في 24 أبريل 2026، أطلقت DeepSeek كلاً من V4-Pro و V4-Flash كمصادر مفتوحة. إذا كان إصدار Flash يمثل "الخيار الاقتصادي الأمثل"، فإن V4-Pro يمثل فئة مختلفة تماماً من المنتجات:
إنه حالياً أقوى نموذج لغة كبير مفتوح المصدر في مجال البرمجة.
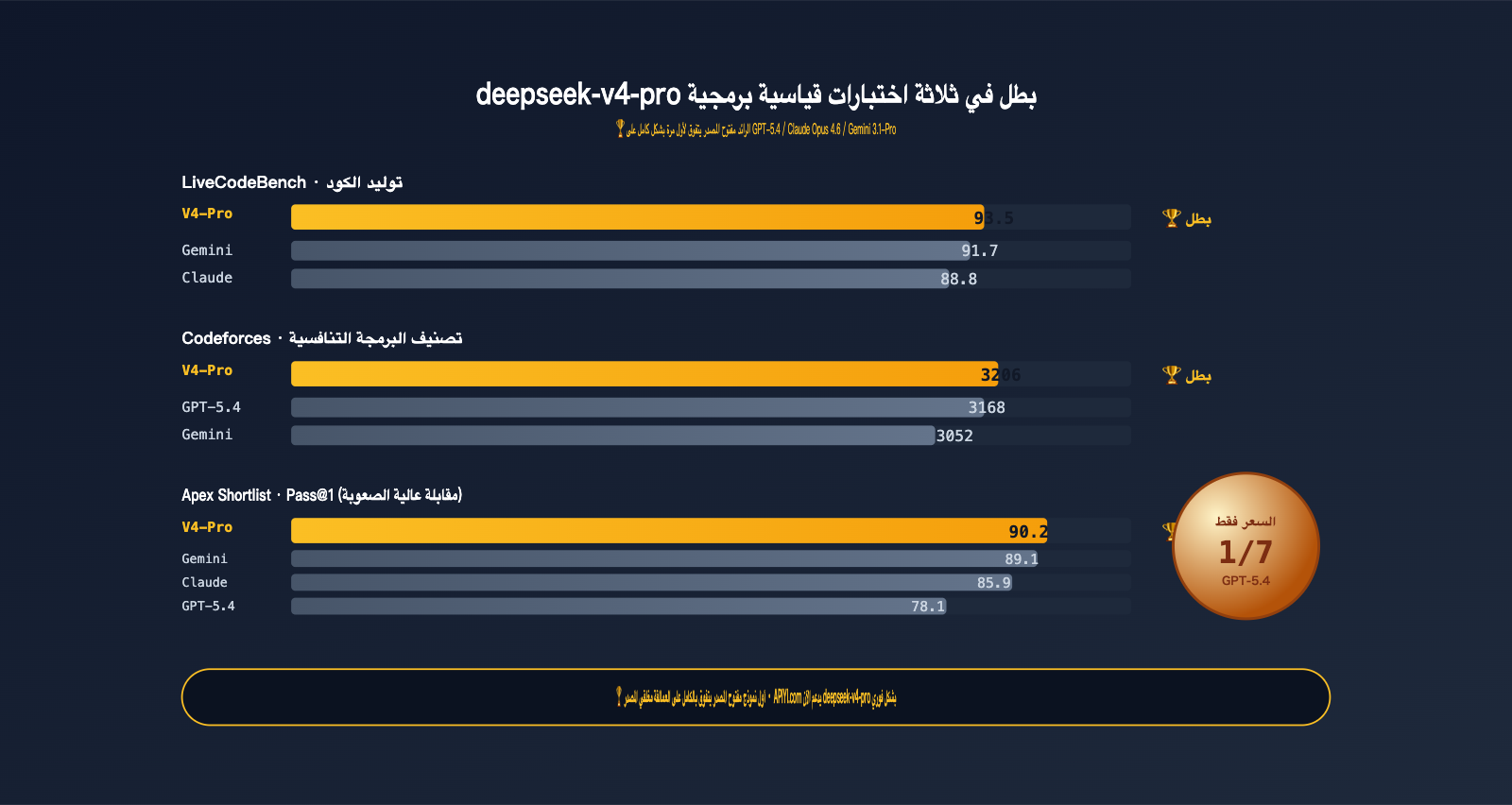
هذا ليس مجرد تعبير مجازي عن تفوقه في عالم المصادر المفتوحة، بل هو تفوق رقمي صريح يتجاوز نماذج GPT-5.4 و Claude Opus 4.6 و Gemini 3.1-Pro في الاختبارات المعيارية:
- LiveCodeBench 93.5 — المركز الأول، متفوقاً على Gemini 3.1-Pro (91.7) و Claude Opus 4.6 (88.8).
- Codeforces Rating 3206 — متفوقاً على GPT-5.4 (3168) و Gemini 3.1-Pro (3052).
- Apex Shortlist Pass@1 90.2 — بفارق كبير عن GPT-5.4 (78.1) و Claude (85.9).
- IMOAnswerBench 89.8 — في مسائل الرياضيات التنافسية، تفوق على Claude Opus 4.6 (75.3) بفارق 14 نقطة كاملة.
تأتي هذه القدرات بفضل مواصفات تقنية مذهلة: 1.6 تريليون بارامتر إجمالي / 49 مليار بارامتر نشط / 32 تريليون توكن للتدريب المسبق / نافذة سياق 1 مليون توكن / 384 ألف توكن للمخرجات، بالإضافة إلى الابتكارات المعمارية الأربعة التي صممتها DeepSeek خصيصاً لسلسلة V4: وهي Hybrid Attention، و Manifold-Constrained Hyper-Connections (mHC)، و Engram Conditional Memory، و Muon Optimizer.
أصبح نموذج deepseek-v4-pro متاحاً الآن على خدمة وكيل API، APIYI (apiyi.com)، حيث يمكنك استخدامه عبر بروتوكول OpenAI أو Anthropic SDK دون الحاجة لأي تعديلات برمجية، وبتكلفة لا تتجاوز 1/7 من سعر GPT-5.4.
لن نكرر في هذا المقال أساسيات "كيفية الانتقال أو اختيار النماذج الاقتصادية" التي تناولناها في مقال Flash — هذا الدليل مخصص للمؤمنين بقدرات deepseek-v4-pro التقنية:
- 3 دقائق لفهم لماذا يستحق Pro لقب "النموذج الرائد" (البنية + البيانات + النطاق).
- 4 جداول للمقارنة المعيارية، لتوضيح ساحات التفوق والضعف.
- 5 دقائق للربط البرمجي + تجربتان عمليتان في سيناريوهات البرمجة والرياضيات.

أولاً: القدرات الأربع الرائدة لنموذج deepseek-v4-pro
1.1 جدول المواصفات الأساسية
| البعد | deepseek-v4-pro |
|---|---|
| تاريخ الإصدار | 24-04-2026 (نسخة تجريبية) |
| مستودع المصدر المفتوح | huggingface.co/deepseek-ai/DeepSeek-V4-Pro |
| إجمالي المعلمات | 1.6 تريليون (خليط من الخبراء – MoE) |
| المعلمات النشطة | 49 مليار |
| بيانات التدريب المسبق | أكثر من 32 تريليون رمز (tokens) |
| نافذة السياق | 1 مليون رمز |
| الحد الأقصى للمخرجات | 384 ألف رمز |
| ابتكارات البنية | Hybrid Attention + mHC + Engram Memory + Muon |
| نمط الاستدلال | نمط مزدوج (تفكير / غير تفكير) |
| استدعاء الدوال (Function Calling) | ✅ مدعوم |
| نمط JSON | ✅ مدعوم |
| بروتوكول API | متوافق مع OpenAI و Anthropic |
| سعر المدخلات | $1.74 لكل مليون رمز |
| سعر المخرجات | $3.48 لكل مليون رمز |
تذكر الأرقام الأربعة الأكثر أهمية: 1.6T / 49B / 32T / 1M — هذه هي الركائز الأساسية لهذا النموذج الرائد.
1.2 بنية 1.6T / 49B MoE: "سقف المصدر المفتوح" في الحجم
يحتوي DeepSeek-V4-Pro على 1.6 تريليون معلمة إجمالية، ويستخدم بنية "خليط من الخبراء" (MoE)، حيث يتم تفعيل 49 مليار معلمة فقط لكل رمز. إليك دلالة هذه الأرقام:
| النموذج | إجمالي المعلمات | المعلمات النشطة | النوع |
|---|---|---|---|
| Llama 3 70B | 70B | 70B | كثيف (تفعيل كامل) |
| Mistral Large 2 | 123B | 123B | كثيف |
| DeepSeek-V3.2 | 671B | 37B | MoE |
| DeepSeek-V4-Pro | 1.6T | 49B | MoE ⭐ |
| Claude Opus 4.6 | غير معلن | غير معلن | مغلق المصدر |
تمنح إجمالي المعلمات البالغ 1.6 تريليون النموذج نطاقاً معرفياً يقترب من مستوى GPT-5.4 / Claude Opus، بينما تجعل المعلمات النشطة البالغة 49 مليار تكلفة استدلال الرمز الواحد تحت السيطرة — وهذا هو السبب الجوهري وراء نجاح بنية MoE في تحقيق أداء متطور.
1.3 التدريب المسبق بـ 32 تريليون رمز: طاقة بيانات هائلة
بيانات التدريب المسبق > 32 تريليون رمز
هذا رقم مذهل بكل المقاييس:
- بيانات تدريب GPT-4 تبلغ حوالي 13 تريليون رمز (وفقاً لتقديرات الصناعة)
- Llama 3 يبلغ 15 تريليون رمز
- DeepSeek-V3 يبلغ 14.8 تريليون رمز
- DeepSeek-V4-Pro: أكثر من 32 تريليون رمز ⭐
الفوائد المباشرة لمضاعفة حجم البيانات هي: تغطية أشمل للمعرفة الطويلة، تحديث أسرع لبيانات البرمجة، وقاعدة بيانات رياضية أعمق — وهذا هو السبب الجوهري وراء تصدر V4-Pro في اختبارات LiveCodeBench و IMOAnswerBench.
