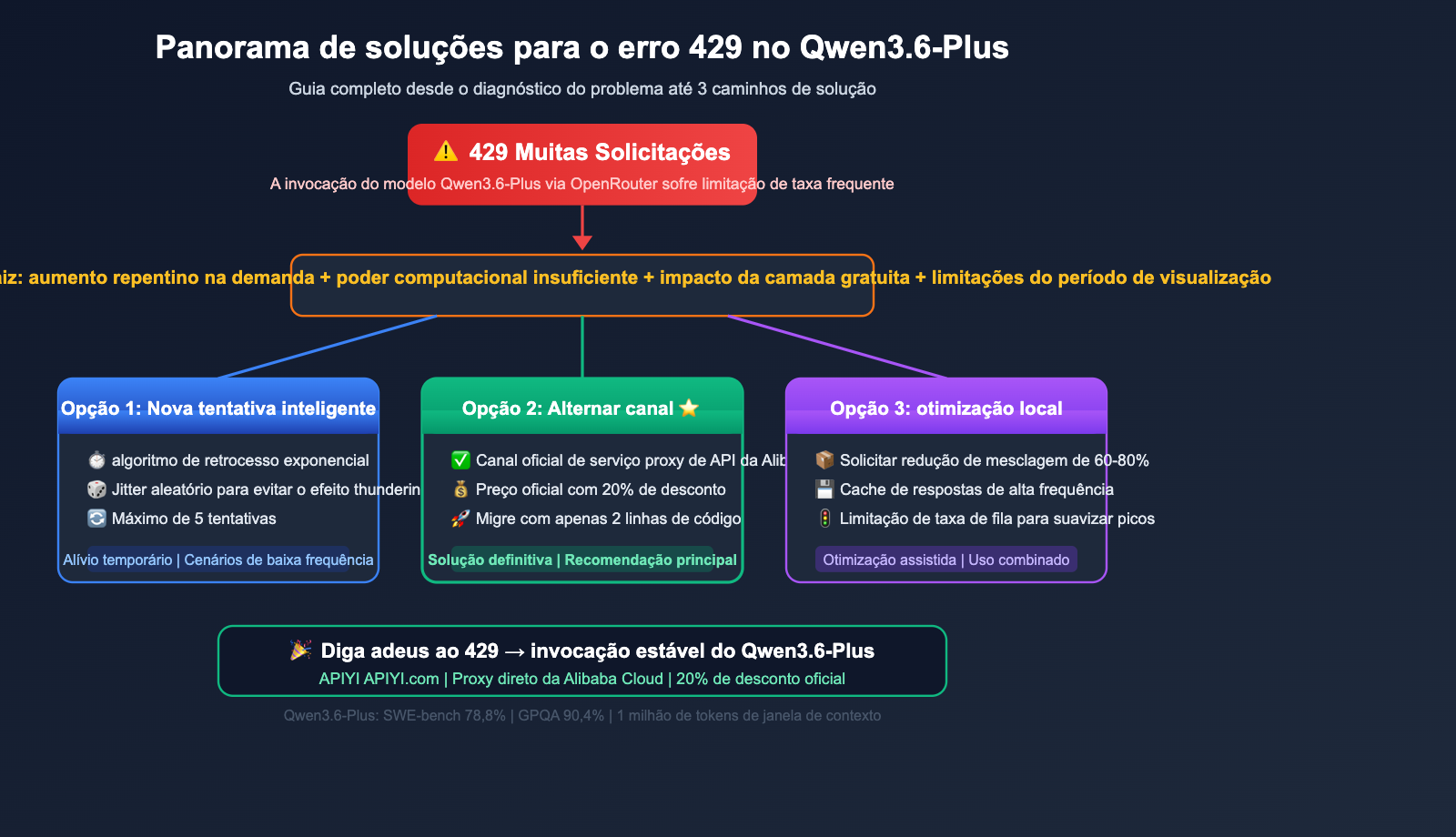
Quem já utilizou o Qwen3.6-Plus sabe bem como é: ao invocar este modelo via OpenRouter, o erro 429 Too Many Requests tornou-se quase uma rotina. Mesmo pagando pelo serviço e não sendo um usuário gratuito, a limitação de taxa (rate limit) chega a ser frustrante.
