阿里雲 Qwen3.5 API 調用慢,是最近開發者社區中討論最多的話題之一。作爲阿里自研的模型,Qwen3.5-Plus 和 Qwen3.5-Flash 理論上應該在自有算力上表現出色,但實際體驗卻讓不少開發者感到困惑——自家模型在自家平臺上跑得慢,通過阿里雲調用 GLM-5、Kimi-K2.5、MiniMax-M2.5 等第三方模型更是卡頓明顯。
核心價值:本文將從算力供給、架構設計、調度策略 3 個維度深度解析阿里雲 API 響應慢的根本原因,並給出 3 種經過驗證的替代方案,幫助你在實際項目中獲得更快的推理體驗。

阿里雲 Qwen3.5 API 慢的 5 大原因分析
原因一:全球 GPU 算力供給嚴重不足
這不僅是阿里雲一家的問題,而是整個行業的結構性矛盾。2026 年數據中心級 GPU 的交付週期已經拉長到 36-52 周,阿里雲高管公開承認——半導體製造商、存儲芯片、內存器件全面短缺,供應端將成爲未來 2-3 年的"較大瓶頸"。
| 算力供給指標 | 2025 年 | 2026 年 | 變化趨勢 |
|---|---|---|---|
| GPU 交付週期 | 12-24 周 | 36-52 周 | ↑ 大幅延長 |
| 阿里雲 AI 收入增長 | — | 34% | 需求爆發 |
| 阿里雲算力價格調整 | 基準價 | 上調最高 34% | ↑ 2026年4月18日起 |
| 全球 AI 推理支出佔比 | 42% | 55% | 首次超過訓練 |
阿里雲已官宣將從 2026 年 4 月 18 日起上調 AI 算力價格,漲幅最高達 34%,直接原因就是"全球 AI 需求爆發和供應鏈價格上漲"。阿里雲收入增長了 34%,但公開表示仍然無法滿足需求——這就是 Qwen3.5 API 慢的宏觀背景。
原因二:Qwen3.5 模型架構的算力消耗
Qwen3.5 家族採用了 MoE(混合專家)架構,旗艦版 Qwen3.5-397B-A17B 總參數量達 3970 億,每次推理激活 170 億參數。即便是定位輕量的 Qwen3.5-Flash(基於 35B-A3B),也原生支持 100 萬 token 上下文和多模態輸入(文本+圖像+視頻)。
| 模型版本 | 總參數量 | 激活參數量 | 默認上下文 | 多模態支持 |
|---|---|---|---|---|
| Qwen3.5-397B-A17B(旗艦) | 3970 億 | 170 億 | 262K→1M | 文本+圖像+視頻 |
| Qwen3.5-Plus(API 版) | 未公開 | 未公開 | 1M | 文本+圖像+視頻 |
| Qwen3.5-Flash(API 版) | 350 億 | 30 億 | 1M | 文本+圖像+視頻 |
| Qwen3.5-122B-A10B | 1220 億 | 100 億 | 262K | 文本+圖像+視頻 |
