Recentemente, um cliente nos perguntou: ao acessar a página de "Data Controls" no painel da OpenAI, ele viu duas chaves — "Share evaluation and fine-tuning data with OpenAI" e "Share inputs and outputs with OpenAI", cada uma com três opções: Disabled, Enabled for all projects e Enabled for selected projects. A primeira exibe um aviso verde: "You're eligible for up to 7 free weekly evals", e a segunda diz "You're enrolled for complimentary daily tokens". Parece que eles estão distribuindo recursos, mas ele não tem certeza se vale a pena ativar e qual seria o custo.
A essência dessas duas chaves é uma troca bidirecional onde a OpenAI oferece "créditos gratuitos" em troca de "dados de treinamento/avaliação". O custo de ativar é real: os dados de avaliação e as entradas/saídas da API serão usados pela OpenAI para aprimorar modelos futuros. Entre os clientes da APIYI (apiyi.com), já vimos casos de pessoas que mantiveram isso ligado por seis meses antes de perceberem uma falha de privacidade, e outros que mantiveram desligado por seis meses antes de notarem que estavam desperdiçando milhões de tokens gratuitos diariamente. Este artigo utiliza a documentação oficial em inglês para explicar detalhadamente o funcionamento real dessas chaves, os créditos obtidos, o impacto na privacidade e a configuração recomendada.
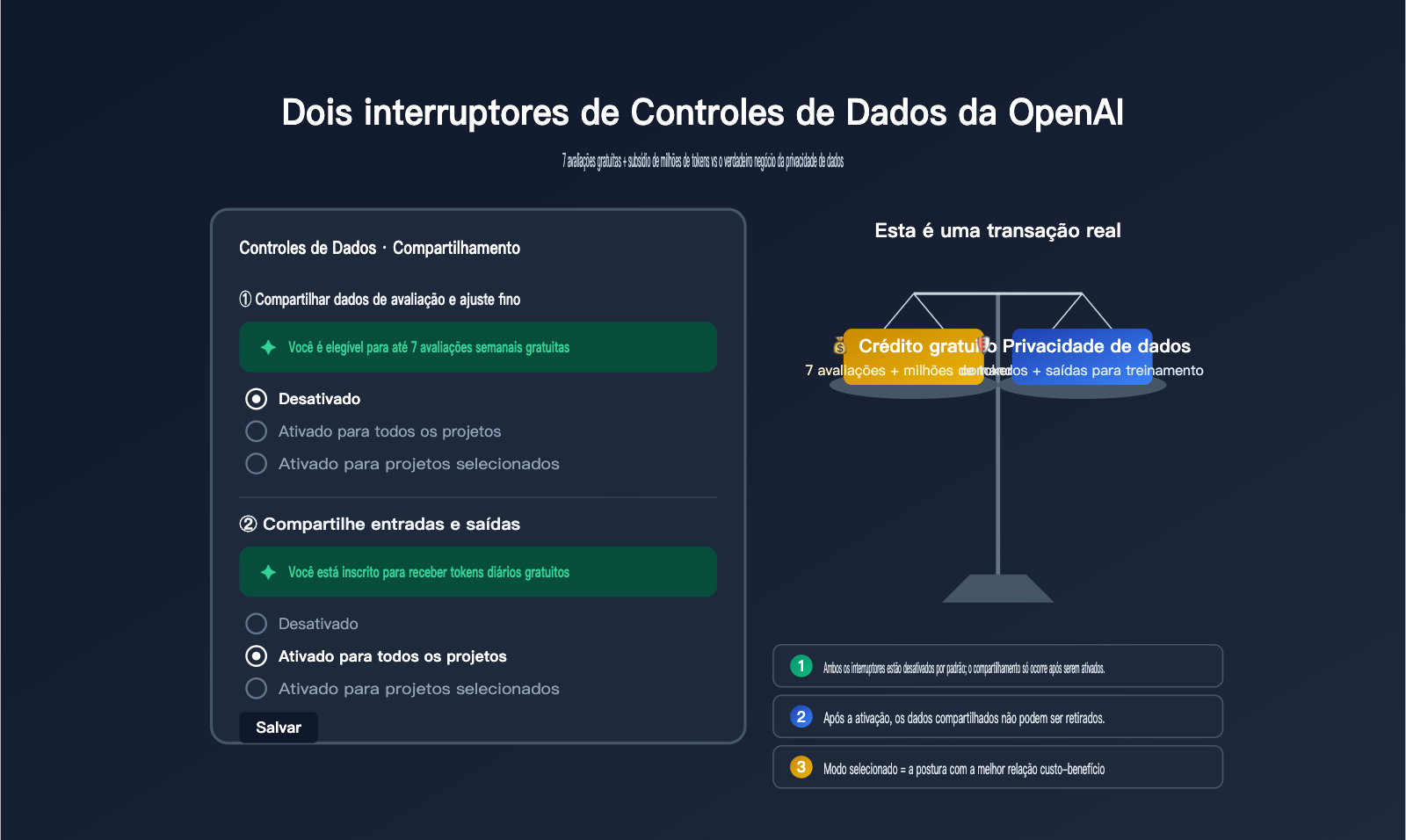
Definições principais das duas configurações de Controles de Dados da OpenAI
Ao abrir a página Settings → Data Controls → Sharing, você encontrará dois interruptores independentes, mas frequentemente confundidos. Eles compartilham conteúdos diferentes, oferecem retornos distintos e possuem impactos na privacidade em níveis completamente diferentes. Compreender seus limites é o pré-requisito para tomar a decisão correta.
| Configuração | Share evaluation and fine-tuning data | Share inputs and outputs |
|---|---|---|
| Conteúdo compartilhado | Comandos de avaliação + resultados + lógica de avaliação + dados de ajuste fino | Todas as entradas e saídas da invocação do modelo via API |
| Retorno gratuito | Até 7 execuções de avaliação gratuitas por semana | Subsídio diário de tokens (alocado por nível e grupo de modelos) |
