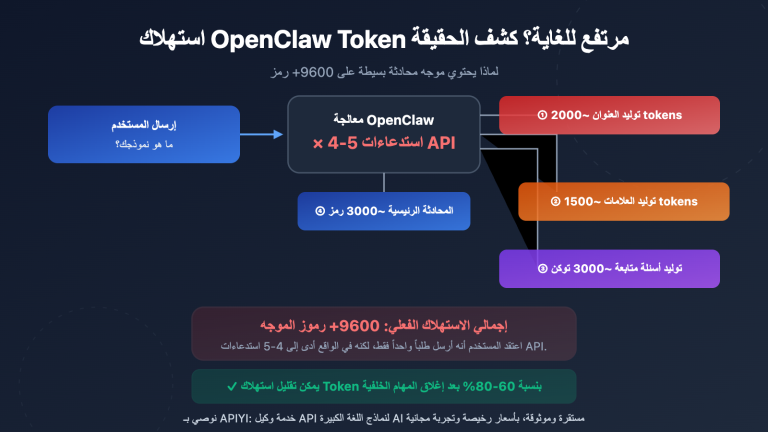
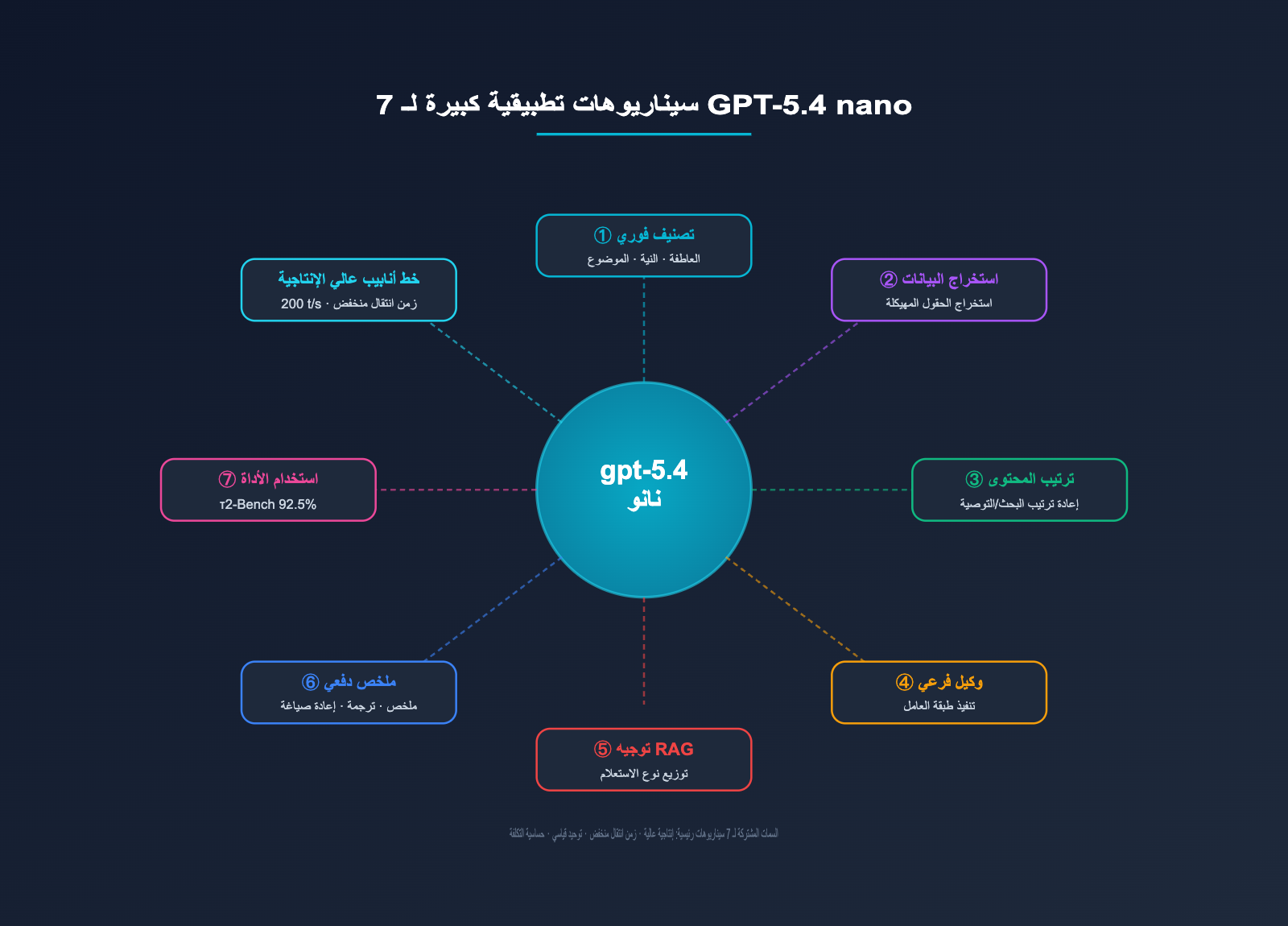
ملاحظة من الكاتب: يُعد نموذج gpt-5.4-nano من OpenAI هو الأرخص على الإطلاق بتكلفة 0.20 دولار/1.25 دولار فقط، حيث حقق 92.5% في اختبار τ2-Bench ليقترب من أداء نسخة mini. يستعرض هذا المقال 7 سيناريوهات مثالية لاستخدام nano، ومتى يجب عليك الانتقال إلى mini، بالإضافة إلى استراتيجية التحسين القصوى التي توفر 90% من التكاليف عبر التخزين المؤقت.
