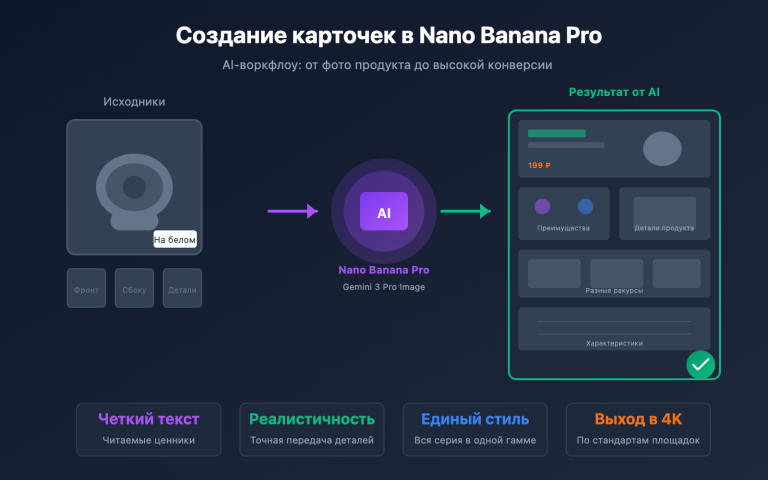
Примечание автора: делюсь опытом работы с Claude Opus 4.7 при обработке CSV и Excel. Объясняю, почему не стоит «скармливать» нейросети огромные таблицы целиком, и почему лучше доверить ей написание скриптов, создание инструментов и проверку данных.
Если у вас есть CSV или Excel-файл на 900+ строк и 50 столбцов, и вы просто спрашиваете Claude Opus 4.7: «обработай эту таблицу», скорее всего, вы получите ответ, который выглядит умным, но который невозможно воспроизвести. Проблема не в том, что Claude Opus 4.7 недостаточно мощный, а в том, что вы используете его как «человека-оператора», который читает таблицу, а не как архитектора процессов обработки данных.
Лучший подход: дайте Claude Opus 4.7 небольшой образец данных, полное описание полей и желаемый результат. Попросите его написать Python-скрипт, создать веб-инструмент или спроектировать воспроизводимый конвейер обработки данных (data pipeline), а затем используйте этот скрипт для обработки полного набора данных. Это позволит использовать возможности модели по рассуждению и написанию кода, при этом вычисления, фильтрацию, агрегацию и проверку данных возьмет на себя детерминированная программа.
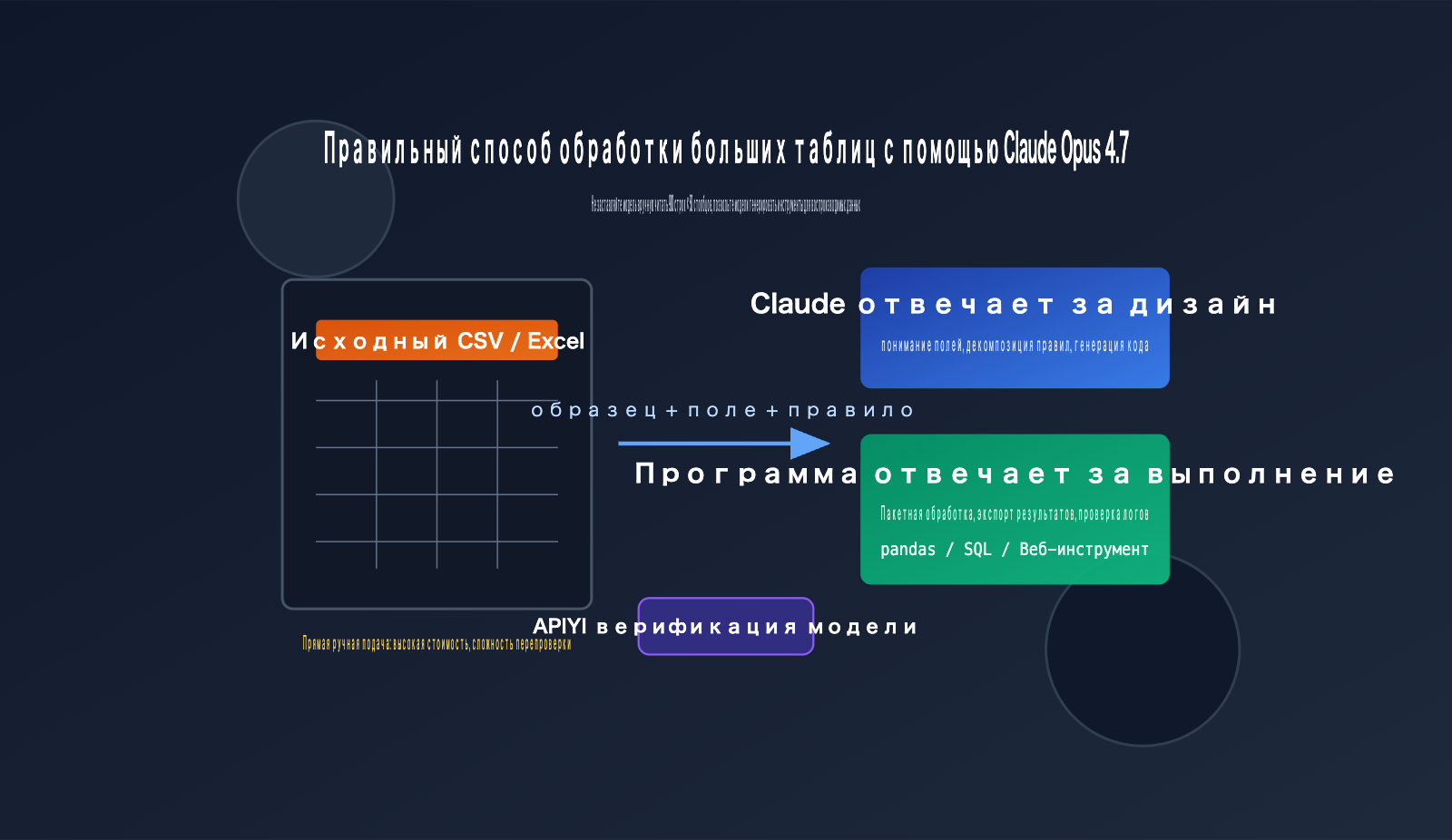
Основные принципы работы с CSV в Claude Opus 4.7
Claude Opus 4.7 — это уже мощная модель для написания кода и агентских рабочих процессов. Разработчики подчеркивают, что она отлично подходит для сложного кода, корпоративных рабочих процессов и работы с электронными таблицами. Но «большое контекстное окно» не означает, что нужно «запихивать» всю таблицу в диалог, особенно если данные содержат много дубликатов, выбросов, скрытых столбцов, хаотичное форматирование или сложные бизнес-правила. Прямая передача сырых данных неэффективна и затрудняет проверку результатов.
По-настоящему эффективный метод работы с CSV в Claude Opus 4.7 заключается в том, чтобы задействовать модель в трех аспектах: понимание бизнес-целей, генерация программы обработки и интерпретация результатов. А вот посимвольное чтение, преобразование типов, удаление дубликатов, агрегация, сортировка и экспорт файлов должны выполняться с помощью Python, SQL, инструментов браузера или встроенной цепочки инструментов анализа данных Claude.
| Сценарий | Проблема при прямой передаче данных AI | Рекомендуемый подход для Claude Opus 4.7 | Преимущество |
|---|---|---|---|
| CSV 900 строк × 50 столбцов | Высокий расход контекста, риск пропуска данных | Дать 20 строк-образцов и описание полей, попросить написать pandas-скрипт | Воспроизводимость и пакетная обработка |
| Excel с несколькими листами | Скрытые формулы, объединенные ячейки, формат мешают пониманию | Сначала попросить написать скрипт для анализа структуры, получить обзор | Понимание структуры перед обработкой |
| Фильтрация по бизнес-правилам | Естественный язык часто упускает граничные условия | Попросить Claude перевести правила в функции и тест-кейсы | Четкие правила, возможность проверки |
| Генерация отчетов | Однократный ответ сложно перепроверить | Попросить Claude создать скрипт экспорта и сводку проверок | Стабильный вывод, удобство сдачи |
Важный момент: Claude Opus 4.7 может «участвовать в анализе данных», но не должен быть «единственной средой исполнения». Если вам нужно через API многократно проверять промпты для обработки данных или выбирать модели, мы рекомендуем использовать APIYI (apiyi.com) для тестирования на небольших выборках, а затем переносить стабильные промпты в скрипты, чтобы не копировать огромные таблицы каждый раз.
Принципы разделения труда при работе с CSV в Claude Opus 4.7
Claude Opus 4.7 лучше всего справляется с высокоуровневыми задачами: интерпретация значений полей, проектирование стратегий очистки, выявление аномалий, генерация кода и объяснение результатов. Он не предназначен для выполнения детерминированных вычислений прямо в чате, так как табличный текст в окне диалога теряет часть структурной информации, а также его неудобно использовать для повторных запусков и управления версиями.
Более надежный принцип: «модели — малые выборки, программе — большие данные». Вы можете предоставить первые 20 строк, 20 случайных строк и 20 строк с аномалиями, добавив словарь полей и целевой формат вывода. После того как Claude Opus 4.7 сгенерирует скрипт на основе этой информации, вы запускаете его для обработки полного файла CSV или Excel. Таким образом, модель отвечает за проектирование, а программа — за исполнение.
Почему не стоит «скармливать» большие таблицы Excel напрямую Claude Opus 4.7
Excel и CSV могут выглядеть как обычные таблицы, но их внутренняя сложность несопоставима. CSV — это простой текстовый формат со строками и столбцами, тогда как Excel может содержать несколько листов, формулы, форматирование, фильтры, скрытые столбцы, объединенные ячейки, специфические форматы дат и локализованные числовые форматы. Если вы просто копируете содержимое Excel в виде текста для ИИ, вы «сплющиваете» эти критически важные данные, превращая их в искаженный плоский текст, который модель воспринимает не как полноценную рабочую книгу, а как поврежденный набор символов.
Официальная документация подтверждает: продукты на базе Claude уже поддерживают инструменты анализа, выполнение кода, плагины для работы с данными и сценарии Excel. Это говорит об одном: обработка таблиц должна опираться на инструментальную среду, а не на «умственные вычисления» языковой модели в окне чата. Даже если Claude Opus 4.7 поддерживает увеличенное контекстное окно, его лучше использовать для бизнес-правил, описания полей, примеров и требований к проверке, а не тратить его на «сырые» строки и столбцы всей таблицы.
| Характеристика данных | Риски при прямой загрузке | Рекомендуемый ввод для Claude Opus 4.7 | Рекомендуемый инструмент |
|---|---|---|---|
| Много столбцов | Модель не может запомнить смысл каждого | Словарь полей, типы данных, описание ключевых колонок | pandas, SQL |
| Много строк | Высокая стоимость токенов, результат нельзя воспроизвести | Заголовочные, случайные и аномальные образцы | Python (потоковая обработка) |
| Несколько листов | Связи между листами теряются | Сводка структуры книги, описание назначения листов | openpyxl, Excel-плагины |
| «Грязные» данные | Аномалии искажают выводы | Статистика пропусков, дублей, примеры форматов | Скрипты контроля качества |
| Сложные правила | Естественный язык часто ведет к ошибкам | Четкие правила, контрпримеры, примеры ожидаемого вывода | Unit-тесты, скрипты проверки |
Технический совет: Если вы планируете интегрировать Claude Opus 4.7 в существующую систему обработки данных, сначала проведите проверку на уровне API через сервис-прокси APIYI (apiyi.com). Рекомендуется сначала отладить промпты, параметры модели и обработку ошибок на небольших выборках, прежде чем подключать полноценную цепочку обработки файлов.
Ключевые заблуждения при работе с Excel в Claude Opus 4.7
Первое заблуждение — считать, что если «модель понимает таблицы», значит, она должна обрабатывать большие таблицы напрямую. Для маленьких файлов, разового анализа или исследовательских вопросов загрузка CSV или Excel — это удобно. Но в задачах массовой очистки, скоринга клиентских баз, сверки заказов или финансовой классификации вам нужны воспроизводимые правила, а не разовый ответ на естественном языке.
Второе заблуждение — ограничиваться только первыми 20 строками. Первые 20 строк обычно показывают лишь нормальную структуру и не охватывают аномалии. Лучшая комбинация образцов: «первые 20 строк + случайные 20 строк + 20 аномальных строк + словарь полей + 3 примера целевого вывода». Только так Claude Opus 4.7 сможет выстроить логику обработки, максимально приближенную к реальным бизнес-задачам.
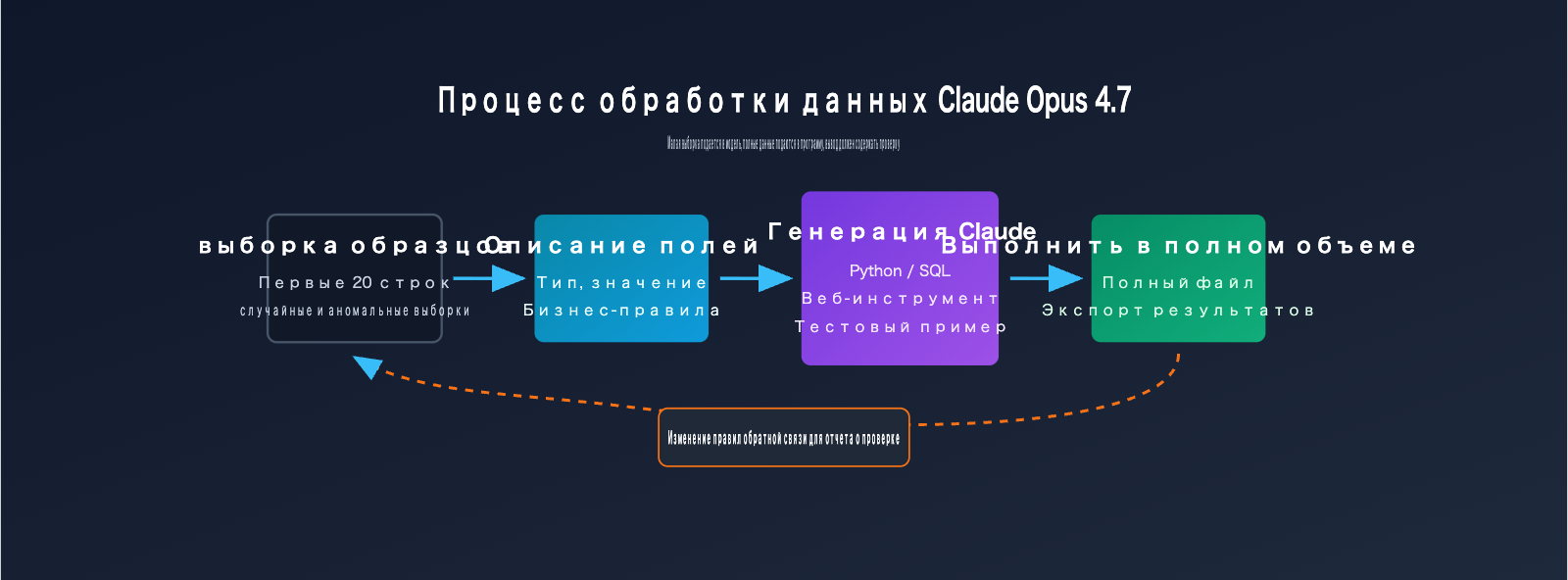
5-шаговый рабочий процесс обработки CSV для Claude Opus 4.7
Этот процесс подходит для большинства задач автоматизации CSV и Excel, особенно если в файле более 500 строк, свыше 20 столбцов и правила требуют постоянной корректировки. Вам не нужно сразу отдавать модели весь файл — достаточно четко описать образцы, структуру и цели, а затем попросить модель создать скрипт, тесты и пояснения к результатам.
| Шаг | Материалы для Claude Opus 4.7 | Что должна выдать модель | Что нужно проверить человеку |
|---|---|---|---|
| 1. Анализ структуры | Формат файла, названия полей, примеры строк | Гипотезы о типах полей и план очистки | Верно ли определен смысл полей |
| 2. Определение правил | Бизнес-цели, условия фильтрации, контрпримеры | Таблица правил обработки и граничные условия | Учтены ли исключения из правил |
| 3. Генерация скрипта | Образцы данных, формат вывода | Скрипт на Python или SQL | Можно ли запустить локально |
| 4. Проверка на малых данных | Образец от 20 до 60 строк | Ожидаемый вывод и тесты (assertions) | Соответствует ли результат интуиции |
| 5. Полное выполнение | Путь к полному файлу | Файл с результатом, логи, отчет о проверке | Совпадают ли суммы, количество и группы |
Главная ценность этого процесса — превращение «разового диалога» в «исполняемый актив». Когда бизнес-правила меняются, вам достаточно попросить Claude Opus 4.7 обновить скрипт и тесты, вместо того чтобы заново загружать полные данные, переобъяснять контекст и гадать, запомнила ли модель все детали.
Шаблон промпта для обработки CSV в Claude Opus 4.7
Вы можете использовать следующую структуру промпта. Важно: не просто вставляйте содержимое CSV, а четко укажите смысл полей, цели обработки, аномальные примеры и критерии приемки. Чем лучше модель понимает, «что считается правильным», тем стабильнее будет сгенерированный скрипт.
У меня есть задача по обработке данных CSV/Excel. Пожалуйста, не давай сразу готовый результат.
Цель:
Оценить таблицу клиентов по отрасли, должности и размеру компании, вывести топ-лиды.
Образцы данных:
1. Первые 20 строк: ...
2. Случайные 20 строк: ...
3. Аномальные 20 строк: ...
Описание полей:
- company_name: название компании
- title: должность контакта
- employee_count: количество сотрудников (может быть пустым)
- industry: отрасль (возможны синонимы)
Что нужно сделать:
1. Сначала объясни смысл полей и потенциальные проблемы с качеством данных.
2. Напиши Python-скрипт для чтения input.csv.
3. Выведи cleaned.csv и scored.csv.
4. Добавь базовые проверки: количество строк, пустые значения, дубликаты, распределение баллов.
5. Не делай предположений о смысле неизвестных полей, если правило неясно — пометь его как TODO.
Если вы хотите превратить этот процесс в API-сервис, используйте шаблон промпта, словарь полей и образцы данных как фиксированный вход, вызывая Claude Opus 4.7 через сервис-прокси APIYI (apiyi.com) для сравнительного тестирования. Это позволит быстро оценить различия в генерации кода, интерпретации правил и обработке исключений между разными моделями.
Пример Python-скрипта для обработки CSV в Claude Opus 4.7
Ниже представлен минималистичный пример, отражающий правильный подход: Claude Opus 4.7 пишет скрипт, скрипт читает полный файл, выводит результат и сводку проверок. В реальных проектах можно добавить логирование, обработку исключений, unit-тесты и конфигурационные файлы.
import pandas as pd
INPUT = "input.csv"
OUTPUT = "scored.csv"
df = pd.read_csv(INPUT)
required = ["company_name", "title", "employee_count", "industry"]
missing = [col for col in required if col not in df.columns]
if missing:
raise ValueError(f"Отсутствующие столбцы: {missing}")
# Приведение типов и заполнение пропусков
df["employee_count"] = pd.to_numeric(df["employee_count"], errors="coerce").fillna(0)
df["score"] = 0
# Логика скоринга
df.loc[df["title"].str.contains("cto|chief|founder", case=False, na=False), "score"] += 40
df.loc[df["employee_count"].between(50, 500), "score"] += 30
df.loc[df["industry"].str.contains("ai|software|saas", case=False, na=False), "score"] += 30
# Базовая проверка
print({"rows": len(df), "duplicates": int(df.duplicated().sum())})
df.sort_values("score", ascending=False).to_csv(OUTPUT, index=False)
Если вам нужно, чтобы модель интерпретировала результаты, вы можете после генерации summary.json скриптом передать эту сводку в Claude Opus 4.7. Для многоэтапных задач автоматизации рекомендуется использовать APIYI (apiyi.com) для централизованного управления вызовами моделей, повторными попытками при сбоях и хранением логов — это сделает цепочку обработки данных гораздо более надежной и удобной в поддержке.
Выбор инструментов для работы с Excel в Claude Opus 4.7
Для разных задач стоит выбирать разные инструменты. Для разового анализа отлично подходят аналитические возможности Claude или плагин Data, но для рабочих процессов лучше использовать Python-скрипты, SQL-пайплайны или веб-инструменты. Если в вашей команде есть сотрудники без технического бэкграунда, можно попросить Claude Opus 4.7 создать локальный веб-инструмент, который превратит загрузку файлов, выбор правил и скачивание результатов в удобный визуальный интерфейс.
| Инструментарий | Подходящие задачи | Неподходящие задачи | Рекомендации по использованию |
|---|---|---|---|
| Python-скрипты | Пакетная очистка, скоринг, сверка, экспорт | Команды, не знакомые с консолью | Попросите Claude написать скрипт и README |
| Локальные веб-инструменты | Повторяющиеся задачи для нетехнических специалистов | Сложные права доступа и совместная работа | Попросите Claude создать HTML/JS или легкий сервис |
| SQL-пайплайны | Хранилища данных, заказы, анализ логов | Временные небольшие таблицы Excel | Попросите Claude написать SQL-запросы для выборки и проверки |
| Инструменты анализа Claude | Исследовательский анализ, графики, отчеты | Задачи с жестким комплаенсом или автоматизацией | Сначала исследование, затем перенос в скрипт |
| API-воркфлоу | Сравнение моделей, интеграция систем | Разовые ручные задачи | Отладка через унифицированный интерфейс |

Идея создания веб-инструмента для обработки Excel в Claude Opus 4.7
Когда пользователь не владеет Python, «попросить Claude написать веб-инструмент» часто оказывается практичнее, чем «заставить Claude прочитать CSV напрямую». Веб-инструмент может включать кнопки загрузки, маппинг полей, настройку правил, предпросмотр и экспорт. Пользователю достаточно просто менять файл, не вступая в бесконечные диалоги с ИИ.
Вы можете дать Claude Opus 4.7 такую задачу: создать HTML-инструмент в одном файле, который использует Papa Parse для чтения CSV, выполняет маппинг полей и скоринг на фронтенде, а затем экспортирует новый CSV. Для небольших объемов данных, несекретных правил и работы в браузере это очень экономичный подход. Для более сложных задач с разграничением прав, аудитом и большими файлами стоит переходить на полноценный бэкенд.
Совет по внедрению: Если вы хотите подключить к веб-инструменту интерпретацию моделей, рекомендации по маппингу полей или диагностику ошибок, используйте API-вызовы через APIYI (apiyi.com). Пусть фронтенд отвечает только за взаимодействие, а бэкенд — за запросы к модели и логирование.
Чек-лист проверки CSV для Claude Opus 4.7
В обработке данных самое страшное — не ошибки в коде, а когда код «тихо» выдает неверный результат. Поэтому, независимо от того, что вы просите Claude Opus 4.7 написать — Python, SQL или веб-инструмент, — требуйте создания чек-листа проверки. Он не должен быть сложным, но обязан охватывать количество строк, поля, пустые значения, дубликаты, ключевые показатели и выборочную проверку.
| Пункт проверки | Почему это важно | Рекомендуемый способ проверки | Рекомендация при ошибке |
|---|---|---|---|
| Кол-во строк (вход/выход) | Предотвращение случайного удаления | Сравнение len(input) и len(output) |
Описание разницы |
| Обязательные поля | Защита от ошибок при смене имен столбцов | Проверка набора столбцов | Ошибка при отсутствии полей |
| Доля пустых значений | Предотвращение искажений в скоринге | Статистика по каждому столбцу | Предупреждение при превышении порога |
| Дубликаты | Предотвращение двойных списаний | Удаление дублей по ключу | Отчет о найденных дублях |
| Сумма денег и кол-ва | Предотвращение логических ошибок | Сравнение суммы до и после агрегации | Остановка при несовпадении |
| Выборочная проверка | Выявление ошибок в понимании правил | Ручная проверка 20 случайных строк | Обратная связь для Claude |
На практике вы можете включить эту таблицу прямо в промпт, чтобы Claude Opus 4.7 автоматически добавлял проверки при генерации скрипта. При тестировании вызовов моделей через APIYI (apiyi.com) мы также рекомендуем требовать вывод результатов проверки в фиксированном формате — это упрощает сравнение стабильности разных моделей, а не просто оценку «красивого» ответа.
Анти-промпт для обработки CSV в Claude Opus 4.7
Не ограничивайтесь фразой «помоги мне очистить эту таблицу». Лучше сказать: «Сначала укажи, какие поля тебе нужны, и только потом пиши скрипт; не выдавай сразу итоговый результат; выводи логи на каждом этапе; помечай TODO правила, в которых не уверен; сгенерируй 5 примеров для модульного тестирования». Такие ограничения заставляют модель делать скрытые выводы явными, а вам позволяют быстрее понять, правильно ли она поняла бизнес-задачу.
Также не стоит считать первые 20 строк файла «истиной в последней инстанции». Они подходят для понимания структуры, но не покрывают все «грязные» данные. Обязательно предоставьте аномальные примеры: пустые значения, дубликаты, путаницу в форматах дат, отрицательные суммы, опечатки в перечислениях, смешение языков и т.д.
FAQ по работе с CSV в Claude Opus 4.7
Достаточно ли 20 первых строк для анализа CSV в Claude Opus 4.7?
Этого недостаточно, но это хороший старт. Первые 20 строк отлично подходят для демонстрации структуры полей и типичных записей, но они не охватывают аномальные данные. Рекомендую использовать комбинацию: «первые 20 строк + 20 случайных строк + 20 строк с аномалиями». Передав такие выборки Claude Opus 4.7, попросите его написать скрипт для обработки полного файла, а не просто делать выводы на основе фрагмента.
Стоит ли загружать весь файл Excel при работе с Claude Opus 4.7?
Если это разовое исследование, можно загрузить файл и использовать инструменты анализа. Если же речь идет о бизнес-процессе для постоянного использования, лучше сначала попросить Claude Opus 4.7 написать скрипт для анализа структуры, а затем — скрипт для обработки данных. Для сценариев автоматизации через API можно использовать сервис-прокси API APIYI (apiyi.com), чтобы сначала прогнать небольшую выборку и убедиться, что модель стабильно понимает поля и правила, прежде чем запускать полный процесс.
Нужно ли писать скрипты, если контекстное окно Claude Opus 4.7 составляет 1 млн токенов?
Да, нужно. Большое контекстное окно позволяет вместить больше описаний полей, примеров и бизнес-контекста, но оно не заменяет воспроизводимую программу вычислений. Особенно когда дело касается сумм, ранжирования, группировки, дедупликации и методик подсчета — скрипты и проверки являются основой достоверности результатов.
В чем разница между обработкой Excel в Claude Opus 4.7 и традиционными BI-системами?
Claude Opus 4.7 лучше справляется с превращением размытых требований в правила, код и пояснения. Традиционные BI-системы больше подходят для стабильной отчетности, управления правами доступа, моделирования данных и совместной работы. Они не конфликтуют: можно использовать Claude для генерации скриптов очистки и логики анализа, а затем передавать готовые результаты в BI или хранилище данных.
Стоит ли использовать Claude Opus 4.7 для обработки CSV, если нет навыков программирования?
Стоит, но рекомендую просить модель создавать локальные веб-инструменты или подробные инструкции, а не просто выводить результат прямо в чате. Вы можете попросить его оформить логику обработки в виде кнопок, форм и функций скачивания, чтобы вам оставалось только загрузить файл и проверить результат. Если нужны API-интерфейсы моделей, используйте APIYI (apiyi.com) для быстрой проверки того, как разные модели справляются с генерацией кода.
На что обратить внимание при работе с конфиденциальными файлами Excel в Claude Opus 4.7?
Чувствительные данные следует предварительно обезличить или обрабатывать в контролируемой среде. Не отправляйте номера паспортов, телефоны, клиентские договоры или финансовые детали в исходном виде в непроверенные среды. Более безопасный подход — предоставить обезличенные образцы и структуру полей, попросить Claude написать скрипт, а затем выполнить обработку полных данных локально или в корпоративной среде.
Основные выводы по работе с CSV в Claude Opus 4.7
- Лучший способ работы с CSV в Claude Opus 4.7 — это не чтение огромных таблиц целиком, а генерация исполняемых скриптов на основе образцов и правил.
- Первые 20 строк помогают модели понять структуру, но для реальных задач нужны также случайные выборки, аномальные примеры и словарь полей.
- Excel сложнее, чем CSV: наличие нескольких листов, формул, скрытых столбцов и форматирования может повлиять на результат, поэтому сначала стоит провести анализ структуры.
- Для пакетных задач Python, SQL и локальные веб-инструменты гораздо надежнее, чем разовые ответы в чате.
- Чек-лист проверок должен создаваться вместе со скриптом обработки: уделите внимание количеству строк, полям, пустым значениям, дубликатам и ключевым суммам.
- В сценариях автоматизации через API рекомендуется сначала протестировать модель на малых выборках, а затем внедрять стабильное решение в производственную цепочку.
Рекомендации по обработке Excel-файлов с помощью Claude Opus 4.7
Claude Opus 4.7 отлично справляется с задачами по работе с данными, но правильный подход заключается не в том, чтобы просто «скормить таблицу ИИ», а в том, чтобы «поручить ИИ разработать инструменты для обработки этой таблицы». Когда объем данных достигает сотен строк и десятков столбцов или когда бизнес-правила требуют многократного использования, написание скриптов, создание веб-инструментов, SQL-пайплайнов и отчетов о проверке данных становятся гораздо более эффективными решениями.
Вы можете использовать Claude Opus 4.7 как своего помощника по инженерии данных: дайте ему проанализировать небольшую выборку, уточните правила, попросите написать скрипт обработки, сгенерировать тесты и объяснить результаты. Такой подход позволяет сохранить преимущество большой языковой модели в понимании бизнес-логики и при этом избежать неэффективности и отсутствия прозрачности, которые возникают при прямой загрузке «сырых» данных.
Если вы занимаетесь разработкой, связанной с Claude Opus 4.7, CSV, Excel или автоматизацией данных, рекомендуем сначала использовать APIYI (apiyi.com) для вызова модели и проверки промптов, а затем превращать стабильные процессы в готовые скрипты или инструменты. Это делает затраты более предсказуемыми, а результаты — удобными для проверки командой и долгосрочного сопровождения.
Ссылки для справки:
- Anthropic Claude Opus 4.7: anthropic.com/claude/opus
- Руководство по использованию Claude Opus 4.7: claude.com/resources/tutorials/working-with-claude-opus-4-7
- Инструмент выполнения кода Claude: platform.claude.com/docs/en/agents-and-tools/tool-use/code-execution-tool
- Плагин данных Claude: claude.com/plugins/data