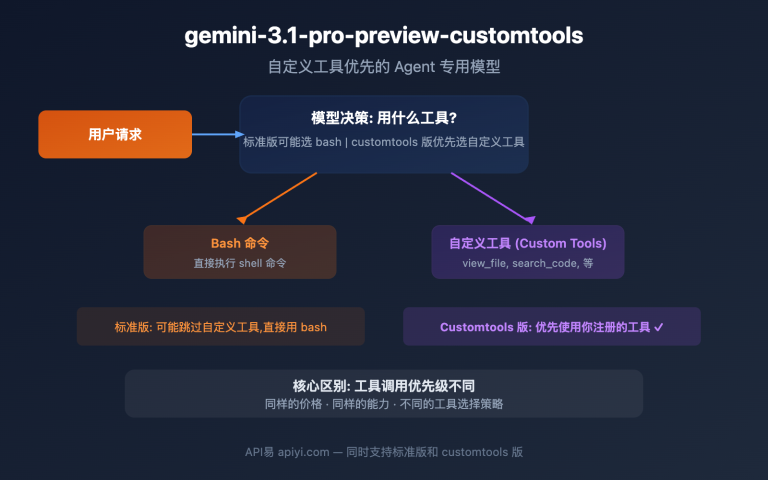
2026 年 6 月 1 日,MiniMax 正式发布开源新旗舰 MiniMax-M3。这是业界第一个在单一模型里同时做到三件事的开放权重模型:前沿级编程能力、100 万 token 上下文窗口、原生多模态输入。SWE-Bench Pro 跑出 59.0 分,直接反超 GPT-5.5 和 Gemini 3.1 Pro,逼近 Claude Opus 4.7。
更有冲击力的是价格。官方标准价输入 $0.60 / 输出 $2.40 每 1M tokens,本身就只有同级闭源模型的 5%-10%;发布期再叠加限时 5 折,降到输入 $0.30 / 输出 $1.20。目前 MiniMax-M3 已同步上线 API易 apiyi.com 平台,对齐官网 5 折价,叠加充值赠送后实际成本最低约 4.1 折,活动截止 6 月 8 日零点(UTC+8)。
本文会把 MiniMax-M3 的架构亮点、基准成绩、价格阶梯和接入代码一次讲清,帮你在活动窗口期内判断它值不值得切换。

MiniMax-M3 是什么:开源阵营的"三合一"旗舰
MiniMax-M3 是 MiniMax 继 M2 系列之后的新一代旗舰,定位是面向编程和 Agent 场景的通用模型。它采用细粒度 MoE(混合专家)架构,总参数约 229.9B,每个 token 仅激活约 9.8B 参数,分布在 256 个专家上。这意味着它在推理成本上更接近一个 10B 级别的小模型,能力上却对标第一梯队旗舰。
训练数据规模约 100 万亿 tokens,并且从预训练阶段就混入了图文交错数据。所以 MiniMax-M3 的多模态是"原生"的——图像、视频理解能力直接长在语义空间里,而不是后期外挂视觉编码器拼接出来的。除了图片和视频输入,它还支持桌面计算机操作(Computer Use),为 Agent 场景留足了接口。
官方承诺模型权重和技术报告将在发布后 10 天内完全开源,届时可以在 HuggingFace 与 GitHub 获取,支持私有化部署和微调。参考此前 M2 系列采用的修改版 MIT 许可,商用门槛预计很低,具体以正式发布的许可证为准。
MiniMax-M3 核心规格一览
| 维度 | MiniMax-M3 规格 |
|---|---|
| 发布时间 | 2026 年 6 月 1 日 |
| 架构 | 细粒度 MoE,总参数 229.9B / 激活 9.8B,256 专家 |
| 注意力机制 | MSA(MiniMax Sparse Attention)稀疏注意力 |
| 上下文窗口 | 1,000,000 tokens(约为 M2 系列的 5 倍) |
| 模态支持 | 文本 + 图像 + 视频输入,文本输出,支持桌面操作 |
| 训练数据 | 约 100T tokens,图文交错多模态语料 |
| 思考模式 | 可开关的 Thinking 模式,价格一致 |
| 开源计划 | 发布后 10 天内开放权重与技术报告 |
🎯 快速体验建议:想第一时间验证 MiniMax-M3 的真实水平,不必等权重放出再自建集群。我们建议直接通过 API易 apiyi.com 的 OpenAI 兼容接口调用,模型名填
MiniMax-M3即可,几分钟就能跑通对比测试,活动期间成本还能再砍一半。
MiniMax-M3 基准成绩:SWE-Bench Pro 59.0 意味着什么
SWE-Bench Pro 是目前公认最难的真实软件工程基准之一,考察模型在真实仓库里修 Bug、写补丁的端到端能力。MiniMax-M3 拿到 59.0 分,官方对比数据显示这一成绩同时超过了 GPT-5.5 和 Gemini 3.1 Pro,与 Claude Opus 4.7 只有一步之遥。对一个即将开源、激活参数不到 10B 的模型来说,这是开源阵营首次在该基准上压过闭源旗舰。
编程之外,Agent 相关指标同样亮眼。Terminal-Bench 2.1 拿到 66.0 分,MCP Atlas 拿到 74.2 分,BrowseComp 自主浏览任务 83.5 分——最后这项甚至小幅超过了 Claude Opus 4.7。多模态侧,SVG-Bench 超过 Opus 4.7,文档理解基准 OmniDocBench 高于 Gemini 3.1 Pro。
当然它并非全面碾压。在考察科研后训练能力的 PostTrainBench 上,MiniMax-M3 得分 0.37,低于 Claude Opus 4.7 的 0.42,与 GPT-5.5 的 0.39 基本持平。也要提醒一句:目前这批数字主要来自官方技术博客,第三方独立复测还在进行中,关键业务建议自己跑评测确认。
MiniMax-M3 与主流旗舰模型对比
| 基准测试 | MiniMax-M3 | 对比结论 |
|---|---|---|
| SWE-Bench Pro | 59.0 | 超过 GPT-5.5 与 Gemini 3.1 Pro,逼近 Opus 4.7 |
| Terminal-Bench 2.1 | 66.0 | 终端 Agent 任务第一梯队 |
| BrowseComp | 83.5 | 小幅超过 Claude Opus 4.7 |
| MCP Atlas | 74.2 | 工具调用与 MCP 生态适配能力强 |
| SWE-fficiency | 34.8 | 兼顾补丁质量与效率 |
| PostTrainBench | 0.37 | 低于 Opus 4.7(0.42),持平 GPT-5.5(0.39) |
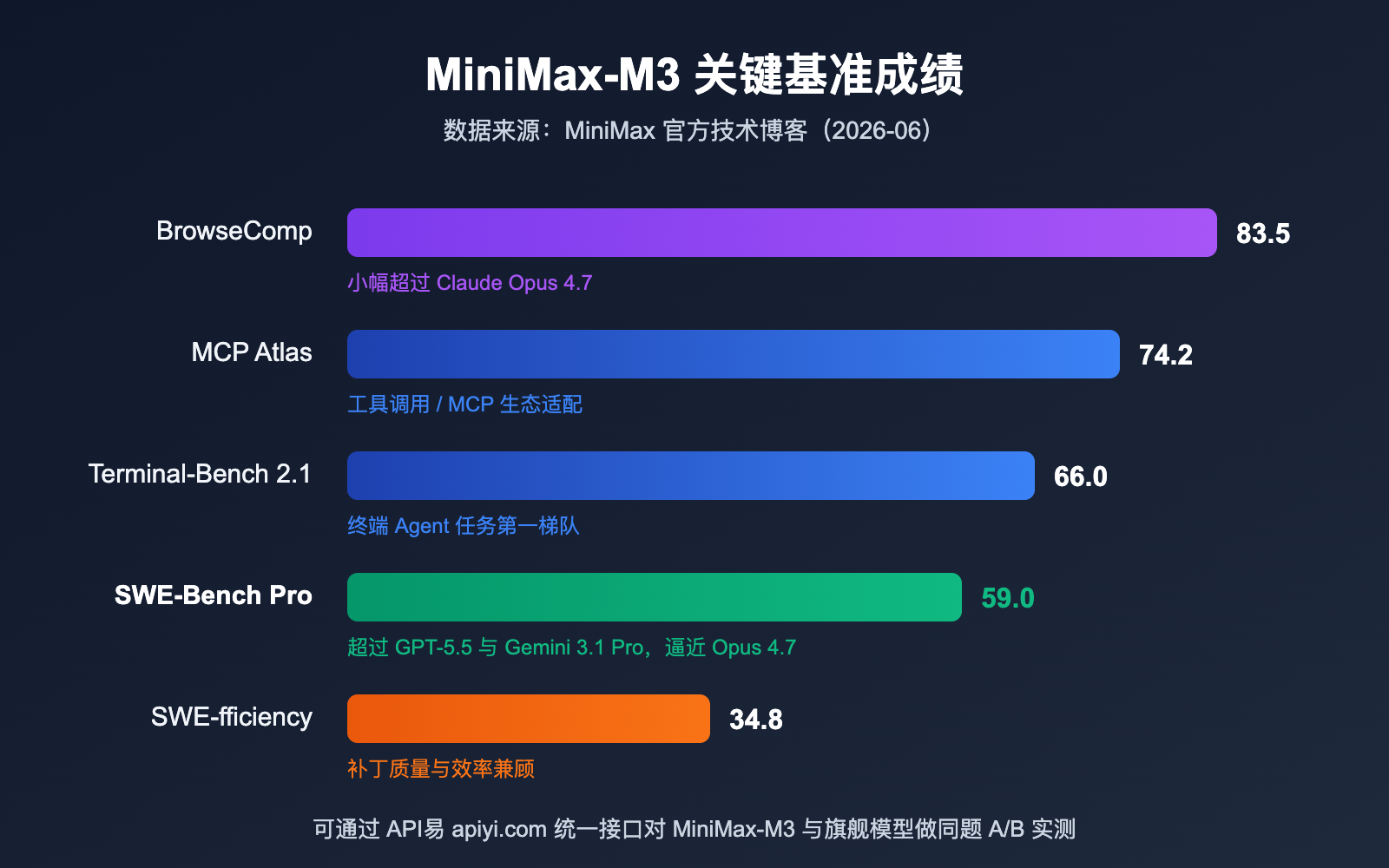
如果你想横向验证这些数字,可以在 API易平台上用同一套 Prompt 同时调用 MiniMax-M3、GPT-5.5 和 Claude Opus 4.7——平台统一了接口格式,切换模型只需要改一个 model 参数,非常适合做 A/B 评测。
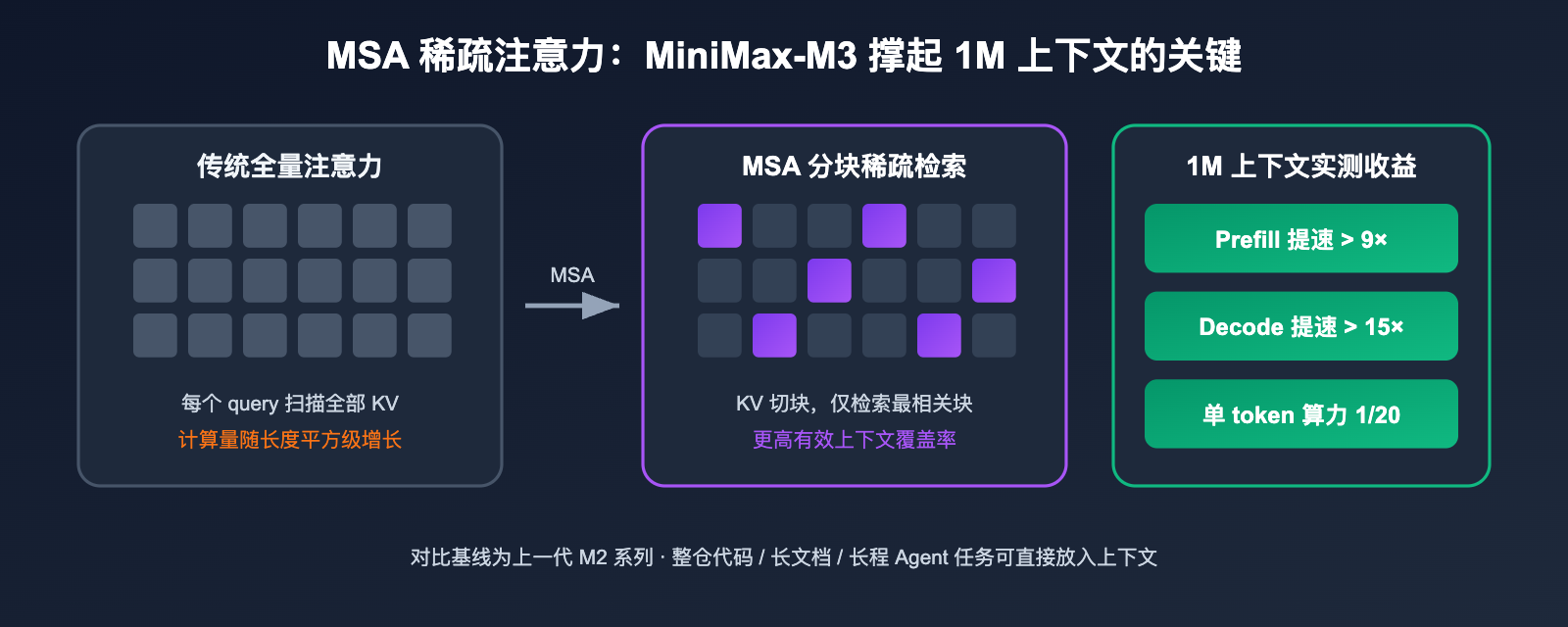
MiniMax-M3 架构解析:MSA 稀疏注意力如何撑起 1M 上下文
100 万 token 上下文不稀奇,稀奇的是让它在经济上可行。MiniMax-M3 的答案是自研的 MSA(MiniMax Sparse Attention)。传统全量注意力的计算量随上下文长度平方级增长,而 MSA 把 KV 缓存切成块,每个 query 只精确检索最相关的 KV 块,实现了更高的有效上下文覆盖率。
官方给出的工程数据相当激进:在 1M token 上下文下,MiniMax-M3 的单 token 计算量只有上一代 M2 的 1/20;预填充(prefill)提速超过 9 倍,解码(decode)提速超过 15 倍;算子层面比开源的 Flash-Sparse-Attention 快 4 倍。换句话说,把整个代码仓库、几百页 PDF 或一小时会议视频塞进上下文,延迟和成本都不再是劝退项。
这对开发者的直接意义是:很多原本需要 RAG 切片、向量检索、多轮摘要才能处理的长文档任务,现在可以"一把梭"直接塞进 prompt。长程 Agent 任务也不再需要频繁压缩历史,任务连贯性显著提升。