Valor central: Este artigo analisa a causa raiz do erro 429 no Qwen3.6-Plus, apresenta 3 soluções práticas e mostra como realizar a invocação do modelo de forma estável e econômica através do canal oficial da Alibaba Cloud.
Pontos principais sobre o erro 429 do Qwen3.6-Plus
| Ponto | Descrição | Benefício para o desenvolvedor |
|---|---|---|
| Análise da causa raiz do 429 | Alta demanda + abuso do nível gratuito + estratégia de alocação de poder computacional | Entenda a essência do problema e pare de tentar reconectar cegamente |
| 3 soluções | Estratégia de repetição / Troca de canal / Canal oficial | Escolha o melhor caminho de acordo com o cenário |
| Teste de desempenho | Comparação de latência entre canais do Qwen3.6-Plus | Escolha a forma de acesso mais estável |
| Exemplo de código | Python/Node.js pronto para rodar | Conclua a migração em 5 minutos |
Por que o Qwen3.6-Plus está tão popular?
O Qwen3.6-Plus é o Modelo de Linguagem Grande carro-chefe lançado pela equipe Qwen da Alibaba em abril de 2026, competindo diretamente com o Claude Opus 4.5 e o GPT-5.4. A razão de sua popularidade é simples: alto desempenho e baixo custo:
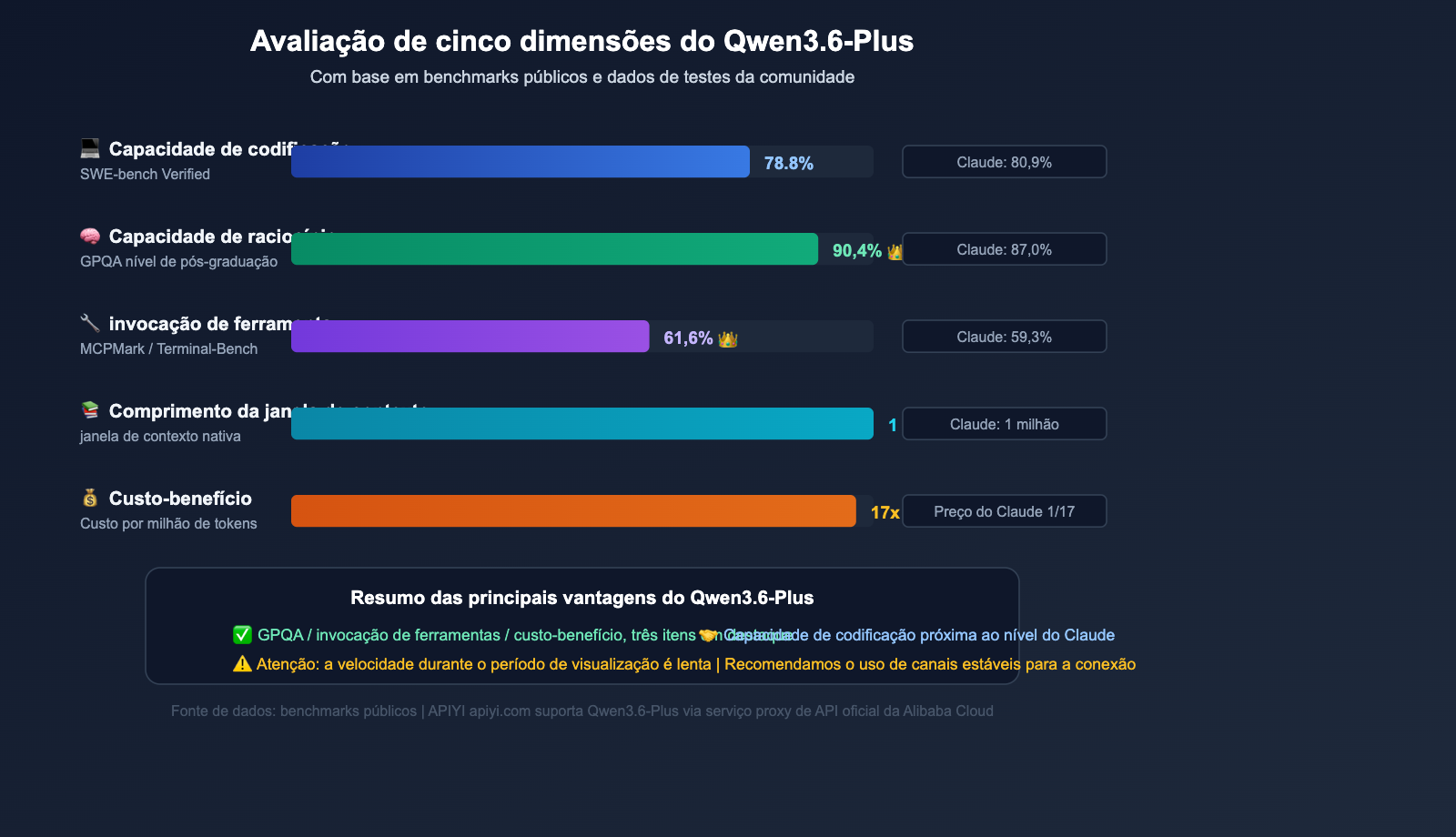
| Benchmark | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 78.8% | 80.9% | 76.2% |
| Terminal-Bench 2.0 | 61.6% | 59.3% | 57.8% |
| GPQA (Ciência nível pós-graduação) | 90.4% | 87.0% | 88.1% |
| MCPMark (Invocação de ferramentas) | 48.2% | 45.6% | 43.9% |
| Janela de contexto | 1 milhão de tokens | 1 milhão de tokens | 256 mil tokens |
| Saída máxima | 65.536 tokens | 32.000 tokens | 16.384 tokens |
Nos benchmarks cruciais Terminal-Bench e GPQA, o Qwen3.6-Plus superou até mesmo o Claude Opus 4.5, enquanto o preço da API oficial é cerca de 1/17 do preço do Claude. Esse custo-benefício impulsionou a demanda dos desenvolvedores — o que é, precisamente, a raiz do problema 429.
Análise profunda do erro 429 no Qwen3.6-Plus
O que é o erro 429
O código de status HTTP 429 é bem direto: Too Many Requests (Muitas solicitações). Quando o servidor recebe mais solicitações do que sua capacidade de processamento ou limites predefinidos em um determinado período, ele retorna este erro.
Uma resposta típica de erro 429:
{
"error": {
"code": 429,
"message": "Rate limit exceeded. Please slow down your requests.",
"metadata": {
"provider_name": "Qwen",
"raw": "{\"error\":{\"message\":\"Rate limit reached\",\"type\":\"rate_limit_error\"}}"
}
}
}
Os 4 principais motivos para a frequência de erros 429 do Qwen3.6-Plus no OpenRouter
Motivo 1: A demanda supera em muito a oferta
A relação custo-benefício do Qwen3.6-Plus é excelente. O preço oficial da API de nível básico é de cerca de US$ 0,29 por milhão de tokens de entrada, o que representa 1/17 do valor do Claude Opus 4.5. Com a entrada massiva de desenvolvedores e o OpenRouter atuando como um serviço proxy de API, a cota de poder computacional obtida da Alibaba Cloud é limitada.
Motivo 2: Ocupação excessiva por usuários do nível gratuito
O OpenRouter oferece o modelo gratuito qwen/qwen3.6-plus:free, atraindo muitos usuários que não pagam. Essas solicitações gratuitas compartilham o mesmo pool de recursos de back-end que as solicitações pagas, fazendo com que os usuários pagantes acabem sendo "prejudicados" pelo excesso de tráfego.
Motivo 3: Alocação conservadora de poder computacional durante o período de visualização
O Qwen3.6-Plus ainda está em fase de Preview (versão de visualização lançada em 30 de março, lançamento oficial em 2 de abril). A alocação de poder computacional da Alibaba Cloud para plataformas de terceiros durante o período de visualização costuma ser bastante conservadora, priorizando a qualidade do serviço em suas próprias plataformas (DashScope / Bailian).
