Anmerkung des Autors: Basierend auf durchgesickerten Informationen aus dem Gray-Box-Test im LM Arena, analysieren wir hier die 8 entscheidenden Upgrades von gpt-image-2 gegenüber gpt-image-1.5, einschließlich Text-Rendering, Realismus, 4K-Ausgabe, Geschwindigkeit, Mehrsprachigkeit und UI-Screenshot-Generierung.
Anfang April 2026 tauchten drei anonyme Bildmodelle mit den Namen maskingtape-alpha、gaffertape-alpha、packingtape-alpha still und leise auf der Bewertungsplattform LM Arena auf. Frühe Tester berichteten von einer Genauigkeit beim Text-Rendering von nahezu 99 %, einer Generierungszeit von nur etwa 3 Sekunden und nativer 4K-Unterstützung – die Community ist sich einig, dass es sich hierbei um das kommende gpt-image-2 von OpenAI handelt.
Dies ist kein Vaporware-Produkt: Die öffentlichen Testaufzeichnungen im LM Arena, Vergleichs-Screenshots unabhängiger Tester und der typische Gray-Box-Testzyklus von OpenAI (der normalerweise 2–4 Wochen vor der offiziellen Veröffentlichung liegt) deuten alle auf dasselbe Ergebnis hin. Dieser Artikel vergleicht systematisch die acht wichtigsten Upgrades von gpt-image-2 gegenüber gpt-image-1.5.
Kernnutzen: Nach der Lektüre dieses Artikels werden Sie die konkreten Fortschritte von gpt-image-2 in den Bereichen Text, Realismus, 4K, Geschwindigkeit, UI-Wiedergabetreue und Mehrsprachigkeit verstehen und wissen, wie Sie am ersten Tag der API-Veröffentlichung nahtlos migrieren können.

Kernpunkte von gpt-image-2
| Upgrade-Dimension | Status gpt-image-1.5 | Verbesserung gpt-image-2 |
|---|---|---|
| Text-Rendering | Kurze Titel (1-5 Wörter) möglich | Zeichengenauigkeit ca. 99 % |
| Generierungsgeschwindigkeit | 8-18 Sekunden | ca. 3 Sekunden (3-5x schneller) |
| Maximale Auflösung | 1536×1024 | 2048×2048 / 4096×4096 |
| Widescreen-Unterstützung | Nur 1:1, 4:3, 3:4 | Neu: 16:9 Widescreen |
| Realismus | Vorhandener "KI-Gelbstich" | Porträts/Produkte wirken täuschend echt |
Die allgemeine Bedeutung der Upgrades von gpt-image-2
Text ist kein Schwachpunkt mehr. In der Ära von gpt-image-1.5 scheiterten die meisten Bildmodelle bei der Textdarstellung von mehr als 5-6 Wörtern. Tester im LM Arena berichten jedoch, dass UI-Labels, Schilder und Plakattexte bei gpt-image-2 kaum noch Nachbearbeitung erfordern. Das bedeutet, dass für lokalisierte Werbekreationen, UI-Mockups und Social-Media-Bilder kein manuelles Layout mehr erforderlich ist.
Vom zweistufigen zum einstufigen Inferenzprozess. Während gpt-image-1.5 noch auf einer zweistufigen Pipeline basierte, wurde gpt-image-2 laut Testern als eigenständiges Bildmodell entkoppelt und nutzt eine einstufige Inferenzarchitektur. Dies ist die Grundlage für die Geschwindigkeit von 3 Sekunden und bedeutet auch, dass der Durchsatz von Batch-Pipelines um eine Größenordnung steigen könnte.

gpt-image-2 vs gpt-image-1.5: Die 8 wichtigsten Neuerungen im Detail
Neuerung 1: Nahezu perfekte Textdarstellung
Tester der LM Arena berichten, dass gpt-image-2 eine Zeichengenauigkeit von etwa 99 % erreicht. Text wird natürlich in die Szene integriert (z. B. in UI-Oberflächen, Plakate oder Firmenschilder), anstatt wie bei älteren Modellen einfach nur "über" dem Bild zu schweben.
Dies war ein hartnäckiges Problem, das alle gängigen Bildmodelle (Midjourney, Stable Diffusion, Imagen, Flux) plagte und nun mit gpt-image-2 systematisch gelöst wurde.
Neuerung 2: Realismus, der das Auge täuscht
Mehrere Tester berichten, dass Porträts, Strand-Selfies und Produkt-Nahaufnahmen, die mit gpt-image-2 erstellt wurden, kaum noch von echten Fotos zu unterscheiden sind:
- Korrekte Anatomie der Hände: Proportionen der fünf Finger und Gelenkwinkel wirken natürlich.
- Präzise Spiegelungen in Sonnenbrillen: Reflexionen stimmen exakt mit der Umgebung überein.
- Verschwinden des Gelbstichs: Der typische "KI-Farbton", der die gpt-image-1-Ära prägte, ist verschwunden.
Neuerung 3: Tiefgreifendes Weltwissen
Wenn Tester Anfragen wie "IKEA-Filiale bei Nacht", "YouTube-Startseiten-Screenshot" oder "Minecraft-Szene mit korrektem Spiel-UI" stellen, ist die Wiedergabe echter Marken, Oberflächen und Umgebungen so präzise, dass sie als echte Aufnahmen durchgehen könnten.
Das bedeutet, dass das Modell die visuellen Konventionen der realen Welt wirklich versteht und nicht nur statistische Pixelverteilungen reproduziert.
Neuerung 4: Native 4K-Ausgabe
Während die maximale Ausgabe von gpt-image-1.5 bei 1536×1024 lag, unterstützt gpt-image-2 voraussichtlich nativ 2048×2048 und 4096×4096 sowie das 16:9-Breitbildformat.
| Anwendungsbereich | gpt-image-1.5 Erfahrung | gpt-image-2 Erfahrung |
|---|---|---|
| Kommerzieller Druck | Nachträgliche Skalierung nötig | Natives 4K, direkt druckbar |
| Marketing-Visuals | Auflösung oft unzureichend | Native Plakatqualität |
| Hochauflösende Produktbilder | Upscaling erforderlich | Direkte Generierung |
| Video-Thumbnails | Kein 16:9-Format | Natives Breitbild unterstützt |
Neuerung 5: Schnellere Generierung (ca. 3 Sekunden)
Beobachter der Arena messen eine Generierungszeit von nur etwa 3 Sekunden – weit schneller als die üblichen 10–20 Sekunden (oder gar 35–55 Sekunden in der gpt-image-1-Ära) bei bisherigen Spitzenmodellen.
Dies ist ein direkter Vorteil für interaktive UX (deutlich geringere Wartezeiten für Nutzer) sowie Batch-Pipelines (3- bis 5-facher Durchsatz in der gleichen Zeit).
Neuerung 6: Mehrsprachige Textdarstellung
In der Vorschau sind lateinische Schriften, CJK (Chinesisch, Japanisch, Koreanisch) sowie rechtsläufige Schriften (Arabisch, Hebräisch) klar und lesbar.
Sollte sich dies bei der Veröffentlichung bestätigen, entfällt bei lokalisierten Werbekampagnen und mehrsprachigen UI-Mockups das manuelle Layouten – ein großer Gewinn für globale Teams, grenzüberschreitenden E-Commerce und mehrsprachiges Content-Management.
Neuerung 7: UI- und Screenshot-Generierung
Tester hoben besonders die Fähigkeit zur UI-Wiedergabe hervor – Webseiten, App-Oberflächen und Betriebssystemfenster werden erstaunlich präzise dargestellt. Ideal für:
- Design-Exploration: Schnelle Erstellung von UI-Konzeptentwürfen.
- Tutorial-Material: Erstellung von Beispiel-Screenshots für technische Dokumentationen.
- Konzeptentwürfe: Präsentation von noch nicht entwickelten Produktoberflächen für Kunden.
- A/B-Testmaterial: Batch-Generierung verschiedener Interface-Stile zur Auswahl.
Neuerung 8: API-Verfügbarkeit ab Start
Sobald OpenAI die API freigibt, ist sie bei APIYI sofort verfügbar. Ihre bestehenden apiyi.com-Schlüssel, Guthaben und Abrechnungen bleiben unverändert – Sie müssen weder neue Konten registrieren noch SDKs austauschen oder Ihren Code anpassen.
Migrationshinweis: Vor der offiziellen Veröffentlichung von gpt-image-2 können Sie über APIYI apiyi.com das aktuelle gpt-image-1.5 testen, um sich mit der base_url-Konfiguration und der Parameterstruktur vertraut zu machen. Am Tag der Veröffentlichung müssen Sie lediglich das Feld
modelaktualisieren.
gpt-image-2 Schnellstart (API-Migrationsleitfaden)
Minimalbeispiel (basierend auf gpt-image-1.5, bei Release nur Modellnamen ersetzen)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-1.5", # Nach offiziellem Release durch "gpt-image-2" ersetzen
prompt="A modern cafe menu board with hand-lettered text 'Today Special: Espresso $4.50'",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
Vollständigen Code anzeigen (inkl. 4K, 16:9, Fehlerbehandlung)
from openai import OpenAI
from typing import Optional, Literal
def generate_image(
prompt: str,
model: str = "gpt-image-1.5",
size: Literal["1024x1024", "1536x1024", "1024x1536", "2048x2048", "4096x4096"] = "1024x1024",
quality: Literal["low", "medium", "high", "auto"] = "high",
n: int = 1
) -> Optional[str]:
"""
Generiert Bilder, kompatibel mit gpt-image-1.5 und dem zukünftigen gpt-image-2
Args:
prompt: Text-Eingabeaufforderung (max. 2000 Tokens)
model: Modellname (nach Release auf gpt-image-2 umstellbar)
size: Ausgabegröße (gpt-image-2 unterstützt 2K/4K)
quality: Qualitätsstufe
n: Anzahl der Generierungen (aktuell nur 1 unterstützt)
Returns:
Temporäre URL des generierten Bildes (24 Stunden gültig)
"""
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
try:
response = client.images.generate(
model=model,
prompt=prompt,
size=size,
quality=quality,
n=n
)
return response.data[0].url
except Exception as e:
print(f"Bilderzeugung fehlgeschlagen: {e}")
return None
url = generate_image(
prompt="Product hero shot: sleek wireless earbuds on marble, 'AuraPods Pro' label visible",
model="gpt-image-1.5",
size="1536x1024",
quality="high"
)
print(f"Bild-URL: {url}")
Plattform-Empfehlung: Sichern Sie sich über APIYI apiyi.com kostenloses Testguthaben, um die neuesten Funktionen von gpt-image-1.5 sofort zu erleben. Am Tag der Veröffentlichung von gpt-image-2 ist kein Code-Update erforderlich.
gpt-image-2 im Vergleich zu gpt-image-1.5: Lösungsübersicht
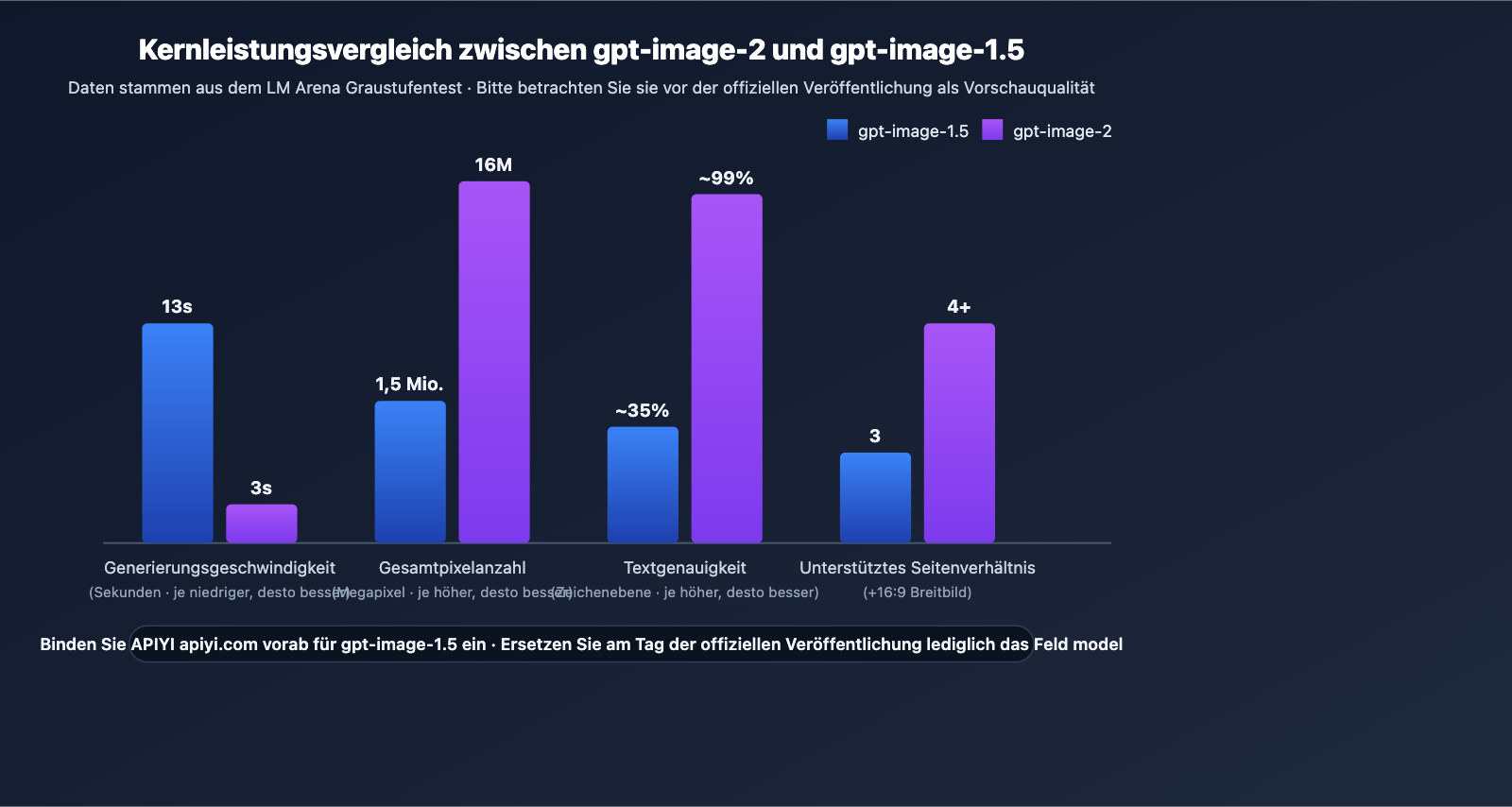
| Dimension | gpt-image-1.5 (12/2025) | gpt-image-2 (erwartet 04-05/2026) | Bedeutung der Differenz |
|---|---|---|---|
| Architektur | Zweistufige Inferenz | Einstufige Inferenz | Deutlich höherer Durchsatz |
| Geschwindigkeit | 8-18 Sekunden | ca. 3 Sekunden | 3- bis 5-mal schneller |
| Max. Auflösung | 1536×1024 | 4096×4096 | Direkt für kommerziellen Druck |
| Seitenverhältnisse | 1:1/3:4/4:3 | + 16:9 Breitbild | Ideal für Video-Thumbnails |
| Textgenauigkeit | 1-5 Wörter (kurz) | ca. 99% auf Zeichenebene | Kein manuelles Layout mehr |
| Mehrsprachigkeit | Instabil bei Nicht-Latein | CJK/RTL klar lesbar | Vorteil für lokalisierte Inhalte |
| UI-Wiedergabe | Durchschnittlich | "Täuschend echte" Screenshots | Ideal für Design/Tutorials |
Analyse des Upgrades
Im Vergleich zu Midjourney: Midjourney bleibt bei künstlerischen Stilen führend, doch der API-Zugriff ist eingeschränkt und die Textdarstellung schwach. gpt-image-2 bietet eine Standard-API-Anbindung und 99% Textgenauigkeit, was es ideal für die Integration in automatisierte Workflows macht.
Im Vergleich zu Imagen 2: Google Imagen 2 überzeugt durch fotorealistische Qualität, hat jedoch ein geschlossenes Ökosystem und begrenzte Unterstützung für Sprachen außerhalb des Englischen. gpt-image-2 ist in den Bereichen mehrsprachiger Text, UI-Wiedergabe und Geschwindigkeit ausgewogener und damit besser für global agierende Teams geeignet.
Im Vergleich zu nano-banana-pro: nano-banana-pro punktet beim Preis-Leistungs-Verhältnis, erreicht jedoch nicht die 4K-Ausgabe und die Marken-Wiedergabetreue, die von gpt-image-2 erwartet werden. Für kommerzielle Druck- und Marketingzwecke bleibt gpt-image-2 die solidere Wahl.
Hinweis zum Vergleich: Die Daten basieren teilweise auf öffentlichen Tests im LM Arena und auf Rückmeldungen früher Tester. Betrachten Sie diese Informationen vor der offiziellen Veröffentlichung von gpt-image-2 als Vorschau. Es wird empfohlen, gpt-image-1.5 über den API-Proxy-Dienst APIYI (apiyi.com) zu testen, um sich mit der Parameterstruktur vertraut zu machen.
Anwendungsbereiche für gpt-image-2
Ein Upgrade auf gpt-image-2 ist besonders für folgende Szenarien sinnvoll:
- Szenario 1 – Kommerzieller Druck: Die native 4K-Ausgabe löst das Auflösungsproblem bei Postern, Broschüren und großformatiger Werbung.
- Szenario 2 – Lokalisierte Werbung: Dank der präzisen mehrsprachigen Textdarstellung entfällt das manuelle Layout – ein enormer Effizienzgewinn für globale Teams.
- Szenario 3 – UI-Design-Exploration: Produktmanager und Designer können schnell Konzeptentwürfe und Tutorial-Materialien erstellen.
- Szenario 4 – E-Commerce-Hauptbilder: Porträtähnlicher Realismus und präzise Produkttexte eignen sich hervorragend für visuelle Marketing-Assets.
- Szenario 5 – Video-Content: Die 16:9-Breitbildunterstützung ermöglicht die massenhafte Erstellung von Thumbnails für YouTube und Kurzvideos.
Empfehlung: Wenn Sie aktuell eine Bild-API evaluieren, empfehlen wir die Anbindung von gpt-image-1.5 über APIYI (apiyi.com). Nach der offiziellen Veröffentlichung können Sie nahtlos durch den Austausch des
model-Feldes upgraden.
Häufig gestellte Fragen (FAQ)
Q1: Was ist gpt-image-2?
gpt-image-2 ist das Bildgenerierungsmodell der nächsten Generation von OpenAI, dessen Veröffentlichung für April/Mai 2026 erwartet wird. Laut LM Arena-Betatests nutzt das Modell eine Single-Inference-Architektur, erreicht eine Genauigkeit bei der Textwiedergabe von etwa 99 %, eine Geschwindigkeit von ca. 3 Sekunden und unterstützt nativ 4K-Ausgabe. Es ist das bedeutende Upgrade nach gpt-image-1 (04/2025) und gpt-image-1.5 (12/2025).
Q2: Was unterscheidet gpt-image-2 von gpt-image-1.5?
Die Kernunterschiede liegen in acht Dimensionen: Textwiedergabe (5 Wörter → 99 %), Geschwindigkeit (8–18 Sek. → 3 Sek.), Auflösung (1536×1024 → 4096×4096), Seitenverhältnis (neu: 16:9), Realismus (Entfernung des Gelbstichs), Weltwissen (präzise Marken/UI), Mehrsprachigkeit (klare CJK/RTL-Darstellung) und UI-Wiedergabetreue (täuschend echte Screenshots). Während gpt-image-1.5 für kurze Titel und Standardformate ausreicht, empfiehlt sich für kommerzielle Drucke, Lokalisierung und UI-Szenarien das Warten auf gpt-image-2.
Q3: Wann wird gpt-image-2 veröffentlicht?
Stand 17.04.2026 gibt es noch keine offizielle Ankündigung von OpenAI. Basierend auf historischen Testzyklen (üblicherweise 2–4 Wochen bis zur Veröffentlichung) rechnet die Branche mit einem Zeitfenster von Ende April bis Mitte Mai 2026. Die drei Codenamen-Modelle auf LM Arena (maskingtape-alpha, gaffertape-alpha, packingtape-alpha) befinden sich derzeit noch im A/B-Test.
Q4: Für welche Anwendungsbereiche eignet sich gpt-image-2 am besten?
Es ist ideal für folgende spezifische Szenarien:
- Kommerzielle Poster/Broschüren: Native 4K-Ausgabe spart nachträgliches Upscaling.
- Lokalisierte Social-Media-Bilder: Textwiedergabe in verschiedenen Sprachen ohne Photoshop-Layout.
- UI-Design-Konzepte: Erstellung von Beispiel-Screenshots für Produktexplorationen und Tutorials.
- E-Commerce-Marketingbilder: Realistische Porträts kombiniert mit präzisem Produkttext.
- Thumbnails für Videoplattformen: Batch-Generierung im nativen 16:9-Format.
Q5: Wie lässt sich gpt-image-2 schnell über die API aufrufen?
Wir empfehlen die frühzeitige Anbindung über APIYI (apiyi.com), um gpt-image-2 sofort nach Veröffentlichung nutzen zu können:
- Besuchen Sie apiyi.com, registrieren Sie ein Konto und erhalten Sie Ihren API-Schlüssel.
- Verwenden Sie
base_url=https://vip.apiyi.com/v1und nutzen Sie die bekannten Parameter von gpt-image-1.5. - Am Tag der Veröffentlichung von gpt-image-2 müssen Sie lediglich das Feld
modelvongpt-image-1.5aufgpt-image-2ändern.
APIYI stellt neue Modelle zeitgleich mit OpenAI bereit; bestehende Schlüssel, Guthaben und Abrechnungen bleiben unverändert, sodass kein neues Konto oder SDK-Wechsel erforderlich ist.
Q6: Welche bekannten Einschränkungen oder Unsicherheiten gibt es bei gpt-image-2?
Die Hauptunsicherheiten ergeben sich aus der noch ausstehenden offiziellen Veröffentlichung:
- Preisgestaltung unbekannt: gpt-image-1.5 war etwa 20 % günstiger als gpt-image-1; der Preis für gpt-image-2 muss noch bestätigt werden.
- Ratenbegrenzungen: Zum Start könnte es Kontingentbeschränkungen geben; die Nutzung über einen API-Proxy-Dienst wird empfohlen, um Kaltstartprobleme zu vermeiden.
- Mögliche Anpassungen: Zwischen der Testversion auf LM Arena und der finalen Version kann es Unterschiede geben.
- Ausweichlösung: Bei dringenden Projekten bleibt gpt-image-1.5 eine stabile und bewährte Wahl.
Q7: Wird gpt-image-2 DALL-E 3 ersetzen?
Gemäß dem Veröffentlichungszyklus von OpenAI wird erwartet, dass DALL-E 3 nach der offiziellen Einführung von gpt-image-2 schrittweise eingestellt wird. Die gpt-image-Serie ist das neue offizielle Flaggschiff, und die API-Struktur ist bereits stabil. Für neue Projekte empfiehlt es sich, direkt auf gpt-image-1.5 zu setzen oder auf gpt-image-2 zu warten, um keine unnötigen Anpassungen in DALL-E 3 zu investieren.
Q8: Sind die „tape“-Modelle auf LM Arena definitiv gpt-image-2?
Es gibt noch keine offizielle Bestätigung, aber vier Indizien deuten stark auf OpenAI hin:
- Das Namensschema (tape-Serie) entspricht den historischen Codenamen von OpenAI.
- Die Fähigkeiten (99 % Textwiedergabe, Weltwissen) übertreffen alle derzeit öffentlich verfügbaren Modelle.
- Die Testzeiträume decken sich mit den üblichen Beta-Zyklen von OpenAI.
- Der Output-Stil der Modelle ist konsistent mit der gpt-image-Serie (kein Midjourney/Imagen-Stil).
Wir empfehlen, die offiziellen Ankündigungen zu verfolgen und die zeitnahe Bereitstellung über APIYI (apiyi.com) abzuwarten.
Wichtige Erkenntnisse zu gpt-image-2
- Modell der nächsten Generation: OpenAIs Bild-Flaggschiff für 2026; ersetzt gpt-image-1.5; Umstellung von zweistufiger auf Single-Inference-Architektur.
- Acht Upgrades: 99 % Textgenauigkeit, 3 Sek. Geschwindigkeit, native 4K-Auflösung, 16:9-Format, Realismus, Weltwissen, Mehrsprachigkeit, UI-Wiedergabetreue.
- Anwendungsbereiche: Kommerzieller Druck, lokalisierte Werbung, UI-Konzepte, E-Commerce-Bilder und Video-Thumbnails.
- Zeitplan: Veröffentlichung voraussichtlich zwischen Ende April und Mitte Mai 2026; aktuelle Beta-Codenamen gehören zur "tape"-Serie.
- Nahtlose Migration: Frühzeitige Anbindung von gpt-image-1.5 über APIYI (apiyi.com); am Tag des Releases genügt ein einfacher Austausch des
model-Feldes.
Zusammenfassung
Die Kernpunkte des Vergleichs zwischen gpt-image-2 und gpt-image-1.5:
- Qualitativer Sprung: Die drei Kernindikatoren Textdarstellung, Geschwindigkeit und Auflösung erreichen oder übertreffen nun produktionsreife Standards. Es ist kein "brauchbar, aber nachbearbeitungsbedürftig" mehr.
- Neue Einsatzmöglichkeiten: Kommerzieller Druck, mehrsprachige Lokalisierung und UI-Wiedergabe sind erstmals wirklich einsatzbereit, was die Kosten für manuelle Nachbearbeitung erheblich senkt.
- Nahtlose Migration: Die API-Parameterstruktur bleibt mit gpt-image-1.5 kompatibel. Teams, die sich frühzeitig vorbereiten, können am Tag der Veröffentlichung ohne Code-Änderungen umstellen.
Für Ihre Teamentscheidung: Wir empfehlen, gpt-image-1.5 sofort über APIYI (apiyi.com) zu integrieren, um sich mit den Parametern und Workflows vertraut zu machen. Die Plattform bietet kostenlose Kontingente und eine einheitliche Schnittstelle. Sobald gpt-image-2 erscheint, können Sie durch einfaches Anpassen des model-Feldes sofort von den acht großen Upgrades profitieren.
Weiterführende Artikel
Wenn Sie sich für gpt-image-2 interessieren, empfehlen wir folgende Lektüre:
- 📘 Vollständiger API-Aufruf-Leitfaden für gpt-image-1.5 – Meistern Sie die Parameter und Best Practices des aktuellen Flaggschiff-Modells für Bilderzeugung.
- 📊 Preis- und Qualitätsvergleich: gpt-image-2 vs. nano-banana-pro – Verstehen Sie die Kostenstruktur gängiger Bild-APIs.
- 🚀 Optimierung von Batch-Aufrufen für Bilderzeugungs-APIs in der Produktion – Entdecken Sie Strategien für Batch-Pipelines, Nebenläufigkeit und Caching.
📚 Referenzmaterialien
-
MindStudio-Analyse: Umfassende Interpretation von "What Is GPT Image 2"
- Link:
mindstudio.ai/blog/what-is-gpt-image-2 - Beschreibung: Systematische Zusammenstellung der Fähigkeitsmatrix von GPT-Image-2 durch einen hochrangigen internationalen Blog.
- Link:
-
getimg.ai Leak-Analyse: GPT Image 2 Gerüchte, Leaks & Veröffentlichungsdatum
- Link:
getimg.ai/blog/gpt-image-2-rumours-leaks-release-date-2026 - Beschreibung: Beobachtungen aus erster Hand zur Leistung der drei Modelle mit dem Codenamen "Tape" in der LM Arena.
- Link:
-
Offizieller OpenAI-Blog: Ankündigung zum Upgrade der ChatGPT-Bildfunktionen
- Link:
openai.com/index/new-chatgpt-images-is-here - Beschreibung: Offizielle und maßgebliche Erläuterung des Entwicklungspfads der GPT-Image-Serie.
- Link:
-
gpt-image-1.5 Parameter-Dokumentation: Zusammengestellt von EvoLink
- Link:
evolink.ai/blog/gpt-image-1-5-guide-features-comparison-access - Beschreibung: Detaillierte Parameter zu Geschwindigkeit, Auflösung und Qualitätsstufen von GPT-Image-1.5.
- Link:
Autor: APIYI Technik-Team
Technischer Austausch: Wir freuen uns auf Diskussionen in den Kommentaren. Weitere Informationen finden Sie im APIYI Dokumentationszentrum unter docs.apiyi.com.