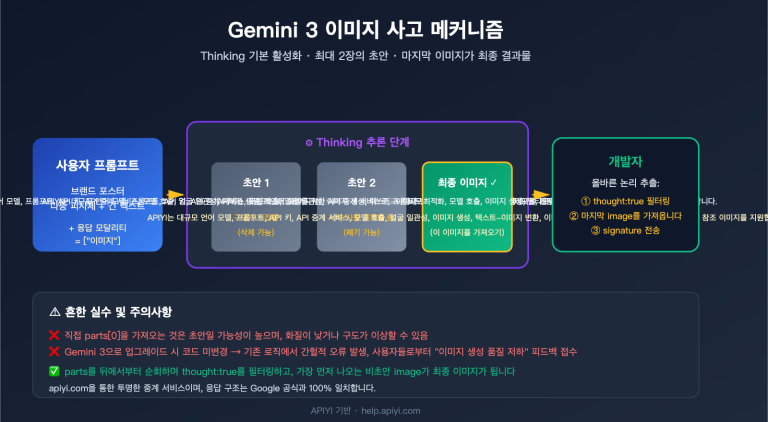
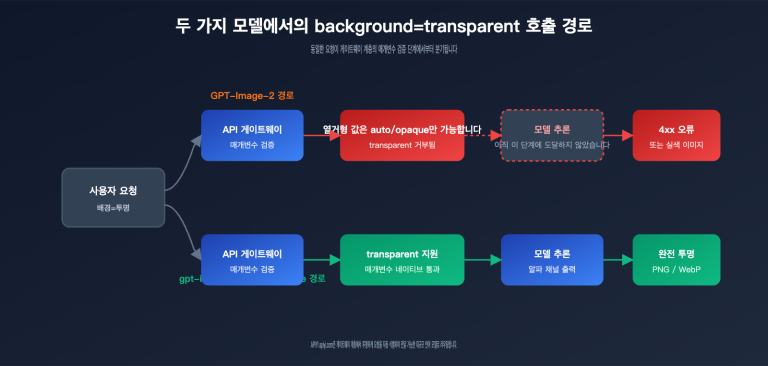
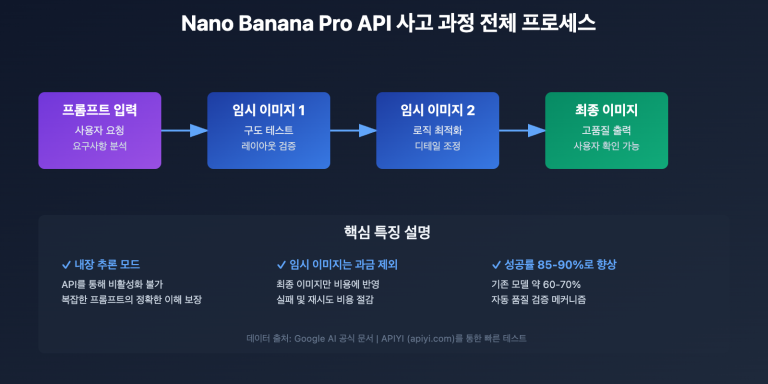
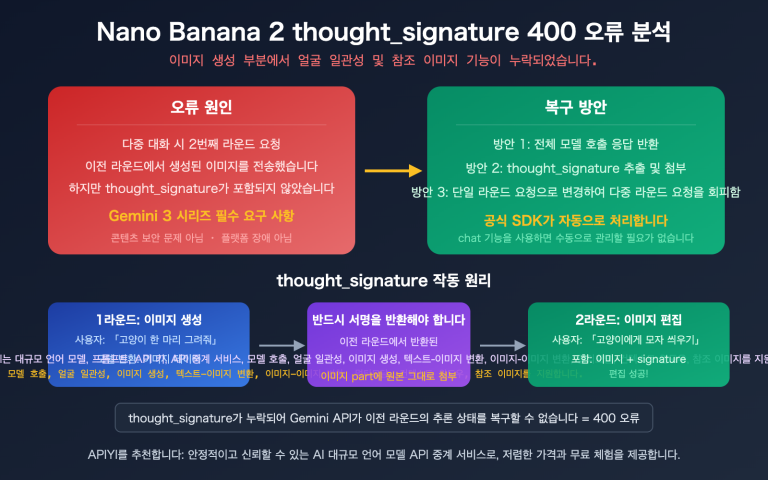
작성자 주: APIYI에서 gpt-image-2-all 공식 역방향 모델을 출시했습니다. 회당 $0.03의 비용으로 동시 접속 제한 없이 이용 가능하며, 텍스트-이미지 변환, 다중 이미지 융합, 자연어 기반 이미지 수정 기능을 지원합니다. ChatGPT 웹 버전의 최신 이미지 생성 기능과 동일한 성능을 제공하며, 본 글에서 API 연동 방법을 상세히 설명합니다.
2026년 4월, ChatGPT 웹 버전은 차세대 이미지 생성 기능에 대한 A/B 테스트를 시작했습니다. 사용자 인터페이스에는 여전히 "GPT Image 1.5"라는 라벨이 표시되지만, 일부 요청은 실제로 새로운 모델에 의해 처리되고 있습니다. OpenAI 공식 API는 아직 gpt-image-2 모델 ID를 공개하지 않았습니다. "gpt-image-2를 직접 API로 호출한다"고 주장하는 서비스는 주의 깊게 확인해야 합니다.
APIYI는 현재 공식 역방향(官逆) 솔루션을 통해 gpt-image-2-all을 정식 출시했습니다. ChatGPT 웹 버전의 최신 이미지 생성 기능과 동일한 성능을 제공하며, 회당 $0.03의 비용으로 동시 접속 제한 없이 이용할 수 있습니다. 이는 단순한 약속이 아니라, 표준 HTTP 요청으로 즉시 호출 가능한 프로덕션급 인터페이스입니다.
핵심 가치: 이 글을 읽고 나면 gpt-image-2-all의 3가지 API 엔드포인트, 다중 이미지 융합 기술, 자연어 기반 이미지 수정 사용법을 익히고 10분 안에 연동을 완료할 수 있습니다.

gpt-image-2-all 핵심 요약
| 기능 | 설명 | 가치 |
|---|---|---|
| ChatGPT 웹 버전 평행 이동 | 공식 역방향 솔루션으로 공식 기능과 동기화 | OpenAI API 공개 대기 불필요 |
| 회당 과금 | $0.03/회, 해상도/품질/프롬프트 제한 없음 | 비용 투명성 및 예측 가능 |
| 동시 접속 제한 없음 | 요청 수 제한 없음 | 배치 파이프라인에 최적화 |
| 다중 이미지 융합 | 프롬프트 내 "이미지1/이미지2/이미지3" 참조 | 다중 피사체 일관성 생성 |
| 자연어 기반 이미지 수정 | 마스크 없이 대화형 편집 | 반복 작업 진입 장벽 대폭 완화 |
gpt-image-2-all 포지셔닝 해석
"공식 역방향(官逆)"이란 무엇인가? 이는 리버스 엔지니어링을 통해 ChatGPT 웹 버전의 최신 이미지 생성 기능을 연결하는 중계 서비스입니다. OpenAI가 향후 정식으로 공개할 gpt-image-2와는 다른 인터페이스이지만, 기반 모델 성능은 동일합니다. 공식 API가 정식으로 공개되기 전까지, ChatGPT의 최신 이미지 생성 기능을 안정적으로 호출할 수 있는 유일한 프로덕션급 솔루션입니다.
왜 지금 바로 연동해야 하는가? 세 가지 현실적인 이유가 있습니다: (1) OpenAI 공식 gpt-image-2 출시일이 미정(2026년 4월 하순~5월 중순 예상); (2) 초기 출시 시 할당량 부족 및 콜드 스타트 문제 발생 가능성; (3) gpt-image-2-all을 통해 비즈니스 프로세스를 미리 구축해두면, 공식 버전이 공개될 때 모델 이름만 변경하여 원활하게 마이그레이션 가능.
gpt-image-2-all 퀵 스타트 가이드
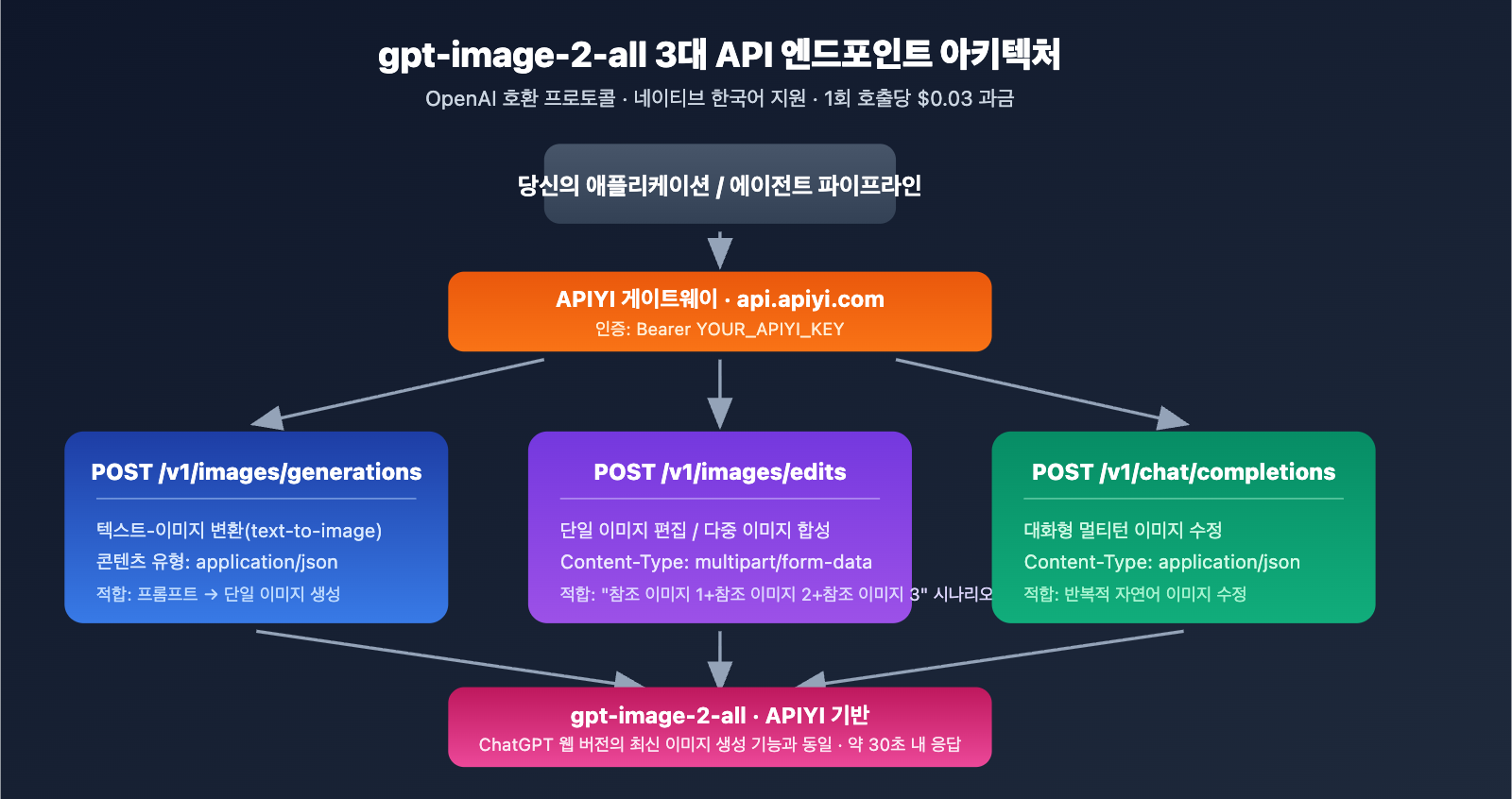
3대 API 엔드포인트
gpt-image-2-all은 전체 이미지 생성 시나리오를 커버하는 세 가지 엔드포인트를 제공합니다:
| 엔드포인트 | 용도 | Content-Type |
|---|---|---|
POST /v1/images/generations |
텍스트-이미지 변환 | application/json |
POST /v1/images/edits |
단일 이미지 편집/다중 이미지 융합 | multipart/form-data |
POST /v1/chat/completions |
대화형 다중 턴 이미지 수정 | application/json |
Base URL: https://api.apiyi.com (대체 주소: b.apiyi.com, vip.apiyi.com)
초간단 텍스트-이미지 변환 예제
import requests
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={
"Authorization": "Bearer YOUR_APIYI_KEY",
"Content-Type": "application/json"
},
json={
"model": "gpt-image-2-all",
"prompt": "가로형 16:9 비율, 라떼 한 잔, 테이블 위에 'Morning Blend $4.50'이라고 적힌 라벨, 카페 창문을 통해 들어오는 아침 햇살",
},
timeout=120
)
result = response.json()
print(result["data"][0]["url"])
전체 연동 코드 보기 (오류 처리, 동시성, 다중 이미지 융합, 대화형 수정 포함)
import requests
import time
from typing import Optional, List
API_KEY = "YOUR_APIYI_KEY"
BASE_URL = "https://api.apiyi.com"
def text_to_image(prompt: str, timeout: int = 120) -> Optional[str]:
"""텍스트-이미지 변환: /v1/images/generations 엔드포인트 사용"""
for attempt in range(3):
try:
r = requests.post(
f"{BASE_URL}/v1/images/generations",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "prompt": prompt},
timeout=timeout
)
if r.status_code == 200:
return r.json()["data"][0]["url"]
if r.status_code == 429:
time.sleep(2 ** attempt)
continue
except requests.Timeout:
continue
return None
def multi_image_fusion(prompt: str, image_paths: List[str]) -> Optional[str]:
"""다중 이미지 융합: /v1/images/edits 엔드포인트 사용"""
files = [
("image[]", (f"img{i}.png", open(p, "rb"), "image/png"))
for i, p in enumerate(image_paths)
]
data = {"model": "gpt-image-2-all", "prompt": prompt}
r = requests.post(
f"{BASE_URL}/v1/images/edits",
headers={"Authorization": f"Bearer {API_KEY}"},
data=data,
files=files,
timeout=120
)
return r.json()["data"][0]["url"] if r.status_code == 200 else None
def conversational_edit(messages: List[dict]) -> Optional[str]:
"""대화형 이미지 수정: /v1/chat/completions 엔드포인트 사용"""
r = requests.post(
f"{BASE_URL}/v1/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "messages": messages},
timeout=120
)
return r.json()["choices"][0]["message"]["content"] if r.status_code == 200 else None
url = text_to_image("세로형 9:16 비율, 휴대폰 광고 포스터, 아이스 라떼 한 잔, 상단에 큰 글씨로 'Summer Sale 50% OFF'")
print(f"Generated: {url}")
fusion_url = multi_image_fusion(
"이미지 1의 인물을 이미지 2의 해변 배경에 배치하고, 인물의 복장은 유지해줘",
["person.png", "beach.png"]
)
print(f"Fusion: {fusion_url}")
연동 팁: APIYI(apiyi.com)에 가입하면 테스트 크레딧을 받을 수 있습니다. 하나의 API 키로 gpt-image-2-all, GPT-4o, Claude 등 모든 모델을 지원하므로 여러 업체의 계정을 관리할 필요가 없습니다.
gpt-image-2-all 핵심 기능 상세
기능 1: 고정밀 텍스트 렌더링
gpt-image-2-all의 가장 큰 강점은 공식 ChatGPT 최신 이미지 생성 기능을 기반으로 한 뛰어난 한글 및 영어 텍스트 렌더링 안정성입니다. 간판, 포스터, 인포그래픽 내의 텍스트를 한 번에 정확하게 생성할 수 있으며, 이는 이전 모델인 gpt-image-1.5에서는 구현하기 어려웠던 부분입니다.
주요 활용 사례:
- 카페 메뉴판:
"Americano $4.00, Latte $4.50"등 문자 단위 정확도 제공 - 제품 패키지: 한글과 영어가 혼합된 성분표를 명확하게 표시
- UI 목업: 버튼 텍스트 및 내비게이션 라벨 정확한 렌더링
- 인포그래픽: 제목, 부제목, 데이터 라벨의 계층 구조 명확화
기능 2: 다중 이미지 융합 기능
/v1/images/edits 엔드포인트를 통해 여러 장의 참조 이미지를 동시에 업로드할 수 있으며, 프롬프트에서 **"이미지 1", "이미지 2", "이미지 3"**과 같이 직접 참조할 수 있습니다.
prompt = """
이미지 1의 제품을 이미지 2의 배경에 배치하고,
이미지 3의 색감 스타일을 적용해줘.
카메라 앵글은 약간 위에서 내려다보는 구도로,
4K 고화질로 생성해줘.
"""
활용 사례:
| 시나리오 | 활용 방법 |
|---|---|
| 이커머스 합성 | 제품 이미지 + 배경 이미지 → 생활 밀착형 합성 |
| 캐릭터 일관성 | 캐릭터 원본 이미지 + 새로운 배경 → 다양한 앵글 생성 |
| 스타일 전이 | 콘텐츠 이미지 + 스타일 이미지 → 스타일화된 출력 |
| 브랜드 비주얼 | 제품 + 로고 + 컬러 팔레트 → 일관된 브랜드 비주얼 |
기능 3: 자연어 기반 이미지 수정 (마스크 불필요)
가장 큰 효율성 혁신은 대화형 이미지 수정입니다. 더 이상 마스크를 그리거나 영역을 선택할 필요 없이, 자연어로 수정 사항을 설명하기만 하면 됩니다.
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "카페 외관 이미지를 생성해줘, 오후의 햇살이 비치는 모습으로"},
]
},
{
"role": "assistant",
"content": "[생성된 이미지 링크]"
},
{
"role": "user",
"content": "건물은 그대로 두고 날씨를 비 오는 날로 바꿔줘"
}
]
이 워크플로우의 의미: 기존의 "생성 → 포토샵 수정 → 재생성" 과정을 거치던 루프가 이제는 대화형 반복으로 대체됩니다. 매번 전체 프롬프트를 다시 작성할 필요 없이 변경 사항만 설명하면 됩니다.
기능 4: 네이티브 한국어 지원
프롬프트를 한국어로 직접 작성할 수 있으며, 영어로 번역할 필요 없이 바로 호출 가능합니다. 한국 개발 팀과 로컬 비즈니스 환경에서 매우 자연스럽고 편리한 경험을 제공합니다.
prompt = "세로형 9:16 비율, 샤오홍슈 스타일 커버 이미지, 커피를 마시는 동양인 여성, 제목 '주말 탐방 · 골목길 속 비밀 카페', 부드러운 조명의 실사 스타일"
gpt-image-2-all 사이즈 및 비율 제어
중요 참고 사항
gpt-image-2-all은 size, n, quality, aspect_ratio와 같은 파라미터를 지원하지 않습니다. 해당 파라미터를 전달하면 검증 오류가 발생합니다. 이미지의 크기와 비율은 반드시 프롬프트 텍스트 설명을 통해 제어해야 합니다.
추천 프롬프트 작성법

| 목표 비율 | 추천 작성법 | 설명 |
|---|---|---|
| 1:1 정사각형 | "1024×1024 정사각형" 또는 "1:1 정사각형 구도" | 소셜 미디어 프로필 |
| 16:9 가로형 | "가로형 16:9" 또는 "16:9 와이드스크린" | 영상 썸네일 |
| 9:16 세로형 | "세로형 9:16" 또는 "9:16 스마트폰 세로 화면" | 숏폼/SNS 게시물 |
| 21:9 초광각 | "가로형 21:9" 또는 "초광각 화면" | 웹 배너 |
| 4:3 표준 | "가로형 4:3" | 프레젠테이션 슬라이드 |
| 3:4 포트레이트 | "세로형 3:4" | 이커머스 상세 이미지 |
핵심 팁
비율 설명을 프롬프트의 맨 앞에 배치하세요. 모델은 프롬프트의 앞부분에 더 높은 가중치를 두기 때문에, 비율을 뒤에 적으면 무시될 가능성이 있습니다.
# ✅ 추천
prompt = "가로형 16:9, 벚꽃 나무 아래에서 웃고 있는 시바견, 부드러운 조명 사진 스타일"
# ❌ 비추천
prompt = "벚꽃 나무 아래에서 웃고 있는 시바견, 부드러운 조명 사진 스타일, 가로형 16:9"
gpt-image-2-all 가격 정책 및 동시성 전략
요금 규칙
| 항목 | 규칙 |
|---|---|
| 단가 | $0.03 / 회 |
| 과금 단위 | 성공적인 생성 횟수 기준 |
| 실패 시 과금 없음 | 401/4xx/5xx 오류 발생 시 과금되지 않음 |
| 파라미터 영향 | 없음(해상도/품질과 무관) |
| 동시성 제한 | 없음(계정 잔액에 따른 자연스러운 제한) |
예상 비용 산출
| 비즈니스 시나리오 | 월 호출량 | 월 비용 |
|---|---|---|
| 개인 프로젝트 | 500회 | $15 |
| 소규모 팀 | 5,000회 | $150 |
| 이커머스 대량 작업 | 50,000회 | $1,500 |
| 대규모 파이프라인 | 500,000회 | $15,000 |
비용 최적화 제안: APIYI(apiyi.com)의 통합 계정 스케줄링을 활용하면 실시간 작업 유형에 따라 gpt-image-2-all, gpt-image-1.5, Nano Banana Pro 중에서 최적의 모델로 라우팅할 수 있습니다. 이를 통해 모든 작업에 최고 단가를 지불하는 상황을 방지하세요.
gpt-image-2-all 오류 처리 및 모범 사례
주요 오류 코드 및 처리 방법
| 상태 코드 | 처리 방식 |
|---|---|
| 401 | Authorization Bearer Token이 올바른지 확인 |
| 429 | 지수 백오프 재시도(2초 → 4초 → 8초) |
| 5xx | 1~2회 재시도 후 실패 시 알림 설정 |
| 타임아웃 | 클라이언트 타임아웃 설정은 120초 이상 권장 |
문제 해결 팁
모든 응답에는 request-id 응답 헤더가 포함되어 있습니다. 문제가 발생하면 이 ID를 기록하여 APIYI 기술 지원팀에 제출하세요. 서버 로그를 통해 빠르게 원인을 파악할 수 있습니다.
지원하지 않는 기능
- 스트리밍 출력:
stream=true는 지원하지 않으며, 단일 응답만 가능합니다. - 다중 이미지 출력: 한 번의 요청당 1장의 이미지만 반환됩니다. 여러 장이 필요한 경우 동시 호출을 사용하세요.
- OpenAI SDK 기본 파라미터: 공식 SDK의 기본값인
size/n파라미터는 검증 오류를 유발할 수 있습니다. requests를 사용하여 직접 요청하는 것을 권장합니다.
자주 묻는 질문 (FAQ)
Q1: gpt-image-2-all이란 무엇인가요?
gpt-image-2-all은 APIYI가 공식 역방향 엔지니어링(Reverse Engineering) 솔루션을 통해 ChatGPT 웹 버전의 최신 이미지 생성 기능을 연동한 API 중계 서비스입니다. OpenAI가 정식으로 gpt-image-2 API를 공개하기 전, ChatGPT의 최신 성능을 그대로 활용할 수 있는 프로덕션급 호출 경로를 제공하며 텍스트-이미지 변환, 다중 이미지 융합, 자연어 기반 이미지 수정 등 3가지 핵심 기능을 지원합니다.
Q2: gpt-image-2-all과 공식 gpt-image-2의 차이점은 무엇인가요?
기본 모델 성능은 동일하지만, 인터페이스 방식에 차이가 있습니다. 현재 OpenAI 공식 API는 gpt-image-2 모델 ID를 공개하지 않은 상태입니다(직접 호출이 가능하다고 주장하는 서비스는 주의해서 확인해야 합니다). ChatGPT 웹 버전에서는 이미 A/B 테스트를 통해 새로운 모델을 적용 중이며, gpt-image-2-all은 이 기능을 안정적으로 호출할 수 있도록 지원합니다. 추후 공식 API가 공개되면 model 필드만 변경하여 공식 인터페이스로 원활하게 전환할 수 있습니다.
Q3: 1회당 $0.03이라는 가격은 어떻게 이해하면 될까요?
성공적으로 생성된 횟수를 기준으로 과금하며, 해상도, 품질, 프롬프트 길이에 따른 추가 비용은 없습니다. 업계에서 추산하는 OpenAI 공식 gpt-image-2 가격($0.15~$0.20)과 비교하면 gpt-image-2-all은 약 1/5에서 1/6 수준입니다. 실패한 요청(인증 오류, 파라미터 오류 등)은 과금되지 않으며, 동시 호출 제한은 계정 잔액 범위 내에서 자유롭게 가능합니다.
Q4: 이미지 생성에 왜 30초가 걸리나요?
30초는 현재 역방향 엔지니어링 솔루션의 평균 응답 시간으로, ChatGPT 웹 버전의 속도와 비슷합니다. 향후 공식 gpt-image-2가 공개되면 더 빨라질 것으로 예상(약 3초)되지만, 공식 API 출시 전까지는 gpt-image-2-all이 최신 기능을 안정적으로 사용할 수 있는 유일한 솔루션입니다. 클라이언트 타임아웃 설정은 120초 이상으로 권장합니다.
Q5: gpt-image-2-all은 어떻게 연동하나요?
다음 3단계로 간단히 연동할 수 있습니다:
- APIYI(apiyi.com)에 가입하고 API 키를 발급받습니다.
- Base URL을
https://api.apiyi.com으로 설정합니다. requests라이브러리를 사용하여/v1/images/generations엔드포인트를 호출합니다(공식 SDK 사용 시size파라미터 문제로 인해 HTTP 요청을 직접 커스텀하는 것을 권장합니다).
상세 문서: docs.apiyi.com/api-capabilities/gpt-image-2-all/overview · 온라인 테스트: imagen.apiyi.com
Q6: 다중 이미지 융합 시 참조 이미지는 최대 몇 장까지 지원하나요?
/v1/images/edits 요청 한 번에 여러 장의 참조 이미지를 지원하며, 이미지당 10MB 이하여야 합니다(PNG/JPG/WebP 지원). 프롬프트 내에서 "이미지1", "이미지2", "이미지3"과 같은 방식으로 참조합니다. 테스트 결과 3~5장의 참조 이미지를 사용할 때 가장 안정적이며, 10장을 초과하면 일부 요소가 누락될 수 있습니다.
Q7: 왜 OpenAI 공식 SDK로 직접 호출할 수 없나요?
OpenAI 공식 SDK의 images.generate() 메서드는 기본적으로 size, n 등의 파라미터를 전송하는데, gpt-image-2-all은 이러한 파라미터를 지원하지 않아 검증 오류가 발생합니다. 권장 해결책: (1) requests를 사용하여 HTTP 요청을 직접 전송하거나, (2) SDK의 요청 본문에서 해당 파라미터를 제거하세요. 공식 버전이 공개되면 SDK와 호환될 예정입니다.
Q8: gpt-image-2-all의 알려진 제한 사항은 무엇인가요?
현재의 제한 사항은 다음과 같습니다:
- 1회당 1장 출력: 여러 장이 필요한 경우 동시 호출이 필요합니다.
- 스트리밍 미지원: 단일 응답 방식이며, 스트림(stream)을 지원하지 않습니다.
- 베타 단계: 안정성을 지속적으로 최적화 중이며, 간혹 불안정할 수 있습니다.
- 역방향 엔지니어링 의존: ChatGPT 웹 버전의 기능이 변경될 경우 서비스에 일시적인 영향이 있을 수 있습니다.
- 안정적인 모델 병행 권장: 중요한 비즈니스 서비스의 경우 gpt-image-1.5 또는 Nano Banana Pro를 대체 수단으로 함께 구성하는 것을 권장합니다.
gpt-image-2-all 핵심 요약
- 역방향 솔루션 · ChatGPT 최신 기능 이식: 공식 API 공개 전 유일한 프로덕션급 경로
- 1회당 $0.03 · 동시 호출 제한 없음: 성공 건당 과금, 투명한 비용, 대량 파이프라인 친화적
- 3개 엔드포인트로 전 장면 커버: 텍스트-이미지 변환 / 다중 이미지 융합 / 대화형 이미지 수정
- 네이티브 한국어 + 고정밀 텍스트: 한국어 및 영어 텍스트 렌더링 안정적, 프롬프트 번역 불필요
- 시작하기: APIYI(apiyi.com) 가입 → 120초 타임아웃 설정 → requests 직접 호출
요약
gpt-image-2-all의 핵심 가치:
- 공식 공백 메우기: OpenAI가
gpt-image-2API를 정식 출시하기 전, ChatGPT의 최신 이미지 생성 기능을 안정적으로 호출할 수 있는 프로덕션급 인터페이스를 제공합니다. - 예상 공식 가격보다 훨씬 저렴한 비용: 1회당 $0.03으로, 공식 예상가인 $0.15~$0.20 대비 대량 작업 시 비용 절감 효과가 매우 뛰어납니다.
- 매끄러운 마이그레이션 설계: OpenAI 호환 프로토콜을 기반으로 설계되어, 공식 버전 출시 시 모델 이름만 변경하면 즉시 전환이 가능합니다.
팀 의사결정을 위해 APIYI(apiyi.com)를 통해 즉시 gpt-image-2-all을 연동하여 비즈니스 프로세스를 검증하는 것을 추천합니다. 현재 1회당 $0.03이라는 가격은 대량 검증을 거의 비용 부담 없이 진행할 수 있게 해주며, 추후 공식 gpt-image-2가 출시되면 필요에 따라 전환하면 됩니다. 미리 준비하는 팀이 신규 모델 출시 초기 시장에서 확실한 제품 경쟁력을 확보할 수 있습니다.
온라인 체험: imagen.apiyi.com · 한국어 문서: docs.apiyi.com/api-capabilities/gpt-image-2-all/overview
관련 읽을거리 (Related Articles)
gpt-image-2-all에 관심이 있으시다면 다음 콘텐츠도 함께 확인해 보세요:
- 📘 gpt-image-2 vs gpt-image-1.5 8대 업그레이드 완벽 분석 – 성능 향상의 근본적인 이유를 알아보세요.
- 📊 gpt-image-2 6대 활용 사례 완벽 분석 – 구체적인 비즈니스 적용 경로를 파악하세요.
- 🚀 gpt-image-2 vs Nano Banana Pro 심층 비교 – 최적의 모델을 합리적으로 선택하는 방법을 확인하세요.
📚 참고 자료
-
APIYI 공식 문서: gpt-image-2-all 전체 기술 사양
- 링크:
docs.apiyi.com/api-capabilities/gpt-image-2-all/overview - 설명: 파라미터, 에러 코드, 모범 사례를 포함한 공식 기술 연동 문서입니다.
- 링크:
-
APIYI 온라인 Playground: imagen.apiyi.com
- 링크:
imagen.apiyi.com - 설명: 코딩 없이도 gpt-image-2-all의 이미지 생성 효과를 직접 테스트해 볼 수 있습니다.
- 링크:
-
OpenAI 공식 이미지 API 문서: 최신 이미지 모델 API
- 링크:
openai.com/index/image-generation-api - 설명: OpenAI 공식 gpt-image-1.5 API 사양과 비교하여 확인해 보세요.
- 링크:
-
LM Arena 그레이스케일 테스트 관찰: GPT Image 2 유출 정보
- 링크:
mindstudio.ai/blog/what-is-gpt-image-2 - 설명: 차세대 이미지 모델의 성능을 미리 엿볼 수 있는 정보입니다.
- 링크:
작성자: APIYI 기술 팀
기술 교류: 댓글을 통해 자유롭게 의견을 나누어 주세요. 더 많은 자료는 APIYI 문서 센터(docs.apiyi.com)에서 확인하실 수 있습니다.