這些模型從訓練階段就採用了早期融合(early-fusion)的多模態架構,原生支持文本、圖像和視頻的統一處理。功能強大的代價就是:每個請求的計算開銷遠高於純文本模型。再疊加百萬級 token 上下文窗口,單次推理的顯存和算力佔用顯著增加。
原因三:阿里雲轉售第三方模型的額外延遲
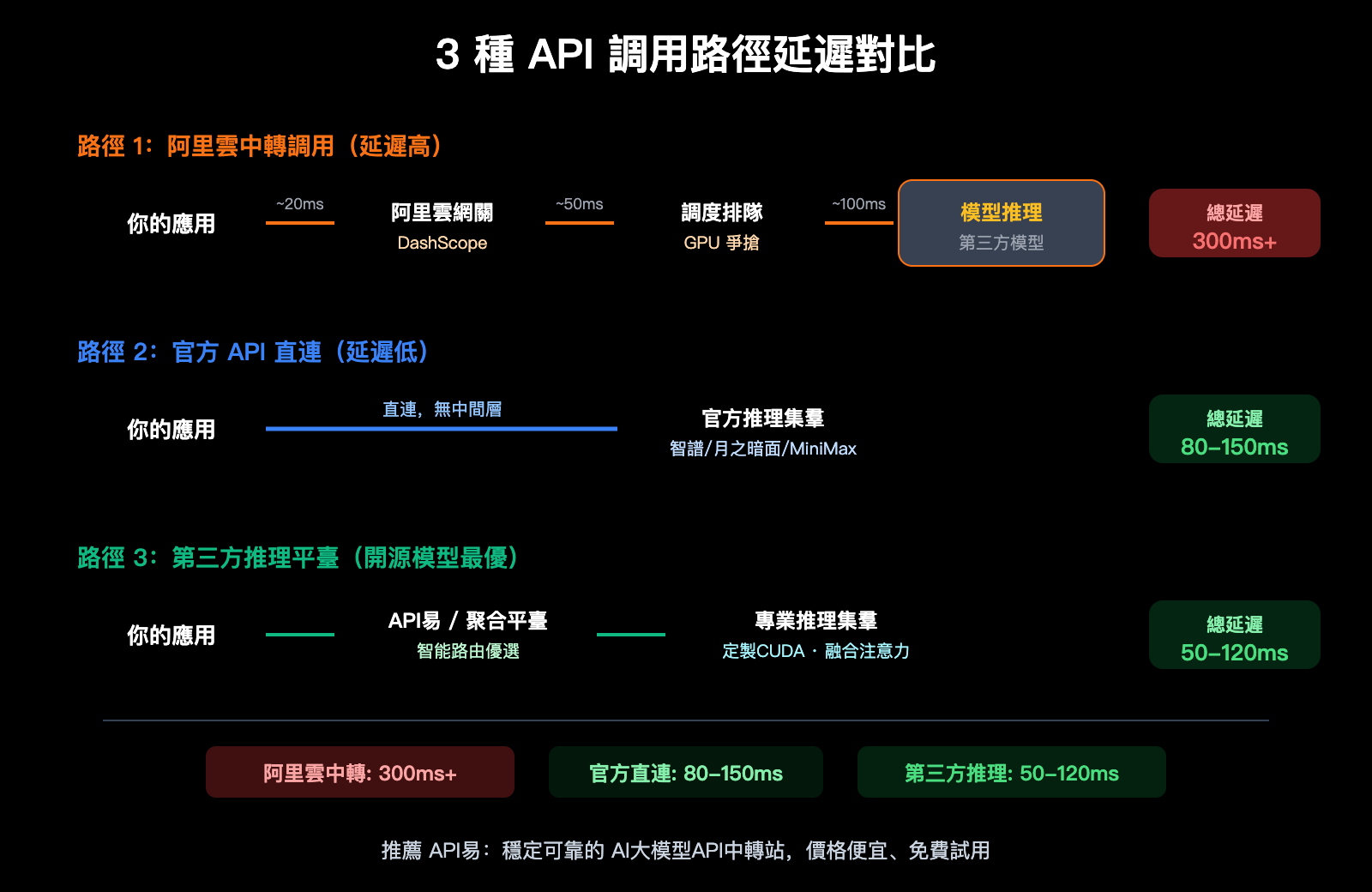
通過阿里雲 DashScope 平臺調用 GLM-5(智譜 AI)、Kimi-K2.5(月之暗面)、MiniMax-M2.5 這些第三方模型時,請求鏈路實際上變成了:
你的應用 → 阿里雲 API 網關 → DashScope 調度層 → 第三方模型服務
每多一層轉發,就多一層延遲。更關鍵的是,阿里雲在轉售這些模型時,GPU 資源的分配優先級可能低於自有模型——畢竟算力本身就不夠用。圈內開發者的普遍反饋是:GLM-5、Kimi-K2.5、MiniMax-M2.5 通過阿里雲調用明顯比官方 API 慢。
原因四:推理調度策略的優化不足
專業的第三方推理平臺(如 SiliconFlow、Fireworks AI、Together AI)通過定製 CUDA 內核、融合注意力機制、細粒度調度等技術手段,在推理效率上具有顯著優勢。實測數據顯示:
- SiliconFlow:推理速度最高比通用雲平臺快 2.3 倍,延遲降低 32%
- Fireworks AI:FireAttention v2 技術聲稱最高 8 倍速度提升,實測約 747 TPS
- Together AI:通過投機解碼和 FP4 量化,開源模型推理速度最高 2 倍提升
阿里雲作爲通用雲平臺,其推理調度更側重通用性和穩定性,而非極致的推理速度優化。這在算力充裕時影響不大,但在 GPU 緊張時期,差距就會被放大。
原因五:多租戶資源爭搶
阿里雲作爲國內最大的雲服務商,其 AI 推理集羣同時服務海量用戶。在高峯期,GPU 資源的爭搶直接導致排隊等待時間增加。阿里雲開發的 Aegaeon 資源池化系統雖然聲稱將 GPU 利用率提升了 82%,但這本質上是"把有限的蛋糕切得更細",並不能從根本上解決算力總量不足的問題。
GLM-5、Kimi-K2.5、MiniMax-M2.5 阿里雲調用 vs 官方 API 延遲對比
瞭解了原因之後,我們來看具體的模型調用場景。以下是 3 款熱門模型在不同平臺上的體驗差異分析。
GLM-5(智譜 AI)API 調用延遲分析
GLM-5 是智譜 AI 於 2026 年 2 月發佈的旗艦模型,總參數 7440 億,激活參數 400 億,採用 MoE 架構。它在華爲昇騰芯片上訓練,支持 20 萬 token 上下文,並且已經開源(MIT 許可證)。
關鍵事實:GLM-5 原生支持 Agent 模式,能自主拆解任務爲子任務執行,並可直接生成專業辦公文檔(.docx、.pdf、.xlsx)。其定價爲輸入 $1.00/M tokens、輸出 $3.20/M tokens。
通過阿里雲調用 GLM-5 時,請求需要經過額外的網關和調度層轉發,延遲顯著增加。而直連智譜 AI 官方 API(bigmodel.cn),請求直接到達智譜自有的推理集羣,響應更快。
Kimi-K2.5(月之暗面)API 調用延遲分析
Kimi-K2.5 於 2026 年 1 月發佈,是一個 1 萬億參數的 MoE 模型,每次請求僅激活 320 億參數。它在 15 萬億混合視覺和文本 token 上預訓練,原生多模態。
最大亮點:Agent Swarm 功能——可以同時協調最高 100 個專業 AI Agent 協同工作,執行時間縮短 4.5 倍。在 SWE-Bench Verified 上超越 Gemini 3 Pro,Cursor AI 已確認其 Composer 2 功能基於 Kimi 技術構建。
通過阿里雲中轉調用 Kimi-K2.5,額外的轉發鏈路讓這個本就需要大量算力的萬億參數模型體驗更差。建議直接使用月之暗面官方 API(platform.moonshot.ai)。
MiniMax-M2.5 API 調用延遲分析
MiniMax-M2.5 於 2026 年 2 月發佈,總參數 2300 億,激活參數 100 億。在 SWE-Bench Verified 上得分 80.2%,完成速度比 M2.1 快 37%,與 Claude Opus 4.6 持平。
成本優勢突出:號稱首個"用戶無需擔心成本"的前沿模型——以 100 tokens/秒的速度持續運行 1 小時僅需約 1 美元。已在 Hugging Face 開源,推薦使用 vLLM 或 SGLang 部署。
| 模型 | 發佈時間 | 總參數 | 激活參數 | 建議調用方式 | 開源狀態 |
|---|---|---|---|---|---|
| GLM-5 | 2026.02.11 | 7440 億 | 400 億 | 智譜官方 API | MIT 開源 |
| Kimi-K2.5 | 2026.01.27 | 1 萬億 | 320 億 | 月之暗面官方 API | 開源 |
| MiniMax-M2.5 | 2026.02.12 | 2300 億 | 100 億 | MiniMax 官方 / 第三方 | MIT 修改版 |
🎯 實測建議:對於 GLM-5、Kimi-K2.5、MiniMax-M2.5 這類閉源或半開源的第三方模型,推薦直連各家官方 API 獲取最佳體驗。如果需要統一管理多家模型的 API 接口,可以通過 API易 apiyi.com 平臺實現一個 API Key 調用多家模型,同時享受更優的價格。
第三方推理平臺 vs 阿里雲:開源模型部署的 3 大優勢
對於 Qwen3.5 這樣的開源模型,除了阿里雲官方 API,開發者還有更多選擇。專業的第三方推理平臺在部署開源模型方面,往往有着不輸甚至超越原廠的表現。
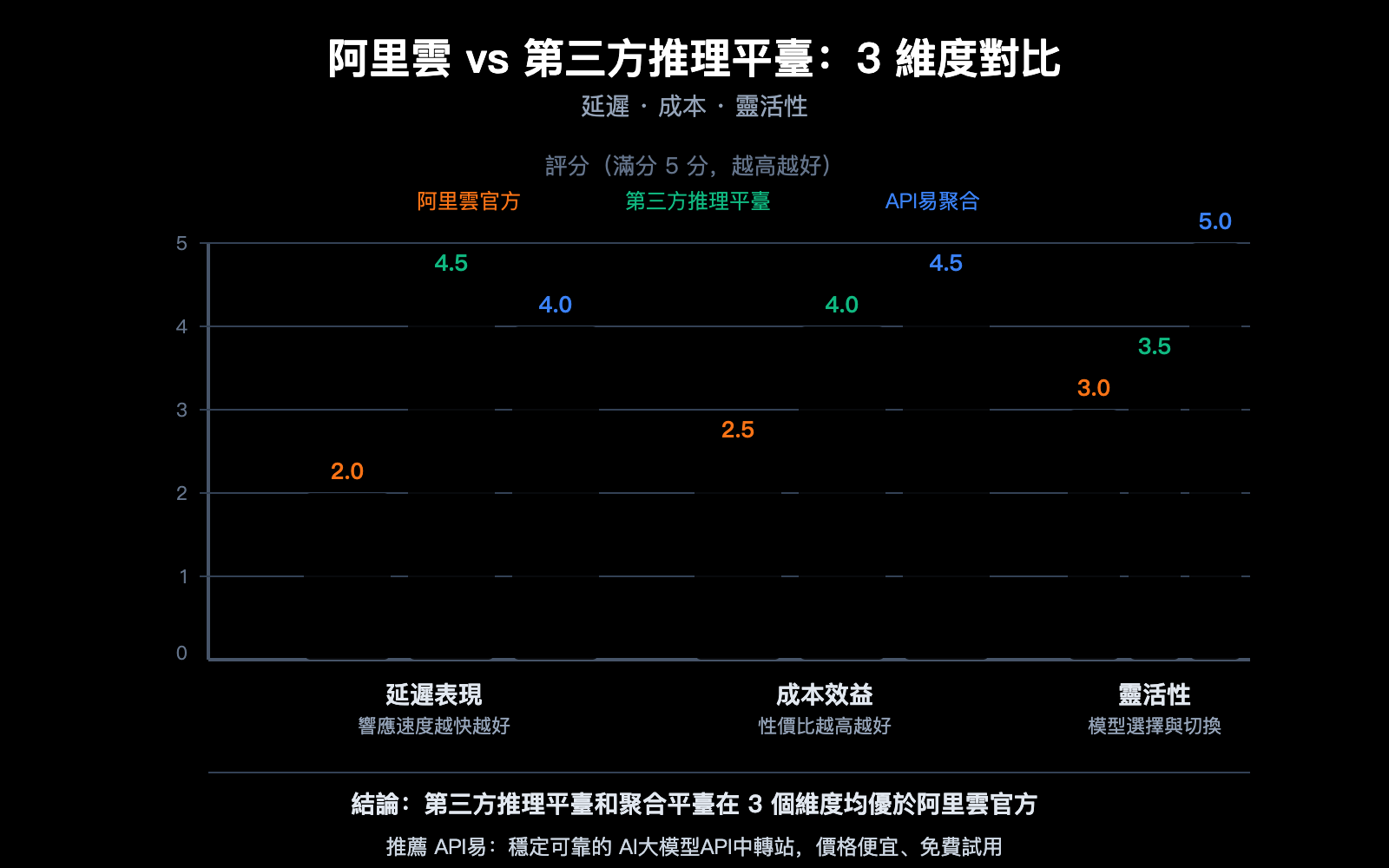
優勢一:推理速度更快
專業推理平臺的核心競爭力就是速度。它們通過定製化的推理引擎優化,在相同模型上實現更低延遲:
| 平臺類型 | 典型延遲 | 吞吐量 | 速度優勢 |
|---|---|---|---|
| 通用雲平臺(阿里雲等) | 100-300ms | 基準 | — |
| SiliconFlow | 降低 32% | 提升 2.3x | 定製 CUDA 內核 |
| Fireworks AI | ~0.17s | ~747 TPS | FireAttention v2 |
| Together AI | — | 提升 2x | 投機解碼+FP4 量化 |
| API易 apiyi.com | 多通道優選 | 智能路由 | 自動選擇最快通道 |
優勢二:成本更低
2026 年 AI 推理支出首次超過訓練支出,佔 AI 雲基礎設施總支出的 55%。在這一背景下,推理成本優化變得至關重要:
- 開源模型通過第三方 API 調用,價格通常低於 $1/M tokens,比閉源模型節省 70-90%
- 專業推理平臺利用 NVIDIA Blackwell 等新一代硬件,將 AI 推理成本降低最高 10 倍
- 無需自建 GPU 集羣,按需付費,適合中小團隊和個人開發者
優勢三:更靈活的模型選擇
第三方平臺通常同時支持開源和閉源模型,提供統一的 API 接口和透明的定價。這意味着:
- 無廠商鎖定:不綁定任何一家雲服務商
- 快速切換:一個接口調用多個模型,對比效果後選擇最優
- 自定義優化:開源模型支持量化、微調、合併等自定義操作
💡 選擇建議:對於 Qwen3.5 等開源模型,第三方推理平臺的部署效果可能比阿里雲官方 API 更好。我們建議通過 API易 apiyi.com 平臺進行實際測試對比,該平臺聚合了多家推理通道,自動爲你選擇延遲最低的路徑。
開源模型 API 調用快速上手:5 分鐘接入指南
以 Qwen3.5-Flash 爲例,展示如何通過第三方平臺快速調用開源模型 API。
極簡代碼示例
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # API易統一接口
)
response = client.chat.completions.create(
model="qwen3.5-flash",
messages=[
{"role": "user", "content": "分析 Qwen3.5 的 MoE 架構優勢"}
]
)
print(response.choices[0].message.content)
查看完整代碼(含多模型切換和錯誤處理)
import openai
import time
# 初始化客戶端 - 通過 API易 統一調用多家模型
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# 支持的模型列表
models = [
"qwen3.5-flash", # 阿里 Qwen3.5-Flash
"qwen3.5-plus", # 阿里 Qwen3.5-Plus
"glm-5", # 智譜 GLM-5
"kimi-k2.5", # 月之暗面 Kimi-K2.5
"minimax-m2.5", # MiniMax-M2.5
]
prompt = "用 3 句話解釋 MoE 架構在大模型推理中的優勢"
for model_name in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.7
)
elapsed = time.time() - start
content = response.choices[0].message.content
print(f"\n[{model_name}] 耗時: {elapsed:.2f}s")
print(f"回覆: {content[:200]}...")
except Exception as e:
print(f"\n[{model_name}] 調用失敗: {e}")
🚀 快速開始:推薦使用 API易 apiyi.com 平臺快速測試上述模型。註冊即送免費額度,一個 API Key 即可調用 Qwen3.5、GLM-5、Kimi-K2.5、MiniMax-M2.5 等主流模型,無需分別註冊多家平臺。
不同場景下的模型調用方案推薦
根據你的實際需求,選擇最合適的調用方式:
場景一:需要調用閉源/半閉源模型
如果你主要使用 GLM-5、Kimi-K2.5 等模型的閉源版本(非自部署),建議:
- 首選:直連各家官方 API,延遲最低
- 次選:通過 API易 apiyi.com 等聚合平臺統一調用,犧牲少量延遲換取管理便利
場景二:需要部署開源模型
如果你使用 Qwen3.5、GLM-5 開源版、MiniMax-M2.5 開源版等模型:
- 預算充足:選擇 SiliconFlow、Together AI 等專業推理平臺,延遲最優
- 性價比優先:通過 API易 apiyi.com 聚合調用,自動路由到最優通道
- 完全自控:使用 vLLM 或 SGLang 自建推理服務,需要自有 GPU 資源
場景三:需要多模型對比測試
開發初期需要快速對比多個模型的效果時:
- 推薦:使用統一 API 接口(如 API易 apiyi.com),一次註冊即可切換測試多個模型
- 避免爲每個模型單獨註冊賬號、管理多套 API Key
💰 成本優化建議:對於預算敏感的項目,通過 API易 apiyi.com 平臺調用開源模型 API 是最具性價比的方案。平臺提供靈活的計費方式,開源模型調用成本遠低於閉源模型官方定價。
常見問題
Q1:Qwen3.5-Flash 號稱輕量模型,爲什麼 API 還是慢?
Qwen3.5-Flash 雖然每次推理僅激活 30 億參數,但它默認支持 100 萬 token 上下文窗口,並且原生集成了多模態處理能力(文本+圖像+視頻)和內置工具調用。這些"隱藏成本"讓它的實際算力消耗遠高於同等參數量的純文本模型。加上阿里雲 GPU 資源緊張的大背景,排隊等待時間進一步拉高了感知延遲。
Q2:開源模型用第三方平臺部署,效果會不會打折扣?
不會。專業的第三方推理平臺(如 SiliconFlow、Together AI)使用的是原版開源權重,配合優化的推理引擎,效果與原廠一致,推理速度反而更快。通過 API易 apiyi.com 平臺可以快速對比不同通道的推理質量和速度,選擇最優方案。
Q3:阿里雲的算力問題什麼時候能緩解?
根據阿里雲高管的公開表態,GPU 供應短缺預計將持續 2-3 年。短期內,阿里雲更傾向於通過 Aegaeon 等資源池化技術提高現有 GPU 的利用率,而非大幅擴容。建議開發者不要等待平臺優化,而是主動選擇更適合的調用方案——官方 API 直連或第三方推理平臺都是當下可行的替代方案。可以通過 API易 apiyi.com 免費測試不同模型的調用速度。
總結:阿里雲 Qwen3.5 API 慢的應對策略
阿里雲 Qwen3.5 API 響應慢的根本原因是全球 GPU 算力供給不足,疊加模型架構的高算力消耗、多租戶資源爭搶等因素。對於通過阿里雲調用 GLM-5、Kimi-K2.5、MiniMax-M2.5 等第三方模型出現的卡頓問題,本質上也是同一原因——阿里雲的算力優先保障自有模型,第三方模型的資源分配處於次要位置。
3 條核心建議:
- 閉源模型直連官方:GLM-5 用智譜 API、Kimi-K2.5 用月之暗面 API、MiniMax-M2.5 用 MiniMax API,避免中間層轉發延遲
- 開源模型選第三方:Qwen3.5 等開源模型在專業推理平臺上的表現可能優於阿里雲官方 API
- 統一管理用聚合平臺:如果需要同時使用多個模型,推薦通過 API易 apiyi.com 實現一個接口調用所有模型,兼顧效率和管理便利
算力短缺是整個行業未來 2-3 年的常態。與其被動等待雲平臺擴容,不如主動優化調用策略——選擇最適合的平臺和模型組合,纔是提升 AI 應用體驗的最佳路徑。
作者:APIYI Team | 更多 AI 模型 API 調用技巧,歡迎訪問 API易 apiyi.com 獲取最新教程和免費測試額度
📚 參考資料
-
Qwen3.5 模型系列官方文檔:阿里雲通義千問模型技術規格
- 鏈接:
github.com/QwenLM/Qwen3.5 - 說明: 包含完整的模型參數、基準測試和使用指南
- 鏈接:
-
阿里雲算力價格調整公告:2026 年 4 月起 AI 算力價格上調
- 鏈接:
www.alibabacloud.com - 說明: 官方關於算力供需矛盾的說明
- 鏈接:
-
GLM-5 技術報告:智譜 AI 旗艦模型技術細節
- 鏈接:
github.com/THUDM/GLM-5 - 說明: 7440 億參數 MoE 架構和 Agent 模式說明
- 鏈接:
-
Kimi-K2.5 官方文檔:月之暗面萬億參數模型
- 鏈接:
platform.moonshot.ai/docs/guide/kimi-k2-5-quickstart - 說明: Agent Swarm 功能和 API 接入指南
- 鏈接:
-
MiniMax-M2.5 技術博客:前沿開源模型詳解
- 鏈接:
www.minimax.io/news/minimax-m25 - 說明: 性能基準、部署建議和成本分析
- 鏈接: