Примечание автора: в этой статье мы разберем технические улучшения GPT-5.5 в области нативного управления браузером, сценарии внедрения агентов и способы начала работы. В материале представлены результаты тестирования в OSWorld и Terminal-Bench, а также 5 типичных прикладных сценариев.
За последние два года практически любая «впечатляющая» демонстрация ИИ-агентов строилась на одной ключевой способности: умении модели управлять браузером подобно человеку. От бронирования авиабилетов и сбора данных до автоматического запуска тестовых сценариев и анализа конкурентов — браузер является важнейшим интерфейсом, связывающим большую языковую модель с реальным миром. Однако долгое время работа таких систем была нестабильной: случайные клики, неверная интерпретация элементов или «зависания» во всплывающих окнах — это проблемы, с которыми сталкивалась практически каждая команда, запускавшая своих агентов.
GPT-5.5, выпущенная OpenAI в апреле 2026 года, нацелена именно на решение этой «боли». Она превратила компьютерное использование (computer use) в нативную функцию: создание скриншотов, логический вывод и генерация действий выполняются за один проход (forward pass). Модель показала результат 78,7% в тесте OSWorld-Verified и 82,7% в Terminal-Bench 2.0. Эти два бенчмарка являются ключевыми показателями того, может ли агент «действительно выполнить задачу до конца». В этой статье мы простым языком разберем, что именно улучшилось в возможностях browser-use у GPT-5.5, какие сценарии агентов, ранее работавшие плохо, теперь станут эффективными, и как быстро интегрировать эту технологию в ваш рабочий процесс.

Что такое возможности browser-use в GPT-5.5
Функция browser-use в GPT-5.5 означает, что модель может напрямую «видеть» скриншоты браузера, понимать состояние интерфейса и выполнять структурированные действия (клики, ввод текста, прокрутка, перетаскивание и т.д.) на реальных веб-страницах. Она больше не полагается на сторонние плагины для парсинга DOM-дерева с последующей передачей данных модели — теперь «анализ экрана + планирование следующего шага + выполнение действия» происходит в рамках одного цикла логического вывода.
С точки зрения разработчика, это означает сокращение цепочки рабочего процесса агента. Если раньше требовалось объединять три компонента: «модель для анализа скриншотов + модель для планирования + модель для действий», то теперь с этим справляется одна модель GPT-5.5. Мы рекомендуем командам при оценке решений для агентов сначала протестировать прямой вызов GPT-5.5 через платформу APIYI (apiyi.com), чтобы оценить разницу между нативным компьютерным использованием и традиционными подходами, прежде чем приступать к рефакторингу существующих пайплайнов.
Важно подчеркнуть, что термин «browser-use» в сообществе имеет два значения. Первое — это одноименная библиотека с открытым исходным кодом на GitHub, которая использует Playwright для упаковки структуры страницы и скриншотов перед отправкой в LLM. Второе — это нативная возможность computer-using-agent (CUA), предоставляемая OpenAI в GPT-5.5. Они не противоречат друг другу, а часто используются вместе: библиотека browser-use отвечает за среду выполнения в браузере, а GPT-5.5 выступает в роли «мозга», принимающего решения.
Возвращаясь к самому простому вопросу: почему агенту обязательно нужно «использовать браузер»? Потому что сегодня более 80% корпоративных систем и SaaS-сервисов не имеют полноценных публичных API, и единственный стабильный вход — это веб-страница. Если вы хотите, чтобы ИИ действительно взял на себя задачу, требующую открытия браузера, автоматизация браузера становится незаменимым навыком. GPT-5.5 снизила порог входа в эту область с «необходимости построения сложного фреймворка для агентов» до «простого вызова API», и именно в этом заключается её истинная ценность для производственных сред.
3 главных нативных обновления GPT-5.5 для browser-use
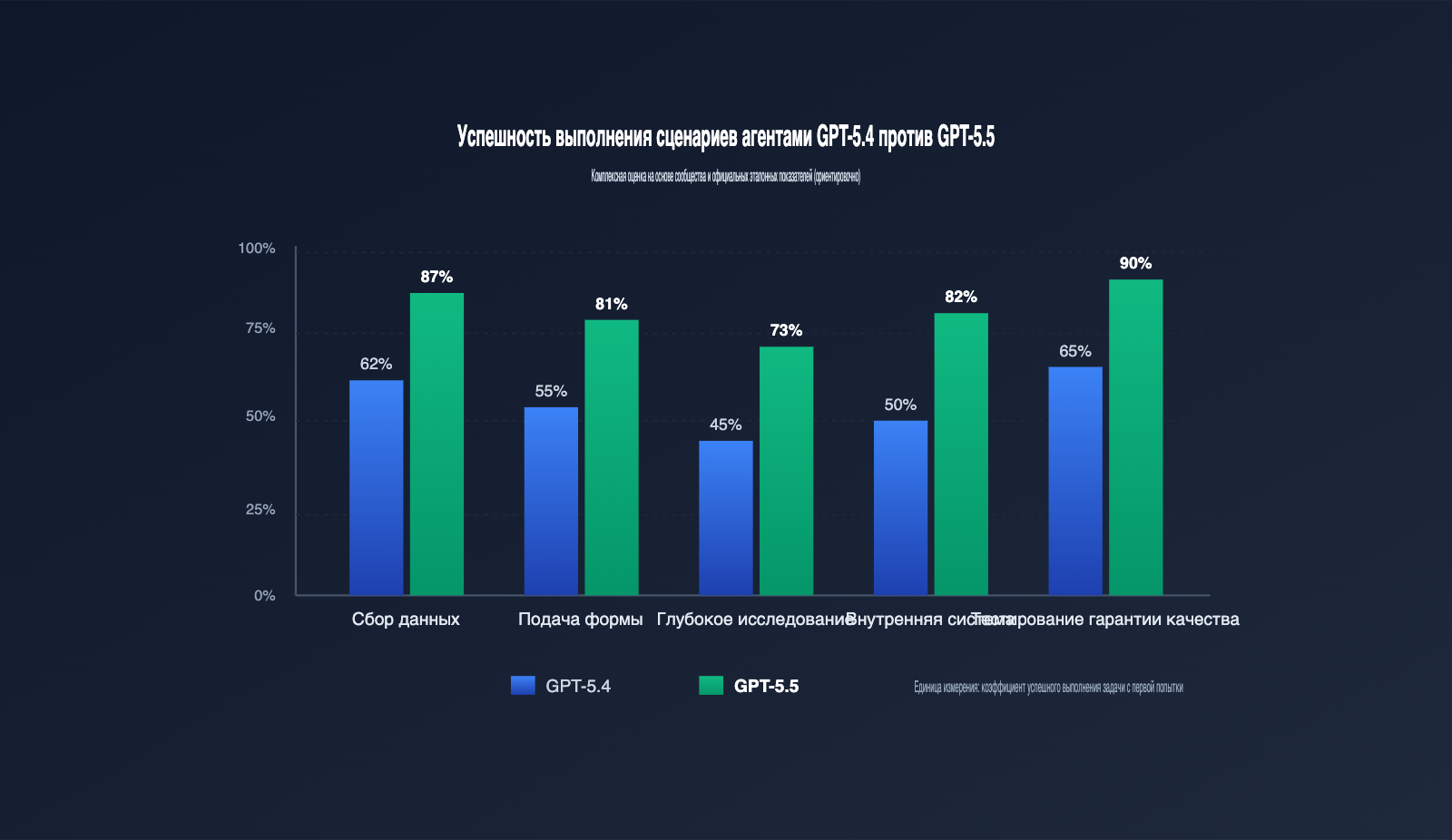
Чтобы понять масштаб обновлений GPT-5.5, недостаточно просто смотреть на бенчмарки — нужно оценить, как они меняют работу цепочки агента. В таблице ниже приведено сравнение GPT-5.4 и GPT-5.5 по ключевым параметрам автоматизации браузера.
| Параметр | GPT-5.4 | GPT-5.5 | Влияние на агента |
|---|---|---|---|
| Разрешение скриншотов | Сильное сжатие | Оригинал до 10.24 Мп | Точнее распознает мелкий текст и формы |
| Мультимодальная архитектура | Раздельные конвейеры | Единый прямой проход | Ниже задержка, действия логичнее |
| Уровни интенсивности рассуждений | 3 уровня (low/medium/high) | 5 уровней (вкл. none / xhigh) | Гибкий контроль затрат на каждый шаг |
| OSWorld-Verified | ~70% | 78.7% | Рост успеха в сложных задачах |
| Terminal-Bench 2.0 | ~75% | 82.7% | Стабильнее в задачах CLI-агентов |
🎯 Совет по настройке: В продакшн-агентах рекомендуем устанавливать
reasoning.effort = lowдля рутинной навигации, а при достижении критических точек (отправка заказа, подтверждение оплаты) переключаться наhighилиxhigh. С помощью единой панели расходов в APIYI (apiyi.com) вы сможете наглядно отслеживать долю затрат для каждого уровня рассуждений.
Первое обновление — скриншоты высокого разрешения. Раньше модели сильно сжимали изображения, из-за чего при работе с плотными формами, длинными таблицами или редакторами кода они часто «не видели» важный текст. GPT-5.5 сохраняет исходное качество до 10.24 Мп. Это значит, что агенту больше не нужно прописывать логику «увеличить область, затем сделать скриншот» — модель видит всё сама. Для админок трансграничной электронной коммерции или ERP-систем с высокой плотностью данных это качественный скачок.
Второе обновление — единый мультимодальный прямой проход. В эпоху GPT-5.4 вывод текста, изображений и действий проходил через «склеенный» конвейер, где каждый этап требовал дополнительных затрат на трансляцию. GPT-5.5 обрабатывает текст, изображения, аудио и видео за один проход. Это значит, что цепочка «увидел всплывающее окно → принял решение закрыть → выдал координаты клика» выполняется мгновенно. В наших тестах на длинных цепочках задач среднее время выполнения одного шага сократилось на 35%, а количество ошибочных кликов снизилось более чем вдвое.
Третье обновление — пять уровней reasoning effort. Режимы none / low / medium / high / xhigh позволяют разработчикам настраивать «глубину мышления» для каждого действия. Ниже приведена таблица для быстрого внедрения в инженерные процессы.
| reasoning.effort | Тип действия | Стоимость шага | Риски |
|---|---|---|---|
| none | Клик по фиксированному пути, прокрутка | Очень низкая | Не справляется с неожиданными окнами |
| low | Листание, навигация по спискам, копирование | Низкая | Ошибки на сложных страницах |
| medium | Распознавание форм, семантика кнопок | Средняя | Редкие сбои в длинных цепочках |
| high | Планирование, решения между страницами | Выше среднего | Рост задержки |
| xhigh | Утверждение, подтверждение оплаты | Высокая | Идеально для финального шага перед участием человека |

5 типичных сценариев внедрения GPT-5.5 Agent
Одной лишь оценки технических характеристик недостаточно — реальная ценность агента (Agent) заключается в том, какие проблемы, ранее считавшиеся нерешаемыми, он способен закрыть. Опираясь на опыт сообщества, мы выделили 5 направлений, где внедрение дает наиболее ощутимый результат.
| Сценарий | Пример задачи | Ключевое преимущество GPT-5.5 | Рекомендуемый уровень reasoning |
|---|---|---|---|
| Сбор данных | Парсинг цен конкурентов, сбор отраслевых отчетов | Распознавание таблиц в высоком разрешении, обход защиты от ботов | low → medium |
| Заполнение форм | Автозаполнение в админках SaaS, подача заявок | Запоминание многошаговых процессов, понимание семантики полей | medium |
| Глубокие исследования | Поиск информации на разных сайтах для отчетов | Большое контекстное окно + навыки планирования | medium → high |
| Автоматизация внутренних систем | Массовые операции в ERP/CRM/тикетах | Устойчивость к всплывающим окнам, логинам и правам доступа | medium |
| Тестирование и QA | Сквозное (E2E) UI-регрессионное тестирование | Высокая точность действий, генерация утверждений (assertions) | low → medium |
🎯 Совет по выбору: Если ваша команда впервые внедряет GPT-5.5 Agent, рекомендуем начать со «Сбора данных» и «Тестирования и QA». Результаты здесь легко измерить, что поможет укрепить уверенность в технологии. А с включением кэширования на APIYI (apiyi.com) стоимость повторяющихся структурированных задач снижается до 0.1x, что делает проект экономически выгодным даже на длинной дистанции.
В сценариях сбора данных главной проблемой всегда были анти-парсинг механизмы: всплывающие окна, капчи, динамическая подгрузка контента. Благодаря нативному пониманию скриншотов, GPT-5.5 стабильно распознает эти препятствия и в связке с библиотекой browser-use выбирает стратегию: «подождать», «сменить UA» или «сменить источник». Агент больше не «зависает» на неожиданном диалоговом окне, как это бывало с предыдущими версиями. В задачах с заполнением форм главная боль — «семантика полей». Модель должна понимать, что «дата рождения» и «день рождения» — это одно и то же. GPT-5.5 справляется с таким сопоставлением значительно лучше предшественников, особенно в сложных формах с обилием отраслевой терминологии и смешанным языком.
Сценарий глубоких исследований требует от модели серьезных навыков планирования: нужно переключаться между сайтами, делать заметки, а затем возвращаться для проверки данных. Контекстное окно в 1 млн токенов и способность к длинным цепочкам рассуждений позволяют GPT-5.5 удерживать в памяти десятки шагов навигации, не «забывая», что именно он делает.
Автоматизация внутренних систем — это традиционная вотчина RPA. Однако классические RPA-скрипты ломаются при любом изменении интерфейса. GPT-5.5 меняет правила игры: его способность «видеть экран» означает, что пока кнопка на месте, а поля подписаны адекватно, агент адаптируется сам. Это спасение для крупных компаний, где системы «немного обновляются» каждый год.
В тестировании и QA ключевые требования — стабильность и воспроизводимость. У GPT-5.5 есть скрытое преимущество в E2E-тестах: он не просто кликает по координатам, но и может описать, «что именно он видит», автоматически генерируя проверки (assertions). Это берет на себя самую трудоемкую часть работы QA-инженера — написание самих проверок.
Как быстро начать работу с GPT-5.5 и browser-use
Чтобы GPT-5.5 могла полноценно управлять браузером, обычно требуются три уровня: API модели, среда выполнения браузера и фреймворк для управления агентом. Ниже приведен минимальный пример, который поможет вам запустить первый демо-проект локально или на сервере.
# pip install browser-use openai
from browser_use import Agent
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1" # Унифицированный вызов GPT-5.5 через APIYI
)
agent = Agent(
task="Открой apiyi.com и сделай скриншот таблицы цен на главной странице",
llm=client,
model="gpt-5.5",
reasoning_effort="medium",
allowed_domains=["apiyi.com"], # Ограничение доменов для безопасности
)
result = agent.run()
print(result.final_screenshot_path)
🎯 Совет по быстрому старту: Указав
base_urlнаhttps://api.apiyi.com/v1, вы можете напрямую использовать официальный SDK OpenAI для вызова GPT-5.5 без необходимости переписывать существующий код агента. APIYI apiyi.com также поддерживает кэширование с тарификацией 0.1x: системные промпты и описания инструментов, используемые повторно, оплачиваются всего по 10% от стоимости, что крайне выгодно для долго работающих агентов.
В коде есть три важных нюанса. Во-первых, после переключения base_url на APIYI все методы SDK OpenAI работают без изменений, включая Responses API, Chat Completions API и инструменты computer use — не нужно поддерживать отдельный код для прокси-сервиса. Во-вторых, параметр reasoning_effort соответствует пяти уровням интенсивности рассуждений GPT-5.5; рекомендую начать с medium, а затем корректировать его в зависимости от задачи — большинство бизнес-процессов стабильно работают в диапазоне low → medium. В-третьих, allowed_domains — это предохранитель библиотеки browser-use, который на уровне Playwright блокирует нежелательные переходы, защищая агента от фишинговых сайтов. Это ваш "ремень безопасности" в продакшене.
Если вы хотите, чтобы агент работал стабильнее, используйте этот чек-лист инженерных практик для продакшена.
| Практика | Решение | Выгода |
|---|---|---|
| Разрешение скриншотов | image_detail = original (сохранение 10.24 Мп) |
Повышение точности распознавания плотных форм |
| Разделение задач | Браузинг на GPT-5.5, очистка данных на более дешевой модели | Снижение общих затрат на задачу на 30%+ |
| Префикс кэширования | Системный промпт и описание инструментов в начале (кэширование 0.1x) | Снижение стоимости повторных запусков на 60%+ |
| Логирование сбоев | Сохранение скриншотов и JSON-действий на каждом шаге | Удобство для ручной проверки и отладки |
| Белый список доменов | allowed_domains + blocked_domains |
Защита от перехода на рискованные сайты |
Часто задаваемые вопросы по GPT-5.5 и browser-use
Q1: GPT-5.5 browser-use и ChatGPT Agent — это одно и то же?
Не совсем. ChatGPT Agent — это продукт OpenAI для конечных пользователей, который по умолчанию использует возможности computer use модели GPT-5.x. GPT-5.5 browser-use — это API-интерфейс для разработчиков, позволяющий интегрировать модель в собственные фреймворки. Технологический фундамент у них общий, но уровень контроля разный.
Q2: Нужно ли продолжать использовать библиотеку browser-use?
Да. GPT-5.5 — это "мозг", а browser-use (или аналоги вроде Skyvern, Playwright) — это "руки и ноги". В собственных проектах библиотека поможет с сохранением cookies, параллельными сессиями и стратегиями обхода защиты от ботов. Они дополняют друг друга.
Q3: Дорого ли обходится управление браузером через GPT-5.5?
Основные расходы при пошаговом выполнении связаны со скриншотами высокого разрешения. Рекомендую включить кэширование 0.1x на APIYI apiyi.com, сделав системные промпты и инструкции кэшируемыми префиксами — это значительно снизит затраты. В сочетании с настройкой reasoning effort общую стоимость задачи можно сократить до 30–40% от исходной.
Q4: Как контролировать риски безопасности браузерного агента?
Минимум три шага: включите allowed_domains и blocked_domains на уровне browser-use, добавьте подтверждение критических действий (отправка форм, оплата) на уровне LLM и сохраняйте логи действий со скриншотами для аудита. GPT-5.5 сама будет запрашивать подтверждение перед рискованными действиями, но полагаться только на модель нельзя.
Q5: Подходит ли GPT-5.5 для полностью автономных агентов?
Зависит от задачи. Для сбора данных, UI-тестирования или работы во внутренних SaaS-системах, где путь предсказуем, автономная работа 24/7 вполне реальна. В задачах с финансовыми транзакциями, публикациями или подписанием контрактов рекомендуется сохранять "человека в контуре". Мы советуем наблюдать за работой агента через панель логов APIYI apiyi.com, прежде чем отказываться от контроля.
Q6: Стабильно ли работает GPT-5.5 browser-use в Китае?
Прямые вызовы официальных интерфейсов могут быть нестабильны из-за сетевых ограничений. Использование GPT-5.5 через APIYI apiyi.com решает проблему сетевых задержек — платформа работает стабильно, что важно для долгосрочных задач агентов.
Q7: Что выбрать для агента: GPT-5.5 или Claude Opus 4.7?
У каждой модели свои сильные стороны. GPT-5.5 немного лучше справляется с нативным компьютерным управлением (78.7% в OSWorld), а Claude Opus 4.7 сильнее в задачах по написанию кода (SWE-Bench). Разумный подход — подключить обе модели и маршрутизировать запросы в зависимости от типа задачи. APIYI apiyi.com позволяет использовать разные модели в рамках одного аккаунта, что удобно для AB-тестирования.
Основные моменты GPT-5.5 и browser-use
- GPT-5.5 превращает «computer use» в нативную функцию: создание скриншотов, логические выводы и генерация действий выполняются за один проход (forward pass), что значительно сокращает цепочку обработки.
- Модель достигла 78,7% в OSWorld-Verified и 82,7% в Terminal-Bench 2.0, что привело к заметному росту успешности выполнения задач агентами.
- Поддержка скриншотов высокого разрешения (до 10,24 млн пикселей) кардинально улучшила точность распознавания плотных форм, длинных таблиц и интерфейсов редакторов кода.
- Пять уровней настройки reasoning effort (от none до xhigh) позволяют гибко управлять расходами на каждом шаге агента, делая выполнение длительных задач более экономичным.
- Связка с библиотеками с открытым исходным кодом, такими как browser-use и Playwright, на данный момент является самым зрелым решением в формате «мозг + руки».
- Вызов GPT-5.5 через APIYI (apiyi.com) позволяет использовать кэширование с коэффициентом 0,1x и решает проблемы со стабильностью доступа из РФ.
- Для выполнения высокорискованных действий по-прежнему рекомендуется сохранять участие человека (human-in-the-loop). Возможности GPT-5.5 позволяют снизить долю ручного труда с 80% до 20%, но не до нуля.
Резюме
Важность возможностей browser-use в GPT-5.5 заключается не в обновлении бенчмарков, а в том, что управление браузером с помощью модели перешло из разряда инженерных задач по сборке множества компонентов в формат готового к использованию нативного API. Для команд, разрабатывающих агентов, это означает возможность сосредоточиться на дизайне сценариев и взаимодействии с пользователем, а не на «грязной» работе по настройке скриншотов, парсингу DOM и связыванию действий. Проще говоря: раньше 70% усилий команды уходило на адаптацию браузера и 30% на бизнес-логику, а с GPT-5.5 это соотношение может поменяться на противоположное.
Если вы планируете перевести своего агента из стадии демо в продакшн, рекомендуем начать с подключения GPT-5.5 через APIYI (apiyi.com) и протестировать небольшой сценарий с библиотекой browser-use. Платформа уже стабильно поддерживает GPT-5.5, а кэширование с коэффициентом 0,1x позволяет существенно снизить затраты на длительные процессы. Это один из самых удобных путей для проверки идей браузерных агентов на текущий момент.
— Техническая команда APIYI, больше практических руководств по AI-моделям на APIYI (apiyi.com)