ملاحظة المؤلف: شرح مفصل لسبب تجاوز وحدات Token الناتجة من Gemini 3.1 Pro Preview للنص المرئي بكثير: آلية سلسلة التفكير Thinking Tokens، قواعد الفوترة، ونصائح ضبط thinking_level لتوفير المال.
"لقد أرسلت جملة واحدة فقط، والنموذج ردّ بعشرات الكلمات فقط، فلماذا تظهر وحدات Token الناتجة حوالي 900؟ أين ذهبت الأموال؟" – هذا هو الارتباك الحقيقي الذي يواجهه العديد من المطورين عند استخدامهم الأول لـ Gemini 3.1 Pro Preview. البيانات في لقطة الشاشة تُظهر هذه الظاهرة بوضوح: 13 وحدة Token مدخلة، ولكن الناتج وصل إلى 898 وحدة Token.
الجواب هو Thinking Tokens (وحدات Token الخاصة بالاستدلال). Gemini 3.1 Pro هو نموذج استدلالي، حيث يقوم بـ "تفكير واستدلال" مطول في "ذهنه" قبل أن يقدم لك الإجابة. محتوى هذا الاستدلال لا يتم عرضه لك افتراضيًا، ولكنه يُحتسب ضمن وحدات Token الناتجة ويتم فوترته بشكل طبيعي.
القيمة الأساسية: بعد قراءة هذه المقالة، ستُدرك تمامًا آلية Thinking Tokens الخاصة بنماذج الاستدلال، وتتعلم كيفية استخدام معلمة thinking_level للتحكم في عمق الاستدلال، مما يوفر 50-80% من تكلفة وحدات Token الناتجة مع الحفاظ على الجودة.
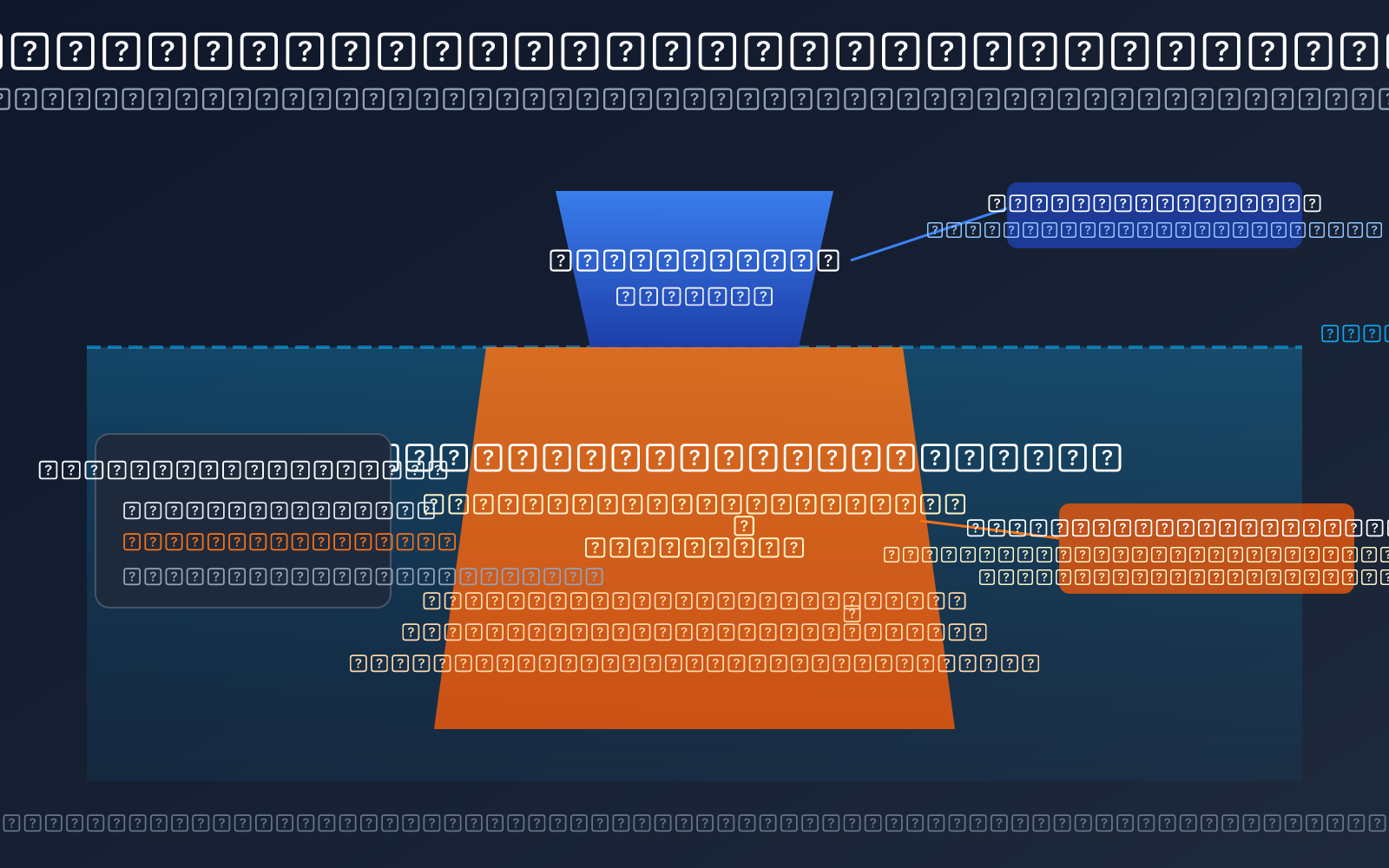
النقاط الأساسية لـ Thinking Tokens في Gemini 3.1 Pro
الفرق الأكبر بين نموذج الاستدلال ونموذج الحوار العادي يكمن في تكوين وحدات Token الناتجة. فيما يلي المفاهيم الأساسية التي تحتاج لفهمها:
| النقطة | الشرح | التأثير العملي |
|---|---|---|
