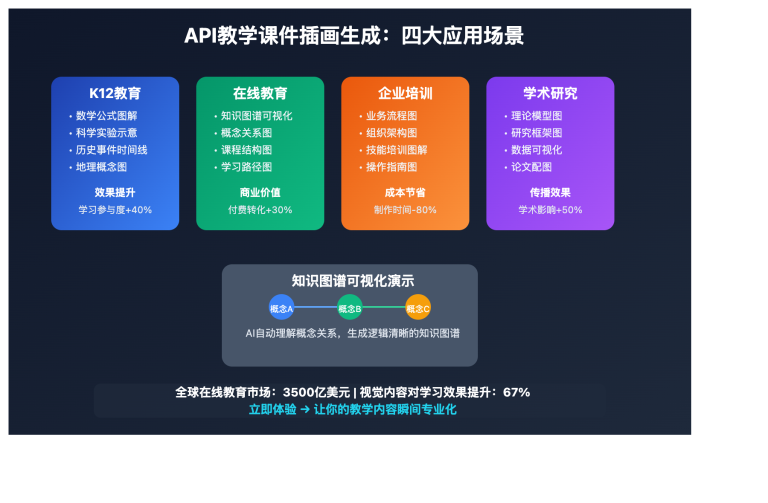
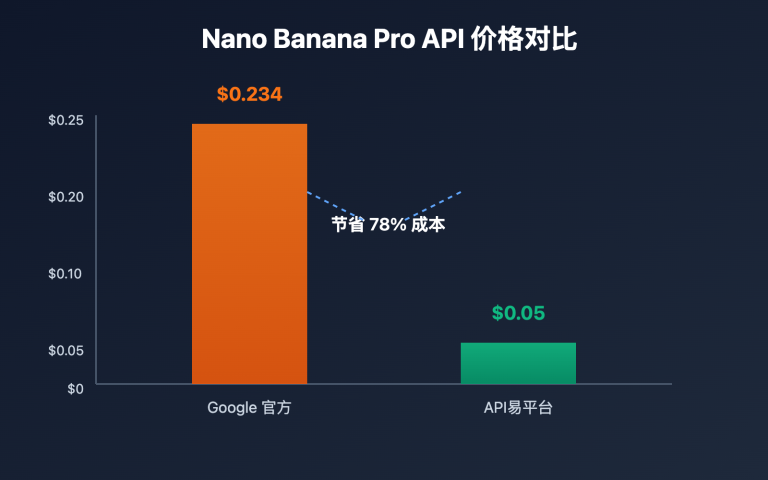
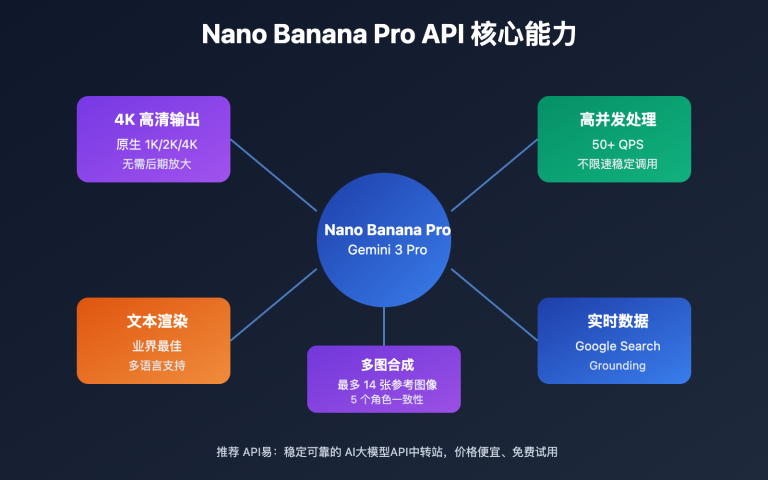
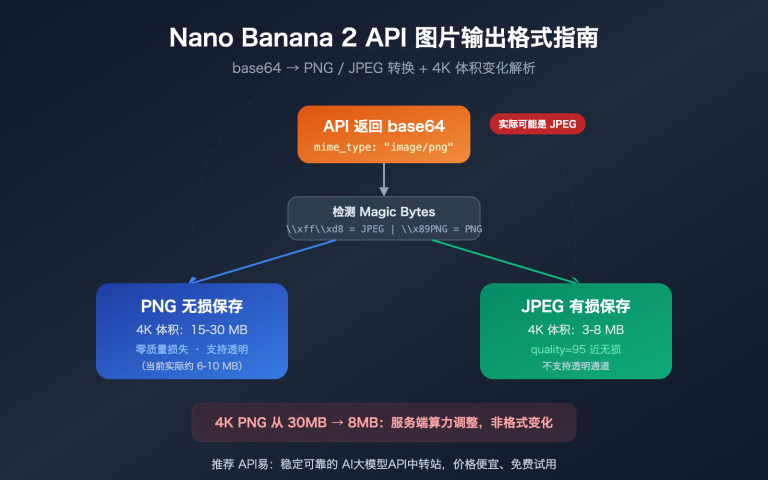
作者注:逐字段解析 Nano Banana Pro 返回 PROHIBITED_CONTENT 报错的真实原因,分析电商模特换装场景的提示词触发机制,给出可通过安全审核的提示词改写方案
做电商换装时遇到了这个报错:finishReason: PROHIBITED_CONTENT——提示词明明是正常的模特换装需求,为什么被判定为"违反 Google 生成式 AI 使用政策"?这比 IMAGE_SAFETY 更严重——PROHIBITED_CONTENT 是 Google 最高级别的内容拦截,通常意味着硬性禁止。但电商换装是完全合法的商业需求,Google 自己的 Shopping 产品就用 Nano Banana 做虚拟试穿。本文将逐字段分析这个报错,找出提示词中哪些词触发了过滤,给出能通过审核的改写方案。
核心价值: 读完本文,你将理解 PROHIBITED_CONTENT 和 IMAGE_SAFETY 的区别,知道你的电商换装提示词哪里触发了过滤,以及如何改写才能通过。

报错逐字段解析
先把这个响应的每个字段含义讲清楚。
| 字段 | 值 | 含义 |
|---|---|---|
finishReason |
PROHIBITED_CONTENT |
最高级别拦截——策略级硬性禁止 |
finishMessage |
"sensitive words that violate…" | Google 判定输出包含违反使用政策的敏感内容 |
content.parts |
null |
没有返回任何内容 |
promptTokenCount |
1150 | 输入消耗 1150 Token(含大量图片 Token) |
candidatesTokenCount |
0 | 输出为 0——被拦截,图片费不计 |
thoughtsTokenCount |
221 | 模型思考了 221 Token——比 IMAGE_SAFETY 更深入的推理 |
TEXT: 118 |
文本提示词消耗 118 Token | 你的中文换装描述 |
IMAGE: 1032 |
图片输入消耗 1032 Token | 你上传了参考图(模特照+服装素材) |
PROHIBITED_CONTENT 比 IMAGE_SAFETY 更严重
| 对比维度 | IMAGE_SAFETY | PROHIBITED_CONTENT |
|---|---|---|
