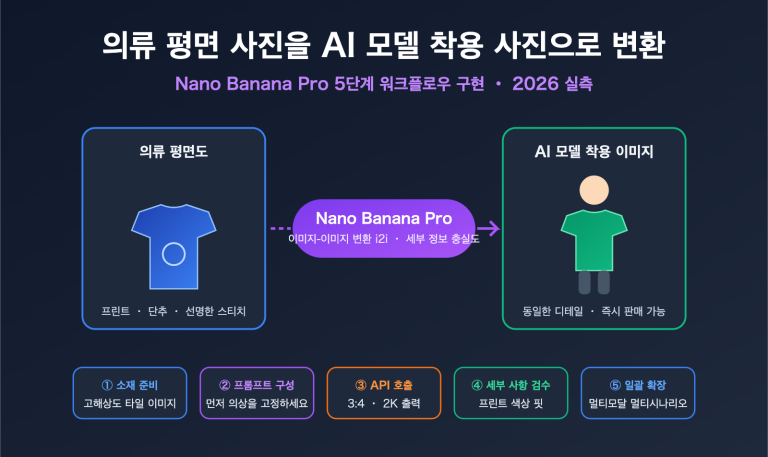
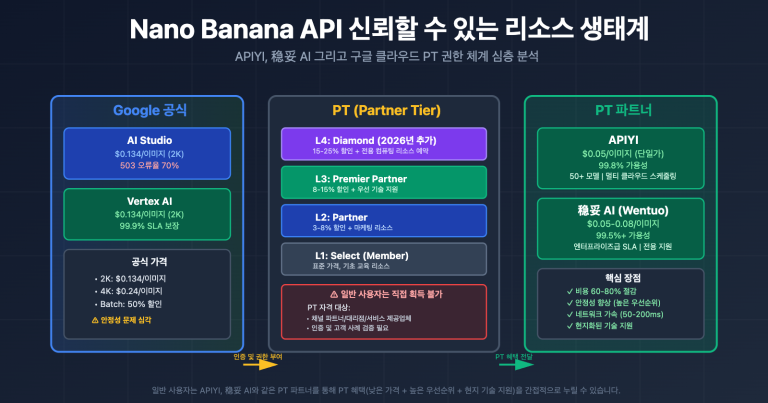
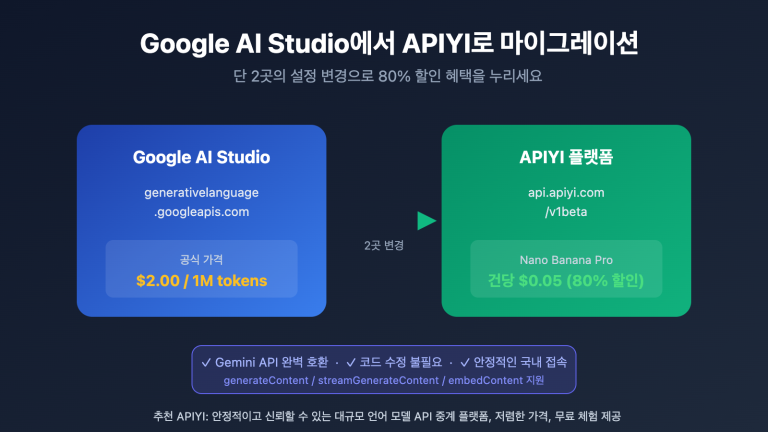
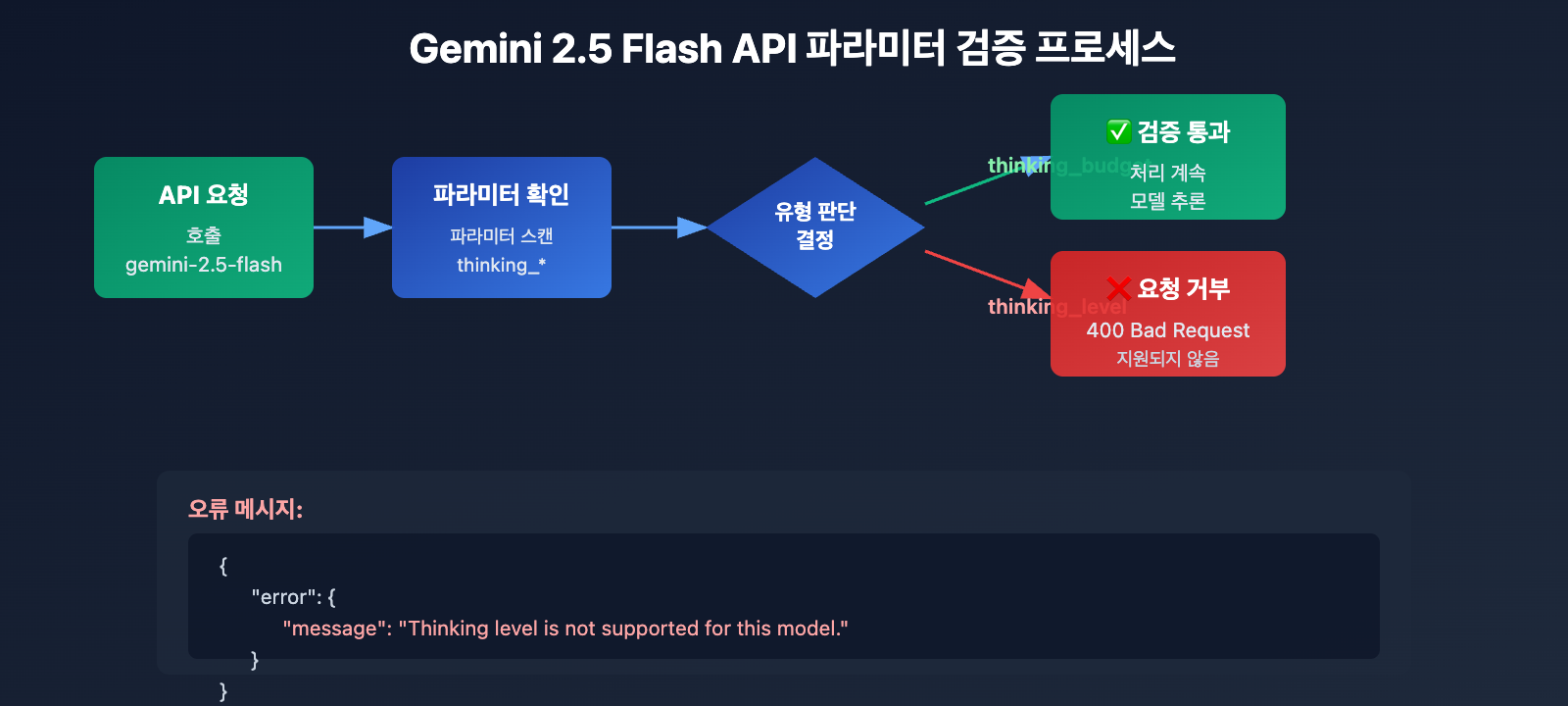
gemini-2.5-flash를 호출할 때 Thinking level is not supported for this model 오류가 발생하는데, gemini-3-flash-preview로 바꾸면 정상적으로 작동하나요? 이는 Google Gemini API가 모델 세대 업그레이드 과정에서 도입한 파라미터 설계의 변화 때문입니다. 이 글에서는 Gemini 2.5와 3.0의 사고 모드 파라미터 지원에 관한 근본적인 차이점을 체계적으로 분석해 보겠습니다.
핵심 가치: 이 글을 읽고 나면 Gemini 2.5와 3.0 시리즈 모델의 사고 모드 파라미터 설계에 담긴 본질적인 차이를 이해하고, 올바른 파라미터 설정 방법을 익혀 파라미터 혼용으로 인한 API 호출 실패를 방지할 수 있습니다.

