2026-04-24,DeepSeek 同時開源 V4-Pro 和 V4-Flash。如果說 Flash 是"便宜就夠用"的性價比甜點,那 V4-Pro 是一件完全不同的產品:
它是當前代碼能力最強的開源模型。
不是"在開源裏最強"的委婉表達,而是硬數據直接碾過 GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro 的冠軍:
- LiveCodeBench 93.5 — 全場第一,超過 Gemini 3.1-Pro(91.7)和 Claude Opus 4.6(88.8)
- Codeforces Rating 3206 — 超過 GPT-5.4(3168)和 Gemini 3.1-Pro(3052)
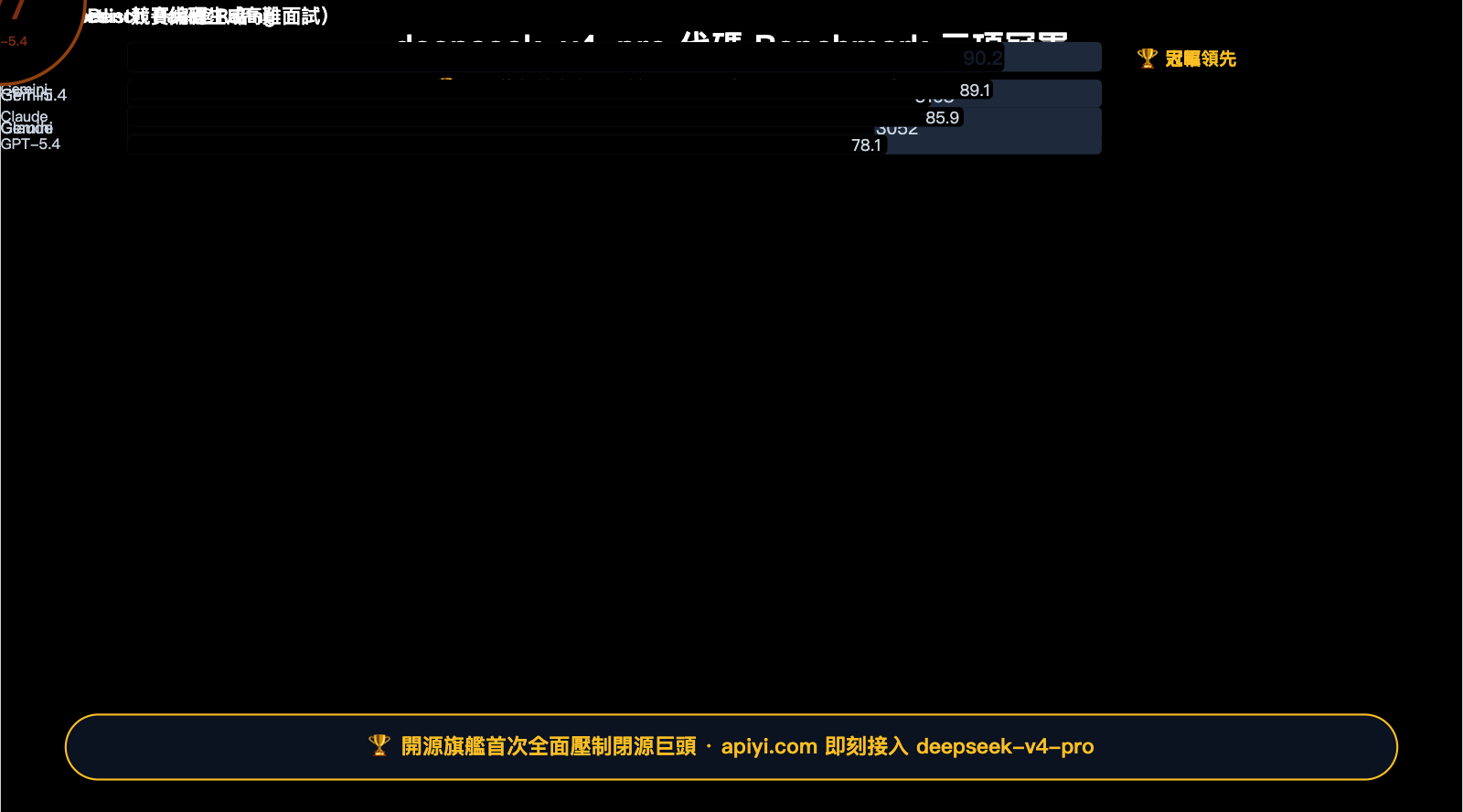
- Apex Shortlist Pass@1 90.2 — 大幅領先 GPT-5.4(78.1)、Claude(85.9)
- IMOAnswerBench 89.8 — 數學競賽題上把 Claude Opus 4.6(75.3)拉開整整 14 分
對應的配置是:1.6T 總參數 / 49B 激活 / 32T tokens 預訓練 / 1M 上下文 / 384K 輸出,再加上 DeepSeek 爲 V4 系列專門設計的四大架構創新:Hybrid Attention、Manifold-Constrained Hyper-Connections (mHC)、Engram Conditional Memory、Muon Optimizer。
deepseek-v4-pro 已在 API易 apiyi.com 上架,你可以用 OpenAI 或 Anthropic 協議 SDK 零改造接入,價格只有 GPT-5.4 的 1/7。
本文不再重複"怎麼遷移/怎麼選便宜模型"這些 Flash 篇已經講過的基礎——這是一份專爲 deepseek-v4-pro 的技術信徒準備的旗艦解讀:
- 3 分鐘搞懂 Pro 爲什麼有資格稱作"旗艦"(架構 + 數據 + 規模)
- 4 張 Benchmark 對決表,看清 Pro 在哪些戰場贏、哪些戰場輸
- 5 分鐘接入 + 2 個真實代碼/數學場景實戰
一、deepseek-v4-pro 的四大旗艦能力
1.1 核心規格一覽表
| 維度 | deepseek-v4-pro |
|---|---|
| 發佈日期 | 2026-04-24(預覽版) |
| 開源倉庫 | huggingface.co/deepseek-ai/DeepSeek-V4-Pro |
| 總參數 | 1.6T(Mixture of Experts) |
| 激活參數 | 49B |
| 預訓練數據 | > 32T tokens |
| 上下文窗口 | 1M tokens |
| 最大輸出 | 384K tokens |
| 架構創新 | Hybrid Attention + mHC + Engram Memory + Muon |
| 推理模式 | Thinking / Non-Thinking 雙模式 |
| Function Calling | ✅ 支持 |
| JSON 模式 | ✅ 支持 |
| API 協議 | OpenAI + Anthropic 雙兼容 |
| 輸入價格 | $1.74 / M tokens |
| 輸出價格 | $3.48 / M tokens |
把最核心的 4 個數字記住:1.6T / 49B / 32T / 1M——這是旗艦的底氣。
1.2 1.6T / 49B MoE:規模上的"開源天花板"
DeepSeek-V4-Pro 總參數 1.6 萬億,採用 Mixture of Experts 架構,每 token 只激活 49B 參數。這組數字的含義:
| 模型 | 總參數 | 激活參數 | 類型 |
|---|---|---|---|
| Llama 3 70B | 70B | 70B | Dense(全激活) |
| Mistral Large 2 | 123B | 123B | Dense |
| DeepSeek-V3.2 | 671B | 37B | MoE |
| DeepSeek-V4-Pro | 1.6T | 49B | MoE ⭐ |
