作者注:GPT-5.4 还是 Claude Opus 4.6?2026年最值得关注的两款旗舰AI模型正面交锋。本文汇总 Chatbot Arena、SWE-bench、ARC-AGI-2 以及 OpenClaw PinchBench 的最新实测数据,从编程、推理、智能体任务和性价比四大维度给出明确选择建议。

GPT-5.4 vs Claude Opus 4.6:核心差异速览
选择旗舰AI模型,最关键的几个维度一目了然:
| 对比维度 | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|
| 发布时间 | 2025年底 | 2026年2月 |
| Chatbot Arena ELO | 1463 | 1503 (#1) |
| AI综合智能指数 | 57 | 53 |
| API输入价格 | $2.50/M tokens | $5.00/M tokens |
| API输出价格 | $15.00/M tokens | $25.00/M tokens |
| 上下文窗口 | ~1M tokens | 200K(1M Beta) |
| 最大输出长度 | — | 128K tokens |
| 状态 | 现役 | 现役 |
核心结论:GPT-5.4 综合智能指数更高,价格便宜约 50%;Claude Opus 4.6 在 Chatbot Arena 用户满意度排名全球第一,复杂编程和智能体任务更强。
🎯 快速建议:如果你是价格敏感的开发者,GPT-5.4 性价比更高;如果你的项目需要复杂代码生成或长文档处理,Opus 4.6 更值得投入。建议通过 API易 apiyi.com 同时接入两款模型进行实际对比测试,平台支持统一 API 接口快速切换。
权威基准测试:GPT-5.4 vs Claude Opus 4.6 全维度对比
推理与知识能力对比
| 基准测试 | GPT-5.4 | Claude Opus 4.6 | 说明 |
|---|---|---|---|
| GPQA Diamond(研究生科学题) | 93.2% | 91.3% | GPT-5.4 胜 |
| MMLU(百科知识) | 89.6% | 91.1% | Opus 4.6 胜 |
| ARC-AGI-2(抽象推理) | 52.9% | 68.8% | Opus 4.6 大幅领先 |
| BigLaw Bench(法律专业) | — | 90.2% | Opus 4.6 专项优势 |
| MRCR v2(1M 长上下文) | — | 76% | Opus 4.6 超长文档领先 |
| GDPval-AA ELO(专业任务) | 1462 | 1606 | Opus 4.6 明显优于 |
解读:GPT-5.4 在科学推理(GPQA Diamond)上有微弱优势,但在抽象推理(ARC-AGI-2 领先 16 个百分点)、专业知识工作和长上下文处理上,Claude Opus 4.6 均表现更强。
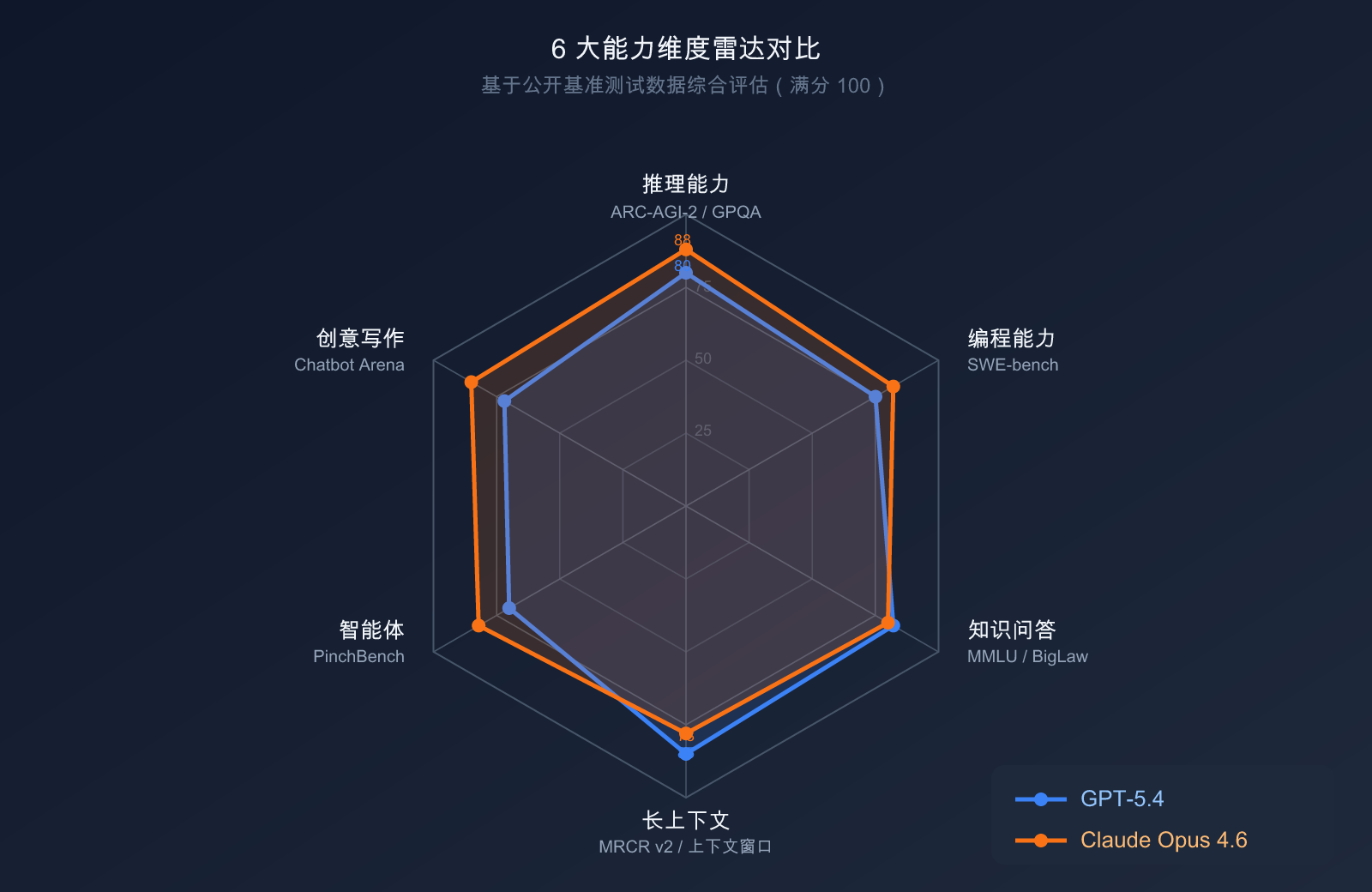
编程与智能体能力对比
| 基准测试 | GPT-5.4 | Claude Opus 4.6 | 说明 |
|---|---|---|---|
| SWE-bench Verified(真实代码修复) | ~77.2% | 80.8% | Opus 4.6 胜 |
| SWE-bench Pro(专业级代码) | 57.7% | ~45% | GPT-5.4 胜 |
| Terminal-Bench 2.0(终端操作) | 64.7% | 65.4% | Opus 4.6 微弱胜 |
| OSWorld(电脑操控) | 75.0% | 72.7% | GPT-5.4 微弱胜 |
| BrowseComp(网页搜索研究) | 77.9% | 84.0% | Opus 4.6 胜 |
| OpenRCA(根因分析) | — | 34.9% | Opus 4.6 专项优势 |
解读:两款模型在编程方向各有侧重。SWE-bench Verified(日常代码修复)Opus 4.6 更强;SWE-bench Pro(企业级复杂代码)GPT-5.4 领先;电脑操控 GPT-5.4 小胜,但 Opus 4.6 在网页研究和根因分析上表现突出。
💡 开发者建议:面向产品交付的代码生成任务,推荐先通过 API易 apiyi.com 的统一接口分别测试两款模型,结合你的具体代码库特点做决策,成本仅为直接调用 Anthropic/OpenAI 官方 API 的 60-80%。
OpenClaw 智能体实战:PinchBench 最新实测数据
什么是 OpenClaw 和 PinchBench?
OpenClaw 是一个开源、可自托管的 AI 智能体平台(类似 Claude Code),支持终端访问、多文件编辑、与 WhatsApp/Telegram/Slack 等 50+ 工具集成。由奥地利开发者 Peter Steinberger 于2025年11月创建,目前在 GitHub 上快速增长。
PinchBench 是专为 OpenClaw 智能体设计的评测基准,由 Kilo.ai 开发。它不像传统 benchmark 测单一问答,而是测试模型在真实世界多步骤任务中的表现:
- 安排会议、管理日历
- 编写多文件代码项目
- 分类处理邮件、文件管理
- 网页研究和信息整合
这是目前最接近真实 AI Agent 使用场景的测试之一。
PinchBench 排行榜(2026年3月13日,47个模型,277次运行)
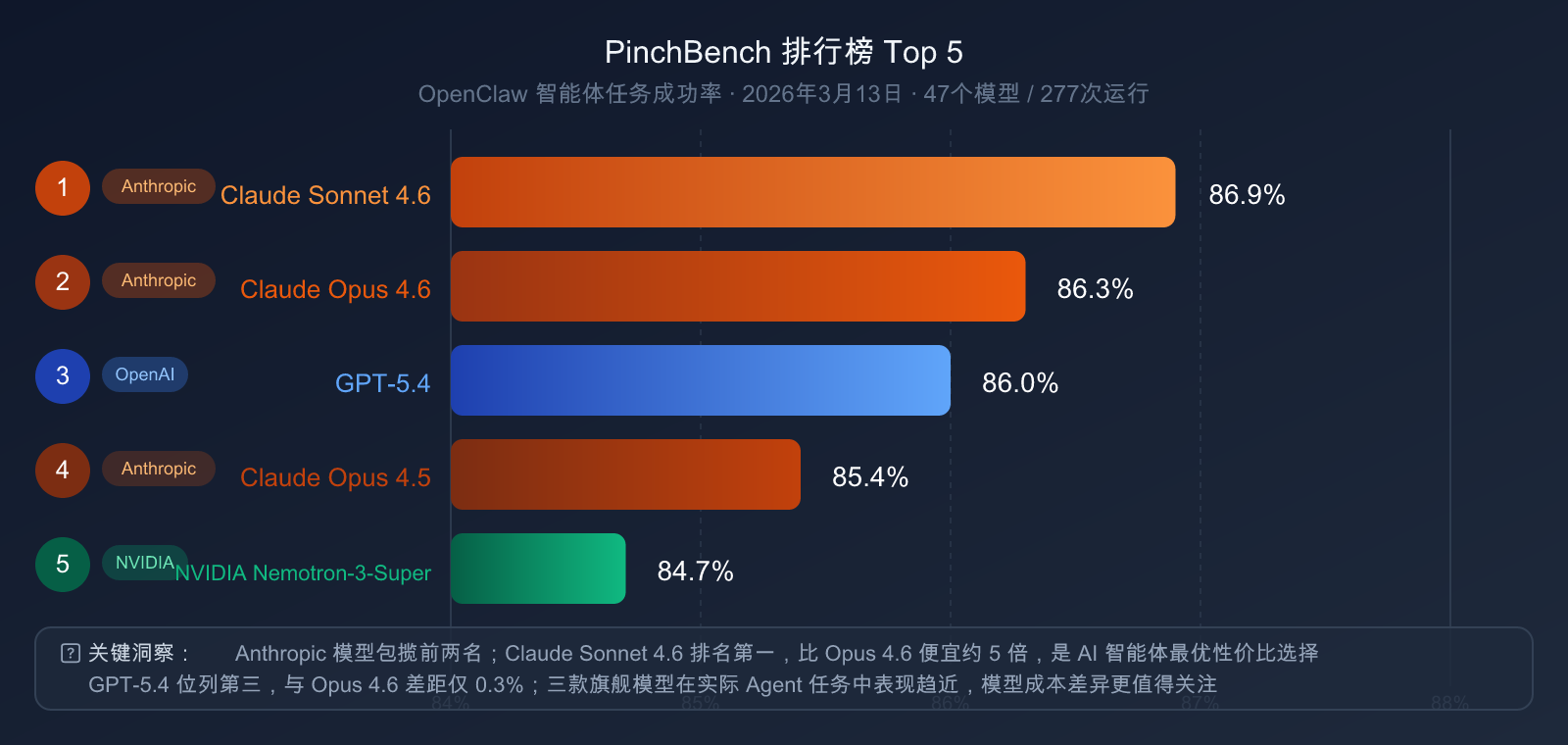
| 排名 | 模型 | PinchBench 成功率 |
|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% |
| 🥈 2 | Claude Opus 4.6 | 86.3% |
| 🥉 3 | GPT-5.4 | 86.0% |
| 4 | Claude Opus 4.5 | 85.4% |
| 5 | NVIDIA Nemotron-3-Super | 84.7% |
关键发现:
- Claude 系列包揽前两名:Sonnet 4.6 和 Opus 4.6 分别占据第一、第二,说明 Anthropic 在智能体工程上的系统性优势
- GPT-5.4 位列第三:与 Opus 4.6 差距仅 0.3 个百分点,差距极小
- 性价比亮点:Claude Sonnet 4.6(比 Opus 4.6 便宜约 5 倍)在 PinchBench 上反而排名更高,说明并非越贵越好
- Claude Sonnet 4.6 值得重新审视:对于 OpenClaw 类智能体任务,Sonnet 4.6 是最优性价比选择
🔍 智能体项目推荐:如果你在构建基于 OpenClaw 的 AI Agent,三款模型(Sonnet 4.6、Opus 4.6、GPT-5.4)差距不足 1%,推荐通过 API易 apiyi.com 按需接入,根据实际任务类型动态选择模型,降低成本的同时保持高成功率。
Chatbot Arena ELO:用户真实投票选出的最强模型
Chatbot Arena(原 LMSYS)是目前最权威的 AI 模型用户偏好排行榜,通过数百万次真实对话盲测投票产生 ELO 分数。
2026年2月最新排名(Top 5):
| 排名 | 模型 | ELO 分数 |
|---|---|---|
| 🥇 1 | Claude Opus 4.6 | 1503 |
| 2 | Grok-4.1-Thinking | 1482 |
| 🥉 3 | GPT-5.4 | 1463 |
| 4 | Gemini 3 Pro | ~1445 |
| 5 | Claude Sonnet 4.6 | ~1438 |
Claude Opus 4.6 以 40 分的 ELO 差距领先 GPT-5.4,在多轮对话、风格控制、创意写作等维度尤为突出。这一差距在 Chatbot Arena 的评估体系中属于显著优势。
GPT-4.5(历史参考):OpenAI 于2025年2月发布的 GPT-4.5(代号"Orion")专注于情感智能和对话质量,在发布初期曾短暂登顶 Chatbot Arena。但该模型已于2025年7月14日从 API 下线,ChatGPT 内也于2025年8月完全退出。GPT-5.4 是其现任继承者,在各项能力上全面超越。
API 价格与性价比:成本敏感项目如何选择
| 费用项目 | GPT-5.4 | Claude Opus 4.6 | 差异 |
|---|---|---|---|
| 输入价格(每百万 tokens) | $2.50 | $5.00 | Opus 4.6 贵 2x |
| 输出价格(每百万 tokens) | $15.00 | $25.00 | Opus 4.6 贵 1.67x |
| 上下文窗口 | ~1M tokens | 200K(1M Beta) | GPT-5.4 胜 |
| 最大输出长度 | — | 128K tokens | Opus 4.6 胜 |
| 多模态支持 | ✅ 图像输入 | ✅ 图像输入 | 相当 |
成本估算(每日处理 100 万 tokens 输入 + 200K tokens 输出):
- GPT-5.4:约 $5.50/天(月均 $165)
- Claude Opus 4.6:约 $10.00/天(月均 $300)
💰 成本优化方案:对于高并发或预算有限的项目,推荐在 API易 apiyi.com 使用 Claude Sonnet 4.6 处理日常任务,仅在需要最强推理能力时调用 Opus 4.6,可将 API 成本降低 60-75%。API易支持同账户多模型统一计费,方便做精细化成本管理。
场景推荐:GPT-5.4 vs Claude Opus 4.6 该选哪个?
优先选择 GPT-5.4 的场景
✅ 高性价比通用任务
- 预算有限但需要旗舰级能力
- 日常内容创作、客服问答、信息提取
- 月 API 调用费用超过 $500 时,节省成本显著
✅ 科学研究与技术问答
- GPQA Diamond 领先,对博士级科学推理更强
- 化学、物理、生物等学术领域的专业问答
✅ 企业级复杂代码(SWE-bench Pro 领先)
- 处理超大型代码库的架构级修改
- 需要深度理解复杂依赖关系的重构任务
✅ 超长上下文场景
- 需要处理接近 1M tokens 的超长文档或代码库
- Opus 4.6 的 1M 上下文还在 Beta 阶段
优先选择 Claude Opus 4.6 的场景
✅ 产品级代码生成与修复
- SWE-bench Verified 80.8%,日常 Bug 修复和功能开发更可靠
- BrowseComp 84% 的网页研究能力,适合 RAG 增强应用
✅ OpenClaw 类智能体项目
- PinchBench 排名前二,Anthropic 模型在实际 Agent 任务中系统性更优
✅ 对话质量要求高的产品
- Chatbot Arena ELO 1503,用户满意度全球第一
- 多轮对话连贯性和风格适应能力更强
✅ 专业知识工作
- ARC-AGI-2 领先 16 个百分点,抽象推理更强
- BigLaw Bench 90.2%,法律、合规、文档分析更可靠
✅ 长文档输出
- 128K 最大输出,适合生成完整报告、长篇文档
🎯 场景决策建议:两款模型各有所长,差距主要体现在特定任务上。我们建议通过 API易 apiyi.com 平台在正式上线前进行 A/B 测试,平台提供统一接口支持快速切换模型,帮助你找到最适合自己业务场景的最优选择。
快速接入:通过统一 API 同时使用两款模型
无需分别注册 OpenAI 和 Anthropic 账户,通过 API易 可用统一接口访问所有主流模型:
from openai import OpenAI
# 通过 API易 统一接口,支持 GPT-5.4 和 Claude Opus 4.6
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # API易统一接入地址
)
# 调用 Claude Opus 4.6
response_opus = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": "请帮我分析以下代码中的潜在Bug..."}
],
max_tokens=4096
)
# 调用 GPT-5.4(同一接口,切换模型名称即可)
response_gpt = client.chat.completions.create(
model="gpt-5-4",
messages=[
{"role": "user", "content": "请帮我分析以下代码中的潜在Bug..."}
],
max_tokens=4096
)
print("Opus 4.6:", response_opus.choices[0].message.content)
print("GPT-5.4:", response_gpt.choices[0].message.content)
💡 接入说明:将
base_url设为https://vip.apiyi.com/v1,api_key换成你在 API易 apiyi.com 申请的密钥,即可一键切换。首充有赠送额度,方便在正式上线前测试两款模型的实际差异。
模型名称对照:
| 模型 | API 调用名称 | 月均成本(100M tokens/月) |
|---|---|---|
| Claude Opus 4.6 | claude-opus-4-6 |
约 $500+ |
| Claude Sonnet 4.6 | claude-sonnet-4-6 |
约 $100+ |
| GPT-5.4 | gpt-5-4 |
约 $250+ |
常见问题解答
Q: GPT-4.5 和 GPT-5.4 是同一款模型吗?
不是。GPT-4.5(代号"Orion")是 OpenAI 于2025年2月发布的过渡模型,主打情感智能和对话质量,定价极高($75/$150 per M tokens),已于2025年7月14日从 API 正式下线。GPT-5.4 是 OpenAI 目前在售的旗舰模型,能力全面超越 GPT-4.5,价格也大幅下降至 $2.50/$15 per M tokens。如需调用最强 OpenAI 模型,应使用 GPT-5.4,可通过 API易 apiyi.com 接入。
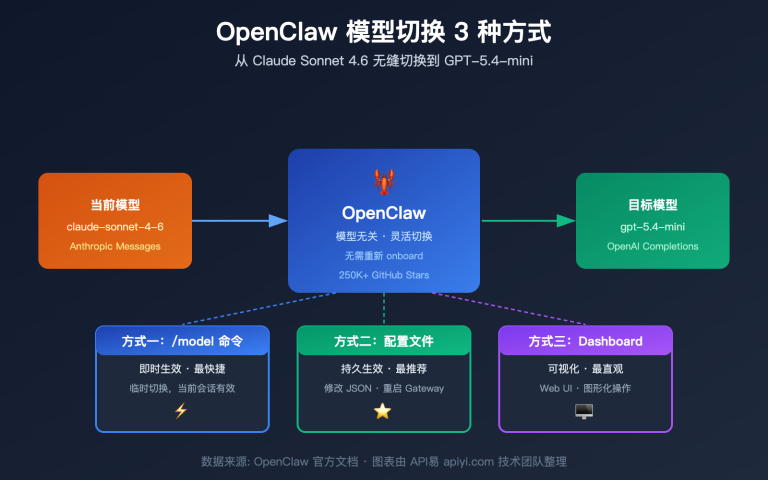
Q: OpenClaw 是什么?它和 Cursor / Claude Code 有什么区别?
OpenClaw 是一个开源、可自托管的 AI 智能体平台,支持终端访问、多文件代码编辑、WhatsApp/Telegram/Slack 等 50+ 工具集成,还具备自动生成新技能的"自进化"能力。与 Cursor(商业 IDE 插件)和 Claude Code(Anthropic 官方 CLI)相比,OpenClaw 的核心优势是完全开源且可私有化部署,适合对数据安全有要求的企业场景。PinchBench 是专门评测 AI 模型在 OpenClaw 智能体任务中表现的基准测试。
Q: 对于 AI 写作类任务,哪款模型更好?
根据 Chatbot Arena ELO 评分,Claude Opus 4.6 在用户偏好测试中以 1503 分排名全球第一,在创意写作、多轮对话和文风适配方面表现尤为突出。GPT-5.4 在写作上同样出色但用户满意度排名略低。建议通过 API易 apiyi.com 对你的具体写作场景分别测试,不同风格和类型的写作任务可能有不同结果。
Q: Claude Sonnet 4.6 和 Claude Opus 4.6 差距有多大?
从 PinchBench 智能体测试来看,Sonnet 4.6(86.9%)甚至略高于 Opus 4.6(86.3%)。在 Chatbot Arena ELO 上,Sonnet 4.6 约为 1438,Opus 4.6 为 1503,差距约 65 分。对于大多数编程和分析任务,Sonnet 4.6 是更优性价比选择(价格约为 Opus 4.6 的 20%)。复杂推理、长文档处理和极端精度要求的场景,才值得升级到 Opus 4.6。
总结:2026 年旗舰模型该如何选择?
| 需求场景 | 推荐模型 | 核心理由 |
|---|---|---|
| 日常开发 + 控制成本 | GPT-5.4 | 便宜 50%,综合能力强 |
| 复杂代码修复(SWE-bench) | Claude Opus 4.6 | 80.8% 领先 GPT-5.4 的 77.2% |
| AI 智能体任务(OpenClaw) | Claude Sonnet 4.6 | PinchBench 第一,比 Opus 还便宜 |
| 对话产品 / 用户满意度 | Claude Opus 4.6 | Chatbot Arena ELO #1(1503) |
| 科学研究 / 学术问答 | GPT-5.4 | GPQA Diamond 93.2% 小幅领先 |
| 超长文档分析 | Claude Opus 4.6 | 128K 输出 + MRCR v2 76% |
| 抽象推理 / AGI 任务 | Claude Opus 4.6 | ARC-AGI-2 68.8% vs 52.9% |
关键总结:
- GPT-5.4 是综合性价比最高的选择,AI 综合智能指数(57 vs 53)略优,价格约为 Opus 4.6 的一半
- Claude Opus 4.6 是用户满意度全球第一(ELO 1503)的模型,在复杂代码、智能体、抽象推理上均有明显优势
- 对于大多数实际项目,Claude Sonnet 4.6 才是性价比最优解——PinchBench 排名第一,价格远低于 Opus 4.6
没有"永远最好"的模型,只有最适合你场景的模型。
🚀 立即测试:在 API易 apiyi.com 平台,你可以用一个 API Key 同时接入 GPT-5.4、Claude Opus 4.6 和 Claude Sonnet 4.6,通过实际业务数据对比三款模型的表现和成本。新用户注册即可获得测试额度,帮你在上线前做出最优决策。
本文数据来源:Anthropic 官方发布文档、OpenAI API 文档、Chatbot Arena 排行榜(2026年2月)、PinchBench 排行榜(2026年3月13日)、Artificial Analysis 模型对比、DigitalApplied 技术评测。数据随模型更新可能变化,建议以官方最新文档为准。
作者:APIYI Team | 发布于 AI123.dev