Google Gemma 4 正式发布,首次采用 Apache 2.0 完全开源许可,推出 4 款模型覆盖从树莓派到数据中心的完整算力场景。作为 Gemini 3 同源技术的开源版本,Gemma 4 在推理、编码、视觉、长上下文等维度实现了对 Gemma 3 的全面碾压级提升。
核心价值: 读完本文,你将掌握 Gemma 4 的 4 款模型选型、核心架构创新、多模态能力边界,以及本地部署的硬件要求。

Gemma 4 核心信息速览
Gemma 4 于 2026 年 4 月 2 日在 Google Cloud Next 上发布,基于 Gemini 3 的同源研究构建,是 Google 开源模型家族的第四代产品。
| 信息项 | 详情 |
|---|---|
| 发布时间 | 2026 年 4 月 2 日 |
| 模型数量 | 4 款 (E2B / E4B / 26B-A4B / 31B) |
| 许可协议 | Apache 2.0 (首次,此前为 Google 自有许可) |
| 最大上下文 | 256K tokens (31B 和 26B-A4B) |
| 多模态 | 文本 + 图像 + 视频 + 音频 (E2B/E4B) |
| 架构亮点 | 首个 MoE 变体、PLE 技术、混合注意力 |
| 可用平台 | Hugging Face、Google AI Studio、Vertex AI、Ollama 等 |
Gemma 4 四款模型一览
| 模型 | 有效参数 | 总参数 | 架构 | 上下文 | 多模态 |
|---|---|---|---|---|---|
| Gemma 4 E2B | 2.3B | 5.1B | Dense | 128K | 文本+图像+视频+音频 |
| Gemma 4 E4B | 4.5B | 8B | Dense | 128K | 文本+图像+视频+音频 |
| Gemma 4 26B-A4B | 3.8B 激活 | 25.2B | MoE | 256K | 文本+图像+视频 |
| Gemma 4 31B | 30.7B | 30.7B | Dense | 256K | 文本+图像+视频 |
命名规则: "E" 前缀代表 "Effective Parameters" (有效参数),因 PLE 技术导致总参数大于有效参数。26B-A4B 表示总参数 26B、每 token 激活参数 4B 的 MoE 架构。
🎯 技术建议: Gemma 4 的 4 款模型覆盖了从边缘设备到云端推理的全场景。如果你需要在多个开源模型间对比效果,建议通过 API易 apiyi.com 平台统一接入,快速切换和评估不同模型。
Gemma 4 vs Gemma 3 性能对比: 史上最大代际提升
Google 官方称 Gemma 4 是"开源模型领域最大的单代性能提升"。基准测试数据完全支撑了这一说法。
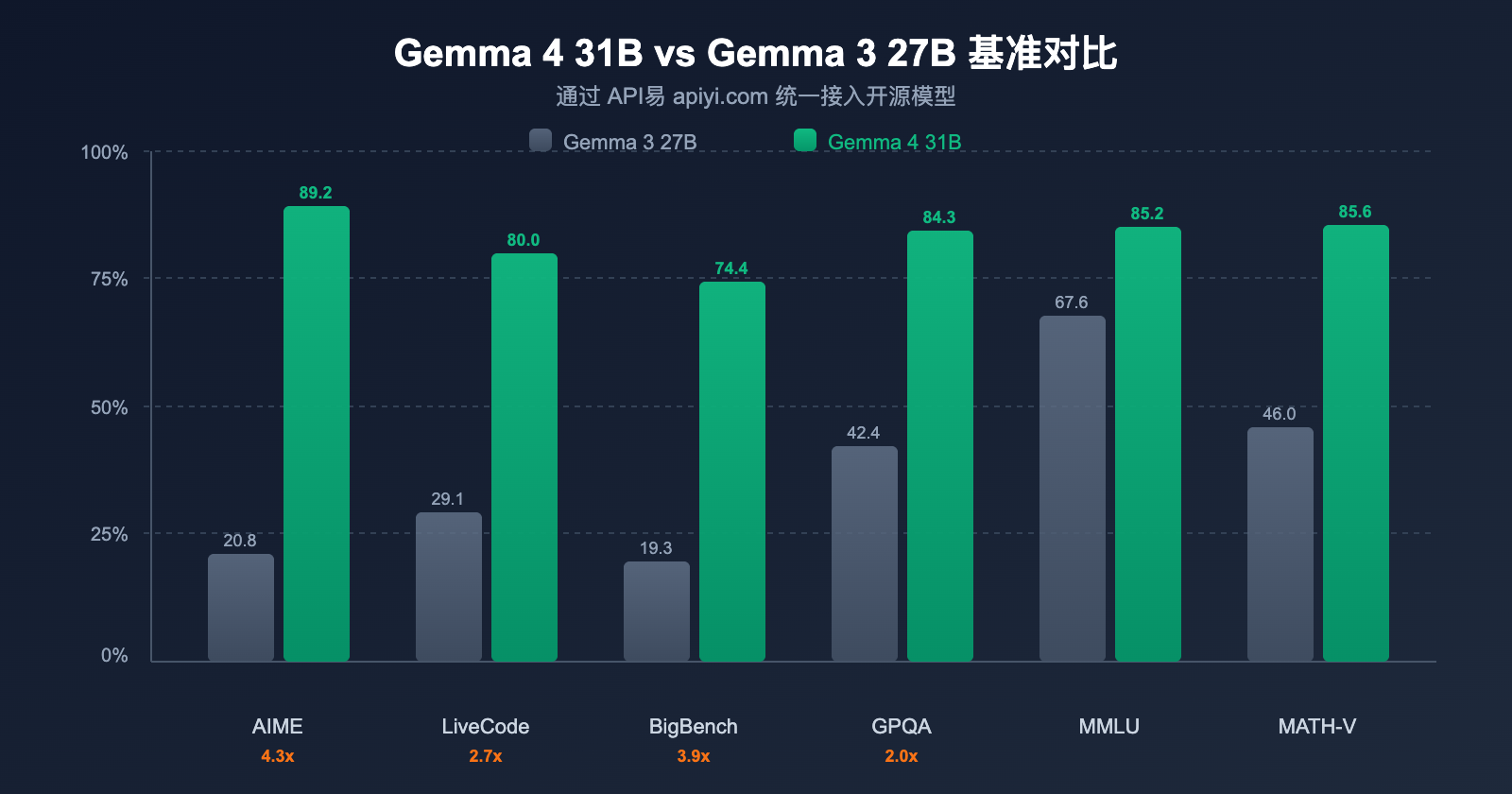
核心基准测试对比
| 基准测试 | Gemma 3 27B | Gemma 4 31B | 提升幅度 |
|---|---|---|---|
| AIME 2026 (数学推理) | 20.8% | 89.2% | +68.4 pts (4.3x) |
| LiveCodeBench v6 (编码) | 29.1% | 80.0% | +50.9 pts (2.7x) |
| BigBench Extra Hard (推理) | 19.3% | 74.4% | +55.1 pts (3.9x) |
| GPQA Diamond (科学推理) | 42.4% | 84.3% | +41.9 pts (2.0x) |
| MMLU Pro (知识) | 67.6% | 85.2% | +17.6 pts |
| MATH-Vision (视觉数学) | 46.0% | 85.6% | +39.6 pts |
| MRCR 128K (长上下文) | 13.5% | 66.4% | +52.9 pts |
关键发现: AIME 数学推理从 20.8% 跃升至 89.2%,提升 4.3 倍;LiveCodeBench 编码从 29.1% 到 80.0%,提升 2.7 倍。这不是渐进式改进,而是代际飞跃。
4 款模型完整基准数据
