xAI 的 Grok 4.20 Beta 系列正式上线 API易平台——一次性新增 4 款模型,覆盖从快速问答到多智能体深度研究的全场景。定价输入 $2 / 输出 $6 每百万 tokens,是当前主流旗舰模型中性价比最高的选择之一。
这 4 款模型不是简单的版本号递增,而是架构层面的差异:有的追求极速响应,有的进行深度推理,还有一款让 4 个 AI 智能体同时协作——幻觉率直降 65%。
核心价值: 读完本文,你将理解 4 款 Grok 4.20 Beta 模型各自的定位和最佳使用场景,掌握 API 调用方法,做出最优的模型选型决策。
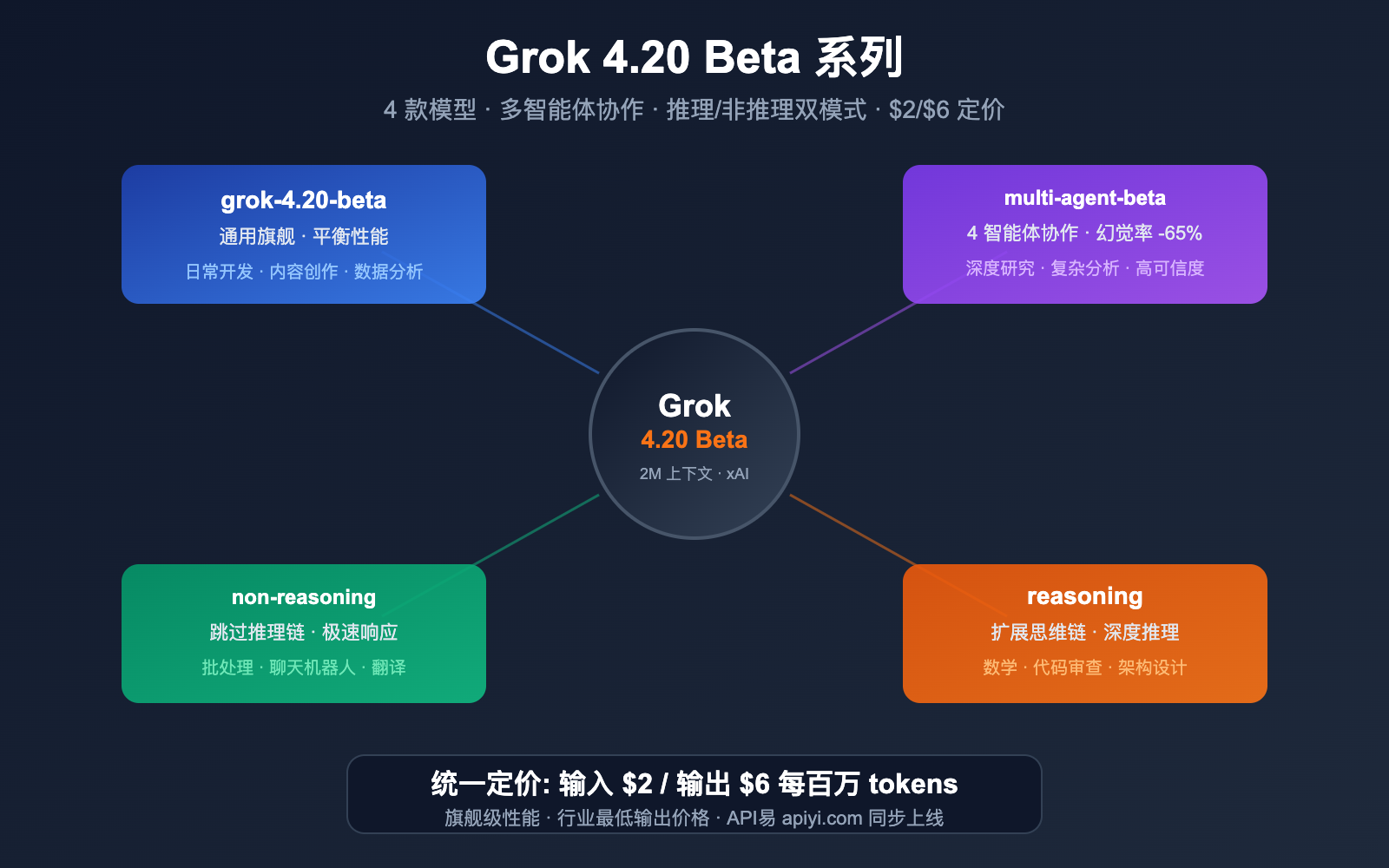
4 款模型一览:核心差异速查
模型矩阵
| 模型 ID | 定位 | 核心特征 | 最佳场景 |
|---|---|---|---|
grok-4.20-beta |
通用旗舰 | 平衡性能和速度 | 日常开发、通用任务 |
grok-4.20-multi-agent-beta-0309 |
多智能体协作 | 4 个 Agent 并行协作 | 深度研究、复杂分析 |
grok-4.20-beta-0309-non-reasoning |
快速响应 | 跳过推理链,低延迟 | 高吞吐批处理、简单问答 |
grok-4.20-beta-0309-reasoning |
深度推理 | 扩展思维链推理 | 数学、代码分析、逻辑论证 |
统一定价
| 计费项 | 价格 |
|---|---|
| 输入 token | $2.00 / 百万 tokens |
| 输出 token | $6.00 / 百万 tokens |
| 上下文窗口 | 200 万 tokens (2M) |
| 批处理折扣 | 50% |
与竞品价格对比:
| 模型 | 输入价格 | 输出价格 | 性价比 |
|---|---|---|---|
| Grok 4.20 Beta | $2.00 | $6.00 | 🟢 最优 |
| Gemini 3.1 Pro | $2.00 | $12.00 | 良好 |
| GPT-5.4 | $2.50 | $15.00 | 一般 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 一般 |
| Claude Opus 4.6 | $15.00 | $75.00 | 较高 |
Grok 4.20 的输出价格仅为 Claude Sonnet 4.6 的 40%,是 Claude Opus 4.6 的 8%。对于输出密集型任务 (代码生成、长文本),成本优势极其显著。
🎯 定价说明: API易 apiyi.com 上线的 Grok 4.20 Beta 系列定价与 xAI 官网一致(输入 $2 / 输出 $6),折扣体现在平台充值活动中。一个 Key 即可同时调用 Grok、Claude、GPT 等 200+ 模型。
