很多团队在批量调用 gpt-image-2-vip 跑图时,会突然撞上一行让人摸不着头脑的提示:An error occurred while processing your request.。它既不像参数错误那样明确指向某一行代码,也不像配额超限那样给出清晰的额度数字,反而像一团迷雾。
经过 API易 apiyi.com 平台对大量真实请求的观察,这个报错并不是单一原因造成的,而是"输入内容"与"上游服务状态"两条线交织的结果。这篇文章会把 gpt-image-2-vip 报错的成因彻底拆开,给出一套可以照着走的排查逻辑,并附上两套已经被验证过的稳定替代方案。

一、gpt-image-2-vip 报错到底意味着什么
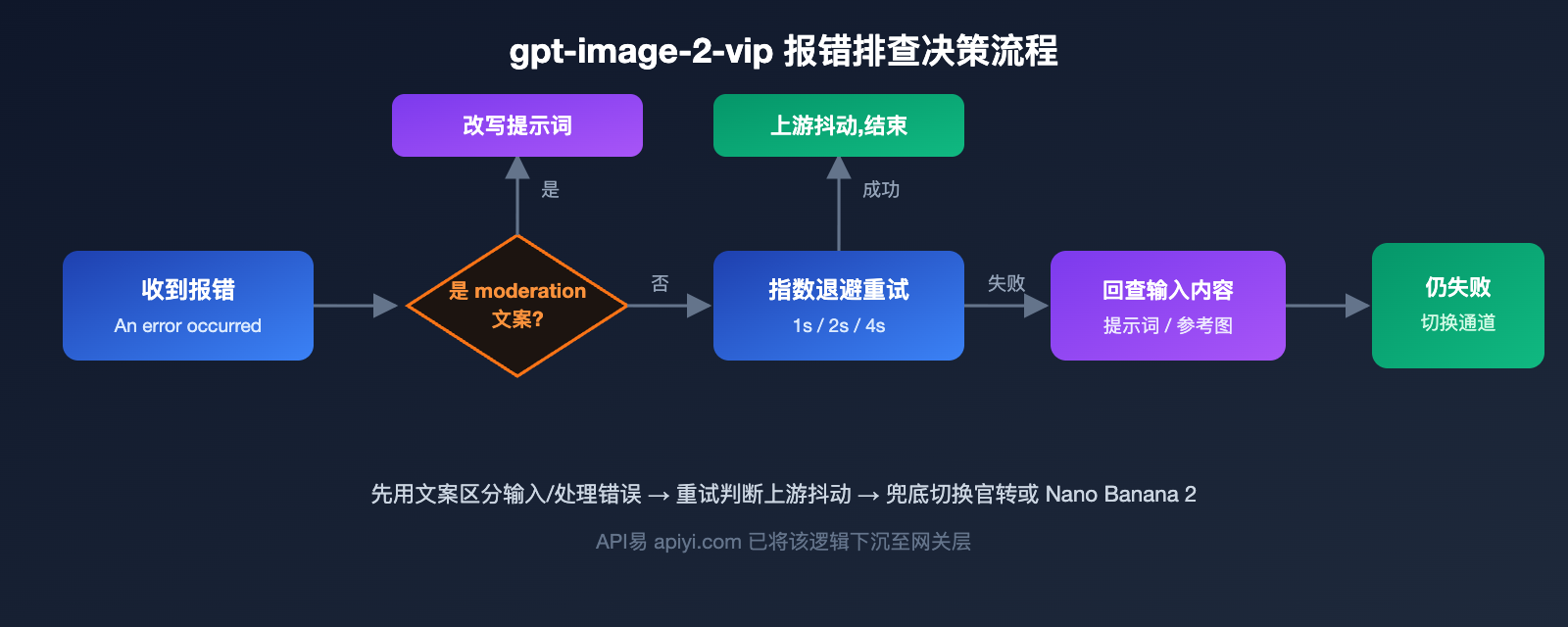
要排查 gpt-image-2-vip 的 An error occurred while processing your request,第一步是把它和另一个长得很像的报错区分开来。这两类错误的触发阶段完全不同,处理思路也截然相反。
第一类是输入阶段被拦截,典型文案是 Your request was rejected by the safety system,错误码 moderation_blocked,HTTP 状态码 400。它的本质是请求还没真正进入模型,就被前置的安全分类器拦下了,改提示词或换图通常就能解决。
第二类才是本文主角,An error occurred while processing your request,通常表现为处理阶段(而非输入校验阶段)的失败,底层往往对应 5xx 级别的服务端错误。它的含义更模糊:可能是输入在生成过程中触发了二次审查,也可能是上游官方服务本身过载或抖动。
| 报错文案 | 错误码 | 触发阶段 | 第一处理动作 |
|---|---|---|---|
| Your request was rejected by the safety system | moderation_blocked (400) | 输入校验 | 改写提示词 / 替换输入图 |
| An error occurred while processing your request | 5xx 处理错误 | 模型处理 | 先重试,再回查输入 |
| That model is currently overloaded | 429 / overloaded | 上游排队 | 退避重试 |
| Both edges must be multiple of 16 | invalid_request (400) | 参数校验 | 修正尺寸参数 |
🎯 判断提示:看到
rejected by the safety system直接改提示词;看到An error occurred while processing则要先走"重试—回查输入"两步。如果你不确定自己拿到的是哪一类报错,可以在 API易 apiyi.com 平台的日志里查看完整的 error body 和 request id,再对照上表定位。
二、gpt-image-2-vip 报错的三大成因排查
把错误类型确认清楚之后,接下来要做的是定位 gpt-image-2-vip 报错的具体来源。结合平台观察,绝大多数 An error occurred 都能归到下面三个原因里。
成因一:输入的提示词或图片不符合内容政策
