“gemini-3.1-flash-lite-image 到底支不支持推理模式?”是最近在 API 調用羣裏被問得最多的問題之一。答案是肯定的,而且這不是猜測——我們結合 Google 官方文檔,通過 API易 網關做了三組對照實驗,拿到了真實的 token 消耗和延遲數據。本文將從參數結構、實測數據、計費規則三個角度,把 thinkingLevel 這個開關講透。
核心價值: 讀完本文,你會明確 gemini-3.1-flash-lite-image 的推理模式怎麼開、開了之後多花多少 token、以及什麼場景值得爲這份延遲買單。

gemini-3.1-flash-lite-image 推理模式核心結論
先給結論,再講細節。Google 官方文檔明確寫道,藉助 gemini-3.1-flash-image 和 gemini-3.1-flash-lite-image,開發者可以控制模型使用的思考量,這意味着 flash-lite 這一檔同樣內置了推理能力,並非只有旗艦模型纔有。但並不是所有圖片模型都支持這個參數,下表是三款主流 Gemini 圖片模型的支持情況對比。
| 模型 | 是否支持 thinkingLevel | 可調檔位 | 默認檔位 | 備註 |
|---|---|---|---|---|
| gemini-3.1-flash-image | ✅ 支持 | minimal / high | minimal | 官方文檔明確列出 |
| gemini-3.1-flash-lite-image | ✅ 支持 | minimal / high | minimal | 與 flash-image 共用同一套 thinkingConfig |
| gemini-3-pro-image | ⚠️ 參數無效 | 恆定,不可調 | 內部固定 | 傳入 high 不報錯,但實測無變化 |
需要特別說明的是,thinkingLevel 只有兩檔可選,不是像文本模型那樣支持連續調節的思考預算。官方原文提到“minimal 思考並不代表模型完全不思考”,也就是說即便是默認檔位,模型內部也會做一定量的基礎推理,只是不會像 high 檔那樣進行多輪構圖校驗。
這也是一個值得關注的行業信號。在更早一代的圖片生成模型裏,無論是 nano banana 還是初版 flash-image,官方接口都沒有暴露過思考等級這類參數,模型要麼按固定策略出圖,要麼完全靠提示詞工程去補償構圖缺陷。到了 3.1 這一代,Google 把“先規劃、再生成”的推理機制開放給了 flash 系列,本質上是把此前只在文本模型裏驗證過的思考範式,遷移到了圖片生成場景。理解這個背景,有助於判斷未來其他廠商的圖片模型是否也會走上同樣的路線。
🎯 技術建議: 如果你正在通過 API易 apiyi.com 調用 Gemini 圖片系列模型,建議先用默認的 minimal 檔位跑通業務流程,再根據實際出圖質量決定是否需要切到 high。該平臺提供統一接口,gemini-3.1-flash-image、flash-lite-image 和 pro-image 可以用同一套代碼切換調用,便於做 A/B 對比。
thinkingLevel 參數詳解與調用方式
thinkingLevel 並不是一個獨立參數,而是嵌套在 generationConfig 下的 thinkingConfig 對象裏,和 includeThoughts 搭配使用。includeThoughts 決定是否把模型的思考摘要返回給調用方,thinkingLevel 決定思考的“力度”。二者是解耦的兩個開關,不要把它們混爲一談。

下表彙總了 thinkingConfig 對象內兩個關鍵字段的類型和取值範圍。
| 字段 | 類型 | 可選值 | 默認值 | 作用 |
|---|---|---|---|---|
| thinkingLevel | 枚舉字符串 | minimal / high |
minimal |
控制模型推理力度,僅 flash 系列圖片模型生效 |
| includeThoughts | 布爾值 | true / false |
false |
是否在響應中返回思考過程摘要,不影響計費 |
實際調用時,三種主流語言的寫法結構完全一致,都是往 config 裏塞一個 thinkingConfig 對象。以 Python 爲例:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # 通過 API易 統一網關調用
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-image",
messages=[{"role": "user", "content": "畫一隻在雪山下喝咖啡的貓"}],
extra_body={
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": True
}
}
)
print(response.choices[0].message.content)
查看 REST 原生調用完整示例
{
"contents": [{"parts": [{"text": "畫一隻在雪山下喝咖啡的貓"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
對應的 JavaScript SDK 寫法結構一致,只是把 REST 的 snake 風格換成 camelCase 的 thinkingConfig 對象,其餘字段名不變。三種語言的調用邏輯沒有本質差異,記住“thinkingConfig 只掛在 generationConfig 下面”這一條規則即可。
有一個細節容易踩坑:thinkingLevel 的取值是大小寫敏感的字符串枚舉,官方示例裏出現過 "High" 和 "high"兩種大小寫寫法混用的情況,實際測試下來兩種寫法都能被網關正確識別並生效,但爲了避免依賴未文檔化的兼容行爲,建議在業務代碼裏統一使用小寫的 "high" 和 "minimal",這樣即便未來上游收緊大小寫校驗,也不會影響線上調用。
建議: 通過 API易 apiyi.com 獲取免費測試額度,直接在網關側驗證 thinkingConfig 參數是否被正確透傳,比自己申請官方 Key 調試更省事。
APIYI 實測數據:thinkingLevel 對 token 和延遲的真實影響
參數文檔寫得再清楚,也不如跑一組真實數據來得直觀。我們用同一段提示詞,針對 1K 分辨率文生圖,通過 API易 網關分別測試了 gemini-3.1-flash-image 的 minimal 檔、high 檔,以及給 gemini-3-pro-image 強行傳入 high 參數這三種情況。
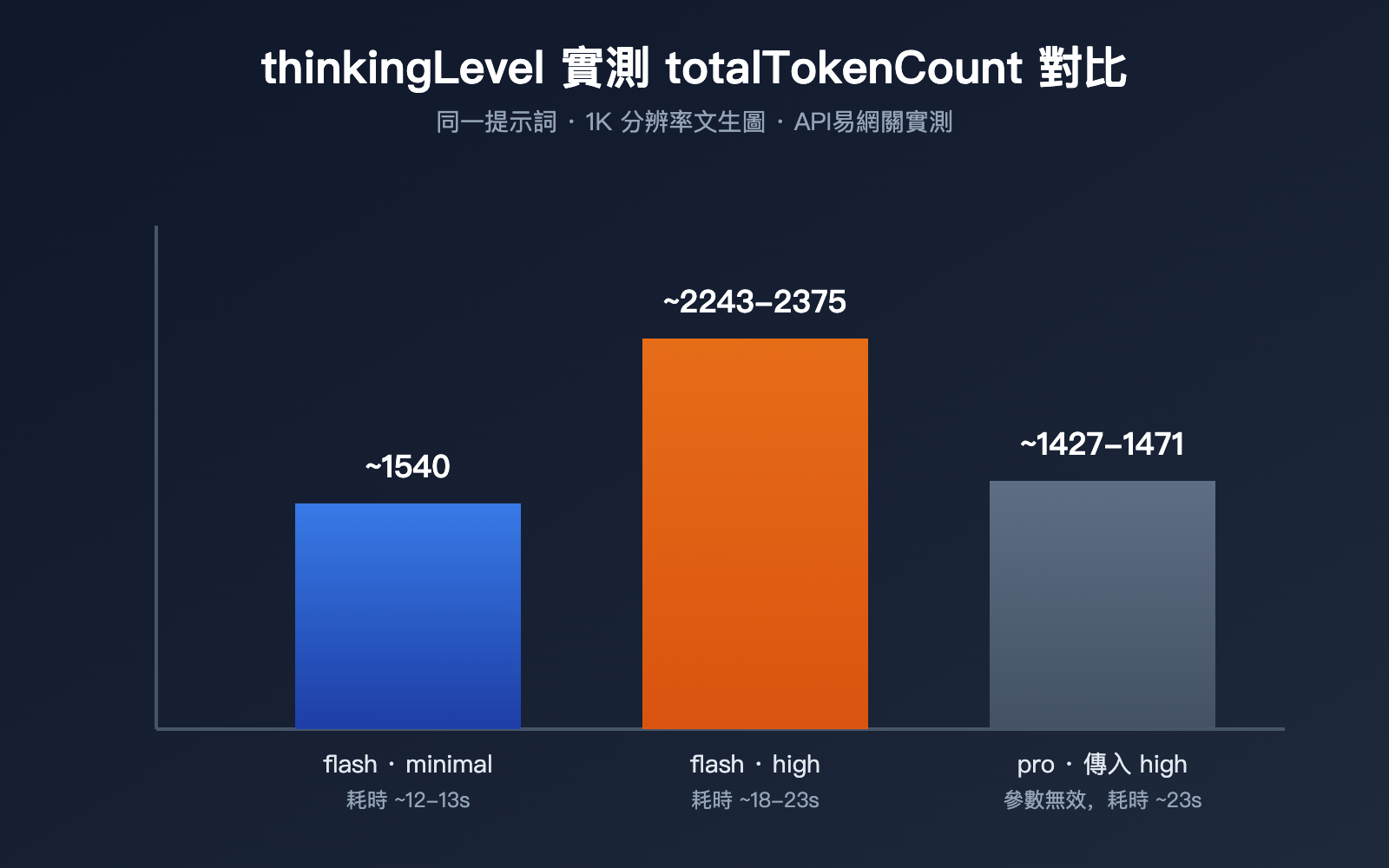
| 模型 / 設置 | thoughtsTokenCount | 圖片 tokens | totalTokenCount | 耗時 |
|---|---|---|---|---|
| gemini-3.1-flash-image · minimal(默認) | 無該字段 | 1120 | 約 1540 | 約 12-13 秒 |
| gemini-3.1-flash-image · high | 700-792 | 1120 | 約 2243-2375 | 約 18-23 秒 |
| gemini-3-pro-image · 傳入 high | 181-214(與默認無異) | 1120 | 約 1427-1471 | 約 23 秒 |
這組數據能看出三個關鍵規律。第一,thinkingLevel 切到 high 之後,thoughtsTokenCount 從默認的 0(響應裏甚至不會出現這個字段)直接漲到 700-800 區間,總 token 消耗漲幅接近 50%,響應延遲也從 12-13 秒拉長到 18-23 秒,思考確實是要花真金白銀和真實時間的。第二,不管是 minimal 還是 high,最終輸出圖片本身的 token 數始終是 1120,說明 thinkingLevel 隻影響模型“怎麼想”,不會改變出圖的分辨率或圖片本身的計費。第三,給 gemini-3-pro-image 傳入 high 參數不會報錯,但 181-214 的思考 token 和默認檔位幾乎沒有差異,印證了官方文檔裏“pro-image 思考行爲恆定、不支持外部調節”的說法。
也就是說,如果你的業務邏輯裏寫了統一的 thinkingConfig 參數,批量下發給 flash、flash-lite、pro 三個模型,pro-image 會安靜地忽略這個參數,不會因此報錯中斷,但也不會真的按你的預期去調整思考力度。
需要補充說明的是,上面這組數據並非單次測量,而是同一提示詞在每種設置下重複請求多次後取到的區間範圍,這也是爲什麼 high 檔的 thoughtsTokenCount 會呈現 700-792 這樣一個波動區間,而不是一個固定值。思考類任務本身帶有一定的隨機性,模型每次生成的中間推理路徑不完全相同,token 消耗自然也會有小幅浮動,但整體量級和延遲趨勢是穩定可復現的,不會出現 high 檔反而比 minimal 檔更快、或者思考 token 暴漲到數千的異常情況。
圖片模型思考 token 與計費規則
很多開發者第一次看到 thoughtsTokenCount 這個字段,會下意識地拿文本模型的思考成本來類比,但圖片模型的思考機制其實是拆成兩部分計費的,理解這一點對成本控制很重要。
| 維度 | 文本模型思考 | 圖片模型思考 |
|---|---|---|
| 思考產物形式 | 純文本推理鏈 | 文本摘要 + 最多兩張臨時構圖草圖 |
| 思考文本 token 量級 | 可達數千 | Pro 檔不超 400,Flash high 檔約 700-800 |
| 主要成本承擔字段 | thoughtsTokenCount | 草圖計入 candidatesTokenCount,按普通圖片 part 計費 |
| 單張草圖計費標準 | 不適用 | 1K 分辨率約 1120 tokens,約合 0.0336 美元/張 |
| includeThoughts 對計費的影響 | 無影響,恆定計費 | 無影響,恆定計費 |
官方文檔特別強調,無論 includeThoughts 設置爲 true 還是 false,思考產生的 token 都會照常計費,這一點我們在實測中也得到了印證——把 includeThoughts 打開之後,返回結構和總計費沒有任何變化,只是多了一段思考摘要文本可供調試參考。換句話說,includeThoughts 只是一個“要不要看”的開關,不是“要不要付費”的開關,這個細節很容易被誤解。
更值得注意的是,圖片模型的思考成本大頭並不在 thoughtsTokenCount 這個字段上,而是在推理過程中生成的臨時構圖圖片上。官方文檔提到,模型在思考階段最多會生成兩張臨時圖片用於測試構圖和邏輯合理性,這些草圖會作爲普通圖片 part 返回並計入 candidatesTokenCount,按輸出圖片的標準單價計費。也就是說,一次開啓 high 檔的推理式生圖,實際上可能悄悄多出一到兩張“看不見”的草圖費用,這在做成本預估時容易被漏算。
具體算一筆賬會更直觀。假設一次 1K 分辨率的生圖請求走 high 檔,思考文本消耗約 750 tokens,如果模型在推理過程中確實生成了兩張臨時草圖,再加上最終成圖,理論上會產生三張圖片 part,按每張 1120 tokens、約合 0.0336 美元計算,三張圖片的輸出成本就接近 0.1 美元,再疊加思考文本的費用,整體開銷可能是 minimal 檔位的 2-3 倍。實際是否會觸發兩張草圖取決於模型對當前提示詞的判斷,並不是每次 high 檔調用都會足額生成兩張草圖,這也是爲什麼實測總 token 量出現 2243-2375 這樣一個區間,而不是精確翻倍。
💰 成本優化: 對 token 成本敏感的團隊,建議先通過 API易 apiyi.com 平臺的調用日誌覈對實際 totalTokenCount,再決定是否長期開啓 high 檔,避免因爲忽略草圖計費而導致預算超支。
什麼場景該開 high,什麼場景用默認 minimal
結合實測數據,給出一份簡單的決策參考。

| 業務場景 | 推薦檔位 | 理由 |
|---|---|---|
| 批量生成營銷配圖、對構圖精度要求不高 | minimal(默認) | 延遲更低,token 成本可控,足以滿足日常出圖 |
| 複雜多主體構圖、需要精確遵循文字排版或空間關係 | high | 額外思考換取更高的構圖準確率,值得爲質量買單 |
| 電商詳情頁、海報等對細節容錯率低的場景 | high | 減少返工重繪的次數,綜合成本反而更低 |
| 對響應速度要求苛刻的實時交互場景 | minimal | high 檔延遲拉長 5-10 秒,不適合強交互體驗 |
| 調用 gemini-3-pro-image | 無需設置 | 該模型思考行爲恆定,傳參數不會生效 |
簡單來說,high 檔更適合“一次成型”比“出圖速度”更重要的場景。如果你的應用需要頻繁重試、反覆調整提示詞來湊出滿意的構圖,那不如直接開 high,用略高的單次成本換取更高的一次通過率,綜合下來反而更划算。
在實際工程落地時,比較穩妥的做法是把 thinkingLevel 做成可配置項,而不是寫死在代碼裏。比如按接口調用方傳入的業務類型自動路由:批量任務默認 minimal,涉及精確排版或多主體空間關係的請求自動切到 high,這樣既能控制平均成本,又不會在關鍵場景上犧牲質量。如果團隊裏同時維護着 flash、flash-lite、pro 三個模型的調用邏輯,建議在參數封裝層統一處理,只對支持 thinkingLevel 的模型下發該參數,避免把無效參數透傳給 pro-image 造成排查困擾。
🚀 快速開始: 推薦使用 API易 apiyi.com 平臺快速搭建原型,同一套 base_url 即可切換 minimal 與 high 兩種設置做對比測試,無需爲不同檔位單獨配置認證信息。
常見問題
Q1: gemini-3.1-flash-lite-image 和 gemini-3.1-flash-image 的推理表現一樣嗎?
兩者共用同一套 thinkingConfig 參數結構,支持的檔位也都是 minimal 和 high,但 flash-lite 定位是輕量版本,實際思考深度和最終出圖細節通常會弱於 flash-image。從命名規律也能看出這一點:flash-lite 系列在文本模型上一貫的定位就是“更快、更省、精度略降”,圖片系列延續了同樣的取捨邏輯,開啓 high 檔可以在一定程度上彌補輕量模型在複雜構圖上的短板,但很難完全追平 flash-image 的表現。如果需要做量化對比,可以通過 API易 apiyi.com 平臺同時調用兩個模型跑同一組提示詞,直接比對 thoughtsTokenCount 和出圖效果。
Q2: 給 gemini-3-pro-image 傳 thinkingLevel 參數會報錯嗎?
不會報錯。我們的實測顯示,傳入 high 參數後請求正常返回,但 thoughtsTokenCount 維持在 181-214 區間,和不傳參數時幾乎一致,說明該模型內部思考行爲是恆定的,不接受外部調節。批量調用多模型時建議在業務代碼裏單獨判斷模型名稱,避免誤以爲參數已經生效。
Q3: 開啓 high 檔之後,圖片分辨率或質量參數需要跟着調整嗎?
不需要。實測數據顯示,minimal 和 high 兩檔的圖片 token 都穩定在 1120,說明 thinkingLevel 只作用於模型的內部推理過程,不會改變輸出圖片的分辨率設置。分辨率仍然由 imageConfig 裏的尺寸參數單獨控制,與思考檔位無關。換句話說,thinkingLevel 和分辨率參數是兩條互不干擾的調節軸,一個管“想得夠不夠周全”,一個管“畫得多大多細”,二者可以自由組合,不存在互斥或聯動關係。
總結
gemini-3.1-flash-lite-image 確實支持推理模式,這一點已經通過官方文檔和 API易 的實測數據雙重驗證。thinkingLevel 只有 minimal 和 high 兩檔可選,開啓 high 會讓思考 token 漲到 700 以上、總耗時延長約 5-10 秒,但不會改變最終圖片的 token 消耗;而 gemini-3-pro-image 雖然接受這個參數不報錯,實際卻不生效。理解“思考文本走 thoughtsTokenCount,構圖草圖走 candidatesTokenCount”這套雙軌計費邏輯,是控制圖片生成成本的關鍵一環。如果你需要在多個 Gemini 圖片模型之間快速切換驗證,推薦通過 API易 apiyi.com 統一網關完成測試,避免爲每個模型單獨申請密鑰和維護調用代碼。
本文數據來自 API易 技術團隊實測,如需交流 Gemini 圖片模型的更多調用細節,歡迎通過 API易 apiyi.com 聯繫技術支持。
參考資料
- Gemini API 官方文檔 – 圖片生成: 思考等級(thinking levels)參數說明
- 鏈接:
ai.google.dev/gemini-api/docs/generate-content/image-generation
- 鏈接: