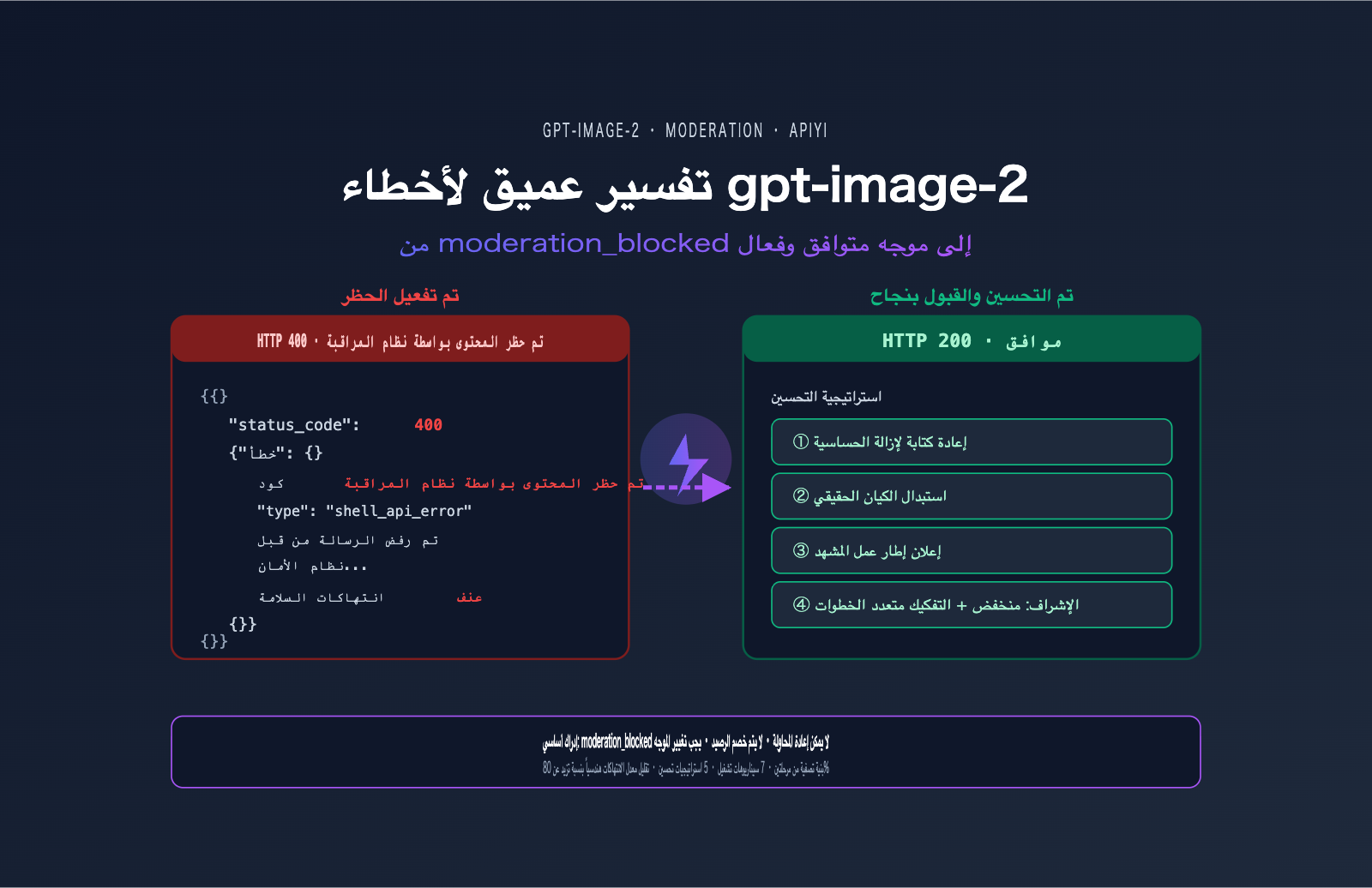
تلقى أحد المستخدمين رسالة الخطأ التالية عند استدعاء gpt-image-2 — وهي واحدة من أكثر رسائل الخطأ شيوعاً في مجتمع المطورين منذ إطلاق gpt-image-2 في أبريل 2026:
{
"status_code": 400,
"error": {
"message": "Your request was rejected by the safety system. ... safety_violations=[violence].",
"type": "shell_api_error",
"code": "moderation_blocked"
}
}
رد الفعل الأول للكثيرين هو: "سأضيف محاولة إعادة اتصال (Retry) وسينتهي الأمر". لكن هذا رد فعل خاطئ؛ فإعادة إرسال نفس الموجه (Prompt) 100 مرة سيؤدي إلى حظره في كل مرة. جوهر خطأ moderation_blocked في gpt-image-2 هو أن الطلب لم يصل إلى النموذج من الأساس، بل تم رفضه استباقياً بواسطة نظام تصنيف الأمان الأمامي، لذا فإن إعادة المحاولة هي مجرد إضاعة للوقت.
في هذا المقال، ننطلق من حالة الخطأ الواقعية هذه لنقوم بتفكيك آلية فحص الأمان في gpt-image-2 (بما في ذلك بنية التصفية ثنائية المرحلة)، واستعراض 7 سيناريوهات تؤدي لهذا الخطأ، و5 استراتيجيات لتحسين الموجه، بالإضافة إلى ممارسات هندسية لتقليل معدل الخطأ في gpt-image-2 في بيئات الإنتاج. بعد قراءة هذا المقال، ستتمكن فوراً من إجراء تدقيق امتثال لقوالب الموجهات الخاصة بك، وخفض معدل الانتهاكات بنسبة تزيد عن 80%.