第一个、也是最容易被忽略的原因,是用户传入的提示词或参考图踩到了内容安全红线。gpt-image-2 的安全系统在 vip 通道上做了显著升级,不仅扫描提示词里的敏感词,还会对生成中或生成后的图像做二次判定。
值得注意的是,这套机制对 IP 版权和身着/服饰类描述的权重很高。哪怕你的意图完全是正当的商业需求(例如电商卖家要生成内衣、泳装类产品图),只要生成结果"看起来像"违规,就可能在处理阶段被拦下,返回的恰恰是这个模糊的 An error occurred,而不是清晰的 moderation 文案。
OpenAI 官方提供了免费的 omni-moderation-latest 审查端点,它同时接受文本和图像。在正式调用 gpt-image-2-vip 之前,先把用户提交的提示词过一遍这个端点,可以在付费生成之前就拦下大部分会违规的请求。
成因二:上游官方服务过载或抖动
第二个原因和你完全无关:官方上游崩了。An error occurred while processing your request 在底层往往就是 5xx 服务端错误,而 5xx 是 OpenAI 侧的问题,清 cookie、重新登录都无济于事。
这里有一个值得记录的变化趋势。早期这类抖动主要集中在 4K 这种高分辨率、高 token 消耗的大请求上;而近期观察到,即便是 2K 分辨率的请求也开始频繁出现同样的报错。原因不难理解:gpt-image-2 在 quality="high" 下会走完整的"理解—规划—生成—审查"四阶段流程,耗时是 quality="low" 的 30 到 50 倍,单次请求越重,撞上上游抖动窗口的概率就越大。
| 触发场景 | 早期表现 | 近期表现 | 根因 |
|---|---|---|---|
| 4K / high quality 大图 | 偶发失败 | 频繁失败 | 单请求过重,上游处理压力大 |
| 2K / high quality | 基本稳定 | 开始频现报错 | 上游整体负载升高 |
| 1K / low-medium | 较稳定 | 相对稳定 | 请求轻,容错空间大 |
🎯 稳定性建议:如果你的业务对 4K 和高质量参数等级有硬性要求,又频繁撞上这类抖动,建议直接在 API易 apiyi.com 平台切换到更稳定的通道(详见第四节),不要在同一条不稳定链路上反复硬刚。
成因三:重试到底有没有用
第三点不是独立成因,而是一个判定动作:重试。对于 5xx 类处理错误,OpenAI 官方明确建议采用指数退避(exponential backoff)策略重试,并尊重响应头里的限流信息。
重试的价值在于它能帮你区分前两个成因。如果重试几次后成功了,说明刚才大概率是成因二的上游抖动,扛过去就好;如果重试依旧失败,就要回到成因一,老老实实检查输入的提示词和图片是不是触发了安全策略。换句话说,重试既是缓解手段,也是诊断工具。
三、gpt-image-2-vip 排查清单与最佳实践
把成因理清后,落到日常工程里,可以用下面这份清单把排查动作标准化。它的顺序刻意按"先排除自己、再判断上游、最后兜底切换"来设计,避免一上来就盲目重试。
- 先看错误文案:是
rejected by the safety system还是An error occurred,前者改提示词,后者进入下一步。 - 本地预审输入:用
omni-moderation-latest把提示词和参考图过一遍,排除明显违规。 - 指数退避重试:对 5xx 错误做 2 到 3 次退避重试,记录 request id 以便追溯。