Motivo 4: Gargalo na velocidade de inferência do próprio modelo
Embora testes da comunidade mostrem que o rendimento do Qwen3.6-Plus é cerca de 3 vezes maior que o do Claude Opus 4.6, no uso real, sua janela de contexto de 1 milhão de tokens e a arquitetura MoE ainda apresentam latência de resposta elevada ao lidar com tarefas complexas de agentes. Isso significa que cada solicitação ocupa a GPU por mais tempo, reduzindo o número total de solicitações que podem ser processadas por unidade de tempo.

🎯 Insight principal: O erro 429 não significa que seu código está com problemas, mas sim que há um desequilíbrio entre oferta e demanda. A solução é mudar para um canal com oferta suficiente, em vez de tentar novamente indefinidamente. Ao acessar o canal de redirecionamento oficial da Alibaba Cloud via APIYI (apiyi.com), você pode evitar efetivamente o problema de limitação de taxa do OpenRouter.
Solução 1 para o erro 429 no Qwen3.6-Plus: Estratégia de nova tentativa inteligente
Nova tentativa com recuo exponencial
Quando você não consegue alternar de canal temporariamente, uma estratégia de nova tentativa (retry) bem estruturada pode aliviar (embora não cure totalmente) o problema 429:
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI interface unificada, redirecionamento oficial do Alibaba Cloud
)
def call_qwen36_with_retry(messages, max_retries=5):
"""Invocação do modelo Qwen3.6-Plus com recuo exponencial"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=messages,
max_tokens=4096
)
return response.choices[0].message.content
except openai.RateLimitError as e:
if attempt == max_retries - 1:
raise
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Limite de taxa 429, {attempt+1}ª tentativa, aguardando {wait_time:.1f}s...")
time.sleep(wait_time)
# Exemplo de uso
result = call_qwen36_with_retry([
{"role": "user", "content": "Analise os gargalos de desempenho deste código"}
])
print(result)
Sugestões de parâmetros para a estratégia de nova tentativa
| Parâmetro | Valor recomendado | Explicação |
|---|---|---|
| Máximo de tentativas | 3-5 vezes | Mais de 5 vezes indica que o canal está instável |
| Tempo de espera inicial | 1-2 segundos | Muito curto é ineficaz, muito longo desperdiça tempo |
| Fator de recuo | 2x | O recuo exponencial é o padrão da indústria |
| Jitter (aleatoriedade) | 0-1 segundo | Evita o "efeito manada" |
| Limite de timeout | 30 segundos | A espera por tentativa não deve exceder 30 segundos |
Limitações da estratégia de nova tentativa
É importante deixar claro: a nova tentativa é apenas um analgésico, não uma cura. Quando o backend do Qwen3.6-Plus no OpenRouter está continuamente sobrecarregado, a taxa de sucesso das novas tentativas cai drasticamente. A solução definitiva é mudar para um canal de API com oferta suficiente.
Solução 2 para o erro 429 no Qwen3.6-Plus: Alternar canal de API
Por que alternar de canal é mais eficaz do que tentar novamente
A essência das frequentes ocorrências de 429 no OpenRouter é a insuficiência de cota de processamento para o Qwen3.6-Plus nesse canal. Mudar para um canal que se conecta diretamente ao poder computacional do Alibaba Cloud pode resolver o problema na raiz.
Comparação de canais de API para o Qwen3.6-Plus
| Canal | Estabilidade | Preço (Entrada/Milhão de Tokens) | Frequência de 429 | Coleta de dados |
|---|---|---|---|---|
| OpenRouter Free | Ruim | Gratuito | Altíssima | Sim (dados de treino) |
| OpenRouter Paid | Regular | ~$0.29 | Frequente | Sim (período de preview) |
| Alibaba Cloud Bailian | Boa | ¥2.00 | Baixa | Verificar contrato |
| APIYI (Direto Alibaba) | Boa | 20% de desconto oficial | Baixa | Não |
💡 Dica de escolha: Se sua aplicação exige estabilidade, recomendamos acessar o Qwen3.6-Plus via APIYI (apiyi.com). A plataforma utiliza o canal de redirecionamento oficial do Alibaba Cloud, com preços de apenas 80% do valor oficial (desconto de 0.88 no grupo + recarga de 100 dólares ganha 10 dólares), evitando os problemas de limitação de taxa do OpenRouter.
Migrar do OpenRouter para a APIYI exige apenas 2 linhas de código
O custo de migração é baixíssimo, basta alterar a base_url e a api_key:
import openai
# ❌ Antes: OpenRouter (frequentes 429)
# client = openai.OpenAI(
# api_key="sk-or-v1-xxxx",
# base_url="https://openrouter.ai/api/v1"
# )
# ✅ Agora: APIYI redirecionamento direto Alibaba (estável, sem 429)
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Você é um assistente profissional de revisão de código"},
{"role": "user", "content": "Ajude-me a otimizar o desempenho desta consulta SQL"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Versão Node.js:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'YOUR_APIYI_KEY',
baseURL: 'https://api.apiyi.com/v1' // APIYI interface unificada
});
const response = await client.chat.completions.create({
model: 'qwen3.6-plus',
messages: [
{ role: 'user', content: 'Analise a complexidade de tempo deste código' }
],
max_tokens: 4096
});
console.log(response.choices[0].message.content);

Qwen3.6-Plus 429 错误解决方案三:Otimização de solicitações locais
Reduzindo invocações do modelo desnecessárias
Além de alternar canais, otimizar seu padrão de solicitação também pode reduzir a probabilidade de disparar erros 429:
1. Consolidação de solicitações
# ❌ Ineficiente: envio item por item
for item in data_list:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Analise: {item}"}]
)
# ✅ Eficiente: consolidação em lote
batch_content = "\n".join([f"{i+1}. {item}" for i, item in enumerate(data_list)])
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Analise o conteúdo a seguir sequencialmente:\n{batch_content}"}],
max_tokens=16384
)
2. Cache de respostas de alta frequência
import hashlib
import json
_cache = {}
def cached_qwen_call(prompt, model="qwen3.6-plus"):
cache_key = hashlib.md5(f"{model}:{prompt}".encode()).hexdigest()
if cache_key in _cache:
return _cache[cache_key]
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
_cache[cache_key] = result
return result
3. Limitação de taxa na fila de solicitações
| Estratégia de Otimização | Efeito | Cenário de Aplicação |
|---|---|---|
| Consolidação de solicitações | Reduz 60-80% do volume | Processamento de dados em lote |
| Cache de respostas | Zero chamadas de API para solicitações idênticas | Cenários de consulta repetida |
| Limitação de taxa na fila | Suaviza picos de solicitação | Aplicações de alta concorrência |
| Estratégia de degradação | Alterna para modelo menor em caso de 429 | Serviços sensíveis à latência |
🔧 Dica técnica: As estratégias de otimização local acima funcionam melhor quando combinadas com canais de API estáveis. Ao acessar o Qwen3.6-Plus via APIYI (apiyi.com) e combinar a consolidação de solicitações com estratégias de cache, você pode reduzir custos enquanto mantém a estabilidade.
Análise das causas da lentidão do modelo Qwen3.6-Plus
Por que a resposta do Qwen3.6-Plus às vezes é lenta?
Muitos desenvolvedores relatam que, mesmo sem encontrar erros 429, a velocidade de resposta do Qwen3.6-Plus é "inexplicavelmente lenta". Isso não é um caso isolado e existem razões técnicas para isso:
1. Custo de inferência da arquitetura MoE
O Qwen3.6-Plus utiliza uma arquitetura de Especialistas Mistos (MoE). Embora o MoE possa reduzir significativamente os custos de treinamento, na fase de inferência, as decisões de roteamento e a troca de especialistas trazem custos adicionais. Especialmente ao lidar com janelas de contexto longas, a eficiência de inferência da arquitetura MoE é inferior à de modelos densos com o mesmo número de parâmetros.
2. Pressão de memória com janela de contexto de 1 milhão de tokens
A janela de contexto de 1 milhão de tokens é o principal diferencial do Qwen3.6-Plus, mas também significa que o KV Cache ocupa uma quantidade enorme de memória de vídeo (VRAM) da GPU. Quando vários usuários fazem solicitações de contexto longo simultaneamente, a VRAM da GPU torna-se um gargalo e a velocidade de inferência cai drasticamente.
3. Recursos computacionais limitados durante o período de pré-visualização
O Qwen3.6-Plus ainda está em fase de pré-visualização. Durante este estágio, a Alibaba Cloud geralmente não investe na mesma escala de poder computacional que terá no lançamento oficial. A equipe oficial pode estar observando os padrões de uso reais antes de expandir a capacidade gradualmente.
4. Consumo adicional de tokens pela cadeia de inferência Always-On
O Qwen3.6-Plus tem o modo de inferência de Cadeia de Pensamento (Chain-of-Thought) ativado por padrão. Isso significa que o modelo gera um processo de pensamento interno a cada resposta, e o número real de tokens gerados é muito maior do que a saída final. Esses "tokens ocultos" consomem tempo de inferência adicional.
Referência de teste de latência entre diferentes canais
| Canal | Latência do primeiro token | Throughput (Token/s) | Observações |
|---|---|---|---|
| OpenRouter (Pico) | 8-15s | 15-25 | Erros 429 frequentes |
| OpenRouter (Vale) | 3-5s | 30-50 | Horários de madrugada |
| Alibaba Cloud Bailian | 2-4s | 40-60 | Conexão direta doméstica |
| APIYI (Proxy direto) | 2-5s | 35-55 | Acesso estável no exterior |
💰 Dica de custo: A velocidade do Qwen3.6-Plus varia significativamente entre diferentes canais e cargas. Se você é sensível à latência, recomendamos realizar testes práticos via APIYI (apiyi.com). A plataforma oferece canais de proxy direto oficiais da Alibaba Cloud, permitindo que você aproveite descontos e obtenha uma velocidade de resposta mais estável.
Guia Prático de Início Rápido com o Qwen3.6-Plus
Exemplo completo de como chamar o Qwen3.6-Plus usando a APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Conversa básica
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Você é um especialista sênior em desenvolvimento Python"},
{"role": "user", "content": "Ajude-me a escrever um framework de crawler assíncrono de alto desempenho"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
Ver código completo para saída em streaming
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Saída em streaming - ideal para cenários que exigem feedback em tempo real
stream = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Você é um arquiteto sênior"},
{"role": "user", "content": "Projete um sistema de fila de mensagens que suporte um milhão de acessos simultâneos"}
],
max_tokens=16384,
temperature=0.7,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # Quebra de linha
🚀 Início rápido: Recomendamos obter sua chave API através da plataforma APIYI (apiyi.com) para realizar a invocação do modelo Qwen3.6-Plus. Registre-se para experimentar; recargas de 100 dólares ganham 10 dólares de bônus, e o Qwen3.6-Plus conta com 20% de desconto sobre o preço oficial.
Cenários de aplicação e recomendações de seleção para o Qwen3.6-Plus
Em quais cenários o Qwen3.6-Plus se destaca
| Cenário de Aplicação | Motivo da recomendação | Alternativas |
|---|---|---|
| Automação de Agentes | Liderança de 61,6% no Terminal-Bench, chamada de ferramenta nativa | Claude Opus 4.5 |
| Revisão/Correção de Código | 78,8% no SWE-bench, próximo ao nível do Claude | Claude Opus 4.5 |
| Raciocínio Científico | 90,4% no GPQA, o mais alto do mercado | GPT-5.4 |
| Processamento de Documentos Longos | Janela de contexto de 1 milhão de tokens | Gemini 2.5 Pro |
| Projetos sensíveis a custos | Preço de aproximadamente 1/17 do Claude | DeepSeek V3 |
Cenários onde o uso requer cautela
- Aplicações em tempo real extremamente sensíveis à latência: A arquitetura MoE do Qwen3.6-Plus apresenta latência mais alta em contextos longos.
- Caminhos críticos em ambientes de produção: Modelos em fase de pré-visualização podem apresentar mudanças de comportamento imprevisíveis.
- Cenários que exigem garantia estrita de SLA: Não há SLA oficial para modelos em fase de pré-visualização.
🎯 Recomendação de seleção: Para projetos que precisam utilizar vários modelos simultaneamente, sugerimos a integração unificada através da plataforma APIYI (apiyi.com). A plataforma suporta interfaces compatíveis com OpenAI para modelos convencionais como Qwen3.6-Plus, Claude e GPT. Com uma única chave API, você pode alternar entre diferentes modelos, facilitando o agendamento flexível conforme a necessidade.