فهم جوهر خطأ moderation_blocked في gpt-image-2
لحل هذا الخطأ، يجب أولاً فهم ماهيته الحقيقية. يعتقد العديد من المطورين أنه يعني "رفض النموذج للإجابة"، لكن هذا غير صحيح تماماً.
حقائق أساسية حول خطأ moderation_blocked في gpt-image-2
| الحقيقة | الشرح | المعنى الهندسي |
|---|---|---|
| HTTP 400 (client-side) | خطأ على مستوى الطلب، وليس عطلاً في الخادم | إعادة المحاولة لا تجدي نفعاً، يجب تعديل الموجه |
| الطلب لم يصل للنموذج | تم اعتراضه بواسطة مصنف أولي | لا يتم خصم رصيد، ولا يستهلك توكنز |
code=moderation_blocked |
رمز خطأ معياري، قابل للتعرف برمجياً | مناسب لبناء خط أنابيب إعادة صياغة تلقائي |
safety_violations=[…] |
مصفوفة تعرض فئات الانتهاك التي تم تفعيلها | تحديد دقيق للأجزاء التي تحتاج إلى تعديل |
| تكرار 100% لنفس الموجه | النتيجة حتمية وليست احتمالية | يجب إعادة صياغة الموجه لاستعادة العمل |
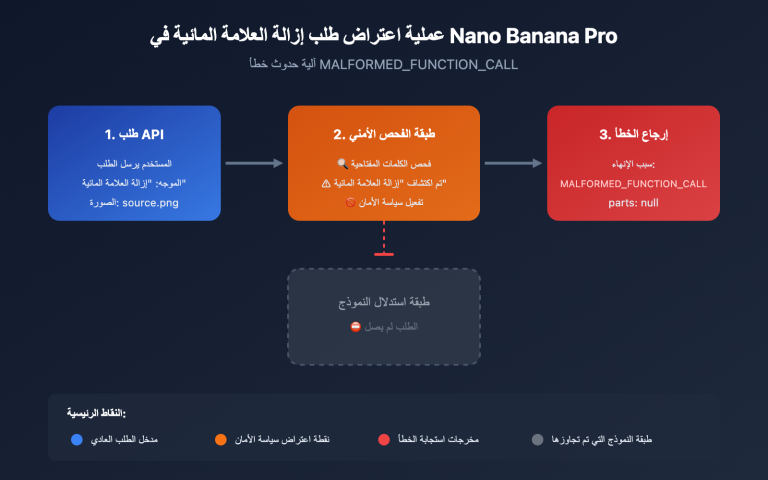
آلية فحص الأمان ثنائية المرحلة لخطأ gpt-image-2
لفهم خطأ gpt-image-2، يجب النظر بوضوح إلى بنية تصفية الأمان ثنائية المرحلة لدى OpenAI.
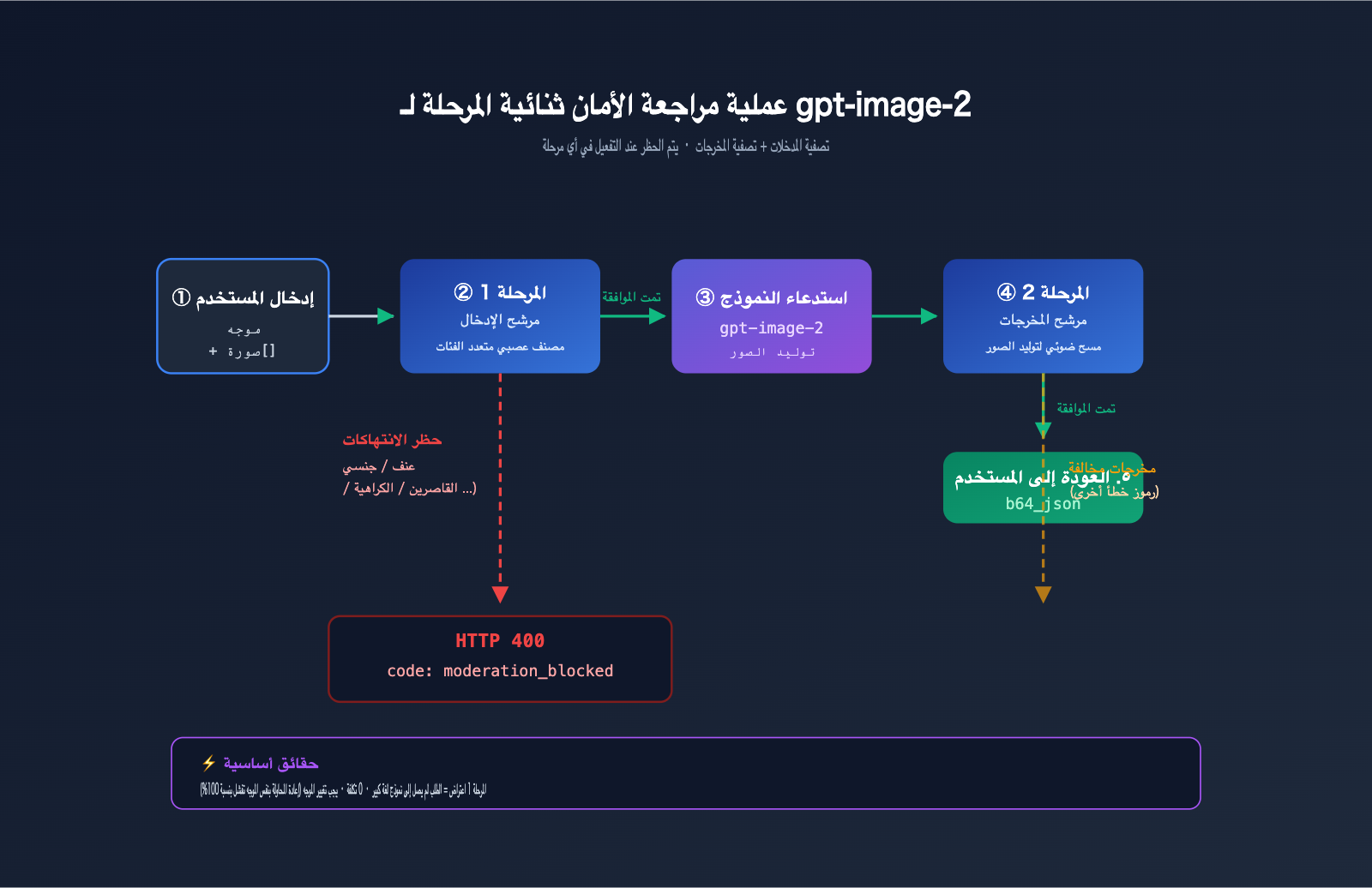
تتكون سلسلة الأمان فعلياً من مرحلتين:
المرحلة 1 · مرشح الإدخال (Input Filter):
- فحص نص الموجه الخاص بك.
- فحص جميع الصور المرجعية المرفوعة (إذا كنت تستخدم
/v1/images/edits). - استخدام مصنف عصبي متعدد الفئات (multi-class neural classifier).
- هذا هو المكان الذي يتم فيه تفعيل
moderation_blocked.
المرحلة 2 · مرشح الإخراج (Output Filter):
- فحص الصور التي قام النموذج بتوليدها بالفعل.
- إذا كان المحتوى المولد مخالفاً، فقد يتم اعتراضه أيضاً.
- عادة ما يعيد رمز خطأ مختلفاً (ليس
moderation_blocked).
الحالة التي قدمها المستخدم تسببت في تفعيل المرحلة 1 (تصفية الإدخال)، لذا لم يصل الطلب أبداً إلى مرحلة استنتاج النموذج. وهذا يفسر سبب سرعة استجابة هذا الخطأ (عادة أقل من ثانية واحدة)؛ فهو لم يدخل في طابور الانتظار ولم يستهلك موارد معالجة الرسوميات (GPU).
تباينات الواجهة الخلفية (Backend) لخطأ gpt-image-2
حقيقة يسهل تجاهلها: تختلف صرامة الفحص بين قنوات الواجهة الخلفية المختلفة. هناك فرق ملحوظ في معدل التفعيل عند استخدام الربط المباشر مع OpenAI مقابل Azure OpenAI لنفس الموجه، حيث تكون Azure أكثر صرامة بشكل عام. وهذا هو السبب في أن معلومات الخطأ في حالة المستخدم تشير إلى "اتصل بنا عبر تذكرة دعم Azure" – حيث تم توجيه هذا الطلب فعلياً إلى مرشح الواجهة الخلفية لـ Azure.
🎯 نصيحة اختيار القناة: إذا كنت تختبر نفس الموجه عبر قنوات مختلفة، فمن الطبيعي أن تجد اعتراضاً في بعض القنوات ومروراً في أخرى. نوصي بالتحقق عبر قناة OpenAI الرسمية الموجهة (Official Proxy) في APIYI (apiyi.com)، حيث تتبع هذه القناة سياسات التصفية الرسمية لـ OpenAI، ويكون معدل التفعيل فيها متطابقاً مع الربط المباشر بـ OpenAI، مما يسهل إجراء مقارنة مرجعية دقيقة.
نظرة شاملة على سيناريوهات الخطأ السبعة في gpt-image-2
حددت OpenAI بوضوح 7 فئات من السيناريوهات ذات التكرار العالي في بطاقة نظام ChatGPT Images 2.0. إن فهم هذه السيناريوهات السبعة هو الأساس لكتابة موجه (prompt) متوافق مع سياسات الاستخدام.