- 降档验证:把
quality从 high 降到 medium、分辨率从 4K 降到 2K,确认是不是单请求过重导致。 - 切换稳定通道:若以上都无法稳定出图,切到官转 gpt-image-2 或 Nano Banana 2 兜底。
| 排查动作 | 对应成因 | 预期效果 |
|---|---|---|
| 检查错误文案 | 区分输入 / 处理错误 | 选对修复方向 |
| 本地 moderation 预审 | 成因一 | 提前拦截违规输入 |
| 指数退避重试 | 成因二 | 扛过上游抖动 |
| 降低 quality / 分辨率 | 成因二 | 减小单请求压力 |
| 切换稳定通道 | 兜底 | 保障出图成功率 |
🎯 快速上手:如果你只想要一套开箱即用的稳定调用环境,API易 apiyi.com 平台已经把上述重试、降档、通道切换的逻辑做到了网关层,统一 base_url 即可在 vip、官转、Nano Banana 2 之间无缝切换。
下面是一段极简的调用与重试骨架,展示如何在收到处理错误时自动退避重试。
import time
from openai import OpenAI
# base_url 统一走 API易,便于在多通道间切换
client = OpenAI(base_url="https://api.apiyi.com/v1", api_key="YOUR_API_KEY")
def generate(prompt, model="gpt-image-2-vip", retries=3):
for i in range(retries):
try:
return client.images.generate(model=model, prompt=prompt, size="2048x2048")
except Exception as e:
if i == retries - 1:
raise
time.sleep(2 ** i) # 指数退避:1s, 2s, 4s
四、gpt-image-2-vip 的两套稳定替代方案
当 vip 通道因为上游抖动而难以稳定出图时,与其在原地反复重试,不如准备好兜底通道。这里给出两套经过验证、面向不同需求的替代方案。
替代方案一:官转 gpt-image-2,稳压 4K 与高质量
第一套方案是改用官转 gpt-image-2。所谓"官转",指的是更接近官方原生链路、稳定性更高的通道。它的价格相对 vip 要高一些,但换来的是显著更高的成功率,尤其是在 4K 分辨率和 high 质量参数等级这种最容易出问题的场景下。
如果你的产品对画质有硬性要求,比如电商主图、海报级输出,那么这点价格差换来的稳定性通常是划算的。gpt-image-2 在官转通道下支持任意分辨率,约束是两条边都必须是 16 的倍数,长边最高到 3840px(4K),总像素在 655,360 到 8,294,400 之间。
🎯 选型建议:对稳定性和高分辨率敏感的生产场景,我们建议在 API易 apiyi.com 平台优先选用官转 gpt-image-2,把 vip 通道留给对成本更敏感、可容忍偶发重试的批量任务。
替代方案二:Nano Banana 2,按量计费的高性价比之选
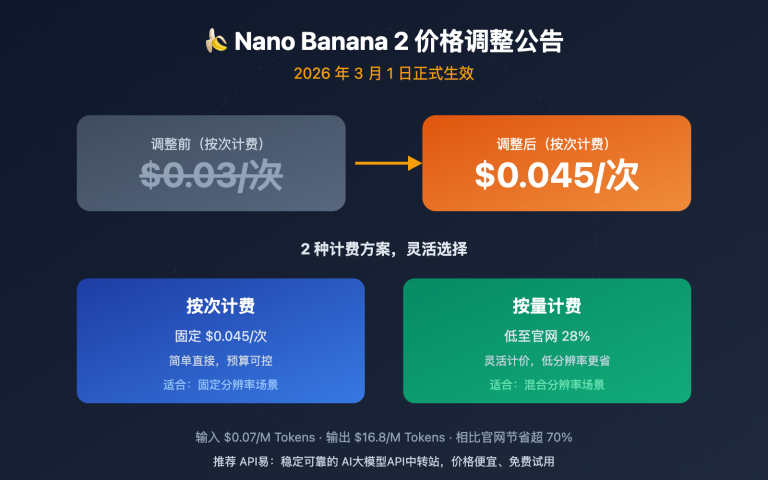
第二套方案是引导用户切换到 Nano Banana 2,也就是 Google 的 gemini-3.1-flash-image 模型。它走的是按量计费路线,单图成本大致落在 0.03 到 0.05 美元区间,非常适合对成本敏感、又需要稳定高并发出图的场景。