| Uso dos dados | Melhoria do pipeline de avaliação + treinamento de futuros modelos | Usado diretamente para treinar / melhorar modelos |
| Estado padrão | Desativado | Desativado |
| Granularidade | Três níveis: Desativado / Todos / Selecionados | Três níveis: Desativado / Todos / Selecionados |
| Permissões | Apenas Proprietário da Organização | Apenas Proprietário da Organização |
| Escopo | Apenas dados gerados após a ativação | Apenas tráfego gerado após a ativação |
| Dificuldade de desativação | Alternância a qualquer momento | Alternância a qualquer momento |
🎯 Sugestão de compreensão rápida: Se você deseja apenas "obter a cota gratuita com segurança", pode definir o interruptor como "Enabled for selected projects" (Ativado para projetos selecionados), criar um projeto de teste separado para rodar scripts de desenvolvimento/internos e direcionar o tráfego da API do projeto principal e de produção através do serviço proxy de API da APIYI (apiyi.com), evitando expor todos os seus projetos ao pipeline de treinamento de dados de uma só vez.
Detalhes da configuração Share evaluation and fine-tuning data
O significado literal deste interruptor é "compartilhar dados de avaliação e ajuste fino", mas o escopo real compartilhado é muito mais amplo do que o nome sugere. Após a ativação, a OpenAI não apenas receberá seus comandos de avaliação e conclusões, mas também a lógica de avaliação (critérios de julgamento) que você definiu e os comandos + conclusões presentes nos seus conjuntos de dados de ajuste fino. Isso significa que: como você pontua o modelo, o que você considera uma boa resposta e o conhecimento de domínio presente nos seus dados de treinamento serão coletados pela OpenAI.
O retorno é de até 7 execuções de avaliação gratuitas por semana. A OpenAI afirma claramente em sua central de ajuda que "as avaliações que você compartilha com a OpenAI são atualmente processadas sem custo para até 7 execuções por semana". Exceder esse limite ou usar modelos que não participam da cota gratuita ainda será cobrado conforme o preço padrão por token. Esse número pode não parecer grande, mas para equipes que frequentemente realizam comparações de seleção de modelos, 7 execuções gratuitas por semana podem economizar dezenas a centenas de dólares em custos de avaliação.
