gpt-image-2를 호출하다 보면 아래와 같은 에러를 마주할 때가 있습니다. 이는 2026년 4월 gpt-image-2 출시 이후 개발자 커뮤니티에서 가장 빈번하게 발생하는 에러 중 하나입니다.
{
"status_code": 400,
"error": {
"message": "Your request was rejected by the safety system. ... safety_violations=[violence].",
"type": "shell_api_error",
"code": "moderation_blocked"
}
}
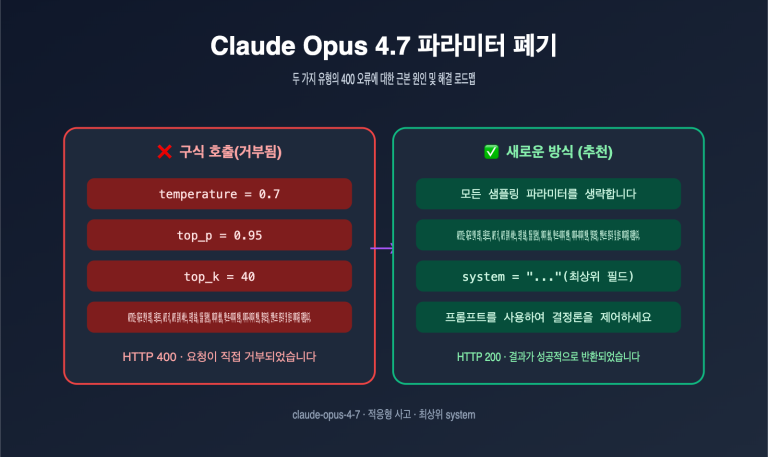
많은 분이 첫 반응으로 "재시도(retry)를 추가하면 되겠지"라고 생각합니다. 하지만 이는 잘못된 대응입니다. 같은 프롬프트를 100번 재시도해도 여전히 차단됩니다. gpt-image-2의 moderation_blocked 에러는 요청이 모델에 도달조차 하지 못하고, 전단 안전 분류기에 의해 능동적으로 거부된 것이기 때문에 재시도는 그저 시간 낭비일 뿐입니다.
이 글에서는 실제 에러 사례를 바탕으로 gpt-image-2의 안전 심사 메커니즘(2단계 필터링 아키텍처 포함), 7가지 주요 트리거 시나리오, 5가지 프롬프트 최적화 전략, 그리고 에러율을 낮추기 위한 엔지니어링 실무를 체계적으로 분석합니다. 이 글을 읽고 나면 즉시 자신의 프롬프트 템플릿을 검토하여 위반율을 80% 이상 낮출 수 있을 것입니다.

gpt-image-2의 moderation_blocked 에러 본질 파악하기
이 에러를 해결하려면 먼저 이것이 정확히 무엇인지 이해해야 합니다. 많은 개발자가 이를 "모델이 답변을 거부한 것"으로 생각하지만, 사실은 전혀 그렇지 않습니다.
gpt-image-2의 moderation_blocked 에러 핵심 사실
| 사실 | 설명 | 엔지니어링 의미 |
|---|---|---|
| HTTP 400 (클라이언트 측) | 요청 단계 에러, 서버 장애 아님 | 재시도 무의미, 프롬프트 수정 필수 |
| 모델 미도달 | 전단 분류기에 의해 차단됨 | 비용 미발생, 토큰 미소모 |
code=moderation_blocked |
표준화된 에러 코드, 프로그래밍 식별 가능 | 자동 재작성 파이프라인 구축에 적합 |
safety_violations=[…] |
위반 카테고리 목록 | 수정이 필요한 부분 정밀 타겟팅 |
| 동일 프롬프트 100% 재현 | 결정론적 결과, 확률적 이벤트 아님 | 프롬프트를 수정해야만 복구 가능 |
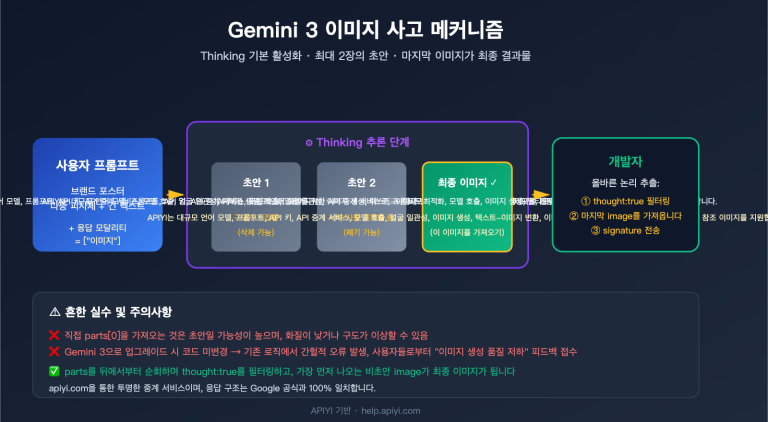
gpt-image-2 에러의 2단계 안전 심사 메커니즘
gpt-image-2 에러를 이해하려면 OpenAI의 2단계 안전 필터링 아키텍처를 먼저 살펴봐야 합니다.
