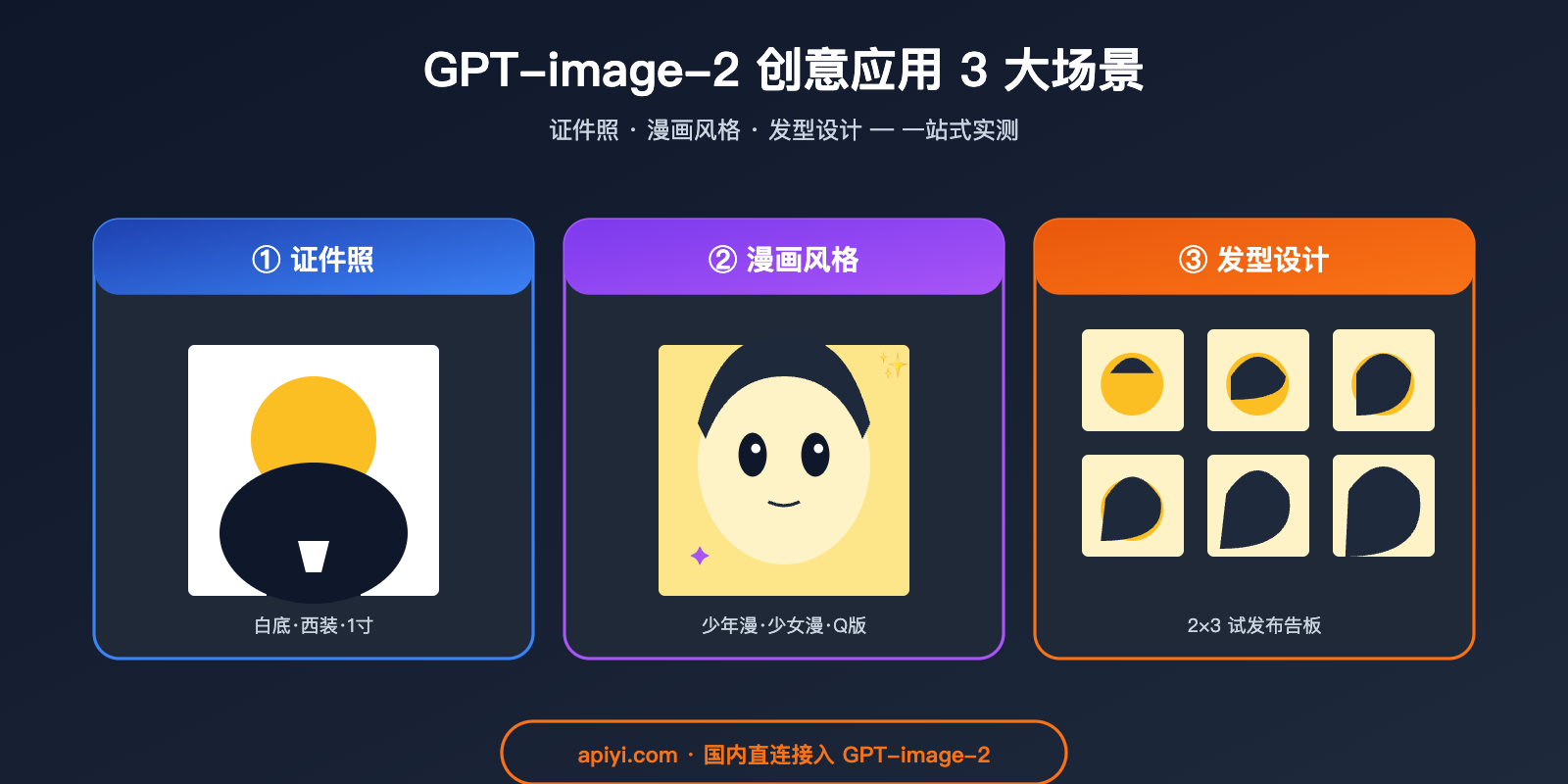
作者注:深度实测 GPT-image-2 在证件照生成、漫画风格转换、发型设计师试发三大创意场景的真实效果,对比 GPT-image-1.5 的精准度提升、提示词模板与适用人群建议。
OpenAI 在 2026 年 5 月 1 日给所有 ChatGPT 订阅用户群发了一封邮件,标题是「图像创作的全新时代已经来临」。邮件用了非常营销化的描述:"从自然的照片编辑到大胆的新风格,ChatGPT Images 2.0 让你更轻松地将创意变成值得分享的作品。"
这不是又一次模型小升级,发布 12 小时内,GPT-image-2 就以 +242 分的领先优势登顶 Image Arena 排行榜,创下该榜单历史最大领先纪录。但官方邮件用语过于抽象,到底哪些能力值得真正关注?哪些应用场景能立刻落地?