| وحدات Token الناتجة = التفكير + الإجابة | وحدات Token الناتجة من Gemini 3.1 Pro تشمل Thinking Tokens (سلسلة الاستدلال) والإجابة الفعلية | النص المرئي قليل، ولكن إجمالي وحدات Token مرتفع |
| يتم فوترة Thinking Tokens بشكل طبيعي | عملية الاستدلال، رغم أنها غير مرئية، تُحتسب حسب سعر وحدات Token الناتجة (12 دولارًا لكل مليون وحدة Token) | قد تصل تكلفة سؤال بسيط إلى 5-10 أضعاف تكلفة النماذج العادية |
thinking_level قابل للتعديل |
يدعم التحكم في عمق الاستدلال بثلاث مستويات: LOW/MEDIUM/HIGH | مستوى LOW يمكنه توفير أكثر من 80% من وحدات Token الناتجة |
| النماذج غير الاستدلالية لا تواجه هذه المشكلة | نماذج مثل GPT-4o، Claude Sonnet 4.6 (مع إيقاف Extended Thinking) تعطي ما تراه | المهام البسيطة تكون أكثر توفيرًا باستخدام النماذج غير الاستدلالية |
حالة استهلاك حقيقية لـ Thinking Tokens في Gemini 3.1 Pro
لنعد إلى المثال في لقطة الشاشة. أرسل المستخدم سؤالاً بسيطًا، ورد النموذج بحوالي عشر كلمات، ولكن وحدات Token الناتجة أظهرت 891-898 وحدة. تكوين هذه الوحدات يكون تقريبًا كما يلي:
- الإجابة المرئية: حوالي 30-50 وحدة Token (العشر كلمات التي تراها)
- Thinking Tokens: حوالي 840-860 وحدة Token (عملية الاستدلال الداخلية للنموذج)
أي أن أكثر من 95% من وحدات Token الناتجة لا تراها، حيث استُهلكت في سلسلة استدلال النموذج. هذا يشبه أن تسأل مدرس رياضيات "ما ناتج 1+1؟"، فيقول المدرس شفهيًا فقط "يساوي 2"، ولكنه في ذهنه فكر: "هذه مسألة حسابية أساسية، تحتاج إلى استخدام عملية الجمع…" – ثم تدفع أنت مقابل عملية التفكير الكاملة للمدرس.
هذه الآلية ليست خطأ، بل هي خاصية تصميم لنماذج الاستدلال. سبب أداء Gemini 3.1 Pro الأفضل في المشكلات المعقدة (درجة 95.1% في معيار MATH، و 77.1% في ARC-AGI-2) هو أنه يقوم باستدلال عميق قبل الإجابة.
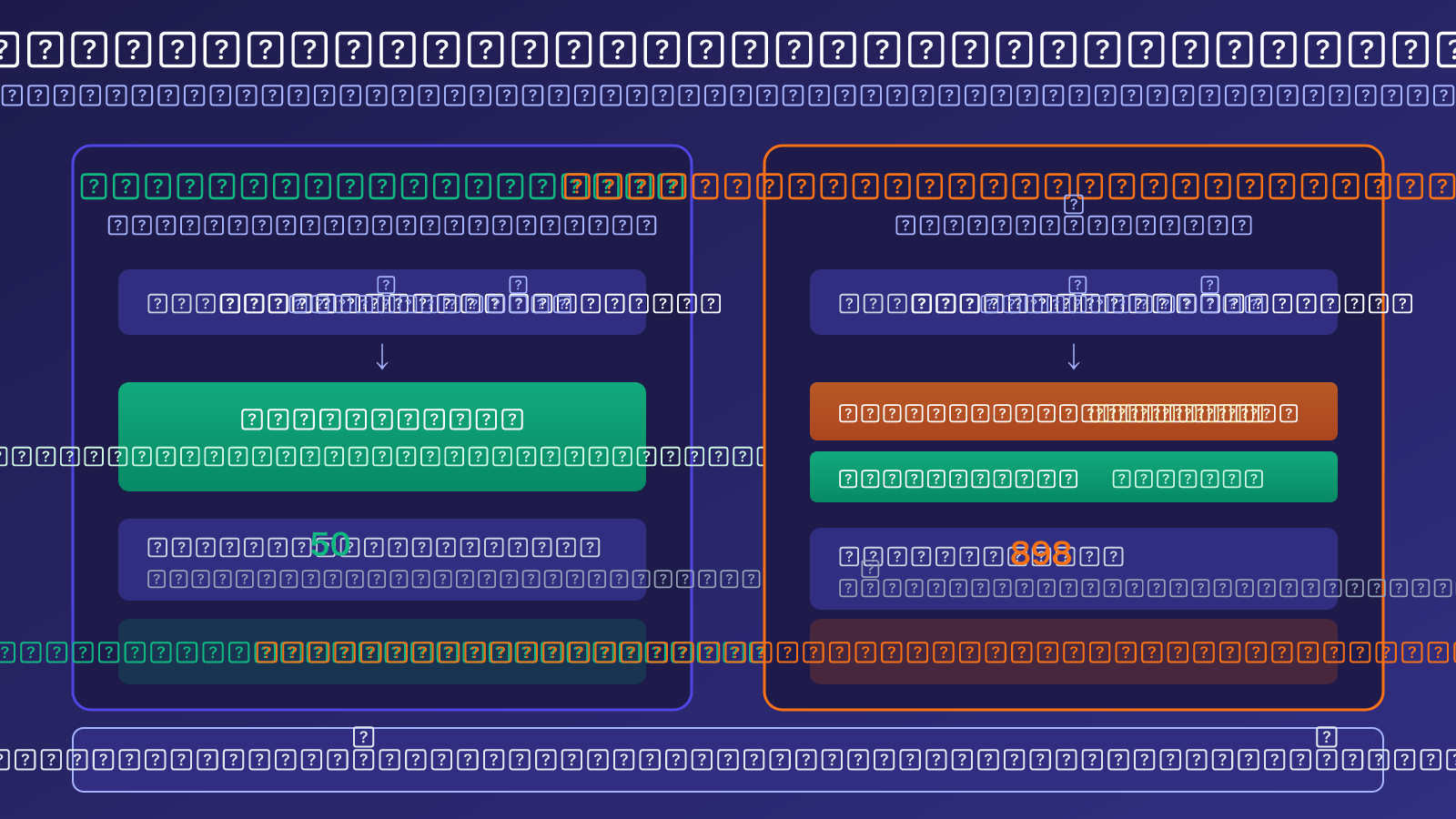
آلية عمل Thinking Tokens في نموذج Gemini 3.1 Pro للاستدلال
الفرق الجوهري بين نماذج الاستدلال والنماذج العادية
النماذج العادية (مثل GPT-4o) تولد الإجابة مباشرةً بعد تلقي سؤالك. ما تراه من إجابة هو ما تدفع ثمنه من وحدات Token للإخراج. هذا هو مبدأ "ما تراه هو ما تحصل عليه".
نماذج الاستدلال (مثل Gemini 3.1 Pro Preview) تتبع نهجًا مختلفًا. بعد تلقي السؤال، تقوم أولاً بتوليد سلسلة استدلالية داخلية (Chain of Thought)، ثم تولد الإجابة النهائية بناءً على نتيجة هذا الاستدلال. أنت ترى الإجابة النهائية فقط، ولكنك تدفع مقابل إجمالي وحدات Token المستخدمة في "سلسلة الاستدلال + الإجابة".
| نوع النموذج | نموذج ممثل | تكوين وحدات Token للإخراج | تكلفة الأسئلة البسيطة | ميزة الأسئلة المعقدة |
|---|---|---|---|---|
| نموذج عادي | GPT-4o، Claude Sonnet 4.6 | 100% إجابة مرئية | منخفضة (ما تراه هو ما تحصل عليه) | قدرة استدلالية متوسطة |
| نموذج استدلال | Gemini 3.1 Pro، GPT-5.4 Thinking | سلسلة استدلال + إجابة مرئية | مرتفعة (5-10 أضعاف أو أكثر) | قدرة استدلال قوية للمسائل المعقدة |
| نموذج قابل للتبديل | Claude Sonnet 4.6 (Extended Thinking) | اختياري تفعيل الاستدلال | مرونة في التبديل | تفعيل الاستدلال عند الحاجة |
3 تفاصيل رئيسية حول Thinking Tokens في Gemini 3.1 Pro
التفصيل الأول: طريقة حساب تكلفة Thinking Tokens. وفقًا للوثائق الرسمية من Google، يتم احتساب تكلفة Thinking Tokens بنفس سعر وحدات Token للإخراج القياسي. سعر وحدات Token للإخراج في Gemini 3.1 Pro هو $12 لكل مليون Token. عندما يستخدم النموذج 4000 Token للاستدلال و 500 Token للإجابة، فأنت تدفع مقابل 4500 Token للإخراج – وليس 500 فقط.
التفصيل الثاني: كيفية التمييز في استجابة API. في استجابة Gemini API، ستعيد حقل usage_metadata قيمتين منفصلتين: thoughts_token_count (عدد وحدات Token للاستدلال) و candidates_token_count (إجمالي وحدات Token للإخراج). لكن انتبه: في Gemini API، يشمل candidatesTokenCount وحدات Thinking Tokens، بينما في Vertex AI لا يشملها.
التفصيل الثالث: محتوى سلسلة الاستدلال غير مرئي افتراضيًا. يمكنك الحصول على ملخص لعملية الاستدلال (وليس السلسلة الكاملة) عن طريق تعيين includeThoughts: true. كما يمكنك تمكين عرض سلسلة الاستدلال في أدوات مثل Cherry Studio لمشاهدة عملية تفكير النموذج.
🎯 نصيحة لتوفير التكلفة: إذا كنت تقوم بمحادثات بسيطة أو مهام ترجمة ولا تحتاج إلى استدلال عميق، ننصح بالتبديل إلى نموذج عادي (مثل GPT-4o-mini أو Claude Sonnet 4.6). تدعم منصة APIYI (apiyi.com) التبديل بين النماذج بمجرد تعديل معلمة
modelواحدة، دون الحاجة لتغيير أي كود آخر.
تحسين Thinking Tokens في Gemini 3.1 Pro: 3 استراتيجيات لتوفير التكلفة
الاستراتيجية الأولى: استخدام معلمة thinking_level للتحكم في عمق الاستدلال
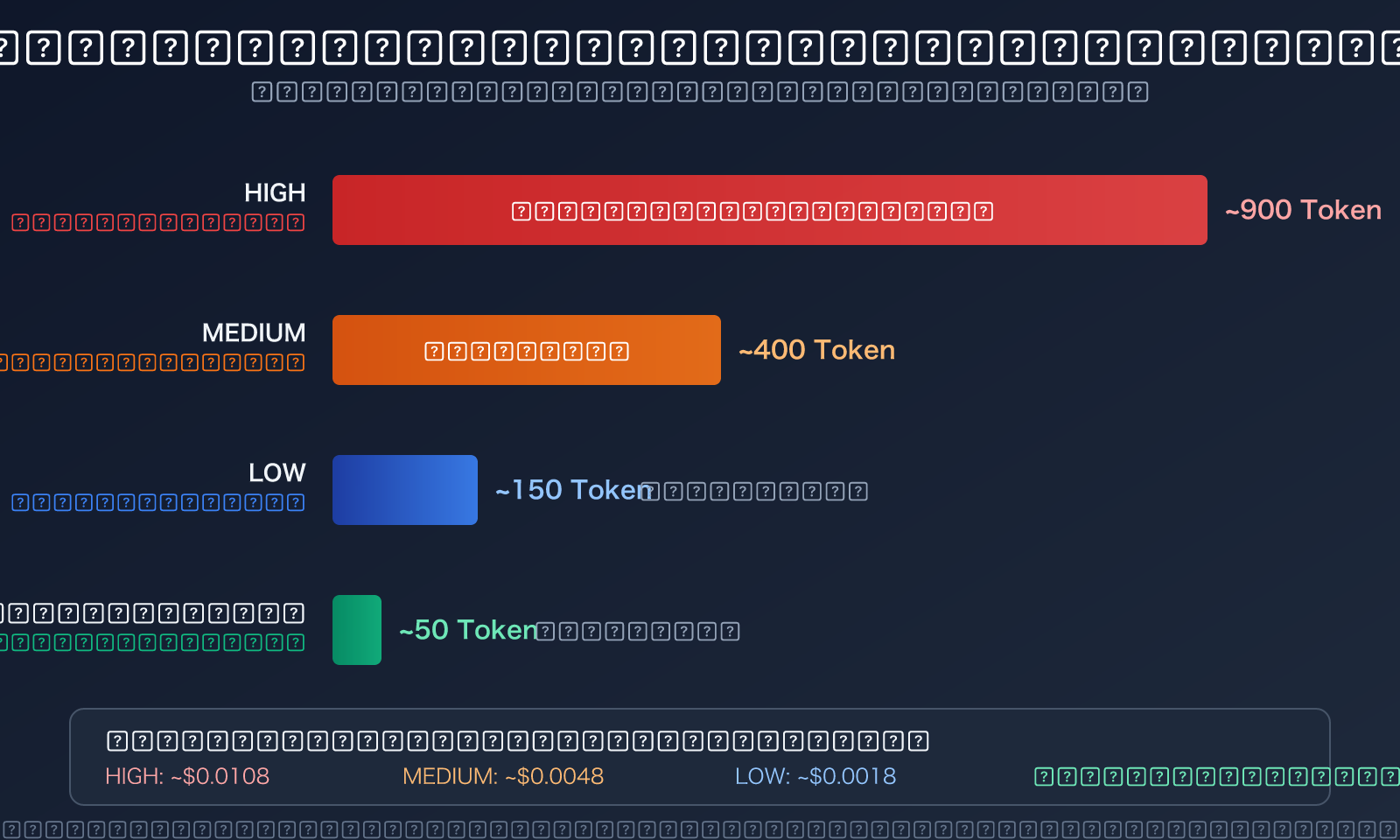
يوفر Gemini 3.1 Pro معلمة thinking_level، التي تدعم ثلاثة مستويات: LOW، MEDIUM، HIGH. يختلف استهلاك وحدات Token بشكل كبير بين المستويات:
| thinking_level | عمق الاستدلال | استهلاك Token | سيناريوهات مناسبة | مقارنة مع HIGH |
|---|---|---|---|---|
| LOW | استدلال سطحي | الأقل | الترجمة، التصنيف، الأسئلة والإجابات البسيطة | توفير حوالي 80%+ |
| MEDIUM | استدلال متوازن | متوسط | البرمجة اليومية، توليد المستندات، التحليل العام | توفير حوالي 50% |
| HIGH | استدلال عميق | الأعلى | الاستنتاج الرياضي، المسائل العلمية، المنطق المعقد | خط الأساس |
إليك مثال على كود لتعيين thinking_level:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# استخدم LOW للمهام البسيطة لتقليل Thinking Tokens بشكل كبير
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "ترجمة هذه الجملة إلى الإنجليزية: الطقس جميل اليوم"}],
extra_body={"thinking_level": "LOW"} # LOW / MEDIUM / HIGH
)
print(response.choices[0].message.content)
print(f"إجمالي وحدات Token للإخراج: {response.usage.completion_tokens}")
عرض كود التوجيه الذكي الكامل (اختيار عمق الاستدلال تلقائيًا بناءً على تعقيد السؤال)
import openai
import json
def smart_gemini_call(
prompt: str,
complexity: str = "auto",
api_key: str = "YOUR_API_KEY"
) -> dict:
"""
استدعاء ذكي لـ Gemini 3.1 Pro، يختار عمق الاستدلال تلقائيًا بناءً على تعقيد المهمة
Args:
prompt: إدخال المستخدم
complexity: "low" / "medium" / "high" / "auto"
api_key: مفتاح API
Returns:
قاموس يحتوي على الإجابة وإحصائيات استخدام Token
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# الحكم التلقائي على مستوى التعقيد
if complexity == "auto":
simple_keywords = ["ترجمة", "translate", "تصنيف", "classify", "ملخص", "summarize"]
complex_keywords = ["استنتاج", "إثبات", "حساب", "تحليل", "مقارنة", "لماذا"]
prompt_lower = prompt.lower()
if any(kw in prompt_lower for kw in simple_keywords):
thinking_level = "LOW"
elif any(kw in prompt_lower for kw in complex_keywords):
thinking_level = "HIGH"
else:
thinking_level = "MEDIUM"
else:
thinking_level = complexity.upper()
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking_level": thinking_level}
)
return {
"answer": response.choices[0].message.content,
"thinking_level": thinking_level,
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
}
# مثال على الاستخدام
# مهمة بسيطة → اختيار LOW تلقائيًا
result = smart_gemini_call("ترجمة: الطقس جميل اليوم")
print(f"عمق الاستدلال: {result['thinking_level']}, وحدات Token للإخراج: {result['output_tokens']}")
# مهمة معقدة → اختيار HIGH تلقائيًا
result = smart_gemini_call("أثبت نظرية فيثاغورس بطريقتين على الأقل")
print(f"عمق الاستدلال: {result['thinking_level']}, وحدات Token للإخراج: {result['output_tokens']}")
اقتراح: عند استدعاء Gemini 3.1 Pro عبر APIYI (apiyi.com)، يمكنك تمرير معلمة
thinking_level. نوصي بتعيينها على MEDIUM للاستخدام اليومي، واستخدام HIGH فقط في سيناريوهات الاستدلال المعقدة مثل الرياضيات أو العلوم.
الاستراتيجية الثانية: استخدام النماذج غير الاستدلالية مباشرة للمهام البسيطة
ليس كل السيناريوهات تتطلب نموذج استدلال. لمهام مثل الترجمة، تحويل التنسيق، الأسئلة والإجابات البسيطة، يمكن للنماذج غير الاستدلالية توفير 5-10 أضعاف من تكلفة وحدات Token:
- GPT-4o-mini: نسبة سعر/أداء ممتازة، الخيار الأول للمحادثات اليومية.
- Claude Sonnet 4.6 (مع إيقاف Extended Thinking): جودة إخراج عالية، وحدات Token "ما تراه هو ما تحصل عليه".
- Gemini 3.1 Flash: نموذج Google الخفيف، سريع ومنخفض التكلفة.
الاستراتيجية الثالثة: تعيين max_tokens للحد من الإخراج
إضافة معلمة max_tokens لاستدعاء API يمكن أن تمنع نموذج الاستدلال من "التفكير المفرط". لكن انتبه: max_tokens تحد من إجمالي الإخراج (الاستدلال + الإجابة). إذا تم تعيينها منخفضة جدًا، فقد يؤدي ذلك إلى اقتطاع الإجابة. نوصي بتعيينها بحيث تكون 2-3 أضعاف طول الإجابة المتوقع.
🎯 اقتراح شامل: على منصة APIYI (apiyi.com)، يمكنك استخدام واجهة موحدة للوصول إلى نماذج الاستدلال وغير الاستدلالية في نفس الوقت، والتبديل بينها ديناميكيًا بناءً على نوع المهمة. مفتاح API واحد يكفي لاستدعاء جميع سلسلة نماذج Gemini و Claude و GPT.
الأسئلة الشائعة
س1: لماذا لا يتم عرض عملية التفكير (Thinking Tokens) في نموذج Gemini 3.1 Pro بشكل افتراضي؟
هذا خيار تصميم منتج من Google. قد تحتوي سلسلة التفكير الكاملة على آلاف الرموز (Tokens) للاستدلالات الوسيطة، وعرضها مباشرة سيؤثر بشدة على تجربة المستخدم. يمكنك الحصول على ملخص للتفكير عن طريق تعيين includeThoughts: true، أو يمكنك عرض سلسلة التفكير في واجهات المستخدم مثل Cherry Studio من خلال تفعيل خاصية عرض سلسلة التفكير.
س2: كيف يمكنني رؤية عدد الرموز (Tokens) المستهلكة في عملية التفكير (Thinking Tokens) في استجابة الـ API؟
اطلع على حقل thoughts_token_count في usage_metadata الذي يعيده Gemini API. إذا كنت تستدعي النموذج عبر APIYI (apiyi.com)، يمكنك عرض تفصيل الرموز (Tokens) لكل استدعاء (الإدخال/الإخراج/التفكير) في صفحة إحصائيات الاستخدام على المنصة، مما يسهل مراقبة التكاليف وتحسينها.
س3: ما هي النماذج الأخرى التي تمتلك آلية مشابهة لـ Thinking Tokens بالإضافة إلى Gemini 3.1 Pro؟
معظم نماذج الاستدلال لديها آليات مماثلة:
- GPT-5.4 Thinking: نموذج الاستدلال من OpenAI، حيث يتم احتساب رموز التفكير (Tokens) أيضًا ضمن رموز الإخراج للفوترة.
- Claude Sonnet 4.6 Extended Thinking: وضع الاستدلال من Anthropic، يمكن تفعيله بشكل اختياري.
- DeepSeek-R1: نموذج استدلال مفتوح المصدر، حيث تكون سلسلة التفكير مرئية بالكامل.