إذا كان تطبيقك يتجاوز 10 آلاف استدعاء يومياً، أو إذا كنت تبحث عن نموذج لمهام ذات إنتاجية عالية مثل خدمة العملاء، التصنيف، أو توجيه RAG، فقد لاحظت بالتأكيد أن OpenAI قد خفضت "السعر الأساسي" لسلسلة GPT-5.4 إلى مستوى جديد: gpt-5.4-nano، بسعر 0.20 دولار للمدخلات / 1.25 دولار للمخرجات لكل مليون رمز (tokens)، وهو أرخص بـ 3.75 مرة من 5.4-mini في المدخلات.
هذا ليس مجرد "نموذج رخيص ومحدود". تُظهر اختبارات الأداء التي نشرتها OpenAI أن نموذج nano حقق 92.5% في استدعاء الأدوات (τ2-Bench)، وهو ما يقارب أداء mini البالغ 93.4%؛ وفي اختبار الإجابة على الأسئلة المعرفية العامة (GPQA Diamond) حصل على 82.8%، بفارق 5.2 نقطة مئوية فقط عن mini. هذا يعني أنه بالنسبة للعديد من سيناريوهات "الإنتاجية العالية + التعقيد المنخفض"، فإن nano هو الخيار الأمثل حقاً.
القيمة الجوهرية: يتناول هذا المقال 7 سيناريوهات تطبيقية محددة، ويوضح بالتفصيل المهام التي يكون فيها nano "كافياً وأرخص"، والمهام التي "يجب فيها استخدام mini"، مع تقديم مقتطفات برمجية وحسابات التكلفة لكل سيناريو.

النقاط الجوهرية لسيناريوهات تطبيق GPT-5.4 nano
| النقطة | الشرح | القيمة |
|---|---|---|
| سعر زهيد جداً | 0.20 دولار / 1.25 دولار لكل مليون رمز | أرخص بـ 3.75 مرة من 5.4-mini |
| تخزين مؤقت -90% | تكلفة المدخلات المخزنة 0.02 دولار فقط | مجاني تقريباً لسيناريوهات السياق المتكرر |
| استدعاء الأدوات يقارب mini | τ2-Bench 92.5% مقابل 93.4% لـ mini | كافٍ لمعظم مهام استدعاء الأدوات |
| قوي في الأسئلة المعرفية | GPQA Diamond 82.8% | مناسب لخدمات الأسئلة الشائعة والبحث المعرفي |
| نافذة سياق 400 ألف | 400 ألف للمدخلات + 128 ألف للمخرجات | معالجة دفعات المستندات الطويلة بسهولة |
| سرعة رائدة | ~200 رمز/ثانية، أسرع من mini بـ 10% | الخيار الأول لخطوط الإنتاج عالية الكثافة |
كيف تحدد "عتبة الكفاية" لنموذج GPT-5.4 nano؟
يمكنك تحديد ما إذا كان nano كافياً باستخدام "طريقة التصنيف الثلاثي" البسيطة:
المنطقة الخضراء (استخدم nano بثقة): استدعاء الأدوات، استخراج البيانات المهيكلة، التصنيف والوسم، الإجابة على الأسئلة المعرفية، توجيه المحتوى، الترجمة/التلخيص بالدفعات — في هذه المهام يكون الفارق في الأداء بين nano وmini أقل من 10 نقاط مئوية، وتتفوق ميزة السعر على فارق القدرات.
المنطقة الصفراء (قيّم بحذر): الاستنتاج المعقد متعدد الخطوات، تنسيق الوكيل (Agent) طويل السلسلة، توليد الأكواد — لا يزال نموذج nano قادراً على تحقيق 52.4% في اختبار SWE-Bench Pro، ولكن يُنصح بإجراء اختبار AB قبل اتخاذ القرار.
المنطقة الحمراء (استخدم mini مباشرة): استخدام الحاسوب (Computer Use) (حيث حقق nano 39% فقط في OSWorld)، المهام الطويلة في الطرفية (Terminal) (أداء ضعيف بنسبة 46.3%)، السيناريوهات المخصصة التي تتطلب ضبطاً دقيقاً (Fine-tuning) — في هذه الحالات، لا يواكب nano الأداء المطلوب، لذا اختر mini أو الإصدار القياسي مباشرة.
سيناريو تطبيق GPT-5.4 nano الأول: التصنيف الفوري
وصف السيناريو
يُعد التصنيف الفوري (Real-time Classification) التطبيق الأكثر كلاسيكية لنموذج nano، ويشمل ذلك تحليل المشاعر، التعرف على النوايا، تصنيف المواضيع، ووسم محتوى المراجعة. تتطلب هذه المهام عادةً بضع مئات من الرموز (tokens) للإدخال وبضع عشرات للإخراج في كل استدعاء، وهي حساسة للغاية تجاه التأخير والتكلفة.
