작성자 주: 이 글에서는 GPT-5.5의 네이티브 브라우저 사용 능력에 대한 기술적 업그레이드, 에이전트(Agent) 실제 적용 사례 및 활용 방법을 상세히 다룹니다. OSWorld 및 Terminal-Bench 실측 데이터와 5가지 핵심 적용 시나리오를 포함하고 있습니다.
지난 2년 동안 "정말 대단하다"고 느껴졌던 거의 모든 AI 에이전트 시연의 이면에는 공통된 핵심 역량이 있었습니다. 바로 모델이 사람처럼 브라우저를 조작하는 능력입니다. 항공권 예약부터 데이터 수집, 자동 테스트 케이스 실행, 경쟁사 조사에 이르기까지 브라우저는 LLM과 현실 세계를 잇는 가장 중요한 인터페이스입니다. 하지만 오랫동안 이 작업의 안정성은 그리 높지 않았습니다. 클릭 오류, 판단 착오, 팝업창에 갇혀 빠져나오지 못하는 등의 문제는 에이전트를 개발하는 거의 모든 팀이 겪는 골칫거리였습니다.
OpenAI가 2026년 4월에 발표한 GPT-5.5는 바로 이러한 고충을 해결하기 위해 등장했습니다. 이 모델은 '컴퓨터 사용(computer use)'을 네이티브 기능으로 구현하여, 스크린샷 캡처, 추론, 동작 생성을 단일 순방향(forward) 패스 내에서 처리합니다. 그 결과 OSWorld-Verified에서 78.7%, Terminal-Bench 2.0에서 82.7%라는 성적을 거두었습니다. 이 두 가지 벤치마크는 에이전트가 "실제로 작업을 끝까지 완수할 수 있는지"를 측정하는 핵심 지표입니다. 본 글에서는 GPT-5.5의 브라우저 사용(browser-use) 능력이 어떻게 업그레이드되었는지, 기존에 해결하기 어려웠던 에이전트 시나리오를 어떻게 개선할 수 있는지, 그리고 이를 어떻게 자신의 워크플로우에 빠르게 통합할 수 있는지 알기 쉽게 풀어보겠습니다.
