Примечание автора: Подробное объяснение, почему выходные токены Gemini 3.1 Pro Preview значительно превышают видимый текст: механизм цепочки рассуждений Thinking Tokens, правила тарификации и техника настройки параметра thinking_level для экономии средств.
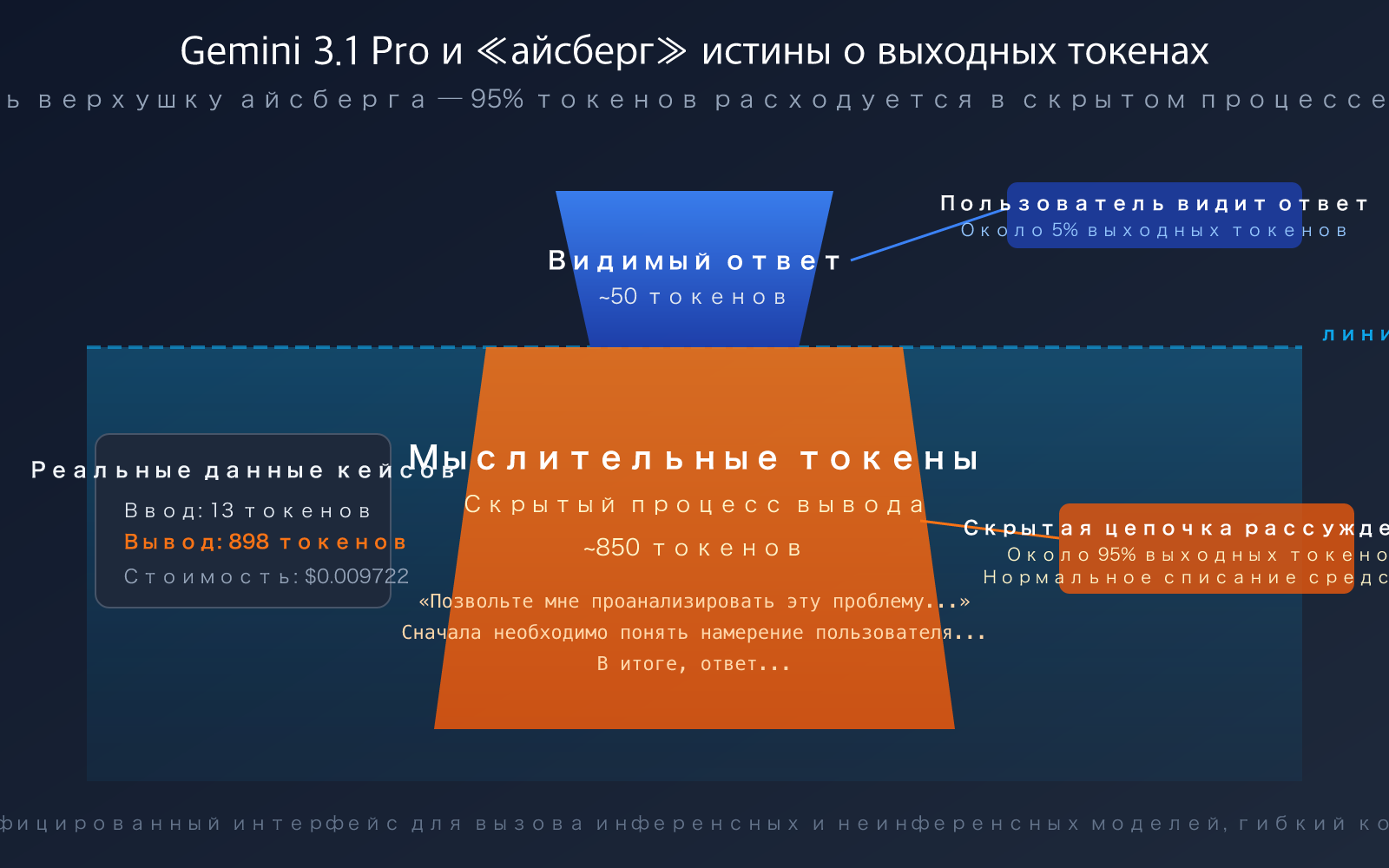
«Я отправил всего одну фразу, модель ответила парой слов, а выходных токенов показывает почти 900? Куда ушли деньги?» — это реальное недоумение многих разработчиков, впервые использующих Gemini 3.1 Pro Preview. Данные на скриншоте также ясно демонстрируют этот феномен: ввод — 13 токенов, вывод — целых 898 токенов.