Gemini 사고 모드 파라미터 진화 핵심 요점
| 모델 시리즈 | 지원 파라미터 | 파라미터 타입 | 사용 가능 범위 | 기본값 | 비활성화 가능 여부 |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | thinking_budget |
정수 (128-32768) | 정밀한 토큰 예산 | 8192 | ❌ 비활성화 불가 |
| Gemini 2.5 Flash | thinking_budget |
정수 (0-24576) 또는 -1 | 정밀한 토큰 예산 또는 동적 | -1 (동적) | ✅ 비활성화 가능 (0으로 설정) |
| Gemini 2.5 Flash-Lite | thinking_budget |
정수 (512-24576) | 정밀한 토큰 예산 | 0 (비활성화) | ✅ 기본 비활성화 |
| Gemini 3.0 Pro | thinking_level |
열거형 ("low"/"high") | 시맨틱 레벨 | "high" | ❌ 완전 비활성화 불가 |
| Gemini 3.0 Flash | thinking_level |
열거형 ("minimal"/"low"/"medium"/"high") | 시맨틱 레벨 | "high" | ⚠️ "minimal"만 가능 |
Gemini 2.5 vs 3.0 사고 모드 파라미터 설계 차이
핵심 차이점: Gemini 2.5 시리즈는 thinking_budget(토큰 예산제)을 사용하고, Gemini 3.0 시리즈는 thinking_level(시맨틱 레벨제)을 사용합니다. 이 두 파라미터는 서로 완전히 호환되지 않으며, 잘못된 모델 버전에 사용하면 400 Bad Request 오류가 발생합니다.
Google이 Gemini 3.0에서 thinking_level을 도입한 핵심 이유는 설정의 복잡성을 줄이고 추론 효율을 높이기 위해서입니다. Gemini 2.5의 토큰 예산제는 개발자가 사고 토큰 수를 정밀하게 예측해야 했지만, Gemini 3.0의 레벨제는 이러한 복잡성을 4가지 시맨틱 레벨로 추상화했습니다. 이를 통해 모델 내부에서 최적의 토큰 예산을 자동으로 할당하며, 추론 속도를 2배까지 향상시켰습니다.
💡 기술 팁: 실제 개발 시에는 APIYI(apiyi.com) 플랫폼을 통해 모델 전환 테스트를 진행해 보시는 것을 추천합니다. 이 플랫폼은 통합 API 인터페이스를 제공하여 Gemini 2.5와 3.0 전 시리즈 모델을 지원하므로, 다양한 사고 모드 파라미터의 호환성과 실제 효과를 빠르게 검증하기에 매우 편리합니다.
근본 원인 1: Gemini 2.5 시리즈는 thinking_level 파라미터를 지원하지 않습니다
API 파라미터 설계의 세대 간 격리
Gemini 2.5 시리즈 모델(Pro, Flash, Flash-Lite 포함)은 API 설계 단계에서 thinking_level 파라미터를 전혀 인식하지 못합니다. gemini-2.5-flash를 호출할 때 thinking_level 파라미터를 전달하면 API는 다음과 같은 오류를 반환해요.
{
"error": {
"message": "Thinking level is not supported for this model.",
"type": "upstream_error",
"code": 400
}
}
오류 발생 메커니즘:
- Gemini 2.5 모델의 API 검증 레이어에는
thinking_level파라미터 정의가 포함되어 있지 않습니다. thinking_level이 포함된 모든 요청은 즉시 거부되며,thinking_budget으로 매핑하려는 시도조차 하지 않습니다.- 이는 하드코딩된 파라미터 격리로, 자동 전환이나 하위 호환성이 존재하지 않습니다.
Gemini 2.5 시리즈의 올바른 파라미터: thinking_budget
Gemini 2.5 Flash 파라미터 규격:
# 올바른 설정 예시
extra_body = {
"thinking_budget": -1 # 동적 사고 모드
}
# 또는 사고 모드 비활성화
extra_body = {
"thinking_budget": 0 # 완전 비활성화
}
# 또는 정밀 제어
extra_body = {
"thinking_budget": 2048 # 정확히 2048 토큰 예산 할당
}
Gemini 2.5 Flash의 thinking_budget 값 범위:
| 값 | 의미 | 추천 시나리오 |
|---|---|---|
0 |
사고 모드 완전 비활성화 | 단순 지시 수행, 고처리량(High-throughput) 애플리케이션 |
-1 |
동적 사고 모드 (최대 8192 토큰) | 일반적인 상황, 복잡도에 따른 자동 적응 |
512-24576 |
정밀 토큰 예산 | 비용 민감형 애플리케이션, 정밀한 제어가 필요한 경우 |
🎯 선택 가이드: Gemini 2.5 Flash로 전환할 때는 먼저 APIYI(apiyi.com) 플랫폼을 통해
thinking_budget값에 따른 응답 품질과 지연 시간의 변화를 테스트해 보는 것을 추천합니다. 이 플랫폼은 파라미터 설정을 빠르게 변경하며 테스트할 수 있어, 비즈니스 시나리오에 가장 적합한 예산 값을 찾기에 매우 편리합니다.