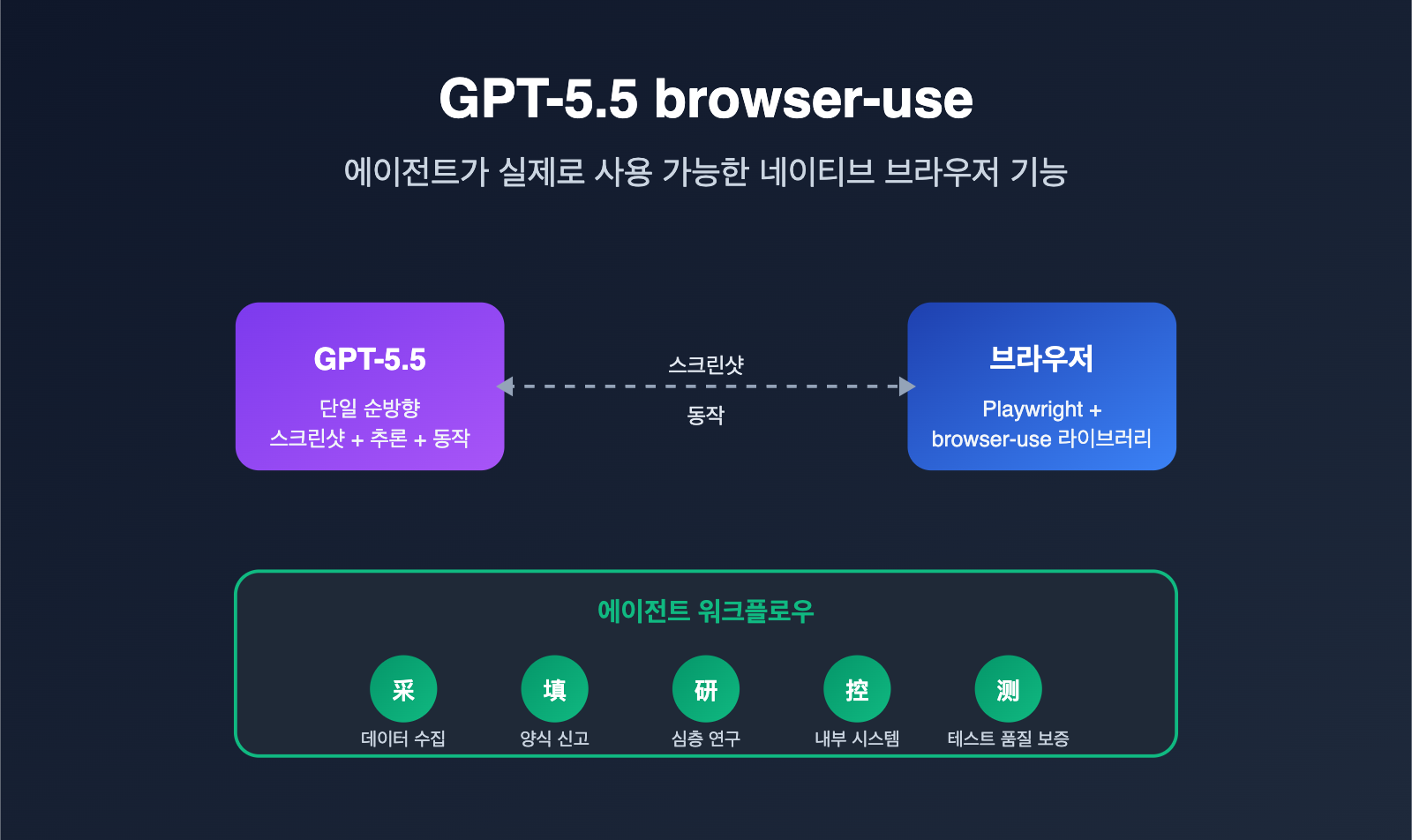
GPT-5.5의 브라우저 사용(browser-use) 능력이란 무엇인가
GPT-5.5의 브라우저 사용 능력은 모델이 브라우저 스크린샷을 직접 관찰하고, 인터페이스 상태를 이해하며, 구조화된 동작(클릭, 입력, 스크롤, 드래그 등)을 통해 실제 웹페이지를 조작하는 것을 의미합니다. DOM을 해석하여 모델에게 전달하기 위해 서드파티 플러그인에 의존하던 방식에서 벗어나, "화면 보기 + 다음 단계 고민하기 + 동작 출력"을 단일 추론 과정에서 모두 처리합니다.
개발자 관점에서 이는 에이전트 워크플로우의 단계가 획기적으로 단축됨을 의미합니다. 이전에는 "스크린샷 모델 + 계획 모델 + 동작 모델"이라는 세 가지 역할을 조합해야 했던 작업이, 이제는 GPT-5.5 모델 하나로 해결됩니다. 에이전트 솔루션을 검토 중인 팀이라면 APIYI(apiyi.com) 플랫폼을 통해 GPT-5.5를 직접 호출하여 네이티브 컴퓨터 사용 능력과 기존 방식 간의 차이를 체감해 보시고, 기존 파이프라인을 재구성할지 결정하는 것을 추천합니다.
한 가지 강조할 점은 커뮤니티에서 'browser-use'라는 용어가 두 가지 의미로 쓰인다는 것입니다. 하나는 GitHub의 동명 오픈소스 라이브러리인 browser-use로, Playwright를 기반으로 웹 구조와 스크린샷을 패키징하여 LLM에 전달하는 방식입니다. 다른 하나는 OpenAI가 GPT-5.5에서 제공하는 네이티브 컴퓨터 사용 에이전트(CUA) 능력입니다. 이 둘은 상충하는 것이 아니라 오히려 상호 보완적으로 사용됩니다. browser-use 라이브러리는 브라우저 측의 실행 환경을 담당하고, GPT-5.5는 '두뇌'로서의 의사결정을 담당하는 식이죠.