Vale ressaltar que o interruptor só entra em vigor para dados gerados após a ativação; dados históricos não serão compartilhados retroativamente, e desativá-lo não "retira" os dados já compartilhados. Portanto, a decisão deve ser baseada em "quantos dados de avaliação você pretende compartilhar nos próximos 6 a 12 meses", e não em "quais dados eu já possuo agora".
| Dimensão | Benefícios da ativação | Custos da ativação |
|---|---|---|
| Benefício direto | 7 avaliações gratuitas por semana | / |
| Benefício indireto | Otimização do pipeline de avaliação pela OpenAI | / |
| Custo de dados | / | Coleta de comandos de avaliação, conclusões e padrões de avaliação |
| Custo de negócio | / | Vazamento de know-how de domínio em conjuntos de ajuste fino |
| Reversibilidade | Pode ser desativado a qualquer momento | Dados já compartilhados não podem ser retirados |
🎯 Quando ativar o compartilhamento de Eval/FT: Se suas avaliações forem baseadas em benchmarks públicos ou conjuntos de testes não sensíveis, ativá-lo é basicamente inofensivo; se os comandos de avaliação contiverem dados reais de clientes, regras de negócio internas ou lógica de avaliação proprietária, recomenda-se usar o modo "Selecionado" e ativá-lo apenas para projetos em sandbox.
Explicação detalhada das configurações de "Compartilhar entradas e saídas" (Share inputs and outputs)
Esta é uma das duas opções que traz "um custo maior, mas um retorno também mais considerável". Ao ativá-la, todas as chamadas de API que passam por este projeto terão seus prompts de entrada e completions de saída coletados pela OpenAI para treinar ou aprimorar seus modelos. Isso é fundamentalmente diferente do comportamento padrão da API — por padrão, desde março de 2023, a OpenAI declara explicitamente que não utiliza dados de API para treinar modelos; ativar esta opção equivale a revogar voluntariamente essa proteção.
