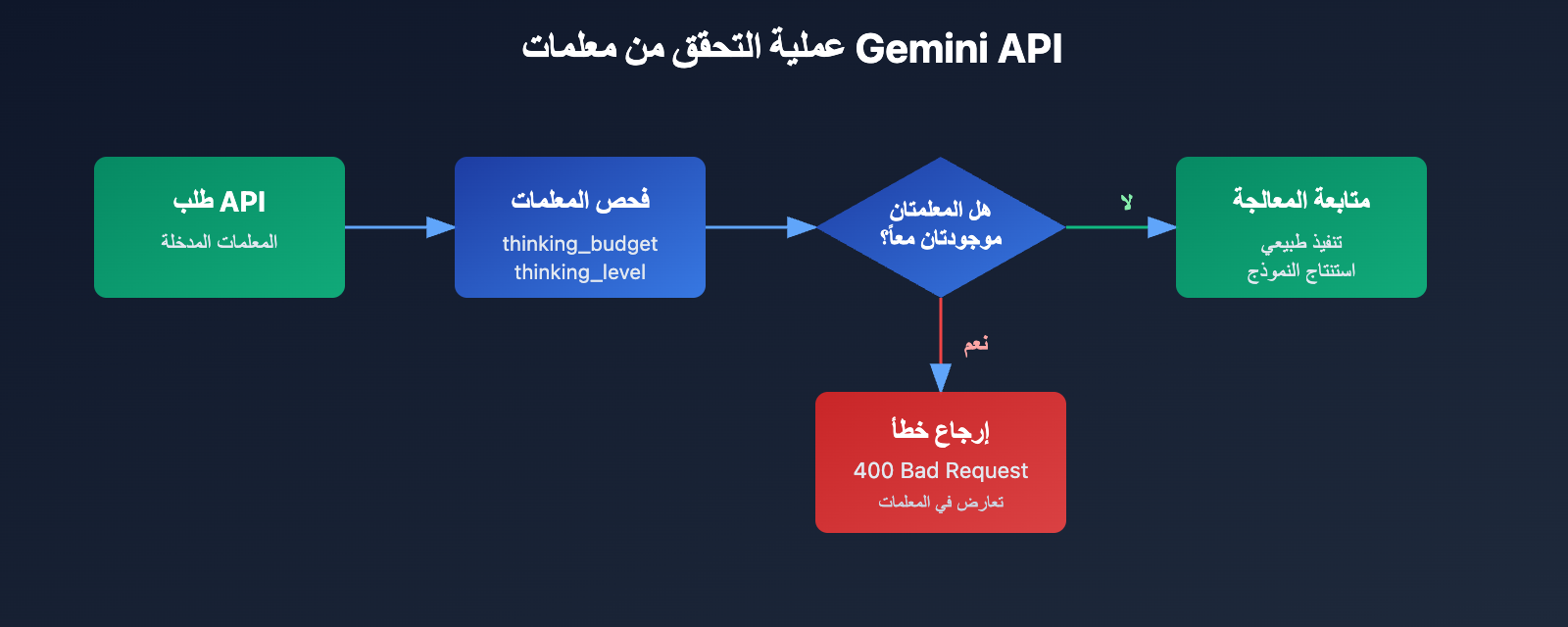
هل تواجه خطأ thinking_budget and thinking_level are not supported together عند استدعاء نماذج Gemini 3.0 Pro Preview أو gemini-3-flash-preview؟ هذه مشكلة توافق ناتجة عن ترقية المعلمات (parameters) بين إصدارات النماذج المختلفة في Google Gemini API. في هذا المقال، سنحلل بشكل منهجي السبب الجذري لهذا الخطأ وطريقة التكوين الصحيحة من منظور تطور تصميم واجهة البرمجة (API).
القيمة المحورية: بعد قراءة هذا المقال، ستتقن الطريقة الصحيحة لتكوين معلمات نمط التفكير لنماذج Gemini 2.5 و 3.0، مما يساعدك على تجنب أخطاء استدعاء API الشائعة، وتحسين أداء استدلال النموذج والتحكم في التكاليف.