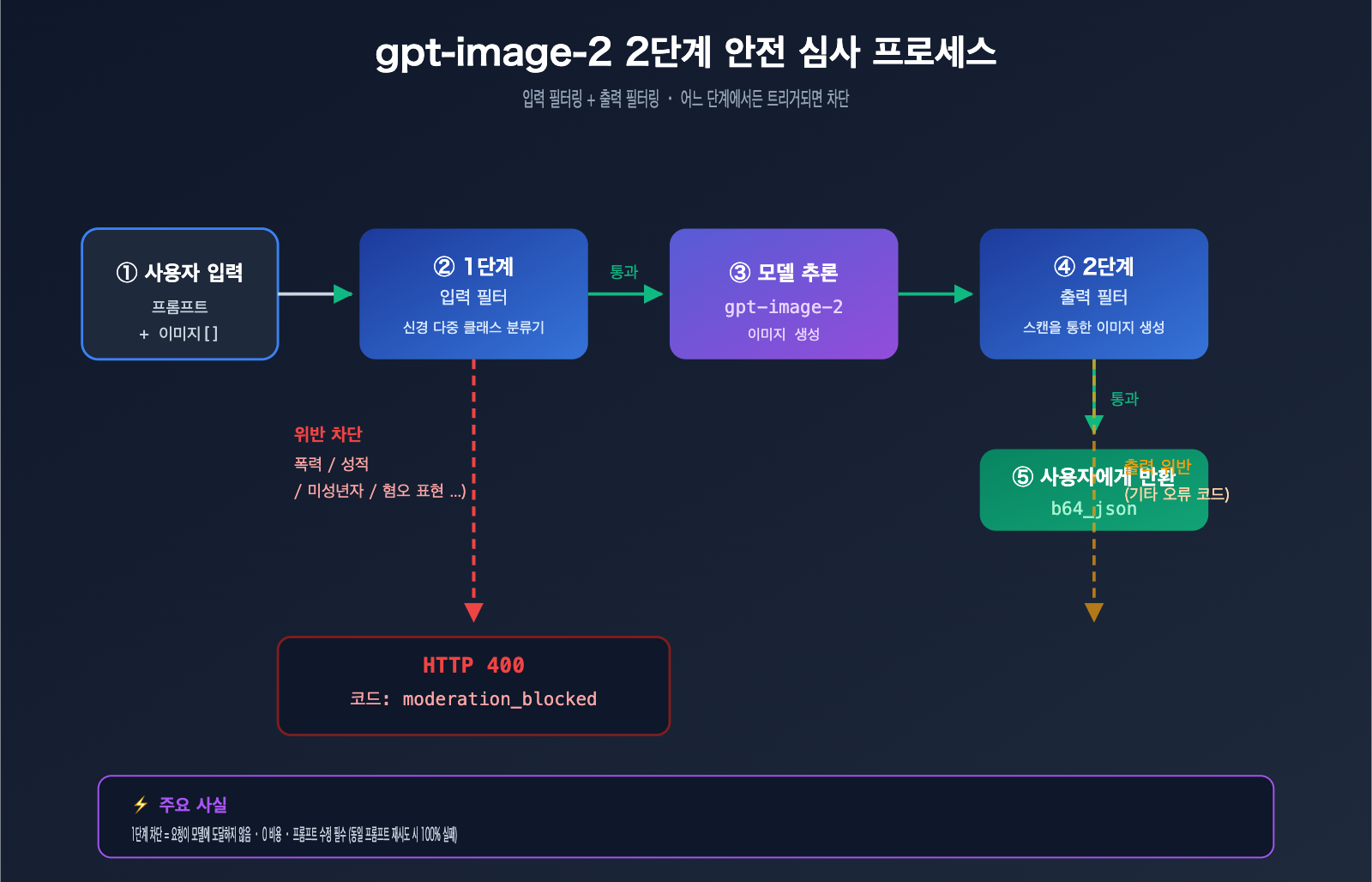
전체 안전 경로에는 실제로 두 개의 관문이 있습니다.