4 款模型深度解析
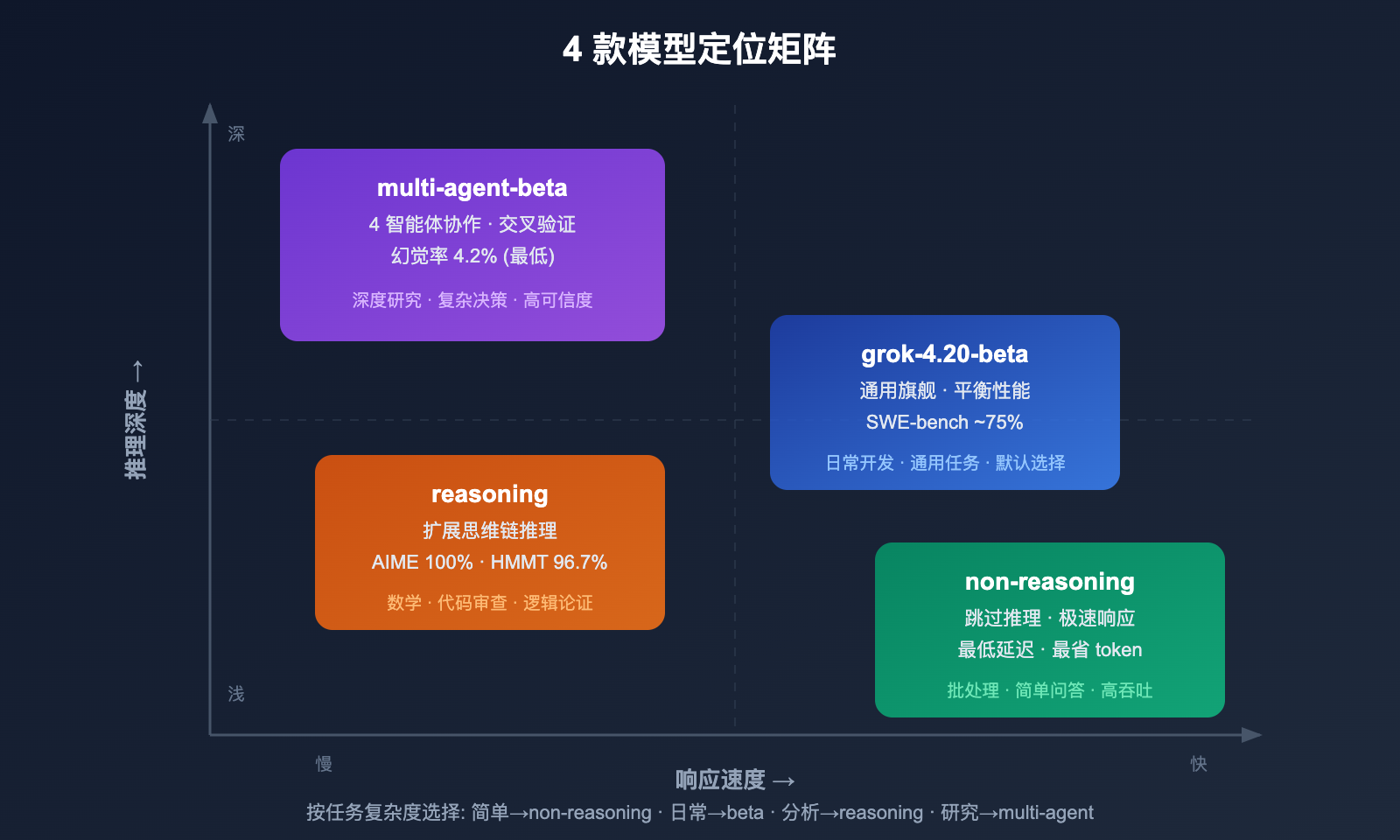
模型一:grok-4.20-beta (通用旗舰)
这是 Grok 4.20 系列的默认入口,平衡了性能、速度和成本。
核心特性:
- 继承 Grok 4 家族的全部能力
- 200 万 token 上下文窗口——西方前沿模型中最大
- 支持图片输入 (JPG/PNG)
- 每周根据真实世界反馈持续改进
基准表现:
- SWE-bench: ~75% (接近 GPT-5 的 74.9%)
- GPQA (研究生级别): 88.4%
- Arena Elo: ~1,505-1,535
适用场景: 日常编程辅助、内容创作、数据分析、通用对话
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易统一接口
)
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "user", "content": "用 Python 实现一个 LRU 缓存"}
]
)
print(response.choices[0].message.content)
模型二:grok-4.20-multi-agent-beta-0309 (多智能体)
这是 Grok 4.20 最具创新性的变体——4 个 AI 智能体同时协作处理你的请求。
4 个智能体各司其职:
| 智能体 | 角色 | 专长 |
|---|---|---|
| Grok (队长) | 协调员 | 任务分解、流程管理、聚合输出 |
| Harper | 研究员 | 实时数据检索、事实核查 (接入 X/Twitter 数据) |
| Benjamin | 分析师 | 逻辑推理、数学计算、代码分析 |
| Lucas | 挑战者 | 创意综合、内建反对立场——质疑其他智能体的结论 |
工作流程:
用户提问
↓
Grok 分解任务 → 分配给 4 个智能体
↓
Harper 搜集数据 | Benjamin 逻辑分析 | Lucas 质疑挑战
↓
智能体间内部辩论 + 交叉验证
↓
Grok 聚合共识 → 返回最终答案
最大亮点——幻觉率降低 65%:
| 指标 | 单模型基线 | 多智能体模式 | 改善 |
|---|---|---|---|
| 幻觉率 | ~12% | ~4.2% | 降低 65% |
| "不确定时说不知道"比率 | — | 78% | 行业最高 |
Lucas 的"内建反对立场"是关键设计:它的工作就是找其他智能体结论中的漏洞。这种对抗式协作让最终输出更加可靠。
适用场景: 深度研究报告、复杂决策分析、需要高可信度的输出
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[