1.4 أربعة ابتكارات معمارية: الميزة التنافسية الحقيقية لـ Pro
هذا هو الفارق الجوهري بين V4-Pro وأي "نموذج MoE آخر". إليك الابتكارات الأربعة الرئيسية التي كشفت عنها الشركة:
| الابتكار | الاسم الكامل | المشكلة التي يحلها |
|---|---|---|
| Hybrid Attention | انتباه هجين (CSA + HCA) | مشاكل العمليات الحسابية وذاكرة الفيديو في استدلال السياق الطويل (1M) |
| mHC | اتصالات فائقة مقيدة بالمتشعبات | استقرار اتصالات البقايا العميقة، منع تلاشي/انفجار التدرج |
| Engram | ذاكرة شرطية Engram | فصل "الحقائق الثابتة" عن "قدرات الاستدلال"، تحديث أسهل للحقائق |
| Muon | محسن Muon | سرعة تقارب التدريب واستقراره، خفض تكاليف التدريب |
كل ابتكار يستحق التوضيح:
-
Hybrid Attention (CSA + HCA): تعقيد الانتباه في Transformer التقليدي هو O(n²)، مما يؤدي لانهيار النظام عند سياق 1M. يستخدم V4 الانتباه المتناثر المضغوط (CSA) للتصفية الخشنة، والانتباه المضغوط بشدة (HCA) للتركيز الدقيق، مما يقلل العمليات الحسابية إلى 27% من V3.2، ويستهلك ذاكرة KV بنسبة 10% فقط. هذا هو سر قدرة deepseek-v4-pro على التعامل مع سياق 1M.
-
mHC: عند تدريب نماذج MoE العميقة، تتشوه إشارات اتصالات البقايا بعد عشرات الطبقات. يضيف mHC قيوداً في فضاء المتشعبات لجعل انتشار الإشارة أكثر استقراراً. عملياً: يمكن تدريب النموذج ليكون أعمق وأطول دون أن ينهار.
-
Engram Conditional Memory: ابتكار هندسي بحت. يفصل بين "الحقائق في ذاكرة النموذج" و"قدرات الاستدلال" — تُخزن الحقائق في وحدة ذاكرة مخصصة، بينما يسلك مسار الاستدلال طريقاً آخر. النتيجة هي أنه عند تحديث المعرفة العالمية، لا نحتاج إلى إعادة تدريب النموذج بالكامل، مما يقلل تكاليف إصدار النسخ المستقبلية بشكل كبير.
-
Muon Optimizer: محسن طورته DeepSeek ذاتياً، يتميز بتقارب أسرع واستقرار أفضل مقارنة بـ AdamW. في مقياس تدريب التريليونات، يعني هذا تدريباً أكثر كفاءة بنفس القدرة الحسابية.
🎯 رؤية تقنية: deepseek-v4-pro ليس مجرد تكبير لبنية قديمة، بل هو إعادة كتابة للبنية التحتية بالكامل. هذا هو السبب الجوهري وراء وصوله إلى مستوى عمالقة النماذج مغلقة المصدر وهو مفتوح المصدر. إذا كنت تخطط لاستخدامه بعمق، ننصحك بتجربة مجموعة من الموجهات (prompts) النموذجية عبر خدمة APIYI (apiyi.com) لتشعر بالفرق الذي أحدثته ترقية البنية — خاصة في سيناريوهات السياق الطويل والاستدلال متعدد الخطوات.
1.5 سياق 1M + مخرجات 384K: نقطة التحول في توليد النصوص الطويلة
تتطابق مواصفات السياق في Pro و Flash (مدخلات 1M، مخرجات 384K). لكن ميزة Pro لا تكمن في "طول القراءة"، بل في "عمق التفكير ضمن 1M".
الأهمية العملية لسيناريوهات النصوص الطويلة:
| المهمة | عصر V3.2 | عصر V4-Pro |
|---|---|---|
| تعديل كامل لمخطوطة 500 ألف كلمة | يتطلب التقسيم إلى 10+ أجزاء | معالجة دفعة واحدة في نافذة 1M |
| أسئلة وأجوبة حول وثائق تقنية من 200 صفحة | يتطلب بناء RAG | إدخال مباشر للنص |
| تدقيق مستودع برمجيات متوسط | تحليل ملخص | فحص الاتساق بين الملفات |
| تماسك كتابة الروايات | يتطلب إدارة الذاكرة يدوياً | مخرجات 384K في دفعة واحدة متماسكة |
ثانياً: عرش المعايير لنموذج deepseek-v4-pro

2.1 القدرة البرمجية: deepseek-v4-pro يتصدر القائمة
لنلقِ نظرة على البيانات الأكثر دقة — القدرة على البرمجة:
| المعيار | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro | المركز الأول |
|---|---|---|---|---|---|
| LiveCodeBench | 93.5 | — | 88.8 | 91.7 | V4-Pro 🏆 |
| Codeforces Rating | 3206 | 3168 | — | 3052 | V4-Pro 🏆 |
| Apex Shortlist Pass@1 | 90.2 | 78.1 | 85.9 | 89.1 | V4-Pro 🏆 |
| SWE-bench Verified | 80.6–82.1 | — | 80.8 | 80.6 | تعادل |
| Terminal-Bench 2.0 | 67.9 | 75.1 | 65.4 | 68.5 | GPT-5.4 |
ثلاثة مراكز صدارة، ومركزان "تعادل أو خسارة طفيفة". لأول مرة يتفوق نموذج مفتوح المصدر على العمالقة مغلقي المصدر في القدرة البرمجية — وهو حدث فارق في عام 2026.
تفسير النتائج:
- LiveCodeBench 93.5: يتم تحديث أسئلة LiveCodeBench شهرياً لتجنب تلوث بيانات التدريب. تشير نتيجة 93.5 لـ V4-Pro إلى أن قدرته البرمجية عامة وقادرة على حل أسئلة جديدة، وليست مجرد حفظ لقاعدة البيانات.
- Codeforces 3206: تقييم برمجة المسابقات، 3206 نقطة تقترب من مستوى IGM (أستاذ دولي كبير). هذا التقييم كافٍ تماماً للتعامل مع البرمجة التجارية اليومية.
- Apex Shortlist Pass@1 90.2 مقابل GPT-5.4 78.1: هذا الفارق منهجي. Apex Shortlist هي مجموعة أسئلة مقابلات عالية الصعوبة، وقد تفوق V4-Pro بفارق 12 نقطة مئوية كاملة.
- Terminal-Bench 2.0 (أضعف قليلاً): هذا المعيار يقيس القدرة على استخدام أدوات سطر الأوامر متعددة الخطوات. لا يزال GPT-5.4 يتفوق هنا، مما يعني أن GPT-5.4 لا يزال يمتلك ميزة في سيناريوهات "الوكيل (Agent) المعقد متعدد الخطوات".
2.2 الرياضيات والاستدلال: deepseek-v4-pro يقترب من القمة
في بُعد الرياضيات، يتنافس Pro مع العمالقة مغلقي المصدر، لكنه ليس متفوقاً في كل شيء:
| المعيار | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | 87.5 | 89.1 | 91.0 |
| IMOAnswerBench | 89.8 | 91.4 | 75.3 | 81.0 |
| HMMT 2026 | 95.2 | 97.7 | 96.2 | — |
| MATH | 92% | — | — | — |
| HumanEval | 90% | — | — | — |
| MMLU | 89% | — | — | — |
نقطة القوة في IMOAnswerBench: مجموعة أسئلة أولمبياد الرياضيات الدولي، حيث سجل V4-Pro 89.8 نقطة، متفوقاً على Claude Opus 4.6 بفارق 14.5 نقطة، وعلى Gemini 3.1-Pro بفارق 8.8 نقطة. بالنسبة للمهام عالية المستوى مثل الاستدلال الرياضي والإثبات الصوري، يعد Pro سقف النماذج مفتوحة المصدر حالياً.
نقطة الضعف في MMLU-Pro (المعرفة العامة): تعادل Pro مع GPT-5.4 بـ 87.5 نقطة، لكنه يتأخر عن Gemini 3.1-Pro بـ 3.5 نقطة. في سيناريوهات الأسئلة والأجوبة حول المعرفة العامة، لا يزال Gemini يتمتع بميزة معينة.
2.3 خريطة توزيع المعارك: أين يربح deepseek-v4-pro وأين يخسر؟
| الميدان | البطل | موقع V4-Pro |
|---|---|---|
| توليد الكود (LiveCodeBench) | V4-Pro 🏆 | بطل |
| برمجة المسابقات (Codeforces) | V4-Pro 🏆 | بطل |
| مقابلات عالية الصعوبة (Apex) | V4-Pro 🏆 | بطل (تفوق كبير) |
| هندسة البرمجيات (SWE-bench) | تعادل | تعادل في المركز الأول |
| أولمبياد الرياضيات (IMO) | GPT-5.4 | الثاني (يتفوق بكثير على Claude/Gemini) |
| المعرفة العامة (MMLU-Pro) | Gemini 3.1-Pro | الثالث |
| سلسلة أدوات متعددة الخطوات (Terminal-Bench) | GPT-5.4 | الثاني |
| استدلال الاتساق (HMMT) | GPT-5.4 | الثالث |
الخلاصة: إذا كان عبء عملك يعتمد بشكل أساسي على الكود البرمجي، فإن deepseek-v4-pro هو أحد أقوى الخيارات على وجه الأرض حالياً (سواء مفتوح أو مغلق المصدر). إذا كان عملك يعتمد على سلسلة أدوات الوكيل (Agent) متعددة الخطوات، فلا يزال GPT-5.4 يتمتع بميزة طفيفة؛ وإذا كان يعتمد على الأسئلة والأجوبة العامة، فإن Gemini 3.1-Pro هو الأقوى.
🎯 نصيحة للاختيار: ننصحك بتجربة مجموعة من الموجهات (prompts) النموذجية لعملك عبر APIYI (apiyi.com) لإجراء مقارنة AB بين V4-Pro والنماذج الحالية (20-50 موجه كافية). لا تعتمد على المعايير العامة لاتخاذ قرار الاختيار — توزيع الموجهات الخاص بك هو المعيار الحقيقي. للمقارنات الجماعية، نوصي باستخدام خط التزامن العالي
vip.apiyi.com.
ثالثاً: استدعاء deepseek-v4-pro عبر APIYI (apiyi.com) في 5 دقائق
3.1 الخطوة 1: الحصول على المفتاح واختيار المسار
البيئة المطلوبة: Python 3.8+ أو Node.js 18+، مع استخدام مكتبة OpenAI SDK أو Anthropic SDK الرسمية.
الحصول على المفتاح (Key):
- قم بزيارة موقع APIYI
apiyi.com، ثم توجه إلى لوحة التحكم (Console) ← مفاتيح API (API Keys) ← إنشاء مفتاح جديد. - يُنصح بتعيين حد يومي منفصل للمفتاح المخصص لنموذج Pro (مثلاً 200–500 يوان، حسب حجم عملك).
- انسخ المفتاح الذي يبدأ بـ
sk-.
اختيار المسار (ثلاثة مسارات تشترك في مفتاح واحد):
| base_url | الاستخدام |
|---|---|
https://api.apiyi.com/v1 |
الاستدعاءات اليومية، سيناريوهات التفاعل |
https://vip.apiyi.com/v1 |
المهام الجماعية، التزامن العالي |
https://b.apiyi.com/v1 |
مسار احتياطي عند حدوث اضطراب في الموقع الرئيسي |
3.2 الخطوة 2: الحد الأدنى لاستدعاء Python (بدون تفكير)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "أنت مهندس برمجيات بايثون خبير."},
{"role": "user", "content": "اكتب كود LRU cache جاهز للإنتاج في 30 سطراً."},
],
max_tokens=2048,
)
print(resp.choices[0].message.content)
قم بتعديل قيمتين فقط: base_url و model — أما باقي كود OpenAI SDK فلا يحتاج إلى أي تغيير.
3.3 الخطوة 3: تفعيل وضع التفكير (القيمة الحقيقية لـ Pro)
تظهر القيمة الحقيقية لنموذج deepseek-v4-pro عند تفعيل وضع التفكير (Thinking). النتائج القياسية مثل IMOAnswerBench 89.8 و LiveCodeBench 93.5 تم قياسها جميعاً باستخدام هذا الوضع.
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": """
يرجى تنفيذ محدد معدل (Rate Limiter) من نوع token bucket آمن للتزامن، مع مراعاة:
1. دعم تعديل المعدل ديناميكياً
2. دعم حجز حركة المرور المفاجئة (Burst)
3. التنفيذ بدون أقفال (CAS أو عمليات ذرية)
4. تضمين اختبارات وحدة كاملة
"""},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=16384,
)
print("--- عملية التفكير ---")
print(resp.choices[0].message.reasoning_content)
print("\n--- الإجابة النهائية ---")
print(resp.choices[0].message.content)
عند ضبط effort=high سيقوم نموذج Pro بتخطيط عميق جداً؛ ستراه يحلل المتطلبات أولاً، ثم يصمم واجهة البرمجة (API)، ثم يناقش حلولاً مختلفة، وأخيراً يقدم الكود. هذا هو الفرق الذي يستحق دفع تكلفة إضافية مقارنة بنسخة Flash.
3.4 الخطوة 4: سيناريو إصلاح الكود عملياً
في بيئة العمل الحقيقية: دع Pro يصلح خطأ برمجياً (Bug).
buggy_code = """
def find_kth_largest(nums, k):
nums.sort()
return nums[k] # يوجد خطأ هنا
"""
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "أنت مراجع كود خبير. حدد الأخطاء، اشرح السبب الجذري، وقدم الكود المصحح."},
{"role": "user", "content": f"راجع هذا الكود:\n```python\n{buggy_code}\n```"},
],
extra_body={"reasoning": {"enabled": True}},
max_tokens=4096,
)
print(resp.choices[0].message.content)
سيشير Pro إلى أن الفهرس يجب أن يكون -k (لأن العنصر الأكبر رقم k بعد الترتيب يقع في الموقع k من النهاية)، وسيقدم الإصلاح مع معالجة الحالات الحدية (مثل k <= 0 أو k > len(nums)) بالإضافة إلى حالات الاختبار.
نتائج SWE-bench التي تتجاوز 80% هي انعكاس واقعي لهذه القدرات.
3.5 الخطوة 5: استدعاء الدوال / استخدام الأدوات (Function Calling)
يتميز Pro باستقرار عالٍ في استدعاء الأدوات الفردية، ورغم أنه أقل قليلاً من GPT-5.4 في سلاسل الأدوات متعددة الخطوات، إلا أنه يتفوق على Claude:
tools = [
{
"type": "function",
"function": {
"name": "run_sql",
"description": "تنفيذ استعلام SQL للقراءة فقط على قاعدة بيانات التحليلات.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "استعلام SQL من نوع SELECT فقط"},
},
"required": ["query"],
},
},
},
]
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "ما هي أفضل 5 مدن من حيث عدد المستخدمين النشطين يومياً (DAU) في آخر 30 يوماً؟"},
],
tools=tools,
tool_choice="auto",
)
print(resp.choices[0].message.tool_calls)
3.6 الخطوة 6: بروتوكول Anthropic (ربط Claude Code بـ Pro)
هذا المسار هو الأكثر استهانة بقيمة deepseek-v4-pro: يمكنك استبدال النموذج الأساسي في جميع مشاريع Claude SDK / Claude Code الحالية بـ V4-Pro دون تغيير أي كود برمجي.
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com", # ملاحظة: بدون /v1
)
resp = client.messages.create(
model="deepseek-v4-pro",
max_tokens=4096,
messages=[
{"role": "user", "content": "أعد هيكلة كود بايثون هذا إلى أسلوب async/await..."},
],
)
print(resp.content[0].text)
في طرفية Claude Code: قم بضبط الإعدادات ANTHROPIC_BASE_URL=https://api.apiyi.com و ANTHROPIC_API_KEY=sk-... وغير النموذج إلى deepseek-v4-pro؛ ستحصل فوراً على وكيل ذكاء اصطناعي (Agent) متفوق في البرمجة.
3.7 الخطوة 7: ربط deepseek-v4-pro في Cursor
في Cursor انتقل إلى Settings → Models → Custom OpenAI-Compatible:
- Base URL:
https://api.apiyi.com/v1 - API Key:
sk-... - Model Name:
deepseek-v4-pro
بعد الانتهاء، ستستخدم جميع مداخل Cursor (الدردشة / Cmd+K / Composer) نموذج V4-Pro، وستلاحظ تحسناً ملحوظاً في جودة إكمال الكود وإعادة الهيكلة.
🎯 نصيحة لربط بيئات التطوير (IDE): تتوافق معظم أدوات البرمجة بالذكاء الاصطناعي مثل Cursor و Windsurf و Cline و Continue مع بروتوكول OpenAI. يكفي توجيه
base_urlإلىapi.apiyi.com/v1وتغيير النموذج إلىdeepseek-v4-proللانتقال السلس. يمكن الاطلاع على أمثلة تفصيلية لإعدادات IDE في قسم DeepSeek V4 على توثيق APIYI الرسميdocs.apiyi.com.
رابعاً: متى تختار deepseek-v4-pro ومتى تتجنبه
4.1 شروط اتخاذ قرار اختيار Pro
✅ اختر deepseek-v4-pro مباشرة في السيناريوهات التالية:
| السيناريو | السبب |
|---|---|
| توليد الكود، إعادة الهيكلة، المراجعة | بطل LiveCodeBench بنتيجة 93.5 |
| برمجة المسابقات، تدريب مسائل الخوارزميات | مستوى Codeforces 3206 (يعادل مستوى IGM) |
| الإجابة الجماعية على أسئلة المقابلات | يتفوق بشكل كبير في Apex Shortlist بنتيجة 90.2 |
| الاستنتاج الرياضي، الإثبات الصوري | يتفوق على Claude بـ 14 نقطة في IMOAnswerBench (89.8) |
| فهم المستودعات البرمجية الضخمة | نافذة سياق 1M + 49B بارامتر نشط |
| الكتابة والتحرير الطويل | مخرجات تصل إلى 384K في مرة واحدة |
| النشر المحلي / التدريب الثانوي | أوزان مفتوحة المصدر + وحدة Engram لتسهيل الضبط الدقيق |
| بديل للنموذج الأساسي في Cursor / Claude Code | ربط بدون تعديل عبر بروتوكول Anthropic |
4.2 حالات لا ينصح فيها باختيار Pro
❌ لا تهدر موارد Pro في السيناريوهات التالية:
| السيناريو | الاقتراح |
|---|---|
| المحادثات اليومية، الأسئلة الشائعة | استخدم Flash (يوفر 12 ضعف التكلفة) |
| تصنيف النصوص القصيرة، الاستخراج | استخدم Flash أو نموذج أصغر |
| سلاسل أدوات Agent معقدة متعددة الخطوات | فكر في GPT-5.4 (يتفوق في Terminal-Bench) |
| الإجابة على الأسئلة المعرفية العامة | Gemini 3.1-Pro أقوى |
| التفاعل عبر الإنترنت الحساس للتأخير | استخدم Flash (وضع Non-Thinking) أو أضف تخزيناً مؤقتاً |
4.3 نصيحة بشأن التوجيه الهجين (Hybrid Routing)
الحل الأمثل في بيئة الإنتاج هو التوجيه الطبقي:
def pick_model(request_type: str, complexity: str) -> str:
# المهام البرمجية الشاقة → Pro
if request_type in ("code_gen", "code_review", "refactor") and complexity == "hard":
return "deepseek-v4-pro"
# الاستنتاج الرياضي → Pro
if request_type in ("math_proof", "competitive_programming"):
return "deepseek-v4-pro"
# الفهم العميق للمستندات الطويلة → Pro
if request_type == "long_doc_analysis":
return "deepseek-v4-pro"
# المهام اليومية الأخرى → Flash
return "deepseek-v4-flash"
في موقع APIYI apiyi.com، يشترك هذان النموذجان في مفتاح واحد، والتبديل بينهما يتطلب فقط تغيير حقل model دون الحاجة لتغيير أي إعدادات أخرى.
خامساً: الأسئلة الشائعة حول deepseek-v4-pro
س1: لماذا تعد قدرات البرمجة في إصدار Pro قوية جداً؟
يعود ذلك لتضافر ثلاثة أسباب:
- التدريب المسبق على 32 تريليون رمز (tokens): والذي تضمن كمية هائلة من بيانات الكود عالية الجودة.
- بنية 1.6T MoE / 49B تفعيل: مما يسمح بتخزين واستدعاء معرفة برمجية واسعة.
- نمط التفكير (Thinking mode) + ذاكرة Engram: التي تفصل بين "حفظ أنماط الكود" و"استنتاج كود جديد".
أي من هذه العوامل بمفرده لا يمكنه تحقيق هذه النتائج، ولكن باجتماعها معاً وصلنا إلى 93.5 في اختبار LiveCodeBench.
س2: هل ستكون الاستجابة بطيئة بسبب حجم المعاملات البالغ 1.6T؟
تعتمد سرعة الاستجابة الواحدة على المعاملات المفعلة، وليس إجمالي المعاملات. يقوم إصدار Pro بتفعيل 49B فقط لكل رمز، وبالإضافة إلى تحسينات FLOPs في Hybrid Attention، فإن تأخير الرمز الأول قريب جداً من إصدار Flash. قد يكون نمط التفكير أبطأ قليلاً (بسبب الحاجة لإخراج عملية الاستنتاج)، ولكن هذا مقايضة تصميمية مقصودة؛ فأنت تدفع الوقت مقابل جودة الاستنتاج.
س3: هل يجب تفعيل نمط التفكير (Thinking mode) دائماً؟
ليس بالضرورة. يمكنك إيقافه في المحادثات العادية، الأكواد البسيطة، والأسئلة اليومية. لكن معظم قيمة اشتراكك في Pro تكمن في نمط التفكير؛ لذا تأكد من تفعيل reasoning.enabled=true + effort=high عند التعامل مع الأكواد المعقدة، المسائل الرياضية، والمنطق متعدد الخطوات.
س4: كيف يمكن استخدامه في Cursor / Claude Code؟
- Cursor: الإعدادات (Settings) ← النماذج (Models) ← Custom OpenAI-Compatible، في خانة Base URL ضع
https://api.apiyi.com/v1وفي خانة النموذج ضعdeepseek-v4-pro. - Claude Code: اضبط متغير البيئة
ANTHROPIC_BASE_URL=https://api.apiyi.comوANTHROPIC_API_KEY=sk-...، ثم حدد النموذجdeepseek-v4-proعند التشغيل.
يمكنك العثور على لقطات شاشة للخطوات التفصيلية في قسم دمج بيئات التطوير (IDE) على docs.apiyi.com.
س5: أيهما أفضل مقارنة بـ GPT-5.4؟
إذا كان عليك الاختيار:
- الكود اليومي / المسابقات / الرياضيات / الحساسية للتكلفة ← deepseek-v4-pro (بطل البرمجة، بسعر 1/7).
- وكلاء الأدوات متعددة الخطوات / الأسئلة المعرفية العامة ← GPT-5.4.
- الاستخدام المختلط هو الحل الأمثل (استخدام مفتاح API واحد عبر APIYI apiyi.com للتبديل بين النموذجين).
س6: هل يمكن نشره محلياً؟
نعم، تم فتح مصدر الأوزان الكاملة لإصدار V4-Pro على Hugging Face (deepseek-ai/DeepSeek-V4-Pro). لكن النشر الذاتي يتطلب:
- جهاز واحد يحتوي على 8×H200 أو ما يعادلها من وحدات معالجة الرسوميات (GPU).
- ذاكرة تخزين مؤقت KV إضافية لسياق 1M (رغم أن Pro قلل التخزين المؤقت إلى 10% مقارنة بـ V3.2).
- تكاليف هندسية لصيانة خدمة الاستنتاج.
حساب التكلفة: ما لم يتجاوز حجم استدعاءاتك الشهرية 50 مليار رمز، فإن الاستعانة بخدمة الاستضافة عبر APIYI apiyi.com أكثر اقتصادية من النشر الذاتي.
س7: ما هو الحد الأقصى للتزامن (Concurrency)؟
توصيات بيئة الإنتاج:
- الموقع الرئيسي
api.apiyi.com: آمن حتى 50 اتصالاً متزامناً. - خط التزامن العالي
vip.apiyi.com: أكثر من 200 اتصال متزامن. - الاحتياطي
b.apiyi.com: للتحويل التلقائي عند حدوث تذبذب في الخط الرئيسي.
نظراً لأن مهام التفكير المعقدة في Pro تسبب تأخيراً أعلى، فإن زيادة التزامن ليست دائماً الحل الأمثل؛ تقدير نافذة التزامن المطلوبة بناءً على (QPS × متوسط وقت الاستجابة) هو الأنسب.
س8: هل سيصدر إصدار رسمي قريباً؟
الإصدار الذي تم إطلاقه في 2026-04-24 هو إصدار معاينة (Preview). وفقاً لوتيرة DeepSeek السابقة، عادة ما يصدر الإصدار الرسمي بعد 1-2 شهر من المعاينة، وقد يتضمن تحسينات طفيفة في المعايير (Benchmarks). لا توجد مشكلة في استخدام نسخة المعاينة عبر APIYI apiyi.com حالياً، فمن المرجح أن يظل معرف النموذج deepseek-v4-pro ثابتاً في الإصدار الرسمي لضمان التوافق.
سادساً: ملخص إطلاق deepseek-v4-pro
إذا كنت تريد الخلاصة:
- ✅ deepseek-v4-pro هو أقوى نموذج مفتوح المصدر حالياً في قدرات البرمجة، حيث تفوق على GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro في ثلاثة معايير تقنية صعبة.
- ✅ أربعة ابتكارات معمارية (Hybrid Attention / mHC / Engram Memory / Muon) تجعله ليس مجرد "نموذج لغة كبير آخر"، بل نوعاً جديداً بعد إعادة كتابة البنية التحتية.
- ✅ 1.6T / 49B MoE + تدريب مسبق على 32T + سياق 1M، مما يضعه في قمة النماذج مفتوحة المصدر.
- ✅ متاح الآن على APIYI apiyi.com، متوافق مع بروتوكولي OpenAI و Anthropic، ويدعم الربط المباشر مع Cursor / Claude Code / Cline دون أي تعديلات.
- ✅ السعر هو 1/7 من سعر GPT-5.4 فقط، ويظهر قوته الحقيقية عند استخدام نمط التفكير.
بالنسبة لفرق التطوير التي تركز على البرمجة، يستحق deepseek-v4-pro الاختبار فوراً؛ فهو ليس مجرد "بديل أرخص"، بل نموذج رائد قد يصبح المعيار الجديد.
🎯 نصيحة عملية: ننصحك اليوم بطلب مفتاح API من
apiyi.com(مخصص لـ Pro، مع ضبط سقف يومي 200–500 يوان)، وقم بتشغيل 20 موجه (prompt) تمثل طبيعة عملك في البرمجة أو الرياضيات أو النصوص الطويلة، وقارن بين V4-Pro (بنمط التفكير) ونموذجك الحالي. إذا تحسنت جودة المهام البرمجية بشكل ملحوظ، قم بتحويل النموذج الافتراضي في Cursor / Claude Code إليه. إذا كنت بحاجة لنموذج أرخص للمهام اليومية، يمكنك إضافة V4-Flash (راجع دليل الترحيل السابق). عند تشغيل الاختبارات الجماعية، استخدمvip.apiyi.comواستخدمb.apiyi.comكخيار احتياطي. يمكنك العثور على أمثلة الربط الكاملة وإعدادات IDE ونصوص إعادة إنتاج المعايير علىdocs.apiyi.com.
إن أهمية deepseek-v4-pro تتجاوز كونه "نموذجاً رخيصاً آخر". إنه يمثل المرة الأولى التي تتفوق فيها النماذج مفتوحة المصدر بشكل كامل على النماذج المغلقة الرائدة في قدرات البرمجة الأساسية، وهو أمر يستحق أن يختبره كل فريق يتعامل بجدية مع هندسة الذكاء الاصطناعي.
الكاتب: فريق APIYI التقني
موارد ذات صلة:
- إعلان DeepSeek الرسمي: api-docs.deepseek.com/news/news260424
- مستودع المصدر على Hugging Face: huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- موقع APIYI الرسمي: apiyi.com
- وثائق APIYI: docs.apiyi.com
- الموقع الرئيسي لـ APIYI: api.apiyi.com (الاحتياطي vip.apiyi.com / b.apiyi.com)