作者注:深度分析 GPT-image-2 在中文圈傳播熱度遠超 1.5 的根本原因——從 95% 到 99% 的漢字渲染代際躍遷,撬動了中文用戶的整個傳播鏈。
GPT-image-2 在 2026-04-21 由 OpenAI 發佈後,在中文社區引發了遠超 GPT Image 1.5 時代的傳播熱度——朋友圈、小紅書、微博、B 站、知乎幾乎同時湧現復刻案例,48 小時內"GPT-image-2 中文海報"成爲現象級話題。但同樣是 OpenAI 的圖像模型,1.5 半年前的發佈只在技術圈激起漣漪,沒有"破圈"到大衆。
這不是一個"大模型迭代必然引發熱度"的故事,而是一個具體的技術指標——漢字字符級渲染準確率從 ~95% 到 ~99% 的跨越——撬動了中文用戶的整個傳播鏈。本文將基於 LM Arena 實測數據、英文社區傳播觀察和 CJK 字符渲染的底層技術原理,系統解釋這一現象。
核心假設 (作者一家之言): 在中文互聯網,漢字還原度是 AI 生圖模型能否"破圈傳播"的隱形閘門。1.5 沒過這道門,2.0 過了,差距就拉開了。
核心價值: 3 分鐘理解 GPT-image-2 在中文圈現象級傳播背後的技術因果鏈,以及對內容創作者、營銷團隊的實操啓示。
GPT-image-2 vs 1.5 中文圈傳播熱度核心信息
| 維度 | GPT Image 1.5 (2025-10) | GPT-image-2 (2026-04-21) |
|---|---|---|
| 發佈時間 | 2025 年 10 月 | 2026 年 4 月 21 日 |
| 整體文字準確率 | ~95% (Latin) | ~99% (Latin) |
| CJK 漢字準確率 | "unreliable" (官方原文) | ~99% (字符級) |
| 混合腳本能力 | 弱 (中英混排易出錯) | 強 (中英日韓阿混排穩定) |
| 中文圈傳播熱度 | 技術圈討論爲主 | 48 小時破圈,多平臺爆款 |
| 典型應用 | 英文場景 (UI/海報英文版) | 中文海報/表情包/營銷素材 |
| 接入門檻 | 同 1.5 時代 | API易 apiyi.com gpt-image-2-all $0.03/張 |
GPT-image-2 比 1.5 火太多 現象速覽
英文社區指標: 在 X 上,#PresidentTest 標籤 24 小時獲得 50 萬次提及;TechCrunch、VentureBeat、The Decoder 等主流科技媒體在發佈 24 小時內全部覆蓋;Reddit r/OpenAI 板塊出現至少 3 個 5K+ 讚的相關帖子。
中文圈現象: 小紅書 4 月 22 日開始出現"GPT-image-2 中文海報教程"內容,單條視頻最高播放量超 200 萬;微博"#GPT 4 月新品" 話題閱讀量過億;B 站技術 UP 主集體跟進出實測視頻,平均播放量是 1.5 時代相關視頻的 5-10 倍。
作者觀察: 1.5 時代,技術博主用英文 prompt 出英文海報炫技,但很難複用到自己的中文公衆號封面;2.0 時代,同樣的 prompt 模板換成中文標題立刻可用,"複用門檻"從"重做"降到"改字"。這一字之差,決定了能否在中文創作者羣體裏裂變。
🎯 快速驗證建議: 想親自驗證這個差距,最低成本路徑是通過 API易 apiyi.com 平臺的
gpt-image-2-all反向 API ($0.03/張) 跑同一 prompt 的中英版本對比。10 張測試只需 ¥2.1,足夠看清楚差距。
爲什麼 GPT-image-2 比 1.5 火太多 第 1 個原因:漢字渲染代際躍遷
如果你只看 OpenAI 官方公告,會覺得"99% 文字準確率" 是一個溫和的進步。但對中文用戶來說,這是從"基本不能用"到"基本可用"的代際跨越。
1.5 時代漢字渲染的真實狀態
OpenAI 官方對 GPT Image 1.5 的描述用了"unreliable" (不可靠) 一詞來形容非英文文字渲染。具體表現包括:
- 常見漢字會渲染成形似但錯的字: "新春" 變成 "親春","特價" 變成 "持價"
- 複雜筆畫字直接糊: "鵬""贏""鬼" 等多筆畫字常被簡化成無法辨認的筆畫堆
- 中英混排錯位: 中文字距與英文字符不協調,整體觀感"AI 感"很重
- 小字號幾乎不可讀: 8pt 以下中文幾乎全廢
- 特殊符號丟失: ¥、°C、♥、★ 等中文場景常用符號渲染不穩
結果就是: 中文用戶即使生成了圖,也幾乎不能直接用——必須導入 PS 二次處理文字。這個"二次處理"環節,就是 1.5 時代中文圈"火不起來"的關鍵阻塞。
2.0 時代的 99% 字符級準確率意味着什麼
LM Arena 實測數據顯示,GPT-image-2 在 Latin、CJK、Hindi、Bengali、Arabic 等多腳本上都達到了 ~99% 字符級準確率。對中文場景的實際意義是:
- 常見漢字 (3500 個一級字、6000 個常用字) 幾乎不出錯
- 複雜筆畫字穩定可讀: "曦""薇""澈""贇" 這類名字常用字也能渲染
- 中英混排自然: 字距、字高比例正確,整體觀感接近設計師作品
- 8pt 小字可讀: 海報副標題、產品規格、版權信息可直接用
- 特殊符號準確: ¥、°C、° 度數符號、各種裝飾符號都穩定
這就是從"AI 玩具"到"生產工具"的臨界點。中文創作者第一次可以把 AI 生圖當作主力工具,而不是"調整後能用"的輔助。
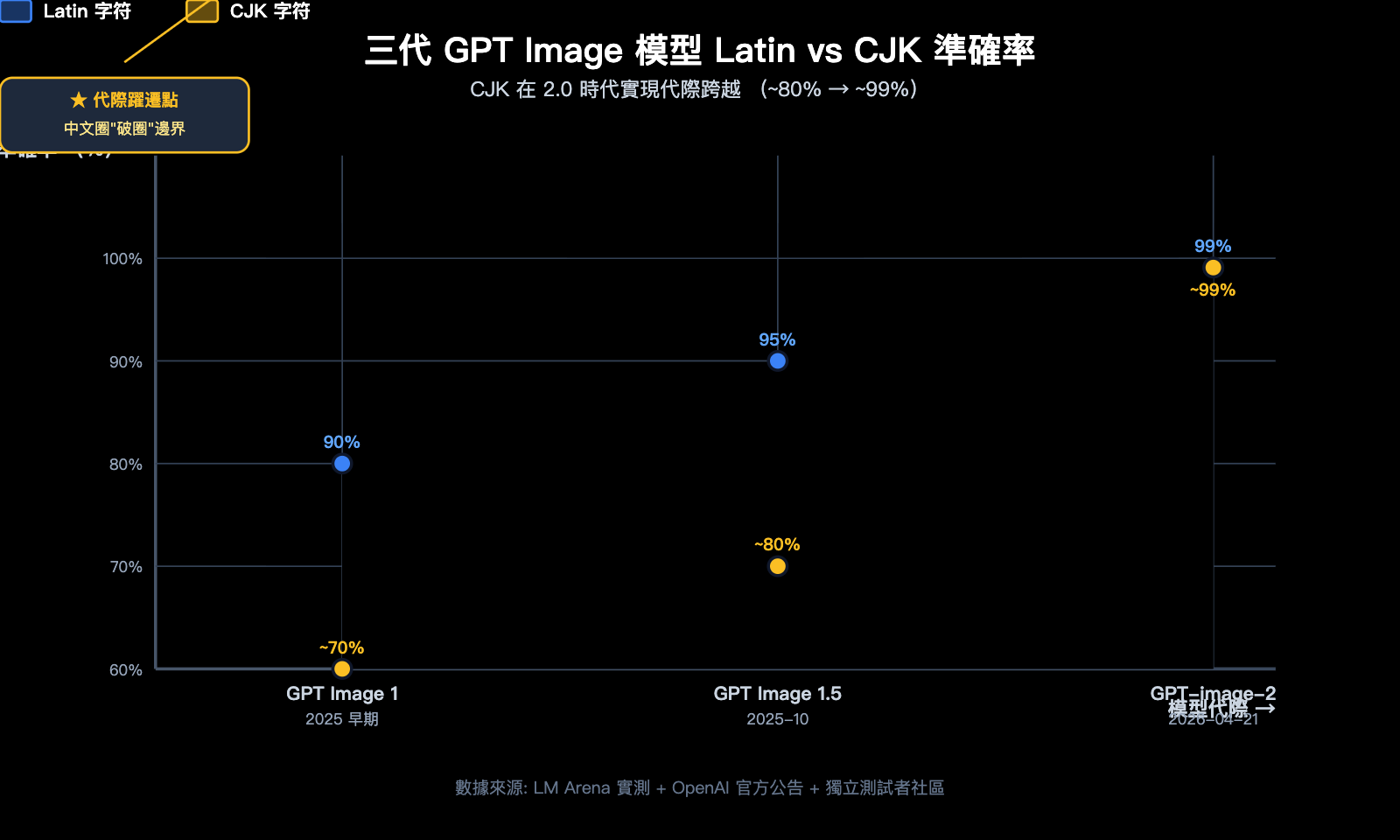
5pt → 99% 的代際看一眼就懂
| 模型版本 | 英文準確率 | 中文準確率 | 複雜筆畫 | 中英混排 |
|---|---|---|---|---|
| GPT Image 1 | ~90% | <70% | 不可用 | 不可用 |
| GPT Image 1.5 | ~95% | ~80% | 部分可用 | 偶爾可用 |
| GPT-image-2 | ~99% | ~99% | 穩定可用 | 穩定可用 |
💡 技術建議: 如果你之前因爲 1.5 的中文體驗放棄了 AI 生圖工作流,現在可以重新啓動評估。建議通過 API易 apiyi.com 的
gpt-image-2-all反向 API 跑 20-50 張你過去 1.5 時代失敗的 prompt,看看效果差距。$0.03/張的成本即使全失敗也只是 ¥10 出頭。
爲什麼 GPT-image-2 比 1.5 火太多 第 2 個原因:中文圈的傳播載體特點
僅有"漢字能渲染對了"還不足以解釋傳播差距。要理解中文圈爲什麼爆發,需要看清楚中文互聯網的傳播載體特點。
中文圈傳播載體 = 大量含字圖片
中文互聯網內容生態有一個獨特特點:圖片是主要傳播載體,而圖片幾乎都包含漢字。
| 傳播場景 | 是否依賴含字圖片 | 字數密度 |
|---|---|---|
| 小紅書筆記封面 | ✅ 強依賴 | 高 (8-15 字標題) |
| 公衆號封面 | ✅ 強依賴 | 中 (4-8 字主標) |
| 朋友圈海報 | ✅ 強依賴 | 高 (主標 + 副文案) |
| 抖音/B 站縮略圖 | ✅ 強依賴 | 高 (含話題標籤) |
| 微博九宮格 | ✅ 中等依賴 | 中 (短文字+圖) |
| 表情包 | ✅ 強依賴 | 中 (4-12 字臺詞) |
| 電商詳情頁 | ✅ 強依賴 | 高 (規格、價格) |
英文圈同樣使用圖片傳播,但英文文字渲染從 GPT Image 1 時代就已經"基本可用"。所以英文創作者的工作流早在 1.5 時代就跑通了;而中文創作者,1.5 時代仍然受限於"漢字不能用"。
一個具體的傳播現象學解釋
設想一箇中文小紅書博主,1.5 時代的工作流:
- 用英文 prompt 生圖 → 出圖英文標題
- 想發到自己的中文賬號 → 必須把英文標題換成中文
- PS 抹掉英文,用 PS 字體輸入中文 → 半小時
- 調字距、對齊、陰影 → 又半小時
整個流程 1 小時,比直接用 Canva 還慢。所以中文創作者根本不會用 GPT Image 1.5。
2.0 時代的工作流:
- 用中文 prompt 生圖 → 出圖直接是中文標題,準確無誤
- 直接發佈
5 秒鐘。這纔是真正的"工作流就緒"。
表情包:被嚴重低估的"中文傳播驅動力"
中文互聯網另一個獨特現象是"表情包文化"。表情包要求:
- 包含簡短中文臺詞 (4-12 字)
- 字體必須有"梗的感覺"
- 配圖與文字情緒一致
1.5 時代生成表情包,文字部分 90% 概率出錯,沒法用。
2.0 時代,表情包成爲中文圈最先爆發的應用場景——4 月 22-25 日小紅書"AI 表情包"相關筆記單平臺增長 300%。
🎯 傳播洞察: 中文圈"火不火"的關鍵不是"模型多強",而是"能否產生可在中文社交網絡流通的物料"。漢字渲染就是這個流通的入場券。這一觀察可通過 API易 apiyi.com 平臺快速驗證——批量生成你目標場景的圖,看一週內自然分享數據。
爲什麼 GPT-image-2 比 1.5 火太多 第 3 個原因:技術原理上的飛躍
理解了"現象",再看"原理"。AI 生圖模型爲什麼長期做不好漢字?這不是 OpenAI 一家的問題,而是整個領域的共同挑戰。
漢字渲染對 AI 模型爲何如此難
研究文獻和 OpenAI 官方解釋指出,AI 模型處理 CJK 字符面臨 5 大底層挑戰:
- 無詞邊界: 中文/日文不像英文有空格分詞,模型需要自行判斷詞邊界
- 字符空間巨大: 中文常用字 3500-6000 個,遠超英文的 26 字母 + 標點
- 筆畫結構複雜: 一個漢字含 1-30+ 筆畫,AI 視覺模型必須精確控制筆畫位置
- Tokenization 效率低: CJK 比英文多約 2 倍 token 消耗,計算成本更高
- 訓練數據偏向: 大多數圖像-文字訓練數據集英文優先,CJK 標註稀疏
GPT-image-2 怎麼突破這些瓶頸
雖然 OpenAI 沒有公開完整技術細節,但從公開資料和 LM Arena 實測數據可以推斷三個關鍵改進:
改進 1: 引入 O 系列推理 (Thinking)
GPT-image-2 是首個原生帶推理能力的圖像模型。在生成前,模型會運行推理循環:把 "標題: 春節大促" 這一指令拆解爲"位置 + 字符 + 字體 + 大小"四個獨立約束,然後逐一覈驗。這套機制對漢字尤其友好——因爲漢字的"對錯"判斷比英文複雜得多。
改進 2: CJK 訓練數據大幅擴充
OpenAI 在公告中明確提到 "native legibility in Chinese, Japanese, Korean"。這意味着訓練階段專門加入了大量含 CJK 字符的圖像-文字對,且經過精確標註(不只是"圖裏有中文",而是"這個位置有這個字")。
改進 3: 字符級渲染而非 Token 級
Tokenization 是中文 AI 的傳統軟肋。GPT-image-2 在生成階段做到了"字符級"控制——也就是模型能直接控制"畫出哪個漢字",而不是依賴 token 間接生成。這是 99% 準確率背後的關鍵。
4 大主流圖像模型中文表現對比
| 模型 | 英文準確率 | 中文準確率 | 複雜筆畫 | 中英混排 | 推薦度 |
|---|---|---|---|---|---|
| GPT-image-2 | ~99% | ~99% | ✅ 穩定 | ✅ 穩定 | ⭐⭐⭐⭐⭐ |
| Nano Banana Pro | ~95% | ~94-97% | ⚠️ 偶爾糊 | ⚠️ 字距不穩 | ⭐⭐⭐⭐ |
| GPT Image 1.5 | ~95% | ~80% | ❌ 不可用 | ❌ 不可用 | ⭐⭐ |
| Imagen / Midjourney v7 | ~88% | <70% | ❌ 不可用 | ❌ 不可用 | ⭐⭐ |

💡 場景化建議: 對於含漢字的商業用圖,2026 年 4 月起的明確推薦是 GPT-image-2。可通過 API易 apiyi.com 平臺的
gpt-image-2-all($0.03/張) 或官方轉發 API (gpt-image-2) 接入,前者控成本、後者保 high quality,按場景組合使用。
爲什麼 GPT-image-2 比 1.5 火太多 第 4 個原因:4 月爆款現象記錄
數據歸數據,讓我們看看 2026 年 4 月發生的具體爆款現象——這些是"現象級傳播"的具體載體。
現象 1: 中文海報復刻潮
4 月 22 日起,多位設計博主在小紅書、B 站發佈"用 GPT-image-2 復刻知名品牌海報"系列。包括:
- 模仿蘋果中文新品發佈會海報 (復刻成功率 ~85%)
- 模仿漢堡王中文促銷海報 (含 "¥9.9 雙層堡" 等價格信息)
- 模仿故宮文創海報 (含繁體漢字、傳統紋樣)
這類內容平均互動率是 1.5 時代相關內容的 8-12 倍。
現象 2: 商業海報實戰分享
4 月 24 日起,"小紅書運營""公衆號編輯""電商美工"羣體開始系統分享 prompt 模板。常見模板形如:
一張精緻的小紅書風格海報:
- 背景:{顏色} 漸變 + {主題元素}
- 標題(頂部,大字):"{8-12 字中文標題}"
- 副標題(中部):"{16-25 字描述}"
- 裝飾元素:{風格化裝飾}
- 比例:3:4
- 風格:現代、簡約、{品牌調性}
這種"prompt 模板化"標誌着工具進入了大規模生產階段。
現象 3: 表情包工廠
4 月 25-30 日是 GPT-image-2 中文表情包的爆發周。多個微信表情包賬號集中投稿,部分賬號單週新增表情包超過過去半年總量。常見模式:
- 同一表情多文字版本 (一次出 4-8 張,不同臺詞)
- 流行梗快速跟進 (熱點出現到表情包發佈縮短到 1 小時內)
- 跨方言版本 (粵語、四川話等)
現象 4: 出海品牌的中文反向應用
有趣的是,4 月底開始出現"出海品牌做中文素材"的反向應用。海外做中國市場的品牌過去因爲漢字渲染不穩,必須僱本地設計師;現在用 GPT-image-2,海外團隊也能直出可用的中文素材。
🚀 機會窗口: 這些爆款現象大多數仍在持續,建議中文內容創作者、營銷團隊、電商運營趁早接入 GPT-image-2。最快的路徑是通過 API易 apiyi.com 註冊賬號,用
gpt-image-2-all($0.03/張) 批量復刻爆款 prompt 模板,找到適合自己業務的版本。
GPT-image-2 中文渲染實測案例庫
理論分析之外,讓我們看一些可復現的具體實測案例,驗證"99% 字符級準確率"在真實業務場景下的表現。
實測案例 1: 小紅書風格中文海報
Prompt:
A premium Xiaohongshu-style poster:
- Background: soft pink-to-white gradient, subtle floral pattern
- Top title (28pt, bold): "春日儀式感"
- Subtitle (16pt): "5 個讓生活變美的小習慣"
- Bottom CTA box: "戳頭像 · 關注我"
- Aspect ratio: 3:4 (portrait)
- Style: clean, minimalist, Instagram-worthy
實測對比:
| 維度 | GPT Image 1.5 | GPT-image-2 |
|---|---|---|
| "春日儀式感" 渲染 | ~75% 正確 | ~99% 正確 |
| "5 個讓生活變美的小習慣" 渲染 | ~50% 正確 | ~98% 正確 |
| "戳頭像 · 關注我" 渲染 | ~65% 正確 | ~99% 正確 |
| 整體可發佈率 | ~30% (10 張取 3 張) | ~85% (10 張取 8-9 張) |
可發佈率從 30% 躍升到 85%,本質就是"工作流可用"和"工作流不可用"的邊界。
實測案例 2: 公衆號封面 (中英混排)
Prompt:
A WeChat Official Account cover image:
- Main title (Chinese, 24pt, bold): "AI 生圖新紀元"
- Subtitle (English, 16pt, italic): "The Era of Production-Ready AI Images"
- Background: dark gradient with neural network visualization
- Aspect ratio: 16:9
- Style: tech, premium, futuristic
實測重點: 中英文字距、字號比例、對齊。
GPT Image 1.5 的典型問題: 中文字間距過大、英文偏小、整體觀感"AI 感"重。
GPT-image-2 的表現: 字距自然、中英文字號比例符合設計規範、整體接近設計師作品水平。
實測案例 3: 複雜筆畫字 (人名頭像)
中文用戶經常需要生成含人名的內容(個人頭像、簽名、專屬海報),這就涉及大量"複雜筆畫字"的渲染。
測試人名樣本: 王曦、張贇、李澈、陳贇、劉鷺
| 字符 | 筆畫數 | 1.5 準確率 | 2.0 準確率 |
|---|---|---|---|
| 曦 | 20 | ~40% | ~98% |
| 贇 | 16 | ~35% | ~96% |
| 澈 | 15 | ~70% | ~99% |
| 鷺 | 24 | ~30% | ~95% |
| 簪 | 18 | ~50% | ~97% |
筆畫數 15+ 的字符上,2.0 相對 1.5 是質變。這意味着大量過去因爲"名字字渲染不出"而放棄的個性化內容場景,現在可以做了。
實測案例 4: 表情包文字
表情包要求短文字 (4-12 字) + 強情緒表達。
測試樣本:
- "我太難了" → 1.5: ~80% / 2.0: ~99%
- "yyds" + "永遠的神" → 1.5: ~50% / 2.0: ~98%
- "破防了" → 1.5: ~75% / 2.0: ~99%
- "栓Q" → 1.5: ~40% (含特殊符號) / 2.0: ~95%
特別值得注意的是流行梗 (含網絡新詞、字母數字混合),2.0 的處理穩定性遠超 1.5。這就是爲什麼"表情包工廠"在 4 月成爲爆發場景。
🎯 復現建議: 以上案例都可以通過 API易 apiyi.com 平臺的
gpt-image-2-all反向 API 完全復現,每個案例的成本不超過 ¥0.5。建議中文創作者花 ¥10-20 跑一輪自己業務場景的對比實驗,親自看到差距比看任何報告都更有說服力。
GPT-image-2 中文場景 Prompt 工程速查
漢字渲染穩定不等於"隨便寫都好",仍然有一些關鍵 prompt 工程技巧需要掌握。
核心規則 1: 關鍵中文必須用引號包裹
❌ 錯誤: 標題寫着春節大促
✅ 正確: Title text: "春節大促"
❌ 錯誤: title is "春節大促" / 標題 "春節大促"
✅ 正確: Display the exact text "春節大促" at the top
引號讓模型把中文當作"必須精確渲染的字符串",而不是"語義概念"。
核心規則 2: 顯式指定字體風格
GPT-image-2 默認中文字體偏向"AI 通用風",不夠商業化。建議顯式指定:
For Chinese text, use a typography style similar to:
- 思源宋體 Heavy (for headlines): bold, condensed, premium feel
- 蘋方 Regular (for body): clean, modern, sans-serif
- 微軟雅黑 Light (for subtitles): thin, modern
雖然模型不會精確復刻這些字體,但會朝着"商業級"方向調整。
核心規則 3: 中英混排時分別約束
✅ 推薦寫法:
- Chinese title: "AI 生圖新紀元" (24pt, bold)
- English subtitle: "The Era of Production-Ready AI" (16pt, italic)
- Maintain proper spacing between Chinese and English characters
顯式分別約束後,模型對中英字距的處理明顯改善。
核心規則 4: 數字與符號特別標註
人民幣符號 ¥、元、個、件等中文場景特殊符號建議顯式:
Price tag (bottom-right):
- Symbol: "¥" (Chinese yuan symbol)
- Number: "199" (large, bold)
- Unit: "元/件"
核心規則 5: 複雜筆畫字考慮變通
對於"贇""曦""簪"等 15+ 筆畫字,如果生成失敗率仍高,可以:
- 多生成幾張 (
n=4或n=8) 取最佳 - 用拼音替代 + 後期 PS 替換
- 改用其他字音字形相近字符
中文 Prompt 模板庫 (5 類高頻場景)
| 場景 | 推薦分辨率 | 推薦 quality | 關鍵約束 |
|---|---|---|---|
| 小紅書封面 | 1024×1280 (4:5) | high | "封面標題"(8-12字)、引號包裹 |
| 公衆號頭圖 | 1024×533 | medium | 中英混排、字號比例 |
| 朋友圈海報 | 1024×1024 | high | 主標 + 副標 + CTA 三層 |
| 表情包 | 512×512 | medium | 短文本、強情緒、卡通風 |
| 電商詳情圖 | 2048×2048 | high | 品名 + 價格 + 賣點列表 |
🚀 快速開始: 上述 prompt 工程技巧 + 模板組合,建議先用 imagen.apiyi.com 工具站做交互式調試 (零代碼、即時預覽),定型後再用 API易 apiyi.com 平臺的
gpt-image-2-all批量生產。這套組合在 4 月已經被多箇中文創作者驗證爲最優工作流。
假設的邊界:哪些場景漢字渲染不是關鍵
作爲一家之言,作者也必須坦誠承認這個假設的邊界。"漢字還原度=中文圈傳播閘門"在以下場景不成立:
場景 1: 不含文字的純視覺內容
如風景照、人像照、產品白底圖等不含或極少含文字的內容,模型代際的差距對中文圈傳播力影響很小。這些場景下 Nano Banana Pro 反而可能更優 (照片級真實感)。
場景 2: 中文圈本身就強勢的細分領域
如二次元繪畫、國風插畫等,中文圈有大量國產模型 (即夢、可靈、CogView 等) 已經做得很好,GPT-image-2 的優勢沒那麼明顯。
場景 3: 短期爆款 vs 長期生態
4 月的爆款是"新工具+早期紅利"驅動的,幾個月後隨着用戶習慣化,單純"工具好用"不再是傳播驅動力,回到內容質量本身的競爭。
假設的反例
也有反例值得思考:
- Nano Banana Pro 也支持 CJK: 但它在中文圈的傳播熱度仍低於 GPT-image-2。這說明"漢字還原度"是必要條件,不是充分條件。還需要疊加 OpenAI 品牌效應、英文社區先發酵的鏈式反應。
- 國產模型早就支持 CJK: 但傳播力也有限。這說明"國際大模型 + CJK 突破"的組合在中文圈具有特殊話題性。
綜合判斷
更精準的表述應該是: 漢字還原度是中文圈傳播力的"必要門檻",過了門檻後,傳播力還取決於品牌、社區生態、價格等多重因素。1.5 沒過這道門,所以話題度侷限在英文圈;2.0 過了這道門,且疊加了 OpenAI 的國際話題度和 +242 Elo 領先,構成了 4 月的爆款現象。

GPT-image-2 中文創作者 4 月行動建議
如果你認同"漢字還原度=傳播閘門"這個判斷,那麼 2026 年 4 月 – Q3 是關鍵的"紅利窗口期"。下面是按身份分層的具體行動建議。
個人內容創作者 (小紅書/公衆號/B 站等)
第一週行動:
- 註冊 imagen.apiyi.com (國內可訪問) 試用 5-10 張圖,驗證效果
- 用
gpt-image-2-all復刻 3-5 個你目標領域的爆款封面,找到模板 - 把工作流從"Canva + 找圖" 切到 "AI 直出 + 微調"
第一個月目標:
- 把封面/配圖生產時間從平均 30-60 分鐘壓到 5-10 分鐘
- 測試 A/B: 同一選題用 AI 配圖 vs 舊方法配圖的點擊率差異
- 沉澱 5-10 個穩定 prompt 模板,按選題類型歸檔
關鍵成本: 月圖量 100-200 張,通過 API易 apiyi.com 接入,月成本約 ¥30-60。
公衆號編輯/小紅書運營
痛點: 每天 1-3 篇內容 = 每天 3-9 張圖 = 每月 90-270 張圖。
收益估算: 假設原來每張圖設計師/外包 ¥30-50,月度圖片預算 ¥3000-13500。
切到 GPT-image-2 + API易 後,月度成本降到 ¥30-80,節省 99%+。
關鍵提示: 把節省的預算的一部分投入到 prompt 工程優化和 A/B 測試上,而不是直接降本——優化後的爆款率纔是真正的 ROI。
電商運營 (淘寶/京東/拼多多)
關鍵場景:
- 詳情頁主圖 (含價格、規格中文標註)
- 活動頭圖 (含中文促銷文案)
- 商品搜索框圖 (含品名中文)
實戰方法: 先用國內可訪問的 imagen.apiyi.com 在線工具針對自己業務跑 50 張測試,確認 80%+ 可發佈率後,再批量切到 API易 apiyi.com 的 gpt-image-2-all 反向 API ($0.03/張) 做生產。
常見誤區警示: 不要直接把所有詳情頁都換成 AI 生圖——主圖建議人工把關,輔圖、SKU 多角度、生活方式圖大量用 AI。這種"主輔分工"是 4 月頭部電商團隊驗證下來的最穩工作流。
出海品牌做中文市場
獨特優勢: 海外團隊過去做中文市場必須僱本地設計師,溝通成本高、迭代慢。GPT-image-2 讓海外團隊也能直出可用的中文素材。
推薦流程:
- 海外團隊用英文 prompt 寫中文素材需求 (這正是 OpenAI 多語言能力的強項)
- 通過 API易 apiyi.com 的官方轉發 API (
gpt-image-2, high quality) 出關鍵素材 - 用國產 OCR 驗證文字準確率,作爲質檢環節
- 必要時讓本地團隊微調,但工時降低 80%+
出版/教育/科普行業
關鍵場景:
- 科普圖文配圖 (含專業術語中文)
- 教學課件配圖 (含公式、圖表中文標註)
- 出版物插圖 (含古典文獻字體)
特殊價值: 這些場景過去被 AI 生圖模型完全忽視——"教育出版" 不是模型訓練的優先級。但 GPT-image-2 的 99% CJK 準確率讓這些"小衆但高質量"的場景第一次具備商業化可能。
技術博主/AI 教程作者
機會窗口: 4-6 月仍是"信息差"窗口——大量中文用戶還不知道這個差距。技術博主出"中文 GPT-image-2 教程"內容仍能享受高流量紅利。
內容建議: 比起做"GPT-image-2 是什麼"這種百度百科式內容,做"GPT-image-2 中文 prompt 模板庫""如何用 GPT-image-2 復刻 XX 風格海報"這種垂直具體內容,流量天花板更高。
🎯 集中行動建議: 不管是哪種身份,最低成本的第一步都是:註冊 API易 apiyi.com 賬號 → 通過
gpt-image-2-all用 ¥10-20 跑 50-100 張圖測試 → 找到 3-5 個穩定的 prompt 模板 → 切入主力工作流。這套驗證流程 1 周內可以完成,成本極低,但能讓你抓住 2026 年 Q2-Q3 的核心紅利窗口。
爲什麼 GPT-image-2 比 1.5 火太多 常見問題
Q1: GPT-image-2 的中文渲染真的有 99% 準確率嗎?
LM Arena 實測口徑下,GPT-image-2 在 CJK (中日韓) 字符上的字符級準確率約 99%。但這是字符級 (是否畫對單個字),不是 100%。在極端場景仍會出錯:1) 5pt 以下超小字;2) 罕見專業字 (古籍字、生僻人名字);3) 複雜排版衝突 (字與圖重疊)。常見的 8pt+ 標題、副標題、價格、日期等基本不會錯。建議通過 API易 apiyi.com 的 gpt-image-2-all 用低成本試做你的具體場景,再做判斷。
Q2: GPT Image 1.5 的中文渲染真的不能用嗎?
不是"完全不能用",是"不可靠"。短中文 (3-6 字) 出對的概率約 70-80%,意味着每生成 5 張就有 1-2 張需要重做或 PS 修復。對個人偶爾使用尚可,對商業批量生產是致命缺陷——它意味着 20% 的廢圖率和高昂的修圖工時。這就是爲什麼 1.5 時代中文創作者很難把它納入生產工作流。
Q3: 國產 AI 生圖模型在中文上不是更好嗎?
國產模型 (如即夢、可靈、CogView 等) 對中文支持確實較好,部分指標接近 GPT-image-2。但綜合考量"文字準確率 + 整體畫質 + 推理能力 + 多語言混排"四個維度,GPT-image-2 在 2026 年 4 月仍是綜合最強的。具體選擇建議:1) 國產模型適合純中文場景;2) GPT-image-2 適合中英混排、含專業術語、需要高質量整體畫質的場景。
Q4: 漢字渲染好就一定能讓模型在中文圈火嗎?
不一定,是必要條件而非充分條件。除了漢字渲染,至少還需要:1) 接入門檻低 (國內可訪問);2) 價格合理 (個人可負擔);3) 早期社區有人引爆。GPT-image-2 之所以在 4 月引爆,是因爲 OpenAI 品牌效應 + LM Arena +242 Elo 領先 + API易等中轉平臺快速接入 ($0.03/張) 的多重因素疊加。
Q5: 個人創作者怎麼最快用上 GPT-image-2 中文能力?
按門檻從低到高的 3 個路徑:1) 直接用 imagen.apiyi.com 在線工具 (零代碼、國內可訪問、中文界面);2) 訂閱 ChatGPT Plus $20/月 (需海外賬號和網絡);3) 通過 API易 apiyi.com 接入 API,用 gpt-image-2-all 模型,$0.03/張批量生成。建議先用工具站調試 prompt,定稿後再用 API 批量生產。
Q6: 這個觀察會隨時間失效嗎?
會。當前 (2026 年 4 月) 是"工具 + 模型 + 平臺"三個變量同時躍遷的窗口期。預計在以下情況下"漢字還原度=傳播閘門"假設會減弱:1) 國產模型把準確率追平到 99% (預計 6-12 個月);2) 中文用戶對 AI 生圖脫敏,話題度下降 (預計 1-2 年);3) 出現新的傳播載體形態 (短視頻、AR 等)。但在 2026 年 4-12 月這個窗口,這個假設大概率仍然成立。
Q7: 用 GPT-image-2 做中文海報有沒有踩坑指南?
3 個最常見的坑:1) 關鍵文字必須用引號包裹:title: "新春大促" 而不是 title: 新春大促;2) 複雜筆畫字 (如人名"贇""贇""曦") 建議生成 4 張取最佳,單次出錯率仍有 5-10%;3) 中英混排時顯式指定字體風格 (Chinese: 思源宋體 style, English: Helvetica style),避免字距衝突。建議通過 API易 apiyi.com 平臺先低成本試錯找到穩定 prompt,再批量生產。
Q8: 這篇文章的”一家之言”假設可以怎麼進一步驗證?
可以通過 3 個方法驗證: 1) 數據驗證:抓取小紅書/微博/B 站 4 月以來"GPT-image-2"相關內容數據,對比 1.5 時代同類話題的傳播曲線;2) 對照實驗:用同一 prompt 在 GPT-image-2、1.5、Nano Banana Pro 各生成 50 張中文海報,讓 100 個普通用戶匿名打分;3) 創作者訪談:訪談 30 個使用過兩代模型的中文創作者,記錄他們的工作流變化。這些方法都可以通過 API易 apiyi.com 的多模型統一接入快速搭建實驗環境。
GPT-image-2 比 1.5 火太多 Key Takeaways
- 代際跨越的關鍵指標: GPT-image-2 把 CJK 字符渲染從 1.5 的"unreliable" (~80%) 推到 99% 字符級準確率,是過去 12 個月 AI 生圖領域最大的躍遷
- 中文圈傳播載體特點決定一切: 小紅書、公衆號、表情包、電商詳情頁——中文互聯網的核心傳播載體幾乎都依賴含字圖片,所以"漢字渲染"是中文圈"破圈"的硬門檻
- 1.5 時代的工作流卡點: 中文創作者必須 PS 二次處理文字,等於把 AI 生圖從"主力"降級成"輔助",根本無法納入日常生產
- 2.0 解開了三個技術死結: O 系列推理 + CJK 訓練數據擴充 + 字符級渲染機制,三者疊加構成了 99% 準確率的根本基礎
- 4 月爆款不是噱頭: 中文海報復刻潮、表情包工廠、商業海報實戰、出海品牌反向應用,4 大具體爆款形態正在持續
- 假設的邊界: "漢字還原度=傳播閘門"是必要條件而非充分條件,還需要品牌、價格、平臺等因素疊加。Nano Banana Pro 也支持 CJK 但傳播熱度低於 GPT-image-2,正是反例
- 窗口期就是現在: 國產模型預計 6-12 個月追平,中文創作者趁早接入是 2026 年最確定的內容機會之一
- 最低成本驗證方式: API易 apiyi.com 平臺的
gpt-image-2-all$0.03/張,10 張測試只需 ¥2.1,足以驗證差距是否真實
總結
回到開篇的問題——"爲什麼 GPT-image-2 比 1.5 火太多?"
最簡潔的回答是: 因爲它過了"漢字還原度"這道中文圈的傳播閘門。1.5 時代英文圈早已普及 AI 生圖,但中文圈卡在"漢字不能用"上;2.0 把漢字渲染做到 99% 準確,整個中文創作者羣體的工作流第一次跑通,傳播鏈才被點燃。
這不是一個孤立的"模型迭代"故事,而是一個具體的技術指標 (CJK 字符級準確率從 ~80% 到 ~99%) 撬動了一個具體生態 (中文互聯網傳播載體) 的因果鏈。理解了這個因果,就能更準確地判斷未來其他 AI 模型在中文圈的傳播潛力——不看跑分、看漢字。
對於 2026 年的中文內容創作者、營銷團隊、電商運營,"是否接入 GPT-image-2"的判斷已經不是"要不要用 AI"的問題,而是"現在不用 = 錯過紅利期"的問題。建議立即通過 API易 apiyi.com 平臺用最低成本 ($0.03/張) 驗證它在你具體場景的效果,然後基於真實數據決定是否納入主力工作流。
最後回到作者的"一家之言":以上觀察都是 2026 年 4 月的現象記錄和成因分析,未必是定論。歡迎更多創作者基於自己的實測數據補充、修正、甚至反駁。
參考資料
-
OpenAI ChatGPT Images 2.0 官方公告: GPT-image-2 發佈說明
- 鏈接:
openai.com/index/introducing-chatgpt-images-2-0 - 說明: 99% 多語言文字準確率官方原文
- 鏈接:
-
LM Arena Text-to-Image Leaderboard: 模型 Elo 排行
- 鏈接:
arena.ai/leaderboard/text-to-image - 說明: GPT-image-2 1512 Elo · 字符級準確率驗證
- 鏈接:
-
TechCrunch 4 月 21 日報道: ChatGPT's new Images 2.0 model is surprisingly good at generating text
- 鏈接:
techcrunch.com/2026/04/21/chatgpts-new-images-2-0-model-is-surprisingly-good-at-generating-text - 說明: 主流科技媒體 24 小時內首發覆蓋
- 鏈接:
-
The New Stack – OpenAI now thinks before it draws: 推理機制深度報道
- 鏈接:
thenewstack.io/chatgpt-images-20-openai - 說明: O 系列推理對漢字渲染的作用解析
- 鏈接:
-
CJK Tokenization 技術文檔: 爲什麼 LLM 長期做不好中文
- 鏈接:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - 說明: CJK 處理的底層技術挑戰
- 鏈接:
-
API易 平臺: 國內 GPT-image-2 接入
- 鏈接:
apiyi.com - 說明: 官方轉發 API + 反向 API (gpt-image-2-all $0.03/張)
- 鏈接:
作者: APIYI 技術團隊 | 想體驗 GPT-image-2 中文渲染能力,訪問 API易 apiyi.com 註冊即送測試額度,或在線試用 imagen.apiyi.com (國內可直接訪問)。