| Claude Opus 4.6 | 未公開 | 未公開 | 閉源 |
1.6T 總參數讓模型擁有接近 GPT-5.4 / Claude Opus 級別的知識面,而 49B 激活參數讓單 token 推理成本可控——這是 MoE 架構能跑通前沿性能的本質原因。
1.3 32T tokens 預訓練:數據總量直接拉滿
預訓練數據 > 32T tokens
這是一個足以震撼的數字:
- GPT-4 預訓練數據量約 13T tokens(業界推測)
- Llama 3 15T tokens
- DeepSeek-V3 14.8T tokens
- DeepSeek-V4-Pro:>32T tokens ⭐
數據量翻倍帶來的直接收益是:長尾知識覆蓋更全、代碼語料更新更及時、數學題庫更深——這也是 V4-Pro 在 LiveCodeBench 和 IMOAnswerBench 上屠榜的根源。
1.4 四大架構創新:Pro 的真正護城河
這是 V4-Pro 和"又一個 MoE 模型"拉開差距的關鍵。官方披露的四項核心創新:
| 創新 | 全名 | 解決什麼問題 |
|---|---|---|
| Hybrid Attention | CSA + HCA 混合注意力 | 長上下文(1M)推理的 FLOPs 與顯存問題 |
| mHC | Manifold-Constrained Hyper-Connections | 深層殘差連接穩定性,防梯度消失/爆炸 |
| Engram | Engram Conditional Memory | 解耦"靜態事實"和"推理能力",事實更新更便宜 |
| Muon | Muon Optimizer | 訓練收斂速度和穩定性,降訓練成本 |
每一項都值得展開講一下:
-
Hybrid Attention(CSA + HCA):傳統 Transformer 的 attention 複雜度是 O(n²),1M 上下文直接爆炸。V4 用壓縮稀疏注意力(CSA) 做粗粒度篩選,高度壓縮注意力(HCA) 做細粒度聚焦,組合起來把 FLOPs 砍到 V3.2 的 27%,KV 緩存只要 10%。這是 deepseek-v4-pro 能把 1M 上下文"開出來還能跑"的關鍵。
-
mHC(Manifold-Constrained Hyper-Connections):深度 MoE 模型訓練時,殘差連接的信號在幾十層之後會出現失真。mHC 在 manifold 空間加約束,讓信號傳播更穩定。實用表達:模型可以訓得更深、更久,而不崩潰。
-
Engram Conditional Memory:一個非常工程化的創新。它把"模型記憶中的事實"和"推理能力"解耦開——事實存放在專門的記憶模塊裏,推理鏈走另一條路徑。結果是當世界知識要更新時,不需要重訓全模型,這會極大降低 Pro 未來版本的發佈成本。
-
Muon Optimizer:DeepSeek 自研的優化器,相比 AdamW 收斂更快、穩定性更好。在萬億參數訓練規模下,這意味着同樣算力下訓得更充分。
🎯 技術啓示:deepseek-v4-pro 不是把舊架構放大,而是把基礎設施重寫了一遍。這是它能在開源狀態下達到閉源巨頭水平的根本原因。接入後如果你打算深度使用,建議通過 API易 apiyi.com 先跑一組業務典型 prompt 感受一下架構升級帶來的差異——尤其是長上下文和多步推理場景。
1.5 1M 上下文 + 384K 輸出:長文生成的分水嶺
Pro 和 Flash 的上下文規格一致:1M tokens 輸入、384K tokens 輸出。但 Pro 的優勢不在"能讀多長",而在"在 1M 下能想多深"。
對長文場景的實際意義:
| 任務 | V3.2 時代 | V4-Pro 時代 |
|---|---|---|
| 50 萬字書稿全文修改 | 要分 10+ 塊拼接 | 一次性 1M 窗口處理 |
| 200 頁技術文檔問答 | 要構建 RAG | 直接喂進去 |
| 中型代碼倉庫審計 | 摘要式分析 | 跨文件一致性檢查 |
| 小說寫作連貫性 | 要自己管理記憶 | 384K 輸出一氣呵成 |
二、deepseek-v4-pro 的 Benchmark 王座

2.1 代碼能力:deepseek-v4-pro 三項屠榜