Perguntas frequentes sobre o erro 429 no Qwen3.6-Plus
Q1: Por que ainda recebo o erro 429 mesmo pagando no OpenRouter?
Isso acontece porque os usuários pagantes e gratuitos do OpenRouter compartilham o mesmo pool de recursos computacionais. Mesmo sendo um usuário pagante, quando o volume total de solicitações excede a cota que o OpenRouter obtém do Alibaba Cloud, os usuários pagantes também são limitados. A solução é mudar para um canal com oferta mais estável, como utilizar o canal de redirecionamento oficial da Alibaba Cloud diretamente através da APIYI (apiyi.com).
Q2: O erro 429 no Qwen3.6-Plus vai melhorar?
Com a expansão da capacidade da Alibaba Cloud e o lançamento oficial (GA – General Availability) do modelo, espera-se que o problema do erro 429 seja atenuado. No entanto, como o OpenRouter é uma plataforma de serviço proxy de API, sua alocação de poder computacional é sempre limitada pela oferta do fornecedor. Se o seu negócio exige estabilidade, recomendamos o uso a longo prazo de canais que se conectam diretamente à infraestrutura da Alibaba Cloud, em vez de depender de plataformas de terceiros.
Q3: Qual é a diferença entre o Qwen3.6-Plus da APIYI e o do OpenRouter?
A principal diferença está na origem do poder computacional. A plataforma APIYI (apiyi.com) utiliza o canal oficial de redirecionamento da Alibaba Cloud, o que significa que o processamento vem diretamente da plataforma Bailian da Alibaba Cloud, e não de um intermediário. Isso resulta em uma taxa de ocorrência de erros 429 muito menor e uma velocidade de resposta mais estável. Em termos de preço, a APIYI oferece um desconto oficial de 20% (desconto de 0,88 no grupo + bônus de recarga), além de ser compatível com o formato da SDK da OpenAI, tornando o custo de migração praticamente zero.
Q4: É normal o Qwen3.6-Plus ser lento?
A arquitetura MoE do Qwen3.6-Plus e sua janela de contexto de 1 milhão de tokens exigem, de fato, mais recursos durante a inferência do que modelos densos. Somado à configuração conservadora de recursos durante o período de pré-visualização, a velocidade mais lenta é um fenômeno comum nesta fase. No entanto, sua capacidade de processamento absoluto ainda é impressionante; recomendamos o uso de saída em fluxo (stream=True) para melhorar a experiência do usuário.
Q5: Como usar o Qwen3.6-Plus no Claude Code?
O Qwen3.6-Plus é compatível tanto com o protocolo da Anthropic quanto com o da OpenAI. Você pode usar o Qwen3.6-Plus alterando a configuração do endpoint da API no Claude Code. Ao acessar através da plataforma APIYI (apiyi.com), basta usar o formato padrão da SDK da OpenAI; consulte a documentação da plataforma para obter as configurações específicas.
Resumo de soluções para o erro 429 no Qwen3.6-Plus
O problema 429 no Qwen3.6-Plus é, essencialmente, uma questão de desequilíbrio entre oferta e demanda: o modelo é muito poderoso, o preço é muito baixo e a demanda é alta demais, superando a cota de processamento que o OpenRouter consegue oferecer a todos os usuários.
Cenários de aplicação para as três soluções:
- Tentativa inteligente (Retry): Solução temporária, ideal para cenários de invocação de baixa frequência.
- Otimização local: Reduz o volume de requisições, adequada para todos os cenários.
- Troca de canal: A solução definitiva, recomendada para projetos que exigem alta estabilidade.
Para desenvolvedores que precisam de uma invocação estável do Qwen3.6-Plus, recomendamos o acesso através da plataforma APIYI (apiyi.com) utilizando o canal de redirecionamento oficial da Alibaba Cloud. Você aproveita 20% de desconto sobre o preço oficial e dá adeus aos problemas de limitação de taxa (429), permitindo que sua aplicação foque na lógica de negócio em vez de lidar com erros.
📝 Autor: Equipe APIYI | Para mais tutoriais de integração de API de Modelos de Linguagem Grande e guias de melhores práticas, visite a Central de Ajuda da APIYI: help.apiyi.com