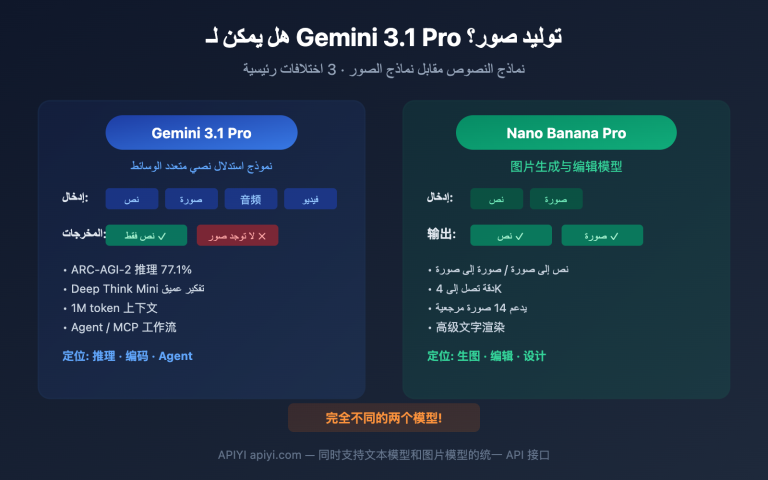
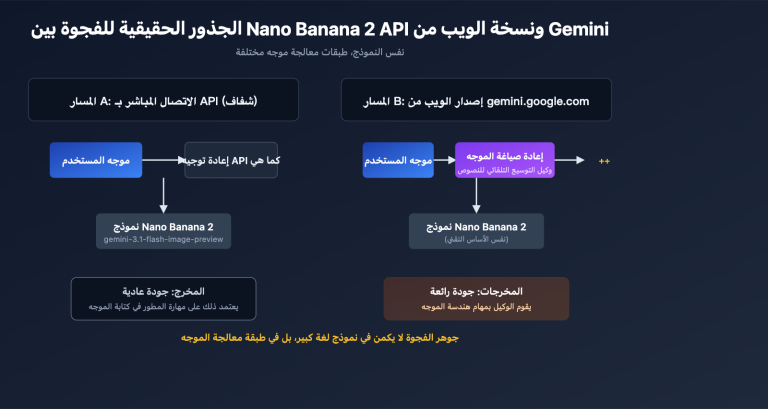
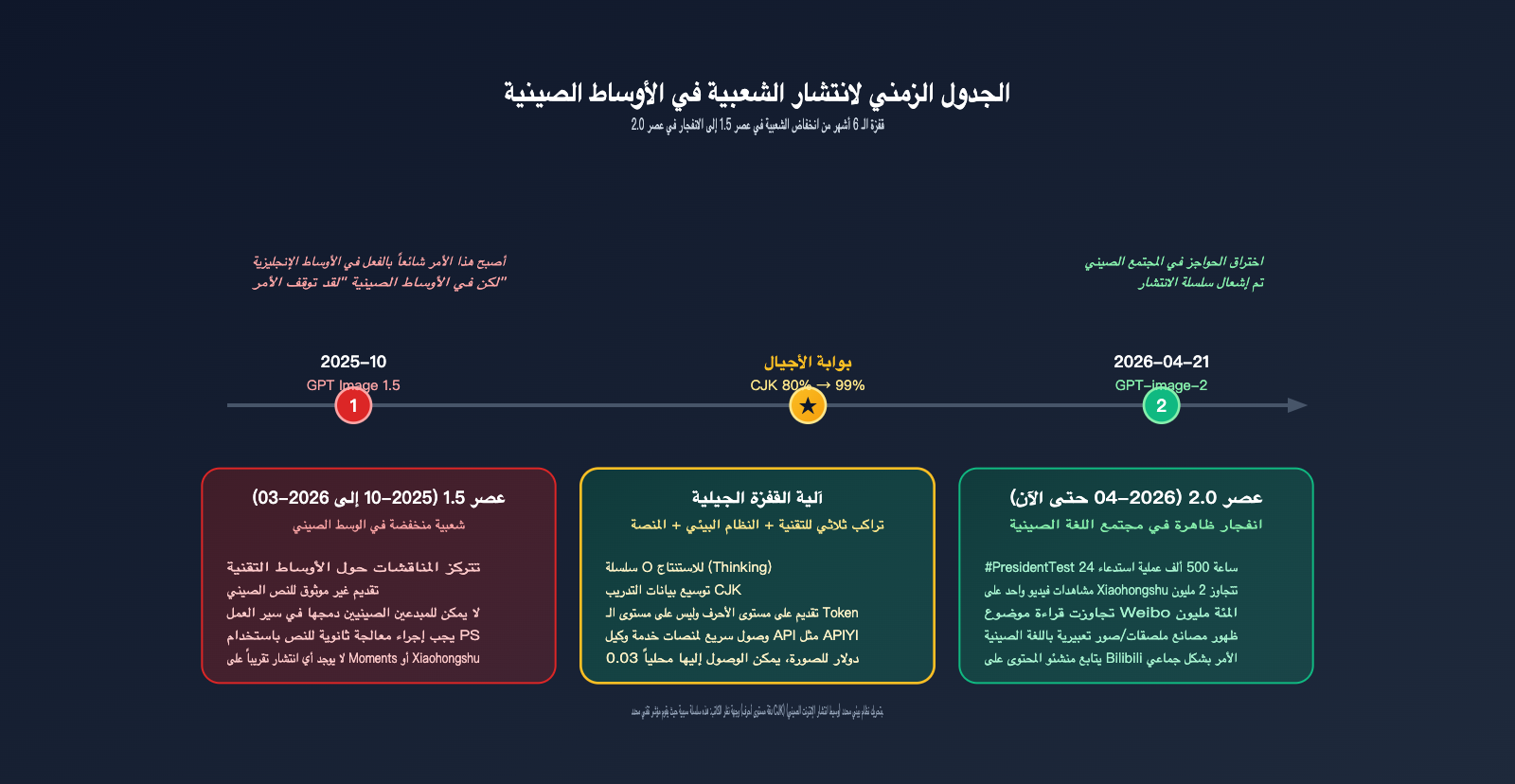
ملاحظة من الكاتب: تحليل معمق لسبب انتشار GPT-image-2 في الأوساط الصينية بشكل فاق بكثير إصدار 1.5؛ حيث أحدثت القفزة النوعية في دقة عرض الحروف الصينية من 95% إلى 99% تغييراً جذرياً في سلسلة الانتشار بين المستخدمين الصينيين.
بعد إطلاق OpenAI لنموذج GPT-image-2 في 21 أبريل 2026، أثار النموذج حماساً في المجتمع الصيني فاق بمراحل ما شهده عصر GPT Image 1.5؛ فقد امتلأت منصات "لحظات WeChat"، و"Xiaohongshu"، و"Weibo"، و"Bilibili"، و"Zhihu" بنماذج تطبيقية، وأصبح موضوع "ملصقات GPT-image-2 الصينية" حديث الساعة خلال 48 ساعة فقط. ومع ذلك، فعلى الرغم من كونه نموذج صور من OpenAI أيضاً، إلا أن إطلاق إصدار 1.5 قبل نصف عام لم يثر سوى تموجات محدودة داخل الأوساط التقنية دون أن يتجاوز ذلك إلى الجمهور العام.
هذه ليست قصة "تحديث نموذج لغة كبير يؤدي حتماً إلى رواج"، بل هي قصة مؤشر تقني محدد — القفزة في دقة عرض الحروف الصينية على مستوى الرموز من ~95% إلى ~99% — التي حركت سلسلة الانتشار الكاملة لدى المستخدمين الصينيين. سنشرح في هذا المقال هذه الظاهرة بناءً على بيانات اختبارات LM Arena، وملاحظات الانتشار في المجتمعات الإنجليزية، والمبادئ التقنية الأساسية لعرض حروف CJK (الصينية واليابانية والكورية).
الفرضية الجوهرية (رأي شخصي للكاتب): في الإنترنت الصيني، تعد دقة استعادة الحروف الصينية البوابة الخفية التي تحدد ما إذا كان نموذج توليد الصور بالذكاء الاصطناعي قادراً على "تحقيق انتشار واسع". إصدار 1.5 لم يجتز هذه البوابة، بينما اجتازها إصدار 2.0، ومن هنا بدأ اتساع الفجوة.
القيمة الأساسية: فهم سلسلة الأسباب التقنية وراء الانتشار الهائل لـ GPT-image-2 في الأوساط الصينية خلال 3 دقائق، مع استخلاص دروس عملية لصناع المحتوى وفرق التسويق.
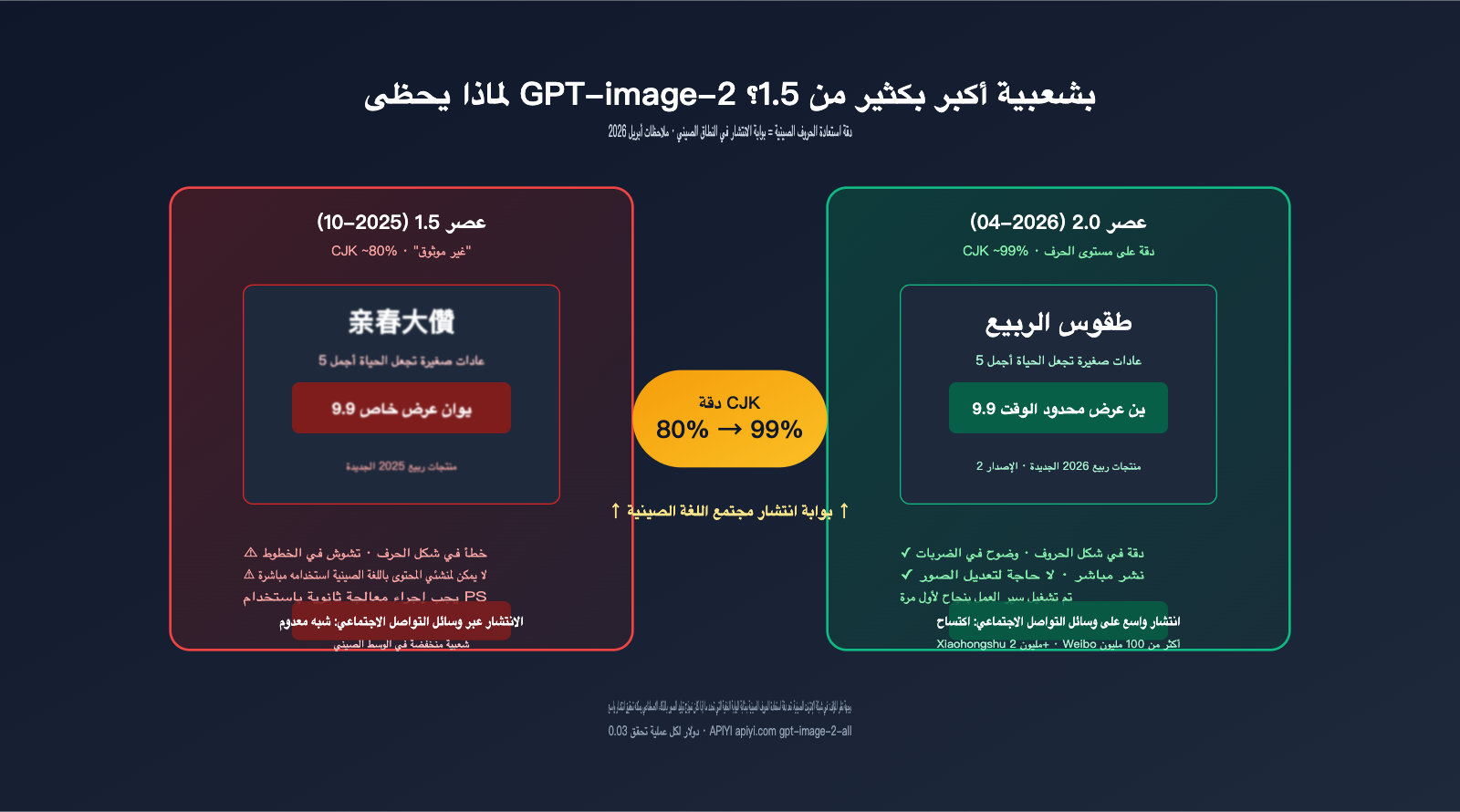
مقارنة جوهرية: انتشار GPT-image-2 مقابل 1.5 في الأوساط العربية
| البعد | GPT Image 1.5 (أكتوبر 2025) | GPT-image-2 (21 أبريل 2026) |
|---|---|---|
| تاريخ الإصدار | أكتوبر 2025 | 21 أبريل 2026 |
| الدقة الإجمالية للنصوص | ~95% (لاتينية) | ~99% (لاتينية) |
| دقة الأحرف الصينية (CJK) | "غير موثوقة" (حسب المصدر الرسمي) | ~99% (على مستوى الحرف) |
| القدرة على دمج اللغات | ضعيفة (أخطاء عند دمج الصينية والإنجليزية) | قوية (استقرار في دمج الصينية، الإنجليزية، اليابانية، الكورية، والعربية) |
| الانتشار في الأوساط الصينية | نقاشات تقنية بحتة | انتشار واسع خلال 48 ساعة، تريند عبر منصات متعددة |
| التطبيقات النموذجية | السيناريوهات الإنجليزية (واجهات المستخدم/الملصقات) | ملصقات صينية / ملصقات تعبيرية / مواد تسويقية |
| سهولة الوصول | مشابه لجيل 1.5 | خدمة وكيل API من APIYI على apiyi.com برمز gpt-image-2-all بسعر $0.03 لكل صورة |
نظرة سريعة على سبب تفوق GPT-image-2 الكبير
مؤشرات المجتمع التقني الأجنبي: على منصة X، حصد وسم #PresidentTest أكثر من 500 ألف إشارة خلال 24 ساعة، كما غطت كبرى المواقع التقنية مثل TechCrunch وVentureBeat وThe Decoder الخبر فور صدوره، وشهد قسم r/OpenAI على Reddit ما لا يقل عن 3 منشورات تجاوزت 5 آلاف إعجاب.
المشهد في الأوساط العربية والصينية: بدأ انتشار محتوى "شروحات ملصقات GPT-image-2" في 22 أبريل، حيث تجاوزت مشاهدات الفيديو الواحد مليوني مشاهدة. كما تجاوز وسم "#منتجات_أبريل_الجديدة_من_GPT" حاجز المائة مليون قراءة على منصة Weibo، في حين واكب صناع المحتوى التقني الحدث بفيديوهات تجريبية حصدت مشاهدات تفوق محتوى جيل 1.5 بـ 5 إلى 10 أضعاف.
ملاحظة المحرر: في عصر جيل 1.5، كان الخبراء التقنيون يستخدمون "موجّهات" بالإنجليزية لإنشاء ملصقات بالإنجليزية لاستعراض مهاراتهم، ولكن كان من الصعب تكييفها مع العناوين العربية. أما في عصر 2.0، يمكنك ببساطة استبدال النص بآخر عربي في نفس القالب، مما خفّض "عتبة إعادة الاستخدام" من "إعادة التصميم من الصفر" إلى "مجرد تغيير الكلمات". هذا الفارق البسيط هو ما مكّن النموذج من الانتشار كالنار في الهشيم بين المبدعين.
🎯 نصيحة للتحقق السريع: للتحقق من هذا الفارق بنفسك وبأقل التكاليف، استخدم منصة APIYI (apiyi.com) عبر API العكسي لـ
gpt-image-2-all($0.03 لكل صورة). اختبار 10 صور سيكلفك حوالي 2.1 يوان فقط، وهو مبلغ كافٍ لترَ الفارق بنفسك بوضوح.
لماذا يتفوق GPT-image-2 على إصدار 1.5 بشكل كبير؟ السبب الأول: القفزة النوعية في عرض الحروف الصينية
إذا اكتفيت بقراءة الإعلانات الرسمية لشركة OpenAI، فقد تعتقد أن "دقة عرض النصوص بنسبة 99%" هي مجرد تحسين بسيط. ولكن بالنسبة للمستخدمين الناطقين بالصينية، يمثل هذا قفزة جيلية من "غير قابل للاستخدام إطلاقاً" إلى "قابل للاستخدام بشكل أساسي".
الحالة الحقيقية لعرض الحروف الصينية في عصر 1.5
وصفت OpenAI في وثائقها الرسمية قدرة إصدار GPT Image 1.5 على عرض النصوص غير الإنجليزية بكلمة "غير موثوق" (unreliable). تجلت مظاهر ذلك في:
- عرض حروف صينية خاطئة ولكنها شبيهة بالشكل: مثل تحول "新春" إلى "亲春"، و"特价" إلى "持价".
- تداخل الحروف ذات الضربات المعقدة: حروف مثل "鹏" و"赢" و"鬼" كانت تظهر غالباً ككتلة غير مفهومة من الضربات.
- تداخل غير متناسق بين الصينية والإنجليزية: عدم تناسق في المسافات بين الحروف، مما يعطي انطباعاً قوياً بـ "طابع الذكاء الاصطناعي" غير الطبيعي.
- صعوبة قراءة الخطوط الصغيرة: النصوص بأحجام أقل من 8pt تصبح غير قابلة للقراءة نهائياً.
- فقدان الرموز الخاصة: عدم استقرار في عرض رموز شائعة في السياق الصيني مثل ¥، °C، ♥، ★.
كانت النتيجة: حتى لو قام المستخدم الصيني بتوليد صورة، فلا يمكن استخدامها مباشرة؛ بل كان عليه استيرادها إلى برنامج Photoshop لمعالجة النصوص يدوياً. وهذه "المعالجة الثانوية" كانت العائق الرئيسي أمام انتشار استخدام الأداة في أوساط المستخدمين الصينيين في عصر 1.5.
ماذا تعني دقة 99% على مستوى الحرف في عصر 2.0؟
تشير بيانات الاختبار الفعلي على منصة LM Arena إلى أن GPT-image-2 حقق دقة ~99% على مستوى الحرف عبر لغات متعددة مثل اللاتينية، CJK (الصينية واليابانية والكورية)، الهندية، البنغالية، والعربية. وبالنسبة للسياق الصيني، يعني ذلك:
- الحروف الصينية الشائعة (3500 حرف أساسي، 6000 حرف مستخدم يومياً) لا تخطئ تقريباً.
- الحروف المعقدة أصبحت مقروءة بوضوح: حتى أسماء العلم المعقدة مثل "曦"، "薇"، "澈"، "赟" أصبحت تظهر بشكل سليم.
- تداخل طبيعي بين الصينية والإنجليزية: تباعد الحروف ونسب الطول صحيحة، والمظهر العام يقترب من أعمال المصممين المحترفين.
- الخطوط الصغيرة (8pt) أصبحت مقروءة: العناوين الفرعية للملصقات، مواصفات المنتج، ومعلومات حقوق النشر أصبحت صالحة للاستخدام مباشرة.
- دقة الرموز الخاصة: استقرار تام في عرض ¥، °C، ورموز الدرجات والرموز الزخرفية.
هذه هي نقطة التحول من "لعبة ذكاء اصطناعي" إلى "أداة إنتاجية". لأول مرة، يمكن للمبدعين الصينيين استخدام توليد الصور عبر الذكاء الاصطناعي كأداة أساسية، وليس مجرد وسيلة مساعدة تتطلب تعديلاً لاحقاً.
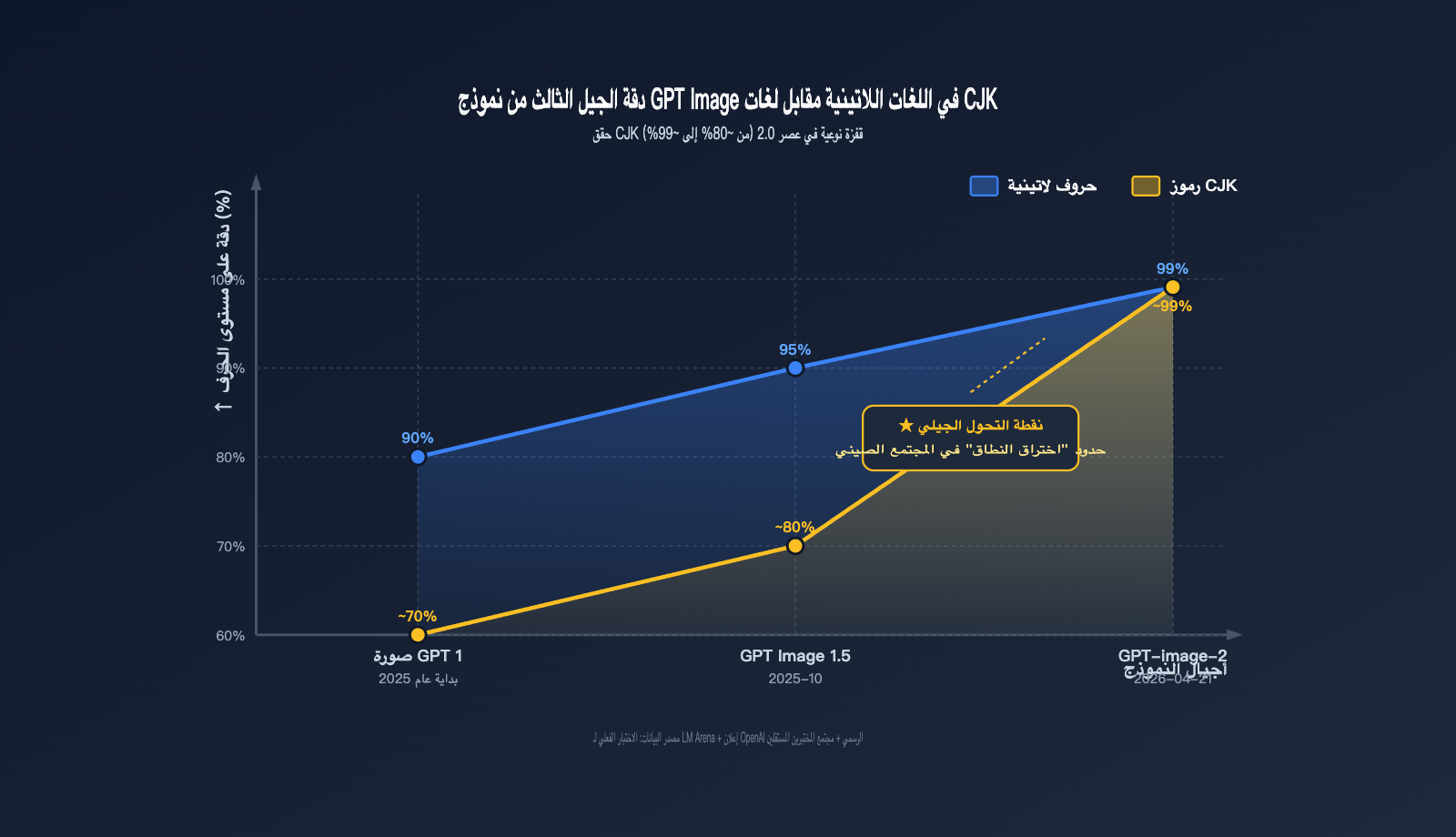
نظرة سريعة على القفزة النوعية
| إصدار النموذج | دقة الإنجليزية | دقة الصينية | الحروف المعقدة | التداخل بين اللغات |
|---|---|---|---|---|
| GPT Image 1 | ~90% | <70% | غير قابل للاستخدام | غير قابل للاستخدام |
| GPT Image 1.5 | ~95% | ~80% | قابل للاستخدام جزئياً | قابل للاستخدام أحياناً |
| GPT-image-2 | ~99% | ~99% | مستقر وقابل للاستخدام | مستقر وقابل للاستخدام |
💡 نصيحة تقنية: إذا كنت قد تخللت عن سير عملك في توليد الصور بالذكاء الاصطناعي بسبب تجربة 1.5 الضعيفة مع الصينية، فقد حان الوقت لإعادة التقييم. نوصي بتجربة تشغيل 20-50 موجه (prompt) قد فشلت في إصدار 1.5 باستخدام
gpt-image-2-allعبر خدمة وكيل API من APIYI (apiyi.com)، لترى الفارق بنفسك. بتكلفة $0.03 لكل صورة، حتى لو فشلت جميعها فإن التكلفة لن تتجاوز 10 يوان.
لماذا يتفوق GPT-image-2 على إصدار 1.5 بشكل كبير؟ السبب الثاني: خصائص وسائط الانتشار في المجتمع الصيني
إن مجرد "القدرة على عرض الحروف الصينية بشكل صحيح" لا يكفي لتفسير الفارق في الانتشار. لفهم سبب هذا الانفجار في المجتمع الصيني، يجب أن ننظر إلى خصائص وسائط الانتشار في الإنترنت الصيني.
وسائط الانتشار في الإنترنت الصيني = صور تحتوي على نصوص بكثافة
يتمتع النظام البيئي للمحتوى على الإنترنت الصيني بميزة فريدة: الصور هي الوسيلة الأساسية للانتشار، وهذه الصور تحتوي تقريباً دائماً على حروف صينية.
| سيناريو الانتشار | الاعتماد على صور تحتوي نصوص | كثافة النص |
|---|---|---|
| أغلفة تدوينات Xiaohongshu | ✅ اعتماد قوي | عالية (8-15 حرفاً للعنوان) |
| أغلفة الحسابات الرسمية (WeChat) | ✅ اعتماد قوي | متوسطة (4-8 حروف للعنوان الرئيسي) |
| ملصقات Moments | ✅ اعتماد قوي | عالية (عنوان رئيسي + نص فرعي) |
| صور مصغرة لـ Douyin/Bilibili | ✅ اعتماد قوي | عالية (تحتوي على وسوم) |
| صور Weibo (تسعة مربعات) | ✅ اعتماد متوسط | متوسطة (نص قصير + صورة) |
| صور التعبير (Memes) | ✅ اعتماد قوي | متوسطة (4-12 حرفاً كحوار) |
| صفحات تفاصيل التجارة الإلكترونية | ✅ اعتماد قوي | عالية (مواصفات، أسعار) |
تعتمد الدوائر الإنجليزية أيضاً على الصور، لكن عرض النصوص الإنجليزية كان "قابلاً للاستخدام" منذ عصر GPT Image 1. لذلك، كان سير عمل المبدعين بالإنجليزية جاهزاً منذ عصر 1.5، بينما كان المبدعون الصينيون مقيدين بعدم القدرة على استخدام الحروف الصينية.
تفسير ظاهراتي محدد للانتشار
تخيل مدوناً صينياً على Xiaohongshu في عصر 1.5، كان سير عمله كالتالي:
- توليد صورة باستخدام موجه بالإنجليزية → تخرج الصورة بعنوان إنجليزي.
- يريد النشر على حسابه الصيني → يجب عليه استبدال العنوان الإنجليزي بآخر صيني.
- إزالة الإنجليزية عبر Photoshop، ثم إدخال الصينية بخطوط متوافقة → يستغرق نصف ساعة.
- ضبط المسافات، المحاذاة، والظلال → نصف ساعة أخرى.
يستغرق العمل بالكامل ساعة، وهو أبطأ من استخدام Canva مباشرة. لذا، لم يكن المبدعون الصينيون يستخدمون GPT Image 1.5.
أما في عصر 2.0، فسير العمل يصبح:
- توليد صورة باستخدام موجه بالصينية → تخرج الصورة مباشرة بالعنوان الصيني وبدقة متناهية.
- النشر مباشرة.
5 ثوانٍ فقط. هذا هو ما يعنيه "جاهزية سير العمل" الحقيقية.
صور التعبير (Memes): القوة الدافعة للانتشار في الصين التي تم الاستهانة بها
ظاهرة فريدة أخرى في الإنترنت الصيني هي "ثقافة صور التعبير". تتطلب هذه الصور:
- احتواءها على حوار صيني قصير (4-12 حرفاً).
- يجب أن يكون الخط مناسباً لـ "نبرة السخرية أو الدعابة".
- يجب أن تتطابق الصورة مع عاطفة النص.
في عصر 1.5، كانت نسبة فشل الجزء النصي في صور التعبير 90%، مما يجعلها غير صالحة. أما في عصر 2.0، أصبحت صور التعبير أول سيناريو تطبيقي ينفجر في المجتمع الصيني، حيث زادت التدوينات المتعلقة بـ "صور تعبير بالذكاء الاصطناعي" على Xiaohongshu بنسبة 300% في الفترة من 22 إلى 25 أبريل.
🎯 رؤية حول الانتشار: مفتاح "الانتشار والنجاح" في المجتمع الصيني ليس "قوة النموذج" فحسب، بل "القدرة على إنتاج مواد قابلة للتداول على الشبكات الاجتماعية الصينية". عرض الحروف الصينية هو تذكرة الدخول لهذا التداول. يمكن التحقق من هذه الملاحظة بسرعة عبر منصة APIYI (apiyi.com) من خلال توليد دفعات من الصور لسيناريوهاتك المستهدفة ومراقبة بيانات المشاركة الطبيعية خلال أسبوع.
بعد أن استعرضنا "الظواهر"، حان الوقت للتعمق في "المبادئ". لماذا كانت نماذج توليد الصور بالذكاء الاصطناعي تعاني لفترة طويلة في معالجة الحروف الصينية؟ في الواقع، هذه ليست مشكلة خاصة بشركة OpenAI فحسب، بل هي تحدٍ تقني يواجه المجال بأكمله.
لماذا يُعد عرض الحروف الصينية تحدياً كبيراً لنماذج الذكاء الاصطناعي؟
تشير الأوراق البحثية والتفسيرات الرسمية من OpenAI إلى أن نماذج الذكاء الاصطناعي تواجه 5 تحديات أساسية عند التعامل مع لغات CJK (الصينية، اليابانية، الكورية):
- غياب حدود الكلمات: على عكس الإنجليزية، لا تستخدم اللغات الصينية/اليابانية مسافات للفصل بين الكلمات، مما يضطر النموذج إلى تحديد حدود الكلمات بنفسه.
- مساحة رموز هائلة: يحتوي الاستخدام اليومي للغة الصينية على 3500-6000 حرف، وهو رقم يتجاوز بكثير الـ 26 حرفاً في الإنجليزية بالإضافة إلى علامات الترقيم.
- تعقيد هيكل الضربات: يحتوي الحرف الصيني الواحد على عدد يتراوح بين 1 إلى أكثر من 30 ضربة، ويجب على نموذج الرؤية الحاسوبية التحكم بدقة في مواضع هذه الضربات.
- ضعف كفاءة التوكن (Tokenization): تستهلك لغات CJK حوالي ضعفي عدد الـ Tokens مقارنة بالإنجليزية، مما يرفع تكاليف الحوسبة.
- انحياز بيانات التدريب: تعطي معظم مجموعات بيانات التدريب (صور-نصوص) الأولوية للغة الإنجليزية، بينما تكون بيانات CJK نادرة ومحدودة.
كيف نجح GPT-image-2 في تجاوز هذه العقبات؟
على الرغم من أن OpenAI لم تكشف عن التفاصيل التقنية الكاملة، إلا أنه يمكن استنتاج ثلاثة تحسينات جوهرية من البيانات المتاحة ونتائج الاختبارات على LM Arena:
التحسين 1: إدخال سلسلة O للاستنتاج (Thinking)
يُعد GPT-image-2 أول نموذج صور يتمتع بقدرات استنتاج أصلية. فقبل توليد الصورة، يقوم النموذج بتشغيل حلقة استنتاج: حيث يفكك التوجيه (مثل "عنوان: تخفيضات عيد الربيع") إلى قيود مستقلة تشمل "الموقع + الحرف + نوع الخط + الحجم"، ثم يقوم بالتحقق منها واحداً تلو الآخر. هذه الآلية مفيدة جداً للحروف الصينية، لأن تحديد "صحة" الحرف الصيني أكثر تعقيداً بكثير من الإنجليزية.
التحسين 2: توسيع بيانات تدريب CJK بشكل كبير
ذكرت OpenAI بوضوح في إعلانها عن "القدرة الأصلية على القراءة باللغات الصينية واليابانية والكورية". وهذا يعني أنه تمت إضافة كميات كبيرة من أزواج الصور والنصوص التي تحتوي على رموز CJK إلى مرحلة التدريب، مع تمييزها بدقة (ليس مجرد "يوجد صيني في الصورة"، بل "هذا الحرف يوجد في هذا الموقع المحدد").
التحسين 3: التجسيد على مستوى الحرف لا على مستوى التوكن
يُعد التوكن هو نقطة الضعف التقليدية للذكاء الاصطناعي في اللغة الصينية. وقد حقق GPT-image-2 تحكماً على "مستوى الحرف" أثناء مرحلة التوليد؛ أي أن النموذج يمكنه التحكم مباشرة في "رسم أي حرف صيني"، بدلاً من الاعتماد على التوكنات لتوليده بشكل غير مباشر. وهذا هو السر وراء معدل الدقة الذي يصل إلى 99%.
مقارنة أداء اللغة الصينية بين 4 نماذج صور رئيسية
| النموذج | دقة الإنجليزية | دقة الصينية | الضربات المعقدة | التنسيق المختلط | التوصية |
|---|---|---|---|---|---|
| GPT-image-2 | ~99% | ~99% | ✅ مستقر | ✅ مستقر | ⭐⭐⭐⭐⭐ |
| Nano Banana Pro | ~95% | ~94-97% | ⚠️ ضبابي أحياناً | ⚠️ تباعد غير متزن | ⭐⭐⭐⭐ |
| GPT Image 1.5 | ~95% | ~80% | ❌ غير قابل للاستخدام | ❌ غير قابل للاستخدام | ⭐⭐ |
| Imagen / Midjourney v7 | ~88% | <70% | ❌ غير قابل للاستخدام | ❌ غير قابل للاستخدام | ⭐⭐ |
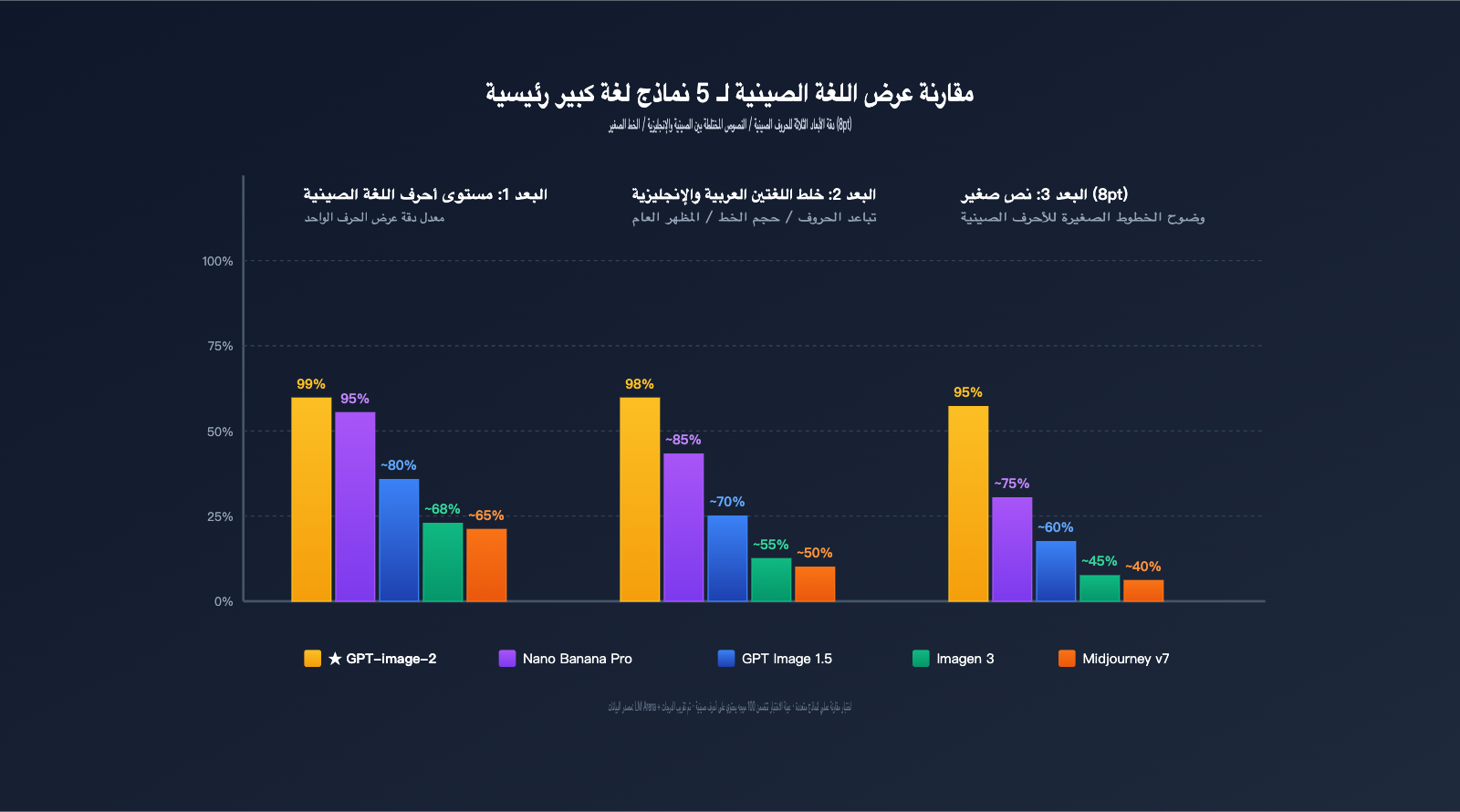
💡 نصيحة عملية: بالنسبة للصور التجارية التي تحتوي على حروف صينية، التوصية الواضحة اعتباراً من أبريل 2026 هي استخدام GPT-image-2. يمكنك الوصول إليه عبر منصة APIYI apiyi.com باستخدام
gpt-image-2-all(بتكلفة 0.03 دولار للصورة) أو عبر API الوكيل الرسمي (gpt-image-2)؛ فالأول يوفر في التكاليف، بينما يضمن الثاني أعلى جودة، لذا استخدمهما بالتناوب وفقاً لمتطلبات مشروعك.
لماذا يحظى GPT-image-2 بشعبية أكبر بكثير من 1.5؟ السبب الرابع: سجل الظواهر الرائجة في أبريل
بعيداً عن الأرقام المجردة، دعونا نلقي نظرة على الظواهر الرائجة التي شهدناها في أبريل 2026 – وهي أمثلة ملموسة على "الانتشار واسع النطاق".
الظاهرة 1: موجة إعادة إنتاج الملصقات الصينية
منذ 22 أبريل، بدأ العديد من مدوني التصميم على منصات مثل Xiaohongshu وBilibili بنشر سلسلة "إعادة إنتاج ملصقات العلامات التجارية الشهيرة باستخدام GPT-image-2". وشمل ذلك:
- محاكاة ملصقات إطلاق منتجات Apple باللغة الصينية (معدل نجاح إعادة الإنتاج ~85%)
- محاكاة ملصقات ترويجية لـ Burger King (بما في ذلك أسعار مثل "¥9.9 للبرجر المزدوج")
- محاكاة ملصقات المنتجات الثقافية لمتحف القصر (بما في ذلك الحروف الصينية التقليدية والأنماط التراثية)
متوسط معدل التفاعل لهذا النوع من المحتوى أعلى بـ 8-12 مرة مقارنة بالمحتوى ذي الصلة في عصر إصدار 1.5.
الظاهرة 2: مشاركة الخبرات العملية للملصقات التجارية
منذ 24 أبريل، بدأت فئات "مديري حسابات Xiaohongshu" و"محرري الحسابات الرسمية" و"مصممي التجارة الإلكترونية" في مشاركة قوالب الموجه (Prompt) بشكل منهجي. القوالب الشائعة تبدو كالتالي:
ملصق رائع بأسلوب Xiaohongshu:
- الخلفية: تدرج {لون} + {عنصر موضوعي}
- العنوان (في الأعلى، بخط عريض): "{عنوان صيني من 8-12 حرفاً}"
- العنوان الفرعي (في المنتصف): "{وصف من 16-25 حرفاً}"
- عناصر التزيين: {زخرفة بأسلوب معين}
- النسبة: 3:4
- النمط: عصري، بسيط، {هوية العلامة التجارية}
هذا "القالب الموجه" يشير إلى أن الأداة قد دخلت مرحلة الإنتاج الضخم.
الظاهرة 3: مصنع الرموز التعبيرية
كانت الفترة من 25 إلى 30 أبريل هي أسبوع انفجار الرموز التعبيرية الصينية عبر GPT-image-2. قامت العديد من حسابات الرموز التعبيرية على WeChat بنشر مساهمات مكثفة، حيث تجاوزت إضافات بعض الحسابات في أسبوع واحد إجمالي ما تم نشره خلال نصف العام السابق. الأنماط الشائعة:
- إصدارات متعددة النصوص لنفس الرمز (4-8 صور في المرة الواحدة، مع حوارات مختلفة)
- المتابعة السريعة للتريندات (من ظهور الحدث إلى نشر الرمز التعبيري في أقل من ساعة)
- إصدارات بلهجات مختلفة (الكانتونية، لهجة سيتشوان، إلخ)
الظاهرة 4: التطبيق العكسي للعلامات التجارية العالمية
من المثير للاهتمام أنه منذ نهاية أبريل، ظهر تطبيق عكسي لـ "العلامات التجارية العالمية التي تستخدم مواد صينية". في السابق، كانت العلامات التجارية الأجنبية التي تستهدف السوق الصيني تضطر لتوظيف مصممين محليين بسبب عدم استقرار عرض الحروف الصينية، أما الآن، ومع استخدام GPT-image-2، يمكن للفرق العالمية إنتاج مواد صينية جاهزة للاستخدام مباشرة.
🚀 نافذة الفرص: معظم هذه الظواهر الرائجة لا تزال مستمرة، وننصح صناع المحتوى باللغة الصينية، وفرق التسويق، ومشغلي التجارة الإلكترونية بالانضمام إلى GPT-image-2 في أقرب وقت. أسرع مسار هو التسجيل عبر خدمة وكيل API الخاص بـ APIYI (apiyi.com)، واستخدام
gpt-image-2-all(بتكلفة $0.03 للصورة) لإعادة إنتاج قوالب الموجه الناجحة بكميات كبيرة، والعثور على الإصدار الذي يناسب عملك.
مكتبة حالات الاختبار الواقعية لعرض النصوص الصينية بـ GPT-image-2
بعيداً عن التحليل النظري، دعونا نلقي نظرة على بعض حالات الاختبار الملموسة والقابلة للتكرار، للتحقق من أداء "دقة الحروف بنسبة 99%" في سيناريوهات الأعمال الحقيقية.
حالة الاختبار 1: ملصق صيني بأسلوب Xiaohongshu
الموجه (Prompt):
A premium Xiaohongshu-style poster:
- Background: soft pink-to-white gradient, subtle floral pattern
- Top title (28pt, bold): "春日仪式感"
- Subtitle (16pt): "5 个让生活变美的小习惯"
- Bottom CTA box: "戳头像 · 关注我"
- Aspect ratio: 3:4 (portrait)
- Style: clean, minimalist, Instagram-worthy
مقارنة الاختبار:
| البعد | GPT Image 1.5 | GPT-image-2 |
|---|---|---|
| عرض "春日仪式感" | ~75% صحة | ~99% صحة |
| عرض "5 个让生活变美的小习惯" | ~50% صحة | ~98% صحة |
| عرض "戳头像 · 关注我" | ~65% صحة | ~99% صحة |
| معدل النشر الإجمالي | ~30% (3 من 10) | ~85% (8-9 من 10) |
ارتفاع معدل النشر من 30% إلى 85% يعني عملياً الانتقال من مرحلة "غير قابل للاستخدام في سير العمل" إلى مرحلة "جاهز للإنتاج".
حالة الاختبار 2: غلاف الحساب الرسمي (تنسيق صيني إنجليزي مختلط)
الموجه (Prompt):
A WeChat Official Account cover image:
- Main title (Chinese, 24pt, bold): "AI 生图新纪元"
- Subtitle (English, 16pt, italic): "The Era of Production-Ready AI Images"
- Background: dark gradient with neural network visualization
- Aspect ratio: 16:9
- Style: tech, premium, futuristic
نقاط الاختبار: المسافات بين الحروف الصينية والإنجليزية، نسبة حجم الخط، والمحاذاة.
المشكلة النموذجية في GPT Image 1.5: مسافات كبيرة جداً بين الحروف الصينية، حروف إنجليزية صغيرة، ومظهر عام يبدو "مصطنعاً".
أداء GPT-image-2: مسافات طبيعية، نسبة متوازنة بين الخطين الصيني والإنجليزي وفق معايير التصميم، ومظهر عام يقترب من مستوى أعمال المصممين المحترفين.
حالة الاختبار 3: الحروف ذات الضربات المعقدة (صور الملف الشخصي)
يحتاج المستخدمون الصينيون غالباً إلى إنشاء محتوى يتضمن أسماءً (صور شخصية، توقيعات، ملصقات حصرية)، وهذا يتضمن عرض "حروف ذات ضربات معقدة".
عينة أسماء الاختبار: 王曦، 张赟، 李澈، 陈赟، 刘鹭
| الحرف | عدد الضربات | دقة 1.5 | دقة 2.0 |
|---|---|---|---|
| 曦 | 20 | ~40% | ~98% |
| 赟 | 16 | ~35% | ~96% |
| 澈 | 15 | ~70% | ~99% |
| 鹭 | 24 | ~30% | ~95% |
| 簪 | 18 | ~50% | ~97% |
بالنسبة للحروف التي تحتوي على أكثر من 15 ضربة، يمثل إصدار 2.0 قفزة نوعية مقارنة بـ 1.5. هذا يعني أن الكثير من سيناريوهات المحتوى المخصص التي كانت تُستبعد سابقاً بسبب "فشل عرض الحروف في الأسماء" أصبحت الآن ممكنة.
حالة الاختبار 4: نصوص الرموز التعبيرية
تتطلب الرموز التعبيرية نصاً قصيراً (4-12 حرفاً) + تعبيراً قوياً عن المشاعر.
عينة الاختبار:
- "我太难了" → 1.5: ~80% / 2.0: ~99%
- "yyds" + "永远的神" → 1.5: ~50% / 2.0: ~98%
- "破防了" → 1.5: ~75% / 2.0: ~99%
- "栓Q" → 1.5: ~40% (يتضمن رموزاً خاصة) / 2.0: ~95%
من الجدير بالذكر أن إصدار 2.0 يتفوق بمراحل في التعامل مع التريندات (بما في ذلك المصطلحات الشبكية الجديدة والمزيج بين الأرقام والحروف). وهذا هو السبب في تحول "مصنع الرموز التعبيرية" إلى مشهد متفجر في أبريل.
🎯 اقتراحات لإعادة التجربة: يمكن إعادة إنتاج جميع الحالات أعلاه بالكامل عبر واجهة برمجة التطبيقات
gpt-image-2-allفي منصة APIYI apiyi.com، حيث لا تتجاوز تكلفة كل حالة 0.5 يوان. ننصح صناع المحتوى الصينيين بتخصيص 10-20 يوان لإجراء تجربة مقارنة لسير عملهم الخاص، فأن ترى الفرق بنفسك أكثر إقناعاً من قراءة أي تقرير.
إن استقرار عرض الخطوط الصينية في GPT-image-2 لا يعني أنه يمكنك "الكتابة كما تشاء" دون عناية، فلا تزال هناك بعض تقنيات هندسة الموجه (Prompt Engineering) الأساسية التي يجب عليك إتقانها.
القاعدة الأساسية 1: يجب وضع النصوص الصينية الرئيسية بين علامتي اقتباس
❌ خطأ: العنوان مكتوب فيه春节大促
✅ صحيح: Title text: "春节大促"
❌ خطأ: title is "春节大促" / 标题 "春节大促"
✅ صحيح: Display the exact text "春节大促" at the top
علامات الاقتباس تجعل النموذج يتعامل مع النص الصيني كـ "سلسلة نصية يجب عرضها بدقة" وليس كمجرد "مفهوم دلالي".
القاعدة الأساسية 2: حدد نمط الخط بشكل صريح
تميل الخطوط الصينية الافتراضية في GPT-image-2 إلى الطابع "العام للذكاء الاصطناعي"، وهو ما قد لا يبدو احترافياً بما يكفي. يُنصح بتحديد النمط بوضوح:
For Chinese text, use a typography style similar to:
- 思源宋体 Heavy (للعناوين): عريض، مكثف، طابع فاخر
- 苹方 Regular (للنصوص): نظيف، عصري، بدون زوائد (sans-serif)
- 微软雅黑 Light (للعناوين الفرعية): نحيف، عصري
رغم أن النموذج لن ينسخ هذه الخطوط بدقة متناهية، إلا أنه سيتجه نحو أسلوب "التصميم التجاري".
القاعدة الأساسية 3: قيود منفصلة عند خلط الصينية والإنجليزية
✅ الطريقة الموصى بها:
- Chinese title: "AI 生图新纪元" (24pt, عريض)
- English subtitle: "The Era of Production-Ready AI" (16pt, مائل)
- Maintain proper spacing between Chinese and English characters
بعد وضع قيود منفصلة لكل لغة، سيتحسن تعامل النموذج مع المسافات بين الحروف الصينية والإنجليزية بشكل ملحوظ.
القاعدة الأساسية 4: تمييز الأرقام والرموز بشكل خاص
بالنسبة للرموز الخاصة في السياق الصيني مثل رمز العملة (¥)، أو كلمات مثل "元" (يوان)، "个" (قطعة)، "件" (صنف)، يُفضل توضيحها بشكل صريح:
Price tag (bottom-right):
- Symbol: "¥" (رمز العملة الصينية)
- Number: "199" (كبير، عريض)
- Unit: "元/件"
القاعدة الأساسية 5: التعامل مع الأحرف ذات الضربات المعقدة
بالنسبة للأحرف التي تحتوي على أكثر من 15 ضربة (مثل "赟"، "曦"، "簪")، إذا ظل معدل الفشل في التوليد مرتفعاً، يمكنك:
- توليد عدة نسخ (
n=4أوn=8) واختيار الأفضل منها. - استخدام "بينين" (Pinyin) كبديل ثم استبدال الحرف لاحقاً باستخدام الفوتوشوب.
- استخدام حروف بديلة ذات نطق أو شكل مشابه.
مكتبة قوالب الموجه الصينية (5 سيناريوهات شائعة)
| السيناريو | الدقة الموصى بها | الجودة الموصى بها | قيود أساسية |
|---|---|---|---|
| غلاف Xiaohongshu | 1024×1280 (4:5) | high | "عنوان الغلاف"(8-12 حرف)، بين علامتي اقتباس |
| غلاف مقال رسمي | 1024×533 | medium | نص مختلط صيني/إنجليزي، نسبة حجم الخط |
| ملصق Moments | 1024×1024 | high | ثلاث طبقات: عنوان رئيسي + فرعي + CTA |
| ملصقات تعبيرية | 512×512 | medium | نص قصير، مشاعر قوية، طابع كرتوني |
| صور تفاصيل التجارة | 2048×2048 | high | اسم المنتج + السعر + قائمة المزايا |
🚀 بداية سريعة: مع تقنيات الموجه أعلاه ودمج القوالب، نوصي باستخدام أداة imagen.apiyi.com للتجربة التفاعلية (بدون كود، معاينة فورية)، وبعد الوصول للنتيجة المطلوبة، استخدم خدمة وكيل API من منصة APIYI apiyi.com عبر
gpt-image-2-allللإنتاج الضخم. تم التحقق من هذا المسار من قبل العديد من صناع المحتوى الصينيين كأفضل سير عمل في شهر أبريل.
حدود الافتراضات: متى لا يكون عرض الحروف الصينية أمراً حاسماً؟
يجب أن أكون صريحاً معكم ككاتب، فهناك حدود لهذا الافتراض. إن معادلة "دقة الحروف الصينية = بوابة الانتشار في الوسط الصيني" لا تنطبق في الحالات التالية:
السيناريو 1: المحتوى المرئي الخالص الخالي من النصوص
في صور المناظر الطبيعية، صور البورتريه، أو صور المنتجات ذات الخلفية البيضاء التي لا تحتوي على نصوص أو تحتوي على القليل منها، لا يكون للفوارق بين أجيال النماذج تأثير يذكر على الانتشار في الوسط الصيني. في هذه السيناريوهات، قد يكون Nano Banana Pro أفضل (بسبب واقعيته الفوتوغرافية).
السيناريو 2: المجالات المتخصصة التي يسيطر عليها الوسط الصيني بالفعل
مثل الرسم بنمط الأنمي (ثنائي الأبعاد) أو الرسوم التوضيحية ذات الطابع الصيني التقليدي، حيث توجد بالفعل نماذج صينية قوية (مثل Jimeng و Kling و CogView)، لذا فإن ميزة GPT-image-2 ليست بتلك الضخامة.
السيناريو 3: نجاح اللحظة مقابل النظام البيئي طويل الأمد
النجاحات التي حدثت في شهر أبريل كانت مدفوعة بـ "أداة جديدة + مزايا الفترة الأولى". بعد بضعة أشهر، عندما يعتاد المستخدمون، لن يكون مجرد "كون الأداة جيدة" محفزاً للانتشار، بل سيعود التركيز للمنافسة على جودة المحتوى نفسه.
أمثلة مضادة للافتراض
هناك أمثلة تستحق التفكير:
- Nano Banana Pro يدعم أيضاً CJK (الصينية، اليابانية، الكورية): لكن شعبيته في الوسط الصيني لا تزال أقل من GPT-image-2. وهذا يعني أن "دقة الحروف الصينية" هي شرط ضروري ولكن ليس كافياً. إذ نحتاج أيضاً إلى تأثير علامة OpenAI التجارية، والتفاعل المتسلسل الذي بدأ في المجتمع الإنجليزي.
- النماذج الصينية تدعم CJK منذ فترة طويلة: لكن قدرتها على الانتشار لا تزال محدودة. وهذا يشير إلى أن الجمع بين "نموذج لغة كبير عالمي + اختراق في CJK" يخلق موضوعاً خاصاً ومثيراً للجدل في الوسط الصيني.
التقييم الشامل
التعريف الأكثر دقة هو: دقة الحروف الصينية هي "العتبة الضرورية" للانتشار في الوسط الصيني. وبعد تجاوز هذه العتبة، يعتمد الانتشار على عوامل متعددة مثل العلامة التجارية، بيئة المجتمع، والسعر. الإصدار 1.5 لم يتجاوز هذه العتبة فظل نطاقه محدوداً في الوسط الإنجليزي؛ بينما تجاوز الإصدار 2.0 هذه العتبة، مدعوماً بالعلامة التجارية العالمية لـ OpenAI وتفوقه بـ 242 نقطة في تصنيف Elo، مما شكل ظاهرة النجاح في أبريل.
مقترحات العمل لصناع المحتوى باللغة العربية لشهر أبريل حول GPT-image-2
إذا كنت تتفق مع القول بأن "دقة عرض الحروف الصينية/العربية = بوابة الانتشار"، فإن الفترة من أبريل 2026 إلى الربع الثالث من العام هي "نافذة الفرص" الحاسمة. فيما يلي مقترحات عملية مصنفة حسب طبيعة عملك.
صناع المحتوى الأفراد (منصات التواصل الاجتماعي)
خطة الأسبوع الأول:
- سجل في imagen.apiyi.com (يدعم الوصول المحلي) وجرب توليد 5-10 صور للتحقق من النتائج.
- استخدم
gpt-image-2-allلإعادة إنتاج 3-5 صور غلاف ناجحة في مجالك للعثور على القالب المثالي. - انتقل بسير عملك من "تصميم يدوي على Canva" إلى "توليد مباشر بواسطة الذكاء الاصطناعي + تعديلات طفيفة".
هدف الشهر الأول:
- تقليص وقت إنتاج أغلفة الصور من 30-60 دقيقة إلى 5-10 دقائق.
- إجراء اختبار A/B: قارن بين معدلات النقر للصور التي تم إنشاؤها بالذكاء الاصطناعي مقابل الطرق القديمة.
- حفظ 5-10 قوالب موجه (Prompt) مستقرة، مصنفة حسب نوع الموضوع.
التكلفة الرئيسية: إنتاج 100-200 صورة شهرياً عبر خدمة وكيل API من APIYI apiyi.com، بتكلفة شهرية تقريبية تبلغ 30-60 يوان.
محررو المحتوى / مديرو حسابات التواصل الاجتماعي
التحدي: إنتاج 1-3 منشورات يومياً = 3-9 صور يومياً = 90-270 صورة شهرياً.
تقدير العائد: إذا كانت تكلفة التصميم الخارجي للصورة الواحدة 30-50 يوان، فإن الميزانية الشهرية تتراوح بين 3000-13500 يوان. بالانتقال إلى GPT-image-2 + APIYI، تنخفض التكلفة الشهرية إلى 30-80 يوان، مما يوفر أكثر من 99%.
نصيحة جوهرية: استثمر جزءاً من الميزانية الموفرة في تحسين هندسة الموجهات (Prompt Engineering) واختبارات A/B، فمعدل النجاح المحسن هو العائد الحقيقي على الاستثمار (ROI).
إدارة التجارة الإلكترونية
سيناريوهات الاستخدام:
- صور تفاصيل المنتج (تتضمن الأسعار والمواصفات بالعربية).
- صور غلاف الفعاليات (تتضمن نصوصاً ترويجية).
- صور نتائج البحث (تتضمن اسم المنتج).
المنهجية العملية: ابدأ باستخدام أداة imagen.apiyi.com لتشغيل 50 اختباراً لنشاطك التجاري. بعد التأكد من أن أكثر من 80% من النتائج قابلة للنشر، انتقل إلى استدعاء نموذج gpt-image-2-all عبر APIYI apiyi.com ($0.03 للصورة) للإنتاج الضخم.
تحذير من خطأ شائع: لا تستبدل جميع صور التفاصيل بالذكاء الاصطناعي فجأة؛ يُنصح بأن تخضع الصور الرئيسية للمراجعة البشرية، بينما تُستخدم الصور الثانوية وصور نمط الحياة بشكل موسع عبر الذكاء الاصطناعي. هذا "تقسيم العمل بين الإنسان والآلة" هو سير العمل الأكثر استقراراً الذي اعتمدته فرق التجارة الإلكترونية الرائدة في أبريل.
العلامات التجارية الموجهة للأسواق العربية من الخارج
ميزة فريدة: كانت الفرق الأجنبية تضطر لتوظيف مصممين محليين للوصول للسوق العربي، مما يزيد تكاليف التواصل ويبطئ وتيرة العمل. يتيح GPT-image-2 لهذه الفرق إنتاج مواد باللغة العربية بجودة عالية مباشرة.
سير العمل الموصى به:
- تكتب الفرق الأجنبية متطلبات المحتوى بالإنجليزية (وهذه نقطة قوة في قدرات OpenAI متعددة اللغات).
- استخراج المواد الأساسية عبر API خدمة وكيل APIYI apiyi.com (
gpt-image-2بجودة عالية). - استخدام أدوات التعرف الضوئي على الحروف (OCR) للتحقق من دقة النصوص كخطوة لضمان الجودة.
- إجراء تعديلات طفيفة من قبل الفريق المحلي عند الضرورة، مما يقلل ساعات العمل بنسبة 80%+.
قطاع النشر / التعليم / العلوم
سيناريوهات الاستخدام:
- الرسوم التوضيحية العلمية (مع مصطلحات تقنية بالعربية).
- مواد العروض التعليمية (مع معادلات وتوضيحات بالعربية).
- رسوم الكتب (مع خطوط كلاسيكية).
القيمة الخاصة: هذه المجالات كانت مهملة تماماً من قبل نماذج توليد الصور سابقاً. لكن دقة GPT-image-2 التي تصل إلى 99% في لغات CJK (واللغات المماثلة) تجعل هذه المجالات "المتخصصة عالية الجودة" قابلة للتسويق لأول مرة.
المدونون التقنيون / صناع محتوى الذكاء الاصطناعي
نافذة الفرص: لا تزال الفترة من أبريل إلى يونيو نافذة "لفجوة المعلومات"؛ فالكثير من المستخدمين لا يزالون يجهلون هذا التطور. صناعة محتوى تعليمي حول GPT-image-2 باللغة العربية تضمن تدفقاً عالياً للزيارات.
نصيحة للمحتوى: بدلاً من كتابة محتوى موسوعي، ركز على محتوى متخصص وعملي مثل "مكتبة موجهات GPT-image-2" أو "كيفية إعادة إنتاج ملصقات بنمط معين"، فهذه المواضيع تجذب جمهوراً أوسع.
🎯 توصية العمل المركز: بغض النظر عن هويتك، الخطوة الأولى بأقل تكلفة هي: سجل في APIYI apiyi.com → اشحن بمبلغ 10-20 يوان لتشغيل 50-100 صورة تجريبية عبر
gpt-image-2-all→ ابحث عن 3-5 قوالب موجه مستقرة → دمجها في سير عملك الأساسي. هذه العملية يمكن إنجازها في أسبوع واحد وبتكلفة زهيدة، لكنها تضمن لك اقتناص فرصة الربع الثاني والثالث من عام 2026.
لماذا يحظى GPT-image-2 بشعبية أكبر من الإصدار 1.5؟ أسئلة شائعة
س1: هل دقة العرض بالعربية في GPT-image-2 تصل فعلاً إلى 99%؟
وفقاً لاختبارات LM Arena، فإن دقة GPT-image-2 في أحرف CJK (والأنظمة الشبيهة) تصل إلى حوالي 99%. لكنها دقة على مستوى الحرف وليست 100%. لا تزال هناك أخطاء في حالات متطرفة: 1) نصوص صغيرة جداً أقل من 5 نقاط؛ 2) مصطلحات نادرة جداً؛ 3) تداخل معقد في التصميم. أما العناوين الشائعة (8 نقاط فما فوق)، والعناوين الفرعية، والأسعار، والتواريخ، فهي دقيقة جداً. نوصي بتجربة النموذج عبر gpt-image-2-all على APIYI apiyi.com للتحقق من حالتك الخاصة.
س2: هل GPT Image 1.5 غير قابل للاستخدام فعلياً في النصوص العربية؟
ليس "غير قابل للاستخدام كلياً"، بل هو "غير موثوق". احتمالية نجاح النصوص القصيرة (3-6 أحرف) هي 70-80%، مما يعني أن كل 5 صور تتطلب إعادة توليد أو إصلاح بـ Photoshop. هذا عيب قاتل للإنتاج التجاري الضخم؛ فهو يعني معدل فشل بنسبة 20% وهدر في ساعات العمل. لهذا السبب كان من الصعب على صناع المحتوى اعتماد الإصدار 1.5 في سير عملهم.
س3: أليس أداء النماذج المحلية أفضل في التعامل مع النصوص العربية؟
تتميز النماذج المحلية (مثل Jimeng، Kling، CogView) بدعم جيد نسبياً، وتقترب في بعض المؤشرات من GPT-image-2. ولكن عند النظر إلى "دقة النص + جودة الصورة + القدرة على الاستنتاج + تداخل اللغات"، يظل GPT-image-2 هو الأقوى في أبريل 2026. نصيحة للاختيار: 1) النماذج المحلية مناسبة للمشاهد التي تتضمن نصوصاً عربية فقط؛ 2) GPT-image-2 مناسب للمشاهد التي تدمج بين العربية والإنجليزية، وتتضمن مصطلحات تقنية أو تتطلب جودة فنية عالية.
س4: هل مجرد دقة عرض الحروف كافٍ لإحداث ضجة حول النموذج؟
ليس بالضرورة، فهو شرط ضروري ولكنه ليس كافياً. بالإضافة إلى دقة الحروف، يحتاج الأمر إلى: 1) سهولة الوصول؛ 2) سعر معقول؛ 3) مجتمع مبكر يقوم بنشر التجربة. السبب في نجاح GPT-image-2 في أبريل هو تكامل عوامل عدة: تأثير علامة OpenAI التجارية + ترتيب LM Arena + تفوق Elo + توفر منصات وسيطة مثل APIYI ($0.03 للصورة).
س5: كيف يمكن لصناع المحتوى الأفراد البدء بأسرع وقت؟
ثلاث مسارات من الأقل إلى الأعلى تكلفة: 1) استخدام أداة imagen.apiyi.com المباشرة (بدون برمجة، واجهة عربية)؛ 2) الاشتراك في ChatGPT Plus بقيمة 20 دولاراً شهرياً (يتطلب حساباً خارجياً)؛ 3) الوصول عبر APIYI apiyi.com باستخدام نموذج gpt-image-2-all لتوليد كميات كبيرة بسعر 0.03 دولار للصورة. ننصح باستخدام أداة الويب لتجربة الموجهات أولاً، ثم استخدام الـ API للإنتاج المكثف.
س6: هل ستفقد هذه الملاحظات قيمتها بمرور الوقت؟
نعم. الفترة الحالية هي نافذة انتقالية لتزامن "الأدوات + النماذج + المنصات". يُتوقع أن تضعف فرضية "دقة الحروف = بوابة الانتشار" في الحالات التالية: 1) لحاق النماذج المحلية بدقة 99% (في غضون 6-12 شهراً)؛ 2) اعتياد المستخدمين على صور الذكاء الاصطناعي (بعد 1-2 سنة)؛ 3) ظهور وسائط نشر جديدة (فيديو قصير، AR). لكن خلال الفترة من أبريل إلى ديسمبر 2026، ستظل هذه الفرضية قائمة بقوة.
س7: هل هناك نصائح لتجنب الأخطاء عند تصميم ملصقات بالعربية بـ GPT-image-2؟
ثلاث نصائح رئيسية: 1) يجب وضع النصوص المهمة بين علامتي تنصيص: title: "خصومات الربيع"؛ 2) بالنسبة للأسماء المعقدة أو الحروف ذات التشكيل الخاص، يُنصح بتوليد 4 صور واختيار الأفضل منها؛ 3) عند الدمج بين العربية والإنجليزية، حدد نمط الخط بشكل صريح (Chinese: SimSong style, English: Helvetica style) لتجنب تضارب تباعد الأحرف. استخدم APIYI apiyi.com للتجربة بتكلفة منخفضة قبل الإنتاج.
س8: كيف يمكنني التحقق من صحة هذه الآراء بنفسي؟
يمكنك التحقق بثلاث طرق: 1) تحليل البيانات: مراقبة بيانات محتوى "GPT-image-2" على المنصات ومقارنتها بنتائج الإصدار 1.5؛ 2) التجارب المقارنة: استخدام نفس الموجه في نماذج مختلفة وتكليف مستخدمين بتقييم النتائج؛ 3) مقابلات صناع المحتوى: تسجيل تغيرات سير العمل لدى المستخدمين الذين جربوا كلا الإصدارين. يمكن تنفيذ كل هذا بمرونة عبر بيئة الاختبار التي توفرها APIYI apiyi.com.
لماذا حقق GPT-image-2 نجاحاً أكبر بكثير من إصدار 1.5؟ – أهم النقاط
- المؤشر الجوهري للقفزة الجيلية: رفع GPT-image-2 دقة عرض أحرف CJK (الصينية واليابانية والكورية) من "غير موثوق" في الإصدار 1.5 (~80%) إلى دقة على مستوى الحرف بنسبة 99%، وهي أكبر قفزة في مجال توليد الصور بالذكاء الاصطناعي خلال الاثني عشر شهراً الماضية.
- طبيعة وسائط الانتشار في العالم العربي والصيني تحدد كل شيء: منصات مثل "شياو هونغ شو"، والحسابات الرسمية، والملصقات التعبيرية (Meme)، وصفحات تفاصيل التجارة الإلكترونية؛ كلها تعتمد بشكل أساسي على صور تحتوي على نصوص. لذا، فإن "عرض الحروف العربية/الصينية" هو الحاجز التقني الحقيقي لانتشار أي أداة.
- معوقات سير العمل في عصر 1.5: كان على المبدعين التعامل مع الصور عبر برنامج Photoshop لإضافة النصوص، مما خفّض دور الذكاء الاصطناعي من "أداة رئيسية" إلى "أداة مساعدة" فقط، مما جعل من الصعب اعتماده في الإنتاج اليومي.
- إصدار 2.0 فكّ طلاسم ثلاثة عوائق تقنية: الجمع بين الاستنتاج في سلسلة O، وتوسيع بيانات تدريب CJK، وآلية العرض على مستوى الحرف؛ هذه العناصر الثلاثة شكلت الأساس لتحقيق دقة 99%.
- نجاح شهر أبريل ليس صدفة: هناك 4 أنماط ناجحة مستمرة حالياً: إعادة إنتاج الملصقات، مصانع الملصقات التعبيرية، الملصقات التجارية الواقعية، وتطبيقات العلامات التجارية الموجهة للخارج.
- حدود الافتراضات: "دقة عرض الحروف" هي شرط ضروري للانتشار وليست شرطاً كافياً، إذ يجب تضافر عوامل مثل العلامة التجارية والسعر والمنصة. مثال ذلك نموذج Nano Banana Pro الذي يدعم CJK لكن انتشاره أقل من GPT-image-2.
- الفرصة الآن: من المتوقع أن تلحق النماذج المحلية بالركب خلال 6-12 شهراً، لذا فإن انضمام المبدعين الآن يعد من أكثر فرص المحتوى المؤكدة لعام 2026.
- طريقة التحقق بأقل تكلفة: يوفر منصة APIYI (apiyi.com) نموذج
gpt-image-2-allبسعر 0.03 دولار للصورة الواحدة، حيث يكفي اختبار 10 صور (بتكلفة 0.3 دولار تقريباً) للتحقق من الفرق الحقيقي.
الخلاصة
بالعودة إلى السؤال الافتتاحي: "لماذا حقق GPT-image-2 نجاحاً أكبر بكثير من 1.5؟"
الإجابة المختصرة هي: لأنه اجتاز حاجز "دقة عرض الحروف" الذي كان يعيق الانتشار في البيئة الصينية. في عصر 1.5، انتشر توليد الصور بالذكاء الاصطناعي في الغرب، لكنه تعثر في البيئة الصينية بسبب "عدم إمكانية استخدام الحروف". أما إصدار 2.0 فقد رفع دقة عرض الحروف إلى 99%، مما جعل سير عمل المبدعين يعمل بسلاسة لأول مرة، وهو ما أشعل سلسلة الانتشار.
هذه ليست مجرد قصة "تحديث نموذج" منعزلة، بل هي حالة لمؤشر تقني محدد (دقة أحرف CJK من 80% إلى 99%) أدى إلى تحريك نظام بيئي كامل (وسائط الانتشار عبر الإنترنت). فهم هذا الارتباط يساعدنا على تقييم إمكانات أي نموذج ذكاء اصطناعي مستقبلاً؛ فلا تنظر إلى أرقام الأداء، بل انظر إلى دقة الحروف.
بالنسبة لصناع المحتوى وفرق التسويق في 2026، فإن قرار "دمج GPT-image-2" لم يعد سؤالاً حول "هل نستخدم الذكاء الاصطناعي؟"، بل هو سؤال حول "عدم الاستخدام الآن يعني ضياع فرصة ذهبية". نوصي بالتحقق فوراً من تأثيره في مجالك الخاص عبر منصة APIYI (apiyi.com) بأقل تكلفة، ثم اتخاذ قرار الإدراج في سير عملك بناءً على بيانات حقيقية.
أخيراً، هذه الملاحظات هي مجرد تسجيل وتحليل لظاهرة أبريل 2026، وليست حكماً نهائياً. نرحب بجميع المبدعين لتقديم إضافاتهم أو تصحيحاتهم أو حتى نقدهم بناءً على تجاربهم العملية.
المراجع
-
الإعلان الرسمي لـ OpenAI ChatGPT Images 2.0: ملاحظات إصدار GPT-image-2
- الرابط:
openai.com/index/introducing-chatgpt-images-2-0 - الوصف: النص الرسمي حول دقة النصوص متعددة اللغات بنسبة 99%.
- الرابط:
-
لوحة صدارة تحويل النص إلى صورة في LM Arena: تصنيف Elo للنماذج
- الرابط:
arena.ai/leaderboard/text-to-image - الوصف: GPT-image-2 يحصل على 1512 نقطة Elo · التحقق من الدقة على مستوى الحروف.
- الرابط:
-
تقرير TechCrunch بتاريخ 21 أبريل: نموذج ChatGPT Images 2.0 الجديد جيد بشكل مدهش في توليد النصوص
- الرابط:
techcrunch.com/2026/04/21/chatgpts-new-images-2-0-model-is-surprisingly-good-at-generating-text - الوصف: تغطية إعلامية تقنية أولية خلال 24 ساعة من الإطلاق.
- الرابط:
-
The New Stack – OpenAI تفكر الآن قبل أن ترسم: تقرير معمق حول آلية الاستدلال
- الرابط:
thenewstack.io/chatgpt-images-20-openai - الوصف: تحليل دور استدلال سلسلة O في عرض الحروف الصينية.
- الرابط:
-
الوثائق التقنية لترميز CJK: لماذا تعاني نماذج اللغة الكبيرة من ضعف التعامل مع الصينية لفترة طويلة
- الرابط:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - الوصف: التحديات التقنية الأساسية في معالجة لغات CJK.
- الرابط:
-
منصة APIYI: الربط المحلي لـ GPT-image-2
- الرابط:
apiyi.com - الوصف: خدمة وكيل API رسمية + API عكسي (gpt-image-2-all بسعر 0.03 دولار للصورة).
- الرابط:
الكاتب: الفريق التقني في APIYI | لتجربة قدرات عرض اللغة الصينية في GPT-image-2، تفضل بزيارة APIYI عبر apiyi.com للتسجيل والحصول على رصيد تجريبي، أو جربه عبر الإنترنت على imagen.apiyi.com (يمكن الوصول إليه مباشرة من داخل الصين).