O retorno vem na forma de tokens diários subsidiados (complimentary daily tokens), distribuídos em níveis de acordo com o tier da sua conta e o grupo de modelos. Este é o plano de cota gratuita mais específico nos dados públicos da OpenAI, com reset automático todos os dias às 00:00 UTC.
| Grupo de Modelos | Limite Diário Tier 1-2 | Limite Diário Tier 3-5 | Horário de Reset |
|---|---|---|---|
| Grupo de Modelos Flagship | 250.000 tokens | 1.000.000 tokens | 00:00 UTC |
| Grupo de Modelos Pequenos | 2.500.000 tokens | 10.000.000 tokens | 00:00 UTC |
O grupo de modelos "Flagship" e o grupo de modelos "Pequenos" não são divididos apenas pelo desempenho, mas sim por uma lista específica fornecida pela OpenAI — chamadas para modelos fora desta lista não contam para a cota gratuita.
| Grupo de Modelos | Modelos incluídos |
|---|---|
| Grupo Flagship | gpt-5, gpt-5-codex, gpt-5-chat-latest, gpt-4.5-preview, gpt-4.1, gpt-4o, o1, o3, o1-preview |
| Grupo Pequenos | gpt-5-mini, gpt-5-nano, gpt-4.1-mini, gpt-4.1-nano, gpt-4o-mini, o1-mini, o4-mini, codex-mini-latest |
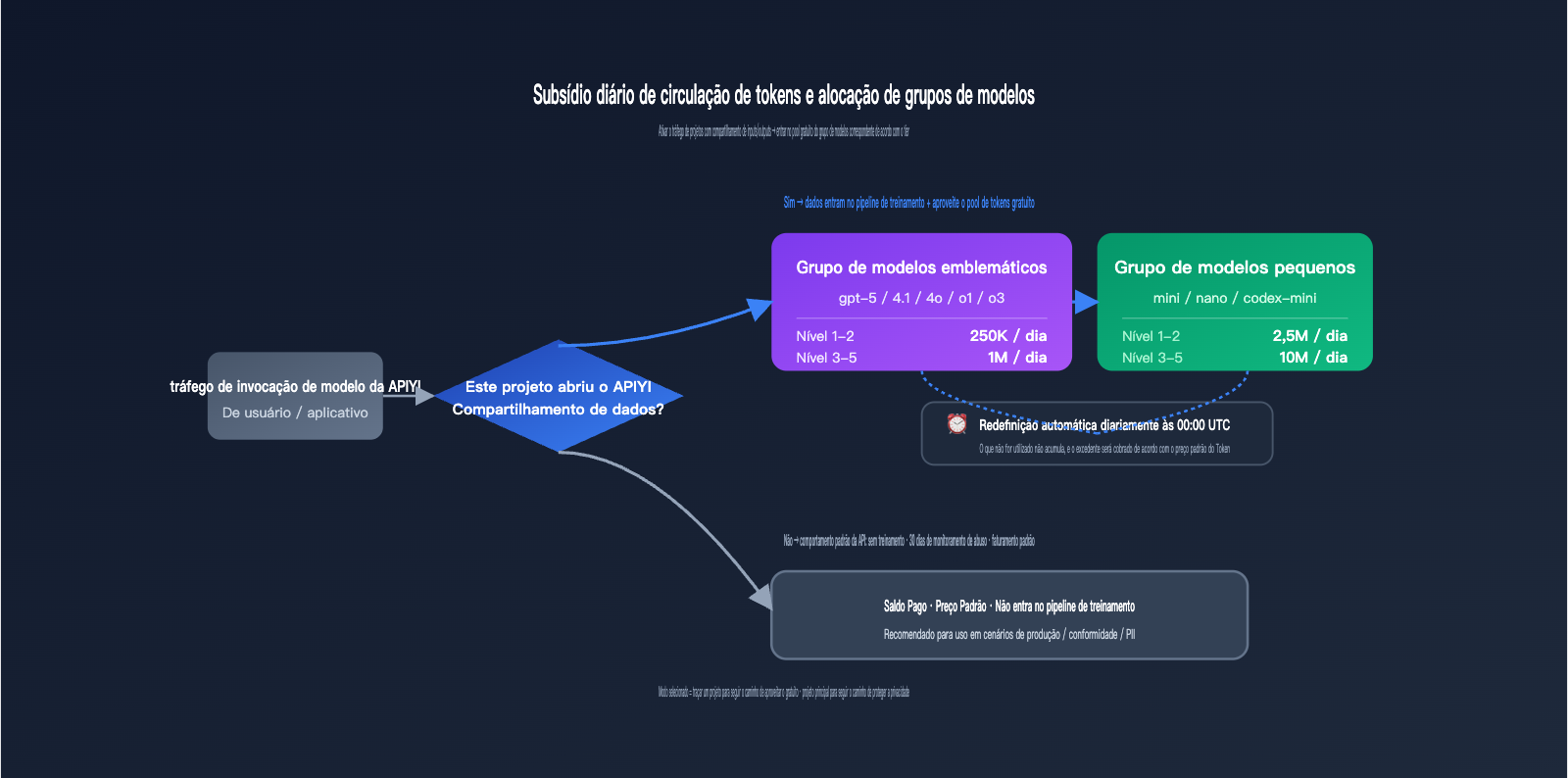
🎯 O valor real da cota de tokens: Estimando com base no gpt-4o-mini a $0,15/M de entrada e $0,60/M de saída, 2,5M de tokens de modelos pequenos por dia no Tier 1-2 equivalem a cerca de $1-2 de crédito gratuito por dia, economizando de $30 a $60 por mês. No Tier 3-5, o limite sobe para 10M de tokens, economizando de $120 a $240 por mês. Se o objetivo for apenas obter essa cota, não vale a pena ativar o tráfego de toda a organização; recomendo criar um projeto de teste independente e configurá-lo no modo "Selected".
Diferença real entre a API padrão e o compartilhamento de dados ativado
Muitas equipes não entendem claramente a questão: "A API padrão é usada para treinamento?". A estratégia real da OpenAI é: a API padrão não é usada para treinamento, mas os dados são retidos por 30 dias para monitoramento de abuso (abuse monitoring). A Retenção Zero de Dados (ZDR) é algo diferente, exigindo que clientes corporativos entrem em contato com a equipe de vendas da OpenAI para solicitar, não sendo um botão de ligar/desligar no painel.
