Nota do autor: Análise aprofundada da janela de contexto de 1M do GPT-5.4, ponto de corte de preço de 272K tokens excede o dobro, intervalo de melhor desempenho 127K-272K, comparação completa de preços e estratégias para economizar
O GPT-5.4 afirma suportar um contexto super longo de 1,05 milhão de tokens, mas muitos desenvolvedores não sabem: após exceder 272K tokens, o preço dobra e a precisão também cai. Esta não é uma história simples de "quanto maior, melhor".
Valor principal: Este artigo detalha a curva de desempenho do contexto do GPT-5.4, o mecanismo do ponto de corte de preço de 272K e como usar o GPT-5.4 com o menor custo e máxima eficiência através do APIYI.

Pontos-chave sobre preços de contexto do GPT-5.4
| Ponto | Descrição | Impacto Prático |
|---|---|---|
| Contexto Total | 1,050,000 tokens (1,05 milhão) | Teoricamente pode processar documentos super longos |
| Ponto de Corte 272K | Após exceder, o preço de entrada dobra ($2.50→$5.00) | Controlar abaixo de 272K pode economizar metade do custo de entrada |
| Intervalo de Melhor Desempenho | 127K-272K tokens | Precisão ~97%, melhor custo-benefício |
| Zona de Queda de Desempenho | Acima de 256K a precisão começa a cair | Intervalo 512K-1M pode ter precisão reduzida para ~36% |
| vs GPT-5.2 | Entrada 43% mais cara, saída 7% mais cara | Mas usa menos Tokens de raciocínio, reduzindo a diferença real |
Compreensão-chave do contexto do GPT-5.4: Suportar não significa ser ideal
Este ponto é crucial: O GPT-5.4 suportar 1,05 milhão de tokens de contexto não significa que você deve enchê-lo. Pelos dados de avaliação públicos da OpenAI:
- 16K-32K tokens: Precisão de recuperação "Needle-in-a-Haystack" ~97%
- 127K-272K tokens: Precisão ainda estável em alto nível, e é o intervalo de preço padrão
- Acima de 256K: A precisão começa a cair
- 512K-1M tokens: A precisão pode cair drasticamente para ~36%
O GPT-5.2 anteriormente atingiu quase 100% de precisão no teste MRCR de 4-needle dentro de 256K tokens, reforçando que 256K é um ponto crítico para confiabilidade de desempenho.
Recomendação prática: Para a maioria dos cenários de aplicação, manter a entrada abaixo de 272K é a estratégia mais inteligente — garante precisão e evita o dobro do preço. Acessando o GPT-5.4 através do APIYI apiyi.com, os preços são sincronizados com os oficiais, e participando de promoções de recarga com bônus, pode-se obter descontos de até 20%.
Análise Completa de Preços de Contexto do GPT-5.4
Preços Padrão do GPT-5.4 (por milhão de Tokens)
Aqui está a estrutura completa de preços por faixa do GPT-5.4:
| Modo de Processamento | Entrada (≤272K) | Entrada (>272K) | Entrada em Cache (≤272K) | Entrada em Cache (>272K) | Saída (≤272K) | Saída (>272K) |
|---|---|---|---|---|---|---|
| Standard | $2.50 | $5.00 | $0.25 | $0.50 | $15.00 | $22.50 |
| Batch | $1.25 | $2.50 | $0.13 | $0.26 | $7.50 | $11.25 |
| Flex | $1.25 | $2.50 | $0.13 | $0.26 | $7.50 | $11.25 |
| Priority | $5.00 | — | $0.50 | — | $30.00 | — |
Três Detalhes Cruciais sobre os Preços de Contexto do GPT-5.4
Primeiro, acima de 272K há um acréscimo total. Quando sua entrada ultrapassa 272K tokens, o mecanismo de acréscimo se aplica a toda a sessão, não apenas à parte excedente. Isso significa que, uma vez ultrapassado o limite, todos os tokens são calculados com o preço dobrado.
Segundo, o preço da saída também aumenta. Não é apenas a entrada que dobra; acima de 272K, o preço da saída também sobe de $15.00 para $22.50, um aumento de 50%. Isso tem um grande impacto em tarefas intensivas em saída (como geração de código, escrita de textos longos).
Terceiro, a entrada em cache é uma arma para economizar. A entrada em cache na faixa padrão custa apenas $0.25/M tokens, um décimo do preço original. Se suas tarefas envolvem comandos de sistema repetidos ou contexto fixo, usar bem o cache pode reduzir drasticamente os custos.
Análise Comparativa de Preços: GPT-5.4 vs GPT-5.2
A principal preocupação de muitos desenvolvedores: Quanto mais custa migrar do GPT-5.2 para o GPT-5.4?

Principais Diferenças de Preços: GPT-5.4 vs GPT-5.2
| Item de Preço | GPT-5.2 | GPT-5.4 Padrão | GPT-5.4 Estendido | Aumento Padrão |
|---|---|---|---|---|
| Entrada | $1.75/M | $2.50/M | $5.00/M | +43% |
| Entrada em Cache | $0.175/M | $0.25/M | $0.50/M | +43% |
| Saída | $14.00/M | $15.00/M | $22.50/M | +7% |
| Entrada Pro | $21.00/M | $30.00/M | $60.00/M | +43% |
| Saída Pro | $168.00/M | $180.00/M | $270.00/M | +7% |
O GPT-5.4 é mais caro, mas a diferença de custo real não é grande
A OpenAI afirma oficialmente que o GPT-5.4 é "o modelo de inferência mais eficiente" — ele resolve o mesmo problema com menos Tokens de inferência. Ou seja, embora o preço unitário tenha subido, o número total de Tokens consumidos por chamada pode ser menor.
No entanto, é importante notar: as respostas do GPT-5.4 são em média 24% mais longas que as do GPT-5.2, o que pode compensar parcialmente o ganho de eficiência na inferência.
Melhores Práticas para Uso do Contexto do GPT-5.4
Três Regras de Ouro
Regra Um: Mantenha-se abaixo de 272K. Esta é a faixa de melhor custo-benefício — alta precisão, baixo custo. Para a grande maioria dos cenários de aplicação, 272K tokens são suficientes para cobrir diálogos multi-turno, análise de documentos longos e revisão de grandes bases de código.
Regra Dois: 127K-272K é a faixa ideal. Dentro deste intervalo, a taxa de precisão de recuperação do modelo permanece estável em cerca de 97%, enquanto aproveita ao máximo a vantagem do contexto longo do GPT-5.4. Isso é o dobro da janela padrão de 128K do GPT-5.2, sendo suficiente para lidar com a maioria das tarefas que "antes não cabiam".
Regra Três: Pense duas vezes antes de exceder 272K. A menos que sua tarefa realmente exija o processamento de um documento super longo de uma só vez (como análise de um repositório de código completo, revisão de grandes textos jurídicos), não é recomendado ultrapassar 272K — porque o preço dobra enquanto a precisão cai, reduzindo drasticamente o custo-benefício.
Técnicas de Otimização de Contexto para o GPT-5.4
| Técnica | Descrição | Economia |
|---|---|---|
| Aproveite o Cache de Entrada | Use cache para comandos de sistema repetidos, apenas $0.25/M | Economiza 90% do custo de entrada |
| Tool Search | Carregue definições de ferramentas sob demanda, não insira todas de uma vez | Economiza 47% dos Tokens |
| Processamento Segmentado | Divida documentos muito longos em segmentos, cada um com até 272K | Evita preços dobrados |
| Compressão por Resumo | Primeiro extraia um resumo com um modelo mais barato, depois faça uma análise profunda com o GPT-5.4 | Reduz significativamente a entrada |
Vantagens Detalhadas da Integração do GPT-5.4 via APIYI
A APIYI (apiyi.com) já disponibilizou o GPT-5.4, com preços idênticos aos oficiais. Abaixo estão as vantagens principais da APIYI em comparação com a conexão direta à OpenAI oficial:
Comparação: APIYI vs. OpenAI Oficial
| Dimensão de Comparação | OpenAI Oficial | APIYI apiyi.com |
|---|---|---|
| Barreira de Cadastro | Exige cartão de crédito americano | ❌ Não exige, use após cadastro |
| Recarga Mínima | Exige métodos de pagamento internacionais | ✅ Mínimo de 35元 (cerca de 5 USD) |
| Limite de Concorrência | Limitação por nível (RPM/TPM) | ✅ Concorrência ilimitada |
| Batch API | ✅ Suportado (metade do preço) | ❌ Não suporta Batch/Flex |
| Preço Standard | $2.50 entrada / $15.00 saída | Preços idênticos |
| Desconto Real | Sem bônus de recarga | ✅ Atividades de recarga podem chegar a 20% de desconto |
| Facilidade de Uso | Requer VPN + pagamento internacional | ✅ Pronto para uso, integração em 5 minutos |
Para quais usuários a APIYI GPT-5.4 é ideal?