先看最硬的數據——代碼編程能力:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro | 第一名 |
|---|---|---|---|---|---|
| LiveCodeBench | 93.5 | — | 88.8 | 91.7 | V4-Pro 🏆 |
| Codeforces Rating | 3206 | 3168 | — | 3052 | V4-Pro 🏆 |
| Apex Shortlist Pass@1 | 90.2 | 78.1 | 85.9 | 89.1 | V4-Pro 🏆 |
| SWE-bench Verified | 80.6–82.1 | — | 80.8 | 80.6 | 並列 |
| Terminal-Bench 2.0 | 67.9 | 75.1 | 65.4 | 68.5 | GPT-5.4 |
三項領跑,兩項"並列第一或略輸"。開源模型在代碼能力上第一次全面壓制閉源旗艦——這是 2026 年非常標誌性的事件。
具體解讀:
- LiveCodeBench 93.5:LiveCodeBench 每月更新題目,避免訓練集污染。V4-Pro 的 93.5 說明它的代碼能力是泛化的、能寫新題的,不是記題庫
- Codeforces 3206:競賽編程評分,3206 分接近 IGM(國際特級大師)水平。這個分數做日常業務代碼完全是降維打擊
- Apex Shortlist Pass@1 90.2 vs GPT-5.4 78.1:這個差距是系統性的。Apex Shortlist 是高難度面試題集,V4-Pro 領先了整整 12 個百分點
- Terminal-Bench 2.0 稍弱:這是多步命令行工具使用能力。GPT-5.4 在這裏仍然領先,說明"多步複雜 Agent"場景 GPT-5.4 有護城河
2.2 數學與推理:deepseek-v4-pro 接近前沿
數學維度 Pro 和閉源巨頭"你追我趕",並非全面領先:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | 87.5 | 89.1 | 91.0 |
| IMOAnswerBench | 89.8 | 91.4 | 75.3 | 81.0 |
| HMMT 2026 | 95.2 | 97.7 | 96.2 | — |
| MATH | 92% | — | — | — |
| HumanEval | 90% | — | — | — |
| MMLU | 89% | — | — | — |
亮點在 IMOAnswerBench:國際數學奧林匹克題集,V4-Pro 89.8 分領先 Claude Opus 4.6 整整 14.5 分,領先 Gemini 3.1-Pro 8.8 分。對數學推理、形式證明這類高階任務,Pro 是目前開源模型的天花板。
弱項在 MMLU-Pro 通用知識:Pro 的 87.5 與 GPT-5.4 持平,但比 Gemini 3.1-Pro 的 91.0 差 3.5 分。通用知識問答場景 Gemini 仍有一定優勢。
2.3 戰場分佈圖:deepseek-v4-pro 贏在哪裏、輸在哪裏
| 戰場 | 冠軍 | V4-Pro 位置 |
|---|---|---|
| 代碼生成(LiveCodeBench) | V4-Pro 🏆 | 冠軍 |
| 競賽編程(Codeforces) | V4-Pro 🏆 | 冠軍 |
| 高難面試(Apex) | V4-Pro 🏆 | 冠軍(大幅領先) |
| 軟件工程(SWE-bench) | 並列 | 並列第一 |
| 數學競賽(IMO) | GPT-5.4 | 第二(遠超 Claude/Gemini) |
| 通用知識(MMLU-Pro) | Gemini 3.1-Pro | 第三 |
| 多步工具鏈(Terminal-Bench) | GPT-5.4 | 第二 |
| 一致性推理(HMMT) | GPT-5.4 | 第三 |
結論:如果你的工作負載以代碼爲主,deepseek-v4-pro 是目前地球上最強的選擇之一(含開源和閉源)。如果以多步 Agent 工具鏈爲主,GPT-5.4 仍有微弱優勢;如果以通用知識問答爲主,Gemini 3.1-Pro 更強。