Após entender essa base, o impacto dos dois interruptores fica claro: ativar "Inputs/Outputs" é "abrir mão voluntariamente da proteção de treinamento vigente desde 2023", e ativar "Eval/FT" é "contribuir adicionalmente com metodologias de avaliação". Nenhum dos dois altera a retenção de 30 dias para monitoramento de abuso, nem podem ser combinados com ZDR.
| Dimensão | API Padrão (ambos desligados) | Ativar Inputs/Outputs | Ativar Dados Eval/FT |
|---|---|---|---|
| Usado para treinamento | ❌ Não treina | ✅ Usado para treinamento | ✅ Treinamento + avaliação |
| Retenção p/ monitoramento | 30 dias | 30 dias | 30 dias |
| Dados podem ser retirados | / | ❌ Compartilhado, não retirável | ❌ Compartilhado, não retirável |
| ZDR é compatível | ✅ Pode solicitar ZDR | ❌ Excludente | ❌ Excludente |
| Cenário ideal | Produção / Compliance / PII | dev / Testes / Dados públicos | Avaliação de benchmark público |
🎯 Recomendação de privacidade: Se o seu negócio possui requisitos de conformidade (GDPR, HIPAA, NDA corporativo, PII de clientes, etc.), ambos os interruptores devem permanecer desativados. Além disso, roteie o tráfego altamente sensível através de um serviço proxy de API como o APIYI (apiyi.com) ou solicite o ZDR. Se for apenas um projeto pessoal, ferramenta interna ou demonstração de Hackathon, pode ativar com segurança (Enabled for all projects).
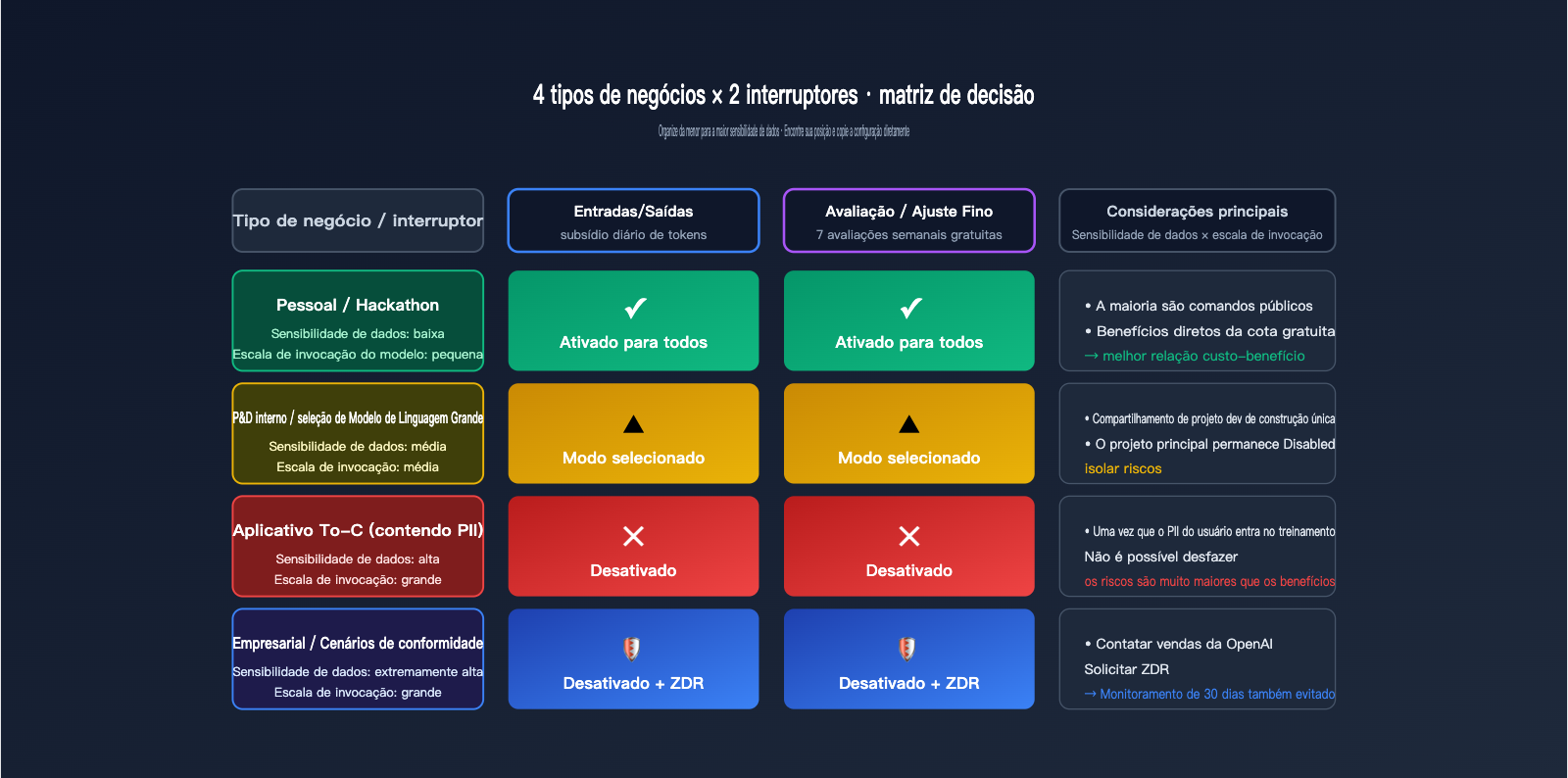
Estrutura de decisão: 4 pontos para avaliar se deve ativar os Controles de Dados da OpenAI
Dar uma resposta binária de "ligar/desligar" é muito simplista. Usamos uma matriz com 4 tipos de cenários de negócios, cada um com sua configuração razoável. As dimensões centrais da decisão são duas: sensibilidade dos dados (se o conteúdo envolve privacidade/segredos comerciais) e escala de invocação (quanto valor real você pode obter das cotas gratuitas).
| Tipo de Negócio | Sensibilidade dos Dados | Recomendação Inputs/Outputs | Recomendação Eval/FT |
|---|---|---|---|
| Desenvolvimento pessoal / Hackathon | Baixa | Enabled for all | Enabled for all |
| R&D interno / Seleção de modelo | Média | Enabled for selected | Enabled for selected |
| Aplicação To-C (com PII) | Alta | Disabled ou Selected (projeto dev) | Disabled |
| Empresa / Cenário de conformidade | Altíssima | Disabled + usar ZDR | Disabled |
A primeira categoria são projetos pessoais ou Hackathons. Nesses casos, o consumo de tokens é principalmente de comandos públicos (como questões de competição, código de demonstração). Ativar o compartilhamento permite obter subsídios diários sem expor informações sensíveis, sendo o melhor custo-benefício. A segunda categoria é R&D interno; sugerimos o modo "Selected" — crie um projeto separado "data-share-test" especificamente para experimentos compartilháveis, mantendo o projeto principal desativado.
A terceira categoria são aplicações To-C, que frequentemente envolvem entradas de usuários, histórico de conversas e informações pessoais. Nesses casos, recomenda-se desativar ambos os interruptores; a cota gratuita não compensa o risco, e uma vez que o PII do usuário é coletado no pipeline de treinamento, é difícil rastreá-lo. A quarta categoria, cenários corporativos ou de conformidade (saúde, finanças, governo), deve utilizar ZDR ou um gateway de conformidade como o APIYI (apiyi.com), evitando até mesmo o monitoramento de abuso de 30 dias.
🎯 Como escolher entre as opções: Se decidir ativar algum interruptor, priorize "Enabled for selected projects" em vez de "Enabled for all projects". Assim, você pode separar um projeto "training-eligible" para dev/testes, mantendo os projetos de produção isolados. Futuras alterações afetarão apenas aquele projeto, mantendo o custo de migração extremamente baixo.
FAQ sobre os Controles de Dados da OpenAI
P1: Ao ativar Inputs/Outputs, a OpenAI pegará imediatamente todos os meus dados históricos?
Não. Ambos os interruptores declaram explicitamente: "Only traffic sent after turning this setting on will be shared" (Apenas o tráfego enviado após ativar esta configuração será compartilhado) / "Only evaluation and fine-tuning data created after turning this setting on will be shared" (Apenas dados de avaliação e fine-tuning criados após ativar esta configuração serão compartilhados). O interruptor só entra em vigor para dados gerados após a ativação; dados históricos não serão retroativamente compartilhados.