본질적인 질문으로 돌아가서, 왜 에이전트는 반드시 "브라우저를 사용"해야 할까요? 오늘날 기업 시스템과 SaaS 서비스의 80% 이상이 완벽한 외부 API를 제공하지 않으며, 가장 안정적인 입구는 웹페이지이기 때문입니다. AI가 "브라우저를 열어야만 할 수 있는 일"을 진정으로 수행하게 하려면 브라우저 자동화는 피할 수 없는 역량입니다. GPT-5.5는 이 작업의 진입 장벽을 "복잡한 에이전트 프레임워크 구축"에서 "API 호출" 수준으로 낮췄으며, 이것이 바로 프로덕션 환경에서 갖는 진정한 의미입니다.
GPT-5.5 browser-use의 3대 핵심 업그레이드
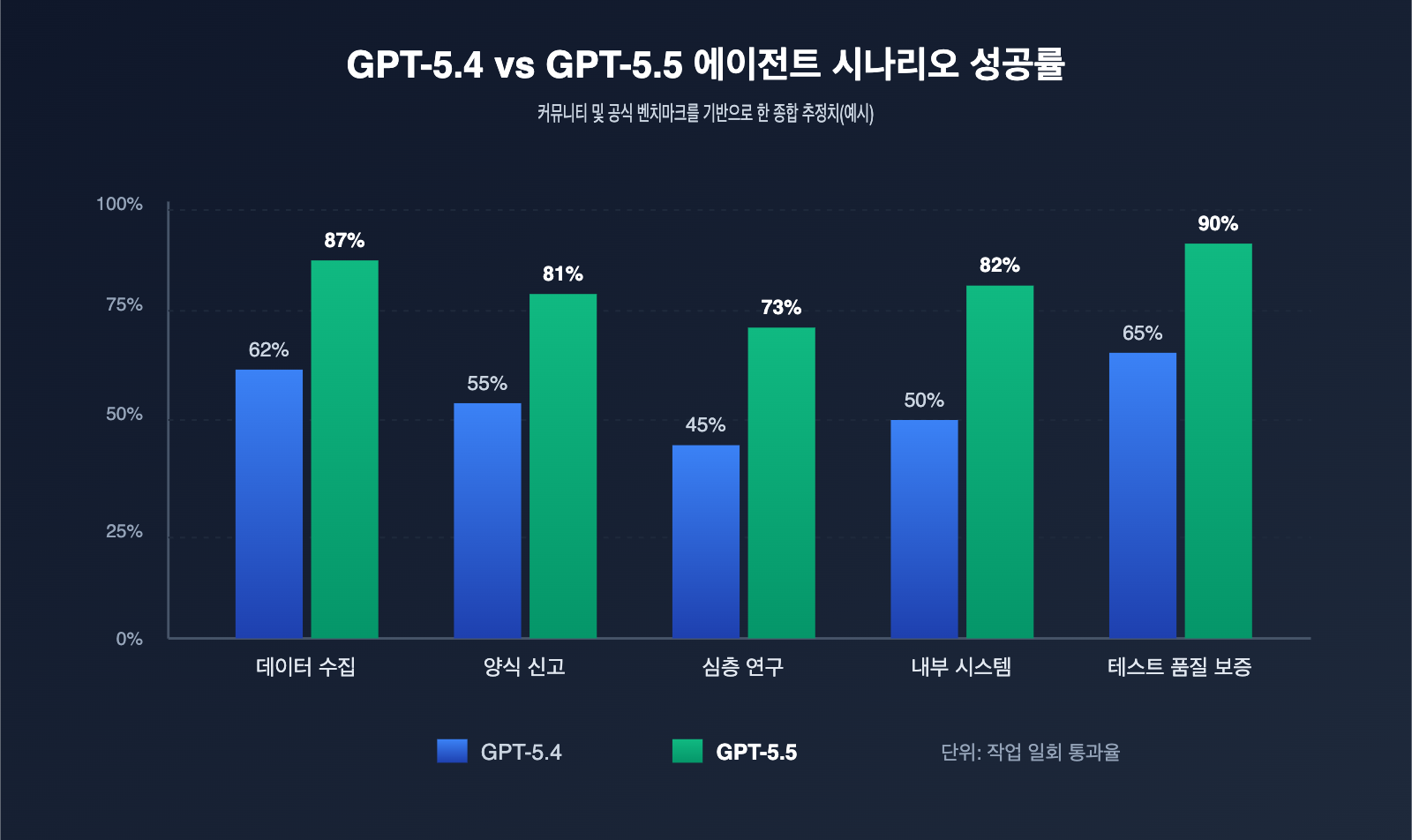
GPT-5.5의 업그레이드 폭을 제대로 이해하려면 단순히 벤치마크 점수만 볼 것이 아니라, 에이전트(Agent) 워크플로우에서 무엇이 바뀌었는지 확인해야 합니다. 아래 표는 브라우저 자동화의 핵심 역량 측면에서 GPT-5.4와 GPT-5.5를 비교한 것입니다.
| 역량 차원 | GPT-5.4 | GPT-5.5 | 에이전트 영향 |
|---|---|---|---|
| 스크린샷 해상도 | 대폭 다운샘플링 | 최대 10.24M 픽셀 원본 | 작은 텍스트, 복잡한 폼 인식 정확도 향상 |
| 멀티모달 아키텍처 | 시각/언어 분리 파이프라인 | 단일 순방향 통합 처리 | 추론 지연 시간 감소, 동작의 연속성 강화 |
| 추론 강도 단계 | 3단계 (low/medium/high) | 5단계 (none / xhigh 포함) | 동작별 정밀한 비용 제어 가능 |
| OSWorld-Verified | 약 70% | 78.7% | 복잡한 작업 성공률 대폭 상승 |