🎯 選型建議:我們建議先用自己業務的典型 prompt 在 API易 apiyi.com 上跑一組 V4-Pro vs 現有模型 的 AB 對比(20–50 條夠了)。不要相信公共 Benchmark 直接決定選型——你自己的 prompt 分佈纔是真實的 Benchmark。批量 AB 跑圖建議走
vip.apiyi.com高併發線路。
三、5 分鐘在 API易 apiyi.com 調用 deepseek-v4-pro
3.1 Step 1:拿 Key 和選線路
前置環境:Python 3.8+ 或 Node.js 18+,官方 OpenAI SDK 或 Anthropic SDK 任選其一。
拿 Key:
- 訪問 API易
apiyi.com,控制檯 → API Keys → 新建密鑰 - 建議給 Pro 用的 Key 單獨設置日額度(¥200–500,視業務規模)
- 複製
sk-開頭的密鑰
選線路(三線路共用一把 Key):
| base_url | 適用 |
|---|---|
https://api.apiyi.com/v1 |
日常調用、交互場景 |
https://vip.apiyi.com/v1 |
批量任務、高併發 |
https://b.apiyi.com/v1 |
主站抖動時備用 |
3.2 Step 2:Python 最小調用(Non-Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "You are a senior Python engineer."},
{"role": "user", "content": "Write a production-ready LRU cache in 30 lines."},
],
max_tokens=2048,
)
print(resp.choices[0].message.content)
改兩處:base_url 和 model — 其餘 OpenAI SDK 代碼不動。
3.3 Step 3:啓用 Thinking 推理模式(Pro 的價值高光)
deepseek-v4-pro 的真正價值在 Thinking 模式下才完全釋放。對應 IMOAnswerBench 89.8、LiveCodeBench 93.5 這些 Benchmark 都是在 Thinking 模式下測出來的。
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": """
請實現一個併發安全的 token bucket 限流器,要求:
1. 支持動態調整速率
2. 支持突發流量預留
3. 無鎖實現(CAS 或原子操作)
4. 包含完整的單元測試
"""},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=16384,
)
print("--- 推理過程 ---")
print(resp.choices[0].message.reasoning_content)
print("\n--- 最終答案 ---")
print(resp.choices[0].message.content)
effort=high 時 Pro 會做非常深入的規劃——你會看到它先分析需求、再設計 API、再討論不同實現方案、最後纔給出代碼。這是 deepseek-v4-pro 相對 Flash 最值得付差價的地方。
3.4 Step 4:代碼修復場景實戰
真實業務場景:讓 Pro 修一個 bug。
buggy_code = """
def find_kth_largest(nums, k):
nums.sort()
return nums[k] # BUG here
"""
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "You are a senior code reviewer. Identify bugs, explain root cause, and give fixed code."},
{"role": "user", "content": f"Review this code:\n```python\n{buggy_code}\n```"},