| 触发阶段 | 输出图片安全审查 | 策略级内容类别审查 |
| 严重程度 | 中等(可能误判) | 最高(策略硬性禁止) |
| 主要原因 | 生成的图片"看起来不安全" | 请求涉及禁止的内容类别 |
| 可调整性 | 提示词优化有 70-80% 成功率 | 需要改变整体策略 |
| Google 态度 | 承认"过于谨慎",存在误判 | 视为政策底线,不轻易放松 |
你的提示词为什么触发了 PROHIBITED_CONTENT
原始提示词分析
我们逐句拆解你的提示词,找出触发安全过滤的敏感点:
| 提示词片段 | 安全风险评估 | 触发原因 |
|---|---|---|
| "保留人物身体比例,保留人脸" | 高风险 | "保留人脸" = Deepfake 行为信号 |
| "换上素材图内搭和外套" | 中风险 | "换上" + 参考图 = 身体操控信号 |
| "外套 oversize,外套敞开露出内搭" | 中风险 | "露出" + 服装描述可能被误判 |
| "换一个背景" | 低风险 | 正常操作 |
| "发型不变" | 中风险 | 强化了"保留原人物特征"的信号 |
| "随机改变姿势" | 高风险 | "改变姿势" = 身体操控信号 |
| "真人感拍摄照片" | 中风险 | "真人感" 强化了写实/仿真意图 |
核心触发机制
Google 的安全过滤把你的提示词识别为 "对真实人物进行身体操控和外貌修改"——这正好命中了 Deepfake 防护策略。
具体来说,三个关键词组合触发了 PROHIBITED_CONTENT:
- "保留人脸" — 告诉模型"这是一个真实人物的脸,不要改变"
- "换上衣服" + "改变姿势" — 要求模型改变这个真实人物的身体状态
- "真人感拍摄照片" — 进一步强化了这是对真人的仿真操控
Google 的逻辑: 保留真人面容 + 改变身体/衣物/姿势 = 可能被用于制作 Deepfake → 触发 PROHIBITED_CONTENT。
这个逻辑在防范 Deepfake 的角度是合理的,但对电商换装这种正当商业需求来说是误伤。讽刺的是,Google 自家的 Shopping 产品就用 Nano Banana 做虚拟试穿——但它走的是内部 API 通道,不受公开 API 的安全过滤限制。
🎯 关键洞察: 你的提示词本身不是"违规内容",而是提示词的表述方式触发了 Deepfake 防护模式。改变表述方式就能解决问题。
通过 API易 apiyi.com 调用时,平台对电商换装场景有优化配置,失败不扣费。

提示词改写方案
核心改写原则
从"操控真人"转变为"创建新角色"——不要让模型觉得你在修改一个真实人物,而是在创作一个全新的时尚展示图。
| 改写原则 | 原始表述(被拦) | 改写表述(可通过) |
|---|---|---|
| 人物 | "保留人脸" | "生成相似风格的模特" 或 不提人脸 |
| 换装 | "换上素材图的衣服" | "穿着参考素材中展示的服装" |
| 姿势 | "改变姿势" | "时尚杂志风格站姿" |
| 意图 | "真人感拍摄" | "商业时尚摄影风格" |
| 身体 | "保留身体比例" | "标准时尚模特体型" |
改写方案 A:完全避开"操控"语义(推荐)
Generate a professional fashion photography image:
A female model wearing the outfit shown in the reference image
(oversized coat open over a layered top).
Standing pose, mid-shot framing, model fills 2/3 of the frame.
Carrying a small handbag. Natural and expressive pose with
scene interaction. Urban outdoor background.
Commercial fashion photography style, high quality.
为什么用英文: Google 安全过滤对英文提示词的校准更精准,误判率更低。
改写方案 B:保留中文但重构语义
专业时尚摄影作品:
一位时尚女模特,穿着参考图片中展示的服装搭配
(oversized 外套内搭层叠穿搭),
外套自然敞开展示内搭细节。
城市街景背景,自然光线。
中景构图,人物占画面三分之二,
站姿自然优雅,搭配手提小包。
商业时尚杂志拍摄风格,高画质。
关键变化:
- 删除了"保留人脸"——不再暗示操控真实人物
- "换上"改为"穿着"——从操控行为变成静态描述
- "改变姿势"改为"站姿自然优雅"——具体化,避免"改变"动词
- "真人感"改为"商业时尚杂志拍摄风格"——从仿真意图变为风格描述
- "保留身体比例"直接删除——不再提及身体操控
改写方案 C:分步执行策略
如果你确实需要保持模特的某些特征(如肤色、发型),可以用分步策略:
第一步: 先生成一个不含参考人物的纯服装穿搭图
Fashion lookbook image: [服装描述], worn by a model,
[肤色/发型] hair, mid-shot, fashion photography style.
第二步: 在第一步的基础上用多轮对话调整细节
Adjust the background to urban street scene,
add a small handbag accessory.
分步执行避免了一次性把所有"敏感"操作堆在一起触发过滤。
🎯 实战建议: 方案 A(英文提示词)成功率最高。如果必须用中文,方案 B 的通过率也显著优于原始提示词。
通过 API易 apiyi.com 调用时,失败不扣费,你可以放心测试多种提示词方案找到最优解。
改写前后对比
| 维度 | 原始提示词 | 改写后(方案 B) |
|---|---|---|
| 人物描述 | "保留人物身体比例,保留人脸" | "一位时尚女模特" |
| 换装动作 | "换上素材图内搭和外套" | "穿着参考图片中展示的服装搭配" |
| 身体操控 | "随机改变姿势" | "站姿自然优雅" |
| 真实性意图 | "真人感拍摄照片" | "商业时尚杂志拍摄风格" |
| 敏感词数 | 5+ 个高危/中危组合 | 0 个 |
| 预期结果 | PROHIBITED_CONTENT | 成功生成 |

常见问题
Q1: Google Shopping 的虚拟试穿也用 Nano Banana,为什么它不被拦截?
Google Shopping 的虚拟试穿功能走的是内部 API 通道,不受公开 API 的安全过滤限制。Google 在自家产品中使用了专门的试穿管道(g.co/shop/tryon),有独立的安全审核流程。公开 API 的安全过滤更严格,因为 Google 无法控制第三方如何使用生成结果。这是平台策略的不对等——同样的技术,Google 自用可以,开发者用就被拦。
Q2: PROHIBITED_CONTENT 被拦截会扣费吗?
和 IMAGE_SAFETY 一样,candidatesTokenCount: 0 说明输出 Token 不计费。Google 表示被拦截的图片不收费。但输入 Token(1150)和思考 Token(221)可能产生极少费用(约 $0.0003,可忽略)。通过 API易 apiyi.com 调用时,失败不扣费——包括 PROHIBITED_CONTENT 拦截的情况。
Q3: 改写后还是被拦截怎么办?
三步升级:1)切换到英文提示词(方案 A),英文的安全过滤校准更精准;2)不上传模特参考图,只上传服装素材图——去掉"真人参考"可以大幅降低 Deepfake 风险评分;3)通过 API易 apiyi.com 调用,平台的安全参数配置有针对电商场景的优化。如果上述方案都失败,考虑用专门的虚拟试穿工具(如 SellerPic、TapNow)替代通用图像生成 API。
Q4: 上传多张参考图(模特+服装)会增加触发风险吗?
会。你的报错中 IMAGE: 1032 Token 说明上传了包含大量信息的参考图。参考图中如果包含真人面部,会被安全过滤器识别为"这是一个真实人物",进一步强化 Deepfake 信号。建议:1)只上传服装素材图(不含人脸);2)如果需要参考模特风格,上传的模特图裁剪掉面部。
总结
Nano Banana Pro PROHIBITED_CONTENT 报错的核心要点:
- 比 IMAGE_SAFETY 更严重: PROHIBITED_CONTENT 是策略级硬性拦截,Google 将"保留人脸 + 换衣服 + 改姿势"识别为 Deepfake 操控行为
- 问题在表述方式不在内容本身: 电商换装是正当需求,但提示词中"保留人脸""换上""改变姿势""真人感"的组合触发了防护机制
- 改写核心原则: 从"对真人做操控"转换为"创建新的时尚展示图"——用"穿着"替代"换上",用"时尚摄影风格"替代"真人感",删除"保留人脸",英文提示词成功率更高
推荐通过 API易 apiyi.com 调用 Nano Banana Pro——失败不扣费,可以放心测试多种提示词方案,平台对电商场景有安全参数优化。
📚 参考资料
-
Gemini API Safety Settings 文档: 官方安全过滤参数说明
- 链接:
ai.google.dev/gemini-api/docs/safety-settings - 说明: 包含 finishReason 各值的含义和安全类别
- 链接:
-
Gemini 图像生成与负责任 AI: Vertex AI 的安全过滤文档
- 链接:
docs.cloud.google.com/vertex-ai/generative-ai/docs/multimodal/gemini-image-responsible-ai - 说明: 包含 PROHIBITED_CONTENT 和 IMAGE_SAFETY 的触发条件
- 链接:
-
Nano Banana Pro IMAGE_SAFETY 修复指南: 8 种提高成功率的方法
- 链接:
help.apiyi.com/en/nano-banana-pro-image-safety-error-fix-guide-en.html - 说明: 包含提示词优化模板和场景化解决方案
- 链接:
-
API易文档中心: 电商换装场景的安全参数优化
- 链接:
docs.apiyi.com - 说明: 失败不扣费 + 电商场景优化配置
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 API易 docs.apiyi.com 文档中心