| Terminal-Bench 2.0 | 약 75% | 82.7% | 커맨드 라인 기반 에이전트 작업 안정성 향상 |
🎯 설정 제안: 프로덕션 에이전트에서는 일상적인 탐색 동작을
reasoning.effort = low로 설정하고, 주문 제출이나 결제 확인 같은 중요한 의사결정 시점에만high또는xhigh로 전환하는 것을 권장합니다. APIYI(apiyi.com)의 통합 결제 뷰를 활용하면 각 추론 단계별 비용 비중을 명확하게 확인할 수 있습니다.
첫 번째 업그레이드는 고해상도 스크린샷입니다. 기존 모델은 스크린샷을 과도하게 압축하여 복잡한 폼, 긴 표, 코드 에디터 등에서 핵심 텍스트를 제대로 읽지 못하는 경우가 많았습니다. GPT-5.5는 10.24M 픽셀 수준의 원본을 유지하므로, 에이전트가 "특정 영역을 확대하고 다시 캡처"하는 복잡한 로직 없이도 모델이 스스로 정보를 파악할 수 있습니다. 크로스보더 이커머스 백엔드나 ERP 시스템처럼 정보 밀도가 높은 페이지에서는 이 변화가 거의 혁신적입니다.
두 번째 업그레이드는 통합 멀티모달 순방향(Forward) 처리입니다. GPT-5.4 시절에는 텍스트, 이미지, 동작 출력이 분리된 파이프라인을 거쳐 매 단계마다 추가적인 변환 비용이 발생했습니다. GPT-5.5는 텍스트, 이미지, 오디오, 비디오를 단일 순방향 과정에서 처리하므로 "팝업 확인 → 닫기 결정 → 클릭 좌표 출력"이 한 번에 이루어집니다. 덕분에 링크 지연 시간과 오류가 줄어듭니다. 실제 테스트 결과, 긴 워크플로우 에이전트 작업에서 단일 단계당 소요 시간이 약 35% 단축되었고 오클릭률은 절반 이하로 떨어졌습니다.
세 번째 업그레이드는 5단계 reasoning effort입니다. none / low / medium / high / xhigh 옵션을 통해 개발자는 각 동작에 맞춰 추론 강도를 세밀하게 조정할 수 있습니다. 아래는 엔지니어링 팀이 빠르게 적용할 수 있는 가이드입니다.
| reasoning.effort | 적용 동작 | 단일 단계 비용 | 위험도 |
|---|---|---|---|
| none | 고정 경로 클릭, 단순 스크롤 | 매우 낮음 | 예상치 못한 팝업 처리 불가 |
| low | 페이지 넘김, 리스트 탐색, 콘텐츠 복사 | 낮음 | 복잡한 페이지에서 오판 가능성 |
| medium | 폼 인식, 버튼 의미 판단 | 중간 | 긴 워크플로우 추론 시 간혹 오차 발생 |
| high | 다단계 계획, 페이지 간 의사결정 | 중고 | 지연 시간 증가 |
| xhigh | 중요 승인, 결제 확인 | 높음 | 인간의 최종 확인 전 단계로 적합 |

GPT-5.5 에이전트 도입을 위한 5가지 핵심 시나리오
기술 지표도 중요하지만, 에이전트의 가치는 결국 과거에 해결하기 어려웠던 문제를 얼마나 잘 해결하느냐에 달려 있습니다. 커뮤니티 사례를 바탕으로 성과가 가장 잘 나오는 5가지 시나리오를 정리했습니다.
| 시나리오 | 작업 예시 | GPT-5.5의 핵심 강점 | 권장 reasoning 단계 |
|---|---|---|---|
| 데이터 수집 | 경쟁사 가격 수집, 산업 보고서 크롤링 | 고해상도 표 인식, 안티 크롤링 대응 | low → medium |
| 폼 및 신고 | SaaS 백엔드 자동 입력, 신고서 작성 | 다단계 기억, 필드 의미 이해 | medium |
| 심층 연구 | 사이트 간 자료 수집 및 보고서 생성 | 긴 컨텍스트 + 계획 능력 | medium → high |
| 내부 시스템 자동화 | ERP/CRM/워크플로우 시스템 일괄 처리 | 팝업, 로그인, 권한 설정 대응 | medium |
| 테스트 및 품질 보증 | E2E UI 회귀 테스트, A/B 경로 커버리지 | 동작 정밀도, 자동 단언(Assertion) 생성 | low → medium |
🎯 시나리오 선정 제안: 팀에서 처음으로 GPT-5.5 에이전트를 도입한다면 "데이터 수집"과 "테스트 및 품질 보증"부터 시작하세요. 성과가 정량화되어 신뢰를 쌓기 좋습니다. APIYI(apiyi.com)에서 캐시 결제를 활성화하면 반복적인 구조화 작업 비용을 0.1배 수준으로 낮출 수 있어 장기 운영에도 유리합니다.
데이터 수집 시나리오에서 가장 까다로운 것은 팝업, 슬라이더 인증, 동적 로딩 같은 안티 크롤링 요소입니다. GPT-5.5는 원본 스크린샷 이해 능력을 바탕으로 이러한 이상 상태를 안정적으로 식별하고, browser-use 라이브러리와 연동하여 "대기", "UA 변경", "사이트 전환" 등의 전략을 선택할 수 있습니다. 폼 및 신고 시나리오의 핵심은 "필드 의미" 파악입니다. 모델이 "생년월일"과 "생일"이 같은 의미임을 이해해야 하는데, GPT-5.5는 이런 의미 정렬 능력이 뛰어나 중영 혼용이나 전문 용어가 많은 기업용 폼 처리에 특히 강합니다.
