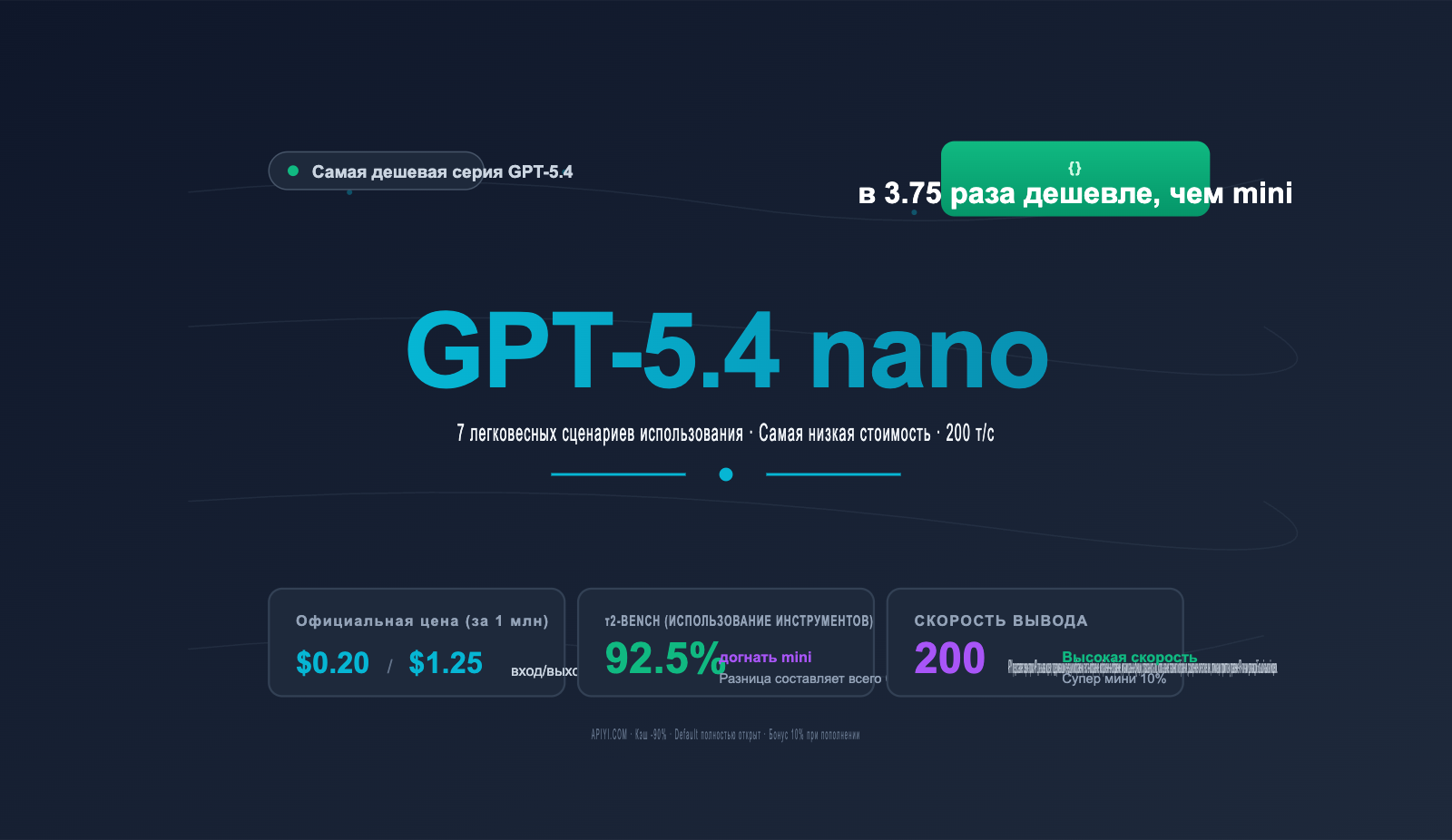
Примечание автора: Самая дешевая модель OpenAI, gpt-5.4-nano, стоит всего $0.20/$1.25, при этом в бенчмарке τ2-Bench она показывает результат 92.5%, почти догоняя mini. В этой статье мы подробно разберем 7 сценариев, где nano подходит идеально, когда стоит перейти на mini, и как с помощью кэширования добиться скидки в 90%.
Если ваше приложение совершает более 10 000 вызовов в день, или вы подбираете модель для задач с высокой пропускной способностью (поддержка клиентов, классификация, маршрутизация RAG), вы наверняка заметили, что OpenAI установила новую «минимальную планку» для серии GPT-5.4 — gpt-5.4-nano, $0.20 за вход / $1.25 за выход на 1 млн токенов, что в 3.75 раза дешевле, чем 5.4-mini.
Это не просто «урезанная дешевая модель». Согласно официальным бенчмаркам OpenAI, nano достигает 92.5% в вызове инструментов (τ2-Bench), почти сравниваясь с 93.4% у mini; в ответах на общие вопросы (GPQA Diamond) она набирает 82.8%, отставая от mini всего на 5.2 процентных пункта. Это означает, что для множества задач с «высокой нагрузкой и низкой сложностью» nano — это по-настоящему оптимальное решение.
Основная ценность: В этой статье мы рассмотрим 7 конкретных сценариев применения, детально разберем, где nano «достаточно и дешевле», а где «необходимо использовать mini», а также приведем фрагменты кода и расчеты стоимости для каждого случая.
Ключевые моменты применения GPT-5.4 nano
| Пункт | Описание | Ценность |
|---|---|---|
| Экстремально низкая цена | $0.20 / $1.25 за 1 млн токенов | В 3.75 раза дешевле 5.4-mini |
| Кэширование -90% | Кэшированный вход всего $0.02 / 1 млн | Почти бесплатно для частого контекста |
| Вызов инструментов как у mini | τ2-Bench 92.5% против 93.4% у mini | Достаточно для большинства задач Tool Use |
| Сильные знания | GPQA Diamond 82.8% | Справляется с общими FAQ и поиском знаний |
| Контекстное окно 400K | Вход 400K + выход 128K | Легкая пакетная обработка длинных документов |
| Лидерство по скорости | ~200 т/с, на 10% быстрее mini | Лучший выбор для высоконагруженных пайплайнов |
Как определить «порог достаточности» для GPT-5.4 nano
Чтобы понять, достаточно ли вам возможностей nano, используйте простую «трехзонную классификацию»:
Зеленая зона (смело используйте nano): вызов инструментов, структурированное извлечение данных, классификация и разметка, ответы на вопросы, маршрутизация контента, пакетный перевод/резюмирование — в этих задачах разница в результатах между nano и mini составляет менее 10 процентных пунктов, а ценовое преимущество полностью перекрывает разницу в способностях.
Желтая зона (требуется оценка): сложные многошаговые рассуждения, длинные цепочки агентов, генерация кода — модель все еще справляется (SWE-Bench Pro 52.4%), но мы рекомендуем сначала провести AB-тестирование с nano, прежде чем принимать решение.
Красная зона (сразу используйте mini): Computer Use (у nano в OSWorld всего 39%), длинные задачи в терминале (46.3% — слабовато), специализированные сценарии, требующие дообучения (Fine-tuning) — в этих задачах nano явно не справляется, лучше сразу выбирать mini или стандартную версию.

GPT-5.4 nano Вариант применения №1: классификация в реальном времени
Описание сценария
Классификация в реальном времени — это классический кейс для nano, включающий анализ тональности, распознавание намерений, тегирование тем, модерацию контента и многое другое. Такие задачи обычно требуют всего несколько сотен токенов на входе и несколько десятков на выходе, поэтому они крайне чувствительны к задержкам и стоимости.
Простой пример кода
import openai
import json
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def classify_intent(user_query: str) -> dict:
"""Классификация намерений пользователя"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": "Ты классификатор намерений. Возвращай ответ в формате JSON: {intent, confidence, sub_category}"},
{"role": "user", "content": user_query}
],
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
# Использование
result = classify_intent("Я хочу отменить заказ, сделанный на прошлой неделе")
# {"intent": "refund_request", "confidence": 0.95, "sub_category": "subscription_cancel"}
Расчет стоимости
| Масштаб сценария | Стоимость за запрос | Дневная стоимость (100 тыс. запросов) |
|---|---|---|
| Базовая поддержка(50 вход + 20 выход) | $0.000035 | $3.5 |
| Средний SaaS(200 вход + 30 выход) | $0.000078 | $7.8 |
| Enterprise(500 вход + 50 выход) | $0.000163 | $16.3 |
💡 Совет по оптимизации: Поместите метки классификации и примеры в системный промпт. После включения кэширования стоимость входных токенов можно снизить еще на 90%. При использовании через сервис-прокси API APIYI (apiyi.com) скидки на кэширование применяются автоматически.
GPT-5.4 nano Вариант применения №2: извлечение данных
Описание сценария
Извлечение структурированных полей из неструктурированного текста (резюме, контракты, новости, электронные письма). Это сильная сторона nano — в сочетании со Structured Outputs (строгие ограничения JSON Schema) можно добиться точности форматирования более 99%.
Практический пример кода
from pydantic import BaseModel
from typing import Optional
class ContactInfo(BaseModel):
name: str
email: Optional[str]
phone: Optional[str]
company: Optional[str]
role: Optional[str]
def extract_contact(text: str) -> ContactInfo:
response = client.beta.chat.completions.parse(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": "Извлеки контактную информацию, для отсутствующих полей возвращай null"},
{"role": "user", "content": text}
],
response_format=ContactInfo
)
return response.choices[0].message.parsed
Список задач по извлечению данных, подходящих для nano
- Извлечение ключевых полей из резюме (CV)
- Распознавание цифр в счетах/квитанциях
- Парсинг подписей в электронных письмах
- Распознавание именованных сущностей в новостях (имена, локации, организации)
- Нормализация данных из форм
- Классификация событий в логах
GPT-5.4 nano, сценарий применения №3: ранжирование контента
Описание сценария
Переранжирование результатов поиска, списков рекомендаций и очередей сообщений. Низкая стоимость модели nano делает использование LLM в качестве реранкера экономически оправданным в продакшене.
Пример кода для реранжирования
def rerank_documents(query: str, candidates: list[str], top_k: int = 5) -> list:
"""Переранжирование документов на основе релевантности запросу"""
docs_text = "\n".join([f"[{i}] {doc[:300]}" for i, doc in enumerate(candidates)])
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[{
"role": "user",
"content": f"""Отсортируй следующие документы по релевантности запросу "{query}".
Документы:
{docs_text}
Верни JSON: {{"ranking": [список индексов документов от наиболее до наименее релевантных]}}"""
}],
response_format={"type": "json_object"}
)
ranking = json.loads(response.choices[0].message.content)["ranking"]
return [candidates[i] for i in ranking[:top_k]]
🎯 Совет по применению: реранжирование с помощью nano точнее, чем традиционные методы BM25 + векторный поиск, при этом стоимость составляет всего 27% от GPT-5.4-mini. Вы можете подключиться напрямую через APIYI (apiyi.com), группа Default доступна без дополнительных заявок.
GPT-5.4 nano, сценарий применения №4: уровень исполнения Sub-agent
Описание сценария
В архитектуре с несколькими агентами основной агент (обычно mini или стандартная версия) отвечает за планирование, а Sub-agent (исполнитель-воркер) — за конкретные вызовы инструментов, запросы данных и обновление состояний. Показатель 92,5% в тесте τ2-Bench делает nano идеальным кандидатом на роль воркера.
Пример взаимодействия нескольких агентов
def execute_subtask(task: dict, available_tools: list) -> dict:
"""nano в роли Sub-agent для выполнения отдельной подзадачи"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": f"Ты исполнитель-воркер. Доступные инструменты: {available_tools}"},
{"role": "user", "content": f"Выполни задачу: {task['description']}"}
],
tools=task.get("tools", []),
tool_choice="auto"
)
return {
"task_id": task["id"],
"result": response.choices[0].message.content,
"tool_calls": response.choices[0].message.tool_calls
}
# Основной агент использует mini, Sub-agent — nano, экономия затрат более 60%
GPT-5.4 nano, сценарий применения №5: уровень маршрутизации RAG
Описание сценария
В системах RAG модель nano выступает в роли «уровня маршрутизации», который определяет тип запроса (технический вопрос / предпродажная консультация / отзыв о продукте / светская беседа) и перенаправляет его соответствующему обработчику. Такая архитектура позволяет задействовать более дорогие модели (mini или стандартную версию) только тогда, когда это действительно необходимо.
Пример маршрутизации RAG
def route_query(query: str) -> str:
"""nano определяет, на какой RAG-обработчик направить запрос"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": """Верните тег маршрутизации в зависимости от типа запроса:
- "technical_docs": запрос к технической документации
- "product_faq": FAQ по продукту
- "code_help": помощь с кодом
- "small_talk": светская беседа (RAG не требуется)
- "complex_reasoning": сложное рассуждение (перенаправить на mini/стандартную версию)"""},
{"role": "user", "content": query}
],
max_tokens=20
)
return response.choices[0].message.content.strip()
route = route_query(user_input)
if route == "complex_reasoning":
final_model = "gpt-5.4-mini" # переходим на mini
else:
final_model = "gpt-5.4-nano" # продолжаем использовать nano
💰 Оптимизация затрат: такая архитектура «nano-маршрутизация + обработка через mini/стандартную модель» обычно позволяет снизить общие расходы на вызовы API на 60–80%. Через сервис-прокси API APIYI (apiyi.com) можно гибко переключаться между двумя моделями в рамках одного API-ключа, просто изменяя параметр
model.
GPT-5.4 nano, сценарий применения №6: высокопроизводительное резюмирование и перевод
Описание сценария
Пакетная обработка задач, таких как создание резюме новостей, перевод документов или перефразирование комментариев. Благодаря поддержке контекстного окна в 400 тыс. токенов, nano может обрабатывать целые длинные статьи за один раз, при этом стоимость одного запроса практически ничтожна.
Пример Batch API
# Подготовка пакетных задач
batch_requests = []
for doc_id, content in documents.items():
batch_requests.append({
"custom_id": f"summary-{doc_id}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-5.4-nano",
"messages": [
{"role": "system", "content": "Сократите следующий текст до 100 слов"},
{"role": "user", "content": content}
],
"max_tokens": 200
}
})
# Отправка через Batch API (та же цена, но не расходует лимиты онлайн-запросов)
batch = client.batches.create(
input_file_id=file_id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
GPT-5.4 nano Сценарий применения №7: Использование инструментов (Tool Use)
Описание сценария
В бенчмарке τ2-Bench модель nano набрала 92,5%, практически догнав mini с её 93,4%. Для стандартных задач вызова функций (function calling), таких как «узнать погоду», «проверить заказ» или «поиск по документам», nano подходит идеально.
Пример вызова функций (Function Calling)
tools = [{
"type": "function",
"function": {
"name": "get_order_status",
"description": "Запрос статуса заказа",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string"}
},
"required": ["order_id"]
}
}
}]
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[{"role": "user", "content": "Что с моим заказом #12345?"}],
tools=tools,
tool_choice="auto"
)
# nano точно определяет необходимость вызова get_order_status и извлекает order_id="12345"
Подробности ценообразования GPT-5.4 nano
Официальная структура тарифов
| Тип оплаты | Цена (за 1 млн токенов) | Примечание |
|---|---|---|
| Входные данные | $0.20 | Стандартный тариф |
| Кэшированный ввод | $0.02 | Скидка 90% |
| Выходные данные | $1.25 | Включая токены рассуждения |
| Batch API | $0.20 / $1.25 | Та же цена, не занимает онлайн-квоту |
| Локализация данных | +10% | Для задач с требованиями комплаенса |
Сравнение цен: nano vs mini
| Параметр | gpt-5.4-nano | gpt-5.4-mini | Разница |
|---|---|---|---|
| Входные данные | $0.20 | $0.75 | nano дешевле в 3,75 раза |
| Кэшированный ввод | $0.02 | $0.075 | nano дешевле в 3,75 раза |
| Выходные данные | $1.25 | $4.50 | nano дешевле в 3,6 раза |
| Скорость ответа | ~200 т/с | ~180 т/с | nano быстрее на ~10% |
| Контекст | 400K | 400K | Одинаково |
| Макс. вывод | 128K | 128K | Одинаково |
💰 Оптимизация затрат: для высоконагруженных сценариев с миллионами запросов в день разница в цене между nano и mini может достигать тысяч долларов в месяц. При подключении через APIYI (apiyi.com) вы дополнительно получаете бонус 10% при пополнении от 100 долларов, что эквивалентно скидке 15% от официальных цен. В совокупности это позволяет снизить затраты до 25% по сравнению с прямым использованием через официальный сайт.
Сравнительный анализ GPT-5.4 nano и mini

| Параметр | gpt-5.4-nano | gpt-5.4-mini | Разница | Стоит ли брать nano? |
|---|---|---|---|---|
| SWE-Bench Pro | 52.4% | 54.4% | -2.0 п.п. | ✅ Почти наравне |
| Terminal-Bench 2.0 | 46.3% | 60.0% | -13.7 п.п. | ⚠️ Для длинных задач — mini |
| Toolathlon | 35.5% | 42.9% | -7.4 п.п. | ✅ Для простых задач хватит |
| GPQA Diamond | 82.8% | 88.0% | -5.2 п.п. | ✅ Справится с вопросами |
| OSWorld-Verified | 39.0% | 72.1% | -33.1 п.п. | ❌ Для Computer Use — только mini |
| τ2-Bench (Tool Use) | 92.5% | 93.4% | -0.9 п.п. | ✅ Почти догнал |
| MCP Atlas | 56.1% | 57.7% | -1.6 п.п. | ✅ Почти наравне |
| Скорость ответа | ~200 т/с | ~180 т/с | +10% | ✅ nano даже быстрее |
Рекомендации по выбору
Когда лучше выбрать nano:
- Задачи из «зеленой зоны» (классификация, извлечение данных, сортировка, маршрутизация, использование инструментов, пакетная обработка).
- Высокая нагрузка (>10 000 вызовов в день) и чувствительность к бюджету.
- Нужна минимальная задержка (<1 сек).
- В качестве вспомогательного агента (основной агент — mini, исполнитель — nano).
Когда стоит перейти на mini:
- Если требуется Computer Use (огромный разрыв в OSWorld).
- Длинные задачи в терминале (>10 шагов).
- Сложные многошаговые рассуждения или глубокая отладка кода.
- Когда качество результата важнее экономии.
📊 Совет: В 80% сценариев с высокой пропускной способностью и низкой сложностью nano выигрывает у mini по соотношению цена/качество. Вы можете сравнить работу обеих моделей в своих задачах через сервис-прокси API APIYI (apiyi.com), просто изменив параметр
model.
Инструкция по подключению GPT-5.4 nano через APIYI
Доступно сразу в группе Default
Платформа APIYI применяет единую стратегию доступа для моделей GPT-5.4 nano и 5.4-mini:
- ✅ Группа Default (по умолчанию): полностью открыта, доступна сразу после регистрации.
- ✅ Группа SVIP (премиум): полностью открыта, без каких-либо ограничений.
- ✅ Синхронизация скидок на кэширование: цена $0.02/1M токенов полностью поддерживается.
- ✅ Поддержка Batch API: пакетные задачи также доступны по той же цене.
Сравнение стоимости: APIYI vs Официальный сайт
| Проект | Официальный сайт OpenAI | APIYI apiyi.com |
|---|---|---|
| Базовая цена | $0.20 / $1.25 за 1M | $0.20 / $1.25 за 1M (та же цена) |
| Скидка на кэш | $0.02 / 1M (90%) | $0.02 / 1M (полная синхронизация) |
| Бонус при пополнении | Нет | При пополнении на $100 дарим $10 (10%) |
| Реальная стоимость | 100% стандартной цены | около 90% (скидка ~15%) |
| Доступ из РФ | Требуется VPN | Прямое подключение, без VPN |
| Способы оплаты | Международные карты | Поддержка рубля, Alipay, WeChat |
| Совместимость SDK | OpenAI Native | Полная совместимость с OpenAI SDK |
| Мин. сумма пополнения | $5 | От $1 |
💰 Оптимизация затрат: Для приложений с объемом вызовов более миллиона токенов в месяц, подключение через APIYI apiyi.com позволяет суммировать скидку на кэширование с бонусом за пополнение. Итоговая стоимость может быть на 25–35% ниже, чем при прямой работе с OpenAI.
Часто задаваемые вопросы (FAQ)
Q1: Что такое gpt-5.4-nano? В чем основные отличия от gpt-5.4-mini?
GPT-5.4-nano — это самая доступная и быстрая облегченная модель в серии OpenAI GPT-5.4 ($0.20/$1.25 за 1M токенов), скорость отклика составляет около 200 токенов/с. Основные отличия от 5.4-mini: 1) цена ниже в 3.6–3.75 раза; 2) заметно слабее в Computer Use (OSWorld 39% против 72.1%) и длинных задачах в терминале (46.3% против 60%); 3) в остальных сценариях (классификация, извлечение данных, использование инструментов, ответы на вопросы) разница обычно составляет менее 10 п.п.
Q2: Для каких задач лучше всего подходит nano? А где обязательно нужен mini?
Подходит для nano (зеленая зона):
- Классификация в реальном времени (тональность, намерение, тема)
- Извлечение структурированных данных
- Ранжирование и переранжирование контента
- Уровень исполнения Sub-agent
- Маршрутизация RAG
- Высокопроизводительная суммаризация/перевод
- Стандартные вызовы инструментов (τ2-Bench 92.5%)
Обязательно используйте mini (красная зона):
- Автоматизация рабочего стола Computer Use (разрыв в OSWorld 33 п.п.)
- Длинные задачи в терминале (>10 шагов)
- Сложные многошаговые рассуждения
- Задачи, требующие Fine-tuning
Q3: Почему nano не рекомендуется для Computer Use?
В тестах OSWorld-Verified модель nano показала результат всего 39.0%, что значительно ниже 72.1% у mini. Это означает, что при многошаговых операциях на рабочем столе (открыть браузер → поиск → клик → заполнение формы) частота ошибок у nano слишком высока для стабильной работы. Если ваш сценарий требует Computer Use, выбирайте mini или стандартную версию 5.4.
Q4: Как активировать скидку на кэширование $0.02/1M для nano?
Механизм кэширования OpenAI срабатывает автоматически, дополнительные параметры не нужны. Он активируется, когда префикс промпта (обычно system prompt + общий контекст) совпадает с запросами за последние 5–10 минут, предоставляя скидку 90%.
Советы по оптимизации:
- Размещайте system prompt в самом начале массива messages.
- Общий контекст (метки классификации, определение схемы) размещайте сразу после него.
- Пользовательский запрос ставьте в конец.
- Поддерживайте частоту вызовов (кэш истекает через 5 минут).
При вызове через APIYI apiyi.com скидка на кэширование полностью синхронизирована с официальной.
Q5: Какие лучшие практики для обработки пакетных задач (batch) на nano?
Три ключевые стратегии:
- Используйте Batch API: отправляйте задачи через интерфейс
/v1/batches. Они выполняются в течение 24 часов, цена та же, но они не расходуют квоту RPM для онлайн-запросов. - Общий system prompt: используйте одинаковые инструкции для всех задач, чтобы активировать кэширование.
- Установите разумный max_tokens: вывод nano дешевый, но при больших объемах расходы накапливаются — установите лимит в 50–500 токенов.
При отправке Batch-задач через APIYI apiyi.com вы получаете бонус 10% при пополнении, что делает итоговую стоимость около 85% от официальной цены.
Q6: Как вызывать GPT-5.4 nano через APIYI?
APIYI полностью совместим с OpenAI SDK, нужно всего три шага:
- Зарегистрируйтесь на APIYI apiyi.com (группа Default доступна сразу).
- Получите API-ключ.
- Измените
base_urlв коде наhttps://vip.apiyi.com/v1, аmodelустановите какgpt-5.4-nano.
client = openai.OpenAI(
api_key="YOUR_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[...]
)
Пополнение на $100 дает бонус 10%, что эквивалентно скидке 15% от официальных цен, плюс синхронизация скидок на кэш.
Q7: Когда nano выгоднее, чем mini? Как посчитать?
Формула расчета:
Условие выгоды nano = (Допустимое снижение качества) × (Объем вызовов) × (Разница в цене)
> (Прирост качества от перехода на mini)
Реальные сценарии:
- Объем > 10 тыс./день: экономия > $30/день ($1000/мес)
- Объем > 100 тыс./день: экономия > $300/день ($9000/мес)
- Объем > 1 млн/день: экономия > $3000/день ($90000/мес)
Для задач в «зеленой зоне» (классификация, извлечение, инструменты) потеря качества у nano обычно составляет < 5%, при этом экономия затрат достигает 73% (в 3.6 раза). Совокупный ROI почти всегда на стороне nano.
Q8: Какие есть известные ограничения у GPT-5.4 nano?
Основные ограничения:
- Нет поддержки Computer Use: результат OSWorld 39% слишком низок для стабильной автоматизации.
- Нет поддержки Fine-tuning: нельзя дообучать на своих данных.
- Нет поддержки аудио/видео: только текст и изображения.
- Слабость в длинных задачах в терминале: Terminal-Bench 46.3%, операции длиннее 10 шагов часто срываются.
- Ограниченные способности к сложным рассуждениям: результат GPQA 82.8% близок к mini, но в сверхсложных задачах (например, FrontierMath) показатели заметно ниже.
Альтернатива: при столкновении с этими ограничениями переключайтесь на gpt-5.4-mini или стандартную версию 5.4.
Основные сценарии использования GPT-5.4 nano: ключевые выводы
- Минимальная цена: $0.20/$1.25 за 1 млн токенов, что в 3,6–3,75 раза дешевле, чем 5.4-mini.
- Скидка 90% на кэширование: стоимость входящих токенов снижается до $0,02 за 1 млн, что делает работу с контекстом в высокочастотных сценариях практически бесплатной.
- 7 «зеленых» сценариев: классификация, извлечение данных, сортировка, работа в качестве Sub-agent, маршрутизация, пакетная обработка и использование инструментов (Tool Use).
- τ2-Bench 92,5%: эффективность вызова инструментов почти на уровне mini; модель отлично справляется с 90%+ задач Function Calling.
- GPQA 82,8%: сильные навыки в общих вопросах и ответах, идеально подходит для FAQ и модерации контента.
- Скорость 200 т/с: на 10% быстрее, чем mini, — лучший выбор для высоконагруженных конвейеров.
- «Красная зона» (предупреждение): для задач Computer Use и длительных сессий в терминале обязательно переключайтесь на mini.
Резюме
Ключевые моменты при использовании GPT-5.4 nano:
- Позиционирование: nano — оптимальный выбор для задач с высокой пропускной способностью и низкой сложностью. Его стихия — классификация в реальном времени, извлечение данных, работа в качестве Sub-agent, маршрутизация RAG и пакетная обработка.
- Границы возможностей: по результатам τ2-Bench, GPQA и SWE-Bench Pro модель почти догнала mini, однако в задачах Computer Use и при длительной работе в терминале она заметно уступает.
- Как подключиться: используйте сервис-прокси API APIYI (apiyi.com). Доступ через группу Default, скидки на кэширование работают автоматически, а при пополнении баланса на 100 вы получаете бонус 10.
GPT-5.4 nano — это не «дешевка, которая делает всё понемногу», а легкий и мощный инструмент, специально оптимизированный OpenAI для задач с высокой пропускной способностью и низкой сложностью. Если ваше приложение попадает в один из 7 «зеленых» сценариев, nano почти всегда выгоднее, чем mini. Но если речь заходит о Computer Use или длительных задачах в терминале, правильным выбором будет переключение на mini.
Рекомендуем быстро подключиться к GPT-5.4 nano через платформу APIYI (apiyi.com): группа Default не требует одобрения, скидки на кэширование полностью синхронизированы, действует бонус 10% при пополнении, а прямое подключение из РФ обеспечивает стабильную работу.
Дополнительные материалы
Если вас заинтересовал API GPT-5.4 nano, рекомендуем ознакомиться с этими статьями:
- 📘 Руководство по обновлению до GPT-5.4 mini API — узнайте о возможностях и сценариях использования предыдущей модели mini.
- 📊 Глубокий анализ механизма кэширования OpenAI: лучшие практики для получения скидки 90% — освойте инженерные приемы оптимизации кэша.
- 🚀 Практика построения уровня маршрутизации RAG на базе GPT-5.4 nano — изучите гибридную архитектуру «nano-маршрутизация + mini-обработка».
📚 Справочные материалы
-
Официальная документация OpenAI по GPT-5.4 nano: спецификации модели, ценообразование, примеры вызовов
- Ссылка:
developers.openai.com/api/docs/models/gpt-5.4-nano - Примечание: здесь вы найдете самые актуальные и достоверные технические параметры.
- Ссылка:
-
Анализ бенчмарков AI Cost Check: полномасштабное сравнение nano и mini
- Ссылка:
aicostcheck.com/blog/gpt-5-4-mini-nano-pricing-benchmarks - Примечание: независимое тестирование, идеально подходит для сравнения производительности.
- Ссылка:
-
Документация APIYI по подключению GPT-5.4 nano: решения для вызова API внутри страны, инструкции по группам и скидки на пополнение
- Ссылка:
docs.apiyi.com - Примечание: практическое руководство по интеграции для разработчиков.
- Ссылка:
-
Страница цен OpenAI: полная таблица тарифов и описание механизма кэширования
- Ссылка:
developers.openai.com/api/docs/pricing - Примечание: актуальные стандарты тарификации для всех моделей.
- Ссылка:
Автор: Техническая команда APIYI
Техническое сообщество: Приглашаем обсудить опыт работы с GPT-5.4 nano в комментариях. Больше материалов по интеграции моделей можно найти в центре документации APIYI по адресу docs.apiyi.com.