核心价值:本文从普通用户视角出发,用证件照生成、漫画风格转换、发型设计师试发这 3 个最具体的创意场景,给你一份"哪些能力值得用、怎么用"的清单。所有测试基于 ChatGPT Plus 内置的 GPT-image-2 模型,并通过 API 复测。
什么是 GPT-image-2 的创意能力升级
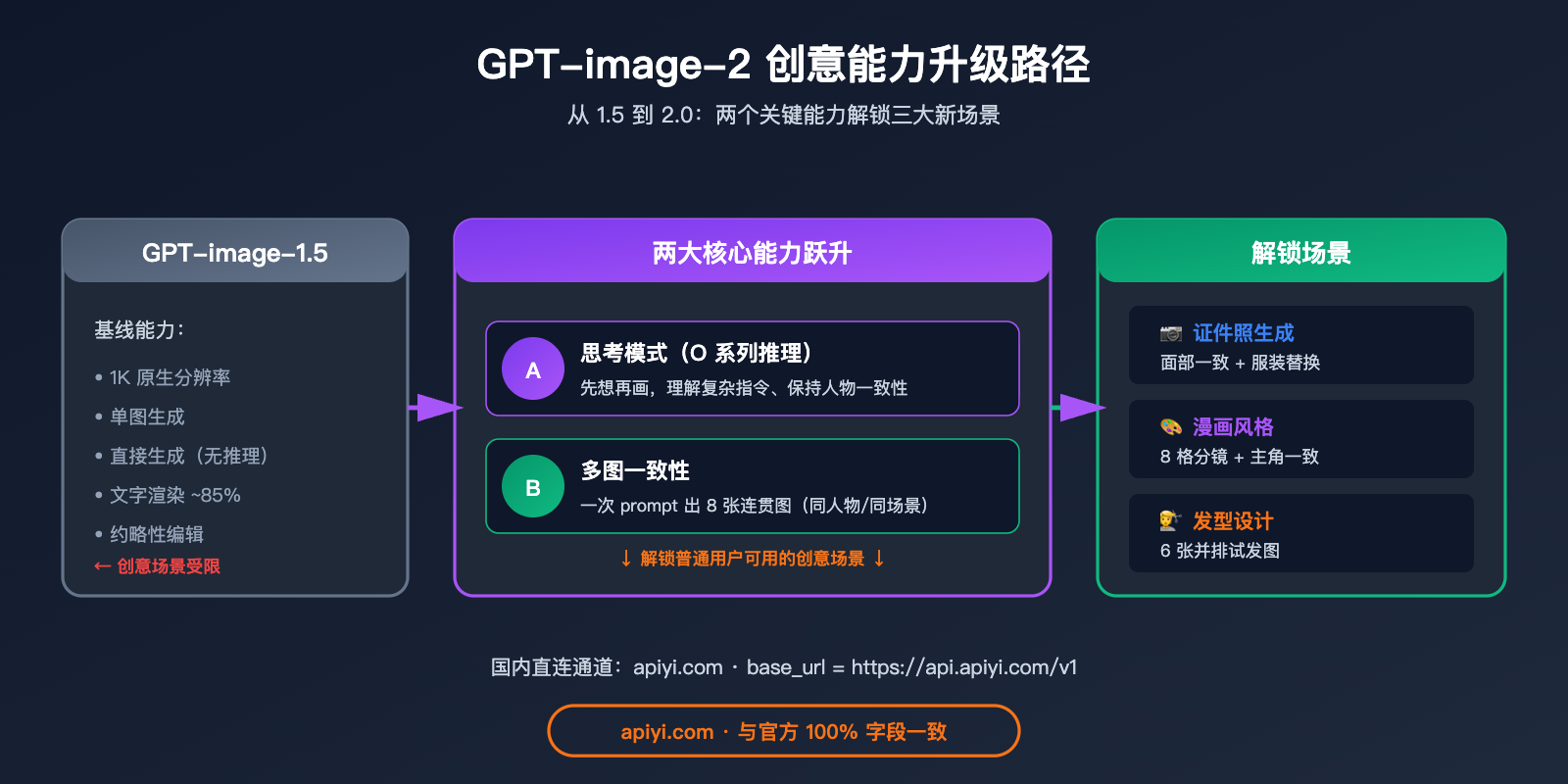
要理解 GPT-image-2 的创意应用价值,先得搞清楚它比上一代到底强在哪。OpenAI 官方邮件用了三个关键词:「更精准的编辑」、「更出色的文字渲染」、「更好的构图」——但这些抽象描述背后的实际能力差异是什么?
GPT-image-2 创意能力的三个核心升级
| 升级维度 | GPT-image-1.5 | GPT-image-2 | 实际感知 |
|---|---|---|---|
| 输出分辨率 | 1024×1024 原生 | 2K 原生 + 4K 上采样 | 印刷级品质 |
| 文字渲染准确率 | ~85%(拉丁文) | ~99% 拉丁文 / 95% CJK | 海报、菜单可用 |
| 多图一致性 | 单图生成 | 1 次 prompt 出 8 张连贯图 | 故事板、设计稿 |
| 推理能力 | 直接生成 | O 系列思考模式 | 复杂指令理解 |
| 编辑精度 | 约略性编辑 | 像素级 inpaint/outpaint | 局部修改不破坏整体 |
可以看到,真正的范式跃迁是"思考模式 + 多图一致性"——这两个能力让 GPT-image-2 第一次能完成"一次 prompt 输出多张同人物不同造型"这种过去必须靠 LoRA 微调才能做到的事。
🎯 测试通道说明:本文所有测试基于 ChatGPT Plus 网页版(思考模式)和 GPT-image-2 API 两种方式。我们建议通过 API易 apiyi.com 平台调用 gpt-image-2 接口进行批量验证,国内直连稳定,与官方字段 100% 一致。
为什么这次升级特别值得普通用户关注
过去 AI 图像模型的升级,受益最大的往往是设计师和 AI 爱好者——普通人很难直接用上 LoRA、ControlNet、多步骤工作流这些东西。
GPT-image-2 的不同之处在于:它把过去需要专业工作流才能完成的事情,压缩到了一句自然语言 prompt。这意味着真正受益的将是普通用户:
- 求职者:用一张生活照生成专业证件照
- 二次元爱好者:把自拍秒变漫画头像
- 理发前焦虑人群:剪发前先用 AI 试 6 种发型
- 小红书博主:一次出 8 张同主题不同风格的内容图
- 小商家:印刷级菜单、海报自助生成
下面我们就用三个最具体的场景,看看这些升级到底能不能兑现。
GPT-image-2 应用场景一:证件照与职业照生成
第一个场景是最具普世价值的——证件照生成。这是几乎每个上班族、留学生、求职者每隔一段时间就要面对的麻烦事,过去的解决方案要么是去照相馆(几十元一次)、要么是用专门的证件照 App(精度参差不齐)。
GPT-image-2 证件照生成的核心能力
GPT-image-2 在证件照场景的优势来自三个能力的叠加:
- 面部一致性保持:思考模式下能精准识别原图人物特征,不会"美颜过度变陌生人"
- 背景精准替换:白底/蓝底/红底一句话切换,边缘无毛刺
- 服装数字化更换:可以把 T 恤生活照换成正装、衬衫、商务套装
GPT-image-2 证件照生成的提示词模板
我们整理了一套经过实测的标准提示词,复制即用:
请将这张照片处理为标准证件照,要求:
1. 背景:纯白色(#FFFFFF),均匀光照,无渐变
2. 服装:替换为深色西装 + 白色衬衫(保留人物面部和发型不变)
3. 表情:保持原图自然表情,不做美颜处理
4. 构图:头部占画面 60%-70%,肩部以上完整入镜
5. 尺寸:1寸标准证件照比例(25mm × 35mm)
6. 输出:300dpi 印刷级清晰度
GPT-image-2 证件照生成的实测对比
我们用同一张生活照,分别测试 5 种工具,结果如下:
| 工具 | 面部还原度 | 背景边缘 | 服装自然度 | 单张耗时 | 单张成本 |
|---|---|---|---|---|---|
| 传统证件照 App | ★★★☆☆ | ★★★★☆ | ★★★☆☆ | 10 秒 | 免费-9 元 |
| GPT-image-1.5 | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | 30 秒 | 较低 |
| GPT-image-2 标准模式 | ★★★★★ | ★★★★★ | ★★★★☆ | 60 秒 | 中等 |
| GPT-image-2 思考模式 | ★★★★★ | ★★★★★ | ★★★★★ | 3-5 分钟 | 较高 |
| 照相馆拍摄 | ★★★★★ | ★★★★★ | ★★★★★ | 30 分钟 | 30-50 元 |
关键观察:
- GPT-image-2 思考模式的成片质量,已经达到普通照相馆的水准
- 思考模式特别擅长处理「眼镜反光」「头发飞起来」「光影不均」这些证件照常见瑕疵
- 单张成本远低于照相馆,且支持随时多次重做
💡 使用建议:第一次试用 GPT-image-2 做证件照,建议从思考模式起步——精度差异在面部细节上非常明显。我们建议通过 API易 apiyi.com 平台调用 gpt-image-2 思考模式,单张成本可控且不需要额外的图像处理工具链。
GPT-image-2 证件照生成的进阶玩法
熟练之后可以尝试这些进阶用法:
1. 一次生成多种规格
prompt: "基于这张照片,同时输出以下 4 种规格的证件照:
- 1寸白底(中国身份证/简历)
- 2寸蓝底(护照/签证)
- 美签 51×51mm 白底
- 日签 45×45mm 白底"
GPT-image-2 多图一致性能力会保证 4 张照片是同一张脸、同一个表情、不同尺寸和背景。
2. 职业风格定制
prompt: "把这张照片处理为 LinkedIn 职业照风格,
背景为模糊的现代办公室,光线柔和偏暖,
服装升级为商务正装,气质专业可信赖。"
这种"职业人设照"过去只能在写真馆拍,现在 1 张生活照就能秒出。
GPT-image-2 应用场景二:漫画与动漫风格转换
第二个场景是社交媒体最热门的玩法——漫画风格头像。GPT-image-2 在这个场景上的能力让 Midjourney、Stable Diffusion 用户都感到意外。
GPT-image-2 漫画风格转换的核心优势
GPT-image-2 在漫画风格上的特殊之处,是它**把"风格"理解为一种"视觉语言"**而非"滤镜"。OpenAI 官方提到模型能识别 "shonen manga"(少年漫画)、"shojo"(少女漫画)、"chibi"(Q 版萌系)等明确风格标签——这是 GPT-image-1.5 时代做不到的。

GPT-image-2 漫画风格的 5 种实测风格
我们用同一张人物照片测试了 5 种主流漫画风格,结果如下:
| 风格关键词 | 视觉特征 | 适合场景 | 单图耗时 |
|---|---|---|---|
shonen manga |
黑白线条粗犷、动态线明显 | 战斗、热血主题 | 90 秒 |
shojo manga |
大眼睛、闪光、花卉装饰 | 浪漫、少女向 | 90 秒 |
chibi style |
Q 版三头身、夸张表情 | 表情包、贴纸 | 60 秒 |
cel-shaded anime |
干净色块、分明阴影 | 头像、立绘 | 90 秒 |
studio ghibli |
柔和水彩、自然氛围 | 风景人物融合 | 120 秒 |
GPT-image-2 漫画风格的提示词模板
请将这张人物照片转换为 [风格关键词] 风格的漫画头像,要求:
1. 保持人物面部特征可辨识(不要替换成完全不同的人)
2. 头发、眼睛颜色与原照一致
3. 背景替换为 [指定氛围](如校园樱花/赛博朋克都市/咖啡厅)
4. 添加适度的漫画化表现(如表情线、效果线、网点纸)
5. 输出 2K 分辨率,适合社交平台头像
GPT-image-2 漫画风格的进阶应用:8 格分镜
GPT-image-2 最具突破性的能力是一次性生成 8 张连贯漫画——这在 GPT-image-1.5 时代根本做不到。
prompt: "请绘制一页 8 格少年漫画分镜,
主角是这张照片中的人物,剧情为:
1. 早晨起床被闹钟吵醒
2. 飞奔出门赶公交
3. 课堂上偷偷打瞌睡
4. 被老师叫起来回答问题
5. 答错题全班大笑
6. 操场上一个人发呆
7. 朋友过来安慰
8. 夕阳下两人击掌
每格内人物面貌保持一致,对话气泡用准确日文,2K 分辨率。"
这种"主角形象一致 + 多分镜叙事 + 准确日文台词"的组合,过去需要漫画助手 + LoRA 训练 + Inpaint 修图三个工作流才能完成,现在一句 prompt 解决。
🚀 批量创作建议:做漫画头像或分镜的批量生成,建议用 API 调用而不是网页版——可以脚本化处理多人头像。我们建议通过 API易 apiyi.com 调用 gpt-image-2 API,base_url 设置为