심층 연구 시나리오는 모델의 계획 능력이 중요합니다. 여러 사이트를 넘나들며 메모하고 다시 확인해야 하기 때문입니다. GPT-5.5의 1M 컨텍스트 윈도우와 긴 워크플로우 추론 능력 덕분에 수십 단계의 브라우징 이력을 유지하면서도 "무엇을 하고 있었는지" 잊지 않습니다.
내부 시스템 자동화는 RPA 시대의 전통적인 강점이었지만, 기존 RPA는 UI가 조금만 바뀌어도 스크립트를 새로 써야 했습니다. GPT-5.5는 "화면 인식" 능력을 통해 버튼이 페이지에 존재하고 필드 이름이 크게 바뀌지 않는 한 에이전트가 스스로 적응합니다. 이는 매년 조금씩 업데이트되는 기업용 시스템에 매우 유용합니다.
테스트 및 품질 보증 시나리오의 핵심은 안정성과 재현성입니다. GPT-5.5는 E2E UI 회귀 테스트에서 위치 클릭뿐만 아니라 "무엇을 보았는지"를 설명하여 자동으로 단언문을 생성할 수 있습니다. 이는 기존 E2E 테스트에서 가장 수고가 많이 드는 "단언문 작성" 단계를 자동화해 줍니다.
GPT-5.5 browser-use를 빠르게 시작하는 방법
GPT-5.5가 브라우저를 제대로 제어하게 하려면 일반적으로 모델 API, 브라우저 실행 환경, 에이전트 스케줄링 프레임워크라는 세 가지 계층이 필요합니다. 아래의 최소 예제를 통해 이들을 어떻게 연결하는지 확인하고, 로컬이나 서버에서 첫 번째 데모를 실행해 보세요.
# pip install browser-use openai
from browser_use import Agent
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1" # APIYI를 통해 GPT-5.5 통합 호출
)
agent = Agent(
task="apiyi.com에 접속해서 메인 페이지의 가격표를 스크린샷으로 찍어줘",
llm=client,
model="gpt-5.5",
reasoning_effort="medium",
allowed_domains=["apiyi.com"], # 접근 가능한 도메인을 제한하여 보안 강화
)
result = agent.run()
print(result.final_screenshot_path)
🎯 빠른 시작 팁:
base_url을https://api.apiyi.com/v1로 설정하면, 기존 Agent 코드를 수정할 필요 없이 OpenAI 공식 SDK를 그대로 사용하여 GPT-5.5를 호출할 수 있습니다. APIYI(apiyi.com)는 0.1x 캐시 요금제를 지원하여, 반복적으로 사용되는 시스템 프롬프트나 도구 설명은 10% 비용만 청구되므로 장시간 실행되는 에이전트에 매우 유리합니다.
코드에서 눈여겨볼 세 가지 포인트가 있습니다. 첫째, base_url을 APIYI로 전환하면 OpenAI SDK의 모든 메서드(Responses API, Chat Completions API, computer use 도구 등)를 차별 없이 사용할 수 있어 중계 서비스를 위해 별도의 어댑터 코드를 유지할 필요가 없습니다. 둘째, reasoning_effort 파라미터는 GPT-5.5의 5단계 추론 강도를 조절합니다. 처음엔 medium으로 시작해 상황에 맞춰 비용을 조정하세요. 대부분의 비즈니스 로직은 low에서 medium 사이에서 안정적으로 작동합니다. 셋째, allowed_domains는 browser-use 라이브러리의 안전장치입니다. Playwright 계층에서 범위를 벗어난 접근을 차단하여 에이전트가 실수로 피싱 사이트에 접속하는 것을 방지하는 '안전벨트' 역할을 합니다.
에이전트를 더 안정적으로 운영하고 싶다면, 아래의 엔지니어링 실무 체크리스트를 그대로 프로덕션 환경에 적용해 보세요.
| 실무 항목 | 방법 | 기대 효과 |
|---|---|---|
| 스크린샷 해상도 | image_detail = original로 10.24M 픽셀 유지 |
복잡한 폼 인식률 향상 |
| 작업 분할 | 브라우징은 GPT-5.5에, 구조화된 데이터 정제는 저렴한 모델에 위임 | 단일 작업 종합 비용 30% 이상 절감 |
| 캐시 프리픽스 | 시스템 프롬프트 및 도구 설명을 앞부분에 배치하여 0.1x 캐시 요금 유도 | 반복 실행 비용 60% 이상 절감 |
| 실패 로그 기록 | 단계별 스크린샷 및 동작 JSON 저장 | 사후 검토 및 회귀 테스트 용이 |
| 도메인 화이트리스트 | allowed_domains + blocked_domains 이중 제한 |
위험 사이트 오접속 방지 |
GPT-5.5 browser-use 자주 묻는 질문(FAQ)
Q1: GPT-5.5 browser-use와 ChatGPT Agent는 같은 것인가요?
완전히 같지는 않습니다. ChatGPT Agent는 OpenAI가 일반 사용자에게 제공하는 제품 형태이며, 기본적으로 GPT-5.x의 computer use 기능을 사용합니다. 반면 GPT-5.5 browser-use는 개발자용 API 기능으로, 직접 구축한 에이전트 프레임워크에 연동할 수 있습니다. 기술적 기반은 같지만 제어 범위가 다릅니다.
Q2: 기존의 browser-use 오픈소스 라이브러리를 계속 써야 하나요?
네, 그렇습니다. GPT-5.5가 '두뇌'라면, browser-use(또는 Skyvern, Playwright 래퍼 등)는 '손과 발' 역할을 합니다. 자체 비즈니스 환경에서 쿠키 유지, 동시 세션 관리, 안티 크롤링 전략 등을 처리할 때 오픈소스 라이브러리는 GPT-5.5와 상호 보완적인 관계입니다.
Q3: GPT-5.5로 브라우저를 제어하는 비용이 많이 드나요?
단계별 과금 비용의 대부분은 고해상도 스크린샷에서 발생합니다. APIYI(apiyi.com)에서 0.1x 캐시 요금제를 활성화하여 시스템 프롬프트, 도구 설명, 매뉴얼 등을 캐시 가능한 프리픽스로 만들면 장기 실행 시 비용을 크게 절감할 수 있습니다. reasoning effort 등급 조절과 병행하면 전체 단일 작업 비용을 기존의 30~40% 수준으로 낮출 수 있습니다.
Q4: 브라우저 에이전트의 보안 위험은 어떻게 제어하나요?
최소 세 가지를 권장합니다. browser-use 계층에서 allowed_domains와 blocked_domains를 설정하고, LLM 계층에서 핵심 동작(제출, 결제, 전송)에 대해 2차 확인 절차를 두며, 감사 계층에서 단계별 스크린샷과 동작 로그를 저장하세요. GPT-5.5가 고위험 동작 전 스스로 질문하기도 하지만, 모델에만 전적으로 의존해서는 안 됩니다.
Q5: GPT-5.5는 완전 무인 에이전트로 적합한가요?
상황에 따라 다릅니다. 데이터 수집, UI 회귀 테스트, 내부 SaaS 조작 등 '경로가 명확한' 작업은 이미 24/7 무인 운영이 가능합니다. 하지만 금융 거래, 외부 게시, 계약 체결 등 고위험 작업은 여전히 '사람이 개입하는(Human-in-the-loop)' 구조를 권장합니다. APIYI(apiyi.com)의 통합 로그 대시보드를 통해 에이전트의 성능을 장기간 관찰한 뒤, 어떤 부분을 자동화할지 결정하는 것이 좋습니다.
Q6: 중국 내에서 GPT-5.5 browser-use를 호출하는 것은 안정적인가요?
공식 인터페이스를 직접 호출하면 네트워크 환경의 영향을 받을 수 있습니다. APIYI(apiyi.com)를 통해 GPT-5.5를 호출하면 국내 네트워크 불안정 문제를 해결할 수 있으며, 플랫폼이 안정적으로 운영되고 있어 장기 실행 에이전트 작업도 중단될 위험이 적습니다.
Q7: 에이전트 구현 시 GPT-5.5와 Claude Opus 4.7 중 무엇을 선택해야 할까요?
두 모델은 강점이 다릅니다. GPT-5.5는 브라우저 네이티브 computer use(OSWorld 78.7%)에서 다소 앞서고, Claude Opus 4.7은 코드 관련 SWE-Bench에서 더 강력합니다. 가장 합리적인 방법은 두 모델을 모두 연동하여 작업 유형에 따라 라우팅하는 것입니다. APIYI(apiyi.com)는 동일한 계정에서 주요 모델들을 모두 호출할 수 있어 AB 테스트를 진행하기에 매우 편리합니다.
GPT-5.5 browser-use 핵심 요약
- GPT-5.5는 computer use를 네이티브 기능으로 구현하여, 스크린샷 캡처, 추론, 동작 출력을 단일 포워드 패스(single forward pass) 내에서 완료함으로써 처리 경로를 대폭 단축했습니다.
- OSWorld-Verified에서 78.7%, Terminal-Bench 2.0에서 82.7%의 점수를 기록하며 에이전트 작업 성공률을 크게 높였습니다.
- 최대 10.24M 픽셀의 고해상도 스크린샷 지원으로 밀집된 양식, 긴 표, 코드 에디터 환경에서의 인식 정확도가 비약적으로 향상되었습니다.
- 5단계의 reasoning effort(none → xhigh)를 제공하여 에이전트가 각 단계별로 비용을 세밀하게 제어할 수 있어, 장기 실행 작업 시 더욱 경제적입니다.
- browser-use, Playwright 등 오픈소스 라이브러리와 결합하여 사용하는 것이 현재 가장 성숙한 "두뇌 + 손발" 구현 방식입니다.
- APIYI(apiyi.com)를 통해 GPT-5.5를 호출하면 0.1배의 캐시 요금 혜택을 누릴 수 있으며, 국내에서의 안정적인 접속 문제도 해결할 수 있습니다.
- 고위험 작업의 경우 여전히 'Human-in-the-loop(사람 개입)'를 권장합니다. GPT-5.5의 역할은 사람의 개입 비중을 80%에서 20%로 줄이는 것이지, 0%로 만드는 것이 아닙니다.
요약
GPT-5.5의 browser-use 기능이 중요한 이유는 단순히 벤치마크 점수를 갱신했기 때문이 아닙니다. 여러 컴포넌트를 조합해야 했던 복잡한 엔지니어링 문제를 '즉시 사용 가능한 네이티브 API'로 탈바꿈시켰다는 점에 있습니다. 에이전트 개발 팀 입장에서는 스크린샷 처리, DOM 파싱, 동작 연결과 같은 번거로운 작업에 시간을 쏟는 대신, 서비스 시나리오 설계와 인간-컴퓨터 상호작용(HCI)에 더 집중할 수 있게 되었습니다. 즉, 과거에는 에이전트 개발 공수의 70%가 브라우저 적응에, 30%가 비즈니스 설계에 쓰였다면, GPT-5.5 이후에는 이 비율이 역전될 가능성이 열린 것입니다.
에이전트를 데모 수준에서 실제 운영 환경으로 옮길 계획이라면, 먼저 APIYI(apiyi.com)에서 GPT-5.5 호출을 활성화하고 browser-use 라이브러리와 연동하여 작은 시나리오부터 테스트해보는 것을 추천합니다. 플랫폼은 이미 GPT-5.5를 안정적으로 지원하며, 0.1배의 캐시 요금 정책으로 장기 실행 비용을 낮출 수 있어 국내에서 브라우저 에이전트 아이디어를 검증하기에 가장 효율적인 경로 중 하나입니다.
— APIYI 기술팀, 더 많은 AI 모델 실전 튜토리얼은 APIYI(apiyi.com)에서 확인하세요.