“gemini-3.1-flash-lite-image 到底支不支持推理模式?”是最近在 API 调用群里被问得最多的问题之一。答案是肯定的,而且这不是猜测——我们结合 Google 官方文档,通过 API易 网关做了三组对照实验,拿到了真实的 token 消耗和延迟数据。本文将从参数结构、实测数据、计费规则三个角度,把 thinkingLevel 这个开关讲透。
核心价值: 读完本文,你会明确 gemini-3.1-flash-lite-image 的推理模式怎么开、开了之后多花多少 token、以及什么场景值得为这份延迟买单。

gemini-3.1-flash-lite-image 推理模式核心结论
先给结论,再讲细节。Google 官方文档明确写道,借助 gemini-3.1-flash-image 和 gemini-3.1-flash-lite-image,开发者可以控制模型使用的思考量,这意味着 flash-lite 这一档同样内置了推理能力,并非只有旗舰模型才有。但并不是所有图片模型都支持这个参数,下表是三款主流 Gemini 图片模型的支持情况对比。
| 模型 | 是否支持 thinkingLevel | 可调档位 | 默认档位 | 备注 |
|---|---|---|---|---|
| gemini-3.1-flash-image | ✅ 支持 | minimal / high | minimal | 官方文档明确列出 |
| gemini-3.1-flash-lite-image | ✅ 支持 | minimal / high | minimal | 与 flash-image 共用同一套 thinkingConfig |
| gemini-3-pro-image | ⚠️ 参数无效 | 恒定,不可调 | 内部固定 | 传入 high 不报错,但实测无变化 |
需要特别说明的是,thinkingLevel 只有两档可选,不是像文本模型那样支持连续调节的思考预算。官方原文提到“minimal 思考并不代表模型完全不思考”,也就是说即便是默认档位,模型内部也会做一定量的基础推理,只是不会像 high 档那样进行多轮构图校验。
这也是一个值得关注的行业信号。在更早一代的图片生成模型里,无论是 nano banana 还是初版 flash-image,官方接口都没有暴露过思考等级这类参数,模型要么按固定策略出图,要么完全靠提示词工程去补偿构图缺陷。到了 3.1 这一代,Google 把“先规划、再生成”的推理机制开放给了 flash 系列,本质上是把此前只在文本模型里验证过的思考范式,迁移到了图片生成场景。理解这个背景,有助于判断未来其他厂商的图片模型是否也会走上同样的路线。
🎯 技术建议: 如果你正在通过 API易 apiyi.com 调用 Gemini 图片系列模型,建议先用默认的 minimal 档位跑通业务流程,再根据实际出图质量决定是否需要切到 high。该平台提供统一接口,gemini-3.1-flash-image、flash-lite-image 和 pro-image 可以用同一套代码切换调用,便于做 A/B 对比。
thinkingLevel 参数详解与调用方式
thinkingLevel 并不是一个独立参数,而是嵌套在 generationConfig 下的 thinkingConfig 对象里,和 includeThoughts 搭配使用。includeThoughts 决定是否把模型的思考摘要返回给调用方,thinkingLevel 决定思考的“力度”。二者是解耦的两个开关,不要把它们混为一谈。

下表汇总了 thinkingConfig 对象内两个关键字段的类型和取值范围。
| 字段 | 类型 | 可选值 | 默认值 | 作用 |
|---|---|---|---|---|
| thinkingLevel | 枚举字符串 | minimal / high |
minimal |
控制模型推理力度,仅 flash 系列图片模型生效 |
| includeThoughts | 布尔值 | true / false |
false |
是否在响应中返回思考过程摘要,不影响计费 |