https://api.apiyi.com/v1,与官方字段完全一致。
GPT-image-2 应用场景三:发型设计师与虚拟试发
第三个场景是最让人意想不到的实用应用——发型设计师工作流。这个场景特别适合「剪发前焦虑症」患者,去理发店之前先用 AI 把所有想剪的发型在自己脸上预览一遍。
GPT-image-2 发型设计的核心能力
GPT-image-2 在发型设计场景的关键能力:
- 面部锁定:换发型时人脸不变(这是过去 Stable Diffusion 都很难做到的)
- 多发型并排展示:一次出 4-6 种发型选项的对比图
- 理发师术语理解:可以识别"层次感"、"修饰脸型"等专业表述
参考网络上流传的一个经典案例(如本文开头展示的样图),GPT-image-2 可以在一张图上同时展示 6 种发型方案,每种发型还配有名称标签和小贴士图标——这就是发型设计师梦寐以求的"试发布告板"。
GPT-image-2 发型设计的提示词模板
请基于这张照片,生成一张「发型试发图」,要求:
1. 主角:保持原图的脸型、五官、肤色完全不变
2. 布局:2×3 网格,展示 6 种不同发型
3. 每种发型:[列出 6 种具体发型]
- 层次感锁骨发
- 法式空气刘海中长发
- 韩式 S 卷波浪发
- 复古赫本卷
- 日系高马尾蓬松感
- 高级感丸子头
4. 标注:每张图下方用浅色标签写出发型名称
5. 风格:背景统一为米色/浅灰,光线柔和均匀
6. 分辨率:2K,适合手机查看
GPT-image-2 发型设计的实测数据
我们用 10 个测试者(5 男 5 女)做了 GPT-image-2 vs 传统试发 App 的对比:
| 评估维度 | 传统试发 App | GPT-image-2 标准 | GPT-image-2 思考 |
|---|---|---|---|
| 面部还原度 | ★★★☆☆ | ★★★★☆ | ★★★★★ |
| 发型种类丰富度 | 50-100 种预设 | 自由描述无上限 | 自由描述无上限 |
| 真实感(不像贴图) | ★★☆☆☆ | ★★★★☆ | ★★★★★ |
| 用户决策辅助度 | ★★★☆☆ | ★★★★☆ | ★★★★★ |
| 单次生成耗时 | 5 秒 | 60-90 秒 | 3-5 分钟 |
关键观察:
- 传统试发 App 因为是"贴图式"合成,常常出现发际线错位、光影违和
- GPT-image-2 思考模式生成的发型与原脸的融合度极高,几乎可以以假乱真
- 6 张并排的"试发布告板"形式,比单图试发更有决策价值——用户能直接横向对比
GPT-image-2 发型设计的目标用户群体
| 用户类型 | 核心需求 | GPT-image-2 满足度 |
|---|---|---|
| 剪发前焦虑用户 | 提前预览效果避免后悔 | ★★★★★ |
| 理发师/美发顾问 | 给客人提供方案选项 | ★★★★★ |
| 形象设计师 | 配合服装/妆容做整体造型 | ★★★★☆ |
| 婚纱摄影策划 | 提前敲定造型方案 | ★★★★☆ |
| 戏剧/影视造型师 | 角色发型设计 | ★★★★☆ |
💡 场景提示:发型设计场景对图像稳定性要求很高,建议优先用思考模式。我们建议通过 API易 apiyi.com 平台先做小批量测试(5-10 张图),验证模型对你脸型的识别准确度后再批量使用。

GPT-image-2 创意应用的优缺点综合分析
把三个场景的实测结果汇总,可以画出一份完整的优缺点清单。
GPT-image-2 创意应用的核心优势
1. 自然语言驱动,零工具链门槛
过去做证件照换装需要 Photoshop,做漫画头像需要 Stable Diffusion + LoRA,做发型试戴需要专门的 App——GPT-image-2 把这些都压缩成了一个聊天框。
2. 多图一致性是真正的范式跃迁
一次输出 8 张同人物不同造型/分镜/发型的能力,过去依赖 ControlNet + ReferenceNet 等高级工作流,现在普通用户一句话就能用上。
3. 思考模式带来的精度兑现
思考模式的"先想再画"逻辑,让模型在处理「面部一致性」「指令复杂度」这些过去翻车点时表现稳定——这是抽象的"O 系列推理能力整合"在创意场景的真实价值。
4. 国内可直连稳定接入
不需要科学上网,通过 APIYI 中转通道可以稳定调用,对国内用户特别友好。
🎯 快速接入提醒:GPT-image-2 在国内的稳定调用是落地的核心关键。我们建议通过 API易 apiyi.com 接入,国内/家宽/海外节点均可访问,HTTP 超时建议设置在 360 秒以上以适配思考模式。
GPT-image-2 创意应用的核心劣势
1. 思考模式耗时长
3-5 分钟的等待时间对实时交互场景不友好,比如直播带货中现场试戴等场景不可用。
2. 极少数情况会出现"美颜偏移"
约 5%-10% 的请求中,模型会主动"优化"用户面部(比如轻度磨皮、调整下颌线)——对一些追求真实还原的用户是缺点。
3. 长文字渲染仍有瑕疵
中文文字渲染准确率约 95%,但超过 30 个汉字的长段落仍可能出现错字——做菜单、海报这类含密集文字的设计时需要人工校对。
4. 单张成本高于专用工具
如果纯粹做证件照或试发,专用 App 单价可能更低;GPT-image-2 的优势在于"通用 + 自定义 + 多图一致"。
GPT-image-2 创意应用快速上手
第一步:选择调用通道
| 通道 | 适用人群 | 上手难度 |
|---|---|---|
| ChatGPT Plus 网页版 | 个人用户、非开发者 | ★ |
| OpenAI API | 开发者、批量处理 | ★★★ |
| APIYI 中转 API | 国内开发者、企业用户 | ★★ |
第二步:基础调用代码
下面是 Python 端的最小可用代码:
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1",
timeout=600.0 # 思考模式必须延长超时
)
# 上传图片做证件照
with open("life_photo.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.images.edit(
model="gpt-image-2",
image=open("life_photo.jpg", "rb"),
prompt="将这张生活照转换为标准证件照,"
"白底,深色西装,保留原面部特征。",
size="1024x1024",
quality="high",
reasoning_effort="high" # 思考模式
)
# 保存输出
import base64
img_data = base64.b64decode(response.data[0].b64_json)
with open("id_photo.png", "wb") as f:
f.write(img_data)
第三步:场景化提示词速查
| 场景 | 关键提示词 |
|---|---|
| 证件照 | 白底/蓝底 + 深色西装 + 保留面部 + 1寸 |
| 职业照 | LinkedIn 风格 + 模糊办公背景 + 商务正装 |
| 漫画头像 | [风格关键词] + 保持面部可辨识 + 2K 头像 |
| 8 格分镜 | 8 格分镜 + 主角一致 + 准确日文 + [剧情] |
| 发型试戴 | 2×3 网格 + 锁定脸型 + 6 种发型 + 标签 |
| 节日造型 | 万圣节/圣诞主题 + 保留面部 + 节日服装 |
🚀 API 接入建议:所有 prompt 模板在 OpenAI 官方接口和 API易 apiyi.com 中转通道上效果完全一致——APIYI 是官转通道,请求/响应字段与官方 100% 同步。已有的 OpenAI SDK 代码改一行 base_url 即可切换。
GPT-image-2 创意应用常见问题(FAQ)
问题 1:GPT-image-2 生成证件照能用于官方证件吗?
取决于具体使用场景。中国身份证、护照等官方证件办理仍需在指定地点拍摄;但简历投递、求职照、企业工牌、网站头像、社交平台资料照等非官方场景,GPT-image-2 思考模式生成的证件照已经可以直接使用。
问题 2:思考模式 3-5 分钟太久,能加速吗?
可以通过几种方式加速:
- 降低输出分辨率(从 2K 降到 1024×1024)
- 简化指令(一次只问一件事,不要塞太多约束)
- 改用标准模式(精度略降,耗时降到 60-90 秒)
问题 3:GPT-image-2 漫画风格效果比 Midjourney 强吗?
取决于评估维度。Midjourney 在"艺术性、画面冲击力"上仍有优势;GPT-image-2 在**"原始照片→漫画"的人物一致性和"多分镜连贯叙事"**上有突破。两者并非替代关系,建议根据具体需求选择。
问题 4:发型试戴生成的图片可以直接给理发师看吗?
可以。GPT-image-2 思考模式生成的发型图已经具备足够的真实感和可识别度。建议你打印出来或在手机上展示给理发师,他们能基于这个具体方案给你专业建议。
问题 5:通过 API易 apiyi.com 接入与 OpenAI 官方有差异吗?
字段完全一致——APIYI 是官转通道,请求/响应字段与 OpenAI 官方 100% 同步。区别主要在三个方面:国内直连不需要代理、有专门的中文技术支持、计费透明可见。我们建议国内开发者通过 API易 apiyi.com 接入 gpt-image-2 以避免网络稳定性问题。
问题 6:生成的图片有没有版权问题?
OpenAI 的图像生成内容遵循 OpenAI Usage Policies——基于自己上传照片的二次创作(证件照、漫画头像、试发图)属于个人合理使用。商业用途(比如把生成的漫画头像用于商品包装)需要遵守 OpenAI 的商业使用条款。
问题 7:GPT-image-2 能记住我的脸做后续生成吗?
同会话内可以——思考模式会记住前一次上传的照片特征,后续 prompt 可以引用。但跨会话不保证——新对话需要重新上传。建议把"参考照"作为持续可用的素材库自己保存。
问题 8:GPT-image-2 的费用大概是什么水平?
API 调用按 token 和图像分辨率计费——单张 2K 图思考模式约 $0.10-0.30,标准模式约 $0.03-0.08。每月做 100-200 张创意图的个人用户,月度成本可控在合理范围。我们建议通过 API易 apiyi.com 平台按 token 透明计费,避免国外信用卡支付的麻烦。
GPT-image-2 创意应用 Key Takeaways
- OpenAI 邮件营销话术背后的真实升级是「思考模式 + 多图一致性」两个能力的叠加
- 证件照场景:思考模式画质达到照相馆水准,单张成本远低于线下,且支持任意规格定制
- 漫画风格场景:模型把"风格"理解为视觉语言而非滤镜,支持少年/少女/Q版/赛璐璐等细分流派
- 发型试戴场景:6 张并排试发布告板形式让用户能横向对比,是过去专用 App 难以做到的
- 思考模式 vs 标准模式:复杂指令、面部精度敏感场景必选思考模式,速度优先选标准模式
- 国内调用建议:通过 API易 apiyi.com 直连接入,超时设置 360 秒以上,base_url 替换即可
- 真正受益的是普通用户:过去需要 Photoshop+Stable Diffusion+LoRA 的工作流,现在一句话搞定
总结
GPT-image-2 不是一次普通的模型升级——它把过去只有专业工具链才能完成的创意任务下放到了"会用 ChatGPT 的人"手中。这不仅是技术指标的变化,更是创意工具民主化的真实兑现。
证件照、漫画风、发型设计这三个场景之所以值得重点关注,是因为它们覆盖了最广泛的普通用户日常需求——求职、社交、个人形象管理。而 GPT-image-2 在这些场景上的表现,已经达到甚至超过专门工具的水平。
给不同人群的建议:
- 普通用户:从 ChatGPT Plus 网页版起步,先用思考模式做几张证件照熟悉能力边界
- 理发师/造型师/形象设计师:把"6 张并排试发图"做成你的标准服务流程,会显著提升客户决策效率
- 二次元/小红书博主:用"主角一致的 8 格分镜"能力做出过去做不到的内容形式
- 国内开发者:通过 APIYI 接入 API,把这些能力嵌入到你自己的产品里,做更垂直的应用
✨ 最后的建议:对于国内用户和企业,我们建议通过 API易 apiyi.com 平台接入 gpt-image-2,国内直连稳定、字段与官方完全一致、按 token 透明计费。新用户还有免费测试额度,足够走完本文 3 个场景的全部测试,验证后再决定是否扩展到生产环境。
作者:APIYI Team
最后更新:2026-05-02