen Programmierung, Agenten und lange Kontexte liegt die Leistung von K2.6 auf Augenhöhe mit GPT-5.4/Claude Opus 4.6, während die Kosten nur ein Fünftel bis ein Dreißigstel betragen. Dies ist besonders für budgetbewusste Teams und Einzelentwickler vorteilhaft.
🎯 Auswahlempfehlung: Die Wahl des Modells hängt stark von Ihrem spezifischen Anwendungsszenario und den Qualitätsanforderungen ab. Wir empfehlen, über die Plattform APIYI (apiyi.com) Praxistests durchzuführen, um die beste Entscheidung zu treffen. Die Plattform unterstützt eine einheitliche Schnittstelle für verschiedene Mainstream-Modelle wie Kimi K2.6, GPT-5.4 und Claude Opus 4.6, was schnelle Vergleiche und Wechsel ermöglicht.
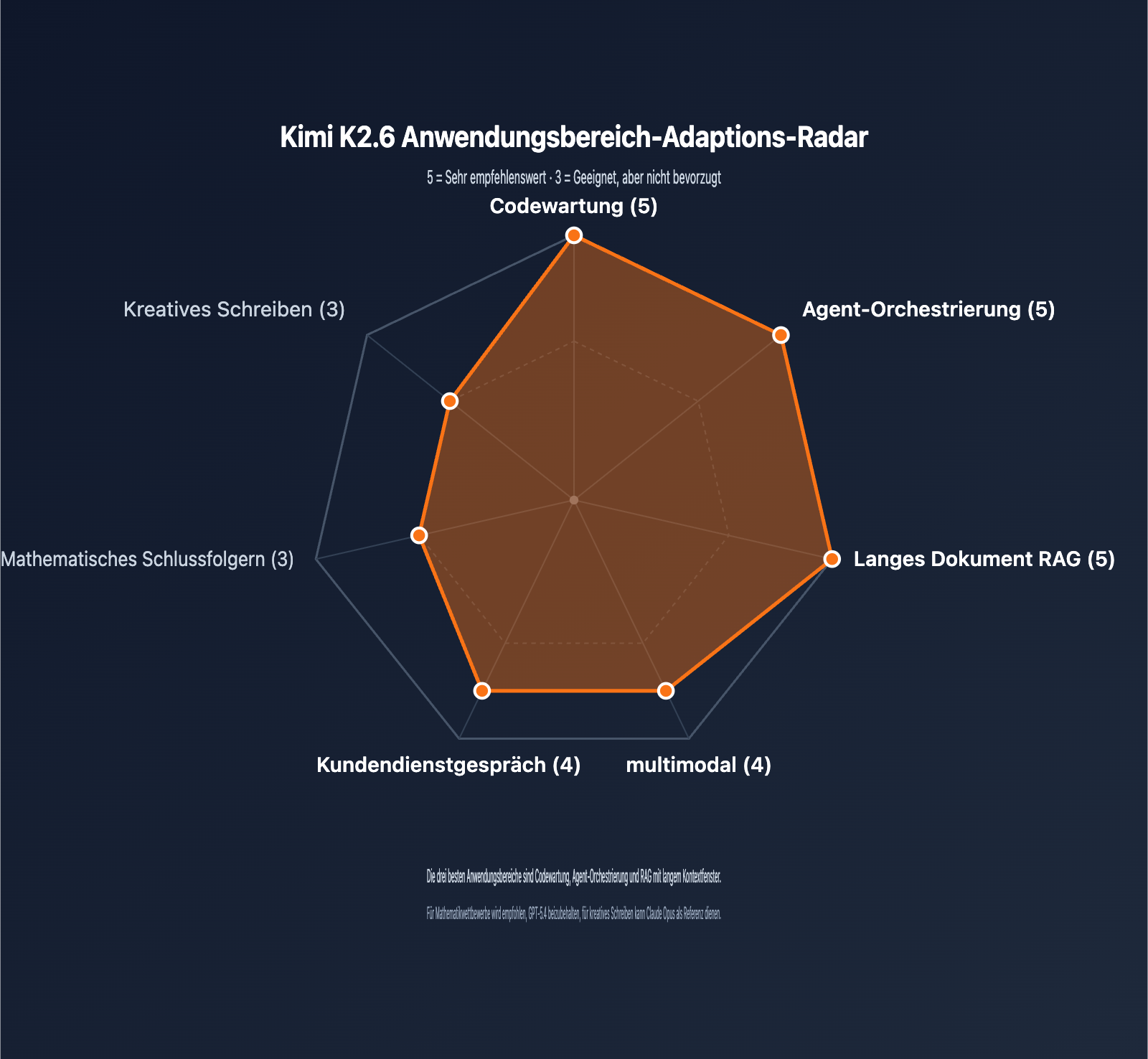
Empfohlene Anwendungsgebiete
Die Eignung von K2.6 variiert je nach Geschäftsszenario. Die folgende Tabelle gibt klare Empfehlungen:
| Anwendungsszenario | Empfehlung | Begründung |
|---|---|---|
| Codewartung & Refactoring | ⭐⭐⭐⭐⭐ | SWE-Bench Pro Platz 1, 256K ermöglicht Laden großer Repos |
| Agent-Orchestrierung | ⭐⭐⭐⭐⭐ | 300 Sub-Agenten / 4000 Schritte, unterstützt komplexe Workflows |
| Analyse langer Dokumente | ⭐⭐⭐⭐⭐ | 256K Kontext + MLA-Optimierung, kontrollierbare Kosten |
| Multimodales Verständnis | ⭐⭐⭐⭐ | Natives MoonViT, sofort einsatzbereit für Bild & Video |
| Kundenservice & Dialog | ⭐⭐⭐⭐ | Exzellentes Function Calling, Kostensenkung durch Caching |
| Mathematisches Schlussfolgern | ⭐⭐⭐ | AIME 96.4 Punkte solide, aber GPT-5.4 stärker |
| Kreatives Schreiben | ⭐⭐⭐ | Natürlicher chinesischer Ausdruck, aber stilistisch etwas schwächer als Claude |
Häufig gestellte Fragen (FAQ)
Q1: Was sind die Hauptunterschiede zwischen der Kimi K2.6 API und K2.5 / K2?