| 基准测试 | 31B | 26B-A4B | E4B | E2B |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% |
| AIME 2026 | 89.2% | 88.3% | 42.5% | 37.5% |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% |
| MMMU Pro (视觉) | 76.9% | 73.8% | 52.6% | 44.2% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 |
MoE 的效率优势: 26B-A4B 仅用 3.8B 激活参数就达到了 31B Dense 模型约 97% 的性能,推理成本大幅降低。在 LMArena 上,26B-A4B (~1441 ELO) 甚至超过了 OpenAI 的 gpt-oss-120B。
💡 选择建议: 追求极致性能选 31B,追求性价比选 26B-A4B (97% 性能仅需 12% 的激活参数)。通过 API易 apiyi.com 平台可以快速对比两个版本在具体业务场景中的实际表现。
Gemma 4 架构创新 6 大核心技术
Gemma 4 在架构层面引入了多项创新技术,这是其性能飞跃的根本原因。

技术 1: Per-Layer Embeddings (PLE)
PLE 在主残差流之外增加了一条并行条件路径,为每个 decoder 层生成专用的 token 向量。这项技术提高了小模型的表达能力,使 2.3B 有效参数的 E2B 获得了远超其参数量的性能。
技术 2: 混合注意力 (Hybrid Attention)
交替使用局部滑动窗口注意力和全局完整上下文注意力层:
- 滑动窗口层: 处理局部上下文 (E2B/E4B: 512 tokens; 31B/26B: 1024 tokens)
- 全局注意力层: 处理完整上下文范围
这种混合设计在保持长上下文能力的同时,显著降低了计算开销。
技术 3: Dual RoPE 位置编码
- 滑动窗口层使用标准 RoPE
- 全局注意力层使用 Proportional RoPE
这种双 RoPE 设计使 256K 上下文在不损失质量的前提下成为可能。
技术 4: 共享 KV 缓存
最后 N 层复用同类型最后一个非共享层的 K/V 张量,大幅减少计算量和显存占用。这是 Gemma 4 能在消费级硬件上运行大模型的关键技术之一。
技术 5: MoE 专家混合 (26B-A4B)
Gemma 4 首次引入 MoE 变体:
- 128 个小型专家
- 每 token 激活 8 个专家 + 1 个共享专家
- 以 3.8B 激活参数达到 31B Dense 约 97% 的性能
技术 6: 原生多模态
视觉和音频能力在预训练阶段直接集成:
- 视觉编码器: E2B/E4B ~150M 参数; 31B/26B ~550M 参数
- 音频编码器: USM 风格 conformer,~300M 参数 (仅 E2B/E4B)
- 支持变长宽比图像,可配置 token 预算 (70-1120 tokens)
Gemma 4 多模态和 Agent 能力详解
Gemma 4 不仅是一个对话模型,更是一个具备完整 Agent 能力的多模态系统。
多模态输入能力
| 模态 | E2B | E4B | 31B | 26B-A4B |
|---|---|---|---|---|
| 文本 | ✅ | ✅ | ✅ | ✅ |
| 图像 | ✅ | ✅ | ✅ | ✅ |
| 视频 (最长60秒 1fps) | ✅ | ✅ | ✅ | ✅ |
| 音频 (最长30秒) | ✅ | ✅ | ❌ | ❌ |
视觉能力覆盖:
- 目标检测与边界框输出 (原生 JSON 格式)
- GUI 元素检测和指向
- 文档/PDF 解析、图表理解
- 屏幕/UI 界面理解
- 图文交叉输入 (任意顺序混合)
原生函数调用和 Agent 能力
Gemma 4 从训练阶段就内置了函数调用能力,不是后期微调添加:
- 原生函数调用: 训练阶段直接优化,支持多工具编排
- Extended Thinking: 可通过
enable_thinking=True启用多步推理 - 结构化输出: 原生 JSON 输出,适合 API 集成
- 多轮 Agent 流程: 支持计划-执行-观察的自主 Agent 循环
# Gemma 4 函数调用示例 (通过 API易 统一接口)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="gemma-4-31b-it",
messages=[{"role": "user", "content": "北京今天天气怎么样?"}],
tools=tools,
tool_choice="auto",
)
🚀 快速开始: Gemma 4 的原生函数调用使其成为构建 AI Agent 的理想选择。推荐使用 API易 apiyi.com 平台快速接入,支持 OpenAI 兼容接口,无需额外适配。
Gemma 4 本地部署硬件指南
Apache 2.0 许可意味着你可以在任何硬件上自由部署 Gemma 4。以下是各模型的硬件需求。
硬件需求一览
| 模型 | 最低硬件 | 典型部署场景 |
|---|---|---|
| E2B (2.3B) | <1.5GB 内存 | 树莓派 5 (133 tok/s 预填充, 7.6 tok/s 解码) |
| E4B (4.5B) | 手机级 NPU/GPU | 移动设备、Apple Silicon (MLX) |
| 26B-A4B (MoE) | 单张消费级 GPU (量化) | 个人工作站、小型服务器 |
| 31B (Dense) | 单张 80GB H100 (FP16) | 云端推理、数据中心 |
支持的硬件和框架
| 硬件/框架 | 支持情况 |
|---|---|
| NVIDIA (H100/B200/RTX) | ✅ 全系列支持 |
| Google TPU (Trillium/Ironwood) | ✅ 原生优化 |
| Apple Silicon (MLX) | ✅ mlx-community/gemma-4-* |
| AMD ROCm | ✅ 支持 |
| Qualcomm NPU (IQ8) | ✅ 移动端推理 |
| GGUF (llama.cpp/Ollama) | ✅ 2-bit/4-bit 量化 |
| ONNX (WebGPU/浏览器) | ✅ onnx-community/gemma-4-* |
| NVIDIA NIM | ✅ 容器化部署 |
E2B 可以在树莓派 5 上以每秒 7.6 tokens 的速度运行解码,这为边缘 AI 应用打开了全新的可能性。
Apache 2.0 许可: 为什么这次不同
Gemma 4 首次采用 Apache 2.0 许可,这是一个重大变化。此前所有 Gemma 模型都使用 Google 自有许可协议,存在特定使用限制和终止权。
许可对比
| 维度 | Gemma 3 (Google 许可) | Gemma 4 (Apache 2.0) |
|---|---|---|
| 商业使用 | 有限制条件 | ✅ 完全自由 |
| 修改分发 | 需遵守附加条款 | ✅ 完全自由 |
| 衍生模型 | 有限制 | ✅ 完全自由 |
| 终止权 | Google 保留终止权 | ❌ 不可撤销 |
| 专利授权 | 有限 | ✅ 明确授权 |
Apache 2.0 意味着:
- 企业可以放心用于商业产品,无法律风险
- 可以自由微调并分发衍生模型
- 与 Meta Llama 和 DeepSeek 的开源策略对齐
- 大幅降低了企业采用的合规门槛
💰 成本优化: Apache 2.0 + 本地部署 = 零 API 调用成本。对于推理量大的场景,本地部署 Gemma 4 可能比 API 调用更经济。如果需要对比本地部署和 API 调用的成本效益,可以通过 API易 apiyi.com 平台先用 API 验证效果,再决定是否本地部署。
Gemma 4 模型获取和快速上手
模型下载渠道
| 平台 | 可用模型 | 用途 |
|---|---|---|
| Hugging Face | 全部 4 款 (base + IT) | 通用下载、研究 |
| Google AI Studio | 31B、26B MoE | 免费在线体验 |
| Vertex AI | 全部 4 款 | 企业级部署 |