Stage 1 · 입력 필터 (Input Filter):
- 프롬프트 텍스트 스캔
- 업로드된 모든 참조 이미지 스캔 (
/v1/images/edits호출 시) - 신경 다중 분류기(multi-class neural classifier) 사용
- 여기가 바로
moderation_blocked가 트리거되는 지점입니다.
Stage 2 · 출력 필터 (Output Filter):
- 모델이 이미 생성한 이미지 스캔
- 생성된 콘텐츠가 규정을 위반하면 차단될 수 있음
- 일반적으로 다른 에러 코드를 반환함 (
moderation_blocked가 아님)
사용자가 제공한 사례는 Stage 1 입력 필터링을 트리거한 것이므로 모델 추론 단계로 진입조차 하지 않은 것입니다. 이것이 바로 이러한 에러 응답이 매우 빠른(보통 1초 미만) 이유입니다. 대기열에 들어가지도, GPU를 점유하지도 않았기 때문이죠.
gpt-image-2 에러의 백엔드 차이
간과하기 쉬운 사실 하나: 백엔드 채널마다 심사 엄격도가 다릅니다. OpenAI 직연동 vs Azure OpenAI는 동일한 프롬프트에서도 트리거율에 상당한 차이가 있으며, Azure가 일반적으로 더 엄격합니다. 사용자의 에러 메시지에 "Azure 지원 티켓으로 문의하라"는 내용이 포함된 이유입니다. 이 요청은 실제로 Azure 백엔드 필터로 라우팅되었습니다.
🎯 채널 선택 제언: 동일한 프롬프트로 여러 채널을 테스트할 때, 일부 채널에서는 차단되고 일부는 통과되는 것은 정상입니다. APIYI(apiyi.com)의 OpenAI 공식 전환 채널을 통해 검증하는 것을 권장합니다. 이 채널은 OpenAI의 공식 필터링 정책을 따르므로 트리거율이 OpenAI 직연동과 동일하여 베이스라인 비교에 용이합니다.
gpt-image-2 오류 발생 7대 트리거 시나리오 총정리
OpenAI는 공개된 ChatGPT Images 2.0 시스템 카드에서 7가지 고빈도 트리거 시나리오를 명확히 제시했습니다. 이 7가지 시나리오를 이해하는 것이 규정을 준수하는 프롬프트를 작성하는 첫걸음입니다.

gpt-image-2 오류 발생 시나리오 대조표
| 카테고리 | 고위험 트리거 단어 예시 | 위험 등급 |
|---|---|---|
| Violence(폭력) | fight, war, weapon, blood, shoot, punch, kill | 🔴 높음 |
| Violence/Graphic(잔혹한 폭력) | gore, gruesome, mutilation, severed | 🔴 매우 높음 |
| Sexual(성적 콘텐츠) | nude, explicit, suggestive, intimate poses | 🔴 매우 높음 |
| Hate Symbols(혐오 상징) | swastika, 특정 극단주의 도상 | 🔴 매우 높음 |
| Self-harm(자해) | suicide, cut wrists, harming oneself | 🔴 매우 높음 |
| Minors(미성년자 실사 묘사) | child + photorealistic 조합 | 🟡 중-고 |
| Public Figures(공인) | 정치인, 유명인 이름 | 🟡 중 |
| Copyrighted IP(저작권 IP) | 디즈니 캐릭터, 마블 캐릭터, 유명 IP 이름 | 🟡 중 |
| Living Artists(생존 작가 화풍) | "in the style of [생존 작가 이름]" | 🟡 중 |
gpt-image-2 violence 하위 카테고리 분석
safety_violations=[violence]는 실제로는 두 가지 세부 카테고리로 나뉘는데, 많은 분이 이를 혼동하곤 합니다.
violence → 일반적인 폭력 묘사 (동작, 갈등, 무기 존재)
violence/graphic → 잔혹하고 유혈이 낭자한 폭력 디테일
프롬프트가 이 중 하나라도 트리거하면 safety_violations=[violence] 오류가 발생합니다. 즉, 단순히 "소총을 든 군인(a soldier with a rifle)"처럼 비교적 중립적인 묘사를 하더라도, 전체적인 문맥에 따라 분류기가 이를 폭력 카테고리로 판단할 수 있다는 점을 유의해야 합니다.
사용자 사례 심층 분석: violence 오류의 근본 원인
앞서 언급한 실제 오류로 돌아가 보겠습니다. safety_violations=[violence]라는 필드는 폭력성 관련 차단이 발생했음을 알려줍니다. 하지만 정확히 어떤 단어가 차단을 유발했을까요? 아래에 체계적인 진단 방법을 정리했습니다.
gpt-image-2 오류: violence 트리거 단어 리스트
커뮤니티 피드백과 실제 테스트에 따르면, 다음 단어들은 violence 관련 차단율을 크게 높입니다(이 외에도 더 있을 수 있습니다).
| 트리거 유형 | 고빈도 위반 단어 | 안전한 대체 표현 |
|---|---|---|
| 무기 명칭 | gun, rifle, sword, knife, weapon | ceremonial prop, movie prop, decorative blade |
| 폭력 동작 | fight, attack, shoot, stab, punch | dynamic cinematic action, dramatic standoff |
| 전쟁 문맥 | war, battle, soldier, combat | heroic struggle, historical reenactment |
| 유혈/상해 | blood, wound, scar, gore | red splatter, dramatic shadow, weathered |
| 폭발/파괴 | explosion, destruction, debris | dramatic light burst, swirling particles |
gpt-image-2 오류 진단 프로세스
프롬프트가 violence 관련 차단에 걸렸다면, 다음 순서대로 확인해 보세요.
- 명시적 폭력 단어 확인: 프롬프트에 위 트리거 단어가 포함되어 있는지 스캔합니다.
- 동사 강도 확인: fight/attack 같은 동작 동사를 상태 묘사로 변경해 봅니다.
- 참조 이미지 확인(편집 시): 업로드한 이미지 자체에 폭력적인 요소가 있는지 확인합니다.
- 전체 문맥 확인: 특정 고위험 단어가 없더라도 전체적인 묘사가 폭력적인 장면을 구성하면 차단될 수 있습니다.
- 프레임워크 선언 추가: 프롬프트 시작 부분에 "movie still" 또는 "theatrical scene"을 추가해 봅니다.
gpt-image-2 오류: 요청 ID(Request ID)의 용도
오류 메시지에 포함된 request id: 2026042723155331083492939703753는 단순한 장식이 아닙니다. 로그를 추적하기 위한 유일한 증거입니다. 공식 경로를 통해 연동 중이라면, 이 ID를 사용하여 플랫폼 기술 지원팀에 구체적인 차단 사유를 문의할 수 있습니다.
💡 진단 제안:
moderation_blocked오류가 발생한 모든 request ID와 원본 프롬프트를 저장하여 내부 "위반 샘플 라이브러리"를 구축하고, 자동 재작성 규칙을 훈련하는 데 활용하세요. APIYI(apiyi.com) 콘솔에서 요청 로그를 내보내 월간 규정 준수 감사를 수행하고, 팀 내에서 가장 빈번하게 발생하는 차단 패턴을 식별하는 것을 추천합니다.
gpt-image-2 오류를 해결하는 5가지 프롬프트 최적화 전략
실전에서 검증된 gpt-image-2 차단율을 낮추는 5가지 전략입니다. 우선순위가 높은 순서대로 적용해 보세요.
전략 1: 프롬프트 민감도 낮추기(Desensitization)
가장 흔하게 사용되며 효과적인 전략입니다. 고위험 단어를 시각적으로 동일한 중립적 묘사로 대체하는 것입니다. 핵심 원칙은 시각적 효과는 유지하되 폭력적 지향성은 제거하는 것입니다.
# ✗ violence 차단 발생
- "Two warriors fighting with swords, blood splatter on the ground, war scene"
# ✓ 민감도 완화 후 통과
+ "Two armored figures in dramatic standoff with ceremonial blades, red light reflections on the stone floor, cinematic composition, theatrical scene"
변경 사항:
fighting→dramatic standoffswords→ceremonial bladesblood splatter→red light reflectionswar scene→theatrical scene
전략 2: 실제 대상 교체
실제 공인, 유명인, 저작권이 있는 캐릭터를 직접 언급하는 대신 시각적 특징을 묘사하세요.
# ✗ public_figures 또는 copyrighted_ip 차단 발생
- "A portrait of [연예인 이름] in business suit"
- "Mickey Mouse riding a bicycle in Paris"
# ✓ 안전한 묘사
+ "A portrait of a charismatic 30-year-old Asian businesswoman with shoulder-length black hair, wearing a tailored navy suit"
+ "A friendly anthropomorphic mouse character with round black ears and red shorts, riding a bicycle near the Eiffel Tower"
주의: 완벽한 "스타일 묘사"도 저작권 캐릭터 문맥에서는 차단될 수 있습니다. 검사기는 텍스트 매칭뿐만 아니라 시각적 유사성을 기반으로 판단하기 때문입니다. 충분한 "독창적" 특징을 추가하는 것이 좋습니다.
전략 3: 장면 프레임워크 선언
프롬프트 시작 부분에 명확한 예술/창작 프레임워크를 추가하여, 분류기에게 이것이 현실이 아닌 창작물임을 알리세요.
- "Soldiers running across a battlefield"
+ "Movie still from a 1940s war drama: soldiers running across a foggy field, sepia tones, film grain texture"
- "Action scene with gunfire"
+ "Video game cutscene illustration: heroic action sequence with stylized energy effects, comic book style"
자주 사용하는 프레임워크 단어:
movie still/film stilltheatrical scene/stage performancevideo game cutscene/game illustrationcomic book panel/manga stylehistorical reenactment/museum dioramaoil painting/watercolor sketch
전략 4: 다단계 분해(Multi-step)
복잡하고 위험도가 높은 장면은 여러 단계로 나누어 작업하세요.
# 1단계: "스타일 참조 이미지" 생성 (민감한 요소 제외)
step1_prompt = "Cinematic storyboard sketch, dramatic composition, sepia tones, no text"
style_ref = client.images.generate(model="gpt-image-2", prompt=step1_prompt)
# 2단계: 스타일 묘사 + 중립적 내용으로 최종 이미지 생성
step2_prompt = "Two figures in dramatic standoff, sepia tones, cinematic storyboard style, dust particles in the air"
final_image = client.images.generate(model="gpt-image-2", prompt=step2_prompt)
이러한 '스타일 먼저, 내용 나중' 워크플로우는 단일 프롬프트의 민감도를 현저히 낮춰줍니다.
전략 5: moderation 파라미터 조정
API는 민감도를 제어할 수 있는 moderation 파라미터를 제공합니다(OpenAI 계열 이미지 모델에만 적용).
response = client.images.generate(
model="gpt-image-2",
prompt="A dramatic action scene from a noir film",
moderation="low", # 기본값은 auto, low로 낮출 수 있음
size="1024x1024",
quality="medium"
)
중요 알림:
moderation: "low"는 검사를 끄는 것이 아니라 임계값을 완화하는 것입니다.- 극도로 위험한 콘텐츠(성적, 자해, 미성년자 실사, 혐오 상징)는 low 설정에서도 차단됩니다.
- low 설정 후에도
moderation_blocked가 발생한다면, 이는 선을 넘은 것이므로 반드시 프롬프트를 수정해야 합니다. - 일반 사용자 대상 서비스에서는 low 설정을 신중하게 사용하세요(규정 준수 리스크).
🚀 빠른 시작 제안: 전략 1~3(재작성 + 교체 + 프레임워크 선언)만으로도
moderation_blocked오류의 80% 이상을 해결할 수 있습니다. APIYI(apiyi.com)의 통합 인터페이스를 통해 먼저moderation: auto로 프롬프트가 규정을 준수하는지 확인한 후, 필요에 따라 low로 조정하는 것을 권장합니다.
gpt-image-2 오류 최적화 전후 실전 비교
4가지 실제 시나리오를 통해 프롬프트 최적화의 구체적인 효과를 살펴보겠습니다.

gpt-image-2 오류 최적화 사례 1: 영화 홍보 포스터
# ✗ 최적화 전 (폭력성 트리거)
- "An action movie poster featuring a male hero firing a gun at enemies, blood splatter background"
# ✓ 최적화 후
+ "Cinematic action movie poster: a male protagonist in dramatic pose, holding a stylized prop, dynamic motion lines, red gradient background, theatrical lighting, film grain"
gpt-image-2 오류 최적화 사례 2: 게임 캐릭터 일러스트
# ✗ 최적화 전 (폭력성 트리거)
- "Fantasy warrior with bloody sword, severed enemy head at his feet, gore details"
# ✓ 최적화 후
+ "Fantasy warrior video game character art: armored figure with ornate ceremonial blade, defeated stylized monster silhouette at his feet, JRPG illustration style, painterly textures"
gpt-image-2 오류 최적화 사례 3: 역사 교육용 삽화
# ✗ 최적화 전 (폭력성 트리거)
- "World War II soldiers fighting in trenches with rifles and explosions"
# ✓ 최적화 후
+ "Historical educational illustration depicting a 1940s European trench scene: figures in period uniforms, weathered terrain with dramatic atmospheric effects, sepia documentary style, museum diorama aesthetic"
gpt-image-2 오류 최적화 사례 4: 상업 광고 콘셉트 이미지
# ✗ 최적화 전 (유명인 트리거)
- "[유명인 이름] holding our coffee product in his usual style"
# ✓ 최적화 후
+ "Charismatic 35-year-old male model with confident smile, casual blazer, warmly holding a takeaway coffee cup, modern minimalist café background, professional commercial photography"
gpt-image-2 오류율을 낮추는 엔지니어링 베스트 프랙티스
프로젝트에서 매일 수천 번씩 gpt-image-2를 호출한다면 수동으로 프롬프트를 검토하는 것은 불가능합니다. gpt-image-2의 오류율을 낮추기 위한 몇 가지 엔지니어링 접근 방식을 소개합니다.
gpt-image-2 오류 사전 검증 프로세스
이미지 API를 호출하기 전에 Moderations API를 사용하여 사전 검증을 수행합니다.
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1"
)
def safe_generate(prompt: str, max_rewrites: int = 3):
# 1단계: 사전 검증
mod = client.moderations.create(input=prompt)
flagged = mod.results[0].flagged
categories = mod.results[0].categories
if flagged:
offending = [k for k, v in categories.model_dump().items() if v]
raise ValueError(f"프롬프트 사전 검증 트리거됨: {offending}")
# 2단계: 실제 호출
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="medium"
)
사전 검증을 통해 고위험 요청의 60~70%를 차단하여 불필요한 호출을 방지할 수 있습니다.
gpt-image-2 오류 자동 재작성 파이프라인
프로덕션 환경의 프롬프트 템플릿을 위해 가벼운 재작성기를 구축할 수 있습니다.
SENSITIVE_REPLACEMENTS = {
r"\bgun\b": "ceremonial prop",
r"\bsword\b": "ornate ceremonial blade",
r"\bblood\b": "red splatter",
r"\bfight\b": "dramatic standoff",
r"\bwar\b": "heroic struggle",
r"\battack\b": "dynamic motion",
r"\bweapon\b": "stylized prop",
r"\bkill\b": "defeat",
r"\bshoot\b": "aim",
}
import re
def desensitize(prompt: str) -> str:
out = prompt
for pattern, replacement in SENSITIVE_REPLACEMENTS.items():
out = re.sub(pattern, replacement, out, flags=re.IGNORECASE)
if not out.lower().startswith(("movie still", "video game", "theatrical")):
out = "Cinematic movie still: " + out
return out
gpt-image-2 오류 지능형 재시도 캡슐화
moderation_blocked에 대한 특별 재시도 전략입니다. 그대로 재시도하면 안 되며, 반드시 프롬프트를 먼저 재작성해야 합니다.
from openai import BadRequestError
def generate_with_rewrite(prompt: str, max_attempts: int = 3):
current = prompt
for attempt in range(max_attempts):
try:
return client.images.generate(
model="gpt-image-2",
prompt=current,
size="1024x1024"
)
except BadRequestError as e:
if "moderation_blocked" not in str(e):
raise # 다른 400 오류는 재시도하지 않음
print(f"[{attempt+1}/{max_attempts}] 검토 트리거됨, 민감도 완화 재작성 적용 중...")
current = desensitize(current)
if attempt == max_attempts - 1:
# 마지막 시도 시 moderation: low 적용
return client.images.generate(
model="gpt-image-2",
prompt=current,
moderation="low",
size="1024x1024"
)
raise RuntimeError("모든 재작성 전략 실패")
gpt-image-2 오류 준수 모니터링 대시보드
프로덕션 환경에서는 위반 사항의 핵심 지표를 기록해야 합니다.
| 지표 | 용도 |
|---|---|
| 위반율 (차단 수/총 요청 수) | 전체 상태 점검 |
safety_violations 카테고리별 분포 |
빈도 높은 위반 유형 식별 |
| 위반 트리거 프롬프트 Top 10 | 가장 문제가 되는 템플릿 최적화 |
| 재작성 후 통과율 | 재작성기 효과 평가 |
🎯 프로덕션 배포 제언: 위반율을 핵심 SLO 지표로 설정하는 것을 권장합니다. 건강한 프로덕션 라인의 위반율은 보통 2% 미만이어야 하며, 5%를 초과하면 프롬프트 템플릿에 시스템적인 문제가 있다는 의미입니다. APIYI(apiyi.com) 콘솔의 요청 로그를 통해 일 단위 분석을 수행하고, 위반이 잦은 템플릿을 집중적으로 재작성하는 것을 추천합니다.
gpt-image-2 오류 관련 FAQ
Q1:gpt-image-2에서 moderation_blocked 오류가 발생하면 비용이 청구되나요?
아니요. 안전 분류기가 요청이 모델에 도달하기 전에 차단하기 때문에 토큰이나 GPU 시간은 전혀 소모되지 않습니다. OpenAI와 APIYI 모두 이 규칙을 따릅니다. 만약 청구서에 해당 비용이 포함되어 있다면 즉시 플랫폼에 문의하여 확인하시기 바랍니다. APIYI(apiyi.com) 제어판을 통해 각 request_id별로 결제 내역을 대조하여 차단된 요청에 대해 0원 청구가 이루어졌는지 확인하는 것을 권장합니다.
Q2:gpt-image-2 오류 발생 시 동일한 프롬프트로 재시도해도 소용없는 이유는 무엇인가요?
안전 분류기는 **결정론적(deterministic)**이기 때문입니다. 동일한 입력에 대한 분류 결과는 생성 모델처럼 무작위성을 띠지 않고 일정합니다. 100번을 재시도해도 100번 모두 동일하게 차단됩니다. 유일한 해결책은 프롬프트를 수정하는 것입니다.
Q3:gpt-image-2 오류의 moderation: low 설정을 통해 검열을 완전히 끌 수 있나요?
아니요. low는 단순히 민감도 임계값을 낮추어 중간 수준의 민감한 콘텐츠에 대해 조금 더 관대해질 뿐입니다. 극도로 위험한 콘텐츠(성적, 자해, 미성년자 실사, 혐오 상징, 정치 지도자 등)는 low 설정이라도 차단됩니다. low를 검열 "끄기" 스위치로 생각하는 것은 잘못된 인식입니다.
Q4:프롬프트가 무해해 보이는데도 gpt-image-2에서 차단되는 이유는 무엇인가요?
가능성은 세 가지입니다.
- 전체 문맥이 규정 위반: 개별 단어는 무해하지만, 조합되어 위반 상황을 형성한 경우
- 다의어 트리거: 예를 들어 "shoot a photo"가 폭력적인 단어로 오판될 수 있음
- 백엔드 차이: Azure 백엔드가 OpenAI 직연결보다 더 엄격함
2번 상황의 경우, "professional photography session"과 같은 상황 프레임워크 선언을 추가하면 오판을 크게 줄일 수 있습니다. APIYI(apiyi.com)를 통해 이러한 "오판" 사례를 내부 지식 베이스에 축적하여 프롬프트 템플릿 개선을 위한 자료로 활용하는 것을 추천합니다.
Q5:gpt-image-2 오류 발생 시 어떤 단어가 트리거되었는지 확인할 수 있나요?
API는 구체적인 트리거 단어를 반환하지 않으며, 오직 카테고리(예: [violence])만 반환합니다. 이는 "우회 가이드"로 악용되는 것을 방지하기 위한 OpenAI의 설계 선택입니다. 특정 트리거 단어를 찾으려면 직접 이진 탐색(binary search)을 수행해야 합니다. 프롬프트를 절반으로 나누어 각각 테스트해 보세요.
Q6:gpt-image-2 오류 처리 시 참조 이미지(편집 시나리오)가 위반된 경우는 어떻게 하나요?
/v1/images/edits 엔드포인트의 Stage 1은 프롬프트 텍스트와 업로드된 모든 참조 이미지를 동시에 스캔합니다. 참조 이미지 자체가 위반 사항이라면:
- 참조 이미지에 폭력, 성적 암시, 저작권 캐릭터 요소가 포함되어 있는지 확인하세요.
- 로컬 도구로 참조 이미지를 전처리(민감 영역 자르기, 흐림 처리)하세요.
- 실사 사진인 경우, 공인 정책을 위반하지 않았는지 확인하세요.
Q7:gpt-image-2 오류의 위반 카테고리는 OpenAI Moderations API 카테고리와 동일한가요?
대체로 일치하지만 차이가 있습니다. Moderations API가 반환하는 카테고리는 더 세분화(11개)되어 있고, 이미지 생성의 차단 카테고리는 상대적으로 거친 편(7~9개)입니다. Moderations API를 사전 검증 도구로 사용하는 것은 좋지만, 결과가 100% 동일하다고 가정해서는 안 됩니다. Moderations를 통과한 프롬프트라도 이미지 생성 단계에서 차단될 수 있습니다.
Q8:gpt-image-2 오류에 대해 이의 제기를 할 수 있나요?
가능하지만 효과는 제한적입니다. 오류 정보의 request_id를 사용하여 플랫폼 기술 지원팀에 확인을 요청할 수 있습니다. 실무 경험상, 오판(예: 의학/교육용 중립 콘텐츠)인 경우 플랫폼에서 화이트리스트에 추가해 줄 수 있지만, 실제로 규정을 위반한 경우 이의 제기는 무의미합니다. APIYI(apiyi.com) 고객센터를 통해 이의 제기를 할 때는 전체 request_id와 비즈니스 시나리오 설명을 첨부하여 처리 효율을 높이시기 바랍니다.
요약: gpt-image-2 오류에서 규정 준수 및 효율적인 프롬프트까지
본 글의 7개 섹션을 모두 확인하셨다면, gpt-image-2 오류 처리 체계를 완벽히 마스터하셨을 것입니다.
- ✅ 본질 이해 ——
moderation_blocked는 요청 수준의 400 오류이며, 비용이 청구되지 않고 재시도가 불가능함 - ✅ 아키텍처 파악 —— 2단계 안전 검사(Stage 1 입력 필터링 + Stage 2 출력 필터링)
- ✅ 트리거 상황 숙지 —— 7대 위반 카테고리 + violence 하위 카테고리 세부 사항
- ✅ 위반 진단 ——
safety_violations필드를 통한 정확한 위치 파악 - ✅ 5가지 최적화 전략 —— 민감도 낮추기, 주체 교체, 프레임워크 선언, 다단계 분해, moderation 파라미터 활용
- ✅ 엔지니어링 솔루션 —— 사전 검증, 자동 재작성, 지능형 재시도, 규정 준수 모니터링
가장 중요한 인식: gpt-image-2의 moderation_blocked 오류는 버그가 아니라 제품의 규정 준수 경계입니다. 너무 엄격하다고 불평하기보다 "규정 준수 프롬프트 엔지니어링"을 생산 능력으로 구축하는 것이 중요합니다. 이는 AI 제품이 B2C 시장에 안착하기 위한 핵심 경쟁력 중 하나입니다.
팀에서 잦은 moderation_blocked 오류를 겪고 있거나, 생산 라인을 위한 프롬프트 규정 준수 감사 프로세스가 필요하다면, 지금 바로 APIYI(apiyi.com)에서 테스트 키를 신청하여 본문의 사전 검증 + 자동 재작성 코드 템플릿을 실행해 보세요. 모든 예제는 공식 SDK + APIYI 공식 중계 채널(OpenAI와 필드 100% 일치)을 기반으로 하므로 범용성이 매우 높으며, 자신의 프로젝트에 즉시 적용할 수 있습니다.
참고 자료
-
OpenAI ChatGPT Images 2.0 시스템 카드: 공식 보안 정책 및 차단 메커니즘 설명
- 링크:
deploymentsafety.openai.com/chatgpt-images-2-0/live-blocking - 설명: 2단계 필터링 아키텍처 및 위반 카테고리 전체 목록 포함
- 링크:
-
OpenAI Moderations API 문서: 사전 검증 도구 공식 사용 가이드
- 링크:
developers.openai.com/api/docs/guides/moderation - 설명: 11가지 위반 카테고리 및 API 호출 방법
- 링크:
-
OpenAI 사용 정책: 사용 정책에 대한 공식 설명
- 링크:
openai.com/policies/usage-policies/ - 설명: 금지된 용도, 책임 소재, 규정 준수 요구 사항
- 링크:
-
OpenAI GPT 이미지 모델 프롬프트 가이드: 공식 프롬프트 모범 사례
- 링크:
developers.openai.com/cookbook/examples/multimodal/image-gen-models-prompting-guide - 설명: 규정을 준수하는 프롬프트 작성법 및 사례 포함
- 링크:
-
APIYI gpt-image-2 연동 문서: 한국어 버전 전체 연동 가이드
- 링크:
docs.apiyi.com/api-capabilities/gpt-image-2/overview - 설명: moderation 파라미터 상세 설명 및 오류 코드 처리 방법 포함
- 링크:
작성자: APIYI 기술팀
발행일: 2026년 4월 27일
키워드: gpt-image-2 오류, moderation_blocked, safety_violations, 콘텐츠 검토, 프롬프트 최적화, APIYI, OpenAI 규정 준수