Usuários que querem experimentar: Comece a experimentar todas as capacidades do GPT-5.4 (incluindo Computer Use) com apenas 35元, sem necessidade de pré-pagamento alto.
Usuários de longo prazo: Através de atividades de recarga com bônus, recargas maiores podem render créditos extras, reduzindo o custo real para até 20% de desconto. Se seu consumo mensal for estável em um determinado nível, essa vantagem de desconto se acumula consideravelmente ao longo do tempo.
Desenvolvedores na China: Não precisa de cartão de crédito americano, não precisa de VPN, não precisa de configurações complexas de pagamento internacional. Cadastre-se na APIYI apiyi.com → Recarregue → Obtenha a chave API → Altere uma linha de base_url e já pode fazer chamadas.
Cenários de Alta Concorrência: A OpenAI oficial limita RPM e TPM por nível (Tier 1 cerca de 1000 RPM), a APIYI não limita a concorrência, sendo ideal para ambientes de produção que exigem muitas chamadas concorrentes.
Atenção: Atualmente, a APIYI não suporta o Batch API e o modo de processamento Flex da OpenAI. Se seu fluxo de trabalho depende da capacidade de processamento em lote com metade do preço, avalie se é adequado. Para interações em tempo real e chamadas de API padrão, a APIYI é a escolha mais conveniente.
Guia Rápido de Contexto do GPT-5.4
Exemplo Mínimo
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Chamada no intervalo padrão (≤272K, preço padrão)
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "system", "content": "Você é um especialista em revisão de código"},
{"role": "user", "content": "Analise o seguinte código..."}
],
max_tokens=4096
)
print(response.choices[0].message.content)
Ver exemplo de uso de contexto longo e estimativa de custo
from openai import OpenAI
import tiktoken
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def estimate_cost(input_tokens, output_tokens):
"""Estima o custo de uma chamada ao GPT-5.4"""
if input_tokens <= 272000:
input_cost = (input_tokens / 1_000_000) * 2.50
output_cost = (output_tokens / 1_000_000) * 15.00
else:
input_cost = (input_tokens / 1_000_000) * 5.00 # Dobro
output_cost = (output_tokens / 1_000_000) * 22.50 # 1.5x
return input_cost + output_cost
# Exemplo: analisando um arquivo grande
with open("large_codebase.txt", "r") as f:
code_content = f.read()
# Estima a quantidade de tokens
enc = tiktoken.encoding_for_model("gpt-4o")
token_count = len(enc.encode(code_content))
print(f"Quantidade de Tokens de entrada: {token_count}")
if token_count > 272000:
print(f"⚠️ Excedeu o ponto de corte de 272K, o preço dobrará!")
print(f"Sugestão: considere processar em partes ou usar compressão por resumo")
estimated = estimate_cost(token_count, 4000)
print(f"Custo estimado: ${estimated:.4f}")
# Chamada real
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "user", "content": f"Analise as seguintes vulnerabilidades de segurança no código:\n{code_content}"}
],
max_tokens=8000
)
print(response.choices[0].message.content)
Sugestão: Acesse o GPT-5.4 através da APIYI em apiyi.com, com preços sincronizados com os oficiais. Atividades de recarga com bônus podem oferecer descontos de até 20%. Recarga mínima a partir de 35 yuan, registro e uso imediato, sem necessidade de cartão de crédito americano.