مثال برمجي مبسط
import openai
import json
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def classify_intent(user_query: str) -> dict:
"""تصنيف نية استعلام المستخدم"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": "أنت مصنف للنوايا. أرجع النتيجة بتنسيق JSON: {intent, confidence, sub_category}"},
{"role": "user", "content": user_query}
],
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
# الاستخدام
result = classify_intent("أريد إلغاء طلبي من الأسبوع الماضي")
# {"intent": "refund_request", "confidence": 0.95, "sub_category": "subscription_cancel"}
تقدير التكلفة
| حجم السيناريو | التكلفة لكل استدعاء | التكلفة اليومية (100 ألف استدعاء) |
|---|---|---|
| خدمة عملاء مبتدئة(50 إدخال + 20 إخراج) | $0.000035 | $3.5 |
| SaaS متوسطة(200 إدخال + 30 إخراج) | $0.000078 | $7.8 |
| مستوى المؤسسات(500 إدخال + 50 إخراج) | $0.000163 | $16.3 |
💡 نصيحة للتحسين: ضع تصنيفات التصنيف والأمثلة في موجه النظام (system prompt)، وبعد تفعيل التخزين المؤقت (Caching) يمكن خفض تكلفة الإدخال بنسبة 90% إضافية. عند الاستدعاء عبر خدمة وكيل APIYI (apiyi.com)، يتم مزامنة خصومات التخزين المؤقت بالكامل.
سيناريو تطبيق GPT-5.4 nano الثاني: استخراج البيانات
وصف السيناريو
استخراج حقول منظمة من نصوص غير منظمة (سير ذاتية، عقود، أخبار، رسائل بريد إلكتروني). هذه نقطة قوة نموذج nano، حيث يمكنه تحقيق دقة تنسيق تزيد عن 99% عند استخدامه مع المخرجات المنظمة (Structured Outputs) بفضل القيود الصارمة لمخطط JSON.
كود عملي
from pydantic import BaseModel
from typing import Optional
class ContactInfo(BaseModel):
name: str
email: Optional[str]
phone: Optional[str]
company: Optional[str]
role: Optional[str]
def extract_contact(text: str) -> ContactInfo:
response = client.beta.chat.completions.parse(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": "استخرج معلومات جهة الاتصال، وأرجع null للحقول المفقودة"},
{"role": "user", "content": text}
],
response_format=ContactInfo
)
return response.choices[0].message.parsed
قائمة مهام الاستخراج المناسبة لـ nano
- استخراج الحقول الرئيسية من السير الذاتية (CV).
- التعرف على الأرقام في الفواتير والإيصالات.
- تحليل كتل التوقيع في البريد الإلكتروني.
- التعرف على الكيانات في الأخبار (أسماء الأشخاص، الأماكن، المؤسسات).
- توحيد بيانات النماذج.
- تصنيف أحداث السجلات (Logs).
سيناريو التطبيق الثالث لـ GPT-5.4 nano: ترتيب المحتوى
وصف السيناريو
إعادة ترتيب نتائج البحث، وقوائم التوصيات، وقوائم انتظار الرسائل. بفضل التكلفة المنخفضة لنموذج nano، أصبح استخدام "نموذج لغة كبير كأداة إعادة ترتيب" (reranker) أمراً مجدياً اقتصادياً في بيئات الإنتاج.
مثال على كود إعادة الترتيب
def rerank_documents(query: str, candidates: list[str], top_k: int = 5) -> list:
"""إعادة ترتيب المستندات المرشحة بناءً على مدى صلتها بالاستعلام"""
docs_text = "\n".join([f"[{i}] {doc[:300]}" for i, doc in enumerate(candidates)])
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[{
"role": "user",
"content": f"""بناءً على الاستعلام "{query}"، قم بترتيب المستندات التالية حسب الأهمية.
المستندات:
{docs_text}
أرجع النتيجة بصيغة JSON: {{"ranking": [قائمة فهارس المستندات، من الأكثر صلة إلى الأقل صلة]}}"""
}],
response_format={"type": "json_object"}
)
ranking = json.loads(response.choices[0].message.content)["ranking"]
return [candidates[i] for i in ranking[:top_k]]
🎯 نصيحة للسيناريو: تتميز إعادة الترتيب باستخدام nano بدقة أعلى من أدوات إعادة الترتيب التقليدية التي تعتمد على BM25 + البحث المتجهي، بينما تبلغ تكلفتها 27% فقط من تكلفة GPT-5.4-mini. يمكنك الوصول إليها مباشرة عبر APIYI (apiyi.com)، حيث تتوفر في المجموعة الافتراضية (Default) دون الحاجة لأي طلبات إضافية.
سيناريو التطبيق الرابع لـ GPT-5.4 nano: طبقة تنفيذ الوكلاء الفرعيين (Sub-agent)
وصف السيناريو
في بنية الوكلاء المتعددين (Multi-Agent)، يتولى الوكيل الرئيسي (الذي يستخدم عادةً إصدار mini أو الإصدار القياسي) مهام التخطيط، بينما يتولى الوكيل الفرعي (عامل التنفيذ) استدعاء الأدوات المحددة، والاستعلام عن البيانات، وتحديث الحالة. إن حصول nano على 92.5% في اختبار τ2-Bench يجعله مؤهلاً تماماً للقيام بدور "عامل التنفيذ".
مثال على تعاون الوكلاء المتعددين
def execute_subtask(task: dict, available_tools: list) -> dict:
"""استخدام nano كوكيل فرعي لتنفيذ مهمة جزئية"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": f"أنت عامل تنفيذ. الأدوات المتاحة: {available_tools}"},
{"role": "user", "content": f"تنفيذ المهمة: {task['description']}"}
],
tools=task.get("tools", []),
tool_choice="auto"
)
return {
"task_id": task["id"],
"result": response.choices[0].message.content,
"tool_calls": response.choices[0].message.tool_calls
}
# استخدام mini للوكيل الرئيسي و nano للوكيل الفرعي — يوفر أكثر من 60% من التكلفة
سيناريو تطبيق GPT-5.4 nano الخامس: طبقة توجيه RAG
وصف السيناريو
في أنظمة RAG، يعمل نموذج nano كـ "طبقة توجيه" لتحديد نوع الاستعلام (سؤال تقني / استشارة ما قبل البيع / ملاحظات حول المنتج / دردشة عامة)، ثم يقوم بتوجيهه إلى المعالج المناسب. يتيح هذا التصميم استدعاء نماذج mini أو النماذج القياسية الأكثر تكلفة فقط عند الحاجة الفعلية لذلك.
مثال على توجيه RAG
def route_query(query: str) -> str:
"""يقوم nano بتحديد مسار الاستعلام إلى معالج RAG المناسب"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": """قم بإرجاع وسم التوجيه بناءً على نوع الاستعلام:
- "technical_docs": استعلام عن وثائق تقنية
- "product_faq": الأسئلة الشائعة حول المنتج
- "code_help": مساعدة برمجية
- "small_talk": دردشة عامة (لا تتطلب RAG)
- "complex_reasoning": استنتاج معقد (يتم تحويله إلى نموذج mini/قياسي)"""},
{"role": "user", "content": query}
],
max_tokens=20
)
return response.choices[0].message.content.strip()
route = route_query(user_input)
if route == "complex_reasoning":
final_model = "gpt-5.4-mini" # الترقية إلى mini
else:
final_model = "gpt-5.4-nano" # الاستمرار باستخدام nano
💰 تحسين التكلفة: تتيح بنية "توجيه nano + معالجة mini/قياسية" تقليل تكاليف الاستدعاء الإجمالية بنسبة تتراوح بين 60% إلى 80%. يمكنك التبديل بمرونة بين النموذجين باستخدام نفس مفتاح API عبر خدمة APIYI (apiyi.com)، فقط من خلال تعديل معامل النموذج (model).
سيناريو تطبيق GPT-5.4 nano السادس: التلخيص والترجمة ذات الإنتاجية العالية
وصف السيناريو
معالجة المهام المجمعة مثل تلخيص الأخبار، ترجمة المستندات، وإعادة صياغة التعليقات. بفضل نافذة السياق التي تصل إلى 400 ألف رمز، يمكن لنموذج nano معالجة مستند طويل بالكامل في المرة الواحدة، مع تكلفة تكاد لا تذكر لكل عملية.
مثال على Batch API
# تجهيز المهام المجمعة
batch_requests = []
for doc_id, content in documents.items():
batch_requests.append({
"custom_id": f"summary-{doc_id}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-5.4-nano",
"messages": [
{"role": "system", "content": "لخص المحتوى التالي في 100 كلمة"},
{"role": "user", "content": content}
],
"max_tokens": 200
}
})
# إرسال Batch API (بنفس السعر ولكن لا يستهلك حصة الاستدعاء المباشر)
batch = client.batches.create(
input_file_id=file_id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
سيناريو تطبيق GPT-5.4 nano السابع: استدعاء الأدوات (Tool Use)
وصف السيناريو
حقق نموذج nano نسبة 92.5% في اختبار τ2-Bench، وهو ما يقارب أداء نموذج mini الذي حقق 93.4%. بالنسبة لسيناريوهات استدعاء الوظائف (function calling) القياسية مثل "الاستعلام عن الطقس، أو حالة الطلبات، أو البحث في المستندات"، فإن نموذج nano قادر تماماً على إنجاز هذه المهام بكفاءة.
مثال على استدعاء الوظائف (Function Calling)
tools = [{
"type": "function",
"function": {
"name": "get_order_status",
"description": "الاستعلام عن حالة الطلب",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string"}
},
"required": ["order_id"]
}
}
}]
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[{"role": "user", "content": "ما هي حالة طلبي رقم #12345؟"}],
tools=tools,
tool_choice="auto"
)
# نجح nano في تحديد الحاجة لاستدعاء get_order_status بدقة، واستخراج order_id="12345"
تفاصيل أسعار GPT-5.4 nano
هيكل الأسعار الرسمي
| نوع المحاسبة | السعر (لكل مليون رمز) | ملاحظات |
|---|---|---|
| الإدخال | $0.20 | السعر القياسي |
| الإدخال المخزن مؤقتاً | $0.02 | خصم 90% |
| المخرجات | $1.25 | تشمل رموز الاستنتاج (reasoning tokens) |
| Batch API | $0.20 / $1.25 | نفس السعر، لا يستهلك حصة الاستخدام المباشر |
| توطين البيانات الإقليمي | +10% | لسيناريوهات الامتثال للبيانات |
مقارنة الأسعار بين nano و mini
| البعد | gpt-5.4-nano | gpt-5.4-mini | المضاعف |
|---|---|---|---|
| الإدخال | $0.20 | $0.75 | nano أرخص بـ 3.75 مرة |
| الإدخال المخزن مؤقتاً | $0.02 | $0.075 | nano أرخص بـ 3.75 مرة |
| المخرجات | $1.25 | $4.50 | nano أرخص بـ 3.6 مرة |
| سرعة الاستجابة | ~200 رمز/ثانية | ~180 رمز/ثانية | nano أسرع بنحو 10% |
| نافذة السياق | 400 ألف | 400 ألف | متساويان |
| الحد الأقصى للمخرجات | 128 ألف | 128 ألف | متساويان |
💰 تحسين التكلفة: بالنسبة لسيناريوهات الاستخدام الكثيف التي تتجاوز ملايين الطلبات يومياً، يمكن أن يصل فرق السعر بين nano و mini إلى آلاف الدولارات شهرياً. من خلال الوصول عبر خدمة APIYI (apiyi.com)، يمكنك الاستفادة من عرض شحن 100 دولار والحصول على 10% إضافية، مما يعادل خصماً بنسبة 15% عن السعر الرسمي، لتصل التكلفة الإجمالية إلى أقل من السعر الرسمي بنسبة تصل إلى 25%.
مقارنة شاملة بين GPT-5.4 nano و mini
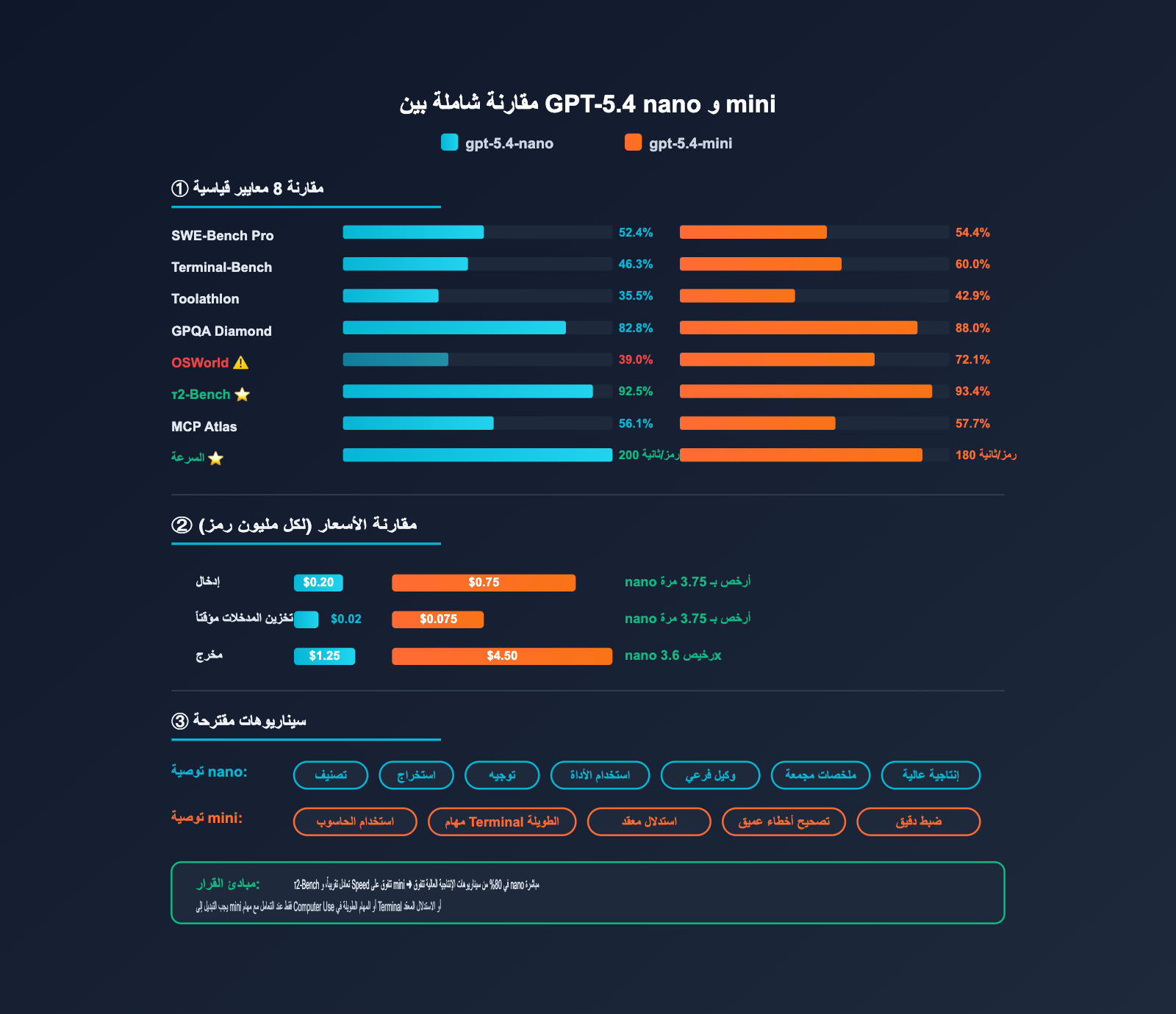
| بُعد التقييم | gpt-5.4-nano | gpt-5.4-mini | الفارق | هل nano كافٍ؟ |
|---|---|---|---|---|
| SWE-Bench Pro | 52.4% | 54.4% | -2.0pp | ✅ متقارب جداً |
| Terminal-Bench 2.0 | 46.3% | 60.0% | -13.7pp | ⚠️ استخدم mini للمهام الطويلة |
| Toolathlon | 35.5% | 42.9% | -7.4pp | ✅ كافٍ للمهام العامة |
| GPQA Diamond | 82.8% | 88.0% | -5.2pp | ✅ كفء في الأسئلة المعرفية |
| OSWorld-Verified | 39.0% | 72.1% | -33.1pp | ❌ يجب استخدام mini لـ Computer Use |
| τ2-Bench(Tool Use) | 92.5% | 93.4% | -0.9pp | ✅ متقارب جداً |
| MCP Atlas | 56.1% | 57.7% | -1.6pp | ✅ متقارب جداً |
| سرعة الاستجابة | ~200 t/s | ~180 t/s | +10% | ✅ nano أسرع |
نصائح لاختيار النموذج
يفضل استخدام nano في الحالات التالية:
- المهام التي تقع في "النطاق الأخضر" (التصنيف، الاستخراج، الترتيب، التوجيه، استخدام الأدوات، المعالجة المجمعة).
- حجم الاستدعاءات > 10,000 مرة/يوم، مع حساسية تجاه التكلفة.