K2.6 bietet signifikante Verbesserungen in drei Bereichen: 1) SWE-Bench Pro stieg von 53 Punkten (K2.5) auf 58,6 und übertrifft damit erstmals GPT-5.4 und Claude Opus 4.6; 2) die Anzahl der Agent-Swarm-Sub-Agenten wurde von 100 auf 300 und die Koordinationsschritte von 1500 auf 4000 erhöht; 3) das 256K-Kontextfenster ist nun für die gesamte Serie verfügbar (bei frühen K2-Versionen unterstützten einige Varianten nur 128K). Laut der offiziellen Ankündigung von Kimi werden frühe K2-Versionen am 25. Mai 2026 eingestellt. Neue Projekte sollten direkt auf K2.6 setzen, die Modell-ID lautet kimi-k2.6 und ist vollständig mit dem OpenAI SDK kompatibel.
Q2: Ist die Kimi K2.6 API vollständig mit dem OpenAI SDK kompatibel?
Ja. Bei einem Modellaufruf über Kanäle wie APIYI ist das API-Protokoll vollständig mit der Chat-Completions-Schnittstelle von OpenAI kompatibel. Dies umfasst Parameter wie Streaming, Tools (Function Call), tool_choice, temperature, top_p und max_tokens. In gängigen SDKs für Python, Node.js oder Go müssen lediglich die Parameter base_url und model angepasst werden. Beachten Sie, dass die maximale Ausgabe von K2.6 bei 98.304 Token liegt, was weit über den 16K von GPT-5 liegt.
Q3: Wie sieht es bei der 256K-Kontextnutzung von K2.6 mit Latenz und Kosten aus?
K2.6 optimiert das Volumen des KV-Caches für lange Kontexte durch Multi-head Latent Attention (MLA) erheblich. Bei Tests in Szenarien mit 100K Eingabe liegt die Latenz bis zum ersten Token bei etwa 8–15 Sekunden (abhängig von der Serverlast), gefolgt vom Streaming der weiteren Token. Kostentechnisch entspricht eine 256K-Eingabe bei einer Kalkulation von $0,60/1M etwa $0,15 pro Durchlauf. Bei Unterhaltungen mit identischem System-Prompt sinken die Eingabekosten nach dem Caching des Präfix um ca. 25 %. Vor dem Produktivgang empfiehlt sich ein End-to-End-Test mit Ihren typischen Eingabeaufforderungen, wobei die Token-Verbrauchslogs zur Kostenoptimierung überwacht werden sollten.
Q4: Wie unterscheidet sich der Function Call von K2.6 von den Tools von GPT-5 / Claude?
Die Schnittstellenebene ist identisch (OpenAI-konformes Tools-Protokoll), aber die internen Fähigkeiten setzen andere Schwerpunkte: 1) K2.6 unterstützt 300 Sub-Agenten gleichzeitig und hat damit bei der parallelen Orchestrierung mehrerer Werkzeuge einen nativen Vorteil; 2) K2.6 gehört im Berkeley Function-Calling Leaderboard zur ersten Riege und erreicht fast GPT-5-Niveau; 3) K2.6 unterstützt Präfix-Fortschreibung (Partial Mode), wodurch das JSON-Ausgabeformat erzwungen werden kann, was die Fehlerrate bei Tool-Aufrufen senkt. Für komplexe Agenten-Workflows bietet K2.6 das beste Preis-Leistungs-Verhältnis.
Q5: Ist der Aufruf von K2.6 über APIYI offiziell autorisiert? Ist die Datensicherheit gewährleistet?
APIYI bindet die offiziellen Kimi-Modelle über den offiziellen Transferkanal der Huawei Cloud an. Es handelt sich um einen regelkonformen, autorisierten Kanal; die Modellgewichtungen und Inferenzergebnisse entsprechen exakt der offiziellen Version. Die Datenübertragung erfolgt via HTTPS-Verschlüsselung, und die Plattform speichert keine Anfrageinhalte. Für Unternehmenskunden bieten wir Funktionen wie unabhängige Sub-Accounts, eine abgestufte Verwaltung von API-Schlüsseln und Ausgabenlimits. Sollten Sie strikte Anforderungen an die Daten-Compliance haben, finden Sie detaillierte Richtlinien auf der Compliance-Seite von apiyi.com.
Q6: Für welche Projekttypen eignet sich K2.6? Wann sollte man GPT-5.4 oder Claude wählen?
Szenarien, in denen K2.6 zu bevorzugen ist: Coding-Assistenten, SWE-Aufgaben, RAG mit langem Kontext, Orchestrierung von Agenten-Workflows sowie kostenkritische kleine bis mittlere Projekte. Szenarien für GPT-5.4: Hochkomplexe mathematische Wettbewerbe (AIME/HMMT) oder wissenschaftliche Aufgaben, die höchste Schlussfolgerungstiefe erfordern. Szenarien für Claude Opus 4.6: Kreatives Schreiben langer Texte oder die Erstellung von Verträgen/juristischen Dokumenten mit strikten Formatvorgaben. Es empfiehlt sich, ein Architekturdesign beizubehalten, das einen Modellwechsel ermöglicht, um nach Vergleichstests das für den konkreten Anwendungsfall beste Modell zu wählen.
Zusammenfassung
Kimi K2.6 ist ein wichtiger Meilenstein für multimodale Großmodelle im Jahr 2026. Es beweist, dass die 100-Milliarden-Parameter-MoE-Architektur in den Bereichen Coding, Agenten-Steuerung und langer Kontext direkt mit den führenden geschlossenen Modellen konkurrieren kann. Das Ergebnis von 58,6 Punkten im SWE-Bench Pro sowie die technologische Kapazität von 256K-Kontext bei 300 Sub-Agenten machen es zur bevorzugten Wahl für Coding-Assistenten und Automatisierungsprojekte in der Forschung und Entwicklung.
Die wichtigsten Punkte im Überblick:
- Architekturvorteil: 1T MoE / 32B aktiv, Leistung im 100-Milliarden-Bereich bei 32B-Inferenzkosten.
- Benchmark-Spitzenreiter: Führend in SWE-Bench Pro, Terminal-Bench 2.0 und HLE.
- Preisvorteil: Über den Kanal von APIYI bei $0,60 / $2,40, ca. 40 % günstiger als beim offiziellen Anbieter.
- Ökosystem: Vollständige Kompatibilität zum OpenAI SDK, Migration in 5 Minuten möglich.
- Engineering: 256K-Kontext + 300 Sub-Agenten + Präfix-Caching.
Für Teams, die 2026 KI-Produkte entwickeln möchten, ist die Kimi K2.6 API eine äußerst wettbewerbsfähige Wahl in Bezug auf Leistung, Kosten und Ökosystem. Wir empfehlen, die Plattform APIYI apiyi.com zu nutzen, um die Ergebnisse schnell zu validieren und verschiedene Modelle direkt für Ihre spezifischen Geschäftsszenarien zu vergleichen, um so eine optimale Entscheidung zu treffen.
Autor: APIYI Technical Team | Wir beobachten kontinuierlich die Dynamik bei großen Sprachmodellen. Für technischen Austausch und Beratung zu unseren Lösungen besuchen Sie bitte APIYI unter apiyi.com.