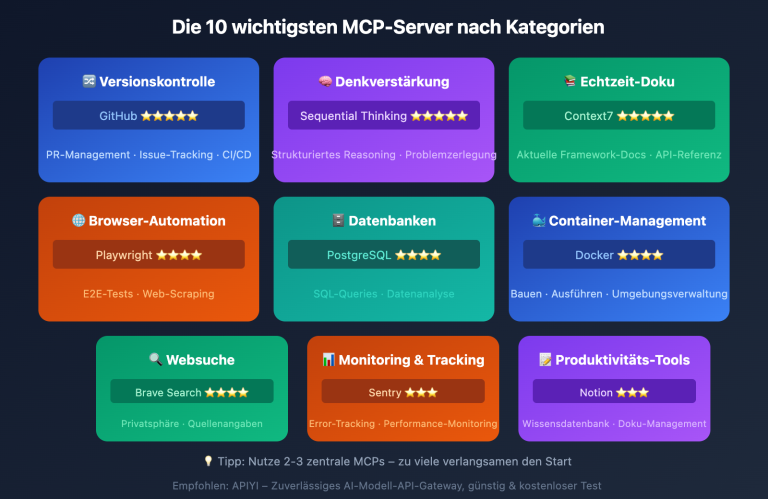
Im Jahr 2026 werden bereits 41 % aller Code-Commits durch KI unterstützt – doch die Fehlerquote von KI-generiertem Code liegt 1,7-mal höher als bei menschlichem Code. Während die Codegenerierung immer schneller wird, hinkt die Kapazität für Code-Reviews massiv hinterher; für 2026 wird eine Qualitätslücke von 40 % prognostiziert.
KI-gestützte Code-Reviews sind keine Frage des „Ob“, sondern des „Wie“. Dieser Artikel stellt 7 bewährte Best Practices vor und analysiert, warum Claude Opus 4.6 und Sonnet 4.6 derzeit die am besten geeigneten KI-Modelle für Code-Reviews sind.
Kernnutzen: Nach der Lektüre dieses Artikels beherrschen Sie den vollständigen Workflow für KI-Code-Reviews und wissen, wie Sie das optimale Modell auswählen, um die Codequalität Ihres Teams zu steigern.
Status quo der KI-Code-Überprüfung: Warum sie heute unverzichtbar ist
Herausforderungen bei der Code-Überprüfung im Jahr 2026
| Herausforderung | Daten | Auswirkungen |
|---|---|---|
| Anstieg von KI-Code | 41 % der Commits KI-unterstützt | Überprüfungsbedarf explodiert |
| Fehlerrate bei KI-Code | 1,7-mal höher als bei menschlichem Code | Strengere Prüfungen nötig |
| Qualitätslücke | 40 % Lücke für 2026 prognostiziert | Kapazität hinkt Generierung hinterher |
| Sicherheitsrisiken | 45 % des KI-Codes enthalten OWASP Top 10-Schwachstellen | Sicherheitsprüfungen sind kritisch |
| Akzeptanzrate | KI-Vorschläge nur 16,6 %, menschliche 56,5 % | KI-Qualität muss verbessert werden |
KI-Code-Überprüfung vs. menschliche Code-Überprüfung
KI ist nicht dazu da, menschliche Prüfer zu ersetzen, sondern deren Fähigkeiten zu erweitern. Teams, die KI-Code-Überprüfung einsetzen, berichten von:
- 40–60 % weniger Zeitaufwand für die Überprüfung
- Höhere Fehlererkennungsrate – insbesondere bei Sicherheitslücken und Randfällen
- Deutliche Verbesserung der Konsistenz des Programmierstils
KI-Überprüfungen haben jedoch klare Grenzen:
- ❌ Kein Verständnis für Geschäftsfristen und Projektkontext
- ❌ Keine Wahrnehmung historischer Kompromisse in Altsystemen
- ❌ Keine Übernahme der endgültigen Verantwortung
- ❌ Kein Mentoring oder Wissenstransfer im Team
🎯 Die beste Strategie: KI übernimmt den ersten Scan (Stil, Bugs, Sicherheit), der Mensch trifft die finale Entscheidung (Architektur, Absicht, Risiko). Über die Plattform APIYI (apiyi.com) können Sie die API von Claude Opus 4.6 oder Sonnet 4.6 nutzen, um KI-Code-Überprüfungen schnell in bestehende CI/CD-Prozesse zu integrieren.
7 Best Practices für die KI-Code-Überprüfung
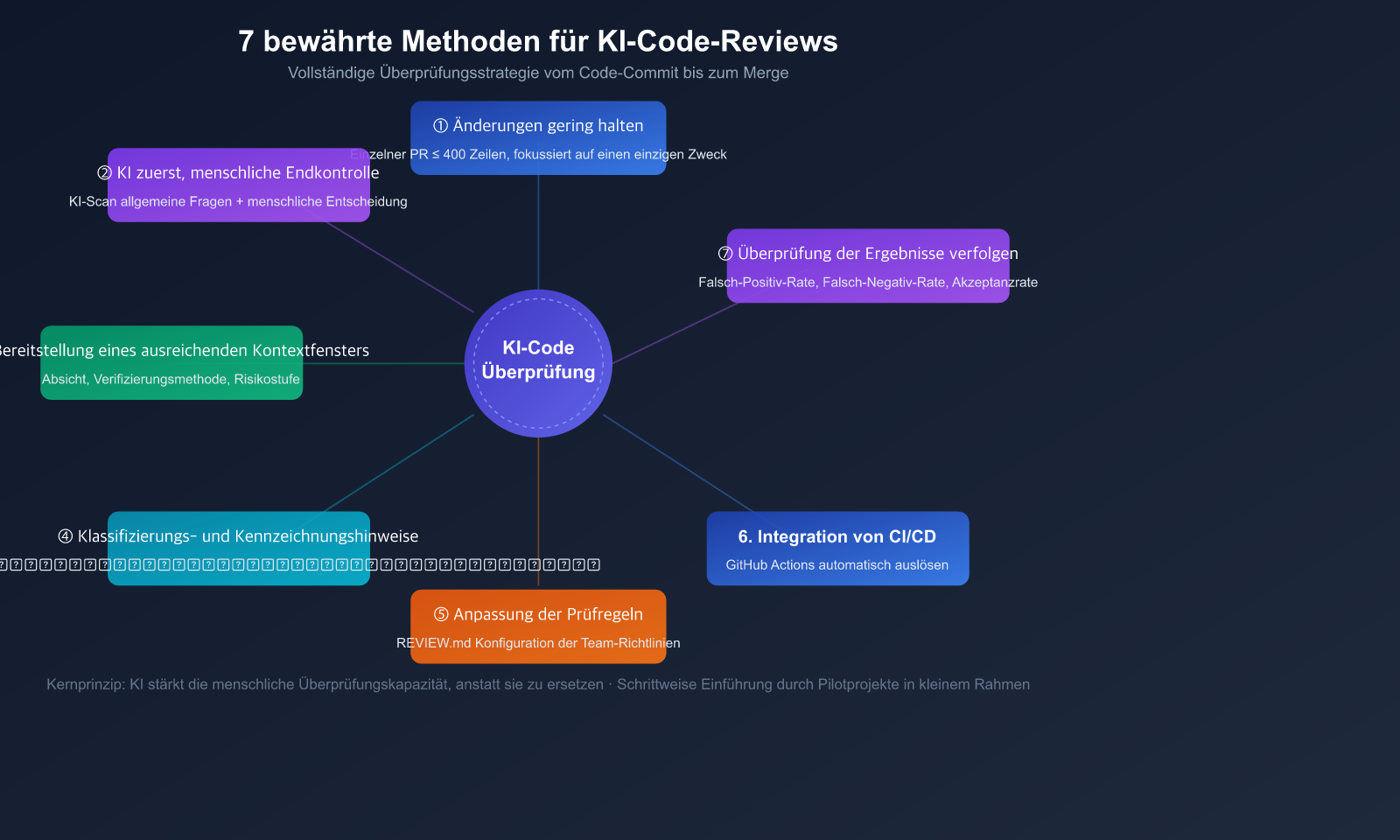
Praxis 1: Änderungen klein und fokussiert halten
KI-Prüfer verlieren bei Diffs von über 1000 Zeilen deutlich an Kohärenz. Auch wenn Claude Opus 4.6 über ein Kontextfenster von 1 Million Token verfügt, ist die Qualität der Überprüfung bei kleineren Änderungen höher.
Vorgehensweise:
- PRs auf 200–400 Zeilen begrenzen
- Große Refactorings in mehrere logisch unabhängige PRs aufteilen
- Jeder PR sollte nur eine Aufgabe erfüllen
Praxis 2: KI zuerst, Mensch als letzte Instanz
Der effektivste Workflow ist das "Zwei-Ebenen-Prüfmodell":
Code-Commit → KI-automatische Überprüfung (erster Durchgang)
↓
Probleme markieren + Schweregrad zuweisen
↓
Menschlicher Prüfer fokussiert auf Hochrisikobereiche (Endkontrolle)
↓
Merge oder Ablehnung
Die KI scannt alle Standardprobleme (Stil, Benennung, toter Code, einfache Bugs), während sich der Mensch auf Folgendes konzentriert:
- Architektur-Logik
- Korrektheit der Geschäftslogik
- Sicherheitskritische Entscheidungen
- Bewertung der Performance-Auswirkungen
Praxis 3: Ausreichend Kontext bereitstellen
Je mehr Informationen der KI-Prüfer erhält, desto höher ist die Qualität der Überprüfung. Es wird empfohlen, in der PR-Beschreibung Folgendes anzugeben:
# Kontext für die KI-Überprüfung
- Ziel des PR: [Kurze Beschreibung]
- Betroffene Module: [Liste]
- Besondere Risiken: [z.B. Datenbank-Migrationen, API-Änderungen]
Änderungsabsicht
Beschreiben Sie in 1-2 Sätzen, warum diese Änderung vorgenommen wurde.
Validierungsmethode
- Unit-Tests erfolgreich bestanden
- Manuelle Tests für das Szenario XX durchgeführt
- Keine Leistungseinbußen festgestellt
Risikostufe
Niedrig/Mittel/Hoch + Erläuterung
KI-Unterstützungserklärung
Ein Teil von XX in dieser Änderung wurde durch KI generiert; bitte führen Sie hier eine gründliche Überprüfung durch.
Fokusbereich
Bitte konzentrieren Sie sich besonders auf die Änderungen der Berechtigungslogik im Verzeichnis src/auth/.
### Praxis 4: Klassifizierung von Review-Kommentaren
Ein häufiges Problem bei KI-gestützten Reviews ist das "Grundrauschen" – wenn Stilvorschläge und kritische Bugs vermischt werden, was dazu führt, dass Entwickler wichtiges Feedback übersehen.
**Empfohlene Kennzeichnung der Schweregrade**:
| Kennzeichnung | Bedeutung | Vorgehensweise |
|------|------|----------|
| 🔴 **Bug** | Fehler, die vor dem Mergen behoben werden müssen | Blockiert den Merge |
| 🟡 **Nit** | Kleines Problem, das behoben werden sollte, aber nicht blockiert | Optionale Behebung |
| 🟣 **Pre-existing** | Altes Problem, nicht durch diesen PR eingeführt | Dokumentieren, aber nicht blockieren |
| 💡 **Suggestion** | Verbesserungsvorschlag | Entscheidung nach Diskussion |
Die native Code-Review-Funktion von Claude Code unterstützt dieses Klassifizierungssystem (Rot/Gelb/Lila) bereits.
### Praxis 5: Anpassung der Review-Regeln
Allgemeine KI-Reviews entsprechen oft nicht den spezifischen Team-Richtlinien. Passen Sie das Review-Verhalten über eine Konfigurationsdatei an:
```markdown
# REVIEW.md (im Projekt-Root-Verzeichnis)
## Pflichtprüfungen
- Alle Datenbankabfragen müssen parametrisierte Anweisungen verwenden
- API-Endpunkte müssen eine Authentifizierungs-Middleware enthalten
- Alle Benutzereingaben müssen validiert werden
Kann übersprungen werden
- Namenskonventionen für CSS-Klassen (bereits durch Prettier automatisch formatiert)
- Import-Sortierung (bereits durch Ruff automatisch verarbeitet)
- Kommentarsprache (Englisch oder Deutsch möglich)
Team-Konventionen
- Komposition vor Vererbung bevorzugen
- Fehlerbehandlung mittels Result-Pattern
- Protokollierungsebene: INFO für Geschäftsereignisse, DEBUG für die Fehlersuche
### Praxis 6: Integration in die CI/CD-Pipeline
KI-Code-Reviews sollten automatisiert und nicht manuell ausgelöst werden.
**Empfohlene Integrationsmethode**:
```yaml
# Beispiel für GitHub Actions
name: KI-Code-Review
on:
pull_request:
types: [opened, synchronize]
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
review_mode: "auto"
Alternativ können Sie das Claude-Modell für benutzerdefinierte Reviews direkt über die API aufrufen:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI einheitliche Schnittstelle
)
diff_content = open("pr_diff.patch").read()
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": """Du bist ein erfahrener Experte für Code-Reviews.
Analysiere die folgenden Code-Änderungen und klassifiziere sie nach Schweregrad:
- 🔴 Bug: Muss behoben werden
- 🟡 Nit: Empfohlene Korrektur
- 💡 Suggestion: Verbesserungsvorschlag
Gib für jedes Problem die genaue Zeilennummer und einen Lösungsvorschlag an."""},
{"role": "user", "content": f"Bitte überprüfe die folgenden Code-Änderungen:\n\n{diff_content}"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Praxis 7: Nachverfolgung der Review-Effektivität
KI-Code-Reviews sind kein "Einmal-Projekt". Es ist wichtig, wichtige Kennzahlen kontinuierlich zu verfolgen:
- Falsch-Positiv-Rate: Wie viele der von der KI markierten Probleme sind tatsächliche Fehler?
- Falsch-Negativ-Rate: Wie viele der nach dem Deployment entdeckten Bugs wurden von der KI übersehen?
- Akzeptanzrate: Welcher Anteil der KI-Vorschläge wird von den Entwicklern tatsächlich umgesetzt?
- Änderung der Review-Zeit: Hat sich die durchschnittliche Review-Zeit der menschlichen Prüfer verkürzt?
💡 Implementierungsempfehlung: Wenn Ihr Team gerade erst mit KI-Code-Reviews beginnt, empfiehlt es sich, mit PRs auf nicht kritischen Pfaden zu starten. Nutzen Sie APIYI (apiyi.com), um Claude Sonnet 4.6 für erste Tests aufzurufen – die Kosten betragen nur ein Fünftel von Opus, bei einer Review-Qualität, die fast an Opus heranreicht. Dies ist der kosteneffizienteste Einstieg.
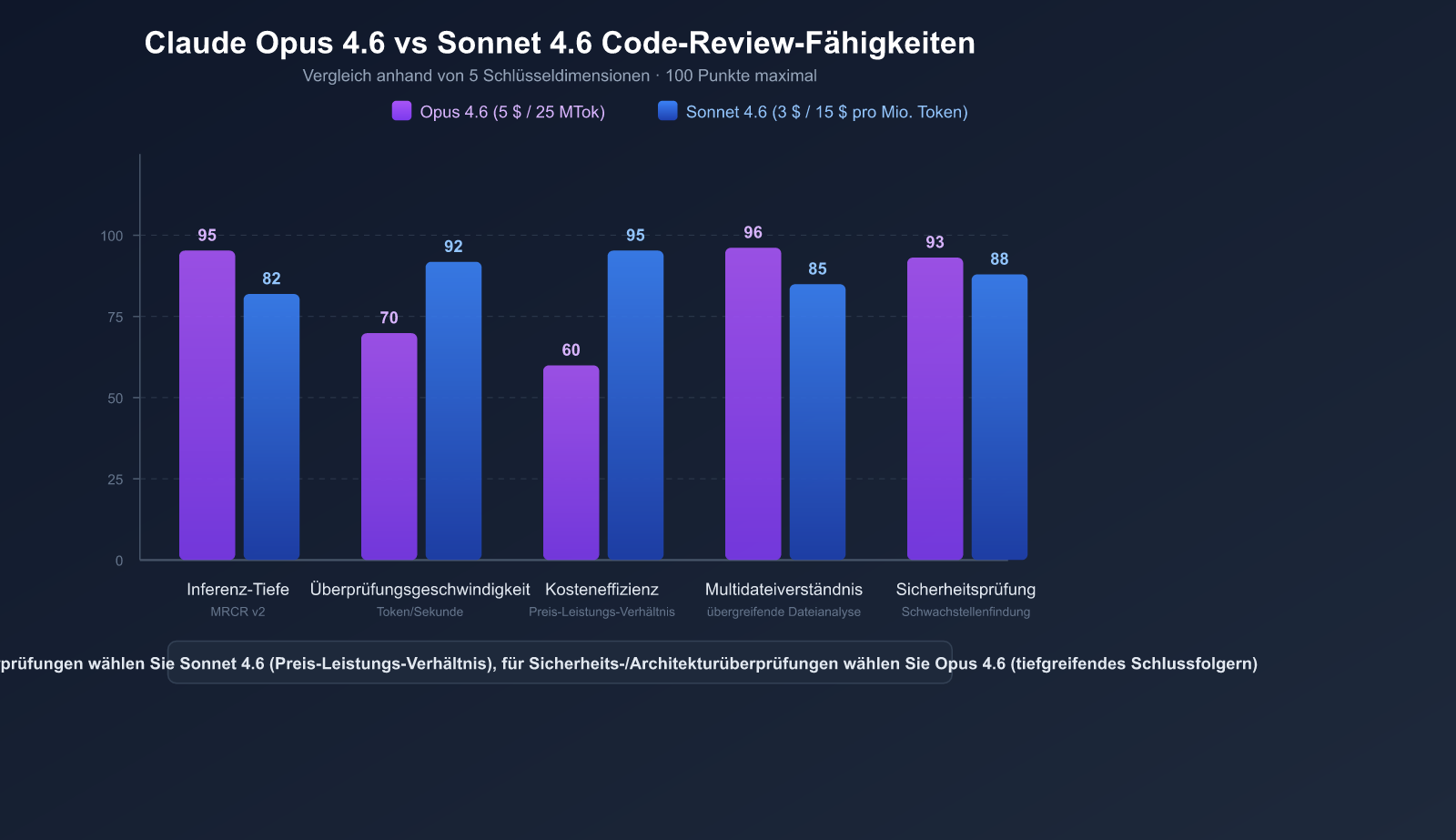
Warum Claude Opus 4.6 und Sonnet 4.6 für das Code-Review empfohlen werden
Unter der Vielzahl an KI-Modellen bietet die Claude 4.6-Serie bei Code-Reviews einzigartige Vorteile.
Vergleich der Kernparameter der Claude 4.6-Modelle
| Parameter | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| Modell-ID | claude-opus-4-6 |
claude-sonnet-4-6 |
| Veröffentlichungsdatum | 5. Februar 2026 | 17. Februar 2026 |
| Kontextfenster | 1 Mio. Token (Beta) | 1 Mio. Token (Beta) |
| Maximale Ausgabe | 128K Token | 64K Token |
| SWE-bench Verified | 81,42 % | 79,6 % |
| Preis (Eingabe/Ausgabe) | $5/$25 pro Mio. Token | $3/$15 pro Mio. Token |
| Einsatzszenarien | Komplexe Architektur-Reviews, Sicherheitsaudits | Tägliche PR-Reviews, Stilprüfungen |
| APIYI-Preis | Günstiger | Günstiger |
Vorteil 1: 1 Million Token Kontextfenster
Dies ist der entscheidende technische Vorteil bei Code-Reviews.
Ein PR in einem großen Projekt kann Dutzende von Dateien umfassen. Die Begrenzung des Kontextfensters herkömmlicher KI-Modelle zwingt Sie dazu, Code zu kürzen, wodurch dem Prüfer der vollständige Kontext fehlt.
Das 1-Million-Token-Kontextfenster von Claude 4.6 kann Folgendes gleichzeitig aufnehmen:
- Vollständige PR-Diffs (normalerweise Hunderte bis Tausende Zeilen)
- Den gesamten Code relevanter Dateien (Import-Ketten, aufgerufene Funktionen)
- Abhängigkeitsdiagramme und Typdefinitionen
- Testdateien und Konfigurationsdateien
- README- und Architektur-Dokumentation des Projekts
Dies bedeutet, dass die KI wie ein erfahrener Entwickler mit vollem Kontextverständnis prüfen kann.
Vorteil 2: Erstklassige übergreifende Schlussfolgerungsfähigkeit
Der größte Wert eines Code-Reviews liegt nicht im Finden von Syntaxfehlern, sondern im Aufdecken von logischen Problemen über Dateigrenzen hinweg.
Claude Opus 4.6 erzielte im MRCR v2-Test (Multi-Needle, Multi-File Retrieval Reasoning) 76 %, während Sonnet 4.5 nur 18,5 % erreichte. Das bedeutet, dass Opus 4.6 in folgenden Szenarien exzellent abschneidet:
- Erkennung, wenn Datei A eine Schnittstelle ändert, aber die Aufrufe in Datei B nicht entsprechend aktualisiert wurden
- Aufdecken fehlender Validierungen im gesamten Datenfluss vom Eingang bis zur Datenbank
- Identifizierung von Race Conditions in Nebenläufigkeitsszenarien
Echter Fall: In Tests entdeckte Claude Opus 4.6 in einem 2400 Zeilen umfassenden PR für eine Datenbankmigration eine Race Condition – einen Fehler in der Rollback-Logik, der nur bei einem Abbruch während der Migration ausgelöst wurde. Dies ist ein Szenario, das automatisierte Tests nicht abdecken können.
Vorteil 3: Adaptive Denktiefe
Claude 4.6 führt den adaptive thinking-Modus ein – die KI entscheidet je nach Komplexität des Problems automatisch, wie "tief" sie nachdenken muss.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI einheitliche Schnittstelle
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": "Überprüfe diese Codeänderung auf Sicherheitsprobleme."},
{"role": "user", "content": diff_content}
],
# Claude 4.6 adaptives Denken: Einfache Probleme schnell lösen, komplexe tiefgehend analysieren
extra_body={"thinking": {"type": "adaptive"}}
)
- Bei einfachen Stilfragen → schnelle Entscheidung, spart Token
- Bei komplexen Nebenläufigkeits- oder Sicherheitsproblemen → tiefgehende Schlussfolgerung, detaillierte Analyse
Vorteil 4: Sicherheitslücken-Erkennung weit über herkömmlichen Tools
Studien zeigen, dass LLMs auf Claude-Niveau bei Sicherheits-Code-Reviews deutlich besser abschneiden als herkömmliche statische Analysetools:
| Vergleichsdimension | Claude (LLM) | CodeQL (herkömmliches SAST) |
|---|---|---|
| Erkannte Schwachstellen | 55 | 27 |
| Entdeckung unbekannter Lücken | 4 Zero-Day-Lücken | 0 |
| Erkennungskategorien | 10+ (Injection, Auth, Datenleck, Krypto, Logikfehler etc.) | Basiert auf Mustervergleich |
| Sprachunterstützung | Jede Programmiersprache | Spezifische Sprachen |
| Fehlalarm-Filterung | KI-automatisiert | Manuelle Filterung erforderlich |
Sicherheitslückentypen, die Claude erkennen kann:
- SQL/Command/LDAP/XPath/NoSQL-Injection
- Authentifizierungs- und Autorisierungsfehler
- Hartkodierte Schlüssel, sensible Protokolldaten
- Schwache Verschlüsselungsalgorithmen, unsachgemäßes Schlüsselmanagement
- Race Conditions (TOCTOU)
- Unsichere Standardkonfigurationen, CORS
- Deserialisierungs-RCE, Pickle/Eval-Injection
- XSS (Reflektiert, gespeichert, DOM-basiert)
Vorteil 5: Kostenflexibilität
Die Preisgestaltung von Sonnet 4.6 liegt bei nur 1/5 von Opus 4.6, liegt aber bei SWE-bench nur 1-2 Prozentpunkte dahinter.
Empfohlene Auswahlstrategie:
| Szenario | Empfohlenes Modell | Grund |
|---|---|---|
| Tägliches PR-Review | Sonnet 4.6 | Bestes Preis-Leistungs-Verhältnis, Qualität nahe an Opus |
| Sicherheitskritischer Code | Opus 4.6 | Tiefste Schlussfolgerung, keine Übersehung kritischer Probleme |
| Große Refactoring-Reviews | Opus 4.6 | Stärkste übergreifende Schlussfolgerungsfähigkeit |
| Stil- und Normprüfung | Sonnet 4.6 | Einfache Aufgaben benötigen kein Opus |
| CI/CD automatisches Review | Sonnet 4.6 | Kostenkontrolliert, geeignet für jeden Commit |
🚀 Auswahl-Tipp: Die offizielle Empfehlung von Anthropic lautet: "Standardmäßig Sonnet 4.6 verwenden und nur bei Bedarf für tiefste Schlussfolgerungen auf Opus 4.6 upgraden". In internen Tests von Claude Code war die Präferenz der Entwickler für Sonnet 4.6 um 70 % höher als bei der vorherigen Generation Sonnet 4.5 und sogar 59 % höher als beim früheren Flaggschiff Opus 4.5. Über APIYI apiyi.com können Sie beide Modelle zu günstigeren Preisen aufrufen.
Vollständiger KI-Code-Review-Workflow
Workflow-Übersicht
Entwickler reicht PR ein
↓
KI-gestützte automatisierte Überprüfung (Sonnet 4.6)
↓
┌─── Geringes Risiko ──→ KI markiert als Nit, automatische Freigabe
│
├─── Mittleres Risiko ──→ KI markiert Probleme, manuelle Schnellprüfung
│
└─── Hohes Risiko ──→ Eskalation zu Opus 4.6 für Tiefenprüfung
↓
Manuelle Endabnahme durch Sicherheitsexperten
↓
Merge oder Ablehnung
Code-Beispiel: Aufbau eines benutzerdefinierten KI-Review-Systems
import openai
import subprocess
client = openai.OpenAI(
api_key="DEIN_API_SCHLUESSEL",
base_url="https://api.apiyi.com/v1" # APIYI einheitliche Schnittstelle
)
def get_pr_diff(pr_number):
"""Ruft den Diff-Inhalt des PR ab"""
result = subprocess.run(
["gh", "pr", "diff", str(pr_number)],
capture_output=True, text=True
)
return result.stdout
def review_code(diff, risk_level="medium"):
"""Wählt das Modell basierend auf dem Risikolevel für die Überprüfung aus"""
model = "claude-opus-4-6" if risk_level == "high" else "claude-sonnet-4-6"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Überprüfe die folgenden Änderungen:\n\n{diff}"}
],
max_tokens=8192
)
return response.choices[0].message.content
# Anwendungsbeispiel
diff = get_pr_diff(123)
review = review_code(diff, risk_level="high")
print(review)
Vollständige Review-Eingabeaufforderung (Prompt) anzeigen
REVIEW_PROMPT = """Du bist ein erfahrener Senior Software Engineer und führst ein Code-Review durch.
## Review-Schwerpunkte
1. **Logische Korrektheit**: Implementiert der Code die erwartete Funktionalität? Gibt es übersehene Randbedingungen?
2. **Sicherheit**: Bestehen Sicherheitsrisiken wie Injektionen, XSS, CSRF, hartcodierte Schlüssel usw.?
3. **Performance**: Gibt es N+1-Abfragen, unnötige Speicherzuweisungen oder blockierende Operationen?
4. **Wartbarkeit**: Sind die Benennungen klar? Ist die Komplexität kontrollierbar? Gibt es doppelten Code?
5. **Fehlerbehandlung**: Werden Ausnahmen korrekt abgefangen und verarbeitet?
6. **Nebenläufigkeit**: Bestehen Risiken für Race Conditions oder Deadlocks?
## Ausgabeformat
Ausgabe sortiert nach Schweregrad:
### 🔴 Muss behoben werden (Bug/Sicherheit)
- [Dateiname:Zeilennummer] Problembeschreibung
- Auswirkung: ...
- Empfohlene Korrektur: ...
### 🟡 Empfohlene Korrektur (Nit)
- [Dateiname:Zeilennummer] Problembeschreibung
- Empfehlung: ...
### 💡 Verbesserungsvorschlag (Suggestion)
- [Dateiname:Zeilennummer] Verbesserungspunkt
- Erläuterung: ...
Sollte die Codequalität gut sein und keine Probleme gefunden werden, geben Sie bitte explizit an: "Prüfung bestanden, keine Probleme gefunden".
Erfinden Sie keine Probleme, nur um eine Ausgabe zu erzwingen.
💰 Kostenoptimierung: Nutzen Sie APIYI (apiyi.com), um das Claude 4.6-Modell für Code-Reviews aufzurufen – das ist günstiger als beim offiziellen Anbieter. Die Plattform unterstützt den flexiblen Wechsel zwischen Opus 4.6 und Sonnet 4.6, sodass je nach Risikostufe des PR automatisch das kosteneffizienteste Modell gewählt werden kann.
Grenzen und Hinweise für KI-Code-Reviews
5 Grenzen, die Sie kennen müssen
- Recall-Rate von ca. 50 %: Die von LLMs gefundenen Schwachstellen sind meist real (Präzision ~80 %), jedoch wird etwa die Hälfte der tatsächlich vorhandenen Fehler übersehen.
- Risiko von Prompt-Injection: KI-Review-Tools sind anfällig für Injections, wenn sie PRs aus nicht vertrauenswürdigen Quellen verarbeiten.
- Kontext-Blindheit: Die KI kann den geschäftlichen Hintergrund, die Fähigkeiten des Teams und historische Entscheidungen nicht nachvollziehen.
- Kostenakkumulation: Bei häufigen Commits können die Kosten für eine automatisierte Prüfung bei hochfrequenten Repositories schnell steigen.
- Risiko der Überabhängigkeit: Teammitglieder könnten mit der Zeit bei der manuellen Prüfung nachlässiger werden.
Strategien zur Risikominimierung
| Grenze | Vermeidungsstrategie |
|---|---|
| Hohe Fehlerrate | KI-Review + manuelle Prüfung als doppelte Absicherung |
| Prompt-Injection | Nur PRs aus vertrauenswürdigen Quellen prüfen |
| Mangelnder Kontext | Projektkontext in einer REVIEW.md bereitstellen |
| Hohe Kosten | Täglich Sonnet 4.6 nutzen, für kritische Pfade Opus 4.6 |
| Überabhängigkeit | Etablierung eines Systems aus "KI-Vorschlag + menschlicher Entscheidung" |
Häufig gestellte Fragen
Q1: Kann eine KI-Code-Überprüfung die menschliche Überprüfung vollständig ersetzen?
Nein. Die KI-Code-Überprüfung ist eine „Ergänzung“ und kein „Ersatz“. KI ist hervorragend darin, musterbasierte Probleme (Stil, häufige Bugs, bekannte Schwachstellenmuster) zu finden, kann jedoch keine Geschäftsabsichten, Abwägungen bei Architekturentscheidungen oder implizites Wissen aus der Teamzusammenarbeit verstehen. Die bewährte Methode ist: Die KI führt den ersten Scan durch, der Mensch trifft die endgültige Entscheidung. Durch den Modellaufruf von Claude 4.6 über APIYI (apiyi.com) können Sie schnell einen KI-Überprüfungsprozess aufbauen, der es menschlichen Prüfern ermöglicht, sich auf wertvollere Aufgaben zu konzentrieren.
Q2: Sollte ich für die Code-Überprüfung Opus 4.6 oder Sonnet 4.6 wählen?
In den meisten Szenarien ist Sonnet 4.6 die richtige Wahl. Auf dem SWE-bench liegt es nur 1-2 Prozentpunkte hinter Opus, kostet aber nur ein Fünftel. Nur bei der Überprüfung von sicherheitskritischem Code, großen Architektur-Refactorings oder wenn tiefgreifende dateiübergreifende Schlussfolgerungen erforderlich sind, ist ein Upgrade auf Opus 4.6 sinnvoll. Über APIYI (apiyi.com) können Sie flexibel und bedarfsgerecht zwischen beiden Modellen wechseln.
Q3: Wie hoch sind die Kosten für eine KI-Code-Überprüfung in etwa?
Die native Überprüfungsfunktion von Claude Code kostet durchschnittlich 15-25 $ pro Durchlauf, abhängig von der Größe des PRs und der Komplexität der Codebasis. Wenn Sie ein eigenes Überprüfungssystem über eine API aufbauen, hängen die Kosten vom Token-Verbrauch ab. Am Beispiel von Sonnet 4.6 kostet die Überprüfung eines 500-Zeilen-PRs (ca. 2000 Token Eingabe + 1000 Token Ausgabe) etwa 0,02 $. Über APIYI (apiyi.com) profitieren Sie zudem von noch günstigeren Preisen.
Q4: Wie lässt sich die Effektivität der KI-Code-Überprüfung bewerten?
Es empfiehlt sich, vier Kernindikatoren zu verfolgen: (1) Falsch-Positiv-Rate – der Anteil der von der KI markierten Probleme, die tatsächlich Fehler sind; (2) Fehlerrate – der Anteil der nach der Veröffentlichung entdeckten Bugs, die von der KI nicht markiert wurden; (3) Akzeptanzrate – der Anteil der KI-Vorschläge, die von Entwicklern tatsächlich übernommen wurden; (4) Veränderung der Überprüfungszeit – ob sich die durchschnittliche Zeit für menschliche Prüfer verkürzt hat. In den ersten zwei Monaten empfiehlt sich eine wöchentliche Überprüfung.
Q5: Wie fange ich schnell mit der KI-Code-Überprüfung an?
Der einfachste Weg besteht aus drei Schritten: (1) Registrieren Sie sich bei APIYI (apiyi.com), um einen API-Schlüssel zu erhalten; (2) Führen Sie mit Sonnet 4.6 einen ersten Überprüfungstest für einen kürzlich erstellten PR durch; (3) Entscheiden Sie basierend auf den Ergebnissen, ob Sie eine CI/CD-Automatisierung anbinden möchten. Beginnen Sie mit Pilotprojekten für weniger kritischen Code und weiten Sie dies schrittweise auf den gesamten Bereich aus.
Fazit: KI-Code-Überprüfung ist ein Multiplikator für die Team-Effizienz
Die KI-Code-Überprüfung ist keine Option, sondern eine unverzichtbare Fähigkeit für Softwareentwicklungsteams im Jahr 2026. Claude Opus 4.6 und Sonnet 4.6 sind mit einem Kontextfenster von 1 Million Token, über 81 % SWE-bench-Score, adaptivem Denken und leistungsstarken Sicherheitsprüfungsfunktionen die derzeit beste Wahl für Code-Überprüfungen.
Empfehlung zur Modellauswahl:
- Tägliche Überprüfung: Standardmäßig Sonnet 4.6, der Preis-Leistungs-Sieger.
- Sicherheits-/Architekturüberprüfung: Upgrade auf Opus 4.6 für kompromisslose Tiefe bei der Analyse.
Wir empfehlen die schnelle Anbindung der gesamten Claude 4.6-Modellreihe über APIYI (apiyi.com), um für Ihr Team kosteneffizient KI-gestützte Code-Überprüfungskapazitäten aufzubauen.
Referenzen
-
Anthropic offiziell: Ankündigung der Veröffentlichung von Claude Opus 4.6 und Sonnet 4.6
- Link:
anthropic.com/news
- Link:
-
Claude Code Code-Review-Dokumentation: Leitfaden zur Nutzung der nativen Review-Funktionen
- Link:
code.claude.com/docs/en/code-review
- Link:
-
Claude Code Security Review: Open-Source-Sicherheitsüberprüfung via GitHub Action
- Link:
github.com/anthropics/claude-code-security-review
- Link:
-
Best Practices für KI-Code-Reviews 2026: Umfassende Branchenanalyse
- Link:
verdent.ai/guides
- Link:
-
IRIS-Forschungsarbeit: LLM-gestützte statische Analyse zur Schwachstellenerkennung
- Link:
arxiv.org
- Link:
Autor: APIYI-Team | Wir erforschen Best Practices für KI-gestützte Softwareentwicklung. Besuchen Sie APIYI unter apiyi.com für API-Schnittstellen und technischen Support für die gesamte Claude 4.6-Modellreihe.