按官方分辨率档位来看,Nano Banana 2 的定价大约是 0.5K 档 0.045 美元、1K 档 0.067 美元、2K 档约 0.101 美元、4K 档约 0.151 美元,通过批处理通道还能再打五折。在第三方网关上,各分辨率往往会被拉平到 0.05 美元左右的统一价位,进一步降低了心智成本。
| 通道 | 稳定性 | 价格水平 | 最适合场景 |
|---|---|---|---|
| gpt-image-2-vip | 受上游抖动影响 | 较低 | 成本敏感、可容忍重试的批量任务 |
| 官转 gpt-image-2 | 高 | 较高 | 4K / 高质量 / 生产级主图 |
| Nano Banana 2 (gemini-3.1-flash-image) | 高 | 按量 0.03-0.05 美元 | 高并发、性价比优先 |

这三条通道并不是互斥的。更聪明的做法是把它们组合起来:日常批量用 vip 控成本,关键高画质订单走官转,高并发场景用 Nano Banana 2 兜底。
🎯 组合建议:在 API易 apiyi.com 平台上,这三个模型共用同一套接口和密钥,你可以在代码里只改一个
model参数就完成切换,无需重构调用逻辑,非常便于做 A/B 测试和故障转移。
五、常见问题 FAQ
Q1:为什么 4K 之前出错多,现在 2K 也频繁报错了?
因为上游整体负载升高了。quality="high" 的请求要走"理解—规划—生成—审查"四阶段,耗时是 low 的 30 到 50 倍,请求越重越容易撞上抖动窗口。早期只有 4K 这种最重的请求会受影响,现在负载上来后 2K 也开始频现。建议在 API易 apiyi.com 平台降档验证或切换通道。
Q2:An error occurred 和 moderation_blocked 是同一回事吗?
不是。后者是 400 输入拦截,文案明确写着 rejected by the safety system,改提示词即可;前者是处理阶段的 5xx 错误,要先重试再回查输入,两者的修复方向相反。
Q3:重试多少次合适?
一般 2 到 3 次指数退避(1s、2s、4s)足够区分上游抖动还是输入问题。如果三次仍失败,大概率是输入触发了安全策略,或该坚决切换到官转 / Nano Banana 2 兜底。
Q4:官转和 vip 的画质有区别吗?
模型能力本身一致,差异主要在链路稳定性和高分辨率/高质量参数下的成功率。对 4K 和 high quality 有硬要求时,官转更稳。
六、总结
gpt-image-2-vip 报 An error occurred while processing your request 并不是玄学,它本质上是"输入内容"和"上游状态"两条线的交汇点。排查时记住三句话:先用文案区分输入错误还是处理错误;再用指数退避重试判断是上游抖动还是输入问题;最后用官转 gpt-image-2 或 Nano Banana 2 做稳定兜底。
把这套逻辑固化进网关层之后,出图成功率和成本就能同时得到控制。如果你希望省去自己搭建重试、降档和多通道切换的工程成本,可以直接在 API易 apiyi.com 平台用一套接口管理 vip、官转与 Nano Banana 2 三条链路,按场景灵活调度。
本文由 API易 apiyi.com 技术团队整理,持续关注主流图像模型的稳定性与最佳实践。