При использовании Claude API для вызовов с длинным контекстом многие разработчики сталкиваются с одним и тем же недоумением: вы явно объявили кэширование в поле cache_control, но в ответе значения cache_creation_input_tokens и cache_read_input_tokens по-прежнему равны 0, а в счетах нет никаких скидок за кэширование. В этой статье мы систематически разберем 5 основных причин, по которым не срабатывает Claude prompt caching, и подробно остановимся на «минимальном пороге токенов для кэширования» и механизме «тихого сбоя», которые чаще всего упускают из виду.
Ключевая ценность: Прочитав эту статью, вы узнаете о минимальных порогах кэширования для различных моделей Anthropic, поймете, почему короткие промпты с cache_control не выдают ошибок, но и не кэшируются, а также научитесь проверять попадание в кэш с помощью 4 строк кода.
Основные моменты Claude prompt caching
Claude prompt caching — это механизм кэширования промптов от Anthropic: он позволяет сохранять повторяющиеся системные промпты, длинные документы и определения инструментов во временном кэше. При следующем обращении стоимость чтения из кэша будет примерно на 90% ниже стандартной цены за ввод. Ключевыми характеристиками являются «префиксное совпадение + явное объявление + тихий сбой» — именно эти три фактора определяют, в каком направлении вам стоит искать причину проблем.
| Пункт | Описание | Важность для отладки |
|---|---|---|
| Явное объявление | Необходимо вставить блок cache_control в system, messages или tools |
Если пропустить или указать неверно, кэширования не будет |
| Префиксное совпадение | Требует побайтового совпадения всего контента перед кэшируемым блоком | Даже лишний пробел приведет к сбою |
| Тихий сбой | Запросы, не соответствующие условиям, выполняются нормально, без ошибок и кэширования | Необходимо активно проверять поле usage |
| Ограничение TTL | По умолчанию 5 минут, максимум 1 час | При редких вызовах кэш будет истекать |
«Тихий сбой» — это часть механизма, на которой чаще всего «спотыкаются» разработчики. Документация Anthropic четко указывает: если ваш запрос не соответствует условиям кэширования (например, недостаточная длина или изменение префикса), API вернет обычный ответ, но не создаст кэш, не прочитает его и не выдаст ошибку. Это означает, что вы не увидите никаких исключений в коде, поэтому вам придется самостоятельно проверять объект usage в ответе.
Если вы вызываете модели Claude серий Sonnet, Opus или Haiku через платформу APIYI (apiyi.com), логика кэширования полностью идентична официальному интерфейсу Anthropic. Рекомендуем перед запуском в продакшн вывести в лог поле usage, чтобы убедиться, что кэширование действительно работает.
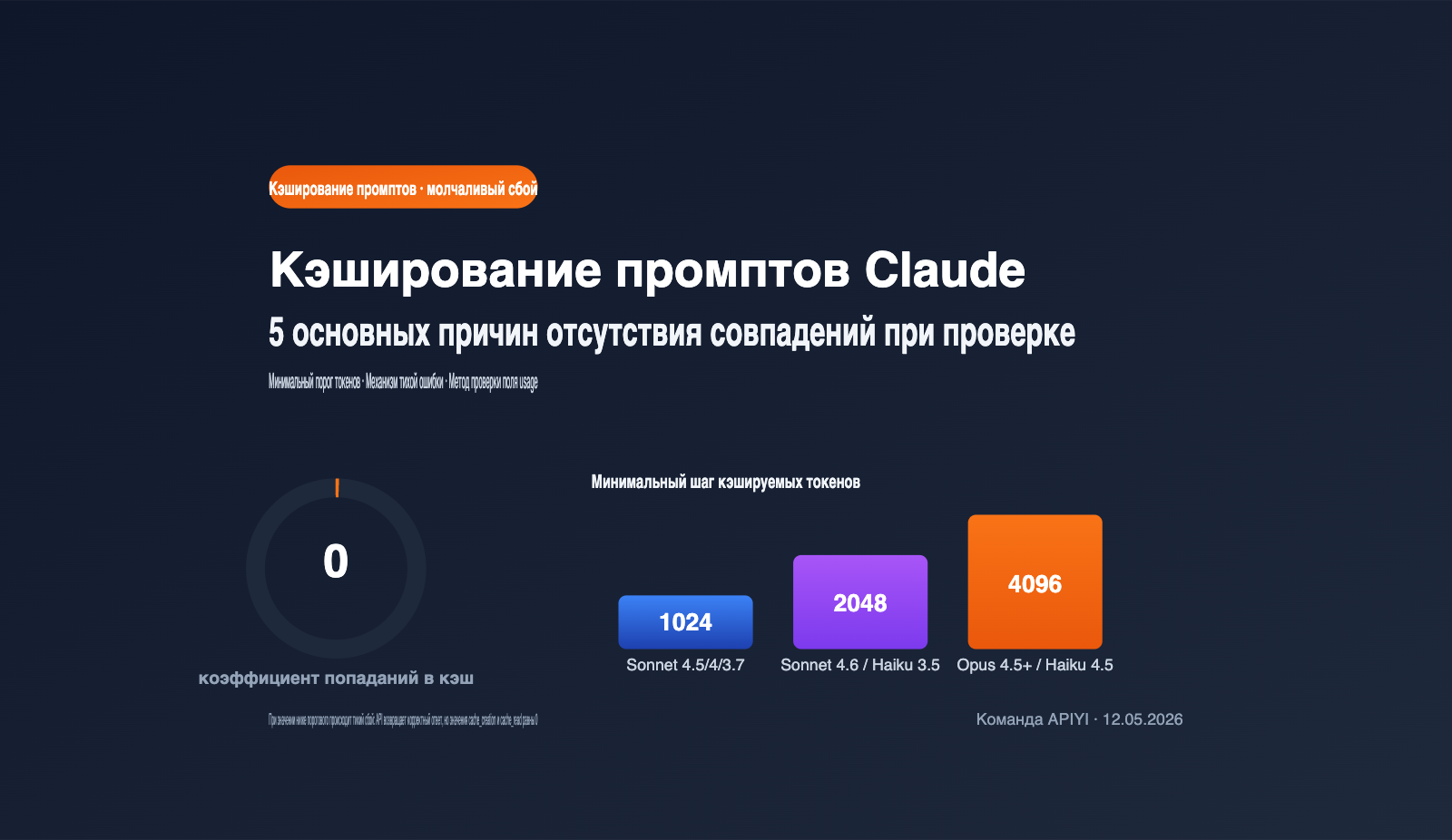
Быстрый справочник: минимальный порог токенов для Claude prompt caching
Самая частая причина, по которой кэширование не срабатывает — это недостаточная длина промпта. Если она не достигает минимального порога, установленного Anthropic для конкретной модели, то даже при наличии cache_control запрос будет обрабатываться как обычный. Пороги сильно различаются в зависимости от модели. Ниже приведена актуальная таблица с официальными данными на май 2026 года — рекомендую сохранить её в закладки.
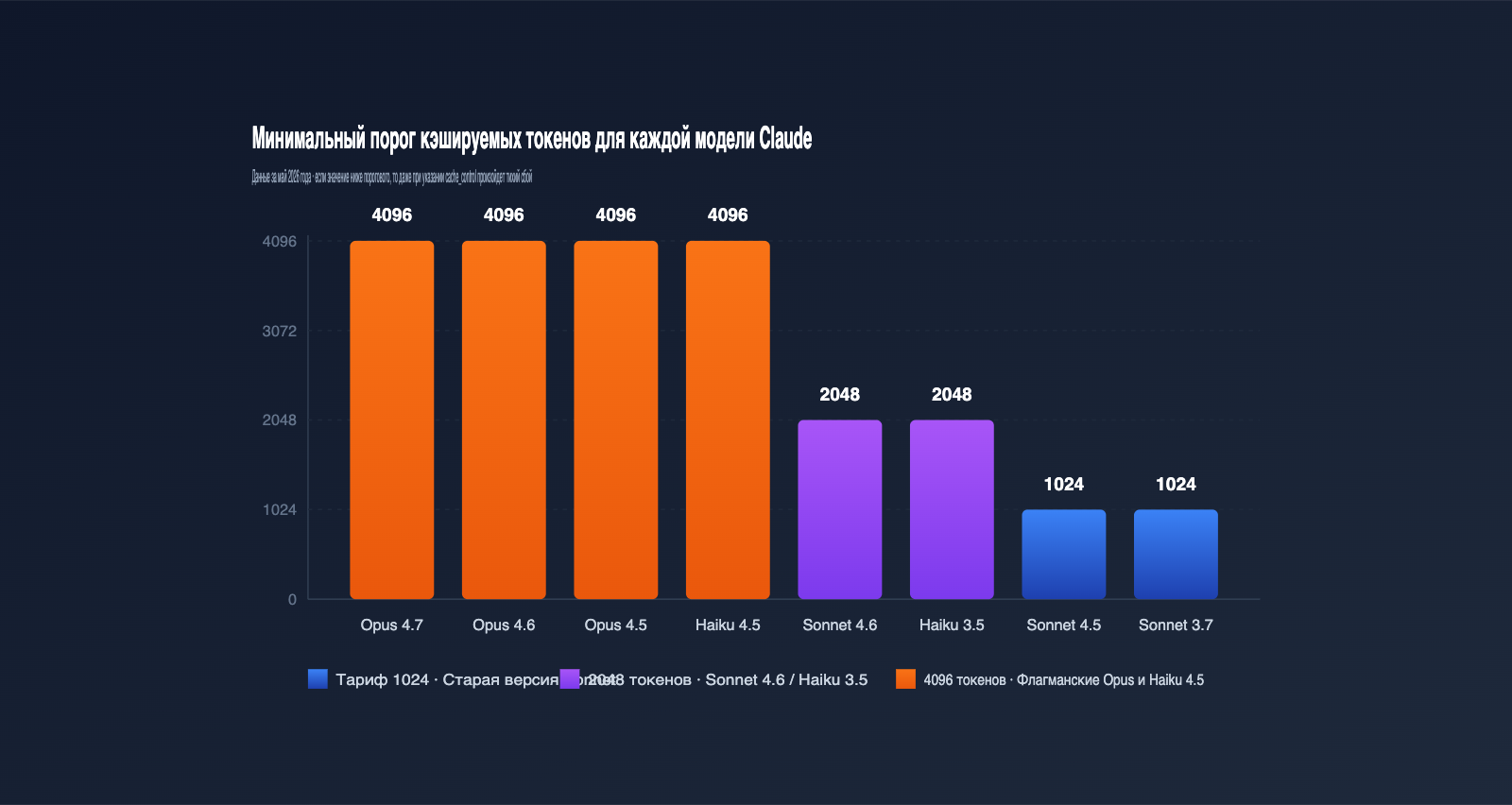
| Модель | Мин. токенов для кэша | Примечание |
|---|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 | Флагман, самый высокий порог |
| Claude Sonnet 4.6 | 2048 | Основная модель, порог удвоен |
| Claude Sonnet 4.5 / Sonnet 4 / Sonnet 3.7 | 1024 | Классика серии Sonnet |
| Claude Opus 4.1 / Opus 4 | 1024 | Предыдущее поколение Opus |
| Claude Haiku 4.5 | 4096 | У Haiku порог выше, чем у Sonnet |
| Claude Haiku 3.5 | 2048 | Стабильная быстрая модель |
Многих удивляет, почему у «маленькой» Haiku 4.5 такой же высокий порог, как у Opus 4.7. Всё дело в том, что новое поколение Haiku использует более длинное окно внимания, и кэширование имеет смысл только при работе с большими префиксами.
Самая частая ошибка разработчиков — перенос привычки использовать порог 1024 (как в Sonnet 3.7) на новые модели. Если вы используете APIYI (apiyi.com) для работы с разными версиями Claude, настоятельно рекомендую сделать проверку порога динамической, основываясь на поле model в вашем коде.
5 причин, почему Claude prompt caching не срабатывает
Разобравшись с «минимальным порогом», можно систематизировать поиск проблем. Вот 5 основных причин, отсортированных по частоте возникновения.
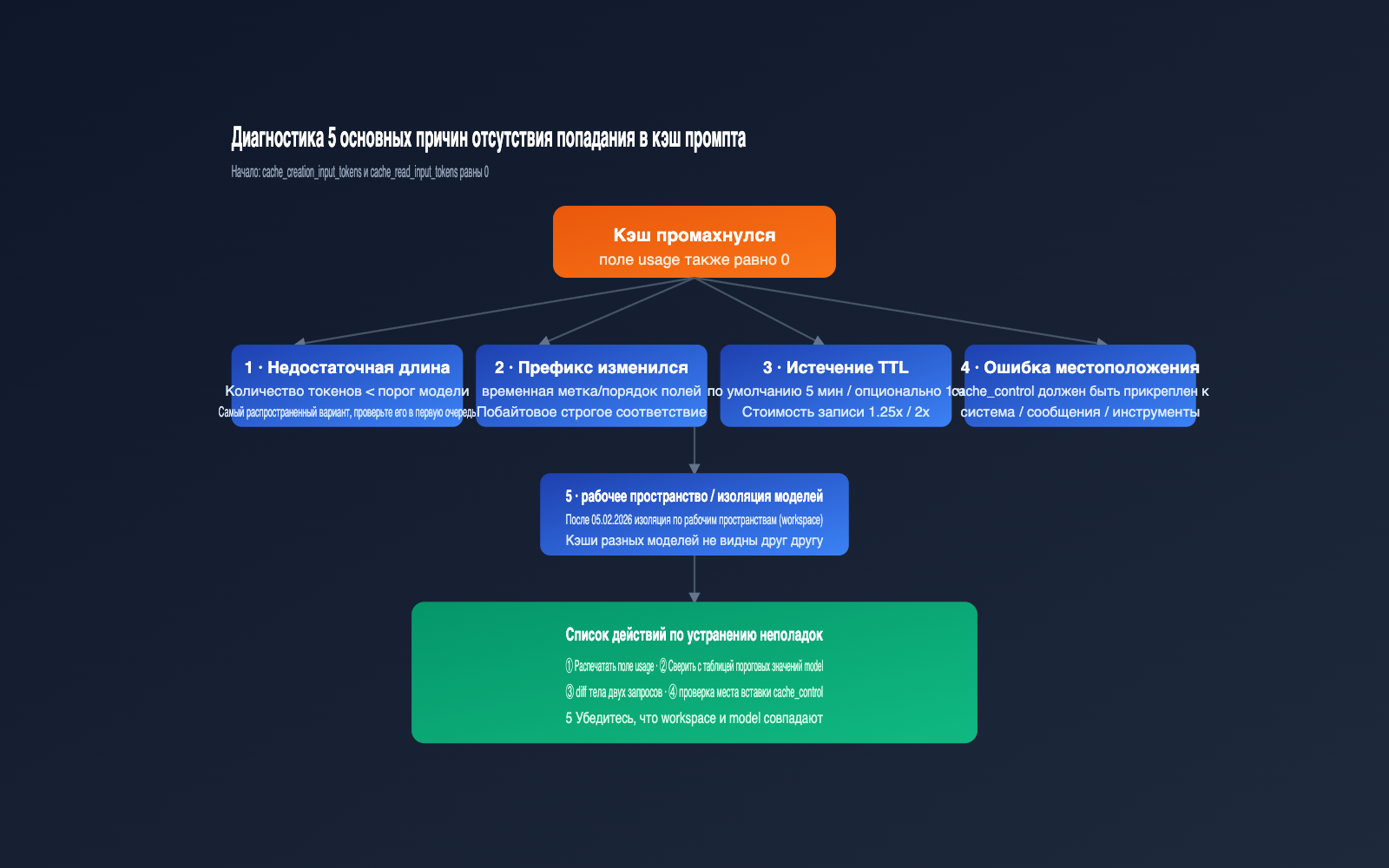
Причина 1: Длина промпта ниже порога
Это главная причина. Если вы объявили кэширование для Sonnet 4.6, но системный промпт занимает всего 1500 токенов, кэш не создастся. Решение: оцените общий объем токенов (системный промпт + инструменты + кэшируемые сообщения) с помощью локального токенизатора и сравните с таблицей.
Причина 2: Любые изменения в байтах префикса
Кэширование требует строгого совпадения префикса. Даже один измененный символ делает кэш недействительным. Частые проблемы:
- Динамические данные (например, временные метки) в системном промпте.
- Недетерминированная сериализация словарей (в Python порядок полей может меняться).
- Обрезка (trim) или дедупликация истории сообщений.
Совет: делайте diff полезной нагрузки (payload) двух запросов. Если вы используете APIYI (apiyi.com) как шлюз, хешируйте тело запроса в логах, чтобы быстро заметить «дрейф» префикса.
Причина 3: Истек TTL
По умолчанию TTL составляет 5 минут. Если интервал между запросами больше, кэш удаляется. Если вы видите, что cache_creation_input_tokens в ответе больше нуля, значит, кэш не сработал. Попробуйте сократить интервал или установить "ttl": "1h".
Причина 4: Ошибка в расположении cache_control
cache_control должен быть привязан к конкретному блоку контента в массивах system, messages или tools, а тип должен быть ephemeral. Не ставьте его в корень запроса. Кэш фиксирует всё содержимое от начала промпта до конца блока, в котором указан cache_control.
Причина 5: Разные рабочие области (workspace) или модели
С 5 февраля 2026 года кэш изолирован на уровне рабочей области. Если вы используете разные API-ключи или разные workspace, кэш не будет общим. То же самое касается моделей: кэш, созданный для Sonnet 4.6, не сработает при вызове Sonnet 4.5. При работе через агрегаторы вроде APIYI старайтесь использовать один и тот же upstream-workspace для эффективного переиспользования кэша.
Проверка попадания в кэш Claude и логика принятия решений
Первый шаг при отладке проблем с кэшированием — это всегда «вывод поля usage». В каждом ответе messages.create от Anthropic содержится объект usage с 4 ключевыми полями. Это единственный надежный способ понять, работает ли кэширование.
Минималистичный код для проверки
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[{
"type": "text",
"text": LONG_SYSTEM_PROMPT, # Должно быть ≥ 2048 токенов
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "your question"}]
)
u = response.usage
print(f"Запись в кэш: {u.cache_creation_input_tokens}")
print(f"Чтение из кэша: {u.cache_read_input_tokens}")
print(f"Ввод без кэширования: {u.input_tokens}")
Используйте этот код как шаблон для отладки. Если подозреваете, что кэш не работает, первым делом запустите этот скрипт — значения полей сразу укажут на причину.
Посмотреть полную версию с оберткой
import anthropic
import logging
MIN_TOKENS = {
"claude-opus-4-7": 4096,
"claude-opus-4-6": 4096,
"claude-opus-4-5": 4096,
"claude-sonnet-4-6": 2048,
"claude-sonnet-4-5": 1024,
"claude-haiku-4-5": 4096,
"claude-haiku-3-5": 2048,
}
def call_with_cache_check(model: str, system_text: str, user_msg: str):
client = anthropic.Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model=model,
max_tokens=1024,
system=[{
"type": "text",
"text": system_text,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": user_msg}]
)
u = response.usage
if u.cache_creation_input_tokens == 0 and u.cache_read_input_tokens == 0:
logging.warning(
f"Кэш не сработал, возможно, объем ниже порога в {MIN_TOKENS.get(model)} токенов"
)
return response
Таблица статусов попадания в кэш
cache_creation_input_tokens |
cache_read_input_tokens |
Вывод |
|---|---|---|
| > 0 | = 0 | Первая запись в кэш (норма) |
| = 0 | > 0 | Попадание в кэш (идеально) |
| > 0 | > 0 | Частичное попадание, новые данные записаны |
| = 0 | = 0 | Кэширование не сработало, нужно проверять причины |
Последняя строка — это признак проблемы. Если видите её, сразу переходите к списку из 5 основных причин и проверяйте их по порядку. Если для вашей команды важна стабильность API, можно обернуть эту логику в middleware на стороне сервиса-прокси API APIYI (apiyi.com), чтобы получать мгновенные уведомления при сбоях.
4 практических способа набрать минимальный порог токенов
Если вы убедились, что кэш не срабатывает из-за недостаточной длины, пора «добить» префикс до нужного порога. Вот 4 способа, отсортированных по эффективности; первые три практически не имеют побочных эффектов.
| Техника | Сценарий | Доп. токены | Примечание |
|---|---|---|---|
| Полная база знаний | Короткий системный промпт | +2000–4000 | Должна быть полезна |
| Централизация инструментов | Приложения с инструментами | +500–2000 | Поле tools тоже кэшируется |
| Few-shot примеры | Сложные задачи | +1000–3000 | Примеры должны быть качественными |
| Заполнение «мусором» | Экстренный случай | Любое | Не рекомендуется, портит результат |
Первый вариант («Полная база знаний») — самый надежный. Если у вас есть FAQ, гайдлайны или инструкции, добавьте их в начало блока system с cache_control. Это позволит легко преодолеть порог в 4096 токенов.
Второй вариант («Определения инструментов») часто упускают из виду. Поле tools в Anthropic также поддерживает cache_control, что крайне эффективно для Agent-приложений. Описание инструментов вместе с JSON Schema легко переваливает за 2048 токенов.
Третий вариант («Few-shot примеры») идеален для сложных задач. Добавьте 3–5 стандартных примеров в конец системного промпта: это не только повысит стабильность ответов, но и увеличит количество токенов с 1500 до 2500–3500, что как раз перекрывает порог Sonnet 4.6.
Четвертый вариант («Заполнение текстом») — это крайняя мера. Не советую использовать его постоянно, так как модель будет «читать» этот текст, что может повлиять на стиль вывода. Если совсем не получается набрать длину, рассмотрите возможность перехода через платформу APIYI (apiyi.com) на модели с более низким порогом, например, Sonnet 4.5 или 3.7.
Часто задаваемые вопросы
Q1: Я добавил cache_control, но кэширование не работает. Это баг API?
Скорее всего, это не баг, а срабатывание механизма «тихого отказа». Во-первых, проверьте минимальный порог токенов для поля model. Во-вторых, выведите объект usage. В 99% случаев проблема заключается в недостаточном количестве токенов или изменении префикса.
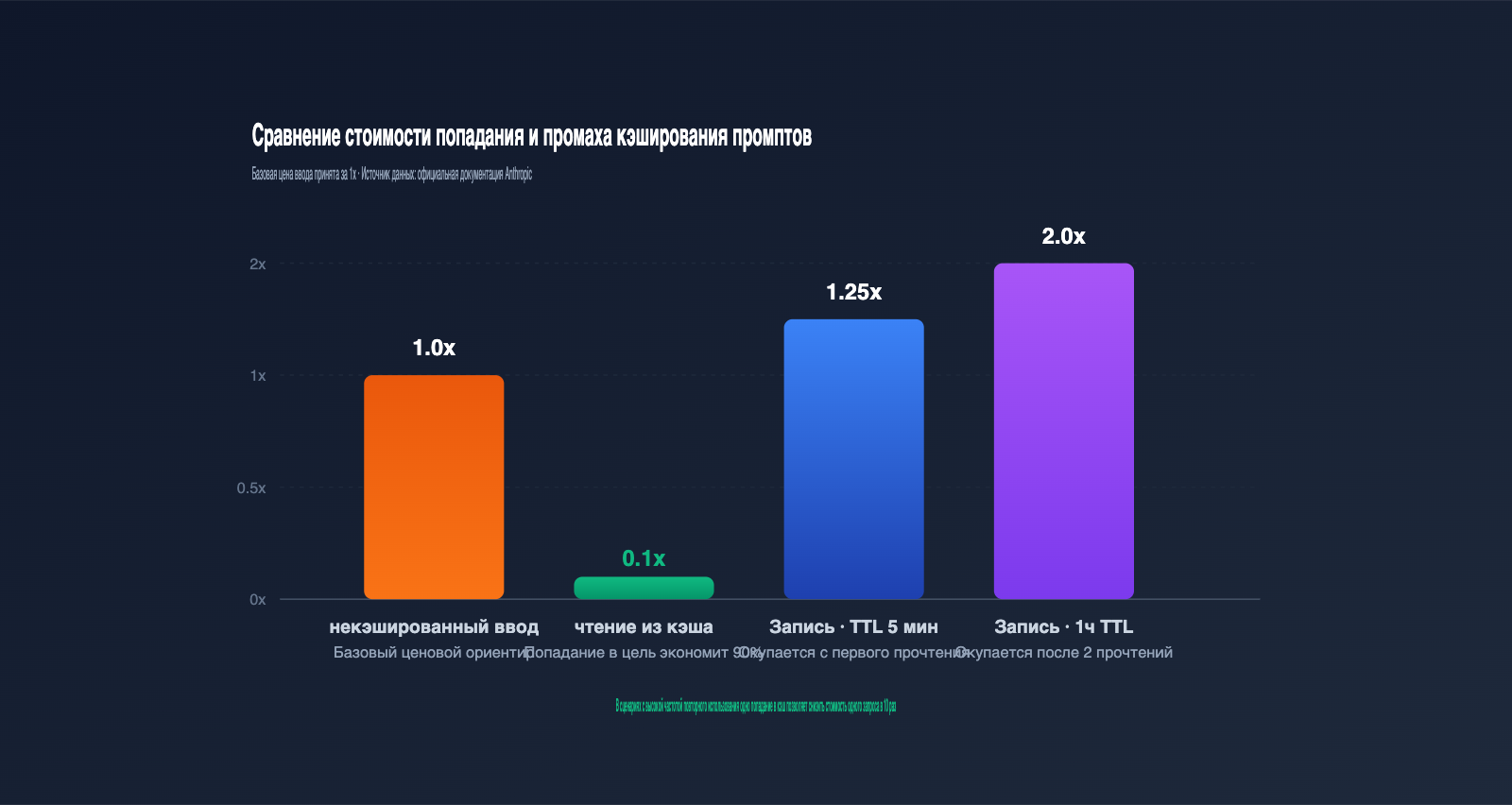
Q2: Дорого ли стоит cache_creation_input_tokens?
Запись с TTL 5 минут стоит в 1,25 раза больше базовой цены ввода, а с TTL 1 час — в 2 раза. Стоимость чтения составляет 0,1 от базовой цены. Как правило, кэш на 5 минут окупается при первом же чтении, а кэш на 1 час — при втором. Чем чаще вы используете кэшированные данные, тем выше выгода.
Q3: В старой документации говорилось, что для Sonnet минимум 1024 токена, а в новой — 2048. Почему?
Это новый порог, введенный начиная с Sonnet 4.6. Для Sonnet 4.5 и более старых версий по-прежнему актуально значение 1024. Рекомендуем хранить в коде таблицу соответствия «модель — порог» и динамически определять его при вызове. При использовании APIYI apiyi.com названия полей model полностью соответствуют официальным спецификациям Anthropic, поэтому вы можете использовать одну и ту же логику маппинга.
Q4: Как безопасно использовать несколько блоков cache_control?
Каждый блок cache_control требует, чтобы накопленный префикс достигал порога, иначе точка останова не сработает. Новичкам мы советуем использовать только одну точку останова, кэшируя весь блок system. Если же необходимо многоуровневое кэширование, поместите «редко меняющуюся базу знаний» на первый уровень, а «инструменты, которые меняются время от времени» — на второй.
Q5: Могу ли я тестировать prompt caching через локальные сервисы-прокси API?
Да. Интерфейсы серии Claude на агрегирующих сервисах-прокси API, таких как APIYI apiyi.com, полностью совместимы с официальными API Anthropic, включая поля cache_control, ttl и usage. Разработчики могут проводить отладку и масштабирование на таких платформах — логика кэширования и правила тарификации остаются идентичными.
Заключение
На первый взгляд кажется, что для работы Claude prompt caching достаточно просто добавить поле cache_control, но на практике можно столкнуться с проблемами из-за «тихих отказов», минимальных порогов токенов и строгой необходимости совпадения префиксов. Список из 5 причин для проверки и таблица попаданий в кэш, приведенные в этой статье, помогут вам выявить 90% проблем с кэшированием менее чем за 5 минут.
Рекомендуем внедрить проверку в виде промежуточного ПО (middleware), вынести пороги моделей в константы кода, а прогрев кэша оформить отдельным скриптом. Если ваш проект часто переключается между разными моделями, используйте APIYI apiyi.com для централизованного управления вызовами Claude. Это позволит унифицировать стратегию кэширования и логику мониторинга, избегая скрытых затрат из-за фрагментации кэша и несоответствия пороговых значений в разных средах.
Автор: Техническая команда APIYI
Связь: Получите полную поддержку отладки всех моделей Claude и prompt caching через APIYI apiyi.com
Дата обновления: 12.05.2026