الفرق الرئيسي هو: بعض النماذج (مثل Claude) تسمح بتشغيل/إيقاف وضع الاستدلال بشكل مرن، بينما بعض النماذج (مثل Gemini 3.1 Pro) تفعّل الاستدلال بشكل افتراضي. يمكنك استخدام واجهة APIYI (apiyi.com) الموحدة لاختبار ومقارنة استهلاك الرموز الفعلي لهذه النماذج.
الخلاصة
النقاط الأساسية لـ Thinking Tokens في نموذج Gemini 3.1 Pro:
- رموز الإخراج تتضمن سلسلة تفكير مخفية: ما تراه هو جزء الإجابة فقط، حيث يتم استهلاك أكثر من 95% من رموز الإخراج في رموز التفكير (Thinking Tokens) غير المرئية.
- رموز التفكير (Thinking Tokens) يتم احتساب تكلفتها بشكل طبيعي: يتم الفوترة حسب سعر رموز الإخراج القياسي، وقد تصل تكلفة الأسئلة البسيطة إلى 5-10 أضعاف تكلفة النماذج غير الاستدلالية.
- استخدم معلمة
thinking_levelلتوفير التكاليف: المستوىLOWيمكن أن يوفر أكثر من 80% من الرموز (Tokens)، والمستوىMEDIUMمناسب للاستخدام اليومي، بينما استخدمHIGHللمهام المعقدة فقط. - اختر نموذجًا غير استدلالي للمهام البسيطة: في سيناريوهات مثل الترجمة، التصنيف، والأسئلة والأجوبة البسيطة، يكون استخدام نموذج مثل GPT-4o-mini أو Claude Sonnet 4.6 أكثر فعالية من حيث التكلفة.
بفهم آلية رموز التفكير (Thinking Tokens)، يمكنك تخصيص ميزانية الاستدلال بشكل منطقي. نوصي باستخدام واجهة APIYI (apiyi.com) الموحدة لإدارة استدعاءات النماذج المتعددة، واختيار نموذج استدلالي أو غير استدلالي ديناميكيًا بناءً على تعقيد المهمة، لتحقيق التوازن الأمثل بين الجودة والتكلفة.
📚 المراجع
-
وثائق Google Cloud – وضع التفكير (Thinking Mode): الوثائق التقنية الرسمية لنماذج الاستدلال من جيميني
- الرابط:
docs.cloud.google.com/vertex-ai/generative-ai/docs/thinking - الوصف: المصدر الرسمي لقواعد الفوترة لـ Thinking Tokens وإعدادات معامل
thinking_level
- الرابط:
-
وثائق مطوري Google AI – عد الرموز (Token Counting): شرح رسمي لحساب الرموز وحقل
usage_metadata- الرابط:
ai.google.dev/gemini-api/docs/tokens - الوصف: كيفية التمييز بين
thoughts_token_countوcandidates_token_countفي استجابة API
- الرابط:
-
Google DeepMind – بطاقة نموذج Gemini 3.1 Pro: تفاصيل قدرات النموذج واختبارات معايير الاستدلال
- الرابط:
deepmind.google/models/model-cards/gemini-3-1-pro/ - الوصف: المصدر الرسمي لبيانات الأداء مثل 95.1% في MATH و 77.1% في ARC-AGI-2
- الرابط:
-
OpenRouter – أفضل الممارسات لرموز الاستدلال: أفضل الممارسات المجتمعية لإدارة رموز الاستدلال
- الرابط:
openrouter.ai/docs/guides/best-practices/reasoning-tokens - الوصف: مقارنة قواعد الفوترة لرموز الاستدلال عبر النماذج المختلفة ونصائح التحسين
- الرابط:
المؤلف: فريق APIYI التقني
التواصل التقني: نرحب بالنقاش حول تجارب تحسين رموز نماذج الاستدلال في قسم التعليقات. لمزيد من دروس استدعاء النماذج، يمكنك زيارة مركز وثائق APIYI على docs.apiyi.com