جدول مرجعي كامل لسيناريوهات أخطاء gpt-image-2
| الفئة | أمثلة على كلمات ذات مخاطر عالية | مستوى المخاطر |
|---|---|---|
| العنف (Violence) | قتال، حرب، سلاح، دم، إطلاق نار، لكم، قتل | 🔴 عالٍ |
| العنف الرسومي (Violence/Graphic) | دماء، بشاعة، تشويه، تقطيع | 🔴 عالٍ جداً |
| المحتوى الجنسي (Sexual) | عري، صريح، إيحاءات، وضعيات حميمية | 🔴 عالٍ جداً |
| رموز الكراهية (Hate Symbols) | الصليب المعقوف، أيقونات متطرفة محددة | 🔴 عالٍ جداً |
| إيذاء النفس (Self-harm) | انتحار، جروح، إيذاء الذات | 🔴 عالٍ جداً |
| القاصرون (Minors) | تصوير واقعي للأطفال | 🟡 متوسط – عالٍ |
| الشخصيات العامة (Public Figures) | شخصيات سياسية، أسماء المشاهير | 🟡 متوسط |
| حقوق الملكية الفكرية (Copyrighted IP) | شخصيات ديزني، مارفل، أسماء علامات تجارية شهيرة | 🟡 متوسط |
| الفنانون الأحياء (Living Artists) | "بأسلوب [اسم فنان حي]" | 🟡 متوسط |
تفكيك الفئات الفرعية للعنف في gpt-image-2
في الواقع، يتوافق safety_violations=[violence] مع فئتين فرعيتين، وهو أمر يخلط فيه الكثيرون في هذا المجال:
violence → وصف العنف العام (وجود حركات، صراعات، أسلحة)
violence/graphic → تفاصيل عنف رسومية أو دموية
بمجرد أن يؤدي الموجه الخاص بك إلى تفعيل أي من هاتين الفئتين الفرعيتين، سيتم إرجاع safety_violations=[violence]. وهذا يعني أنه حتى لو كتبت وصفاً محايداً نسبياً مثل "جندي يحمل بندقية"، فقد يتم تصنيفه ضمن فئة العنف الكبرى بواسطة المصنف (classifier) بناءً على السياق العام للموجه.
تحليل معمق لحالات المستخدم: السبب الجذري لخطأ violence
بالعودة إلى رسالة الخطأ الحقيقية في البداية، يخبرنا الحقل safety_violations=[violence] أن النظام قام بحظر المحتوى بسبب تصنيفه كعنف، ولكن ما هي الكلمة المحددة التي تسببت في ذلك؟ فيما يلي نهج منهجي للتشخيص.
قائمة الكلمات التي تثير خطأ violence في gpt-image-2
بناءً على ملاحظات المجتمع والاختبارات العملية، فإن الكلمات التالية تزيد بشكل ملحوظ من معدل الحظر لفئة العنف (ولا تقتصر على هذه الكلمات فقط):
| نوع الكلمة المحفزة | كلمات مخالفة شائعة | البدائل الآمنة |
|---|---|---|
| أسماء الأسلحة | gun, rifle, sword, knife, weapon | دعامة احتفالية، دعامة سينمائية، نصل للزينة |
| أفعال العنف | fight, attack, shoot, stab, punch | حركة سينمائية ديناميكية، مواجهة درامية |
| سياق الحرب | war, battle, soldier, combat | صراع بطولي، إعادة تمثيل تاريخي |
| دماء/إصابات | blood, wound, scar, gore | بقع حمراء، ظلال درامية، مظهر متآكل |
| انفجارات/تدمير | explosion, destruction, debris | وميض ضوئي درامي، جزيئات متطايرة |
خطوات تشخيص خطأ violence في gpt-image-2
إذا أدى الموجه (prompt) الخاص بك إلى حظر من فئة العنف، فاتبع خطوات الفحص التالية:
- فحص كلمات العنف الصريحة: ابحث في الموجه عما إذا كان يحتوي على الكلمات المحفزة المذكورة أعلاه.
- فحص قوة الأفعال: حاول استبدال أفعال الحركة مثل fight أو attack بأوصاف للحالة.
- فحص الصورة المرجعية (في حال استخدام التحرير): تحقق مما إذا كانت الصورة المرفوعة تحتوي بحد ذاتها على عناصر عنيفة.
- فحص السياق العام: حتى في غياب كلمات عالية الخطورة، فإن الوصف العام إذا شكل مشهداً عنيفاً سيؤدي إلى الحظر.
- محاولة إضافة إطار سياقي: أضف في بداية الموجه عبارات مثل "movie still" (لقطة فيلم) أو "theatrical scene" (مشهد مسرحي).
أهمية معرف الطلب (Request ID) عند حدوث خطأ في gpt-image-2
معرف الطلب request id: 2026042723155331083492939703753 الموجود في رسالة الخطأ ليس مجرد نص عشوائي، بل هو الدليل الوحيد لتحديد موقع السجلات (Logs). إذا كنت تستخدم الخدمة عبر قنوات رسمية، يمكنك التواصل مع الدعم الفني للمنصة باستخدام هذا المعرف للتحقق من سبب الحظر الدقيق.
💡 نصيحة تشخيصية: احتفظ بجميع معرفات الطلبات التي تظهر خطأ
moderation_blockedمع الموجه الأصلي، وقم ببناء "قاعدة بيانات للنماذج المخالفة" داخلياً لتدريب قواعد إعادة الصياغة التلقائية. ننصح بتصدير سجلات الطلبات عبر لوحة تحكم APIYI (apiyi.com) لإجراء تدقيق امتثال شهري وتحديد أنماط الحظر الأكثر تكراراً لدى فريقك.
5 استراتيجيات لتحسين الموجه (Prompt) لتجنب أخطاء gpt-image-2
فيما يلي 5 استراتيجيات تم اختبارها عملياً لتقليل معدل أخطاء gpt-image-2، مرتبة من الأعلى إلى الأقل أولوية، وننصح بتطبيقها بالترتيب.
الاستراتيجية 1: إعادة صياغة الموجه لتقليل الحساسية (Desensitization)
هذه هي الاستراتيجية الأكثر شيوعاً وفعالية، وتعتمد على استبدال الكلمات عالية المخاطر بأوصاف محايدة ذات تأثير بصري مماثل. المبدأ الأساسي هو الحفاظ على التأثير البصري مع إزالة الإيحاء بالعنف.
# ✗ يؤدي إلى حظر بسبب العنف
- "Two warriors fighting with swords, blood splatter on the ground, war scene"
# ✓ تمت إعادة الصياغة وتجاوز الفحص
+ "Two armored figures in dramatic standoff with ceremonial blades, red light reflections on the stone floor, cinematic composition, theatrical scene"
نقاط التغيير:
fighting←dramatic standoffswords←ceremonial bladesblood splatter←red light reflectionswar scene←theatrical scene
الاستراتيجية 2: استبدال الشخصيات الحقيقية
تجنب الإشارة المباشرة إلى الشخصيات العامة، المشاهير، أو الشخصيات المحمية بحقوق الطبع والنشر، واستخدم بدلاً منها أوصافاً للسمات البصرية.
# ✗ يؤدي إلى حظر بسبب الشخصيات العامة أو حقوق الملكية
- "A portrait of [اسم النجم] in business suit"
- "Mickey Mouse riding a bicycle in Paris"
# ✓ وصف آمن
+ "A portrait of a charismatic 30-year-old Asian businesswoman with shoulder-length black hair, wearing a tailored navy suit"
+ "A friendly anthropomorphic mouse character with round black ears and red shorts, riding a bicycle near the Eiffel Tower"
ملاحظة: الوصف الأسلوبي الكامل قد لا يزال يثير الحظر في حالة الشخصيات المحمية، حيث يعتمد نظام الفحص على التشابه البصري وليس فقط مطابقة النصوص. ننصح بإضافة سمات "أصلية" كافية.
الاستراتيجية 3: إضافة إطار سياقي للمشهد
أضف في بداية الموجه إطاراً فنياً أو إبداعياً واضحاً لتوضيح للمصنف أن هذا عمل فني وليس واقعاً.
- "Soldiers running across a battlefield"
+ "Movie still from a 1940s war drama: soldiers running across a foggy field, sepia tones, film grain texture"
- "Action scene with gunfire"
+ "Video game cutscene illustration: heroic action sequence with stylized energy effects, comic book style"
كلمات إطارية شائعة:
movie still/film stilltheatrical scene/stage performancevideo game cutscene/game illustrationcomic book panel/manga stylehistorical reenactment/museum dioramaoil painting/watercolor sketch
الاستراتيجية 4: تقسيم الموجه إلى خطوات متعددة
يمكن تقسيم المشاهد المعقدة وعالية المخاطر إلى خطوات متعددة:
# الخطوة الأولى: توليد "صورة مرجعية للأسلوب" (بدون عناصر حساسة)
step1_prompt = "Cinematic storyboard sketch, dramatic composition, sepia tones, no text"
style_ref = client.images.generate(model="gpt-image-2", prompt=step1_prompt)
# الخطوة الثانية: التوليد باستخدام وصف الأسلوب + محتوى محايد
step2_prompt = "Two figures in dramatic standoff, sepia tones, cinematic storyboard style, dust particles in the air"
final_image = client.images.generate(model="gpt-image-2", prompt=step2_prompt)
سير العمل هذا المعتمد على "الأسلوب أولاً، ثم المحتوى" يمكن أن يقلل بشكل كبير من حساسية الموجه الواحد.
الاستراتيجية 5: تعديل معامل المراجعة (moderation)
توفر واجهة برمجة التطبيقات (API) معامل moderation للتحكم في مستوى الحساسية (ينطبق فقط على نماذج الصور من OpenAI):
response = client.images.generate(
model="gpt-image-2",
prompt="A dramatic action scene from a noir film",
moderation="low", # القيمة الافتراضية auto، يمكن خفضها إلى low
size="1024x1024",
quality="medium"
)
تنبيه هام:
moderation: "low"لا يعني إيقاف الفحص، بل يعني تخفيف العتبة فقط.- المحتوى شديد الخطورة (الجنس، إيذاء النفس، تصوير واقعي لقاصرين، رموز الكراهية) سيتم حظره حتى مع ضبطه على low.
- إذا استمر ظهور
moderation_blockedبعد الضبط على low، فهذا يعني أن المحتوى تجاوز الحدود فعلياً ويجب تعديل الموجه. - كن حذراً عند استخدام low في المنتجات الموجهة للمستخدم النهائي (مخاطر الامتثال).
🚀 نصيحة للبدء السريع: جرب أولاً الاستراتيجيات 1-3 (إعادة الصياغة + الاستبدال + الإطار السياقي) فهي تحل أكثر من 80% من أخطاء
moderation_blocked. ننصح باستخدام الواجهة الموحدة لـ APIYI (apiyi.com) للتحقق أولاً من امتثال الموجه باستخدامmoderation: autoقبل اتخاذ قرار بخفضه إلى low.
فيما يلي استعراض عملي لتأثير تحسين "الموجه" (Prompt) من خلال 4 سيناريوهات واقعية لتجنب أخطاء gpt-image-2.

حالة تحسين أخطاء gpt-image-2 رقم 1: ملصق فيلم سينمائي
# ✗ قبل التحسين (يؤدي إلى حظر بسبب العنف)
- "An action movie poster featuring a male hero firing a gun at enemies, blood splatter background"
# ✓ بعد التحسين
+ "Cinematic action movie poster: a male protagonist in dramatic pose, holding a stylized prop, dynamic motion lines, red gradient background, theatrical lighting, film grain"
حالة تحسين أخطاء gpt-image-2 رقم 2: رسم شخصية لعبة
# ✗ قبل التحسين (يؤدي إلى حظر بسبب العنف)
- "Fantasy warrior with bloody sword, severed enemy head at his feet, gore details"
# ✓ بعد التحسين
+ "Fantasy warrior video game character art: armored figure with ornate ceremonial blade, defeated stylized monster silhouette at his feet, JRPG illustration style, painterly textures"
حالة تحسين أخطاء gpt-image-2 رقم 3: توضيح تعليمي تاريخي
# ✗ قبل التحسين (يؤدي إلى حظر بسبب العنف)
- "World War II soldiers fighting in trenches with rifles and explosions"
# ✓ بعد التحسين
+ "Historical educational illustration depicting a 1940s European trench scene: figures in period uniforms, weathered terrain with dramatic atmospheric effects, sepia documentary style, museum diorama aesthetic"
حالة تحسين أخطاء gpt-image-2 رقم 4: صورة مفاهيمية لإعلان تجاري
# ✗ قبل التحسين (يؤدي إلى حظر بسبب الشخصيات العامة)
- "[اسم الشخصية المشهورة] holding our coffee product in his usual style"
# ✓ بعد التحسين
+ "Charismatic 35-year-old male model with confident smile, casual blazer, warmly holding a takeaway coffee cup, modern minimalist café background, professional commercial photography"
أفضل الممارسات الهندسية لتقليل معدل أخطاء gpt-image-2
إذا كان مشروعك يقوم باستدعاء gpt-image-2 آلاف المرات يومياً، فإن المراجعة اليدوية لكل "موجه" (prompt) ليست عملية. إليك بعض الطرق الهندسية لتقليل معدل الأخطاء في gpt-image-2.
سير عمل التحقق المسبق لأخطاء gpt-image-2
قبل استدعاء واجهة برمجة تطبيقات الصور، قم بإجراء تحقق مسبق باستخدام Moderations API:
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1"
)
def safe_generate(prompt: str, max_rewrites: int = 3):
# الخطوة 1: التحقق المسبق
mod = client.moderations.create(input=prompt)
flagged = mod.results[0].flagged
categories = mod.results[0].categories
if flagged:
offending = [k for k, v in categories.model_dump().items() if v]
raise ValueError(f"الموجه أدى إلى تفعيل التحقق المسبق: {offending}")
# الخطوة 2: الاستدعاء الفعلي
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="medium"
)
يمكن للتحقق المسبق حظر 60-70% من الطلبات عالية المخاطر، مما يمنع الاستدعاءات غير الفعالة.
خط أنابيب إعادة الكتابة التلقائي لأخطاء gpt-image-2
بالنسبة لقوالب الموجهات في خط الإنتاج، يمكنك بناء أداة إعادة كتابة خفيفة:
SENSITIVE_REPLACEMENTS = {
r"\bgun\b": "ceremonial prop",
r"\bsword\b": "ornate ceremonial blade",
r"\bblood\b": "red splatter",
r"\bfight\b": "dramatic standoff",
r"\bwar\b": "heroic struggle",
r"\battack\b": "dynamic motion",
r"\bweapon\b": "stylized prop",
r"\bkill\b": "defeat",
r"\bshoot\b": "aim",
}
import re
def desensitize(prompt: str) -> str:
out = prompt
for pattern, replacement in SENSITIVE_REPLACEMENTS.items():
out = re.sub(pattern, replacement, out, flags=re.IGNORECASE)
if not out.lower().startswith(("movie still", "video game", "theatrical")):
out = "Cinematic movie still: " + out
return out
تغليف إعادة المحاولة الذكية لأخطاء gpt-image-2
بالنسبة لاستراتيجية إعادة المحاولة الخاصة بـ moderation_blocked — لا يمكنك إعادة المحاولة بنفس النص، يجب إعادة كتابة الموجه أولاً:
from openai import BadRequestError
def generate_with_rewrite(prompt: str, max_attempts: int = 3):
current = prompt
for attempt in range(max_attempts):
try:
return client.images.generate(
model="gpt-image-2",
prompt=current,
size="1024x1024"
)
except BadRequestError as e:
if "moderation_blocked" not in str(e):
raise # أخطاء 400 الأخرى لا ينبغي إعادة محاولتها
print(f"[{attempt+1}/{max_attempts}] تم تفعيل المراجعة، جاري تطبيق إعادة الكتابة لتقليل الحساسية...")
current = desensitize(current)
if attempt == max_attempts - 1:
# في المحاولة الأخيرة، نستخدم moderation: low
return client.images.generate(
model="gpt-image-2",
prompt=current,
moderation="low",
size="1024x1024"
)
raise RuntimeError("فشلت جميع استراتيجيات إعادة الكتابة")
لوحة مراقبة الامتثال لأخطاء gpt-image-2
يجب على بيئة الإنتاج تسجيل المؤشرات الرئيسية لكل انتهاك:
| المؤشر | الغرض |
|---|---|
| معدل الانتهاك (عدد الحظر/إجمالي الطلبات) | الصحة العامة للنظام |
توزيع فئات safety_violations |
تحديد أنواع الانتهاكات الأكثر تكراراً |
| أفضل 10 موجهات مسببة للانتهاك | تحسين القوالب الأكثر إشكالية |
| معدل النجاح بعد إعادة الكتابة | تقييم فعالية أداة إعادة الكتابة |
🎯 نصيحة للنشر في الإنتاج: نوصي بجعل معدل الانتهاك مؤشر SLO أساسي. عادةً ما يكون معدل الانتهاك في خط الإنتاج الصحي أقل من 2%، وإذا تجاوز 5% فهذا يشير إلى وجود مشكلة منهجية في قوالب الموجهات. نوصي باستخدام سجلات الطلبات في منصة APIYI (apiyi.com) لإجراء تحليل يومي وتحديد القوالب التي تسبب انتهاكات متكررة لإعادة كتابتها بشكل مركزي.
الأسئلة الشائعة حول أخطاء gpt-image-2
س1: هل يتم خصم الرصيد عند ظهور خطأ moderation_blocked في gpt-image-2؟
لا. يقوم مصنف الأمان بحظر الطلب قبل وصوله إلى النموذج، لذا لا يتم استهلاك أي توكن أو وقت معالجة GPU. تتبع كل من OpenAI وAPIYI هذه القاعدة. إذا لاحظت خصماً في فاتورتك، يجب عليك الاتصال بالمنصة فوراً للتحقق. نوصي بمراجعة سجلات الخصم لكل request_id عبر لوحة تحكم APIYI (apiyi.com) لضمان أن الطلبات المحظورة لا تُحاسب.
س2: لماذا لا تنجح إعادة المحاولة بنفس الموجه عند ظهور خطأ gpt-image-2؟
لأن مصنف الأمان حتمي (Deterministic)؛ فنتائج تصنيف المدخلات نفسها تكون مستقرة، ولا توجد عشوائية كما في نماذج التوليد. إعادة المحاولة 100 مرة ستؤدي إلى 100 عملية حظر متطابقة. الحل الوحيد هو تعديل الموجه.
س3: هل يمكن لـ moderation: low إيقاف المراجعة تماماً؟
لا. low يقوم فقط بخفض عتبة الحساسية، مما يجعله أكثر تسامحاً مع المحتوى متوسط الحساسية، ولكن المحتوى عالي الخطورة (مثل المحتوى الجنسي، إيذاء النفس، تصوير القاصرين، رموز الكراهية، القادة السياسيين، إلخ) سيتم حظره حتى مع استخدام low. الاعتقاد بأن low هو "مفتاح إيقاف" هو اعتقاد خاطئ.
س4: لماذا يتم حظر الموجه الخاص بي رغم أنه يبدو بريئاً؟
هناك ثلاثة احتمالات:
- السياق العام يشكل انتهاكاً: الكلمة الواحدة قد تكون بريئة، لكن تركيبها معاً يشكل مشهداً مخالفاً.
- الكلمات متعددة المعاني: على سبيل المثال، "shoot a photo" قد يُساء فهمها ككلمة عنيفة.
- اختلافات الواجهة الخلفية: واجهة Azure الخلفية أكثر صرامة من الاتصال المباشر بـ OpenAI.
بالنسبة للحالة الثانية، إضافة إطار سياقي (مثل "professional photography session") يمكن أن يخفف من المشكلة. نوصي باستخدام APIYI (apiyi.com) لجمع عينات "التصنيف الخاطئ" هذه في قاعدة معرفية داخلية لاستخدامها في تطوير قوالب الموجهات.
س5: هل يمكنني معرفة الكلمة التي تسببت في الخطأ عند ظهور خطأ gpt-image-2؟
لا تُرجع واجهة برمجة التطبيقات الكلمة المسببة للخطأ، بل تُرجع الفئة فقط (مثل [violence]). هذا تصميم متعمد من OpenAI لتجنب استخدامها كـ "دليل للالتفاف على القيود". لتحديد الكلمة المسببة، يمكنك استخدام البحث الثنائي: قسّم الموجه إلى نصفين واختبر كل جزء على حدة.
س6: ماذا أفعل إذا حدث انتهاك عند استخدام صورة مرجعية (مشاهد التعديل)؟
تقوم المرحلة الأولى من نقطة النهاية /v1/images/edits بمسح نص الموجه + جميع الصور المرفقة. إذا كانت الصورة المرجعية نفسها مخالفة:
- تحقق مما إذا كانت الصورة تحتوي على عنف، إيحاءات جنسية، أو شخصيات محمية بحقوق الطبع والنشر.
- استخدم أدوات محلية لمعالجة الصورة مسبقاً (قص أو تمويه المناطق الحساسة).
- إذا كانت صورة لشخص حقيقي، تأكد من عدم انتهاك سياسات الشخصيات العامة.
س7: هل فئات الانتهاك في gpt-image-2 مطابقة لفئات Moderations API؟
متطابقة تقريباً ولكن مع وجود اختلافات. الفئات التي تُرجعها Moderations API أكثر تفصيلاً (11 فئة)، بينما فئات الحظر في توليد الصور أكثر عمومية (7-9 فئات). نوصي باستخدام Moderations API كأداة تحقق مسبق، ولكن لا تفترض أن النتائج متطابقة تماماً؛ ففي بعض الأحيان قد يمر الموجه عبر Moderations API ولكن يتم حظره في واجهة الصور.
س8: هل يمكن تقديم اعتراض على خطأ gpt-image-2؟
يمكن ذلك ولكن بفعالية محدودة. يمكن استخدام request_id الموجود في رسالة الخطأ للاتصال بالدعم الفني للمنصة للتحقق. تجربة عملية: إذا كان الخطأ ناتجاً عن تصنيف خاطئ (مثل المحتوى الطبي أو التعليمي المحايد)، فقد تقوم المنصة بإضافته إلى القائمة البيضاء؛ أما إذا كان انتهاكاً فعلياً، فلن ينجح الاعتراض. نوصي بتقديم الاعتراض عبر نظام التذاكر في APIYI (apiyi.com) مع إرفاق request_id كامل وشرح لسياق العمل لزيادة كفاءة المعالجة.
ملخص: من أخطاء gpt-image-2 إلى موجه (Prompt) فعال ومتوافق
بعد الانتهاء من الفصول السبعة لهذا المقال، يجب أن تكون قد أتقنت نظام التعامل الكامل مع أخطاء gpt-image-2:
- ✅ فهم الجوهر ——
moderation_blockedهو خطأ من المستوى 400 على مستوى الطلب، لا يتم خصم رصيد مقابله ولا يمكن إعادة المحاولة فيه. - ✅ إتقان البنية —— نظام التدقيق الأمني ثنائي المرحلة (المرحلة الأولى: تصفية المدخلات + المرحلة الثانية: تصفية المخرجات).
- ✅ معرفة سيناريوهات الحظر —— 7 فئات رئيسية للمخالفات مع تفاصيل الفئات الفرعية للعنف.
- ✅ تشخيص المخالفات —— تحديد الموقع بدقة من خلال حقل
safety_violations. - ✅ 5 استراتيجيات للتحسين —— إعادة الصياغة لتقليل الحساسية، استبدال الموضوع، التصريح بالإطار، التفكيك متعدد الخطوات، ومعاملات التعديل (moderation).
- ✅ الحلول الهندسية —— التحقق المسبق، إعادة الصياغة التلقائية، إعادة المحاولة الذكية، ومراقبة الامتثال.
أهم نقطة يجب إدراكها: خطأ moderation_blocked في gpt-image-2 ليس خللاً برمجياً (Bug)، بل هو حدود الامتثال للمنتج. بدلاً من التذمر من الصرامة، اجعل "هندسة الموجهات المتوافقة" مهارة إنتاجية، فهذا هو أحد القدرات التنافسية الجوهرية لتطبيقات الذكاء الاصطناعي الموجهة للمستهلكين.
إذا كان فريقك يواجه أخطاء moderation_blocked متكررة، أو يحتاج إلى بناء عملية تدقيق لامتثال الموجهات في خط الإنتاج، أو يرغب في استخدام حلول هندسية لتقليل معدل المخالفات، فننصحك بطلب مفتاح تجريبي عبر APIYI (apiyi.com) وتجربة قوالب الكود الخاصة بالتحقق المسبق وإعادة الصياغة التلقائية المذكورة في هذا المقال. جميع الأمثلة تعتمد على حزمة SDK الرسمية وقناة التحويل الرسمية لـ APIYI (الحقول متطابقة بنسبة 100% مع OpenAI)، مما يمنحها توافقية عالية جداً وقابلية لإعادة الاستخدام مباشرة في مشاريعك الخاصة.
المراجع
-
بطاقة نظام OpenAI ChatGPT Images 2.0: توضيح السياسات الأمنية وآليات الحظر الرسمية.
- الرابط:
deploymentsafety.openai.com/chatgpt-images-2-0/live-blocking - ملاحظة: تتضمن بنية التصفية ثنائية المرحلة وقائمة كاملة بفئات المخالفات.
- الرابط:
-
وثائق OpenAI Moderations API: دليل الاستخدام الرسمي لأدوات التحقق المسبق.
- الرابط:
developers.openai.com/api/docs/guides/moderation - ملاحظة: تتضمن 11 فئة للمخالفات وطرق استدعاء الـ API.
- الرابط:
-
سياسات استخدام OpenAI: التوضيح المعتمد لسياسات الاستخدام.
- الرابط:
openai.com/policies/usage-policies/ - ملاحظة: تتضمن الاستخدامات المحظورة، تحمل المسؤولية، ومتطلبات الامتثال.
- الرابط:
-
دليل كتابة الموجهات لنماذج OpenAI GPT Image: أفضل الممارسات الرسمية.
- الرابط:
developers.openai.com/cookbook/examples/multimodal/image-gen-models-prompting-guide - ملاحظة: تتضمن طرق كتابة الموجهات المتوافقة وأمثلة عملية.
- الرابط:
-
وثائق ربط APIYI gpt-image-2: دليل الربط الكامل باللغة العربية.
- الرابط:
docs.apiyi.com/api-capabilities/gpt-image-2/overview - ملاحظة: تتضمن شرحاً مفصلاً لمعاملات التعديل (moderation) ومعالجة رموز الخطأ.
- الرابط:
المؤلف: فريق APIYI التقني
تاريخ النشر: 27 أبريل 2026
الكلمات المفتاحية: خطأ gpt-image-2، moderation_blocked، safety_violations، تدقيق المحتوى، تحسين الموجهات، APIYI، امتثال OpenAI