P2: Os Tokens gratuitos são a mesma coisa que os Créditos (Credit Grants)?
Não são a mesma coisa, mas estão relacionados. O que você obtém ao compartilhar Inputs/Outputs é um "pool diário de tokens", que é redefinido automaticamente às 00:00 UTC. Os "pequenos centavos" vistos na aba Credit Grants no painel da OpenAI são o registro contábil posterior desse pool, convertido em valor monetário em dólares com base no uso. Pode-se entender como duas formas de visualizar o mesmo projeto.
P3: Se eu ativar o modo "Selected" para compartilhar apenas um projeto, o tráfego do projeto principal está totalmente seguro?
Totalmente seguro. Na interface de configurações, a OpenAI permite selecionar com precisão quais projetos participam do compartilhamento. O tráfego de projetos não selecionados é tratado de acordo com o comportamento padrão da API — sem treinamento e com retenção de 30 dias para monitoramento de abuso. Se ainda houver preocupações, você pode redirecionar o tráfego do projeto principal para um serviço proxy de API como o APIYI (apiyi.com), isolando-o completamente do ponto de vista arquitetural.
P4: Como são contadas as "7 free weekly evals" (7 avaliações semanais gratuitas) do compartilhamento de Eval/FT?
São contadas por "número de execuções", não por contagem de tokens. Cada vez que uma avaliação é executada (independentemente de quantos exemplos sejam processados), conta como uma vez, com um limite de 7 vezes gratuitas por semana. Após exceder esse limite, a cobrança segue o preço padrão de token do modelo utilizado na avaliação. Alguns modelos não estão na lista gratuita, e sua execução será cobrada conforme a tabela de preços.
P5: Após desativar os Inputs/Outputs, os dados que já foram coletados podem ser recuperados?
Não. A política da OpenAI estabelece claramente que os dados compartilhados não podem ser retirados. Desativar o interruptor apenas impede que dados futuros entrem no pipeline de treinamento. É por isso que sempre recomendamos usar um serviço proxy de API como o APIYI (apiyi.com) para realizar um "isolamento rígido" no tráfego de produção — por padrão, os dados nem entram no pipeline de treinamento da OpenAI, o que é muito mais confiável do que "desativar depois".
3 Resumos sobre os Controles de Dados da OpenAI
Primeiro, estes dois interruptores são uma verdadeira "troca bidirecional": você usa dados reais e quantificáveis (metodologia de avaliação, entradas e saídas da API) em troca de benefícios quantificáveis (7 avaliações semanais, milhões a dezenas de milhões de tokens diários). Entenda que isso é uma transação e não um presente puro, para que suas decisões não sejam equivocadas.
Segundo, a API padrão não treina, mas o monitoramento de abuso de 30 dias permanece. Se o seu negócio possui requisitos de conformidade de privacidade, ambos os interruptores devem estar desativados (Disabled) e o controle deve ser reforçado por meio de uma solicitação ZDR ou de um gateway de conformidade como o APIYI (apiyi.com). O interruptor apenas decide "se autoriza treinamento adicional", não decide "se será monitorado".
Terceiro, priorize o uso do modo "Selected" para fazer o "isolamento por projeto". Crie um novo projeto independente para lidar com o tráfego de desenvolvimento/teste que pode ser compartilhado, mantendo o projeto de produção e os dados sensíveis completamente isolados. Dessa forma, você obtém a cota gratuita sem deixar que nenhum dado do usuário flua para o pipeline de treinamento, sendo a estratégia com melhor custo-benefício.
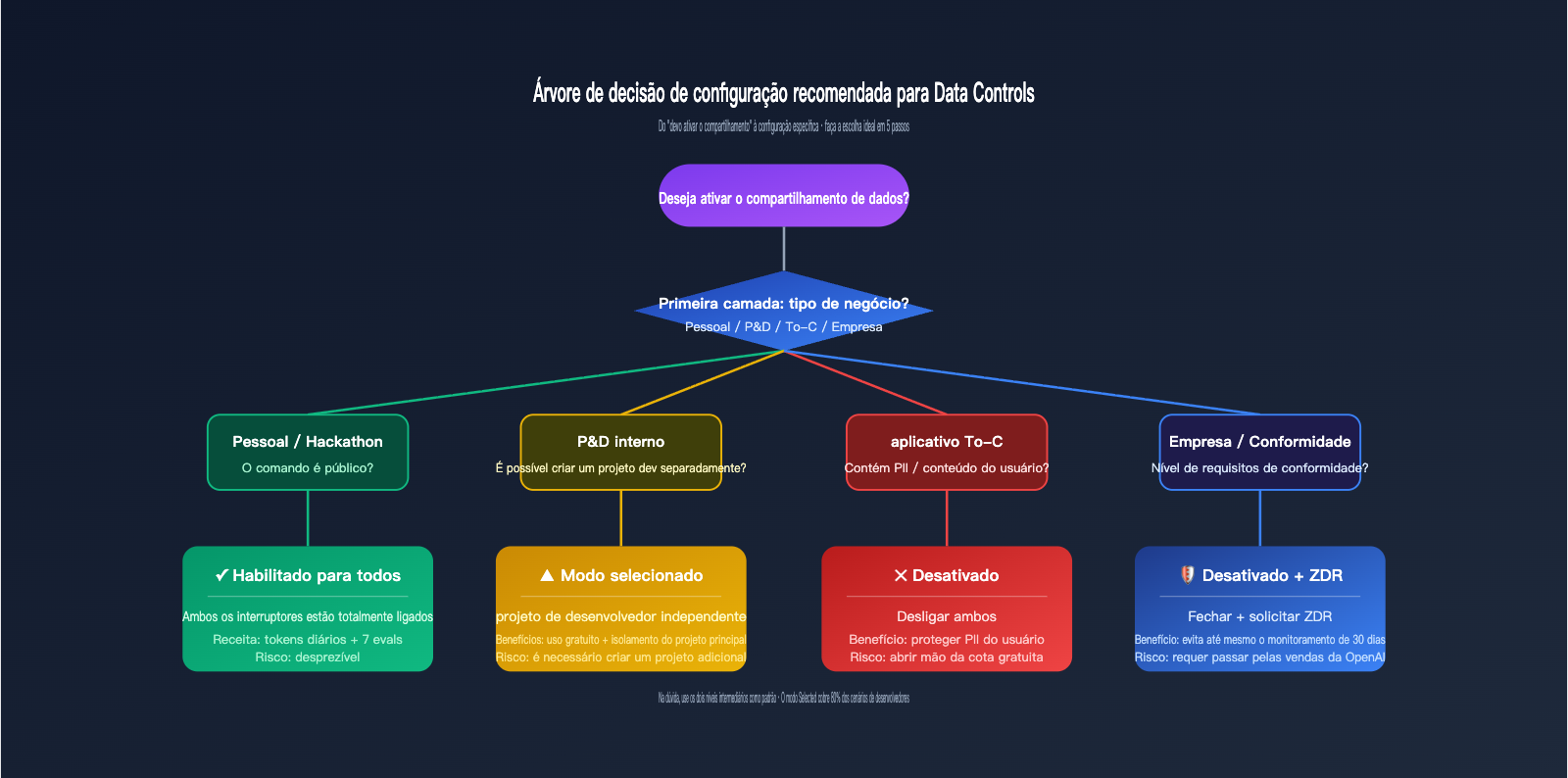
Se você está ponderando sobre esses dois interruptores, a postura mais segura é primeiro classificar seu uso em quatro categorias ("Pessoal / Interno / To-C / Corporativo") para decidir o nível, e então usar o modo "Selected" para criar um projeto de teste independente para aproveitar a cota gratuita. O tráfego de produção principal deve passar por um gateway APIYI (apiyi.com) para isolamento arquitetural; assim, você pode aproveitar a política gratuita da OpenAI enquanto mantém a privacidade dos dados do usuário e do know-how do seu negócio.
📌 Autor: Equipe técnica APIYI — Acompanhamos continuamente as mudanças nas políticas críticas da OpenAI, como Controles de Dados, ZDR e estratégias de cobrança, para oferecer aos desenvolvedores uma experiência de gateway de API multimodal com cobrança unificada e privacidade controlável. Para saber mais, visite APIYI em apiyi.com.