| Ollama / llama.cpp | GGUF 量化版 | 本地快速部署 |
| Google AI Edge Gallery | E4B、E2B | 移动端部署 |
Ollama 一键部署
# 部署 Gemma 4 31B (推荐)
ollama run gemma4:31b
# 部署 MoE 版本 (高性价比)
ollama run gemma4:26b-a4b
# 部署轻量版 (边缘设备)
ollama run gemma4:e4b
微调支持
Gemma 4 提供完整的微调生态:
| 框架 | 支持的方式 |
|---|---|
| TRL | SFT、DPO、强化学习 (含多模态) |
| PEFT | LoRA、QLoRA (via bitsandbytes) |
| Vertex AI | 托管训练 |
| Unsloth Studio | UI 化微调 |
视觉和音频编码器可以冻结,只微调文本部分,大幅降低微调成本。
🎯 技术建议: 建议先通过 API易 apiyi.com 平台用 API 方式测试 Gemma 4 的效果,确认满足需求后再进行本地部署或微调,避免资源浪费。
常见问题
Q1: Gemma 4 和 Gemini 3 是什么关系?
Gemma 4 基于 Gemini 3 的同源研究构建,可以理解为 Gemini 3 技术的开源版本。Gemma 4 的模型规模更小 (最大 31B vs Gemini 数千亿),但采用了相同的核心架构创新。通过 API易 apiyi.com 平台可以同时使用 Gemma 4 和 Gemini 系列模型进行对比。
Q2: 26B MoE 和 31B Dense 怎么选?
如果你的硬件有限或需要高吞吐量,选 26B-A4B MoE — 它仅用 3.8B 激活参数就达到 31B 约 97% 的性能。如果追求极致性能且有 80GB GPU,选 31B Dense。MoE 版本的推理成本约为 Dense 版本的 1/8。
Q3: E2B 和 E4B 适合什么场景?
E2B 适合极致边缘场景 (树莓派、IoT 设备、手机端),E4B 适合移动端和轻量级 PC 部署。两者都支持音频输入,这是 31B 和 26B 不支持的。如果你的应用需要语音理解,必须选择 E2B 或 E4B。
Q4: Apache 2.0 许可对商业使用有什么影响?
Apache 2.0 是最宽松的开源许可之一,允许完全自由的商业使用、修改和分发,且不可撤销。与 Gemma 3 的 Google 自有许可相比,企业无需担心合规风险。你可以在 API易 apiyi.com 平台上先用 API 测试,确认效果后再本地部署用于商业产品。
总结
Gemma 4 是 Google 开源 AI 战略的一次重大升级。Apache 2.0 许可打破了此前的使用壁垒;4 款模型覆盖从树莓派到 H100 的全算力场景;AIME 4.3 倍、LiveCodeBench 2.7 倍的代际性能飞跃;原生多模态和函数调用使其成为开源 Agent 开发的首选基座模型。
核心要点回顾:
- 许可: 首次 Apache 2.0,完全自由商用
- 模型: 4 款覆盖 2B-31B,含首个 MoE 变体
- 性能: AIME +68pts (4.3x),LiveCodeBench +51pts (2.7x)
- 多模态: 文本+图像+视频+音频,原生集成
- Agent: 原生函数调用 + Extended Thinking
- 部署: 树莓派到 H100 全覆盖,GGUF/ONNX/MLX 多框架
推荐通过 API易 apiyi.com 快速接入 Gemma 4 系列模型,在统一接口下对比不同模型的实际效果。
参考资料
- Google 官方博客 – Gemma 4 发布:
blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ - Hugging Face – Gemma 4 模型:
huggingface.co/blog/gemma4 - Google AI – Gemma 4 模型卡:
ai.google.dev/gemma/docs/core/model_card_4
本文由 APIYI Team 技术团队撰写,更多 AI 模型使用教程请关注 API易 apiyi.com