- الحاجة إلى استجابة بزمن انتقال منخفض < 1 ثانية.
- طبقة تنفيذ الوكلاء الفرعية (الوكيل الرئيسي يستخدم mini، والوكلاء المساعدون يستخدمون nano).
يفضل الترقية إلى mini في الحالات التالية:
- المهام التي تتضمن Computer Use (فارق حاسم في OSWorld).
- المهام الطويلة في الطرفية (أكثر من 10 خطوات).
- الحاجة إلى استدلال معقد متعدد الخطوات أو تصحيح عميق للكود.
- عندما تكون جودة المهمة أهم من التكلفة.
📊 نصيحة للمفاضلة: في 80% من سيناريوهات "الإنتاجية العالية + التعقيد المنخفض"، يتفوق nano على mini من حيث القيمة مقابل السعر. يمكنك مقارنة أداء النموذجين مباشرة في مهامك المحددة عبر خدمة وكيل API الخاص بـ APIYI على apiyi.com، فقط قم بتعديل معامل
model.
تعليمات الوصول إلى GPT-5.4 nano عبر APIYI
مجموعة Default متاحة للاستخدام المباشر
تعتمد منصة APIYI نفس استراتيجية الانفتاح لنموذج GPT-5.4 nano ونموذج 5.4-mini:
- ✅ مجموعة Default الافتراضية: مفتوحة بالكامل، يمكن للمستخدمين الجدد استدعاء النموذج فور التسجيل.
- ✅ مجموعة SVIP المتقدمة: مفتوحة بالكامل، بدون أي قيود.
- ✅ مزامنة خصم التخزين المؤقت (Cache): سعر $0.02 لكل مليون رمز (1M) مطبق بالكامل.
- ✅ مزامنة Batch API: المهام الجماعية تتمتع بنفس الأسعار.
مقارنة التكلفة: APIYI مقابل الموقع الرسمي
| البند | موقع OpenAI الرسمي | APIYI (apiyi.com) |
|---|---|---|
| السعر الأساسي | $0.20 / $1.25 لكل 1M | $0.20 / $1.25 لكل 1M (نفس السعر) |
| خصم التخزين المؤقت | $0.02 / 1M (90%) | $0.02 / 1M (مزامنة كاملة) |
| مزايا الشحن | لا يوجد | اشحن $100 واحصل على $10 إضافية (10%) |
| التكلفة الفعلية | 100% من السعر القياسي | حوالي 90% من السعر القياسي (خصم 15%) |
| الوصول من داخل الصين | يتطلب VPN | اتصال مباشر، لا يتطلب VPN |
| طرق الدفع | بطاقات ائتمان دولية | يدعم الرنمينبي، Alipay، WeChat |
| توافق SDK | أصلي من OpenAI | متوافق تماماً مع OpenAI SDK |
| الحد الأدنى للشحن | $5 | يبدأ من $1 |
💰 تحسين التكلفة: بالنسبة للتطبيقات التي يتجاوز حجم استدعاءاتها المليون شهرياً، فإن الوصول إلى نموذج nano عبر APIYI يتيح لك الاستفادة من خصم التخزين المؤقت بالإضافة إلى خصم الشحن، مما يجعل التكلفة الإجمالية أقل بنسبة 25-35% مقارنة بالاستدعاء المباشر من موقع OpenAI.
الأسئلة الشائعة (FAQ)
س1: ما هو gpt-5.4-nano؟ وما الفرق الرئيسي بينه وبين gpt-5.4-mini؟
يعد GPT-5.4-nano أرخص وأسرع نموذج خفيف الوزن في سلسلة OpenAI GPT-5.4 (بسعر $0.20/$1.25 لكل 1M رمز)، بسرعة استجابة تصل إلى 200 رمز/ثانية. الفروقات الجوهرية عن 5.4-mini: 1) أرخص بـ 3.6 إلى 3.75 مرة؛ 2) أداؤه في استخدام الحاسوب (Computer Use) (39% مقابل 72.1% في OSWorld) والمهام الطرفية الطويلة (46.3% مقابل 60%) أضعف بشكل ملحوظ؛ 3) في السيناريوهات الأخرى (التصنيف، الاستخراج، استخدام الأدوات، الإجابة على الأسئلة المعرفية) يكون الفارق عادة أقل من 10 نقاط مئوية.
س2: ما هي أفضل سيناريوهات تطبيق لنموذج nano؟ وما هي السيناريوهات التي تتطلب استخدام mini؟
مناسب لـ nano (المنطقة الخضراء):
- التصنيف اللحظي (المشاعر، النوايا، المواضيع)
- استخراج البيانات المهيكلة
- ترتيب وإعادة ترتيب المحتوى
- طبقة تنفيذ الوكيل الفرعي (Sub-agent)
- طبقة توجيه RAG
- التلخيص/الترجمة ذات الإنتاجية العالية
- استدعاء الأدوات المعياري (92.5% في τ2-Bench)
سيناريوهات تتطلب استخدام mini (المنطقة الحمراء):
- أتمتة سطح المكتب عبر Computer Use (فارق 33 نقطة مئوية في OSWorld)
- المهام الطرفية الطويلة (> 10 خطوات)
- الاستنتاج المعقد متعدد الخطوات
- السيناريوهات المخصصة التي تتطلب ضبطاً دقيقاً (Fine-tuning)
س3: لماذا لا يُنصح باستخدام nano لـ Computer Use؟
في تقييم OSWorld-Verified، سجل nano نسبة 39.0% فقط، وهي أقل بكثير من 72.1% التي سجلها mini. هذا يعني أن معدل فشل nano في عمليات سطح المكتب متعددة الخطوات (فتح المتصفح ← البحث ← النقر ← ملء النموذج) مرتفع جداً، ولا يمكنه إكمال سلسلة المهام بشكل مستقر. إذا كان سيناريو عملك يتطلب Computer Use، يجب عليك اختيار mini أو إصدار 5.4 القياسي مباشرة.
س4: كيف يتم تفعيل خصم التخزين المؤقت $0.02/1M لنموذج nano؟
آلية التخزين المؤقت في OpenAI تُفعل تلقائياً، ولا تتطلب أي معاملات إضافية. يتم تفعيل الخصم عندما يتطابق بادئة الموجه (عادةً موجه النظام + السياق المشترك) مع الطلبات التي تمت في آخر 5-10 دقائق، لتحصل على خصم 90%.
نصائح للتحسين:
- ضع موجه النظام (system prompt) في بداية مصفوفة الرسائل.
- ضع السياق المشترك (ملصقات التصنيف، تعريف المخطط Schema) مباشرة بعده.
- ضع استعلام المستخدم الفعلي في النهاية.
- حافظ على وتيرة الاستدعاء (تنتهي صلاحية التخزين بعد > 5 دقائق).
عند الاستدعاء عبر APIYI، تتم مزامنة خصم التخزين المؤقت بالكامل مع الموقع الرسمي.
س5: ما هي أفضل الممارسات للتعامل مع المهام الجماعية (Batch) باستخدام nano؟
ثلاث استراتيجيات رئيسية:
- استخدام Batch API: قدم المهام الجماعية عبر واجهة
/v1/batches؛ تكتمل خلال 24 ساعة، بنفس السعر، ولا تستهلك حصة الـ RPM المباشرة. - مشاركة موجه النظام (system prompt): استخدم نفس التعليمات لجميع المهام لتحفيز تفعيل التخزين المؤقت.
- ضبط max_tokens بشكل معقول: مخرجات nano رخيصة ولكنها تتراكم، لذا حدد سقفاً معقولاً للمهام يتراوح بين 50-500 رمز.
من خلال تقديم مهام Batch عبر APIYI، ستستمتع بخصم شحن 10%، مما يجعل التكلفة الفعلية حوالي 85% من سعر الموقع الرسمي.
س6: كيف يمكن استدعاء GPT-5.4 nano عبر APIYI؟
APIYI متوافق تماماً مع OpenAI SDK، اتبع ثلاث خطوات فقط:
- قم بزيارة apiyi.com لإنشاء حساب (لا يتطلب طلباً، مجموعة Default متاحة للاستخدام المباشر).
- احصل على مفتاح API.
- قم بتعديل
base_urlفي الكود ليصبحhttps://vip.apiyi.com/v1واضبط النموذج علىgpt-5.4-nano.
client = openai.OpenAI(
api_key="YOUR_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[...]
)
عند شحن 100 دولار تحصل على 10% إضافية، وهو ما يعادل خصم 15% تقريباً عن الموقع الرسمي، مع مزامنة خصومات التخزين المؤقت.
س7: متى يكون nano أكثر توفيراً من mini؟ وكيف يتم الحساب؟
معادلة التقييم:
شرط توفير nano = (مستوى تحمل انخفاض جودة المهمة) × (حجم الاستدعاء) × (فرق السعر)
> (العائد من تحسين الجودة عند الترقية إلى mini)
سيناريوهات واقعية:
- حجم استدعاء > 10 آلاف/يوم: توفير > $30/يوم ($1000/شهر)
- حجم استدعاء > 100 ألف/يوم: توفير > $300/يوم ($9000/شهر)
- حجم استدعاء > 1 مليون/يوم: توفير > $3000/يوم ($90000/شهر)
بالنسبة لمهام المنطقة الخضراء (التصنيف، الاستخراج، استخدام الأدوات)، عادة ما يكون فقدان الجودة في nano أقل من 5%، بينما يتم توفير 73% من التكلفة (بناءً على مضاعف الحساب 3.6x). لذا، فإن العائد على الاستثمار (ROI) يرجح كفة nano دائماً.
س8: ما هي القيود المعروفة لنموذج GPT-5.4 nano؟
القيود الرئيسية:
- لا يدعم Computer Use: نسبة 39% في OSWorld منخفضة جداً، ولا يمكنه إكمال أتمتة سطح المكتب بشكل مستقر.
- لا يدعم الضبط الدقيق (Fine-tuning): لا يمكن تدريبه على مجموعات بيانات مخصصة.
- لا يدعم مدخلات الصوت/الفيديو: يدعم النصوص والصور فقط.
- ضعيف في المهام الطرفية الطويلة: سجل 46.3% في Terminal-Bench، ومن السهل فشل العمليات التي تتجاوز 10 خطوات.
- قدرات استنتاج معقدة محدودة: سجل 82.8% في GPQA وهو قريب من mini، لكن أداءه ينخفض بشكل ملحوظ في المهام الصعبة جداً مثل FrontierMath.
البديل: عند مواجهة هذه القيود، انتقل مباشرة إلى gpt-5.4-mini أو إصدار 5.4 القياسي.
النقاط الجوهرية لاستخدامات GPT-5.4 nano
- سعر تنافسي: 0.20 دولار / 1.25 دولار لكل مليون رمز (tokens)، وهو أرخص بـ 3.6 إلى 3.75 مرة من إصدار 5.4-mini.
- خصم 90% على التخزين المؤقت (Caching): تنخفض تكلفة المدخلات إلى 0.02 دولار لكل مليون رمز، مما يجعل سيناريوهات السياق عالي التكرار شبه مجانية.
- 7 سيناريوهات مثالية (المنطقة الخضراء): التصنيف، الاستخراج، الترتيب، الوكلاء الفرعيون (Sub-agents)، التوجيه، المعالجة المجمعة، واستخدام الأدوات.
- أداء τ2-Bench بنسبة 92.5%: أداء استدعاء الأدوات يقارب إصدار mini، وهو كافٍ لأكثر من 90% من سيناريوهات استدعاء الوظائف (Function Calling).
- أداء GPQA بنسبة 82.8%: قدرة قوية على الإجابة عن الأسئلة العامة، مما يجعله مناسباً للأسئلة الشائعة (FAQ) ومراجعة المحتوى.
- سرعة 200 رمز/ثانية: أسرع بنسبة 10% من إصدار mini، مما يجعله الخيار الأول لخطوط المعالجة ذات الإنتاجية العالية.
- تحذير (المنطقة الحمراء): يجب التبديل إلى إصدار mini عند تنفيذ مهام استخدام الحاسوب (Computer Use) أو مهام المحطة الطرفية (Terminal) الطويلة.
الخلاصة
إليك النقاط الأساسية حول سيناريوهات استخدام GPT-5.4 nano:
- تحديد النطاق: يُعد nano الخيار الأمثل للمهام ذات الإنتاجية العالية والتعقيد المنخفض؛ حيث يتألق في التصنيف اللحظي، استخراج البيانات، عمل الوكلاء الفرعيين، توجيه RAG، والمعالجة المجمعة.
- حدود القدرة: يقترب أداؤه في اختبارات τ2-Bench وGPQA وSWE-Bench Pro من إصدار mini، لكن قدراته في مهام استخدام الحاسوب (Computer Use) والمهام الطويلة في المحطة الطرفية (Terminal) أضعف بشكل ملحوظ.
- طريقة الوصول: يمكن استدعاؤه مباشرة عبر مجموعة Default في منصة APIYI (apiyi.com)، مع تفعيل خصومات التخزين المؤقت تلقائياً، بالإضافة إلى عرض شحن "اشحن 100 واحصل على 10 إضافية".
إن GPT-5.4 nano ليس مجرد خيار رخيص "يفعل كل شيء بجودة متوسطة"، بل هو أداة خفيفة الوزن صممتها OpenAI بعناية لسيناريوهات الإنتاجية العالية والتعقيد المنخفض. إذا كان تطبيقك يندرج ضمن سيناريوهات "المنطقة الخضراء" السبعة المذكورة أعلاه، فإن nano سيكون دائماً أكثر فعالية من حيث التكلفة مقارنة بـ mini. أما إذا كانت مهامك تتطلب استخدام الحاسوب أو تنفيذ أوامر طويلة في المحطة الطرفية، فإن التبديل إلى mini هو الخيار الصحيح.
نوصي بالوصول السريع إلى GPT-5.4 nano عبر منصة APIYI (apiyi.com)، حيث لا يتطلب الأمر تقديم طلبات لمجموعة Default، وتتزامن خصومات التخزين المؤقت بالكامل، مع الاستفادة من مكافأة شحن 10% واتصال مستقر ومباشر داخل البلاد.
قراءات إضافية
إذا كنت مهتماً بـ GPT-5.4 nano API، نوصيك بمتابعة القراءة حول المواضيع التالية:
- 📘 دليل ترقية GPT-5.4 mini API – تعرف على قدرات نموذج mini وسيناريوهات استخدامه المثالية.
- 📊 تحليل معمق لآلية التخزين المؤقت في OpenAI: أفضل الممارسات لتحقيق خصم 90% – أتقن التقنيات الهندسية لتحسين التخزين المؤقت.
- 🚀 تجربة عملية: بناء طبقة توجيه RAG باستخدام GPT-5.4 nano – استكشف البنية الهجينة التي تعتمد على "توجيه nano + معالجة mini".
📚 المراجع
-
وثائق OpenAI الرسمية لنموذج GPT-5.4 nano: مواصفات النموذج، التسعير، وأمثلة الاستدعاء.
- الرابط:
developers.openai.com/api/docs/models/gpt-5.4-nano - ملاحظة: للحصول على أحدث المعايير التقنية الرسمية وأكثرها موثوقية.
- الرابط:
-
تحليل معيار AI Cost Check: تقييم شامل للمقارنة بين nano و mini.
- الرابط:
aicostcheck.com/blog/gpt-5-4-mini-nano-pricing-benchmarks - ملاحظة: تقييم من طرف ثالث، مناسب للمقارنة الأفقية للفروقات في القدرات.
- الرابط:
-
وثائق ربط APIYI لنموذج GPT-5.4 nano: حلول الاستدعاء المحلية، شرح المجموعات، وعروض الشحن.
- الرابط:
docs.apiyi.com - ملاحظة: دليل عملي مناسب للمطورين المحليين للبدء في الربط.
- الرابط:
-
صفحة تسعير OpenAI: جدول الأسعار الكامل وشرح آلية التخزين المؤقت.
- الرابط:
developers.openai.com/api/docs/pricing - ملاحظة: لمعرفة أحدث معايير الفوترة لجميع النماذج.
- الرابط:
المؤلف: الفريق التقني لـ APIYI
تبادل الخبرات: نرحب بمناقشة تجاربكم في تطبيق GPT-5.4 nano في قسم التعليقات. للمزيد من مواد ربط النماذج، يمكنكم زيارة مركز توثيق APIYI عبر الرابط docs.apiyi.com