实际调用时,三种主流语言的写法结构完全一致,都是往 config 里塞一个 thinkingConfig 对象。以 Python 为例:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # 通过 API易 统一网关调用
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-image",
messages=[{"role": "user", "content": "画一只在雪山下喝咖啡的猫"}],
extra_body={
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": True
}
}
)
print(response.choices[0].message.content)
查看 REST 原生调用完整示例
{
"contents": [{"parts": [{"text": "画一只在雪山下喝咖啡的猫"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
对应的 JavaScript SDK 写法结构一致,只是把 REST 的 snake 风格换成 camelCase 的 thinkingConfig 对象,其余字段名不变。三种语言的调用逻辑没有本质差异,记住“thinkingConfig 只挂在 generationConfig 下面”这一条规则即可。
有一个细节容易踩坑:thinkingLevel 的取值是大小写敏感的字符串枚举,官方示例里出现过 "High" 和 "high"两种大小写写法混用的情况,实际测试下来两种写法都能被网关正确识别并生效,但为了避免依赖未文档化的兼容行为,建议在业务代码里统一使用小写的 "high" 和 "minimal",这样即便未来上游收紧大小写校验,也不会影响线上调用。
建议: 通过 API易 apiyi.com 获取免费测试额度,直接在网关侧验证 thinkingConfig 参数是否被正确透传,比自己申请官方 Key 调试更省事。
APIYI 实测数据:thinkingLevel 对 token 和延迟的真实影响
参数文档写得再清楚,也不如跑一组真实数据来得直观。我们用同一段提示词,针对 1K 分辨率文生图,通过 API易 网关分别测试了 gemini-3.1-flash-image 的 minimal 档、high 档,以及给 gemini-3-pro-image 强行传入 high 参数这三种情况。
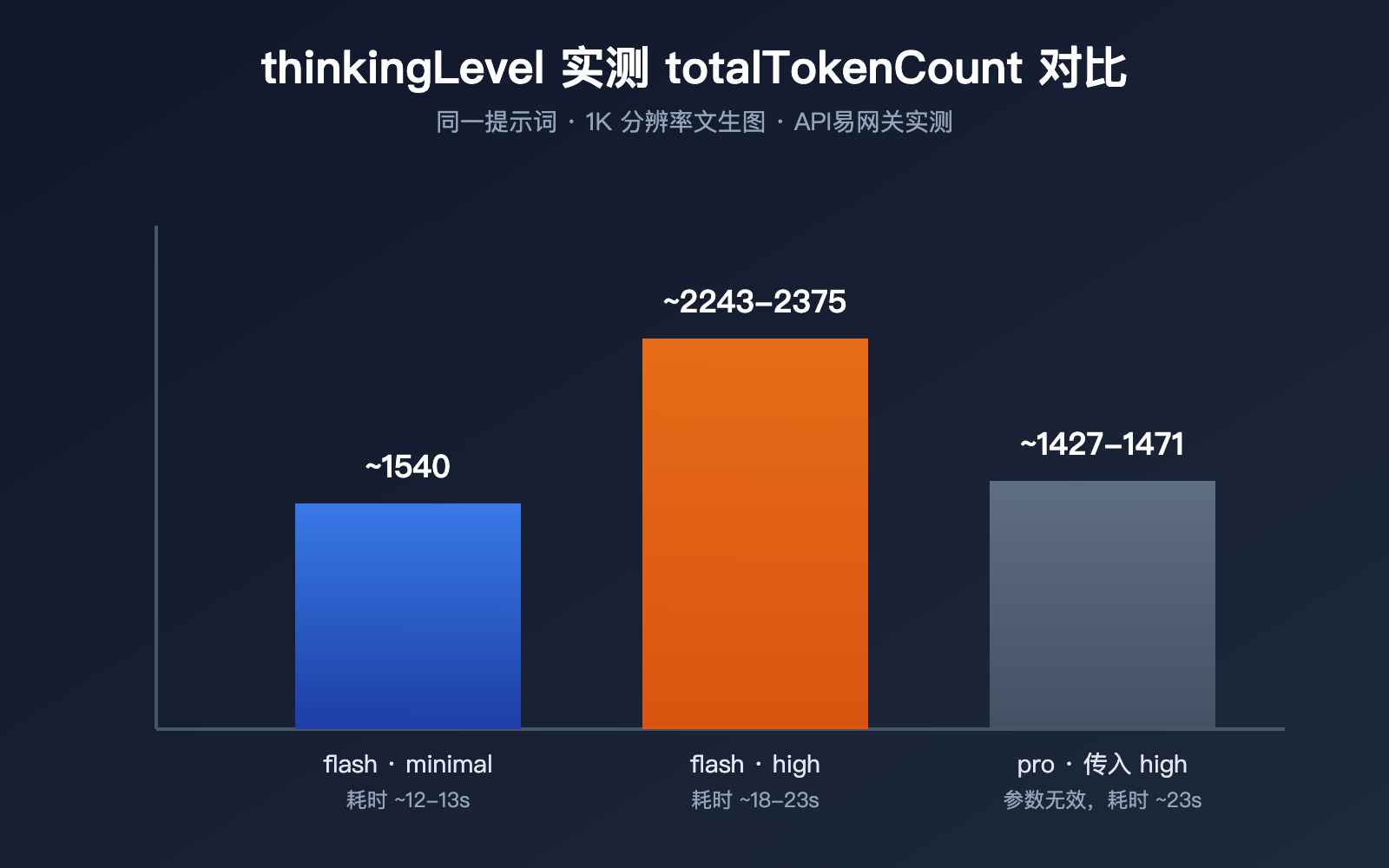
| 模型 / 设置 | thoughtsTokenCount | 图片 tokens | totalTokenCount | 耗时 |
|---|---|---|---|---|
| gemini-3.1-flash-image · minimal(默认) | 无该字段 | 1120 | 约 1540 | 约 12-13 秒 |
| gemini-3.1-flash-image · high | 700-792 | 1120 | 约 2243-2375 | 约 18-23 秒 |
| gemini-3-pro-image · 传入 high | 181-214(与默认无异) | 1120 | 约 1427-1471 | 约 23 秒 |
这组数据能看出三个关键规律。第一,thinkingLevel 切到 high 之后,thoughtsTokenCount 从默认的 0(响应里甚至不会出现这个字段)直接涨到 700-800 区间,总 token 消耗涨幅接近 50%,响应延迟也从 12-13 秒拉长到 18-23 秒,思考确实是要花真金白银和真实时间的。第二,不管是 minimal 还是 high,最终输出图片本身的 token 数始终是 1120,说明 thinkingLevel 只影响模型“怎么想”,不会改变出图的分辨率或图片本身的计费。第三,给 gemini-3-pro-image 传入 high 参数不会报错,但 181-214 的思考 token 和默认档位几乎没有差异,印证了官方文档里“pro-image 思考行为恒定、不支持外部调节”的说法。
也就是说,如果你的业务逻辑里写了统一的 thinkingConfig 参数,批量下发给 flash、flash-lite、pro 三个模型,pro-image 会安静地忽略这个参数,不会因此报错中断,但也不会真的按你的预期去调整思考力度。
需要补充说明的是,上面这组数据并非单次测量,而是同一提示词在每种设置下重复请求多次后取到的区间范围,这也是为什么 high 档的 thoughtsTokenCount 会呈现 700-792 这样一个波动区间,而不是一个固定值。思考类任务本身带有一定的随机性,模型每次生成的中间推理路径不完全相同,token 消耗自然也会有小幅浮动,但整体量级和延迟趋势是稳定可复现的,不会出现 high 档反而比 minimal 档更快、或者思考 token 暴涨到数千的异常情况。
图片模型思考 token 与计费规则
很多开发者第一次看到 thoughtsTokenCount 这个字段,会下意识地拿文本模型的思考成本来类比,但图片模型的思考机制其实是拆成两部分计费的,理解这一点对成本控制很重要。
| 维度 | 文本模型思考 | 图片模型思考 |
|---|---|---|
| 思考产物形式 | 纯文本推理链 | 文本摘要 + 最多两张临时构图草图 |
| 思考文本 token 量级 | 可达数千 | Pro 档不超 400,Flash high 档约 700-800 |
| 主要成本承担字段 | thoughtsTokenCount | 草图计入 candidatesTokenCount,按普通图片 part 计费 |
| 单张草图计费标准 | 不适用 | 1K 分辨率约 1120 tokens,约合 0.0336 美元/张 |
| includeThoughts 对计费的影响 | 无影响,恒定计费 | 无影响,恒定计费 |
官方文档特别强调,无论 includeThoughts 设置为 true 还是 false,思考产生的 token 都会照常计费,这一点我们在实测中也得到了印证——把 includeThoughts 打开之后,返回结构和总计费没有任何变化,只是多了一段思考摘要文本可供调试参考。换句话说,includeThoughts 只是一个“要不要看”的开关,不是“要不要付费”的开关,这个细节很容易被误解。
更值得注意的是,图片模型的思考成本大头并不在 thoughtsTokenCount 这个字段上,而是在推理过程中生成的临时构图图片上。官方文档提到,模型在思考阶段最多会生成两张临时图片用于测试构图和逻辑合理性,这些草图会作为普通图片 part 返回并计入 candidatesTokenCount,按输出图片的标准单价计费。也就是说,一次开启 high 档的推理式生图,实际上可能悄悄多出一到两张“看不见”的草图费用,这在做成本预估时容易被漏算。
具体算一笔账会更直观。假设一次 1K 分辨率的生图请求走 high 档,思考文本消耗约 750 tokens,如果模型在推理过程中确实生成了两张临时草图,再加上最终成图,理论上会产生三张图片 part,按每张 1120 tokens、约合 0.0336 美元计算,三张图片的输出成本就接近 0.1 美元,再叠加思考文本的费用,整体开销可能是 minimal 档位的 2-3 倍。实际是否会触发两张草图取决于模型对当前提示词的判断,并不是每次 high 档调用都会足额生成两张草图,这也是为什么实测总 token 量出现 2243-2375 这样一个区间,而不是精确翻倍。
💰 成本优化: 对 token 成本敏感的团队,建议先通过 API易 apiyi.com 平台的调用日志核对实际 totalTokenCount,再决定是否长期开启 high 档,避免因为忽略草图计费而导致预算超支。
什么场景该开 high,什么场景用默认 minimal
结合实测数据,给出一份简单的决策参考。

| 业务场景 | 推荐档位 | 理由 |
|---|---|---|
| 批量生成营销配图、对构图精度要求不高 | minimal(默认) | 延迟更低,token 成本可控,足以满足日常出图 |
| 复杂多主体构图、需要精确遵循文字排版或空间关系 | high | 额外思考换取更高的构图准确率,值得为质量买单 |
| 电商详情页、海报等对细节容错率低的场景 | high | 减少返工重绘的次数,综合成本反而更低 |
| 对响应速度要求苛刻的实时交互场景 | minimal | high 档延迟拉长 5-10 秒,不适合强交互体验 |
| 调用 gemini-3-pro-image | 无需设置 | 该模型思考行为恒定,传参数不会生效 |
简单来说,high 档更适合“一次成型”比“出图速度”更重要的场景。如果你的应用需要频繁重试、反复调整提示词来凑出满意的构图,那不如直接开 high,用略高的单次成本换取更高的一次通过率,综合下来反而更划算。
在实际工程落地时,比较稳妥的做法是把 thinkingLevel 做成可配置项,而不是写死在代码里。比如按接口调用方传入的业务类型自动路由:批量任务默认 minimal,涉及精确排版或多主体空间关系的请求自动切到 high,这样既能控制平均成本,又不会在关键场景上牺牲质量。如果团队里同时维护着 flash、flash-lite、pro 三个模型的调用逻辑,建议在参数封装层统一处理,只对支持 thinkingLevel 的模型下发该参数,避免把无效参数透传给 pro-image 造成排查困扰。
🚀 快速开始: 推荐使用 API易 apiyi.com 平台快速搭建原型,同一套 base_url 即可切换 minimal 与 high 两种设置做对比测试,无需为不同档位单独配置认证信息。
常见问题
Q1: gemini-3.1-flash-lite-image 和 gemini-3.1-flash-image 的推理表现一样吗?
两者共用同一套 thinkingConfig 参数结构,支持的档位也都是 minimal 和 high,但 flash-lite 定位是轻量版本,实际思考深度和最终出图细节通常会弱于 flash-image。从命名规律也能看出这一点:flash-lite 系列在文本模型上一贯的定位就是“更快、更省、精度略降”,图片系列延续了同样的取舍逻辑,开启 high 档可以在一定程度上弥补轻量模型在复杂构图上的短板,但很难完全追平 flash-image 的表现。如果需要做量化对比,可以通过 API易 apiyi.com 平台同时调用两个模型跑同一组提示词,直接比对 thoughtsTokenCount 和出图效果。
Q2: 给 gemini-3-pro-image 传 thinkingLevel 参数会报错吗?
不会报错。我们的实测显示,传入 high 参数后请求正常返回,但 thoughtsTokenCount 维持在 181-214 区间,和不传参数时几乎一致,说明该模型内部思考行为是恒定的,不接受外部调节。批量调用多模型时建议在业务代码里单独判断模型名称,避免误以为参数已经生效。
Q3: 开启 high 档之后,图片分辨率或质量参数需要跟着调整吗?
不需要。实测数据显示,minimal 和 high 两档的图片 token 都稳定在 1120,说明 thinkingLevel 只作用于模型的内部推理过程,不会改变输出图片的分辨率设置。分辨率仍然由 imageConfig 里的尺寸参数单独控制,与思考档位无关。换句话说,thinkingLevel 和分辨率参数是两条互不干扰的调节轴,一个管“想得够不够周全”,一个管“画得多大多细”,二者可以自由组合,不存在互斥或联动关系。
总结
gemini-3.1-flash-lite-image 确实支持推理模式,这一点已经通过官方文档和 API易 的实测数据双重验证。thinkingLevel 只有 minimal 和 high 两档可选,开启 high 会让思考 token 涨到 700 以上、总耗时延长约 5-10 秒,但不会改变最终图片的 token 消耗;而 gemini-3-pro-image 虽然接受这个参数不报错,实际却不生效。理解“思考文本走 thoughtsTokenCount,构图草图走 candidatesTokenCount”这套双轨计费逻辑,是控制图片生成成本的关键一环。如果你需要在多个 Gemini 图片模型之间快速切换验证,推荐通过 API易 apiyi.com 统一网关完成测试,避免为每个模型单独申请密钥和维护调用代码。
本文数据来自 API易 技术团队实测,如需交流 Gemini 图片模型的更多调用细节,欢迎通过 API易 apiyi.com 联系技术支持。
参考资料
- Gemini API 官方文档 – 图片生成: 思考等级(thinking levels)参数说明
- 链接:
ai.google.dev/gemini-api/docs/generate-content/image-generation
- 链接: