作者注:客觀對比 Claude Opus 4.6 和 GPT-5.4 的 12 項基準測試、定價、上下文窗口、代理能力和適用場景,幫開發者做出正確選型
2026 年 2 月和 3 月,AI 領域迎來兩款重磅旗艦模型:Anthropic 的 Claude Opus 4.6(2 月 5 日)和 OpenAI 的 GPT-5.4(3 月 5 日)。兩者都是各自公司有史以來最強的通用模型,但它們的設計哲學和優勢領域截然不同。
基準測試顯示:GPT-5.4 贏得 5 個類別,Claude Opus 4.6 贏得 3 個類別——但編程、推理和代碼質量這些核心維度上,Claude 的領先更具實際價值。
核心價值: 看完本文,你將明確在編程、推理、自動化、視覺等不同場景下該選擇哪個模型。

Claude Opus 4.6 vs GPT-5.4 核心數據對比
| 對比維度 | Claude Opus 4.6 | GPT-5.4 | 說明 |
|---|---|---|---|
| 發佈日期 | 2026-02-05 | 2026-03-05 | 相隔 1 個月 |
| 模型 ID | claude-opus-4-6 | gpt-5.4 | — |
| 上下文窗口 | 200K (1M Beta) | 1,000K | GPT 正式支持 1M |
| 最大輸出 | 128K | 128K | 相同 |
| 輸入價格 | $5.00/M | $2.50/M | GPT 便宜 50% |
| 輸出價格 | $25.00/M | $15.00/M | GPT 便宜 40% |
| 緩存輸入 | $0.50/M | $0.25/M | GPT 便宜 50% |
| 推理模式 | 自適應思維 (Adaptive) | 5 級推理 (none→xhigh) | 各有特色 |
| 電腦操控 | ✅ (72.7%) | ✅ (75.0%) | GPT 超越人類 |
| 代理團隊 | ✅ Agent Teams | ❌ | Claude 獨有 |
| 工具搜索 | ❌ | ✅ Token 降 47% | GPT 獨有 |
| 金融插件 | ❌ | ✅ Excel/Sheets | GPT 獨有 |
Claude Opus 4.6 與 GPT-5.4 的設計哲學差異
兩款模型的設計哲學截然不同:
Claude Opus 4.6 走的是"深度智能"路線。自適應思維(Adaptive Thinking)讓模型根據問題複雜度自動決定推理深度,無需手動設置預算。Agent Teams 功能允許一個主 Claude 實例派生多個獨立的子代理並行工作,通過共享任務列表和消息系統協調。這種架構設計更適合需要深度理解和長鏈推理的複雜編程任務。
GPT-5.4 走的是"全能工具人"路線。它首次將編程(繼承 GPT-5.3 Codex)、電腦操控、全分辨率視覺和工具搜索融合在一個通用模型中。工具搜索機制讓模型按需查找工具定義,Token 用量降低 47%。金融插件(Moody's、MSCI 等)和 ChatGPT for Excel 則瞄準企業級專業工作。
🎯 選型提示: 兩者的優勢領域幾乎互補。通過 API易 apiyi.com 可以一個 API Key 同時調用 Claude Opus 4.6 和 GPT-5.4,按場景靈活切換。
Claude Opus 4.6 vs GPT-5.4 基準測試詳細分析
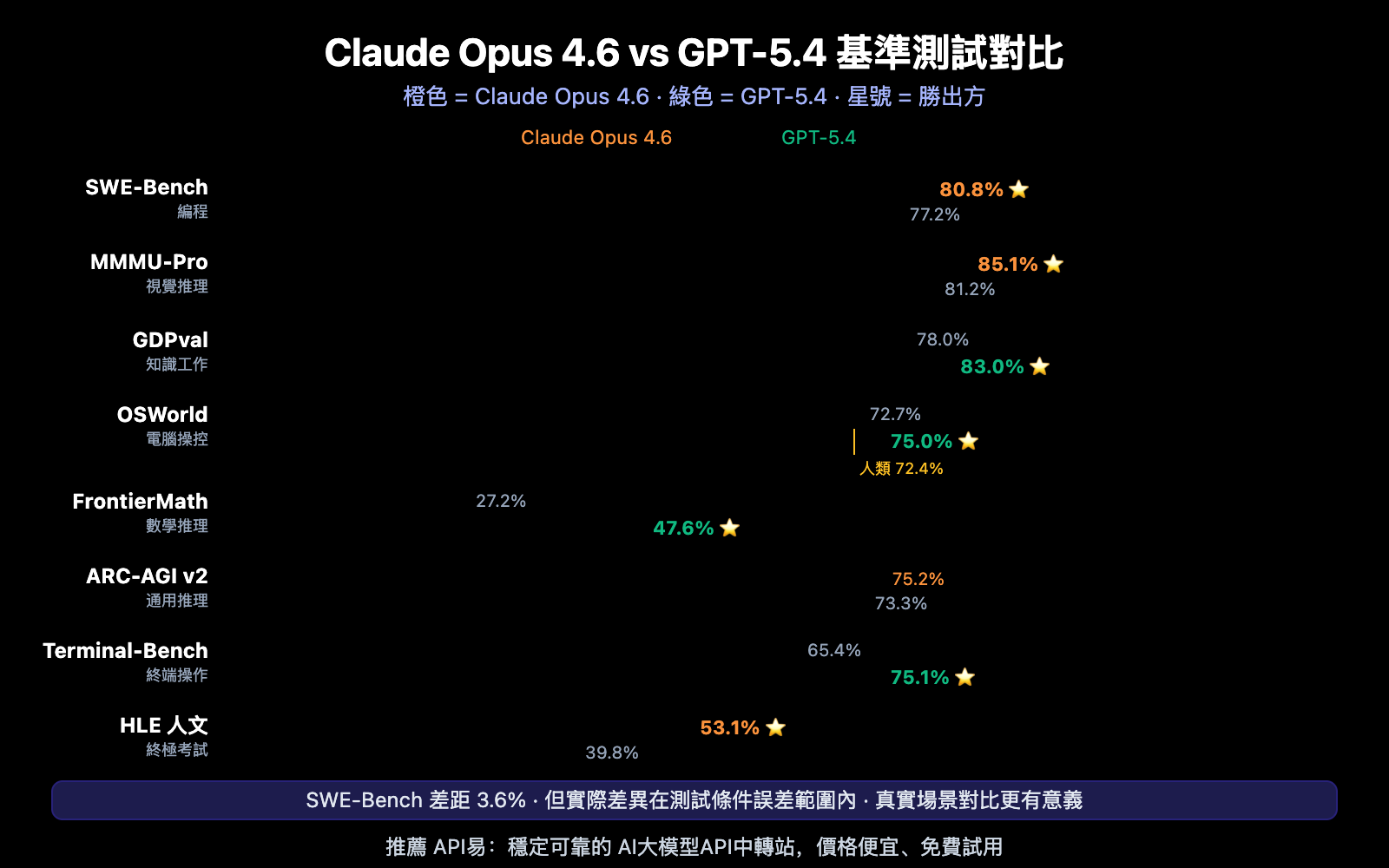
Claude Opus 4.6 vs GPT-5.4 完整基準測試表
| 基準測試 | Claude Opus 4.6 | GPT-5.4 | 差距 | 勝出 |
|---|---|---|---|---|
| SWE-Bench Verified | 80.8% | 77.2% | +3.6% | Claude |
| SWE-Bench Pro (高難度) | ~45.9% | 57.7% | +11.8% | GPT |
| MMMU-Pro 視覺推理 | 85.1% | 81.2% | +3.9% | Claude |
| GDPval 知識工作 | 78.0% | 83.0% | +5.0% | GPT |
| OSWorld 電腦操控 | 72.7% | 75.0% | +2.3% | GPT |
| FrontierMath 數學 | 27.2% | 47.6% | +20.4% | GPT |
| ARC-AGI v2 通用推理 | 75.2% | 73.3% | +1.9% | Claude |
| Terminal-Bench 終端 | 65.4% | 75.1% | +9.7% | GPT |
| Humanity's Last Exam | 53.1% | 39.8% | +13.3% | Claude |
| Tau2 Telecom | 99.3% | 98.9% | +0.4% | Claude |
| GPQA 研究生推理 | 91.3% | 92.8% | +1.5% | GPT |
| BrowseComp 網頁瀏覽 | 84.0% | 82.7% | +1.3% | Claude |
需要特別指出的是:80.0%、80.6% 和 80.8% 之間的 SWE-Bench 差異,實際上已經在測試條件的誤差範圍內。換句話說,在標準化編程基準上,兩者已經趨於收斂。真正的差異體現在代碼質量、架構理解和實際開發體驗上。
🎯 實測建議: 基準測試只是參考起點。建議通過 API易 apiyi.com 獲取免費額度,在你自己的項目中對比兩個模型的實際表現,這比任何基準測試都更有價值。
Claude Opus 4.6 vs GPT-5.4 獨有能力對比
Claude Opus 4.6 獨有優勢
1. Agent Teams(代理團隊)
Claude Opus 4.6 引入的 Agent Teams 是當前 AI 領域獨一無二的功能。一個主 Claude 實例(Lead)可以派生多個獨立的子代理(Teammates),每個子代理擁有完整的獨立上下文窗口,通過共享任務列表和消息系統並行協作。
在深度研究任務中,多代理技術將性能提升了約 15 個百分點。這種架構特別適合大型代碼庫的並行重構——主代理負責規劃,子代理分別處理不同模塊。
2. 自適應思維(Adaptive Thinking)
與 GPT-5.4 的手動 5 級推理等級不同,Claude 的自適應思維讓模型自動判斷問題複雜度並動態分配推理深度。在默認的 high 級別下,Claude 幾乎總會啓用思維鏈;在簡單問題上則自動跳過,節省 Token 和延遲。
自適應思維還支持交錯思維(Interleaved Thinking)——在工具調用之間穿插思考,這對代理式工作流特別有效。
GPT-5.4 獨有優勢
1. 原生電腦操控
GPT-5.4 是 OpenAI 首款內置原生電腦操控能力的通用模型。OSWorld 75.0% 直接超越人類基線 72.4%。它能通過 Playwright 代碼和直接鍵鼠指令兩種方式操作瀏覽器和桌面應用。
2. 工具搜索(Tool Search)
在擁有大量工具的系統中,傳統方式需要將所有工具定義一次性發送給模型。GPT-5.4 的工具搜索讓模型按需查找工具定義,Token 用量降低 47%,準確率不變。
3. 金融行業深度集成
ChatGPT for Excel/Google Sheets + Moody's/MSCI/FactSet 數據集成,讓 GPT-5.4 在金融分析領域形成了 Claude 目前無法匹敵的生態優勢。內部投行基準從 43.7% 提升到 87.3%。
🎯 API 接入: Claude Opus 4.6 和 GPT-5.4 均可通過 API易 apiyi.com 統一接口調用。GPT-5.4 定價同步官網($2.50/$15.00),充值 100 美金起送 10%。
Claude Opus 4.6 vs GPT-5.4 場景選型決策

Claude Opus 4.6 vs GPT-5.4 API 接入示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 複雜代碼重構 → Claude Opus 4.6
refactor = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "重構這個模塊的依賴注入"}]
)
# 超大項目全局分析 → GPT-5.4
analysis = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "分析整個項目的安全漏洞"}]
)
建議: 通過 API易 apiyi.com 註冊一個賬號即可同時調用兩大旗艦模型。GPT-5.4 定價同步官網,充值 100 美金起送 10%。切換模型只需修改一個參數。
常見問題
Q1: Claude Opus 4.6 和 GPT-5.4 哪個編程更強?
看維度。標準編程基準 SWE-Bench 上 Claude 以 80.8% vs 77.2% 領先,代碼質量和多文件重構能力也更優。但 GPT-5.4 在高難度 SWE-Bench Pro 上以 57.7% vs ~45.9% 反超,終端操作任務也大幅領先(75.1% vs 65.4%)。對大多數開發者來說,兩者的編程能力已經趨於收斂。
Q2: 價格差距大嗎?該怎麼選?
GPT-5.4 全面更便宜:輸入 $2.50 vs $5.00/M(50%),輸出 $15.00 vs $25.00/M(40%)。如果成本是主要考量,GPT-5.4 更合適。如果項目對代碼質量和架構理解要求極高,Claude 的溢價值得。建議通過 API易 apiyi.com 按場景混合使用兩者,優化成本。
Q3: 如何通過一個平臺同時使用兩個模型?
通過 API易 apiyi.com 註冊賬號:
- 獲取統一 API Key
- 設置
base_url爲https://vip.apiyi.com/v1 - 重構任務:
model="claude-opus-4-6" - 大項目分析:
model="gpt-5.4" - 日常任務:
model="gpt-5.3-chat-latest"(最省錢)
充值 100 美金起送 10%,一個賬號調用所有主流模型。
總結
Claude Opus 4.6 vs GPT-5.4 的核心結論:
- 編程和視覺推理選 Claude: SWE-Bench 80.8%、MMMU-Pro 85.1% 行業最高,代碼質量更乾淨,Agent Teams 多代理協作是獨有優勢
- 知識工作和自動化選 GPT: GDPval 83.0%、OSWorld 75.0% 超越人類,1M 上下文正式可用,API 價格便宜 40-50%
- 最聰明的策略是組合使用: 兩者的優勢領域幾乎互補——重構用 Claude,大項目分析和自動化用 GPT,日常任務用 GPT-5.3 Instant 省錢
SWE-Bench 上 80.8% vs 77.2% 的差距看起來不大,但在實際開發中,Claude 的架構理解力和代碼整潔度優勢仍然明顯。GPT-5.4 則憑藉 1M 上下文、電腦操控和更低定價在另一個維度建立了優勢。
推薦通過 API易 apiyi.com 統一接入兩大旗艦模型,一個 API Key 調用全部,充值 100 美金起送 10%。
📚 參考資料
-
GPT-5.4 vs Claude Opus 4.6 編程對比: 開發者視角的 SWE-Bench、代碼質量和 Agent 能力分析
- 鏈接:
blog.getbind.co/gpt-5-4-vs-claude-opus-4-6-which-one-is-better-for-coding/ - 說明: 最詳細的編程維度對比,含 SWE-Bench Pro 和 Terminal-Bench 數據
- 鏈接:
-
GPT-5.4 vs Opus 4.6 vs Gemini 3.1 Pro 三強對比: 12 項基準測試全維度分析
- 鏈接:
digitalapplied.com/blog/gpt-5-4-vs-opus-4-6-vs-gemini-3-1-pro-best-frontier-model - 說明: 定價、上下文、基準測試、優劣勢全覆蓋
- 鏈接:
-
Claude Opus 4.6 官方發佈公告: Agent Teams、自適應思維等新功能詳情
- 鏈接:
anthropic.com/news/claude-opus-4-6 - 說明: 瞭解 Claude 獨有功能的第一手資料
- 鏈接:
-
Claude Opus 4.6 自適應思維 API 文檔: 開發者集成指南
- 鏈接:
platform.claude.com/docs/en/build-with-claude/adaptive-thinking - 說明: 瞭解自適應思維的具體使用方法和參數設置
- 鏈接:
作者: APIYI 技術團隊
技術交流: 歡迎在評論區討論,更多資料可訪問 API易 docs.apiyi.com 文檔中心