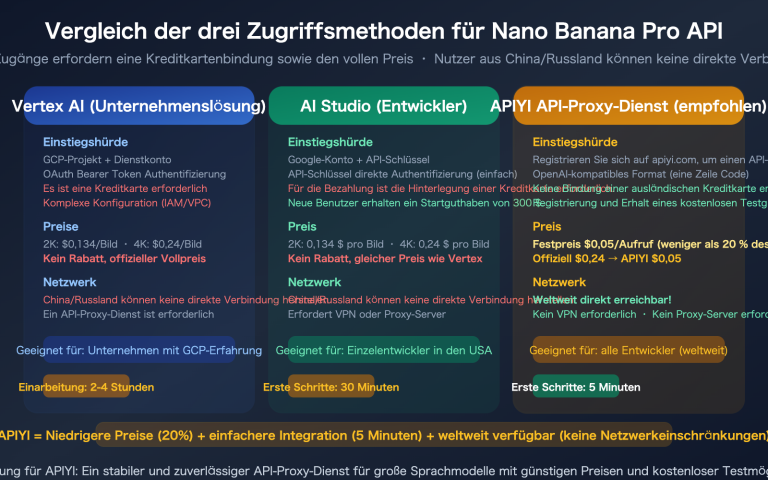
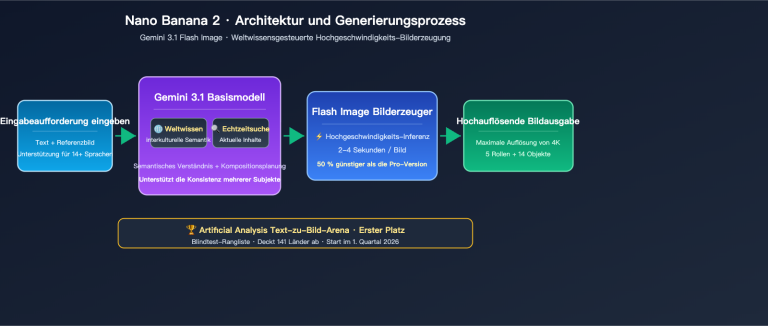
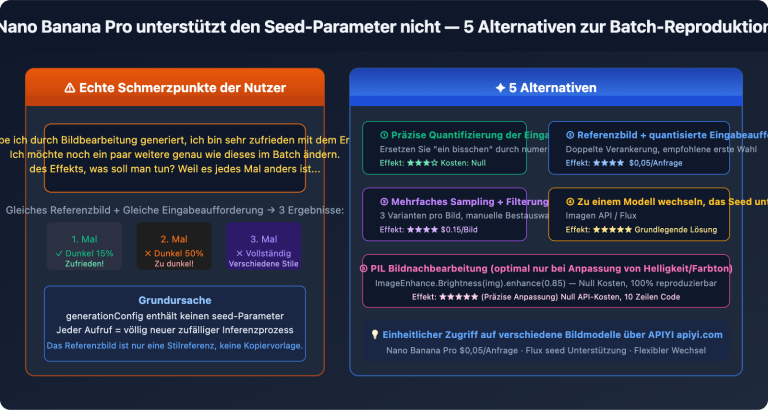
„Wie viele gleichzeitige Anfragen sind sinnvoll?“ – Das ist die am häufigsten gestellte Frage von Entwicklern, die die Nano Banana 2 API für die Stapelverarbeitung der Bilderzeugung nutzen. Die Antwort liegt nicht bei den Plattformbeschränkungen, sondern bei der Frage, wie viele Base64-Bilddaten deine Bandbreite und dein Arbeitsspeicher bewältigen können.
Kernnutzen: Nach dem Lesen dieses Artikels kennst du die entscheidenden Engpässe bei gleichzeitigen Aufrufen der Nano Banana 2 API, kannst die optimale Anzahl an parallelen Anfragen basierend auf deiner Serverkapazität berechnen und erhältst 5 bewährte Tipps zur Leistungsoptimierung.

Nano Banana 2 API: Das Kernproblem bei der Nebenläufigkeit liegt nicht an der Plattform, sondern an deiner Pipeline
Viele Entwickler fragen zuerst: „Wie viele gleichzeitige Anfragen unterstützt die Plattform?“. Die Realität ist jedoch: Die APIYI-Plattform begrenzt die Nebenläufigkeit nicht. Die RPM (Anfragen pro Minute) können problemlos 1000 pro Benutzer erreichen, und bei Bedarf lässt sich das Kontingent individuell erhöhen.
Der eigentliche Flaschenhals ist: Die Gemini-API zur Bilderzeugung überträgt Bilddaten mittels Base64-Kodierung. Das bedeutet, dass das Hoch- und Herunterladen jedes Bildes als riesiger JSON-Text erfolgt und nicht als effizienter Binärstrom. Dies belastet deine Bandbreite und deinen Arbeitsspeicher massiv.
Warum Base64 der zentrale Flaschenhals für die Nebenläufigkeit ist
Die offizielle Gemini-API (einschließlich gemini-3.1-flash-image-preview, das dem Nano Banana 2 entspricht) unterstützt für die Bildübertragung ausschließlich Base64. Die Base64-Kodierung bläht Binärdaten um etwa 33 % auf, was bedeutet:
| Auflösung | Originalbildgröße | Nach Base64-Kodierung | API-Antwortvolumen pro Bild |
|---|---|---|---|
| 512px (0,5K) | ~400 KB | ~530 KB | ~600 KB – 1 MB |
| 1K (Standard) | ~1,5 MB | ~2 MB | ~2 MB |
| 2K | ~4 MB | ~5,3 MB | ~5-8 MB |
| 4K | ~15 MB | ~20 MB | ~20 MB |
Eine API-Antwort für ein 4K-Bild umfasst bereits 20 MB. Wenn du 10 gleichzeitige 4K-Anfragen startest, fließen allein durch die Antwortdaten 200 MB durch dein Netzwerk und deinen Arbeitsspeicher.
Nano Banana 2 API: Parameter-Kurzübersicht
| Parameter | Wert |
|---|---|
| Modell-ID | gemini-3.1-flash-image-preview |
| Eingabe-Kontextfenster | 131.072 Token |
| Ausgabe-Limit | 32.768 Token |
| Unterstützte Auflösungen | 512px / 1K / 2K / 4K |
| Unterstützte Seitenverhältnisse | 14 Typen (1:1, 3:2, 4:3, 16:9, 9:16, 21:9 etc.) |
| Max. Referenzbilder | 14 (10 Objekte + 4 Charaktere) |
| Generierungsgeschwindigkeit | 3-5 Sek./Bild |
| APIYI RPM | 1000/Benutzer (Kontingent erweiterbar) |
| APIYI Nebenläufigkeitslimit | Unbegrenzt |
🎯 Technischer Rat: Die APIYI-Plattform (apiyi.com) begrenzt die Nebenläufigkeit für Nano Banana 2 nicht und unterstützt 1000 RPM pro Benutzer. Der Flaschenhals liegt in deiner lokalen Umgebung – Bandbreite und Arbeitsspeicher bestimmen, wie viele Anfragen du tatsächlich parallel ausführen kannst.
Nano Banana 2 API: Berechnung der Nebenläufigkeit – Die optimale Lösung für deine Umgebung
Die Anzahl der gleichzeitigen Anfragen sollte nicht geraten, sondern basierend auf deiner tatsächlichen Umgebung berechnet werden. Die drei entscheidenden Faktoren sind: Bandbreite, Arbeitsspeicher und Zielauflösung.

Schritt 1: Bestimme deine Bandbreite
Die Bandbreite bestimmt, wie viele Daten gleichzeitig übertragen werden können. Berechnungsformel:
Max. Nebenläufigkeit (Bandbreite) = Verfügbare Bandbreite (MB/s) ÷ Größe der Antwort pro Bild (MB)
| Netzwerkumgebung | Verfügbare Bandbreite | 1K Nebenläufigkeitslimit | 2K Nebenläufigkeitslimit | 4K Nebenläufigkeitslimit |
|---|---|---|---|---|
| Heimnetz (100 Mbps) | ~12 MB/s | 6 | 2 | 0-1 |
| Unternehmensnetz (500 Mbps) | ~60 MB/s | 30 | 10 | 3 |
| Cloud-Server (1 Gbps) | ~120 MB/s | 60 | 20 | 6 |
| High-Performance-Server (10 Gbps) | ~1200 MB/s | 600 | 200 | 60 |
Schritt 2: Bestimme deinen verfügbaren Arbeitsspeicher
Jede gleichzeitige Anfrage muss die Base64-Antwortdaten vollständig im Speicher halten, bis die Dekodierung und das Schreiben auf die Festplatte abgeschlossen sind. Formel für den Arbeitsspeicher:
Benötigter Arbeitsspeicher = Nebenläufigkeit × Größe der Antwort pro Bild × 2,5 (Dekodierungs-Pufferfaktor)
Der Faktor 2,5 wird verwendet, da während der Base64-Dekodierung sowohl der ursprüngliche String als auch die dekodierten Binärdaten gleichzeitig im Speicher existieren, zuzüglich des Overheads für die JSON-Analyse.
| Verfügbarer RAM | 1K Nebenläufigkeitslimit | 2K Nebenläufigkeitslimit | 4K Nebenläufigkeitslimit |
|---|---|---|---|
| 2 GB | 400 | 100 | 40 |
| 4 GB | 800 | 200 | 80 |
| 8 GB | 1600 | 400 | 160 |
Schritt 3: Wähle den kleineren Wert
Empfohlene Nebenläufigkeit = min(Bandbreiten-Limit, RAM-Limit)
In der Praxis ist in den meisten Szenarien die Bandbreite der eigentliche Flaschenhals, nicht der Arbeitsspeicher.
Empfohlene Nebenläufigkeit für reale Szenarien
| Szenario | Empfohlene Auflösung | Empfohlene Nebenläufigkeit | Erwarteter Durchsatz |
|---|---|---|---|
| Persönliche Entwicklung/Tests | 1K | 3-5 | ~1 Bild/Sek. |
| Batch-Generierung (kleines Team) | 1K | 10-20 | ~4 Bilder/Sek. |
| Unternehmens-Produktionsumgebung | 1K-2K | 20-50 | ~10 Bilder/Sek. |
| Hochdurchsatz-Bilddienst | 1K | 50-100 | ~20 Bilder/Sek. |
| 4K HD-Bilder | 4K | 3-5 | ~1 Bild/Sek. |
💡 Praxistipp: Wenn du dir unsicher bist, starte mit 5 gleichzeitigen Anfragen und steigere dich schrittweise auf 10 oder 20, während du die Antwortzeiten und Fehlerraten beobachtest. Wenn die Antwortzeit deutlich ansteigt oder Timeouts auftreten, näherst du dich dem Limit. Wenn du auf der APIYI-Plattform (apiyi.com) testest, musst du dir keine Sorgen um plattformseitige Beschränkungen machen – konzentriere dich einfach auf die Performance deiner lokalen Umgebung.
Schnelle Integration der Nano Banana 2 API: In 3 Schritten zum Ziel
Schritt 1: Abhängigkeiten installieren
pip install openai Pillow
Schritt 2: Minimalistisches Aufrufbeispiel
import openai
import base64
from pathlib import Path
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle
)
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": "Generate a cute cat wearing sunglasses on a beach"
}
]
)
# Base64-Bilddaten extrahieren und speichern
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
img_bytes = base64.b64decode(part.image.data)
Path("output.png").write_bytes(img_bytes)
print("Bild gespeichert: output.png")
Vollständigen Code für parallele Batch-Generierung anzeigen
import openai
import base64
import asyncio
import aiohttp
import time
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle
)
# Konfigurationsparameter
MAX_CONCURRENCY = 10 # Maximale Parallelität, an Bandbreite anpassen
OUTPUT_DIR = Path("output")
OUTPUT_DIR.mkdir(exist_ok=True)
def generate_single_image(prompt: str, index: int) -> dict:
"""Generiert ein einzelnes Bild und speichert es sofort, um Speicher freizugeben"""
start = time.time()
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# Sofort dekodieren und speichern, um Base64-String-Speicherbelegung zu minimieren
img_bytes = base64.b64decode(part.image.data)
filepath = OUTPUT_DIR / f"image_{index:04d}.png"
filepath.write_bytes(img_bytes)
elapsed = time.time() - start
size_mb = len(img_bytes) / (1024 * 1024)
return {
"index": index,
"success": True,
"time": elapsed,
"size_mb": size_mb,
"path": str(filepath)
}
except Exception as e:
return {
"index": index,
"success": False,
"error": str(e),
"time": time.time() - start
}
def batch_generate(prompts: list[str]):
"""Parallele Bilderzeugung mittels Thread-Pool"""
results = []
total = len(prompts)
completed = 0
with ThreadPoolExecutor(max_workers=MAX_CONCURRENCY) as executor:
futures = {
executor.submit(generate_single_image, p, i): i
for i, p in enumerate(prompts)
}
for future in futures:
result = future.result()
completed += 1
status = "OK" if result["success"] else "FAIL"
print(f"[{completed}/{total}] {status} - {result['time']:.1f}s")
results.append(result)
# Statistik
success = [r for r in results if r["success"]]
print(f"\nAbgeschlossen: {len(success)}/{total} erfolgreich")
if success:
avg_time = sum(r["time"] for r in success) / len(success)
total_size = sum(r["size_mb"] for r in success)
print(f"Durchschnittliche Dauer: {avg_time:.1f}s | Gesamtgröße: {total_size:.1f} MB")
# Anwendungsbeispiel
prompts = [
"A futuristic city at sunset",
"A cozy coffee shop interior",
"An underwater coral reef scene",
"A mountain landscape with aurora",
"A cute robot playing guitar",
]
batch_generate(prompts)
Schritt 3: Referenzbild hochladen (Bild-zu-Bild)
Für Bild-zu-Bild-Szenarien muss ein Referenzbild hochgeladen werden, ebenfalls als Base64-Kodierung:
import base64
# Lokales Bild lesen und in Base64 konvertieren
with open("reference.png", "rb") as f:
img_base64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Konvertiere dieses Foto in einen Aquarell-Stil"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{img_base64}"
}
}
]
}
]
)
Hinweis: Beim Hochladen eines Referenzbildes darf die gesamte Größe des Request-Bodys 20 MB nicht überschreiten. Bei größeren Bildern empfiehlt es sich, diese vorab auf eine Auflösung unter 1K zu komprimieren.
5 Praxistipps zur Optimierung der Nano Banana 2 API-Parallelität
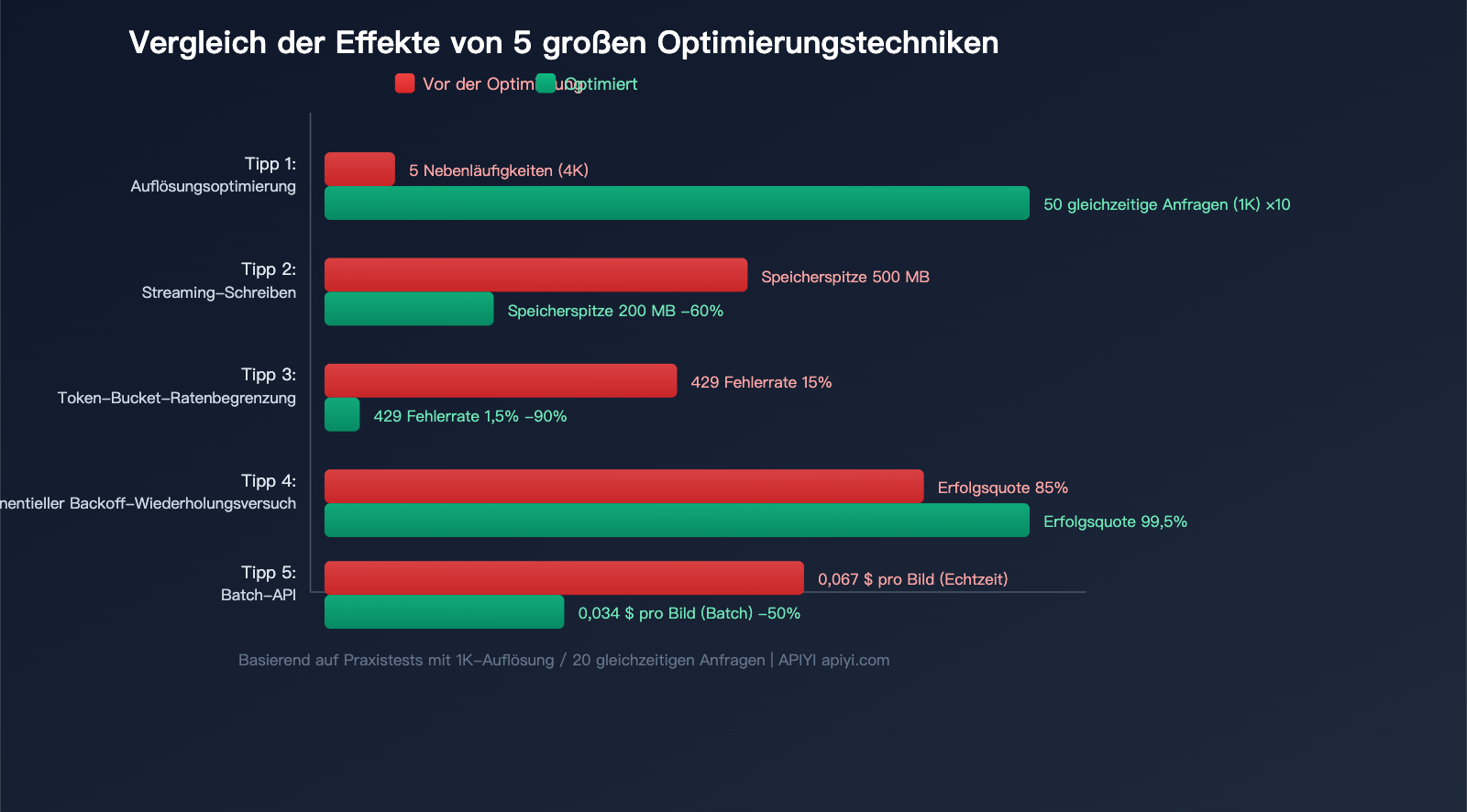
Tipp 1: Auflösung bedarfsgerecht wählen, Standard-4K vermeiden
Dies ist die einfachste und effektivste Optimierung. Viele Entwickler fordern standardmäßig 4K an, obwohl in den meisten Fällen 1K völlig ausreicht:
| Anwendungsfall | Empfohlene Auflösung | Einzelbildgröße | Parallelitätseffizienz |
|---|---|---|---|
| Social Media | 1K | ~2 MB | Hoch |
| E-Commerce | 2K | ~6 MB | Mittel |
| Druck/Poster | 4K | ~20 MB | Niedrig |
| Vorschau/Thumbnails | 512px | ~0.7 MB | Sehr hoch |
Der Wechsel von 4K auf 1K steigert die Parallelität unter gleichen Bedingungen um das ca. 10-fache.
Tipp 2: Streaming-Empfang + sofortiges Schreiben auf die Festplatte
Warten Sie nicht, bis die gesamte JSON-Antwort empfangen wurde. Nutzen Sie Streaming, um Daten während des Empfangs zu dekodieren und direkt auf die Festplatte zu schreiben:
import gc
def generate_and_save(prompt, filepath):
"""Bild generieren und sofort speichern, Speicher aktiv freigeben"""
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# Sofort dekodieren
img_bytes = base64.b64decode(part.image.data)
# Referenz auf Base64-String sofort löschen
del part.image.data
# Sofort auf Festplatte schreiben
Path(filepath).write_bytes(img_bytes)
del img_bytes
gc.collect() # Garbage Collection aktiv auslösen
Tipp 3: Token-Bucket-Limiter zur Steuerung der Parallelität
Senden Sie nicht alle Anfragen gleichzeitig ab, sondern nutzen Sie den Token-Bucket-Algorithmus, um Anfragen gleichmäßig zu verteilen:
import threading
import time
class TokenBucket:
"""Token-Bucket-Ratenbegrenzer"""
def __init__(self, rate: float, capacity: int):
self.rate = rate # Auffüllrate pro Sekunde
self.capacity = capacity # Bucket-Kapazität
self.tokens = capacity
self.lock = threading.Lock()
self.last_refill = time.monotonic()
def acquire(self):
while True:
with self.lock:
now = time.monotonic()
elapsed = now - self.last_refill
self.tokens = min(
self.capacity,
self.tokens + elapsed * self.rate
)
self.last_refill = now
if self.tokens >= 1:
self.tokens -= 1
return
time.sleep(0.05)
# Verwendung: Maximal 10 Anfragen pro Sekunde, Spitze 20
limiter = TokenBucket(rate=10, capacity=20)
def rate_limited_generate(prompt, index):
limiter.acquire() # Auf Token warten
return generate_single_image(prompt, index)
Tipp 4: Exponentielles Backoff bei 429-Fehlern
Bei Ratenbegrenzungen (HTTP 429) sollte eine Strategie des exponentiellen Backoffs angewendet werden:
import random
def generate_with_retry(prompt, index, max_retries=5):
"""Wiederholungsmechanismus mit exponentiellem Backoff"""
for attempt in range(max_retries):
try:
return generate_single_image(prompt, index)
except openai.RateLimitError:
delay = min(60, (2 ** attempt)) + random.uniform(0, 0.5)
print(f"Ratenbegrenzung, warte {delay:.1f}s vor erneutem Versuch...")
time.sleep(delay)
return {"index": index, "success": False, "error": "max retries"}
Tipp 5: Batch API für Stapelverarbeitung spart 50 % Kosten
Für Batch-Aufgaben, die keine Echtzeit-Ergebnisse erfordern, unterstützt Nano Banana 2 die Batch API, wodurch sich die Kosten halbieren:
| Modus | Preis pro 1K-Bild | Preis pro 4K-Bild | Latenz | Anwendungsfall |
|---|---|---|---|---|
| Echtzeit-API | $0.067 | $0.151 | 3-5 Sek. | Interaktive Apps |
| Batch API | $0.034 | $0.076 | Min. bis Std. | Batch-Vorabgenerierung |
💰 Kostenoptimierung: Wenn Ihr Anwendungsfall Wartezeiten zulässt, können Sie durch den Aufruf der Batch API über APIYI (apiyi.com) 50 % der Kosten einsparen. Dies eignet sich besonders für die massenhafte Generierung von E-Commerce-Produktbildern oder die Vorab-Erstellung von Marketingmaterialien.
Detaillierte Aufschlüsselung der Kosten und des Token-Verbrauchs von Nano Banana 2
Das Verständnis des Token-Verbrauchs hilft Ihnen dabei, Ihre Kosten besser zu kontrollieren:
| Auflösung | Output Token-Verbrauch | Standardpreis | Batch-Preis (50% Rabatt) | Kosten pro 100 Bilder |
|---|---|---|---|---|
| 512px | 747 Token | $0,045 | $0,022 | $4,50 / $2,20 |
| 1K | 1.120 Token | $0,067 | $0,034 | $6,70 / $3,40 |
| 2K | 1.680 Token | $0,101 | $0,050 | $10,10 / $5,00 |
| 4K | 2.520 Token | $0,151 | $0,076 | $15,10 / $7,60 |
🚀 Schnellstart: Nutzen Sie Nano Banana 2 über die Plattform APIYI (apiyi.com). Die Preise entsprechen den offiziellen Konditionen, es gibt keine Begrenzung der parallelen Anfragen und der RPM-Support liegt bei 1000 pro Nutzer. Registrieren Sie sich einfach, um ein Testguthaben zu erhalten.
Vergleich von Nano Banana 2 mit Vorgängermodellen
| Vergleichspunkt | Nano Banana | Nano Banana Pro | Nano Banana 2 |
|---|---|---|---|
| Modell-ID | gemini-2.5-flash (Bild) | gemini-3-pro-image-preview | gemini-3.1-flash-image-preview |
| Max. Auflösung | 1024×1024 | 4K | 4K |
| Einzelpreis 1K | $0,039 | $0,134 | $0,067 |
| Einzelpreis 4K | Nicht unterstützt | $0,240 | $0,151 |
| Generierungsgeschwindigkeit | 2-4 Sekunden | 5-8 Sekunden | 3-5 Sekunden |
| Batch API | Nicht unterstützt | Nicht unterstützt | Unterstützt (50% Rabatt) |
| Limit Referenzbilder | 5 Bilder | 10 Bilder | 14 Bilder |
| Verfügbar bei APIYI | ✅ | ✅ | ✅ |
Im Vergleich zur Pro-Version bietet Nano Banana 2 eine Preissenkung von 37% bei 4K-Auflösung, eine Geschwindigkeitssteigerung von 40% und unterstützt nun zusätzlich die Batch API.
Nano Banana 2 API-Parallelleistung überwachen
Bei der Ausführung von parallelen Aufgaben in der Praxis empfiehlt es sich, die folgenden Metriken zu überwachen:
import psutil
import time
class PerformanceMonitor:
"""Überwachung der parallelen Leistung"""
def __init__(self):
self.start_time = time.time()
self.request_count = 0
self.total_bytes = 0
self.errors = 0
def record(self, success: bool, size_bytes: int = 0):
self.request_count += 1
if success:
self.total_bytes += size_bytes
else:
self.errors += 1
def report(self):
elapsed = time.time() - self.start_time
mem = psutil.Process().memory_info().rss / (1024**2)
print(f"--- Leistungsbericht ---")
print(f"Laufzeit: {elapsed:.1f}s")
print(f"Abgeschlossene Anfragen: {self.request_count}")
print(f"Erfolgsrate: {(self.request_count-self.errors)/max(1,self.request_count)*100:.1f}%")
print(f"Durchsatz: {self.request_count/elapsed:.2f} Anfragen/s")
print(f"Datenmenge: {self.total_bytes/(1024**2):.1f} MB")
print(f"Bandbreitennutzung: {self.total_bytes/(1024**2)/elapsed:.1f} MB/s")
print(f"Speicherauslastung: {mem:.0f} MB")
Häufig gestellte Fragen (FAQ)
Q1: Gibt es auf der APIYI-Plattform eine Begrenzung für die Parallelität von Nano Banana 2?
Die APIYI-Plattform begrenzt die Anzahl der parallelen Anfragen für Nano Banana 2 nicht. Die RPM (Anfragen pro Minute) unterstützen standardmäßig 1000 Anfragen pro Benutzer. Bei höherem Bedarf können Sie den Kundendienst kontaktieren, um ein individuelles Kontingent zu erhalten. Der tatsächliche Engpass bei der Parallelität liegt in Ihrer lokalen Bandbreite und Ihrem Arbeitsspeicher. Es wird empfohlen, über die Plattform APIYI apiyi.com reale Tests durchzuführen, um die optimale Parallelität für Ihre Umgebung zu ermitteln.
Q2: Warum unterstützt die Gemini-Bild-API nur die Base64-Übertragung?
Dies ist eine aktuelle Designentscheidung der Google Gemini API. Die Base64-Kodierung ermöglicht es, Bilddaten direkt in die JSON-Antwort einzubetten, ohne dass zusätzliche Dateispeicherung oder CDN-Verteilung erforderlich sind. Der Nachteil ist eine Datenaufblähung von etwa 33 %, was sich ungünstig auf Bandbreite und Speicher auswirkt. Die Entwickler-Community hat Google bereits Feedback gegeben mit dem Wunsch nach einer JPEG-Ausgabe und temporären Download-URLs, was jedoch bisher noch nicht umgesetzt wurde.
Q3: Ist der Qualitätsunterschied zwischen 1K- und 4K-Auflösung groß?
Das hängt vom Anwendungsfall ab. Für Social-Media-Bilder, Web-Präsentationen oder App-Oberflächen ist eine 1K-Auflösung völlig ausreichend; das menschliche Auge erkennt kaum einen Unterschied. 4K wird hauptsächlich für Drucke, Poster, hochauflösende Hintergrundbilder oder Szenarien verwendet, in denen Details vergrößert betrachtet werden müssen. Es wird empfohlen, die Ergebnisse zunächst mit 1K zu testen und erst bei Bedarf einer höheren Klarheit auf 4K umzusteigen. Über APIYI apiyi.com können Sie die Auflösung flexibel umschalten und jederzeit anpassen.
Q4: Was tun bei häufigen 429-Fehlern?
Ein 429-Fehler bedeutet, dass das Ratenlimit erreicht wurde. Lösungen: (1) Reduzieren Sie die Parallelität; (2) Verwenden Sie einen Token-Bucket-Limiter, um Anfragen gleichmäßig zu verteilen; (3) Implementieren Sie eine exponentielle Backoff-Wiederholung; (4) Verwenden Sie für Batch-Aufgaben die Batch-API. Wenn Sie auf der APIYI-Plattform auf Drosselungsprobleme stoßen, können Sie den Kundendienst kontaktieren, um das RPM-Kontingent zu erhöhen.
Q5: Wie schätze ich die Gesamtkosten für Batch-Generierungen?
Verwenden Sie die Formel: Gesamtkosten = Anzahl der Bilder × Einzelpreis. Beispiel für die Generierung von 1000 1K-Bildern: Standardmodus 1000 × 0,067 $ = 67 $, Batch-Modus 1000 × 0,034 $ = 34 $. Die Preise auf APIYI apiyi.com entsprechen den offiziellen Preisen und unterstützen flexible Aufladungen, was ideal für eine bedarfsgerechte Nutzung ist.
Zusammenfassung: Die optimale Strategie für Nano Banana 2 API-Parallelität finden
Bei der Optimierung der Parallelität der Nano Banana 2 API geht es nicht darum, „was die Plattform erlaubt“, sondern „was deine Pipeline bewältigen kann“. Beachte diese 3 Kernpunkte:
- Auflösung ist entscheidend: Der Wechsel von 4K auf 1K steigert die Parallelität um das Zehnfache und senkt die Kosten um 56 %.
- Bandbreite ist der echte Flaschenhals: Durch die Base64-Kodierung ist jedes Bild 33 % größer als das Original; die Bandbreitenbelastung ist weitaus kritischer als die CPU-Auslastung.
- Schrittweise Optimierung: Beginne mit 5 parallelen Anfragen, überwache die Antwortzeiten sowie Fehlerraten und steigere den Wert schrittweise bis zum Optimum.
Wir empfehlen die Nutzung der Nano Banana 2 API über die Plattform APIYI (apiyi.com). Sie bietet unbegrenzte Parallelität, 1000 RPM pro Benutzer und identische Preise wie beim Anbieter, damit du dich voll auf die Performance deiner Pipeline konzentrieren kannst, ohne dir Gedanken über plattformseitige Einschränkungen machen zu müssen.

Referenzmaterialien
-
Gemini 3.1 Flash Image Preview: Modellspezifikationen und API-Dokumentation
- Link:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-image-preview
- Link:
-
Gemini Image Generation API: Leitfaden zur Verwendung der API für die Bilderzeugung
- Link:
ai.google.dev/gemini-api/docs/image-generation
- Link:
-
Gemini API Rate Limits: Offizielle Dokumentation zu Ratenbegrenzungen
- Link:
ai.google.dev/gemini-api/docs/rate-limits
- Link:
-
APIYI Nano Banana 2 Integrationsdokumentation: Erläuterung der einheitlichen API-Schnittstelle
- Link:
api.apiyi.com
- Link:
📝 Autor: APIYI Team | Das technische Team von APIYI ist auf den Bereich der KI-Bilderzeugungs-APIs spezialisiert und bietet Entwicklern über apiyi.com einen Nano Banana 2 API-Zugang mit unbegrenzter Parallelität und flexibler Abrechnung.