Estimativa de Custo Contextualizada para o GPT-5.4
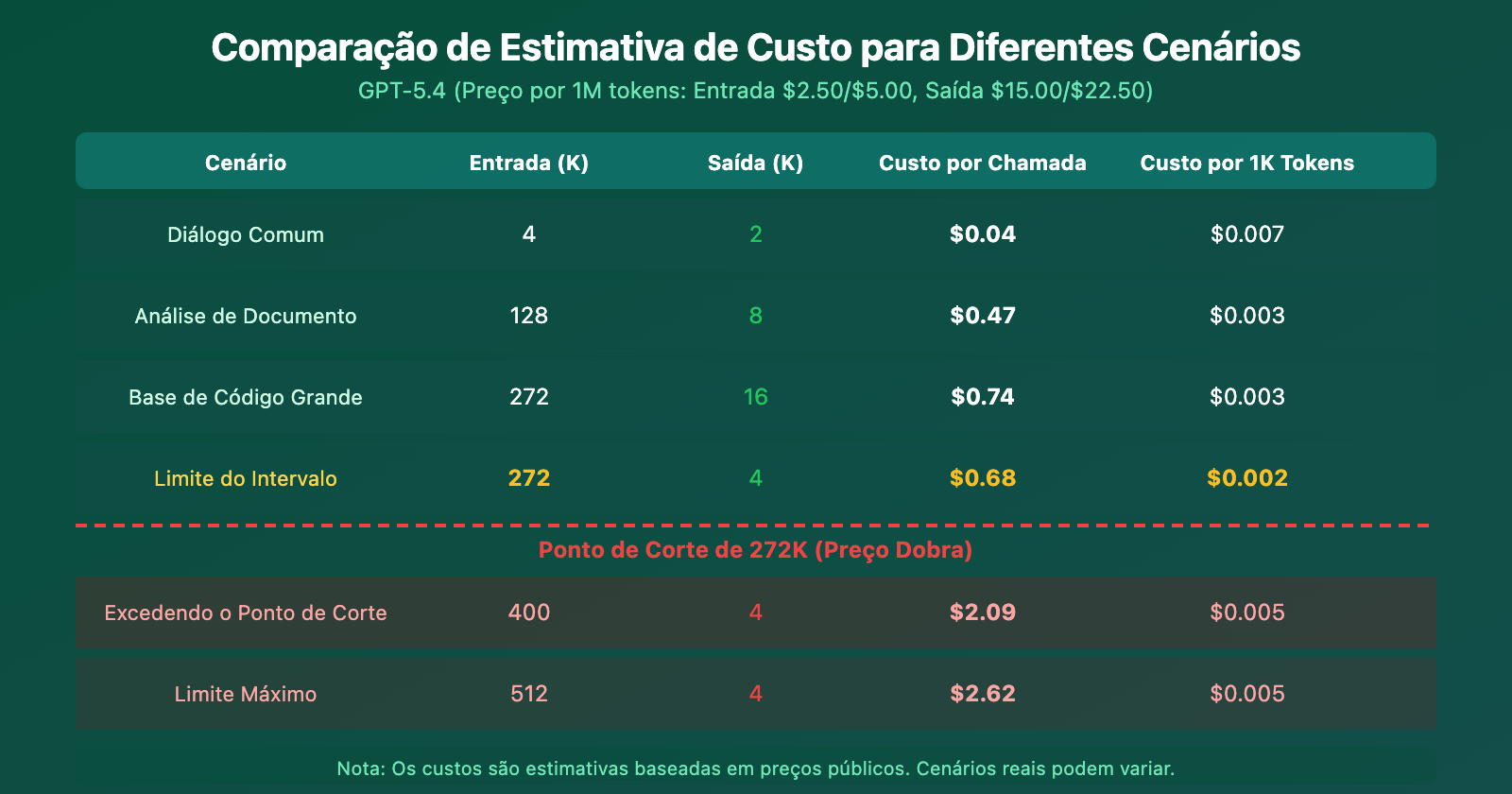
A partir da estimativa de custo, fica claro que: 272K é um penhasco de custo abrupto. Com apenas 128K a mais de entrada (de 272K para 400K), o custo por chamada salta de $0.74 para $2.09 — um aumento de quase 3 vezes.
Perguntas Frequentes
Q1: No GPT-5.4, o preço adicional após exceder 272K é cobrado apenas pela parte excedente ou pelo total?
É pelo total. Uma vez que seus tokens de entrada ultrapassam o limite de 272K, todos os tokens da sessão inteira são calculados pelo preço estendido (entrada $5.00/M, saída $22.50/M), não apenas a parte excedente. Portanto, manter o controle abaixo de 272K é a chave para economizar.
Q2: O APIYI não suporta Batch API, isso não fica muito caro?
É verdade que o APIYI não suporta os modos de processamento Batch e Flex da OpenAI (cujos preços são metade do preço padrão). No entanto, a vantagem do APIYI está em: não exigir cartão de crédito americano, recarga mínima de 35 yuan, concorrência ilimitada e uso imediato. Além disso, através de atividades de recarga com bônus, é possível obter um desconto real de 20%, o que em cenários de invocação padrão já se aproxima do nível de desconto do Batch. Se seu fluxo de trabalho é de interação em tempo real e não de processamento em lote, o APIYI é mais conveniente.
Q3: Como posso julgar rapidamente se minha tarefa vai exceder 272K?
Estimativa simples: 1 palavra em inglês ≈ 1.3 tokens, 1 caractere chinês ≈ 2-3 tokens. 272K tokens equivalem aproximadamente a 200 mil palavras em inglês ou 90-130 mil caracteres chineses. Se sua entrada, somada ao comando do sistema e ao histórico da conversa, não ultrapassar esse volume, você pode aproveitar com segurança o preço padrão. Recomenda-se adicionar verificações de contagem de tokens no código para alertas antecipados. Essa lógica de cálculo também se aplica ao fazer chamadas através do APIYI (apiyi.com).
Resumo
Os pontos principais sobre a precificação de contexto do GPT-5.4:
- 272K é o ponto crítico: Após exceder 272K tokens, o preço de entrada dobra ($2.50→$5.00), a saída aumenta 50% ($15.00→$22.50), e isso se aplica ao volume total de tokens.
- 127K-272K é a faixa ideal: A precisão permanece estável em cerca de 97%, está dentro da faixa de preço padrão, oferecendo o melhor custo-benefício.
- A precisão cai após 256K: Na faixa de 512K-1M, a precisão pode cair para cerca de 36%, use com cautela.
- Mais caro que o GPT-5.2, mas mais eficiente: Na faixa padrão, a entrada é 43% mais cara e a saída 7% mais cara, mas usa menos Tokens de inferência.
Estratégia de economia: Mantenha a entrada abaixo de 272K, aproveite bem o cache de entrada (economiza 90%), utilize a Busca por Ferramentas (Tool Search) (economiza 47%). Ao acessar via APIYI (apiyi.com), a precificação é sincronizada com a oficial, e as atividades de recarga com bônus podem proporcionar um desconto de 20%. Recarga mínima de 35 yuan, não requer cartão de crédito americano, concorrência ilimitada, use imediatamente após o registro — especialmente adequado para experimentação e uso a longo prazo.
📚 Referências
-
Página de preços da API OpenAI: Preços completos do GPT-5.4 e explicação da cobrança por níveis de contexto
- Link:
developers.openai.com/api/docs/pricing - Descrição: Fonte oficial e autoritativa de preços, incluindo preços para todos os modos Standard/Batch/Flex/Priority
- Link:
-
Documentação do modelo OpenAI GPT-5.4: Especificações técnicas como janela de contexto, limites de saída
- Link:
developers.openai.com/api/docs/models/gpt-5.4 - Descrição: Documentação oficial de especificações do modelo
- Link:
-
Anúncio de lançamento do OpenAI GPT-5.4: Capacidades principais e dados de testes de referência
- Link:
openai.com/index/introducing-gpt-5-4/ - Descrição: Inclui benchmarks de desempenho, filosofia de design e explicação da estratégia de preços
- Link:
-
Discussão na comunidade de desenvolvedores OpenAI: Explicação detalhada sobre preços, limites de contexto e Tool Search do GPT-5.4
- Link:
community.openai.com/t/gpt-5-4-deep-dive-pricing-context-limits-and-tool-search-explained/ - Descrição: Discussão aprofundada de desenvolvedores sobre a estrutura de preços e desempenho de contexto
- Link:
Autor: Equipe Técnica da APIYI
Discussão técnica: Sinta-se à vontade para discutir experiências de uso de contexto do GPT-5.4 e técnicas de otimização de custos nos comentários. Mais materiais estão disponíveis no centro de documentação da APIYI docs.apiyi.com