Ответ кроется в Thinking Tokens (токенах рассуждения). Gemini 3.1 Pro — это модель-рассуждалка. Прежде чем дать вам ответ, она проводит в своей «голове» обширный процесс размышления и логических выводов. По умолчанию это рассуждение вам не показывается, но оно учитывается в выходных токенах и тарифицируется как обычно.
Ключевая ценность: Прочитав эту статью, вы полностью поймёте механизм Thinking Tokens в моделях-рассуждалках, научитесь управлять глубиной рассуждений с помощью параметра thinking_level и сможете сократить расходы на выходные токены на 50-80%, сохраняя при этом качество ответов.
Ключевые моменты о Thinking Tokens в Gemini 3.1 Pro
Главное отличие модели-рассуждалки от обычной диалоговой модели заключается в совершенно разной структуре выходных токенов. Вот ключевые концепции, которые вам нужно понять:
| Пункт | Объяснение | Практическое влияние |
|---|---|---|
| Выходные токены = размышления + ответ | Выходные токены Gemini 3.1 Pro включают Thinking Tokens (цепочку рассуждений) и фактический ответ | Видимого текста мало, но общее количество токенов высокое |
| Thinking Tokens тарифицируются | Процесс рассуждения, хоть и невидим, оплачивается по цене выходных токенов ($12/миллион) | Простой вопрос может стоить в 5-10 раз дороже, чем у обычной модели |
Параметр thinking_level настраивается |
Поддерживает три уровня глубины рассуждений: LOW/MEDIUM/HIGH | Уровень LOW может сэкономить 80%+ выходных токенов |
| У моделей без рассуждений этой проблемы нет | Модели вроде GPT-4o, Claude Sonnet 4.6 (с выключенным Extended Thinking) работают по принципу «что видишь, то и получаешь» | Для простых задач использование моделей без рассуждений экономичнее |
Реальный пример расхода Thinking Tokens в Gemini 3.1 Pro
Вернёмся к примеру на скриншоте. Пользователь задал простой вопрос, модель ответила примерно парой слов, но выходных токенов показано 891-898. Примерная структура этих токенов:
- Видимый ответ: примерно 30-50 токенов (те самые пара слов, которые вы видите)
- Thinking Tokens: примерно 840-860 токенов (внутренний процесс рассуждений модели)
То есть более 95% выходных токенов вы не видите — они расходуются на цепочку рассуждений модели. Это как если бы вы спросили учителя математики «Сколько будет 1+1?», а он вслух ответил бы только «2», но в голове продумал: «Это базовая арифметическая задача, нужно применить операцию сложения…» — и вы заплатили за весь этот мыслительный процесс.
Это не баг, а особенность дизайна моделей-рассуждалок. Именно благодаря глубоким рассуждениям перед ответом Gemini 3.1 Pro показывает лучшие результаты в сложных задачах (95.1% на бенчмарке MATH, 77.1% на ARC-AGI-2).

Как работают Thinking Tokens в модели рассуждений Gemini 3.1 Pro
Принципиальная разница между моделями рассуждений и обычными моделями
Обычная модель (например, GPT-4o), получив ваш вопрос, сразу генерирует ответ. Вы видите столько символов, сколько и потребляет выходных токенов. Это «что видишь, то и получаешь».