근본 원인 2: Gemini 3.0 시리즈는 thinking_budget 파라미터를 지원하지 않습니다
파라미터 설계의 전방 비호환성
Google 공식 문서에서는 Gemini 3.0이 하위 호환성을 위해 여전히 thinking_budget 파라미터를 허용한다고 명시하고 있지만, 실제 테스트 결과는 다음과 같습니다.
thinking_budget사용 시 성능 저하 발생 가능성- 공식 문서에서
thinking_level사용을 강력히 권장 - 일부 API 구현에서는
thinking_budget을 완전히 거부할 수 있음
Gemini 3.0 Flash의 올바른 파라미터: thinking_level
# 올바른 설정 예시
extra_body = {
"thinking_level": "medium" # 중간 강도 추론
}
# 또는 최소 사고 (비활성화에 가까움)
extra_body = {
"thinking_level": "minimal" # 최소 사고 모드
}
# 또는 고강도 추론 (기본값)
extra_body = {
"thinking_level": "high" # 심층 추론
}
Gemini 3.0 Flash의 thinking_level 등급 설명:
| 등급 | 추론 강도 | 지연 시간 | 비용 | 추천 시나리오 |
|---|---|---|---|---|
"minimal" |
거의 추론 없음 | 최저 | 최저 | 단순 지시 수행, 고처리량 |
"low" |
얕은 수준의 추론 | 낮음 | 낮음 | 챗봇, 가벼운 QA |
"medium" |
중간 수준의 추론 | 중간 | 중간 | 일반적인 추론 작업, 코드 생성 |
"high" |
심층 추론 | 높음 | 높음 | 복잡한 문제 해결, 심층 분석 (기본값) |
Gemini 3.0 Pro의 특수 제한 사항
중요: Gemini 3.0 Pro는 사고 모드를 완전히 비활성화할 수 없습니다. thinking_level: "low"로 설정하더라도 일정 수준의 추론 능력은 유지됩니다. 만약 최대 속도를 위해 '제로 사고' 응답이 필요하다면 Gemini 2.5 Flash의 thinking_budget: 0을 사용해야 합니다.
# Gemini 3.0 Pro 사용 가능 등급 (2가지만 지원)
extra_body = {
"thinking_level": "low" # 최저 등급 (여전히 추론 수행)
}
# 또는
extra_body = {
"thinking_level": "high" # 기본 고강도 추론
}
💰 비용 최적화: 비용에 민감한 프로젝트에서 비용 절감을 위해 사고 모드를 완전히 비활성화해야 한다면, APIYI(apiyi.com) 플랫폼을 통해 Gemini 2.5 Flash API를 호출하는 것을 권장합니다. 해당 플랫폼은 유연한 과금 방식과 합리적인 가격을 제공하므로 정밀한 비용 제어가 필요한 시나리오에 매우 적합합니다.
근본 원인 3: 이미지 모델 및 특수 변체 모델의 파라미터 제한
Gemini 2.5 Flash Image 모델은 사고 모드를 지원하지 않아요
중요한 발견: gemini-2.5-flash-image와 같은 비전 모델은 thinking_budget이나 thinking_level 등 그 어떤 사고 모드 파라미터도 전혀 지원하지 않습니다.
오류 예시:
# gemini-2.5-flash-image 호출 시
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "이 이미지 분석해줘"}],
extra_body={
"thinking_budget": -1 # ❌ 오류: 이미지 모델은 지원하지 않음
}
)
# 오류 반환: "This model doesn't support thinking"
올바른 방법:
# 이미지 모델을 호출할 때는 사고 파라미터를 전달하지 마세요
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "이 이미지 분석해줘"}],
# ✅ thinking_budget 또는 thinking_level을 전달하지 않음
)
Gemini 2.5 Flash-Lite의 특별한 기본값
Gemini 2.5 Flash-Lite와 표준 Flash 버전의 핵심 차이점은 다음과 같아요:
- 기본적으로 사고 모드가 비활성화됨 (
thinking_budget: 0) - 사고 모드를 활성화하려면
thinking_budget을 0이 아닌 값으로 명시적으로 설정해야 함 - 지원되는 예산 범위: 512~24,576 토큰
# Gemini 2.5 Flash-Lite 사고 모드 활성화
extra_body = {
"thinking_budget": 512 # 0이 아닌 최소값으로 가벼운 사고 활성화
}

| 모델 | thinking_budget | thinking_level | 이미지 지원 | 사고 기본 상태 |
|---|---|---|---|---|
| gemini-2.5-pro | ✅ 지원 (128-32768) | ❌ 미지원 | ❌ | 기본 활성화 (8192) |
| gemini-2.5-flash | ✅ 지원 (0-24576, -1) | ❌ 미지원 | ❌ | 기본 활성화 (동적) |
| gemini-2.5-flash-lite | ✅ 지원 (512-24576) | ❌ 미지원 | ❌ | 기본 비활성화 (0) |
| gemini-2.5-flash-image | ❌ 미지원 | ❌ 미지원 | ✅ | 사고 모드 없음 |
| gemini-3.0-pro | ⚠️ 호환되지만 권장 안 함 | ✅ 권장 (low/high) | ❌ | 기본 high |
| gemini-3.0-flash | ⚠️ 호환되지만 권장 안 함 | ✅ 권장 (minimal/low/medium/high) | ❌ | 기본 high |
🚀 빠른 시작: APIYI 플랫폼을 사용하여 다양한 모델의 사고 파라미터 호환성을 빠르게 테스트해 보세요. 이 플랫폼은 복잡한 설정 없이 바로 사용할 수 있는 Gemini 전체 시리즈 모델 인터페이스를 제공하며, 5분 안에 통합 및 파라미터 검증을 마칠 수 있답니다.
해결책 1: 모델 버전에 따른 매개변수 적응 함수
지능형 매개변수 선택기 (전 시리즈 모델 지원)
def get_gemini_thinking_config(model_name: str, intensity: str = "medium") -> dict:
"""
Gemini 모델 이름에 따라 자동으로 올바른 사고 모드(Thinking Mode) 매개변수를 선택합니다.
Args:
model_name: Gemini 모델 이름
intensity: 사고 강도 ("none", "minimal", "low", "medium", "high", "dynamic")
Returns:
extra_body에 사용할 매개변수 딕셔너리. 모델이 사고 모드를 지원하지 않으면 빈 딕셔너리 반환
"""
# Gemini 3.0 모델 리스트
gemini_3_models = [
"gemini-3.0-flash-preview", "gemini-3.0-pro-preview",
"gemini-3-flash", "gemini-3-pro"
]
# Gemini 2.5 표준 모델 리스트
gemini_2_5_models = [
"gemini-2.5-flash", "gemini-2.5-pro",
"gemini-2.5-flash-lite", "gemini-2-flash", "gemini-2-pro"
]
# 이미지 모델 리스트 (사고 모드 미지원)
image_models = [
"gemini-2.5-flash-image", "gemini-flash-image",
"gemini-pro-vision"
]
# 이미지 모델 여부 확인
if any(img_model in model_name for img_model in image_models):
print(f"⚠️ 경고: {model_name}은(는) 사고 모드 매개변수를 지원하지 않습니다. 빈 구성을 반환합니다.")
return {}
# Gemini 3.0 시리즈는 thinking_level 사용
if any(m in model_name for m in gemini_3_models):
level_map = {
"none": "minimal", # 3.0은 완전히 비활성화할 수 없으므로 minimal 사용
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high"
}
# Gemini 3.0 Pro는 low와 high만 지원
if "pro" in model_name.lower():
if intensity in ["none", "minimal", "low"]:
return {"thinking_level": "low"}
else:
return {"thinking_level": "high"}
# Gemini 3.0 Flash는 4가지 레벨 모두 지원
return {"thinking_level": level_map.get(intensity, "medium")}
# Gemini 2.5 시리즈는 thinking_budget 사용
elif any(m in model_name for m in gemini_2_5_models):
budget_map = {
"none": 0, # 완전히 비활성화
"minimal": 512, # 최소 예산
"low": 2048, # 낮은 강도
"medium": 8192, # 중간 강도
"high": 16384, # 높은 강도
"dynamic": -1 # 동적 적응
}
budget = budget_map.get(intensity, -1)
# Gemini 2.5 Pro는 비활성화 미지원 (최소 128)
if "pro" in model_name.lower() and budget == 0:
print(f"⚠️ 경고: {model_name}은(는) 사고 비활성화를 지원하지 않습니다. 최소값인 128로 자동 조정합니다.")
budget = 128
# Gemini 2.5 Flash-Lite의 최소값은 512
if "lite" in model_name.lower() and budget > 0 and budget < 512:
print(f"⚠️ 경고: {model_name}의 최소 예산은 512입니다. 자동으로 조정합니다.")
budget = 512
return {"thinking_budget": budget}
else:
print(f"⚠️ 경고: 알 수 없는 모델 {model_name}입니다. 기본적으로 Gemini 3.0 매개변수를 사용합니다.")
return {"thinking_level": "medium"}
# 사용 예시
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Gemini 2.5 Flash 테스트
model_2_5 = "gemini-2.5-flash"
config_2_5 = get_gemini_thinking_config(model_2_5, intensity="dynamic")
print(f"{model_2_5} 설정: {config_2_5}")
# 출력: gemini-2.5-flash 설정: {'thinking_budget': -1}
response_2_5 = client.chat.completions.create(
model=model_2_5,
messages=[{"role": "user", "content": "양자 얽힘에 대해 설명해줘"}],
extra_body=config_2_5
)
# Gemini 3.0 Flash 테스트
model_3_0 = "gemini-3.0-flash-preview"
config_3_0 = get_gemini_thinking_config(model_3_0, intensity="medium")
print(f"{model_3_0} 설정: {config_3_0}")
# 출력: gemini-3.0-flash-preview 설정: {'thinking_level': 'medium'}
response_3_0 = client.chat.completions.create(
model=model_3_0,
messages=[{"role": "user", "content": "양자 얽힘에 대해 설명해줘"}],
extra_body=config_3_0
)
# 이미지 모델 테스트
model_image = "gemini-2.5-flash-image"
config_image = get_gemini_thinking_config(model_image, intensity="high")
print(f"{model_image} 설정: {config_image}")
# 출력: ⚠️ 경고: gemini-2.5-flash-image은(는) 사고 모드 매개변수를 지원하지 않습니다. 빈 구성을 반환합니다.
# 출력: gemini-2.5-flash-image 설정: {}
💡 최선의 관행: Gemini 모델을 동적으로 전환해야 하는 상황이라면, APIYI(apiyi.com) 플랫폼을 통해 매개변수 적응 테스트를 진행해 보시는 것을 추천해요. 이 플랫폼은 Gemini 2.5와 3.0 시리즈 모델을 모두 지원하므로, 다양한 매개변수 설정에 따른 응답 품질과 비용 차이를 간편하게 검증할 수 있습니다.
해결책 2: Gemini 2.5에서 3.0으로의 마이그레이션 전략
사고 모드 매개변수 마이그레이션 대조표
| Gemini 2.5 Flash 설정 | Gemini 3.0 Flash 등가 설정 | 지연 시간 비교 | 비용 비교 |
|---|---|---|---|
thinking_budget: 0 |
thinking_level: "minimal" |
3.0이 더 빠름 (약 2배) | 비슷함 |
thinking_budget: 512 |
thinking_level: "low" |
3.0이 더 빠름 | 비슷함 |
thinking_budget: 2048 |
thinking_level: "low" |
3.0이 더 빠름 | 비슷함 |
thinking_budget: 8192 |
thinking_level: "medium" |
3.0이 더 빠름 | 약간 높음 |
thinking_budget: 16384 |
thinking_level: "high" |
3.0이 더 빠름 | 약간 높음 |
thinking_budget: -1 (동적) |
thinking_level: "high" (기본) |
3.0이 눈에 띄게 빠름 | 3.0이 더 높음 |
마이그레이션 코드 예시
def migrate_to_gemini_3(old_model: str, old_config: dict) -> tuple[str, dict]:
"""
Gemini 2.5에서 Gemini 3.0으로 마이그레이션합니다.
Args:
old_model: Gemini 2.5 모델 이름
old_config: Gemini 2.5의 extra_body 설정
Returns:
(새 모델 이름, 새 설정 딕셔너리)
"""
# 모델 이름 매핑
model_map = {
"gemini-2.5-flash": "gemini-3.0-flash-preview",
"gemini-2.5-pro": "gemini-3.0-pro-preview",
"gemini-2-flash": "gemini-3-flash",
"gemini-2-pro": "gemini-3-pro"
}
new_model = model_map.get(old_model, "gemini-3.0-flash-preview")
# 매개변수 변환
if "thinking_budget" in old_config:
budget = old_config["thinking_budget"]
# thinking_level로 변환
if budget == 0:
new_level = "minimal"
elif budget <= 2048:
new_level = "low"
elif budget <= 8192:
new_level = "medium"
else:
new_level = "high"
# Gemini 3.0 Pro는 low/high만 지원
if "pro" in new_model and new_level in ["minimal", "medium"]:
new_level = "low" if new_level == "minimal" else "high"
new_config = {"thinking_level": new_level}
else:
# 기본 설정
new_config = {"thinking_level": "medium"}
return new_model, new_config
# 마이그레이션 예시
old_model = "gemini-2.5-flash"
old_config = {"thinking_budget": -1}
new_model, new_config = migrate_to_gemini_3(old_model, old_config)
print(f"마이그레이션 전: {old_model} {old_config}")
print(f"마이그레이션 후: {new_model} {new_config}")
# 출력:
# 마이그레이션 전: gemini-2.5-flash {'thinking_budget': -1}
# 마이그레이션 후: gemini-3.0-flash-preview {'thinking_level': 'high'}
# 새 설정을 사용하여 호출
response = client.chat.completions.create(
model=new_model,
messages=[{"role": "user", "content": "질문 내용"}],
extra_body=new_config
)
🎯 마이그레이션 제안: Gemini 2.5에서 3.0으로 전환할 때는 먼저 APIYI(apiyi.com) 플랫폼을 통해 A/B 테스트를 진행해 보시는 것이 좋아요. 이 플랫폼은 모델 버전을 빠르게 전환할 수 있어 마이그레이션 전후의 응답 품질, 지연 시간, 비용 차이를 비교하기에 매우 편리하며, 안정적인 전환을 도와줍니다.
자주 묻는 질문
Q1: 제 코드가 Gemini 3.0에서는 잘 작동하는데, 2.5로 바꾸면 왜 에러가 나나요?
원인: 코드에서 thinking_level 파라미터를 사용했기 때문입니다. 이는 Gemini 3.0 전용 파라미터이며, 2.5 시리즈에서는 전혀 지원되지 않습니다.
해결 방법:
# 잘못된 코드 (3.0 전용)
extra_body = {
"thinking_level": "medium" # ❌ 2.5에서는 인식하지 못함
}
# 올바른 코드 (2.5용)
extra_body = {
"thinking_budget": 8192 # ✅ 2.5는 budget을 사용함
}
위에서 언급한 get_gemini_thinking_config() 함수를 사용하여 자동으로 최적화하거나, APIYI(apiyi.com) 플랫폼을 통해 파라미터 호환성을 빠르게 검증해 보시는 것을 추천드려요.
Q2: Gemini 2.5 Flash와 Gemini 3.0 Flash의 성능 차이는 어느 정도인가요?
Google 공식 데이터와 커뮤니티 테스트 결과는 다음과 같습니다:
| 항목 | Gemini 2.5 Flash | Gemini 3.0 Flash | 향상 폭 |
|---|---|---|---|
| 추론 속도 | 기준 | 2배 더 빠름 | +100% |
| 지연 시간 | 기준 | 현저히 감소 | 약 -50% |
| 사고 효율 | 고정 예산 또는 동적 | 자동 최적화 | 품질 향상 |
| 비용 | 기준 | 약간 높음 (고품질) | +10-20% |
핵심 차이점: Gemini 3.0은 동적 사고 할당 방식을 채택하여 필요한 경우에만 필요한 만큼 사고하는 반면, 2.5의 고정 예산 방식은 과도하게 사고하거나 사고가 부족해질 수 있는 가능성이 있습니다.
실시간 성능 모니터링과 비용 분석을 제공하는 APIYI(apiyi.com) 플랫폼에서 실제 테스트를 진행해 보세요. 모델별 실제 성능을 간편하게 비교할 수 있습니다.
Q3: Gemini 3.0에서 사고 모드를 완전히 끌 수 있나요?
중요: Gemini 3.0 Pro는 사고 모드를 완전히 비활성화할 수 없습니다. thinking_level: "low"로 설정하더라도 가벼운 추론 능력은 유지됩니다.
사용 가능한 옵션:
- Gemini 3.0 Flash:
thinking_level: "minimal"을 사용하면 제로(0) 사고에 가깝게 작동합니다. (단, 복잡한 코딩 작업 시에는 여전히 가벼운 사고를 할 수 있습니다.) - Gemini 3.0 Pro: 최하
thinking_level: "low"까지만 설정 가능합니다.
완전한 비활성화가 필요한 경우:
# Gemini 2.5 Flash만 완전 비활성화를 지원함
model = "gemini-2.5-flash"
extra_body = {
"thinking_budget": 0 # 사고 모드 완전 비활성화
}
극강의 속도가 필요하고 추론 능력이 필요 없는 상황(단순 지시 수행 등)이라면, APIYI(apiyi.com)를 통해 Gemini 2.5 Flash를 호출하고
thinking_budget: 0으로 설정하는 방법을 추천드려요.
Q4: Gemini 이미지 모델도 사고 모드를 지원하나요?
지원하지 않습니다. 모든 Gemini 이미지 처리 모델(gemini-2.5-flash-image, gemini-pro-vision 등)은 사고 모드 파라미터를 지원하지 않습니다.
잘못된 예시:
# ❌ 이미지 모델은 어떤 사고 파라미터도 지원하지 않음
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
extra_body={
"thinking_budget": -1 # 에러 유발
}
)
올바른 방법:
# ✅ 이미지 모델 호출 시에는 사고 파라미터를 전달하지 않음
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
# extra_body를 아예 보내지 않거나 다른 비사고 파라미터만 전달
)
기술적 이유: 이미지 모델의 추론 아키텍처는 시각적 이해에 집중되어 있어, 언어 모델의 사고 사슬(Chain of Thought) 메커니즘을 포함하고 있지 않기 때문입니다.
요약
Gemini 2.5 Flash에서 thinking_level not supported 에러가 발생하는 핵심 요약:
- 파라미터 격리: Gemini 2.5는
thinking_budget만, 3.0은thinking_level만 지원하며 서로 호환되지 않습니다. - 모델 식별: 모델 이름으로 버전을 판단하세요. 2.5 시리즈는
thinking_budget을, 3.0 시리즈는thinking_level을 사용합니다. - 이미지 모델 제한: 모든 이미지 모델(예:
gemini-2.5-flash-image)은 어떠한 사고 모드 파라미터도 지원하지 않습니다. - 비활성화 차이: 오직 Gemini 2.5 Flash만 사고 모드 완전 비활성화(
thinking_budget: 0)가 가능하며, 3.0 시리즈는minimal이 최하 단계입니다. - 마이그레이션 전략: 2.5에서 3.0으로 전환할 때는
thinking_budget을thinking_level로 매핑하고, 성능과 비용 변화를 고려해야 합니다.
다양한 모델의 사고 파라미터 호환성과 실제 효과를 APIYI(apiyi.com)에서 빠르게 확인해 보세요. Gemini 전 시리즈 모델을 지원하며, 통합 인터페이스와 유연한 과금 방식을 통해 빠른 비교 테스트와 운영 환경 배포에 최적화되어 있습니다.
작성자: APIYI 기술 팀 | 기술적인 문의가 있으시면 APIYI(apiyi.com)를 방문하여 더 많은 대규모 언어 모델 연동 솔루션을 확인해 보세요.