{"role": "user", "content": "分析 2026 年 AI 编程工具市场的竞争格局和趋势预测"}
]
)
模型三:grok-4.20-beta-0309-non-reasoning (非推理)
这是为速度和吞吐量优化的变体。它跳过内部推理链 (Chain-of-Thought),直接生成答案。
核心特性:
- 低延迟、高吞吐
- 不产生内部推理 token,节省输出成本
- 适合简单明确的任务
适用场景:
- 高频 API 调用 (批量数据处理)
- 聊天机器人 / 客服系统
- 内容分类、标签提取
- 简单代码补全
- 翻译、摘要
不适合: 复杂数学推导、多步逻辑分析、需要深度思考的架构设计
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[
{"role": "user", "content": "将以下 JSON 转换为 CSV 格式: ..."}
]
)
模型四:grok-4.20-beta-0309-reasoning (推理)
这是与非推理版相对的深度推理变体。它启用扩展思维链 (Extended Chain-of-Thought),在回答前进行深入的内部推理。
核心特性:
- 扩展推理 token,深度分析问题
- 数学和逻辑任务表现卓越 (AIME 2025: 100%, HMMT25: 96.7%)
- Artificial Analysis 智力指数: 48
适用场景:
- 数学证明和推导
- 代码审查和 Bug 分析
- 架构设计权衡
- 复杂逻辑论证
- 学术论文分析
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[
{"role": "user", "content": "分析这段并发代码中可能存在的竞态条件和死锁风险"}
]
)
💡 选型建议: 大多数日常任务用
grok-4.20-beta即可。需要高可信度输出用多智能体版,批量处理用非推理版,复杂分析用推理版。通过 API易 apiyi.com 一个 Key 即可调用全部 4 款模型,按需切换。
模型选型决策树
按任务类型选择
| 任务类型 | 推荐模型 | 理由 |
|---|---|---|
| 日常编程辅助 | grok-4.20-beta |
平衡性能和成本 |
| 批量数据处理 | non-reasoning |
最快速度,最低延迟 |
| 代码审查/Bug 分析 | reasoning |
需要深度推理 |
| 研究报告撰写 | multi-agent |
4 智能体交叉验证 |
| 实时数据分析 | multi-agent |
Harper 接入实时 X 数据 |
| 数学/逻辑推导 | reasoning |
AIME 100% 满分 |
| 聊天机器人 | non-reasoning |
低延迟快速响应 |
| 内容翻译/摘要 | non-reasoning |
简单任务无需推理 |
| 架构设计方案 | reasoning 或 multi-agent |
需要权衡分析 |
按成本敏感度选择
极致省钱 → non-reasoning (无推理 token,输出最少)
↓
日常性价比 → grok-4.20-beta (通用平衡)
↓
质量优先 → reasoning (深度推理,输出token更多)
↓
最高可信度 → multi-agent (4 智能体,输出最详尽)
🚀 快速开始: 推荐从
grok-4.20-beta入手体验。通过 API易 apiyi.com 注册即可获取 API Key,定价与 xAI 官网一致(输入 $2 / 输出 $6),折扣体现在充值活动中。
Grok 4.20 vs 主流模型横向对比
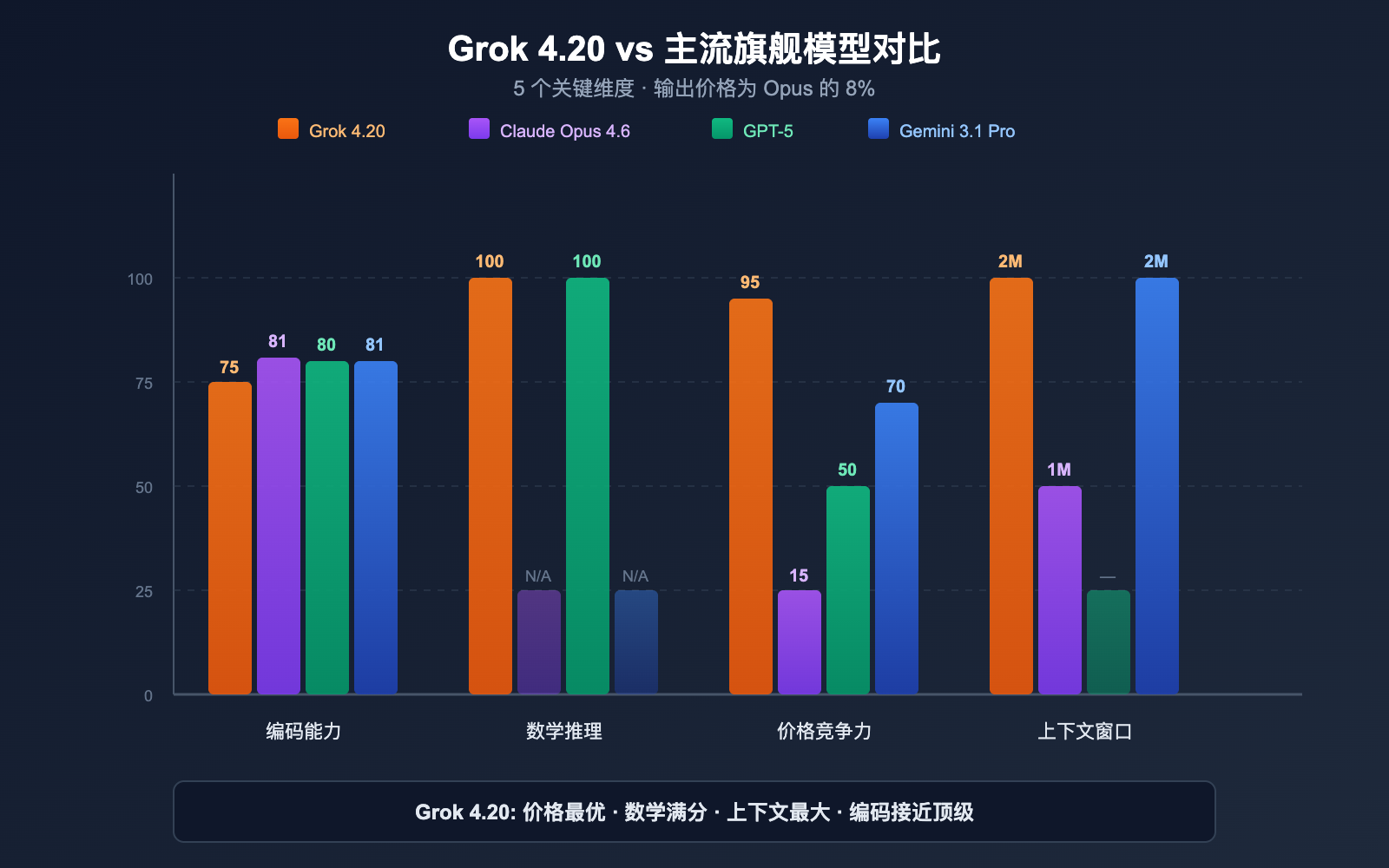
全维度对比
| 维度 | Grok 4.20 Beta | Claude Opus 4.6 | GPT-5 系列 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench | ~75% | 81.4% | ~80% | ~80.6% |
| 数学 (AIME) | 100% | — | 100% | — |
| GPQA | 88.4% | — | — | — |
| 上下文 | 200 万 | 100 万 | 因模型而异 | 200 万 |
| 输入价格 | $2 | $15 | $2.50 | $2 |
| 输出价格 | $6 | $75 | $15 | $12 |
| 多智能体 | ✅ 4 Agent | ❌ | ❌ | ❌ |
| 实时数据 | ✅ X/Twitter | ❌ | ✅ 搜索 | ✅ 搜索 |
| 幻觉控制 | 4.2% (最低) | 较低 | 较低 | 中等 |
| 图片输入 | ✅ JPG/PNG | ✅ 多格式 | ✅ 多格式 | ✅ 多格式 |
各模型最佳场景
- Grok 4.20: 高性价比通用、深度研究 (多智能体)、实时数据分析
- Claude Opus 4.6: 软件工程 (SWE-bench 最高)、超长输出 (128K)、企业级安全
- GPT-5: 数学满分、桌面自动化、最大用户生态
- Gemini 3.1 Pro: Google 生态整合、200 万上下文、成本适中
💰 性价比分析: Grok 4.20 的输出价格 ($6/MTok) 仅为 Claude Opus 4.6 ($75/MTok) 的 8%。对于输出密集型任务(长代码生成、研究报告),使用 Grok 4.20 可以将成本降低 90% 以上。通过 API易 apiyi.com 可以同时接入 Grok、Claude、GPT 全系列模型,根据任务特点灵活切换。
API 调用实战
基础调用示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易统一接口
)
# 通用任务 → 基础版
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "system", "content": "你是一位资深 Python 开发者。"},
{"role": "user", "content": "实现一个异步任务队列"}
],
max_tokens=4096
)
print(response.choices[0].message.content)
根据任务自动选型
def choose_grok_model(task_type):
"""根据任务类型自动选择最优 Grok 模型"""
model_map = {
"quick": "grok-4.20-beta-0309-non-reasoning",
"general": "grok-4.20-beta",
"analysis": "grok-4.20-beta-0309-reasoning",
"research": "grok-4.20-multi-agent-beta-0309"
}
return model_map.get(task_type, "grok-4.20-beta")
# 使用示例
model = choose_grok_model("analysis")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "分析这段代码的性能瓶颈..."}]
)
查看多模型对比测试代码
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
models = [
"grok-4.20-beta",
"grok-4.20-beta-0309-non-reasoning",
"grok-4.20-beta-0309-reasoning",
"grok-4.20-multi-agent-beta-0309"
]
prompt = "用 Python 实现快速排序并分析时间复杂度"
for model in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2048
)
elapsed = time.time() - start
tokens = response.usage.total_tokens
print(f"{model}")
print(f" 耗时: {elapsed:.1f}s | Tokens: {tokens}")
print(f" 预览: {response.choices[0].message.content[:80]}...")
print()
except Exception as e:
print(f"{model} | 错误: {e}")
time.sleep(1)
🎯 实战建议: 建议先用
grok-4.20-beta跑一遍基准测试,再和reasoning版对比复杂任务的输出质量差异。通过 API易 apiyi.com 调用全部 4 款模型,定价与官网一致,折扣体现在充值活动中。
常见问题
Q1: 4 款模型的定价一样吗?
是的,4 款模型统一定价:输入 $2 / 输出 $6 每百万 tokens。但实际成本因模型而异——推理模型会产生更多推理 token (计为输出),多智能体版因 4 个 Agent 协作可能消耗更多 token。非推理版最省钱,因为它跳过推理链,输出 token 最少。通过 API易 apiyi.com 调用定价与 xAI 官网一致,折扣体现在平台充值活动中。
Q2: 多智能体版和推理版有什么区别?
推理版是单个 Agent 进行深度思考——适合有明确答案的分析任务 (数学、代码审查)。多智能体版是4 个 Agent 协作讨论——适合需要多角度分析的开放性问题 (市场研究、决策分析)。多智能体版的核心优势是交叉验证降低幻觉率 (从 12% 降到 4.2%)。
Q3: Grok 4.20 能替代 Claude 做代码审查吗?
部分场景可以。Grok 4.20 推理版在 SWE-bench 上达到 ~75%,低于 Claude Opus 4.6 的 81.4%,但价格仅为其 8%。对于非安全关键的日常代码审查,Grok 4.20 推理版是高性价比选择。对于安全审计和大型架构审查,Claude Opus 4.6 仍然更可靠。通过 API易 apiyi.com 可以同时接入两家模型,按任务灵活切换。
Q4: 200 万 token 上下文有什么实际用处?
200 万 token 约等于一本 1500 页的技术书籍。实际应用:(1) 一次性加载整个中大型代码库进行分析;(2) 处理超长文档 (法律合同、学术论文集);(3) 保持超长对话记忆。这是目前西方前沿模型中最大的上下文窗口。
Q5: 如何在 API易平台调用这些模型?
注册 API易 apiyi.com 获取 Key 后,使用 OpenAI 兼容格式调用即可。只需将 base_url 设为 https://api.apiyi.com/v1,model 设为对应的模型 ID (如 grok-4.20-beta)。代码示例见上文。4 款模型定价与官网一致,折扣通过充值活动发放。
总结:4 款模型的最优使用策略
Grok 4.20 Beta 系列为不同场景提供了精准的模型选择。核心策略是按任务复杂度匹配模型:
| 复杂度 | 推荐模型 | 成本 |
|---|---|---|
| 🟢 简单/高频 | non-reasoning |
最低 |
| 🟡 日常通用 | grok-4.20-beta |
适中 |
| 🟠 深度分析 | reasoning |
较高 |
| 🔴 最高可信度 | multi-agent |
最高 |
$2/$6 的定价让 Grok 4.20 成为当前市场上输出成本最低的旗舰模型。配合 200 万 token 上下文和多智能体系统,它在研究、分析和高吞吐场景下极具竞争力。
推荐通过 API易 apiyi.com 一站式接入 Grok 4.20 Beta 全系列模型,定价与官网一致,折扣体现在充值活动中。一个 Key 同时调用 Grok、Claude、GPT 等 200+ 模型。
参考资料
-
xAI 官方文档: Grok 模型和定价说明
- 链接:
docs.x.ai/developers/models
- 链接:
-
Artificial Analysis: Grok 4.20 Beta 基准评测
- 链接:
artificialanalysis.ai/models/grok-4-20
- 链接:
-
xAI 多智能体文档: Multi-Agent 能力详解
- 链接:
docs.x.ai/developers/model-capabilities/text/multi-agent
- 链接:
-
OpenRouter: Grok 4.20 Beta 模型页面
- 链接:
openrouter.ai
- 链接:
作者: APIYI Team | 第一时间上线最新 AI 模型,欢迎访问 API易 apiyi.com 体验 Grok 4.20 Beta 全系列模型。