Модель рассуждений (например, Gemini 3.1 Pro Preview), получив вопрос, сначала генерирует внутреннюю цепочку рассуждений (Chain of Thought), а затем на основе результата рассуждений формирует окончательный ответ. Вы видите только итоговый ответ, но оплачиваете общее количество токенов: «цепочка рассуждений + ответ».
| Тип модели | Пример модели | Состав выходных токенов | Затраты на простые вопросы | Преимущества для сложных задач |
|---|---|---|---|---|
| Обычная модель | GPT-4o, Claude Sonnet 4.6 | 100% видимый ответ | Низкие (что видишь, то и получаешь) | Обычные способности к рассуждениям |
| Модель рассуждений | Gemini 3.1 Pro, GPT-5.4 Thinking | Цепочка рассуждений + видимый ответ | Высокие (в 5-10 раз и более) | Высокие способности к сложным рассуждениям |
| Переключаемая модель | Claude Sonnet 4.6 (Extended Thinking) | Можно выбрать, включать ли рассуждения | Гибкое переключение | Включение рассуждений по необходимости |
3 ключевых детали о Thinking Tokens в Gemini 3.1 Pro
Деталь 1: Способ тарификации Thinking Tokens. Согласно официальной документации Google, Thinking Tokens тарифицируются по стандартной цене выходных токенов. Цена выходных токенов для Gemini 3.1 Pro составляет $12 за миллион токенов. Когда модель тратит 4000 токенов на рассуждения и 500 токенов на ответ, вы платите за 4500 выходных токенов — а не за 500.
Деталь 2: Как различить в ответе API. В ответе Gemini API поле usage_metadata возвращает отдельно thoughts_token_count (количество токенов рассуждений) и candidates_token_count (общее количество выходных токенов). Но обратите внимание: в Gemini API candidatesTokenCount уже включает Thinking Tokens, а в Vertex AI candidatesTokenCount — нет.
Деталь 3: Содержание цепочки рассуждений по умолчанию невидимо. Вы можете получить краткое изложение процесса рассуждений (не полную цепочку), установив параметр includeThoughts: true. Также можно включить отображение цепочки рассуждений в таких инструментах, как Cherry Studio, чтобы увидеть ход мыслей модели.
🎯 Совет по экономии: Если вам нужен простой диалог или перевод, без глубоких рассуждений, рекомендуется переключиться на обычную модель (например, GPT-4o-mini или Claude Sonnet 4.6). На APIYI apiyi.com можно сменить модель, просто изменив параметр
model, не меняя остальной код.
Оптимизация Thinking Tokens в Gemini 3.1 Pro: 3 стратегии экономии
Стратегия 1: Использование параметра thinking_level для контроля глубины рассуждений
Gemini 3.1 Pro предоставляет параметр thinking_level, который поддерживает три уровня: LOW, MEDIUM, HIGH. Потребление токенов на разных уровнях сильно различается:
| thinking_level | Глубина рассуждений | Потребление токенов | Сценарии применения | Сравнение с HIGH |
|---|---|---|---|---|
| LOW | Поверхностные рассуждения | Минимальное | Перевод, классификация, простые вопросы и ответы | Экономия ~80%+ |
| MEDIUM | Сбалансированные рассуждения | Среднее | Повседневное программирование, генерация документов, общий анализ | Экономия ~50% |
| HIGH | Глубокие рассуждения | Максимальное | Математические выводы, научные задачи, сложная логика | Базовый уровень |
Пример кода для установки thinking_level:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Для простых задач используем LOW, чтобы значительно сократить Thinking Tokens
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "把这句话翻译成英文:今天天气真好"}],
extra_body={"thinking_level": "LOW"} # LOW / MEDIUM / HIGH
)
print(response.choices[0].message.content)
print(f"总输出 Token: {response.usage.completion_tokens}")
Посмотреть полный код интеллектуальной маршрутизации (автоматический выбор глубины рассуждений в зависимости от сложности задачи)
import openai
import json
def smart_gemini_call(
prompt: str,
complexity: str = "auto",
api_key: str = "YOUR_API_KEY"
) -> dict:
"""
Интеллектуальный вызов Gemini 3.1 Pro с автоматическим выбором глубины рассуждений в зависимости от сложности задачи
Args:
prompt: Ввод пользователя
complexity: "low" / "medium" / "high" / "auto"
api_key: API-ключ
Returns:
Словарь, содержащий ответ и статистику использования токенов
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# Автоматическое определение сложности
if complexity == "auto":
simple_keywords = ["翻译", "translate", "分类", "classify", "总结", "summarize"]
complex_keywords = ["推导", "证明", "计算", "分析", "比较", "为什么"]
prompt_lower = prompt.lower()
if any(kw in prompt_lower for kw in simple_keywords):
thinking_level = "LOW"
elif any(kw in prompt_lower for kw in complex_keywords):
thinking_level = "HIGH"
else:
thinking_level = "MEDIUM"
else:
thinking_level = complexity.upper()
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking_level": thinking_level}
)
return {
"answer": response.choices[0].message.content,
"thinking_level": thinking_level,
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
}
# Пример использования
# Простая задача → автоматический выбор LOW
result = smart_gemini_call("翻译:今天天气真好")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
# Сложная задача → автоматический выбор HIGH
result = smart_gemini_call("证明勾股定理的至少两种方法")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
Рекомендация: При вызове Gemini 3.1 Pro через APIYI apiyi.com поддерживается передача параметра
thinking_level. Для повседневного использования рекомендуется установить MEDIUM, а HIGH использовать только в сценариях сложных рассуждений, таких как математика или наука.
Стратегия 2: Использование не-рассуждающих моделей для простых задач
Не все сценарии требуют модели рассуждений. Для таких задач, как перевод, преобразование форматов, простые вопросы и ответы, использование не-рассуждающих моделей может сэкономить в 5-10 раз на токенах:
- GPT-4o-mini: Высокая рентабельность, лучший выбор для повседневного общения
- Claude Sonnet 4.6 (с отключённым Extended Thinking): Высокое качество вывода, токены «что видишь, то и получаешь»
- Gemini 3.1 Flash: Облегчённая модель от Google, высокая скорость, низкая стоимость
Стратегия 3: Установка max_tokens для ограничения верхней границы вывода
Добавление параметра max_tokens к вызову API может предотвратить «чрезмерные размышления» модели рассуждений. Но обратите внимание: max_tokens ограничивает общий вывод (рассуждения + ответ). Если установить слишком низкое значение, ответ может быть обрезан. Рекомендуется устанавливать его в 2-3 раза больше ожидаемой длины ответа.
🎯 Комплексная рекомендация: На платформе APIYI apiyi.com вы можете использовать единый интерфейс для одновременного подключения моделей рассуждений и не-рассуждающих моделей, динамически переключаясь в зависимости от типа задачи. Один API-ключ позволяет вызывать всю линейку моделей Gemini, Claude и GPT.

Часто задаваемые вопросы
Вопрос 1: Почему в Gemini 3.1 Pro Thinking Tokens по умолчанию не отображается процесс рассуждений?
Это выбор дизайна продукта от Google. Полная цепочка рассуждений может содержать тысячи промежуточных токенов, и их прямое отображение серьезно ухудшит пользовательский опыт. Вы можете получить краткое изложение рассуждений, установив параметр includeThoughts: true, или включить функцию отображения цепочки рассуждений в клиентах, таких как Cherry Studio, чтобы увидеть процесс мышления.
Вопрос 2: Как увидеть в ответе API, сколько именно было потрачено Thinking Tokens?