النقاط الجوهرية لتطور معلمات نمط التفكير في Gemini API
| إصدار النموذج | المعلمة الموصى بها | نوع المعلمة | مثال على التكوين | سيناريو الاستخدام |
|---|---|---|---|---|
| Gemini 2.5 Flash/Flash-Lite | thinking_budget |
عدد صحيح أو -1 | thinking_budget: 0 (تعطيل)thinking_budget: -1 (ديناميكي) |
تحكم دقيق في ميزانية توكنات التفكير |
| Gemini 3.0 Pro/Flash | thinking_level |
قيمة تعداد (Enum) | thinking_level: "minimal"/"low"/"medium"/"high" |
تبسيط التكوين حسب مستويات المشهد |
| ملاحظة التوافق | ⚠️ لا يمكن استخدامهما معاً | – | إرسال المعلمتين معاً سيؤدي لخطأ 400 | اختر أحدهما بناءً على إصدار النموذج |
الفروق الجوهرية في معلمات نمط تفكير Gemini
السبب الرئيسي لإدخال Google لمعلمة thinking_level في Gemini 3.0 هو تبسيط تجربة التكوين للمطورين. تتطلب معلمة thinking_budget في Gemini 2.5 من المطورين تقدير عدد توكنات التفكير بدقة، بينما تقوم معلمة thinking_level في Gemini 3.0 بتجريد هذا التعقيد إلى 4 مستويات دلالية، مما يقلل من صعوبة الإعداد.
يعكس هذا التغيير في التصميم المفاضلة التي أجرتها Google في تطور API الخاص بها: التضحية بجزء من قدرة التحكم الدقيق مقابل سهولة استخدام أفضل واتساق عبر النماذج المختلفة. بالنسبة لمعظم سيناريوهات التطبيق، يعد تجريد thinking_level كافياً، ولا يلزم استخدام thinking_budget إلا عند الحاجة إلى تحسين التكاليف بشكل أقصى أو التحكم في ميزانية توكنات محددة.
💡 نصيحة تقنية: في عملية التطوير الفعلية، نوصي بإجراء اختبارات استدعاء الواجهة من خلال منصة APIYI (apiyi.com). توفر هذه المنصة واجهة برمجة تطبيقات موحدة تدعم نماذج Gemini 2.5 Flash، Gemini 3.0 Pro، Gemini 3.0 Flash وغيرها، مما يساعد في التحقق بسرعة من التأثيرات الفعلية واختلافات التكلفة لإعدادات أنماط التفكير المختلفة.
السبب الجذري للخطأ: استراتيجية التوافق الأمامي في تصميم المعلمات
تحليل رسالة خطأ API
{
"status_code": 400,
"error": {
"message": "Unable to submit request because thinking_budget and thinking_level are not supported together.",
"type": "upstream_error",
"code": 400
}
}
المعلومة الأساسية في هذا الخطأ هي أن thinking_budget و thinking_level لا يمكن أن يتواجدا معاً في نفس الوقت. عند تقديم معلمات جديدة في Gemini 3.0، لم تقم Google بإلغاء المعلمات القديمة تماماً، بل اعتمدت استراتيجية الاستبعاد المتبادل:
- نموذج Gemini 2.5: يقبل فقط
thinking_budgetويتجاهلthinking_level. - نموذج Gemini 3.0: يعطي الأولوية لـ
thinking_levelمع قبولthinking_budgetللحفاظ على التوافق مع الإصدارات السابقة، ولكن لا يسمح بإرسال كليهما معاً. - شرط حدوث الخطأ: احتواء طلب API على معملتي
thinking_budgetوthinking_levelفي نفس الوقت.
لماذا يحدث هذا الخطأ؟
غالباً ما يواجه المطورون هذا الخطأ في الحالات الثلاث التالية:
| السيناريو | السبب | سمات الكود النموذجية |
|---|---|---|
| السيناريو 1: الملء التلقائي بواسطة SDK | تقوم بعض أطر عمل الذكاء الاصطناعي (مثل LiteLLM أو AG2) بملء المعلمات تلقائياً بناءً على اسم النموذج، مما يؤدي لإرسال المعلمتين معاً | استخدام SDK جاهز دون فحص جسم الطلب الفعلي |
| السيناريو 2: التكوين المبرمج يدوياً | تم برمجة thinking_budget يدوياً في الكود، ولم يتم تحديث اسم المعلمة عند التبديل إلى نموذج Gemini 3.0 |
وجود تعيين لقيم المعلمتين معاً في ملف التكوين أو الكود |
| السيناريو 3: سوء تقدير الاسم المستعار للنموذج | استخدام أسماء مستعارة مثل gemini-flash-preview تشير في الواقع إلى Gemini 3.0، ولكن مع استخدام إعدادات Gemini 2.5 |
اسم النموذج يحتوي على preview أو latest دون تحديث إعدادات المعلمات بشكل متزامن |
🎯 نصيحة للاختيار: عند تبديل إصدارات نموذج Gemini، نوصي أولاً باختبار توافق المعلمات عبر منصة APIYI (apiyi.com). تدعم هذه المنصة التبديل السريع بين سلسلة نماذج Gemini 2.5 و 3.0، مما يسهل مقارنة جودة الاستجابة واختلافات التأخير في تكوينات وضع التفكير المختلفة، لتجنب مواجهة تعارض المعلمات في بيئة التشغيل الفعلية.
3 حلول: اختيار المعلمات الصحيحة بناءً على إصدار النموذج
الحل 1: تكوين نموذج Gemini 2.5 (استخدام thinking_budget)
النماذج المطبقة: gemini-2.5-flash ، gemini-2.5-pro وغيرهما.
شرح المعلمات:
thinking_budget: 0– تعطيل وضع التفكير تماماً، لتقليل التأخير والتكلفة.thinking_budget: -1– وضع التفكير الديناميكي، حيث يقوم النموذج بضبطه تلقائياً بناءً على تعقيد الطلب.thinking_budget: <عدد صحيح موجب>– تحديد الحد الأقصى لعدد رموز (tokens) التفكير بدقة.
مثال بسيط
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "اشرح مبدأ التشابك الكمي"}],
extra_body={
"thinking_budget": -1 # وضع التفكير الديناميكي
}
)
print(response.choices[0].message.content)
عرض الكود الكامل (يتضمن استخراج محتوى التفكير)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "اشرح مبدأ التشابك الكمي"}],
extra_body={
"thinking_budget": -1, # وضع التفكير الديناميكي
"include_thoughts": True # تمكين إرجاع ملخص التفكير
}
)
# استخراج محتوى التفكير (إذا تم تمكينه)
for part in response.choices[0].message.content:
if hasattr(part, 'thought') and part.thought:
print(f"عملية التفكير: {part.text}")
# استخراج الإجابة النهائية
final_answer = response.choices[0].message.content
print(f"الإجابة النهائية: {final_answer}")
نصيحة: سيتم إيقاف نماذج Gemini 2.5 في 3 مارس 2026، لذا نوصي بالانتقال إلى سلسلة Gemini 3.0 في أقرب وقت ممكن. يمكنك مقارنة جودة الاستجابة قبل وبعد الانتقال بسرعة عبر منصة APIYI (apiyi.com).
الحل 2: تكوين نموذج Gemini 3.0 (استخدام thinking_level)
النماذج المطبقة: gemini-3.0-flash-preview ، gemini-3.0-pro-preview.
شرح المعلمات:
thinking_level: "minimal"– تفكير أدنى، قريب من ميزانية صفرية، يتطلب تمرير تواقيع التفكير (Thought Signatures).thinking_level: "low"– تفكير منخفض الكثافة، مناسب لاتباع التعليمات البسيطة وسيناريوهات الدردشة.thinking_level: "medium"– تفكير متوسط الكثافة، مناسب لمهام الاستنتاج العامة (يدعمه Gemini 3.0 Flash فقط).thinking_level: "high"– تفكير عالي الكثافة، لزيادة عمق الاستنتاج، مناسب للمشكلات المعقدة (القيمة الافتراضية).
مثال بسيط
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "حلل التعقيد الزمني لهذا الكود"}],
extra_body={
"thinking_level": "medium" # تفكير متوسط الكثافة
}
)
print(response.choices[0].message.content)
عرض الكود الكامل (يتضمن تمرير تواقيع التفكير)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# الجولة الأولى من الحوار
response_1 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "صمم خوارزمية تخزين مؤقت LRU"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# استخراج تواقيع التفكير (يعيدها Gemini 3.0 تلقائياً)
thought_signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
thought_signatures.append(part.thought_signature)
# الجولة الثانية من الحوار، تمرير تواقيع التفكير للحفاظ على سلسلة الاستنتاج
response_2 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[
{"role": "user", "content": "صمم خوارزمية تخزين مؤقت LRU"},
{"role": "assistant", "content": response_1.choices[0].message.content, "thought_signatures": thought_signatures},
{"role": "user", "content": "قم بتحسين التعقيد المكاني لهذه الخوارزمية"}
],
extra_body={
"thinking_level": "high"
}
)
print(response_2.choices[0].message.content)
💰 تحسين التكلفة: للمشاريع الحساسة للميزانية، يمكنك التفكير في استخدام Gemini 3.0 Flash API عبر منصة APIYI (apiyi.com)، حيث توفر المنصة طرق فوترة مرنة وأسعاراً أكثر تنافسية، مناسبة للفرق الصغيرة والمتوسطة والمطورين الأفراد. استخدام
thinking_level: "low"يمكن أن يقلل التكاليف بشكل أكبر.
الحل 3: استراتيجية تكييف المعلمات للتبديل الديناميكي بين النماذج
السيناريو المطبق: الحاجة إلى دعم نماذج Gemini 2.5 و 3.0 معاً في نفس الكود.
وظيفة ذكية لتكييف المعلمات
def get_thinking_config(model_name: str, complexity: str = "medium") -> dict:
"""
اختيار معلمة وضع التفكير الصحيحة تلقائياً بناءً على إصدار النموذج
Args:
model_name: اسم نموذج Gemini
complexity: تعقيد التفكير ("minimal", "low", "medium", "high", "dynamic")
Returns:
قاموس المعلمات المناسب لـ extra_body
"""
# قائمة نماذج Gemini 3.0
gemini_3_models = [
"gemini-3.0-flash-preview",
"gemini-3.0-pro-preview",
"gemini-3-flash",
"gemini-3-pro"
]
# قائمة نماذج Gemini 2.5
gemini_2_5_models = [
"gemini-2.5-flash-preview-04-17",
"gemini-2.5-flash-lite",
"gemini-2-flash",
"gemini-2-flash-lite"
]
# تحديد إصدار النموذج
if any(m in model_name for m in gemini_3_models):
# Gemini 3.0 يستخدم thinking_level
level_map = {
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high" # الافتراضي عالي الكثافة
}
return {"thinking_level": level_map.get(complexity, "medium")}
elif any(m in model_name for m in gemini_2_5_models):
# Gemini 2.5 يستخدم thinking_budget
budget_map = {
"minimal": 0,
"low": 512,
"medium": 2048,
"high": 8192,
"dynamic": -1
}
return {"thinking_budget": budget_map.get(complexity, -1)}
else:
# نموذج غير معروف، استخدام معلمات Gemini 3.0 افتراضياً
return {"thinking_level": "medium"}
# مثال على الاستخدام
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
model = "gemini-3.0-flash-preview" # يمكن التبديل ديناميكياً
thinking_config = get_thinking_config(model, complexity="high")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "سؤالك هنا"}],
extra_body=thinking_config
)

| تعقيد التفكير | Gemini 2.5 (thinking_budget) | Gemini 3.0 (thinking_level) | السيناريو الموصى به |
|---|---|---|---|
| أدنى | 0 |
"minimal" |
اتباع التعليمات البسيطة، التطبيقات ذات الإنتاجية العالية |
| منخفض | 512 |
"low" |
روبوتات الدردشة، الأسئلة والأجوبة الخفيفة |
| متوسط | 2048 |
"medium" |
مهام الاستنتاج العامة، توليد الأكواد |
| عالي | 8192 |
"high" |
حل المشكلات المعقدة، التحليل العميق |
| ديناميكي | -1 |
"high" (افتراضي) |
التكيف التلقائي مع التعقيد |
🚀 ابدأ بسرعة: نوصي باستخدام منصة APIYI (apiyi.com) لبناء النماذج الأولية بسرعة. توفر المنصة واجهة Gemini API جاهزة للاستخدام دون الحاجة لتكوينات معقدة، ويمكن إتمام التكامل في 5 دقائق، مع دعم التبديل بنقرة واحدة بين معلمات وضع التفكير المختلفة لمقارنة النتائج.
شرح مفصل لآلية توقيعات التفكير (Thought Signatures) في جيميناي 3.0
ما هي توقيعات التفكير؟
تُعد توقيعات التفكير (Thought Signatures) التي قدمها جيميناي 3.0 تمثيلاً مشفراً لعملية الاستدلال الداخلي للنموذج. عند تفعيل خيار include_thoughts: true في الإعدادات، سيقوم النموذج بإرجاع توقيع مشفر لعملية التفكير ضمن الاستجابة. يمكنك لاحقاً تمرير هذه التوقيعات في الحوارات التالية لضمان الحفاظ على استمرارية وترابط سلسلة الاستدلال لدى النموذج.
الخصائص الأساسية:
- تمثيل مشفر: محتوى التوقيع غير قابل للقراءة البشرية، ولا يمكن فكه وتحليله إلا بواسطة النموذج نفسه.
- الحفاظ على سلسلة الاستدلال: من خلال تمرير التوقيعات في المحادثات متعددة الجولات، يستطيع النموذج مواصلة الاستدلال بناءً على أفكاره وخطواته السابقة.
- إرجاع تلقائي: يقوم جيميناي 3.0 بإرجاع توقيعات التفكير بشكل افتراضي، حتى لو لم يتم طلبها صراحةً.
سيناريوهات التطبيق العملي لتوقيعات التفكير
| السيناريو | هل يلزم تمرير التوقيع؟ | الوصف |
|---|---|---|
| سؤال وجواب من جولة واحدة | ❌ لا حاجة | سؤال مستقل بذاته، لا يتطلب الحفاظ على سلسلة استدلال. |
| حوار متعدد الجولات (بسيط) | ❌ لا حاجة | السياق العادي كافٍ، ولا توجد تبعات معقدة للاستدلال. |
| حوار متعدد الجولات (استدلال معقد) | ✅ نعم | مثل: إعادة هيكلة الكود، البراهين الرياضية، أو التحليلات متعددة الخطوات. |
| وضع التفكير الأدنى (minimal) | ✅ إلزامي | يتطلب مستوى thinking_level: "minimal" تمرير التوقيع، وإلا سيتم إرجاع خطأ 400. |
نموذج كود لتمرير توقيعات التفكير
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# الجولة الأولى: الطلب من النموذج تصميم خوارزمية
response_1 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[{"role": "user", "content": "صمم خوارزمية لتحديد معدل الطلبات الموزع (distributed rate limiting)"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# استخراج توقيعات التفكير
signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
signatures.append(part.thought_signature)
# الجولة الثانية: مواصلة التحسين بناءً على الاستدلال السابق
response_2 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[
{"role": "user", "content": "صمم خوارزمية لتحديد معدل الطلبات الموزع"},
{
"role": "assistant",
"content": response_1.choices[0].message.content,
"thought_signatures": signatures # تمرير توقيعات التفكير
},
{"role": "user", "content": "كيف يمكننا التعامل مع مشكلة عدم تزامن الساعات في النظام الموزع؟"}
],
extra_body={"thinking_level": "high"}
)
💡 أفضل ممارسة: في السيناريوهات التي تتطلب استدلالاً معقداً عبر عدة جولات (مثل تصميم الأنظمة، تحسين الخوارزميات، أو مراجعة الأكواد)، يُنصح باختبار الفرق في جودة النتائج عند تمرير توقيعات التفكير عبر منصة APIYI. تدعم المنصة آلية توقيعات التفكير في جيميناي 3.0 بشكل كامل، مما يسهل التحقق من جودة الاستدلال تحت إعدادات مختلفة.
الأسئلة الشائعة
س1: لماذا يستمر Gemini 2.5 Flash في إرجاع محتوى التفكير حتى بعد ضبط thinking_budget=0؟
هذا خطأ برمجبي (Bug) معروف في إصدار Gemini 2.5 Flash Preview 04-17، حيث لا يتم تنفيذ thinking_budget=0 بشكل صحيح. وقد أكدت غوغل هذا المشكلة في منتدياتها الرسمية.
الحلول المؤقتة:
- استخدم
thinking_budget=1(قيمة ضئيلة جداً) بدلاً من 0. - الترقية إلى Gemini 3.0 Flash واستخدام
thinking_level="minimal". - تصفية محتوى التفكير يدوياً في مرحلة ما بعد المعالجة (إذا كان الـ API يُرجع حقل thought).
نوصي بالانتقال السريع إلى نموذج Gemini 3.0 Flash عبر منصة APIYI، حيث تدعم المنصة أحدث الإصدارات التي تتفادى مثل هذه الأخطاء.
س2: كيف أعرف ما إذا كنت أستخدم نموذج Gemini 2.5 أم 3.0؟
الطريقة 1: التحقق من اسم النموذج
- إصدارات 2.x: تحتوي الأسماء عادةً على
2.5-flashأو2-flash-lite. - إصدارات 3.x: تحتوي الأسماء على
3.0-flashأو3-proأوgemini-3-flash.
الطريقة 2: إرسال طلب اختبار
# مرر معلمة thinking_level فقط وراقب الاستجابة
response = client.chat.completions.create(
model="your-model-name",
messages=[{"role": "user", "content": "test"}],
extra_body={"thinking_level": "low"}
)
# إذا تلقيت خطأ 400 يشير إلى أن thinking_level غير مدعوم، فأنت تستخدم Gemini 2.5
الطريقة 3: فحص رؤوس استجابة الـ API (Headers)
بعض واجهات الـ API تُرجع حقل X-Model-Version في الرأس، مما يسمح بالتعرف المباشر على إصدار النموذج.
س3: كم يستهلك كل مستوى من thinking_level في جيميناي 3.0 من الـ tokens؟
لم تكشف غوغل رسمياً عن ميزانية الـ tokens الدقيقة لكل مستوى من thinking_level بشكل محدد، لكنها قدمت التوجيهات التالية:
| مستوى التفكير (thinking_level) | التكلفة النسبية | التأخير النسبي | عمق الاستدلال |
|---|---|---|---|
| minimal | الأقل | الأقل | شبه منعدم |
| low | منخفضة | منخفض | استدلال سطحي |
| medium | متوسطة | متوسط | استدلال متوسط |
| high | عالية | عالٍ | استدلال عميق |
نصائح عملية:
- قارن الاستهلاك الفعلي للـ tokens بين المستويات المختلفة عبر منصة APIYI.
- استخدم نفس الـ موجه (prompt) لاستدعاء مستويات low/medium/high وراقب الفروق في الفواتير.
- اختر المستوى المناسب بناءً على احتياجات عملك (الجودة مقابل التكلفة).
س4: هل يمكن إجبار جيميناي 3.0 على استخدام thinking_budget؟
نعم، ولكن لا يُنصح بذلك.
من أجل التوافق مع الإصدارات السابقة، لا يزال جيميناي 3.0 يقبل معلمة thinking_budget؛ إلا أن الوثائق الرسمية تنص بوضوح على:
"على الرغم من قبول
thinking_budgetللتوافق مع الإصدارات السابقة، فإن استخدامه مع Gemini 3 Pro قد يؤدي إلى أداء غير مثالي."
الأسباب:
- تم تحسين آليات الاستدلال الداخلي في جيميناي 3.0 لتعمل مع
thinking_level. - قد يؤدي الإجبار على استخدام
thinking_budgetإلى تجاوز استراتيجيات الاستدلال الجديدة. - قد يتسبب ذلك في انخفاض جودة الاستجابة أو زيادة وقت التأخير.
الإجراء الصحيح:
- الانتقال إلى استخدام معلمة
thinking_level. - الاعتماد على وظائف تكييف المعلمات (Parameter adaptation) لاختيار المعلمة الصحيحة ديناميكياً بناءً على إصدار النموذج.
الخلاصة
النقاط الأساسية حول أخطاء thinking_budget و thinking_level في واجهة برمجة تطبيقات Gemini (Gemini API):
- تعارض المعلمات: يستخدم Gemini 2.5 المعلمة
thinking_budgetبينما يستخدم Gemini 3.0 المعلمةthinking_level؛ لذا لا يمكن إرسالهما معًا في نفس الطلب. - تحديد النموذج: يتم تحديد الإصدار بناءً على اسم النموذج؛ حيث تُستخدم
thinking_budgetمع سلسلة 2.5، وتُستخدمthinking_levelمع سلسلة 3.0. - التكيف الديناميكي: يُفضل استخدام دالة لتكييف المعلمات تقوم باختيار المعلمة الصحيحة تلقائيًا بناءً على اسم النموذج، وذلك لتجنب مشاكل "الترميز الثابت" (Hardcoding).
- توقيع التفكير: قدم Gemini 3.0 آلية "توقيع التفكير" (Thinking Signature)، والتي يجب تمريرها في سيناريوهات الاستدلال المعقدة متعددة الجولات للحفاظ على استمرارية سلسلة التفكير.
- توصية الانتقال: سيتم إحالة Gemini 2.5 إلى التقاعد في 3 مارس 2026، لذا نوصي بالانتقال إلى سلسلة 3.0 في أقرب وقت ممكن.
نوصي باستخدام منصة APIYI (apiyi.com) للتحقق بسرعة من التأثير الفعلي لتكوينات أوضاع التفكير المختلفة. تدعم المنصة سلسلة نماذج Gemini بالكامل، وتوفر واجهة موحدة وطرق محاسبة مرنة، مما يجعلها مثالية لاختبارات المقارنة السريعة ونشر المشاريع في بيئة الإنتاج.
المؤلف: الفريق التقني لـ APIYI | إذا كانت لديك أي أسئلة تقنية، يسعدنا تواصلك معنا عبر APIYI (apiyi.com) للحصول على المزيد من حلول الربط مع نماذج الذكاء الاصطناعي (نموذج لغة كبير).