💡 长上下文实测提示:1M 上下文的计费分两档,超过 512K 输入后单价翻倍。我们建议在 API易 apiyi.com 控制台先用 200K-400K 级别的真实文档测试效果,确认质量达标后再上更长的输入,平台的用量统计能帮你精确核算每次调用的 token 成本。
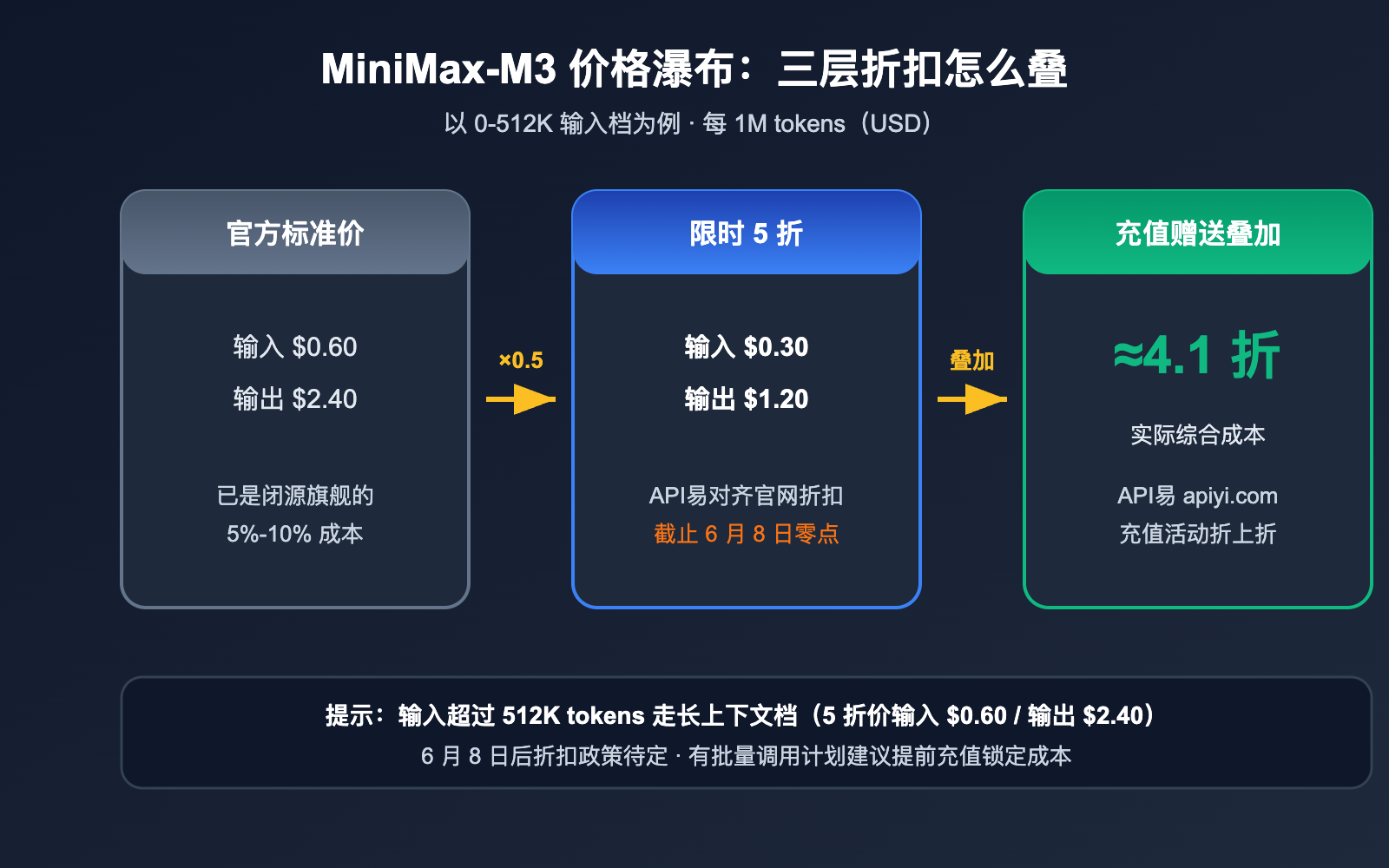
MiniMax-M3 API 价格:限时 5 折 + 充值叠加最低约 4.1 折
MiniMax-M3 的定价采用按输入长度分档的阶梯模式。0-512K tokens 输入走标准档,超过 512K 走长上下文档。发布期全线 5 折,API易 apiyi.com 已同步对齐官方折扣,活动截止 2026 年 6 月 8 日零点(UTC+8),之后的折扣政策待定。
MiniMax-M3 API 价格阶梯表(每 1M tokens)
| 计费档位 | 输入(5 折现价) | 输出(5 折现价) | 恢复后标准价(输入/输出) |
|---|---|---|---|
| 0-512K 输入 | $0.30 | $1.20 | $0.60 / $2.40 |
| 512K 以上输入 | $0.60 | $2.40 | $1.20 / $4.80 |
直观感受一下这个价格:同样跑一个百万 token 级的代码审查任务,用闭源旗舰模型可能要花十几美元,MiniMax-M3 活动价只需要零点几美元,成本差距在 10-20 倍量级。对高频调用的 Agent 流水线、批量代码迁移、长文档处理场景,这个差价一个月就能省出一台开发机。
在 API易平台上还能再降一层。平台的充值赠送活动可以与 5 折模型价叠加,折上折之后实际成本最低约 4.1 折。如果你的团队本来就有稳定的模型调用量,在 6 月 8 日前完成充值是最划算的窗口。
MiniMax-M3 API 快速上手:5 分钟完成接入
MiniMax-M3 在 API易平台走标准的 OpenAI 兼容协议,任何支持自定义 base_url 的 SDK、框架或客户端都能无缝接入。唯一要注意的坑:模型名 MiniMax-M3 严格区分大小写,M 必须大写,写成 minimax-m3 会报模型不存在。
接入只需三步:在 API易 apiyi.com 注册并创建 API Key;把 base_url 指向 https://api.apiyi.com/v1;model 参数填 MiniMax-M3。下面是最简 Python 示例:
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1" # API易统一接口
)
response = client.chat.completions.create(
model="MiniMax-M3", # 注意大小写,M 必须大写
messages=[
{"role": "user", "content": "用 Python 实现一个带 LRU 缓存的斐波那契函数"}
]
)
print(response.choices[0].message.content)
需要传图像或视频时,沿用 OpenAI 的多模态消息格式即可,把 content 改成包含 image_url 的数组,MiniMax-M3 会在同一个会话里完成视觉理解和代码生成。Cline、Cursor、OpenClaw 这类 Agent 工具,只要在设置里改 base_url 和 model 名,就能直接把编程助手的底座换成 MiniMax-M3。
MiniMax-M3 适用场景速查
| 场景 | 适配度 | 说明 |
|---|---|---|
| Agent 编程 / 自动修 Bug | ⭐⭐⭐⭐⭐ | SWE-Bench Pro 59.0,长任务不丢上下文 |
| 整仓代码分析与迁移 | ⭐⭐⭐⭐⭐ | 1M 上下文可容纳完整中型仓库 |
| 长文档 / 多模态文档解析 | ⭐⭐⭐⭐⭐ | OmniDocBench 超过 Gemini 3.1 Pro |
| 自主浏览与工具调用 Agent | ⭐⭐⭐⭐ | BrowseComp 83.5,MCP Atlas 74.2 |
| 科研后训练 / 前沿推理 | ⭐⭐⭐ | PostTrainBench 弱于 Opus 4.7,可混合调度 |
混合调度是更现实的用法:日常高频的编码、文档任务交给 MiniMax-M3 吃掉 80% 的调用量,最难的推理任务保留给 Claude Opus 4.7 或 GPT-5.5。通过 API易的统一接口做模型路由,一套代码就能实现这种"性价比分层"策略,不需要维护多家供应商的密钥和 SDK。
MiniMax-M3 常见问题 FAQ
Q1:MiniMax-M3 的 5 折活动什么时候结束?
活动截止 2026 年 6 月 8 日零点(UTC+8),API易平台与 MiniMax 官网同步。之后的折扣政策官方尚未公布,按惯例可能恢复标准价。如果有批量调用计划,建议在截止前完成充值,叠加充值赠送后实际成本最低约 4.1 折。
Q2:MiniMax-M3 真的开源吗?现在能下载权重吗?
官方承诺发布后 10 天内开放模型权重和技术报告,预计在 HuggingFace 的 MiniMaxAI 主页放出。截至本文发布,权重尚未上传完成。等不及自部署的团队可以先用 API 验证效果,等权重放出后再评估私有化的硬件投入——230B 总参数的 MoE 模型,本地部署对显存的要求并不低。
Q3:1M 上下文是噱头还是真能用?
MSA 架构让 1M 上下文在工程上真正可用:prefill 提速 9 倍以上、decode 提速 15 倍,单 token 计算量降到上一代的 1/20。不过要留意计费分档,输入超过 512K 后单价翻倍,建议按任务实际需要控制上下文长度,而不是无脑塞满。
Q4:MiniMax-M3 和 GPT-5.5、Claude Opus 4.7 怎么选?
看任务类型和预算。编程 Agent、长上下文、多模态文档场景下,MiniMax-M3 的性价比目前没有对手;最顶尖的复杂推理和科研类任务,Opus 4.7 仍有优势。我们建议用真实业务 Prompt 在 API易平台做小规模对比测试,数据会比任何评测榜单都更有说服力。
总结:MiniMax-M3 把旗舰能力打到了"白菜价"
MiniMax-M3 的发布给 2026 年的模型市场扔下了一颗深水炸弹:开源权重 + SWE-Bench Pro 59.0 反超 GPT-5.5 + 100 万上下文 + 原生多模态,叠加只有闭源旗舰 5%-10% 的官方定价。即便后续第三方复测让部分分数回落,它在"性价比"这个维度上的统治力也很难被撼动。
短期最值得行动的是价格窗口:限时 5 折(输入 $0.30 / 输出 $1.20 每 1M tokens)截止 6 月 8 日零点,在 API易 apiyi.com 叠加充值活动可以做到最低约 4.1 折。先用最小成本把评测跑起来,再决定是否把生产流量切过去,这是当下最稳妥的策略。
活动详情与最新模型动态,可以查看 API易官方公告: docs.apiyi.com/news/minimax-m3-launch
作者: APIYI Team
专注 AI 大模型 API 聚合与最佳实践,更多模型评测与接入指南欢迎访问 API易 apiyi.com。