Посмотрите поле thoughts_token_count в usage_metadata, возвращаемом Gemini API. Если вы вызываете API через APIYI (apiyi.com), вы можете просмотреть подробную разбивку токенов (входные/выходные/рассуждения) для каждого вызова на странице статистики использования платформы, что удобно для мониторинга и оптимизации затрат.
Вопрос 3: Какие модели, кроме Gemini 3.1 Pro, имеют аналогичный механизм Thinking Tokens?
У основных моделей рассуждений есть похожие механизмы:
- GPT-5.4 Thinking: Модель рассуждений от OpenAI, токены рассуждений также учитываются в тарификации выходных токенов.
- Claude Sonnet 4.6 Extended Thinking: Режим рассуждений от Anthropic, который можно выборочно включать.
- DeepSeek-R1: Модель рассуждений с открытым исходным кодом, цепочка рассуждений полностью видна.
Ключевое различие в том, что некоторые модели (например, Claude) позволяют гибко включать/выключать режим рассуждений, а другие (например, Gemini 3.1 Pro) по умолчанию используют рассуждения. Через APIYI (apiyi.com) можно тестировать и сравнивать фактическое потребление токенов этими моделями с помощью единого интерфейса.
Итог
Ключевые моменты о Gemini 3.1 Pro Thinking Tokens:
- Выходные токены включают скрытую цепочку рассуждений: Вы видите только часть с ответом, более 95% потребления выходных токенов приходится на невидимые Thinking Tokens.
- Thinking Tokens тарифицируются как обычно: По стандартной цене за выходные токены, стоимость простых задач может быть в 5-10 раз выше, чем у моделей без рассуждений.
- Экономьте с параметром
thinking_level: Уровень LOW может сэкономить более 80% токенов, MEDIUM подходит для повседневного использования, а HIGH — только для сложных задач. - Для простых задач выбирайте модели без рассуждений: Для перевода, классификации, простых вопросов-ответов и подобных сценариев напрямую используйте GPT-4o-mini или Claude Sonnet 4.6 — это выгоднее.
Поняв механизм Thinking Tokens, вы сможете грамотно распределять бюджет на рассуждения. Рекомендуем управлять вызовами нескольких моделей через единый интерфейс APIYI (apiyi.com), динамически выбирая модель с рассуждениями или без в зависимости от сложности задачи для достижения оптимального баланса качества и стоимости.
📚 Справочные материалы
-
Документация Google Cloud — Режим мышления (Thinking): Официальная техническая документация по моделям рассуждений Gemini
- Ссылка:
docs.cloud.google.com/vertex-ai/generative-ai/docs/thinking - Описание: Авторитетный источник информации о правилах тарификации Thinking Tokens и настройке параметра
thinking_level
- Ссылка:
-
Документация Google AI для разработчиков — Подсчёт токенов: Официальное описание подсчёта токенов и поля
usage_metadata- Ссылка:
ai.google.dev/gemini-api/docs/tokens - Описание: Как различать
thoughts_token_countиcandidates_token_countв ответе API
- Ссылка:
-
Google DeepMind — Карточка модели Gemini 3.1 Pro: Подробности о возможностях модели и бенчмарках рассуждений
- Ссылка:
deepmind.google/models/model-cards/gemini-3-1-pro/ - Описание: Официальный источник данных о производительности, таких как MATH 95.1%, ARC-AGI-2 77.1%
- Ссылка:
-
OpenRouter — Лучшие практики работы с токенами рассуждений: Сообщество лучших практик по управлению токенами в моделях рассуждений
- Ссылка:
openrouter.ai/docs/guides/best-practices/reasoning-tokens - Описание: Сравнение правил тарификации токенов рассуждений между моделями и рекомендации по оптимизации
- Ссылка:
Автор: Техническая команда APIYI
Технические обсуждения: Делитесь опытом по оптимизации токенов в моделях рассуждений в комментариях. Больше руководств по вызову моделей можно найти в документации APIYI docs.apiyi.com