],
extra_body={"reasoning": {"enabled": True}},
max_tokens=4096,
)
print(resp.choices[0].message.content)
Pro 會指出:索引應該是 -k(排序後第 k 大在倒數第 k 個位置),並給出修復 + 邊界條件處理(k <= 0、k > len(nums))+ 測試用例。
SWE-bench 80%+ 的數據在這種場景裏就是真實體感。
3.5 Step 5:Function Calling / Tool Use
Pro 在單次工具調用上非常穩定,多步工具鏈雖弱於 GPT-5.4 但領先 Claude:
tools = [
{
"type": "function",
"function": {
"name": "run_sql",
"description": "Execute a read-only SQL query on the analytics DB.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "SELECT-only SQL"},
},
"required": ["query"],
},
},
},
]
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "過去 30 天 DAU 前 5 的城市?"},
],
tools=tools,
tool_choice="auto",
)
print(resp.choices[0].message.tool_calls)
3.6 Step 6:Anthropic 協議(Claude Code 接入 Pro)
這條路徑是 deepseek-v4-pro 最容易被低估的價值:你現有的所有 Claude SDK / Claude Code 項目,可以把底層模型換成 V4-Pro 且不改任何業務代碼。
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com", # 注意無 /v1
)
resp = client.messages.create(
model="deepseek-v4-pro",
max_tokens=4096,
messages=[
{"role": "user", "content": "重構這段 Python 代碼爲 async/await 風格..."},
],
)
print(resp.content[0].text)
Claude Code 終端:在配置裏把 ANTHROPIC_BASE_URL=https://api.apiyi.com + ANTHROPIC_API_KEY=sk-... + 模型換成 deepseek-v4-pro,立刻獲得一個代碼能力領先的終端 Agent。
3.7 Step 7:Cursor 裏接入 deepseek-v4-pro
Cursor 的 Settings → Models → Custom OpenAI-Compatible:
- Base URL:
https://api.apiyi.com/v1 - API Key:
sk-... - Model Name:
deepseek-v4-pro
完成後 Cursor 的 Chat / Cmd+K / Composer 三個入口都會走 V4-Pro,代碼補全和重構的質量會有明顯提升。
🎯 IDE 接入建議:Cursor、Windsurf、Cline、Continue 等主流 AI 編程工具都兼容 OpenAI 協議,把
base_url指向 API易api.apiyi.com/v1、模型換成deepseek-v4-pro就能無縫遷移。詳細 IDE 配置樣例可以在 API易官方文檔docs.apiyi.com的 DeepSeek V4 專欄查閱。
四、deepseek-v4-pro 什麼時候選、什麼時候不選
4.1 選 Pro 的決策條件
✅ 下列場景直接選 deepseek-v4-pro:
| 場景 | 爲什麼 |
|---|---|
| 代碼生成、重構、審查 | LiveCodeBench 93.5 全場冠軍 |
| 競賽編程、算法題訓練 | Codeforces 3206 等效 IGM 水平 |
| 面試題批量解答 | Apex Shortlist 90.2 大幅領先 |
| 數學推理、形式證明 | IMOAnswerBench 89.8 領先 Claude 14 分 |
| 大倉庫整倉理解 | 1M 上下文 + 49B 激活 |
| 長文寫作與編輯 | 384K 輸出一次到位 |
| 本地部署 / 二次訓練 | 開源權重 + Engram 模塊便於微調 |
| 替代 Cursor / Claude Code 的底層模型 | Anthropic 協議零改造接入 |
4.2 不選 Pro 的情況
❌ 以下場景別浪費 Pro 的算力:
| 場景 | 建議 |
|---|---|
| 日常對話、FAQ | 用 Flash(省 12 倍) |
| 短文本分類、抽取 | 用 Flash 或更小模型 |
| 多步複雜 Agent 工具鏈 | 優先考慮 GPT-5.4(Terminal-Bench 領先) |
| 以通用知識問答爲主 | Gemini 3.1-Pro 更強 |
| 對延遲敏感的在線交互 | 用 Flash(Non-Thinking 模式)或加緩存 |
4.3 混合路由建議
生產環境的最優解通常是分層路由:
def pick_model(request_type: str, complexity: str) -> str:
# 代碼類重活 → Pro
if request_type in ("code_gen", "code_review", "refactor") and complexity == "hard":
return "deepseek-v4-pro"
# 數學推理 → Pro
if request_type in ("math_proof", "competitive_programming"):
return "deepseek-v4-pro"
# 長文檔深度理解 → Pro
if request_type == "long_doc_analysis":
return "deepseek-v4-pro"
# 其他日常 → Flash
return "deepseek-v4-flash"
在 API易 apiyi.com 上這兩個模型共用一把 Key,切換隻動 model 字段,不動別的配置。
五、deepseek-v4-pro 常見問題 FAQ
Q1:爲什麼 Pro 的代碼能力這麼強?
三個原因疊加:
- 32T tokens 預訓練 裏包含了大量高質量代碼語料
- 1.6T MoE / 49B 激活 讓代碼知識能存下、能調出
- Thinking 模式 + Engram Memory 把"記代碼範式"和"推理新代碼"解耦
這三件事任何一件單獨做不到這個分數,合起來纔有了 LiveCodeBench 93.5。
Q2:1.6T 參數會不會響應很慢?
單次響應速度由激活參數決定,不是總參數。Pro 每 token 只激活 49B,加上 Hybrid Attention 的 FLOPs 優化,首 token 延遲和 Flash 接近。Thinking 模式會慢一些(因爲要輸出推理過程),但這是設計上的取捨——你是爲推理質量付時間。
Q3:Thinking 模式必須開嗎?
不必須。普通對話、簡單代碼、日常問答都可以關掉。但你付 Pro 的錢大部分價值在 Thinking 模式——複雜代碼、數學題、多步邏輯推理務必打開 reasoning.enabled=true + effort=high。
Q4:在 Cursor / Claude Code 裏怎麼用?
- Cursor:Settings → Models → Custom OpenAI-Compatible,Base URL 填
https://api.apiyi.com/v1,Model 填deepseek-v4-pro - Claude Code:環境變量
ANTHROPIC_BASE_URL=https://api.apiyi.com+ANTHROPIC_API_KEY=sk-...,啓動時 model 指定deepseek-v4-pro
具體截圖步驟可以在 docs.apiyi.com 的 IDE 接入專欄找到。
Q5:和 GPT-5.4 相比到底誰更值?
二選一的話:
- 日常代碼 / 競賽 / 數學 / 成本敏感 → deepseek-v4-pro(代碼冠軍、價格 1/7)
- 多步工具鏈 Agent / 通用知識問答 → GPT-5.4
- 混用 是最優解(通過 API易 apiyi.com 同一把 Key 切兩個模型)
Q6:可以本地部署嗎?
可以,V4-Pro 開源了完整權重到 Hugging Face(deepseek-ai/DeepSeek-V4-Pro)。但自部署要求:
- 單機 ≥ 8×H200 或等效 GPU
- 1M 上下文需要額外 KV 緩存(雖然 Pro 已把緩存壓到 V3.2 的 10%)
- 維護推理服務的工程成本
成本測算:除非你月調用量超過 500 億 tokens,走 API易 apiyi.com 的託管調用比自部署更經濟。
Q7:多併發上限多少?
生產環境建議:
- 主站
api.apiyi.com:50 併發安全 - 高併發線路
vip.apiyi.com:200+ 併發 - 備用
b.apiyi.com:主線路抖動時自動 fallback
Pro 對複雜 Thinking 任務延遲較高,併發數不是越大越好——按 QPS × 平均響應時間 估算所需併發窗口更合適。
Q8:Pro 會不會很快出正式版?
2026-04-24 發佈的是預覽版(Preview)。按 DeepSeek 過去的節奏,正式版通常在預覽版之後 1–2 個月發佈,可能會有小幅 Benchmark 提升。現在用預覽版在 API易 apiyi.com 上跑也沒問題——model id 正式版大概率保持 deepseek-v4-pro 不變,向後兼容。
六、deepseek-v4-pro 上架總結
如果你跳過中間只看結論,這就是:
- ✅ deepseek-v4-pro 是當前代碼能力最強的開源模型——LiveCodeBench / Codeforces / Apex 三項硬核 Benchmark 擊敗 GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro
- ✅ 架構四大創新(Hybrid Attention / mHC / Engram Memory / Muon)讓它不是"又一個大模型",而是基礎設施重寫之後的新物種
- ✅ 1.6T / 49B MoE + 32T tokens 預訓練 + 1M 上下文 規模上達到開源天花板
- ✅ 已在 API易 apiyi.com 上架,兼容 OpenAI + Anthropic 雙協議,Cursor / Claude Code / Cline 等所有主流工具零改造接入
- ✅ 價格僅 GPT-5.4 的 1/7,Thinking 模式下才是它真正的高光
對代碼爲主的開發團隊來說,deepseek-v4-pro 值得立刻測試——它不是"再便宜一點的替代品",而是可能會成爲新默認的旗艦模型。
🎯 行動建議:建議今天就從 API易
apiyi.com申請一把 Key(給 Pro 專用、日額度設 ¥200–500),先跑 20 條最能代表你業務的代碼 / 數學 / 長文 prompt,把 V4-Pro(Thinking 模式)和你現在的主力模型做 AB 對比。如果代碼任務質量提升明顯,就把 Cursor / Claude Code 的默認模型切過來;需要日常便宜模型分流,就再裝一個 V4-Flash(見上一篇遷移指南)。批量跑測試時走vip.apiyi.com,主站抖動時b.apiyi.com自動 fallback。完整接入樣例、IDE 配置、Benchmark 復現腳本都能在docs.apiyi.com找到。
deepseek-v4-pro 的意義超越了"又一個便宜的 SOTA 模型"。它標誌着開源模型第一次在覈心代碼能力上全面壓制閉源旗艦——這件事本身就值得每個嚴肅對待 AI 工程的團隊認真測一次。
作者: API易技術團隊
相關資源:
- DeepSeek 官方公告: api-docs.deepseek.com/news/news260424
- Hugging Face 開源倉庫: huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- API易官網: apiyi.com
- API易文檔: docs.apiyi.com
- API易主站: api.apiyi.com(備用 vip.apiyi.com / b.apiyi.com)