ملاحظة من المؤلف: بناءً على تسريبات اختبارات التدرج الرمادي (Gray-box testing) في منصة LM Arena، نقدم تحليلاً شاملاً لثماني ترقيات رئيسية في نموذج gpt-image-2 مقارنة بـ gpt-image-1.5، تشمل دقة عرض النصوص، الواقعية، مخرجات 4K، السرعة، دعم اللغات المتعددة، وتوليد لقطات واجهة المستخدم (UI).
في أوائل أبريل 2026، ظهرت ثلاثة نماذج صور مجهولة بهدوء على منصة التقييم LM Arena وهي: maskingtape-alpha، gaffertape-alpha، وpackingtape-alpha. أفاد العديد من المختبرين الأوائل أن دقة عرض النصوص لديهم تقترب من 99%، وسرعة التوليد تبلغ حوالي 3 ثوانٍ فقط، مع دعم أصلي لمخرجات 4K؛ ويعتقد المجتمع بشكل عام أن هذا هو نموذج gpt-image-2 الذي توشك OpenAI على إطلاقه.
هذا ليس مجرد "منتج وهمي" (Vaporware)؛ فسجلات الاختبار العلنية في LM Arena، ولقطات الشاشة المقارنة من العديد من المختبرين المستقلين، ودورات اختبار التدرج الرمادي التاريخية لشركة OpenAI (التي عادة ما تتبعها إصدارات رسمية خلال 2-4 أسابيع) تشير جميعها إلى النتيجة نفسها. ستستعرض هذه المقالة بشكل منهجي ثماني ترقيات رئيسية في gpt-image-2 مقابل gpt-image-1.5.
القيمة الجوهرية: بعد قراءة هذا المقال، ستفهم بوضوح التقدم الملموس لنموذج gpt-image-2 في أبعاد النصوص، الواقعية، دقة 4K، السرعة، استعادة واجهات المستخدم، واللغات المتعددة، وكيفية الانتقال السلس في اليوم الأول من إتاحة واجهة البرمجة (API).

النقاط الجوهرية لنموذج gpt-image-2
| بُعد الترقية | وضع gpt-image-1.5 الحالي | تحسينات gpt-image-2 |
|---|---|---|
| عرض النصوص | عناوين قصيرة من 1-5 كلمات | دقة على مستوى الحرف حوالي 99% |
| سرعة التوليد | 8-18 ثانية | حوالي 3 ثوانٍ (أسرع بـ 3-5 مرات) |
| أقصى دقة | 1536×1024 | 2048×2048 / 4096×4096 |
| دعم الشاشات العريضة | فقط 1:1، 4:3، 3:4 | إضافة دعم 16:9 |
| الواقعية | وجود "فلتر الذكاء الاصطناعي الأصفر" | الصور الشخصية/المنتجات تبدو واقعية للغاية |
المعنى العام لترقية gpt-image-2
النصوص لم تعد نقطة ضعف. في عصر gpt-image-1.5، كانت معظم نماذج الصور تخطئ عند عرض نصوص تتجاوز 5-6 كلمات، بينما أفاد مختبرو LM Arena أن ملصقات واجهة المستخدم، واللافتات، ونصوص الملصقات في gpt-image-2 لا تحتاج تقريباً إلى أي تعديل لاحق. هذا يعني أن الإعلانات المترجمة، ونماذج واجهات المستخدم (UI Mockups)، وصور وسائل التواصل الاجتماعي لن تحتاج بعد الآن إلى تنسيق يدوي.
من الاستدلال على مرحلتين إلى الاستدلال في خطوة واحدة. لا يزال gpt-image-1.5 يعتمد على خط أنابيب (Pipeline) من مرحلتين، بينما تشير تقارير المختبرين إلى أن gpt-image-2 قد تم فصله ليصبح نموذج صور مستقلاً، يعتمد بنية الاستدلال في خطوة واحدة. هذا هو الدعم الأساسي للسرعة التي تصل إلى 3 ثوانٍ، ويعني أيضاً أن إنتاجية خطوط الأنابيب المجمعة قد تزيد بمقدار مرتبة من حيث الحجم.

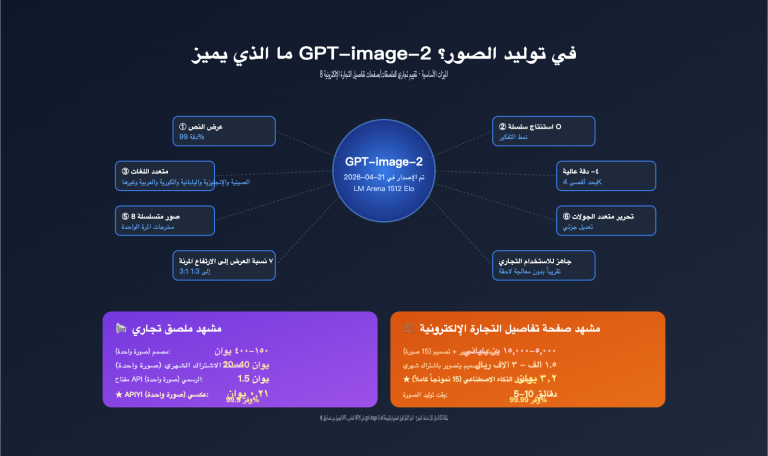
شرح مفصل للترقيات الثمانية الكبرى في gpt-image-2 مقارنة بـ gpt-image-1.5
الترقية الأولى: عرض نصوص شبه مثالي
أفاد مختبرو LM Arena أن دقة عرض الأحرف في gpt-image-2 تصل إلى حوالي 99%، حيث تندمج النصوص بشكل طبيعي داخل المشهد (مثل واجهات المستخدم، والملصقات، واللافتات)، بدلاً من أن تبدو "طافية" فوق الصورة كما كان الحال في النماذج القديمة.
هذه المشكلة كانت تؤرق جميع نماذج الصور الرائدة (Midjourney، Stable Diffusion، Imagen، Flux)، وأخيراً تم حلها بشكل جذري في gpt-image-2.
الترقية الثانية: واقعية تخدع العين
أشار العديد من المختبرين إلى أن الصور التي يولدها gpt-image-2، سواء كانت بورتريهات، أو صور سيلفي على الشاطئ، أو لقطات مقربة للمنتجات، أصبحت واقعية لدرجة يصعب معها تمييز ما إذا كانت من صنع الذكاء الاصطناعي:
- تشريح صحيح لليدين: تناسق الأصابع وزوايا المفاصل تبدو طبيعية.
- انعكاسات دقيقة للنظارات الشمسية: محتوى الانعكاس يتطابق تماماً مع المشهد.
- اختفاء الفلتر الأصفر: لم يعد يظهر "لون الذكاء الاصطناعي" الباهت الذي كان ملازماً لعصر gpt-image-1.
الترقية الثالثة: معرفة عميقة بالعالم
عندما طلب المختبرون "متجر IKEA ليلاً"، أو "لقطة شاشة لصفحة YouTube الرئيسية"، أو "مشهد من لعبة Minecraft مع واجهة مستخدم صحيحة"، أظهر gpt-image-2 قدرة على محاكاة العلامات التجارية الحقيقية والواجهات والبيئات لدرجة تجعلها تبدو كأنها "تصوير حقيقي".
هذا يعني أن النموذج يفهم حقاً الاتفاقيات البصرية للعالم الحقيقي، وليس مجرد توزيع إحصائي للبكسلات.
الترقية الرابعة: مخرجات بدقة 4K أصلية
بينما كان الحد الأقصى لمخرجات gpt-image-1.5 هو 1536×1024، من المتوقع أن يدعم gpt-image-2 دقة 2048×2048 و 4096×4096 بشكل أصلي، بالإضافة إلى دعم صيغة الشاشة العريضة 16:9.
| سيناريو التطبيق | تجربة gpt-image-1.5 | تجربة gpt-image-2 |
|---|---|---|
| الطباعة التجارية | تتطلب تكبيراً لاحقاً | طباعة مباشرة بدقة 4K أصلية |
| تصاميم التسويق | دقة غير كافية | تلبي متطلبات الملصقات أصلاً |
| صور المنتجات عالية الدقة | تتطلب معالجة إضافية | توليد مباشر بجودة عالية |
| صور مصغرة للفيديو | تفتقر إلى 16:9 | دعم أصلي للشاشة العريضة |
الترقية الخامسة: سرعة توليد أكبر (حوالي 3 ثوانٍ)
لاحظ مراقبو Arena أن التوليد الواحد يستغرق حوالي 3 ثوانٍ فقط، وهو أسرع بكثير من النماذج السابقة التي كانت تستغرق 10-20 ثانية (أو حتى 35-55 ثانية في عصر gpt-image-1).
سواء كان ذلك في تجربة المستخدم التفاعلية (UX) (حيث ينخفض وقت انتظار المستخدم بشكل ملحوظ) أو في خطوط الإنتاج الضخمة (زيادة الإنتاجية بمقدار 3-5 أضعاف في نفس الوقت)، فإن الفائدة ستكون مباشرة.
الترقية السادسة: عرض نصوص متعدد اللغات
في النسخة التجريبية، كانت اللغات اللاتينية، وCJK (الصينية واليابانية والكورية)، واللغات التي تُكتب من اليمين إلى اليسار (العربية والعبرية) واضحة ومقروءة.
إذا استمر هذا الأداء عند الإطلاق، فلن تحتاج بعد الآن إلى تنسيق يدوي للإعلانات المحلية أو نماذج واجهة المستخدم متعددة اللغات، وهو أمر مفيد جداً لفرق التوسع العالمي، والتجارة الإلكترونية العابرة للحدود، وإدارة المحتوى متعدد اللغات.
الترقية السابعة: توليد واجهات المستخدم ولقطات الشاشة
أشاد المختبرون بقدرة النموذج على إعادة بناء واجهات المستخدم (صفحات الويب، تطبيقات الجوال، نوافذ أنظمة التشغيل) بدقة مذهلة. وهو مناسب للسيناريوهات التالية:
- استكشاف التصميم: توليد مسودات مفاهيمية لواجهات المستخدم بسرعة.
- مواد تعليمية: توليد لقطات شاشة تجريبية للوثائق التقنية.
- نماذج أولية: عرض واجهات منتجات لم يتم تطويرها بعد للعملاء.
- مواد اختبار A/B: توليد دفعات من واجهات بأنماط مختلفة للمقارنة.
الترقية الثامنة: توفر API فور الإطلاق
بمجرد أن تفتح OpenAI الـ API، ستكون APIYI جاهزة فوراً. مفتاح API الخاص بك في apiyi.com ورصيدك وفواتيرك ستبقى كما هي، دون الحاجة لتسجيل حساب جديد أو تغيير SDK أو تعديل كود العمل الخاص بك.
نصيحة للنقل: قبل الإطلاق الرسمي لـ gpt-image-2، يمكنك اختبار gpt-image-1.5 الحالي عبر APIYI apiyi.com للتعرف على إعدادات
base_urlوهيكل المعاملات، وعند الإطلاق الرسمي، ستحتاج فقط إلى استبدال حقلmodelلإتمام عملية النقل.
دليل البدء السريع لـ gpt-image-2 (دليل نقل الـ API)
مثال بسيط (بناءً على gpt-image-1.5، استبدل اسم النموذج عند الإطلاق الرسمي)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-1.5", # استبدله بـ "gpt-image-2" بعد الإطلاق الرسمي
prompt="لوحة قائمة مقهى حديثة مكتوب عليها بخط اليد 'Today Special: Espresso $4.50'",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
عرض كود التنفيذ الكامل (يشمل 4K، 16:9، ومعالجة الأخطاء)
from openai import OpenAI
from typing import Optional, Literal
def generate_image(
prompt: str,
model: str = "gpt-image-1.5",
size: Literal["1024x1024", "1536x1024", "1024x1536", "2048x2048", "4096x4096"] = "1024x1024",
quality: Literal["low", "medium", "high", "auto"] = "high",
n: int = 1
) -> Optional[str]:
"""
توليد صور، متوافق مع gpt-image-1.5 و gpt-image-2 مستقبلاً
Args:
prompt: الموجه النصي (بحد أقصى 2000 رمز)
model: اسم النموذج (يمكن التبديل إلى gpt-image-2 بعد الإطلاق)
size: أبعاد المخرجات (سيدعم gpt-image-2 دقة 2K/4K)
quality: مستوى الجودة
n: عدد الصور المولدة (يدعم حالياً 1 فقط)
Returns:
رابط مؤقت للصورة المولدة (صالح لمدة 24 ساعة)
"""
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
try:
response = client.images.generate(
model=model,
prompt=prompt,
size=size,
quality=quality,
n=n
)
return response.data[0].url
except Exception as e:
print(f"فشل توليد الصورة: {e}")
return None
url = generate_image(
prompt="لقطة احترافية لمنتج: سماعات أذن لاسلكية أنيقة على رخام، مع ظهور ملصق 'AuraPods Pro'",
model="gpt-image-1.5",
size="1536x1024",
quality="high"
)
print(f"رابط الصورة: {url}")
نصيحة المنصة: احصل على رصيد تجريبي مجاني عبر APIYI apiyi.com لتجربة أحدث قدرات gpt-image-1.5 فوراً، ولن تحتاج إلى أي تعديلات برمجية عند إطلاق gpt-image-2 رسمياً.
مقارنة بين gpt-image-2 و gpt-image-1.5

| البعد | gpt-image-1.5 (ديسمبر 2025) | gpt-image-2 (متوقع أبريل-مايو 2026) | دلالة الفرق |
|---|---|---|---|
| البنية | استنتاج على مرحلتين | استنتاج أحادي المرحلة | زيادة كبيرة في الإنتاجية |
| السرعة | 8-18 ثانية | حوالي 3 ثوانٍ | أسرع بـ 3-5 مرات |
| أقصى دقة | 1536×1024 | 4096×4096 | جاهزة للطباعة التجارية |
| دعم النسب | 1:1/3:4/4:3 | + 16:9 عريضة | مناسبة للصور المصغرة للفيديو |
| دقة النصوص | عناوين قصيرة (1-5 كلمات) | ~99% على مستوى الحرف | وداعاً للتنسيق اليدوي |
| تعدد اللغات | غير مستقر للغات غير اللاتينية | وضوح تام للغات CJK/RTL | مفيد للمحتوى المحلي |
| استعادة واجهة المستخدم | متوسطة | "محاكاة" دقيقة للشاشات | مناسبة للتصاميم والشروحات |
تحليل المقارنة والترقية
مقارنة بـ Midjourney: لا يزال Midjourney يتصدر في توليد الأنماط الفنية، لكن الوصول عبر API محدود، وقدرات عرض النصوص ضعيفة. في المقابل، يوفر gpt-image-2 وصولاً قياسياً عبر API مع دقة نصوص تصل إلى 99%، مما يجعله أكثر ملاءمة لدمجه في سير العمل الآلي.
مقارنة بـ Imagen 2: يتفوق Google Imagen 2 في الواقعية الفوتوغرافية، لكن نظام الـ API الخاص به مغلق نسبياً، ودعمه للغات غير الإنجليزية محدود. في المقابل، يعد gpt-image-2 أكثر توازناً في تعدد اللغات، استعادة واجهات المستخدم، والسرعة، مما يجعله خياراً ممتازاً للفرق التي تستهدف الأسواق العالمية.
مقارنة بـ nano-banana-pro: يتميز nano-banana-pro بفعالية التكلفة، لكنه لا يرقى لمستوى التوقعات في مخرجات 4K وقدرات استعادة العلامة التجارية مقارنة بـ gpt-image-2. بالنسبة للطباعة التجارية وسيناريوهات التسويق للعلامات التجارية، يظل gpt-image-2 الخيار الأكثر موثوقية.
ملاحظة حول المقارنة: البيانات المذكورة أعلاه مستمدة جزئياً من اختبارات LM Arena العامة وجزئياً من تعليقات المختبرين الأوائل. يرجى التعامل معها كمعلومات أولية قبل الإصدار الرسمي لـ gpt-image-2. يُنصح بتجربة gpt-image-1.5 مسبقاً عبر خدمة وكيل API في APIYI (apiyi.com) للتعرف على هيكلية المعاملات.
سيناريوهات تطبيق gpt-image-2
يُنصح بالترقية إلى gpt-image-2 في السيناريوهات التالية:
- السيناريو 1 – الطباعة التجارية: دقة 4K الأصلية تحل مشكلة القيود في دقة الملصقات، الكتيبات، والإعلانات الكبيرة.
- السيناريو 2 – الإعلانات المترجمة: عرض النصوص بلغات متعددة يغني عن التنسيق اليدوي، مما يعزز كفاءة فرق العمل الدولية بشكل ملحوظ.
- السيناريو 3 – استكشاف تصميم واجهة المستخدم (UI): تمكين مديري المنتجات والمصممين من إنشاء مسودات مفاهيمية ومواد تعليمية بسرعة.
- السيناريو 4 – الصور الرئيسية للتجارة الإلكترونية: واقعية تشبه الصور الشخصية ونصوص دقيقة للمنتجات، مما يجعلها مثالية للتسويق المرئي.
- السيناريو 5 – محتوى الفيديو: دعم نسبة العرض 16:9 لإنشاء صور مصغرة (Thumbnails) لمنصات يوتيوب والفيديوهات القصيرة بشكل جماعي.
اقتراح للسيناريوهات: إذا كنت تقيم حالياً واجهة برمجة تطبيقات (API) للصور، فنحن نقترح البدء بدمج gpt-image-1.5 عبر APIYI (apiyi.com). عند إطلاق الإصدار الرسمي، ستحتاج فقط إلى استبدال حقل
modelللترقية بسلاسة.
الأسئلة الشائعة (FAQ)
س1: ما هو gpt-image-2؟
gpt-image-2 هو الجيل القادم من نماذج توليد الصور من OpenAI، ومن المتوقع إطلاقه في أبريل أو مايو 2026. وفقاً لاختبارات LM Arena، يستخدم هذا النموذج بنية استنتاج أحادية الخطوة، بدقة عرض نصوص تصل إلى حوالي 99%، وسرعة حوالي 3 ثوانٍ، مع دعم أصلي لدقة 4K، وهو ترقية كبيرة بعد إصدارات gpt-image-1 (أبريل 2025) وgpt-image-1.5 (ديسمبر 2025).
س2: ما الفرق بين gpt-image-2 و gpt-image-1.5؟
تكمن الاختلافات الجوهرية في ثمانية أبعاد: عرض النصوص (من 5 كلمات إلى 99%)، السرعة (من 8-18 ثانية إلى 3 ثوانٍ)، الدقة (من 1536×1024 إلى 4096×4096)، نسبة العرض (إضافة 16:9)، الواقعية (إزالة الفلتر الأصفر)، المعرفة العالمية (دقة في العلامات التجارية وواجهات المستخدم)، اللغات المتعددة (وضوح في CJK/RTL)، واستعادة واجهة المستخدم (القدرة على محاكاة لقطات شاشة حقيقية). لا يزال gpt-image-1.5 كافياً للعناوين القصيرة والنسب القياسية، ولكن للطباعة التجارية، الترجمة، وتصميم الواجهات، نوصي بانتظار gpt-image-2.
س3: متى سيتم إطلاق gpt-image-2؟
حتى تاريخ 17-04-2026، لم تعلن OpenAI رسمياً عن الموعد. بناءً على دورات الاختبار السابقة (التي تستغرق عادةً 2-4 أسابيع قبل الإطلاق الرسمي)، يتوقع الخبراء أن تكون نافذة الإطلاق بين أواخر أبريل ومنتصف مايو 2026. النماذج الثلاثة ذات الأسماء الرمزية على LM Arena (maskingtape-alpha, gaffertape-alpha, packingtape-alpha) لا تزال حالياً في مرحلة اختبار A/B.
س4: ما هي أفضل سيناريوهات التطبيق لـ gpt-image-2؟
يناسب بشكل أساسي السيناريوهات التالية:
- الملصقات/الكتيبات المخصصة للطباعة التجارية: دقة 4K أصلية توفر عناء التكبير اللاحق.
- صور وسائل التواصل الاجتماعي المترجمة: عرض نصوص بلغات متعددة دون الحاجة لتنسيق عبر فوتوشوب.
- مسودات تصميم واجهة المستخدم: توليد لقطات شاشة تجريبية لتطوير المنتجات والدروس التعليمية.
- صور التسويق للتجارة الإلكترونية: واقعية عالية مع نصوص دقيقة للمنتج.
- الصور المصغرة لمنصات الفيديو: توليد جماعي بنسبة 16:9 الأصلية.
س5: كيف يمكن استدعاء gpt-image-2 بسرعة عبر API؟
نوصي بالبدء عبر APIYI (apiyi.com) للوصول المبكر، مما يضمن جاهزيتك فور الإطلاق:
- قم بزيارة apiyi.com لتسجيل حساب والحصول على مفتاح API.
- استخدم
base_url=https://vip.apiyi.com/v1لاستدعاء gpt-image-1.5 والتعرف على المعاملات. - في يوم إطلاق gpt-image-2، ما عليك سوى استبدال حقل
modelمنgpt-image-1.5إلىgpt-image-2.
تطلق APIYI النماذج الجديدة بالتزامن مع OpenAI، مع بقاء مفاتيحك، رصيدك، وفواتيرك كما هي، دون الحاجة لتسجيل حساب جديد أو تغيير حزمة التطوير (SDK).
س6: ما هي القيود أو الشكوك المعروفة حول gpt-image-2؟
تأتي الشكوك الرئيسية من عدم الإطلاق الرسمي حتى الآن:
- التسعير غير معروف: انخفض سعر gpt-image-1.5 بنحو 20% مقارنة بـ gpt-image-1، وسعر gpt-image-2 ينتظر التأكيد الرسمي.
- حدود السرعة: قد تكون هناك حصص للاستدعاء في فترة الإطلاق الأولي، لذا نوصي باستخدام خدمة وكيل API لتجنب مشاكل البداية.
- تغير القدرات: قد تختلف نسخة الاختبار على LM Arena عن النسخة النهائية، لذا تعامل معها كمعاينة للجودة.
- خطة بديلة: إذا كان مشروعك عاجلاً، فإن gpt-image-1.5 الحالي يظل خياراً مستقراً وموثوقاً.
س7: هل سيحل gpt-image-2 محل DALL-E 3؟
وفقاً لوتيرة إصدارات OpenAI، من المتوقع أن يتم إيقاف DALL-E 3 تدريجياً بعد الإطلاق الرسمي لـ gpt-image-2. في مسار الترحيل، أصبحت سلسلة gpt-image هي التوجه الرسمي، كما أن هيكل معاملات API مستقر. نوصي المشاريع الجديدة بالاعتماد مباشرة على gpt-image-1.5 أو انتظار gpt-image-2 لتجنب استثمار الكثير من العمل المخصص في DALL-E 3.
س8: هل نماذج سلسلة tape على LM Arena هي بالتأكيد gpt-image-2؟
لا يوجد تأكيد رسمي، لكن هناك أربعة أدلة تشير بقوة إلى OpenAI:
- نمط التسمية (سلسلة tape) يتوافق مع عادات OpenAI في الأسماء الرمزية التاريخية.
- قدرات عرض النصوص (99%) والمعرفة العالمية تتجاوز جميع النماذج المتاحة حالياً.
- توقيت الاختبار يتوافق مع دورات الاختبار التجريبي المعتادة لـ OpenAI.
- أسلوب مخرجات النموذج يتماشى مع سلسلة gpt-image (وليس أسلوب Midjourney أو Imagen).
نوصي بمتابعة الإعلانات الرسمية، والانتظار للتحديث عبر APIYI (apiyi.com).
النقاط الرئيسية لنموذج gpt-image-2
- الجيل القادم من النماذج: النموذج الرائد لتوليد الصور من OpenAI لعام 2026، والذي يحل محل gpt-image-1.5، حيث تحولت البنية من مرحلتين إلى استنتاج في خطوة واحدة.
- ثمانية ترقيات كبرى: دقة نصوص بنسبة 99%، سرعة 3 ثوانٍ، دقة 4K أصلية، نسبة عرض إلى ارتفاع 16:9، واقعية فائقة، معرفة عالمية، دعم لغات متعددة، واستعادة دقيقة لواجهات المستخدم (UI).
- سيناريوهات الاستخدام: ترقية مثالية للطباعة التجارية، الإعلانات المترجمة محلياً، مسودات مفاهيم واجهات المستخدم، الصور الرئيسية للتجارة الإلكترونية، وصور مصغرة للفيديو.
- جدول الإصدار: من المتوقع إطلاقه بين أواخر أبريل ومنتصف مايو 2026، ويحمل حالياً الاسم الرمزي "سلسلة tape" في مرحلة الاختبار التجريبي.
- انتقال سلس: يمكنك الوصول مسبقاً إلى gpt-image-1.5 عبر APIYI (apiyi.com)، وفي يوم الإطلاق، ستحتاج فقط إلى استبدال حقل
model.
ملخص
أبرز الفروقات بين gpt-image-2 و gpt-image-1.5:
- قفزة نوعية: وصلت المؤشرات الرئيسية الثلاثة (النصوص، السرعة، والدقة) إلى معايير الإنتاج الاحترافي أو تجاوزتها، مما يعني أن النتائج لم تعد بحاجة إلى تعديلات لاحقة.
- فتح آفاق جديدة: أصبحت سيناريوهات الطباعة التجارية، الترجمة المحلية للغات متعددة، واستعادة واجهات المستخدم ممكنة لأول مرة بشكل فعلي، مما يقلل بشكل كبير من تكاليف المعالجة اليدوية.
- انتقال غير محسوس: هيكلية معلمات API متوافقة مع gpt-image-1.5، مما يسمح للفرق التي بدأت العمل مسبقاً بالتبديل في يوم الإطلاق دون أي تعديلات برمجية.
بالنسبة لقرارات فريقك، نوصي بالبدء فوراً في استخدام gpt-image-1.5 عبر APIYI (apiyi.com) للتعرف على المعلمات وسير العمل، حيث توفر المنصة أرصدة مجانية وواجهة موحدة. بمجرد إطلاق gpt-image-2، يمكنك التبديل بسلاسة عبر تغيير حقل model فقط للاستفادة من الترقيات الثماني الكبرى.
قراءة إضافية
إذا كنت مهتماً بـ gpt-image-2، نوصيك بمتابعة القراءة:
- 📘 دليل استدعاء API الكامل لـ gpt-image-1.5 – أتقن معاملات وأفضل الممارسات لنماذج الصور الرائدة حالياً.
- 📊 مقارنة السعر والجودة بين gpt-image-2 و nano-banana-pro – تعرف على هيكل تكاليف واجهات برمجة تطبيقات الصور الشائعة.
- 🚀 تحسين استدعاءات واجهة برمجة تطبيقات توليد الصور في بيئة الإنتاج – استكشف استراتيجيات خطوط المعالجة المجمعة، التزامن، والتخزين المؤقت.
📚 المراجع
-
تحليل MindStudio: قراءة شاملة حول "ما هو GPT Image 2"
- الرابط:
mindstudio.ai/blog/what-is-gpt-image-2 - الوصف: مراجعة منهجية لمصفوفة قدرات gpt-image-2 من مدونة عالمية ذات تصنيف عالٍ.
- الرابط:
-
تحليل تسريبات getimg.ai: شائعات، تسريبات، وتاريخ إصدار GPT Image 2
- الرابط:
getimg.ai/blog/gpt-image-2-rumours-leaks-release-date-2026 - الوصف: ملاحظات مباشرة حول أداء نماذج "tape" الثلاثة في منصة LM Arena.
- الرابط:
-
مدونة OpenAI الرسمية: إعلان ترقية ميزات الصور في ChatGPT
- الرابط:
openai.com/index/new-chatgpt-images-is-here - الوصف: التوضيح الرسمي لمسار تطور سلسلة gpt-image.
- الرابط:
-
وثائق معاملات gpt-image-1.5: إعداد EvoLink
- الرابط:
evolink.ai/blog/gpt-image-1-5-guide-features-comparison-access - الوصف: تفاصيل المعاملات حول السرعة، الدقة، ومستويات الجودة لنموذج gpt-image-1.5.
- الرابط:
الكاتب: الفريق التقني لـ APIYI
للتواصل التقني: نرحب بمناقشاتكم في قسم التعليقات، ولمزيد من المعلومات يمكنكم زيارة مركز توثيق APIYI عبر الرابط docs.apiyi.com