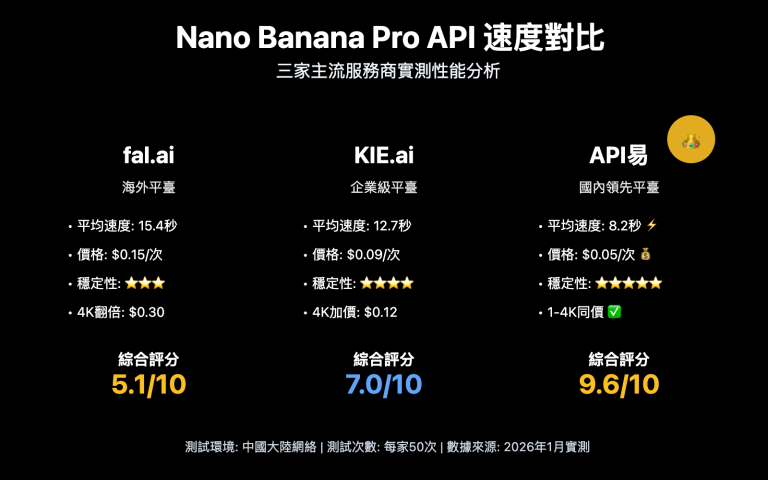
很多設計師和開發者在使用 gpt-image-2 時都會問同一個問題:能不能直接生成 PSD 分層文件? 答案分爲兩層 —— ChatGPT 網頁版藉助 Adobe Photoshop 集成可以做到分層編輯,而 gpt-image-2 API 本身只能輸出常規的 PNG/JPEG/WEBP 格式。
本文將徹底釐清 gpt-image-2 輸出 PSD 的真實能力邊界,提供 3 種切實可行的工作流方案,幫你根據實際場景選擇最合適的路徑。無論你是個人創作者還是團隊開發者,都能在本文中找到對應的解決思路。

gpt-image-2 輸出 PSD 的核心認知
在動手之前,必須先理清一個關鍵事實:gpt-image-2 是一個圖像生成模型,不是圖像編輯軟件。它本身不具備生成"分層文件"的能力,任何 PSD 輸出都需要藉助外部工具配合完成。
輸出能力的本質差異
OpenAI 官方對 gpt-image 系列的輸出格式定義非常明確,模型只支持 3 種柵格化(rasterized)圖像格式:
| 輸出格式 | 文件擴展名 | 是否分層 | 透明通道 | 典型場景 |
|---|---|---|---|---|
| PNG | .png |
❌ 單圖層 | ✅ 支持 | 默認格式,適合需要透明背景的素材 |
| JPEG | .jpg |
❌ 單圖層 | ❌ 不支持 | 文件體積小,適合攝影類圖片 |
| WEBP | .webp |
❌ 單圖層 | ✅ 支持 | 現代 Web 格式,體積/質量平衡好 |
| PSD | .psd |
✅ 多圖層 | ✅ 支持 | API 不支持,需後處理 |
🎯 核心結論: gpt-image-2 API 通過
output_format參數僅接受png、jpeg、webp三個值,沒有任何參數可以讓它直接吐出 PSD 文件。如果你需要在企業項目中穩定調用 gpt-image-2,可以通過 API易 apiyi.com 中轉服務統一接入,該平臺兼容 OpenAI 官方接口規範,支持上述三種輸出格式的全量參數。
爲什麼 API 無法直接輸出 PSD
PSD 是 Adobe Photoshop 的私有分層格式,包含圖層、蒙版、混合模式、調整圖層等複雜結構。要生成真正的 PSD,需要的不是圖像生成模型,而是圖像編輯引擎。這也是爲什麼:
- gpt-image-2 API: 一次性扁平柵格圖,無法理解"圖層"概念
- ChatGPT 網頁版: 藉助 Adobe Photoshop 應用集成,實際由 Photoshop 完成分層
這兩者完全是兩套體系,本文後續會分別講解。

gpt-image-2 輸出 PSD 的 3 種方案對比
針對"我就是要 PSD 文件"的需求,目前有 3 條可行路徑,各自適用不同場景。下表是核心特徵對比:
| 方案 | 實現方式 | PSD 真實分層 | 自動化程度 | 適用人羣 |
|---|---|---|---|---|
| 方案 A: ChatGPT + Photoshop 集成 | 網頁版調用 Adobe 插件 | ✅ 是 | 半自動 | 個人設計師、輕量需求 |
| 方案 B: API 生成 + Photoshop 手動轉 | 先調 API 出 PNG,再人工導入 PS | ⚠️ 僞分層(單圖層) | 全人工 | 需要批量生成的開發者 |
| 方案 C: API 生成 + 第三方分層工具 | API 出圖後用腳本/AI 工具拆層 | ✅ 是(算法估測) | 全自動 | 工程化場景、流水線 |
🎯 選擇建議: 如果你只是偶爾需要一兩張分層圖,方案 A 最簡單;如果你需要在產品中嵌入圖像生成能力,通過 API易 apiyi.com 調用 gpt-image-2 API + 後端集成方案 B 或 C 是更可控的選擇。
方案 A:ChatGPT 網頁版 + Photoshop 集成實現 PSD 輸出
這是 OpenAI 官方在 2025-12 正式推出的能力。Adobe 與 OpenAI 合作將 Adobe Photoshop、Adobe Express 和 Adobe Acrobat 引入 ChatGPT,8 億用戶可以直接在對話中調用專業圖像編輯功能。
啓用 Photoshop for ChatGPT 的步驟
整個流程的關鍵是 ChatGPT 充當"綜合 Agent"的角色,將用戶的自然語言意圖分發給 gpt-image-2 生成圖片,再交給 Adobe Photoshop 應用處理圖層。
用戶輸入 → ChatGPT 解析意圖
├─ 調用 gpt-image-2 生成原圖
└─ 調用 Photoshop 應用進行分層處理
↓
輸出可下載的 PSD 文件
具體操作流程:
- 登錄 ChatGPT 網頁版(chatgpt.com),確認賬號已經升級到包含圖像功能的版本
- 在輸入框點擊 "+" → "更多" → 選擇 "Adobe Photoshop" 應用
- 輸入提示詞,例如:
使用 Adobe Photoshop 幫我生成一張夜景城市插畫,並將前景人物、中景建築、遠景天空分到不同圖層 - ChatGPT 會自動調用 gpt-image-2 生成基礎圖片
- 緊接着調用 Photoshop 應用進行分層、調整、混合操作
- 完成後,點擊對話內的下載按鈕,即可獲得帶圖層的 PSD 文件
Photoshop for ChatGPT 的能力範圍
Adobe 官方 helpx 文檔列出了集成版本支持的核心操作:
| 操作類型 | 是否支持 | 說明 |
|---|---|---|
| 局部區域調整 | ✅ | 可針對圖片特定部分調亮度、對比度 |
| 創意特效 | ✅ | Glitch、Glow 等內置濾鏡 |
| 背景模糊/替換 | ✅ | 利用 Adobe Firefly 實現 |
| 圖層分離 | ✅ | 將主體、前景、背景拆分圖層 |
| 蒙版與選區 | ⚠️ 部分 | 複雜選區仍建議在桌面版處理 |
| 智能對象 | ❌ | 不支持創建可編輯的智能對象 |
| 高級混合模式 | ❌ | 僅支持基礎混合 |
🎯 能力提示: ChatGPT 內的 Photoshop 適合輕量編輯,完整能力仍在 Photoshop 桌面版。如果你需要高頻、批量生成 PSD,通過 API易 apiyi.com 直連 gpt-image-2 API 輸出 PNG 後再交付給桌面 Photoshop 是更高效的工作流。
方案 A 的侷限性
雖然 ChatGPT + Photoshop 集成體驗流暢,但它有幾個硬性限制必須知道:
- 無法 API 化調用: 這是網頁版限定能力,沒有公開的 API 接口讓你在自己的程序中復現這個工作流
- 生成速度慢: 單次生成 + 分層處理通常需要 60-120 秒
- 可控性弱: 圖層數量、命名、順序由 ChatGPT 自行決定,不接受 prompt 強制約束
- 配額限制: 免費用戶每天可調用次數有限,Plus 用戶也有上限
這些限制決定了方案 A 適合"靈感探索"和"一次性創作",不適合穩定的生產環節。

方案 B:gpt-image-2 API + Photoshop 手動轉 PSD
如果你的需求是"用程序批量生成圖片,再人工篩選後轉成 PSD",方案 B 是最直接的選擇。這條路徑將 AI 生成與圖層加工完全解耦。
gpt-image-2 API 調用極簡示例
下面是通過 API 生成圖片的最小可運行代碼,使用 OpenAI 兼容接口:
import requests
import base64
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"model": "gpt-image-2",
"prompt": "夜晚的賽博朋克城市,霓虹燈,雨夜街道",
"size": "1024x1024",
"quality": "high",
"output_format": "png"
}
)
data = response.json()["data"][0]
image_bytes = base64.b64decode(data["b64_json"])
with open("output.png", "wb") as f:
f.write(image_bytes)
📦 完整 Python 示例(含錯誤處理、參數說明)
import os
import base64
import requests
from typing import Optional
def generate_image(
prompt: str,
output_path: str,
size: str = "1024x1024",
quality: str = "high",
output_format: str = "png",
background: Optional[str] = None
) -> dict:
"""
調用 gpt-image-2 生成圖片
Args:
prompt: 圖像描述
output_path: 輸出文件路徑
size: 1024x1024 / 1024x1536 / 1536x1024
quality: low / medium / high
output_format: png / jpeg / webp
background: transparent / opaque (僅 png/webp)
"""
api_key = os.getenv("APIYI_API_KEY")
if not api_key:
raise ValueError("請設置環境變量 APIYI_API_KEY")
payload = {
"model": "gpt-image-2",
"prompt": prompt,
"size": size,
"quality": quality,
"output_format": output_format,
}
if background:
payload["background"] = background
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
},
json=payload,
timeout=180
)
response.raise_for_status()
result = response.json()
image_data = result["data"][0]["b64_json"]
with open(output_path, "wb") as f:
f.write(base64.b64decode(image_data))
return {
"path": output_path,
"usage": result.get("usage", {}),
"size": size
}
if __name__ == "__main__":
info = generate_image(
prompt="一個未來感的城市插畫,準備做產品宣傳海報",
output_path="hero.png",
size="1536x1024",
quality="high",
background="transparent"
)
print(f"生成成功: {info}")
🎯 接入提示: 使用 API易 apiyi.com 調用 gpt-image-2 時,接口 URL 僅需將 OpenAI 官方的
api.openai.com替換爲api.apiyi.com,其他參數完全兼容,支持output_format設置 png/jpeg/webp 三種輸出。
把 PNG 導入 Photoshop 轉 PSD
拿到 API 返回的 PNG 之後,在 Photoshop 中轉成 PSD 的標準流程:
- 在 Photoshop 桌面版打開 PNG 文件 (
File → Open) - 此時圖片爲單圖層,通常顯示爲"背景"層
- 雙擊圖層解鎖,轉爲可編輯圖層
- 根據需要拆分主體:
- 使用 對象選擇工具 自動識別主體
- 使用 生成式擴展 重繪背景
- 使用 Alpha 通道 提取透明區域
- 保存爲 PSD:
File → Save As → Photoshop (.PSD)
方案 B 的真實分層能力
需要注意的是,直接從 PNG 轉 PSD 默認只有 1 個圖層。要得到真正的多圖層 PSD,你必須做額外的拆層工作。常見做法包括:
| 拆層方式 | 操作複雜度 | 分層質量 |
|---|---|---|
| 手動選區 + 複製圖層 | 高 | 極高 |
| AI 摳圖工具(Remove.bg) | 低 | 中等 |
| Photoshop 對象選擇 + 生成式填充 | 中 | 高 |
| Photoshop 神經濾鏡深度估算 | 低 | 中等(僞 3D 分層) |
gpt-image-2 輸出 PSD 時的 Prompt 工程技巧
要讓方案 B 的拆層效率最大化,在 prompt 階段就要考慮後續分層的可能性。下面是經過實踐驗證的提示詞模板:
[主題]:一張產品宣傳海報,主體是一個未來感運動鞋
[構圖要求]:
- 主體居中,佔畫面 60% 面積
- 背景使用純色或簡單漸變,便於後期摳圖
- 主體與背景有明顯色差和景深分離
- 不要在背景中加入與主體相似的元素
[輸出參數]:
- 分辨率: 1536x1024
- 背景: transparent (如果支持)
- 風格: 商業攝影質感
這種 prompt 寫法能讓生成的 PNG 在後續分層時更"友好",摳圖工具識別準確率會顯著提升。
| Prompt 關鍵詞 | 對分層的影響 |
|---|---|
pure background / solid color background |
摳圖邊緣更乾淨 |
clear subject separation |
主體與背景邊界清晰 |
centered composition |
便於自動檢測主體位置 |
studio lighting |
減少陰影投射,降低誤判 |
no overlapping elements |
避免圖層互相遮擋 |
🎯 效率提升: 對接 API易 apiyi.com 的 gpt-image-2 時,可以利用 system 級 prompt 模板預設這些約束,確保團隊所有人生成的圖片都對後續 PSD 工作流友好。
方案 C:API + 第三方分層工具自動化輸出 PSD
對於產品化場景(例如電商素材自動生成、廣告流水線),手動操作 Photoshop 不現實。這時需要引入自動化分層工具。
自動化工作流架構
[用戶輸入提示詞]
↓
[gpt-image-2 API 生成原圖]
↓
[語義分割模型識別區域] (例如 SAM、Florence)
↓
[Alpha 通道生成各圖層]
↓
[psd-tools / photoshop-python-api 寫入 PSD]
↓
[輸出多圖層 PSD 文件]
整條流水線可以全部用代碼實現,無需打開 Photoshop 客戶端。
關鍵工具組合
| 工具 | 作用 | 推薦度 |
|---|---|---|
| psd-tools (Python) | 讀寫 PSD 文件結構 | ⭐⭐⭐⭐⭐ |
| Pillow | 基礎圖像處理 | ⭐⭐⭐⭐⭐ |
| SAM (Segment Anything) | Meta 的語義分割 | ⭐⭐⭐⭐⭐ |
| rembg | 一鍵摳圖,去背景 | ⭐⭐⭐⭐ |
| MiDaS | 深度估計,分前後景 | ⭐⭐⭐⭐ |
| Photopea API | 在線 PSD 編輯 | ⭐⭐⭐ |
自動化分層示例代碼
from psd_tools import PSDImage
from psd_tools.api.layers import PixelLayer
from PIL import Image
from rembg import remove
original = Image.open("gpt_image_2_output.png")
foreground = remove(original)
background = Image.new("RGBA", original.size, (255, 255, 255, 0))
psd = PSDImage.new(mode="RGBA", size=original.size)
psd.append(PixelLayer.frompil(background, psd, "Background"))
psd.append(PixelLayer.frompil(foreground, psd, "Foreground"))
psd.save("layered_output.psd")
🎯 工程化建議: 在生產環境中,建議將"調用 gpt-image-2 → 摳圖 → 寫入 PSD"封裝爲一個微服務。通過 API易 apiyi.com 調用 gpt-image-2 API 時支持高併發和穩定計費,適合作爲圖像流水線的上游能力。
方案 C 的注意事項
- 圖層質量取決於分割模型: SAM 比 rembg 更準,但推理成本更高
- PSD 兼容性: psd-tools 生成的 PSD 在主流 Photoshop 版本中表現良好,但極少數老版本可能丟失元數據
- 批量場景的算力成本: 每張圖都跑一遍分割模型,GPU 成本會顯著提升
- 混合方案更現實: 一種取捨是 API 出圖 + 簡單背景分離 + 少量人工精修

進階:多角色分層的實戰代碼
當需要把人物、商品、文字等多個語義對象分別置於獨立圖層時,可以結合 SAM(Segment Anything Model)做更精細的分割:
📦 SAM + psd-tools 多語義對象分層完整示例
import torch
import numpy as np
from PIL import Image
from segment_anything import SamPredictor, sam_model_registry
from psd_tools import PSDImage
from psd_tools.api.layers import PixelLayer
def gpt_image_to_layered_psd(image_path: str, output_psd: str, points: list):
"""
將 gpt-image-2 輸出的 PNG 拆分爲多語義對象圖層的 PSD
Args:
image_path: gpt-image-2 生成的 PNG 路徑
output_psd: 輸出的 PSD 文件路徑
points: 要分割的對象中心點列表 [(x, y, label), ...]
"""
image = Image.open(image_path).convert("RGBA")
image_np = np.array(image)
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h.pth")
sam.to("cuda" if torch.cuda.is_available() else "cpu")
predictor = SamPredictor(sam)
predictor.set_image(image_np[:, :, :3])
psd = PSDImage.new(mode="RGBA", size=image.size)
for idx, (x, y, label) in enumerate(points):
masks, scores, _ = predictor.predict(
point_coords=np.array([[x, y]]),
point_labels=np.array([1]),
multimask_output=False
)
mask = masks[0]
layer_array = image_np.copy()
layer_array[~mask] = [0, 0, 0, 0]
layer_image = Image.fromarray(layer_array, "RGBA")
psd.append(PixelLayer.frompil(layer_image, psd, label))
background_array = image_np.copy()
background_image = Image.fromarray(background_array, "RGBA")
background_layer = PixelLayer.frompil(background_image, psd, "Background")
psd.insert(0, background_layer)
psd.save(output_psd)
print(f"✅ 已生成多圖層 PSD: {output_psd}")
if __name__ == "__main__":
gpt_image_to_layered_psd(
image_path="gpt_image_2_poster.png",
output_psd="layered_poster.psd",
points=[
(512, 400, "Subject"),
(200, 600, "ProductLeft"),
(800, 600, "ProductRight"),
]
)
通過這個流程,一張 gpt-image-2 生成的海報能被拆成 3-5 個真分層 PSD,每個圖層都可以在 Photoshop 中獨立編輯。
錯誤處理與排查
工程化場景中,gpt-image-2 調用與後續分層都可能出錯。下表彙總了高頻問題和應對方法:
| 問題現象 | 根本原因 | 解決方案 |
|---|---|---|
API 返回 invalid output_format |
誤傳了 psd 等不支持的值 |
僅使用 png/jpeg/webp |
b64_json 字段爲空 |
內容審覈攔截 | 優化 prompt,避開敏感描述 |
| 摳圖後邊緣有鋸齒 | 分割模型精度不足 | 改用 SAM + 邊緣 feather 後處理 |
| PSD 在 Photoshop 中打不開 | psd-tools 寫入元數據不完整 | 升級 psd-tools 至 1.9+ 版本 |
| 分層後圖層錯位 | RGBA 通道未對齊 | 統一畫布尺寸再寫入 |
| 調用速度慢 | 高併發被限流 | 通過 API易 apiyi.com 的多通道路由分流 |
🎯 穩定性提示: 生產環境建議在 API 調用層加入重試和降級邏輯,通過 API易 apiyi.com 中轉的請求會自動識別 OpenAI 的限流響應並支持智能切換,降低批量任務的失敗率。
gpt-image-2 輸出 PSD 的常見問答
針對實際使用中高頻出現的疑問,集中解答如下。
Q1:gpt-image-2 API 真的不能直接輸出 PSD 嗎?
確認不能。OpenAI 官方文檔明確將 output_format 參數的可選值限定爲 png、jpeg、webp 三種。任何號稱"API 直接輸出 PSD"的服務,本質上都是在它們自己的服務器上跑了方案 C 的拆層流程,再把結果包裝成 PSD 返回 —— 這不是 gpt-image-2 模型本身的能力。
🎯 認知澄清: 想要穩定接入官方原生的 gpt-image-2,可以使用 API易 apiyi.com 這類 OpenAI 官方接口兼容的中轉服務,確保參數行爲與 OpenAI 完全一致,避免被封裝層"魔改"。
Q2:ChatGPT 網頁版輸出的 PSD 是真的分層嗎?
是真的。因爲它背後是真正的 Adobe Photoshop 應用在執行編輯操作,生成的 PSD 包含真實圖層、蒙版和效果。但圖層數量和命名你無法精確控制,大多數情況下會得到 3-5 個圖層(背景、主體、前景、調整層等)。
Q3:gpt-image-2 與 gpt-image-2-all 在輸出格式上有差異嗎?
有細微差異。gpt-image-2-all 走的是 ChatGPT 網頁對等的反向通道,返回的 b64_json 字段包含 data:image/png;base64, 前綴;而 gpt-image-2 直連 OpenAI Images API,返回的是無前綴的純 base64 字符串。兩者都不支持 PSD 輸出,但底層的字符串處理代碼需要區別對待。
Q4:如果我只要透明背景的 PNG,是不是就不需要 PSD 了?
對很多場景而言確實如此。gpt-image-2 API 支持 background: "transparent" 參數,直接生成透明背景的 PNG,適用於:
- 電商商品摳圖
- Logo、圖標、貼紙素材
- UI 元素
只有當你需要後期對非主體部分也做分層調整時,才必須落到 PSD 工作流。
Q5:批量生成 PSD 的成本如何控制?
成本主要由三部分構成:
| 成本項 | gpt-image-2 API 部分 | 後處理部分 |
|---|---|---|
| 單次費用 | 約 $0.03 – $0.20/張 | 摳圖 GPU 算力 ~$0.001 |
| 時間成本 | 60-120 秒 | 5-30 秒 |
| 穩定性 | 受 OpenAI 限流影響 | 自有算力可控 |
🎯 降本策略: 大批量場景下,建議只對優質候選圖執行分層。先用 gpt-image-2 低質量參數(
quality=low)快速生成預覽圖,通過 API易 apiyi.com 的統一計費查看消耗,確認滿意後再用 high 質量重生成並進入分層流水線。
Q6:能否用 gpt-image-2 直接編輯已有的 PSD 文件?
不能。gpt-image-2 的 image edit 接口只接受 PNG/JPEG/WEBP 輸入,無法識別 PSD 內部圖層結構。如果你想"對一個 PSD 的某一層做 AI 重繪",標準做法是:
- 在 Photoshop 中導出該圖層爲 PNG(帶 Alpha)
- 用 gpt-image-2 的 edit 接口配合 mask 重繪
- 把結果作爲新圖層導回原 PSD
gpt-image-2 輸出 PSD 的行業實戰案例
不同行業對 PSD 輸出有截然不同的訴求,選擇哪種方案需要結合業務場景。下面是 3 個典型場景的工作流參考。
案例 1:電商商品海報批量生產
某跨境電商團隊每天需要生成 300+ 張商品海報。需求是:商品主體一層、背景一層、文字一層,方便運營按市場快速替換文案。
工作流設計:
- 商品上傳後,運營在後臺填寫賣點關鍵詞
- 調用 gpt-image-2 API 生成主圖(
output_format=png,background=transparent) - 用 rembg 二次確認摳圖邊緣
- 通過 psd-tools 生成 3 層結構:
- Layer 1: 商品主體(透明背景)
- Layer 2: AI 生成的場景背景
- Layer 3: 佔位文字圖層
- 設計師只需在 PSD 中修改文字層即可發佈
效率收益: 單張海報製作時間從 30 分鐘降至 2 分鐘,設計師只需做最後審覈。
🎯 場景選型: 這種重複度高的批量場景,通過 API易 apiyi.com 的 gpt-image-2 接口結合企業級計費方案,可以做到成本可預測、產能可彈性擴展。
案例 2:遊戲 UI 資產快速原型
遊戲美術團隊在原型階段需要大量"佔位用"的 UI 資產 —— 按鈕、圖標、Banner 等,要求是 PSD 格式以便後期精修。
工作流設計:
gpt-image-2 生成基礎視覺
↓
SAM 自動分割主體形狀
↓
導出多個 PNG (frame、icon、glow 等)
↓
psd-tools 整合爲分層 PSD
↓
美術在 PS 中精修最終版本
| 資產類型 | gpt-image-2 輸出 | 後處理動作 | 最終圖層數 |
|---|---|---|---|
| 按鈕 | 透明 PNG | 狀態切片(默認/懸停/按下) | 3 |
| 圖標 | 透明 PNG | 高光/陰影分離 | 2-4 |
| Banner | RGB PNG | 主體/背景/光效拆層 | 3-5 |
| 卡片 | RGB PNG | 邊框/底圖/角標拆層 | 3-4 |
案例 3:營銷內容多語言版本
廣告投放團隊需要將一張主視覺適配 10 種語言版本,核心需求是文字層獨立、圖片層固定。
關鍵操作:
- 用 gpt-image-2 生成"無文字"主視覺(prompt 中明確寫
no text、no letters) - 通過 psd-tools 創建文字圖層佔位
- 後續僅需修改文字層即可輸出 10 個語言版本
這種工作流的好處是:主視覺只生成一次,文字層完全可控,避免了 AI 生成多語言文字時常見的拼寫錯誤。
🎯 多語言提醒: gpt-image-2 在生成英文文字方面相對可靠,但生成中文、日文、韓文容易出現錯別字。建議通過 API易 apiyi.com 調用 gpt-image-2 時,在 prompt 中顯式排除文字,改由 PSD 文字層統一管理。
案例 4:漫畫與插畫分鏡輔助
插畫師在創作分鏡稿時,常用 gpt-image-2 生成草圖靈感,再回到 Photoshop 精修。這種"AI 出靈感 + 人工精修"的混合流程對圖層結構要求較高。
典型分層方案:
- 草圖層: gpt-image-2 輸出原圖,保留爲參考底層
- 線稿層: 基於草圖繪製線條
- 底色層: 塊面填充
- 陰影層: 暗部刻畫
- 高光層: 亮部點綴
- 特效層: 裝飾元素
操作要點:
1. gpt-image-2 輸出 1024x1536 豎版構圖
2. 在 Photoshop 中將該圖作爲 Layer 0(鎖定不可編輯)
3. 在其上新建 5-6 個空圖層用於繪製
4. 完成後保存爲 PSD 歸檔
這套流程讓 AI 草圖變成可繼續創作的資產,而非一次性圖片。
gpt-image-2 與其他圖像格式的對比
爲了更全面地理解 PSD 在工作流中的位置,這裏把它和其他常見輸出格式做一次橫向對比。
| 格式 | 文件大小 | 編輯友好度 | 跨軟件兼容 | 適合 gpt-image-2 後處理 |
|---|---|---|---|---|
| PNG | 中 | 低(扁平) | ✅ 極好 | ⭐⭐⭐⭐⭐ 默認首選 |
| JPEG | 小 | 極低 | ✅ 極好 | ⭐⭐⭐ 僅作爲預覽 |
| WEBP | 小 | 低 | ⚠️ Web 主導 | ⭐⭐⭐ 適合 Web 場景 |
| PSD | 大 | ✅ 極高 | ⚠️ Adobe 生態 | ⭐⭐⭐⭐ 需後處理 |
| TIFF | 極大 | 中 | ✅ 印刷主導 | ⭐⭐ 印刷場景 |
| SVG | 小 | ✅ 極高(矢量) | ✅ Web/印刷 | ❌ gpt-image-2 不支持 |
從這張表可以看出,PSD 的核心價值是"編輯友好度",這是其他格式難以替代的。如果你不需要後期編輯,PNG 通常更合適。
gpt-image-2 輸出 PSD 的最佳實踐總結
回到一開始的問題:gpt-image-2 怎麼輸出爲 PSD 文件? 經過完整梳理,核心結論可以歸納爲三點:
- API 路徑不能直接輸出 PSD: gpt-image-2 API 僅支持 PNG / JPEG / WEBP 三種柵格格式,這是模型本身的能力邊界
- ChatGPT 網頁版可以藉助 Photoshop 輸出真分層 PSD: 由 Adobe Photoshop 應用接管圖層處理,適合個人設計師的輕量需求
- 工程場景需要"API 生成 + 後處理"組合方案: 通過 SAM/rembg 等工具自動拆層,psd-tools 寫入文件,實現批量自動化
| 用戶角色 | 推薦方案 | 工具組合 |
|---|---|---|
| 個人設計師 | 方案 A | ChatGPT + Photoshop 集成 |
| 中小團隊 | 方案 B | gpt-image-2 API + 桌面 Photoshop 人工分層 |
| 企業開發者 | 方案 C | gpt-image-2 API + 自動化分層流水線 |
🎯 最終建議: 先用 ChatGPT 網頁版體驗 Photoshop 集成,理解分層流程後再決定是否搭建 API 流水線。如果確認要做工程化集成,可以通過 API易 apiyi.com 統一接入 gpt-image-2,該平臺提供國內可訪問的 OpenAI 兼容接口,支持企業級穩定性和計費透明。
希望這篇 gpt-image-2 輸出 PSD 的完整指南能幫你少走彎路。gpt-image-2 輸出 PSD 文件的真正難點不在 API,而在如何選擇合適的工作流。結合自己的體量、預算、自動化需求選擇 A/B/C 方案,通常都能在一週內跑通完整流程。
作者: APIYI 技術團隊 | apiyi.com — 企業級 AI 大模型 API 中轉服務平臺